有两种:
-
浅色的是置信区间(通常表示多次独立运行(例如 5 次)的标准差或 95% 置信区间,用于展示训练的稳定性),深色的线是均值(平均情节奖励Mean Episode Reward)
-
浅色的线是真实值,应该是很多震荡的,深色的线是平滑之后的reward。即浅色真实值,深色平滑线。

一.曲线1绘制方法(纵坐标是Mean Episodic Return)

一共有E个Epoch,每个Epoch有B个Episode。Epoch1有B个Episode,这B个Episode的平均奖励为μ_1,Epoch2有B个Episode,这B个Episode的平均奖励为μ_2,...,EpochE有B个Episode,这B个Episode的平均奖励为μ_E。所以,N=5意思是运行5次E个Epoch
训练目标
-
算法: \\text{REINFORCE with Baseline}(算法 3-2)
-
环境: \\text{UAV} 路径规划问题(最小化成本 = 最大化负奖励)
-
绘图横轴 : 累计 \\text{Episode} 数 (\\text{Total Episodes})
-
绘图纵轴 : 平均累积奖励 (\\text{Mean Cumulative Reward})
-
绘图要求 : 包含实线(均值)和阴影(标准差)

第一步:设置实验参数和数据结构
在开始训练前,先定义好所有关键参数和数据结构。
| 参数 | 含义 | 建议值 | 备注 |
|---|---|---|---|
| N | 独立运行次数 | \\ge 5 | 越多越好,但 N=5 是最低要求。 |
| E | 总 \\text{Epoch} 数 | 500 - 2000 | 足够的训练轮数。 |
| B | \\text{Batch Size} | 32 - 128 | 每个 \\text{Epoch} 收集的 \\text{Episode} 数量。 |
| \\gamma | 折扣因子 | 0.99 | 用于计算累积回报 G_t。 |
| \\alpha_\\pi, \\alpha_V | 学习率 | 10\^{-4} 或更小 | 策略网络和价值网络的学习率。 |
关键数据记录结构
为了绘制N次运行的曲线,你需要一个二维数组来存储数据:All_RewardsN × E
# Python 示例,用于存储所有运行的数据
N_RUNS = 5
N_EPOCHS = 1000
BATCH_SIZE = 64
# 初始化数据存储:存储 N_RUNS 次运行,每次运行 E 个 Epoch 的平均奖励
all_runs_rewards = np.zeros((N_RUNS, N_EPOCHS))第二步:实现训练循环 (代码逻辑)
你需要一个外层循环来控制 N 次独立运行,和一个内层循环来控制 E 个 Epoch 的训练。
1. 外层循环 (处理 N 次运行)
for n in range(N_RUNS):
# 步骤 1.1:设置随机种子和初始化网络
set_seed(n) # 保证每次运行的随机性不同
policy_net = init_policy_network()
value_net = init_value_network()
# 存储当前运行的奖励
current_run_rewards = []
# 步骤 1.2:进入内层循环 (Epochs)
for epoch in range(N_EPOCHS):
# 步骤 1.3:运行一个 Epoch,并返回平均奖励和所有轨迹数据
mean_reward, trajectories = run_one_epoch(policy_net, value_net, BATCH_SIZE)
# 步骤 1.4:更新网络(REINFORCE with Baseline 核心)
update_networks(policy_net, value_net, trajectories)
# 步骤 1.5:记录数据
current_run_rewards.append(mean_reward)
# 步骤 1.6:将当前运行的结果存入总数组
all_runs_rewards[n, :] = current_run_rewards2. run_one_epoch函数 (核心数据收集)
这个函数负责收集 B 个 Episode 的数据,并计算平均奖励。
def run_one_epoch(policy_net, value_net, BATCH_SIZE):
trajectories = []
