摘要:在 AIGC 爆发的时代,如何将大模型能力真正落地到垂直场景?本文将分享我开发的智能考研平台------"拾题",探讨如何利用 Vue3、Django 和 Moonshot AI (Kimi) 构建一个集智能问答、模考阅卷和择校分析于一体的全栈应用。文中将重点复盘流式响应 (SSE)、多模态 OCR 识别及 Dify 工作流集成等核心技术难点。
一. 项目背景
考研是一场信息战,也是一场持久战。作为大学生,我深知其中的痛点:
-
择校迷茫:院校数据分散,难以做出科学决策。
-
没人答疑:遇到难题,自学难以突破,找学长学姐成本高。
-
复盘低效:错题整理还在用手抄,复习效率低下。
于是,"拾题"应运而生。我希望打造一个 24小时在线的 AI 私人助教,利用大模型的推理能力和多模态理解能力,重塑备考体验。
二. 技术选型与项目架构
为了保证开发效率与系统的可扩展性,我采用了经典的前后端分离架构,并通过 API 网关集成外部 AI 服务。
1. 技术栈
- 前端:Vue 3 (Composition API) + TypeScript + Pinia + Element Plus
- 后端:Django 5.2 + Django REST Framework + MySQL 8.0
- AI核心:Moonshot AI (Kimi) + Qwen-VL (阿里通义) + Dify
2. 系统架构图
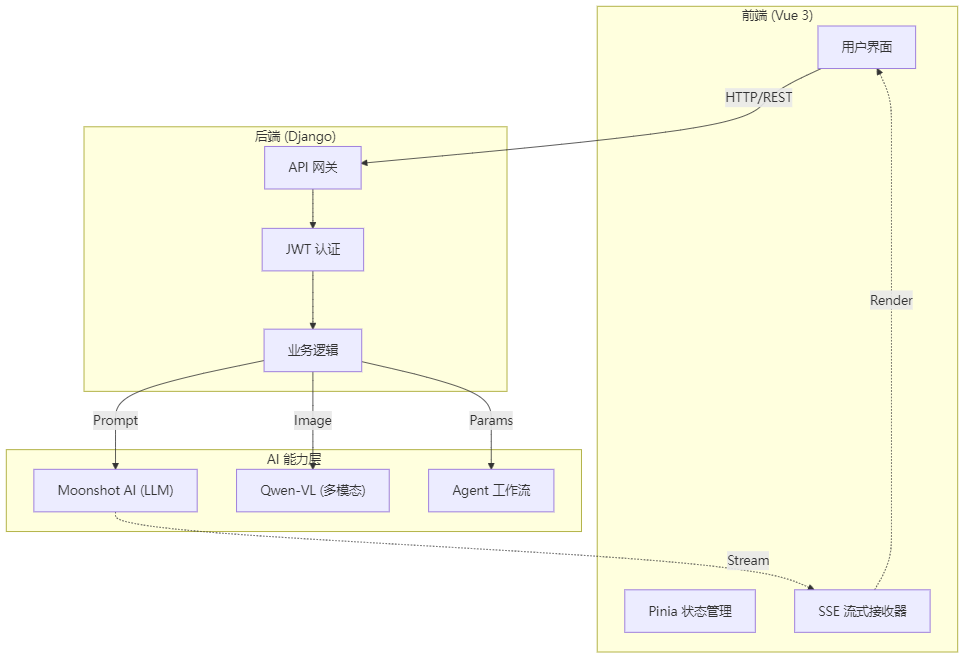
三. 核心技术难点复盘
在开发过程中,我们不仅仅是简单的 API 调用,而是解决了一系列工程化难题。
难点一:实现类 ChatGPT 的流式打字机效果 (Server-Sent Events)
**挑战:**大模型生成长文本通常需要几秒甚至几十秒。如果使用传统的Request-Response模式,用户会面对长达 30 秒的白屏,体验极差。我们需要实现"边生成边显示"的效果。
**后端解决方案 (Django):**利用 Django 的StreamingHttpResponse。我们不直接返回 JSON,而是返回一个生成器 (Generator)。
python
# backend/chat/views.py (简化示例)
def event_stream(question):
client = OpenAI(api_key=API_KEY, base_url="...")