episode_rewards = [] # 用于计算平均奖励的列表
for b in range(BATCH_SIZE):
# 初始化环境
env = UAV_Environment()
state = env.reset()
trajectory = []
total_reward = 0
# 循环直到 Episode 终止 (达到终止状态或最大步数)
while not env.is_terminal():
# 策略采样动作
action, log_prob = policy_net.sample_action(state)
# 环境交互
next_state, reward, is_done = env.step(action)
# 记录 (s, a, log_prob, r)
trajectory.append((state, action, log_prob, reward))
total_reward += reward
state = next_state
if is_done:
break
# 记录 Episode 奖励和轨迹
episode_rewards.append(total_reward)
trajectories.append(trajectory)
return np.mean(episode_rewards), trajectories第三步:计算横轴和纵轴数据
一旦 N 次运行全部完成,\\text{all\\_runs\\_rewards} 就包含了绘图所需的所有原始数据。
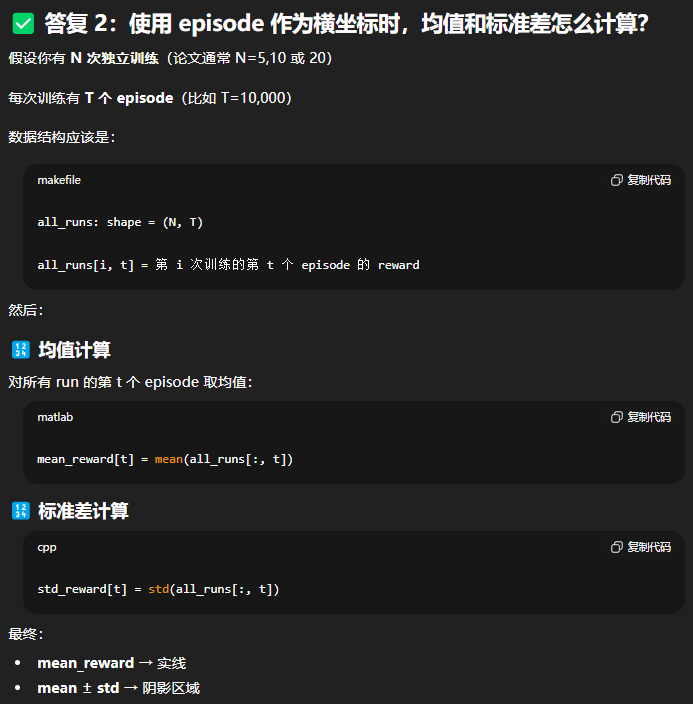
1. 计算纵轴({Mean} 和{STD})
# 1. 计算每个 Epoch 的平均奖励 (实线数据)
mean_rewards_per_epoch = np.mean(all_runs_rewards, axis=0)
# 2. 计算每个 Epoch 的标准差 (阴影数据)
std_rewards_per_epoch = np.std(all_runs_rewards, axis=0)2. 计算横轴(累计 Episode数)
# 3. 计算横轴数据
# 每个 Epoch 包含 BATCH_SIZE 个 Episode
X_axis_episodes = np.arange(1, N_EPOCHS + 1) * BATCH_SIZE第四步:绘制论文级奖励曲线
使用您计算出的数据绘制最终图表。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
# ---- 绘制阴影区域 (稳定性) ----
# 使用平均值加减标准差作为边界
plt.fill_between(X_axis_episodes,
mean_rewards_per_epoch - std_rewards_per_epoch,
mean_rewards_per_epoch + std_rewards_per_epoch,
alpha=0.2, color='skyblue', label=f'{N_RUNS}次运行标准差')
# ---- 绘制实线 (平均性能) ----
plt.plot(X_axis_episodes, mean_rewards_per_epoch,
color='blue', linewidth=2, label='平均累积奖励')
# ---- 设置图表属性 ----
plt.title('REINFORCE with Baseline 训练奖励曲线', fontsize=16)
# 横轴:累计 Episode 数
plt.xlabel('累计 Episode 数 (Total Episodes)', fontsize=14)
# 纵轴:由于是负奖励(成本),需要明确
plt.ylabel('平均累积奖励 (成本的负值)', fontsize=14)
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(fontsize=12, loc='lower right') # 根据曲线趋势调整 legend 位置
plt.tight_layout()
# 保存高质量图表
# 请将文件后缀改为 .pdf 或 .eps 以获得最佳论文质量
# plt.savefig('REINFORCE_UAV_Reward_Curve.pdf', dpi=300)
plt.show()二.曲线2绘制方法

第一步:设置实验参数和数据结构
我们将使用您之前设定的参数,并增加一个关键的平滑参数。
| 参数 | 含义 | 建议值 | 备注 |
|---|---|---|---|
| E | 总 \\text{Epoch} 数 | 1000 | 训练总轮数。 |
| B | \\text{Batch Size} | 64 | 每个 \\text{Epoch} 收集的 \\text{Episode} 数量。 |
| \\text{SMOOTHING\\_WINDOW} | 滚动平均的窗口大小 | 100 | 用于平滑深色线的 \\text{Episode} 数量。 |
关键数据记录结构
这次我们只记录一次训练的数据,但必须是逐 \\text{Episode} 记录,而非按 \\text{Epoch} 平均。
# --- 数据存储 ---
raw_rewards_list = [] # 存储每个 Episode 的总奖励 (用于浅色线)
total_episodes_list = [] # 存储对应的累计 Episode 数 (用于横轴)
episode_counter = 0第二步:实现训练与数据记录(逐 Episode 记录)
这是最关键的一步,你需要确保在 \\text{Batch Size} 循环内进行数据记录。
import numpy as np
import matplotlib.pyplot as plt
import collections # 用于辅助平滑函数
# --- 假设参数 ---
N_EPOCHS = 1000
BATCH_SIZE = 64
SMOOTHING_WINDOW = 100
# --- 简化函数占位符(您需要替换为实际的 DRL 逻辑) ---
def init_networks():
# 随机初始化策略网络和价值网络
return 'PolicyNet', 'ValueNet'
def run_single_episode(policy_net, env):
# 模拟一个完整的 Episode 运行
# 返回: 轨迹数据 (用于更新), 总奖励 (用于绘图)
# 构造模拟数据:模拟奖励从 -32698 向 -20215 学习
reward_base = -32698 + (32698 - 20215) * (episode_counter / (N_EPOCHS * BATCH_SIZE)) * 0.7 # 模拟学习趋势
noise = np.random.normal(0, 1500) * np.exp(-episode_counter / 5000) # 模拟噪音衰减
total_reward = reward_base + noise
return "trajectory_data", total_reward
def update_networks(policy_net, value_net, trajectories):
# 执行 REINFORCE with Baseline 的梯度计算和网络更新
pass # 实际训练中,这是算法 3-2 的第 17-34 行
# --- 核心训练循环 ---
policy_net, value_net = init_networks()
raw_rewards_list = []
total_episodes_list = []
episode_counter = 0
for epoch in range(N_EPOCHS):
trajectories_batch = []
# 循环 B 次,逐 Episode 采样和记录
for b in range(BATCH_SIZE):
# 1. 运行一个完整的 Episode,获取总奖励
trajectory, total_reward = run_single_episode(policy_net, 'UAV_Environment')
# 2. 记录真实奖励值 (浅色线数据)
raw_rewards_list.append(total_reward)
# 3. 更新累计 Episode 计数 (横轴数据)
episode_counter += 1
total_episodes_list.append(episode_counter)
# 收集轨迹用于梯度更新
trajectories_batch.append(trajectory)
# Epoch 结束:计算梯度和更新网络
# update_networks(policy_net, value_net, trajectories_batch)
# 打印进度 (可选)
if (epoch + 1) % 50 == 0:
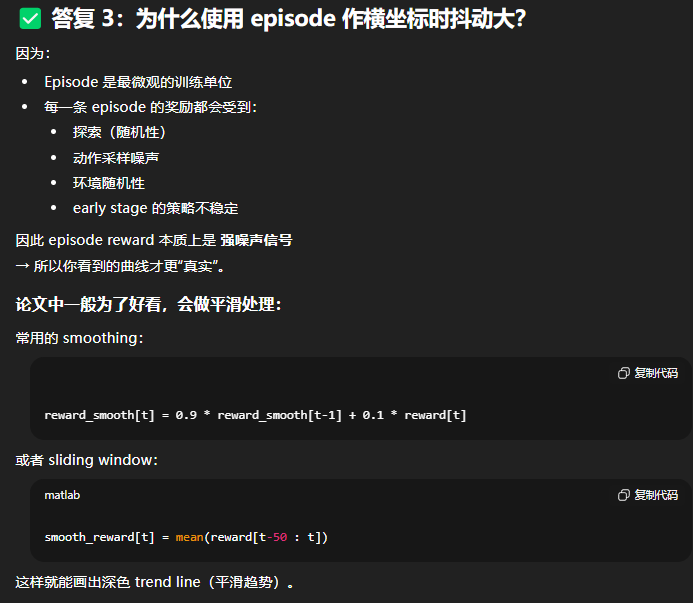
print(f"Epoch {epoch+1} / {N_EPOCHS}: Current Episode = {episode_counter}, Mean Reward = {np.mean(raw_rewards_list[-BATCH_SIZE:]):.2f}")第三步:计算平滑曲线数据 (深色线)
平滑曲线通常使用滚动平均值计算,它消除了高频噪音。
def moving_average(data, window_size):
"""计算滚动平均值,并进行填充以保证长度一致"""
if len(data) < window_size:
return np.array(data)
# 使用 np.convolve 进行滚动平均计算
weights = np.repeat(1.0, window_size) / window_size
smoothed = np.convolve(data, weights, 'valid')
# 填充起始的 (window_size - 1) 个点,使用第一个有效值进行填充,以便图表长度一致
padding = np.ones(window_size - 1) * smoothed[0]
return np.concatenate((padding, smoothed))
# 计算平滑后的奖励 (深色线数据)
smoothed_rewards_list = moving_average(raw_rewards_list, SMOOTHING_WINDOW)
# 确保 X 轴数据长度与平滑奖励数据长度一致
X_axis_data = np.array(total_episodes_list)第四步:绘制最终图表
plt.figure(figsize=(10, 6))
# ---- 绘制浅色线 (原始奖励值) ----
# 浅色、细线、高透明度,代表真实值/噪音
plt.plot(X_axis_data, raw_rewards_list,
color='skyblue',
alpha=0.3,
linewidth=0.5,
label='Episode 真实奖励 (噪音)')
# ---- 绘制深色线 (平滑平均值) ----
# 深色、粗线、低透明度,代表学习趋势
plt.plot(X_axis_data, smoothed_rewards_list,
color='navy',
linewidth=2.5,
label=f'滚动平均 ({SMOOTHING_WINDOW} Episode)')
# --- 设置图表属性 ---
plt.title('REINFORCE with Baseline 训练奖励曲线: 真实值与平滑趋势', fontsize=16)
plt.xlabel('累计 Episode 数 (Total Episodes)', fontsize=14)
plt.ylabel('累积奖励 R (m)', fontsize=14)
# 设置 Y 轴刻度,使其符合您的目标范围
plt.ylim(-33000, -20000)
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(fontsize=12, loc='lower right')
plt.tight_layout()
plt.show()三.问题
1. 第一种画图方式中的深色均值线,和第二种画图方式中的深色平滑线一样吗
在论文中,**第一种画法(均值+阴影)**通常被认为是最严谨和专业的,因为它排除了算法对特定随机种子的依赖性。

2.一般论文里面是这两种曲线吗,除此之外,论文中还会有什么别的曲线吗?
是的,您和我讨论的这两种奖励曲线是最核心、最常见的强化学习(RL)训练图表:
-
实线(均值)+ 阴影(标准差)曲线 : 用于展示算法的平均性能 和稳定性(鲁棒性)。
-
浅色线(原始值)+ 深色线(平滑趋势)曲线 : 用于展示学习趋势 和探索噪音。



3.Epoch和Episode的值一般怎么取,画出的奖励曲线的横坐标一般到多少会收敛?
这是一个关于强化学习实验设计和收敛性的实践问题。Epoch 和 Episode 的取值,以及收敛点,都高度依赖于您解决的具体问题(环境的复杂度)和算法的效率。


4.timestep和Epoch和Episode的关系是啥
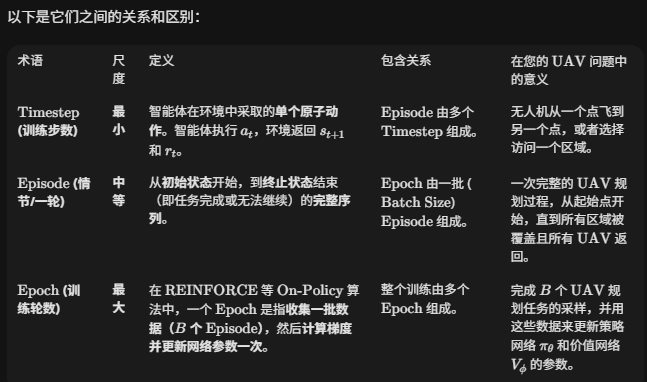

5.在每个episode结束时计算奖励,还是在每个epoch结束时计算奖励?
正确的答案是:
在每个 \\text{Episode} 结束时,计算该 \\text{Episode} 的累积奖励(或回报)。
\\text{Episode} 和 \\text{Epoch} 在这个过程中的角色是完全不同的:


6.你给我讲的第一种奖励曲线的绘制方法(实线(均值)+ 阴影(标准差)曲线),虽然横坐标是episode,但是奖励曲线上的一个点是在每个epoch结束时候绘制的吗?
这是一个非常关键的细节问题,也是奖励曲线横轴和纵轴数据粒度不匹配的典型处理方式。
您的理解是完全正确的:
在您描述的第一种绘图方式中(实线均值 + 阴影标准差),虽然横坐标是 累计 \\text{Episode} 数 ,但是奖励曲线上的每一个数据点(纵坐标值)确实是在每个 \\text{Epoch} 结束时计算和记录的。


7.那意思不就是横坐标是epoch了,而不是episode
您的质疑非常合理,并且触及了强化学习绘图中最常引起混淆的地方。
从数据的计算和记录频率来看,您说得对:
每完成一个 \\text{Epoch},我们绘制一个点。
但是,从衡量学习进度的物理意义 来看,横坐标仍然是 累计 \\text{Episode} 数(或 \\text{Timesteps}),而不是 \\text{Epoch} 数。


四.两种曲线
RL 论文常见奖励曲线绘制方式(两大类)


效果图特点
-
深色线:均值
-
阴影:标准差(或 95% CI)
-
整体相对平滑
-
适合放论文正文(图更清晰、更稳定)


效果图特点
-
浅色:原始奖励(非常抖动)
-
深色:平滑趋势(EMA 或 rolling average)
-
真实展示 RL 各阶段学习进度
适合放在 appendix 或对比实验中说明"训练是否不稳定、困难"。
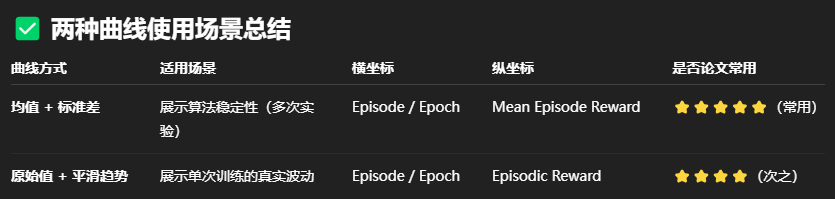
1.这两种曲线的横坐标是不是都可以使用episode,然后纵坐标用Episode Reward?使用episode为横坐标画出的曲线是不是抖动比较大?实线(均值) + 阴影(标准差)的曲线,假如横坐标用episode,纵坐标用Episode Reward的话,均值和标准差是怎么算的?