response = client.chat.completions.create(
model="kimi-k2-turbo",
messages=[{"role": "user", "content": question}],
stream=True # 关键点:开启流式
)
for chunk in response:
content = chunk.choices[0].delta.content
if content:
yield content # 实时 yield 字符
return StreamingHttpResponse(event_stream(q), content_type='text/event-stream')前端解决方案 (Vue 3): 使用fetchAPI的ReadableStream进行读取,避免等待整个响应结束。
TypeScript
// frontend/src/views/dashboard/SmartQAView.vue (核心逻辑)
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
// 实时追加到当前消息内容,触发 Vue 响应式更新
currentMessage.value.content += chunk;
// 滚动到底部
scrollToBottom();
}效果:首字响应时间从 5s 缩短至 0.5s,用户体验极其丝滑。
难点二:考研数学公式的精准识别 (OCR + LLM)
挑战: 考研数学题包含大量复杂的积分符号、矩阵和几何图形。普通的 OCR 只能识别文字,对公式识别一塌糊涂,直接传给 LLM 会导致严重的幻觉(Hallucination)。
解决方案 : 我们引入了 多模态大模型 (Qwen-VL) 作为"前置视觉处理器"。
1.上传:用户上传题目图片。
2.识别:后端调用 Qwen-VL-OCR 接口,专门提取LaTeX格式的公式。
- Prompt: "请提取图片中的所有内容,公式请使用LaTeX格式输出。"
3.推理:将识别出的精准文本作为Context,拼接Prompt发送给Kimi大模型进行解题。
代码片段:
python
# 先识别
ocr_response = dashscope.MultiModalConversation.call(
model="qwen-vl-ocr-latest",
messages=[{"role": "user", "content": [{"image": img_path}, {"text": "提取文字"}]}]
)
extracted_text = ocr_response.output.choices[0].message.content
# 再推理
llm_response = client.chat.completions.create(
model="kimi-k2-turbo",
messages=[{"role": "user", "content": extracted_text}]
)难点三:基于 Dify 的智能择校工作流
挑战: "智能择校"不是简单的问答,它需要结合知识库中的报录比、分数线,并结合用户偏好进行分析。单一的Prompt无法完成如此复杂的任务链。
解决方案 : 我们使用Dify编排了一个Agent工作流。
-
输入解析:提取用户的本科院校、考研分数、目标地区。
-
知识库匹配:调用我们预存的院校数据库。
-
报告生成:LLM 综合上述信息,生成结构化的 Markdown 报告。
后端只需调用 Dify 的 API 接口,即可获得这就好比雇佣了一个专业的咨询团队。
四. 项目展示
用户注册界面:
用户登录界面:
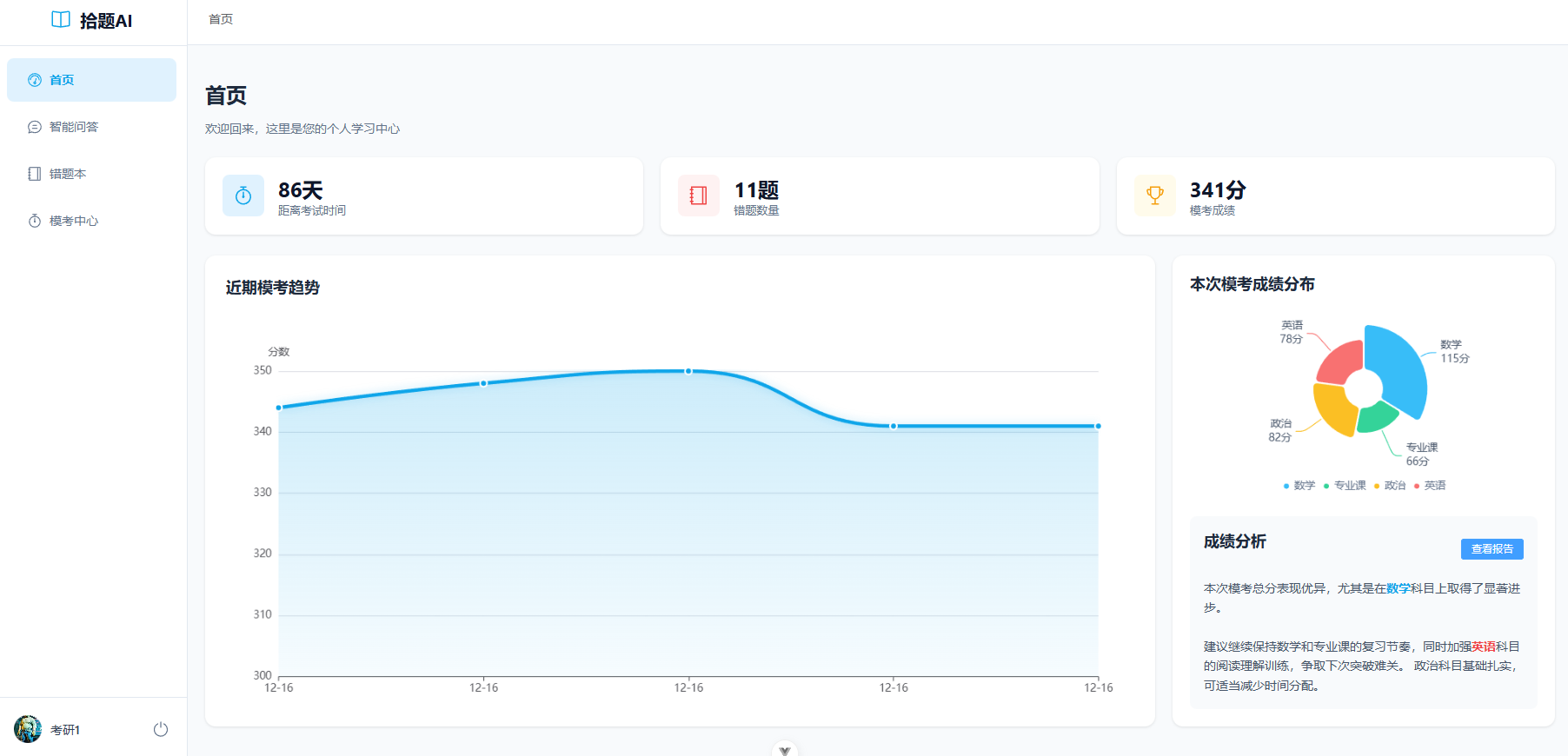
首页界面:
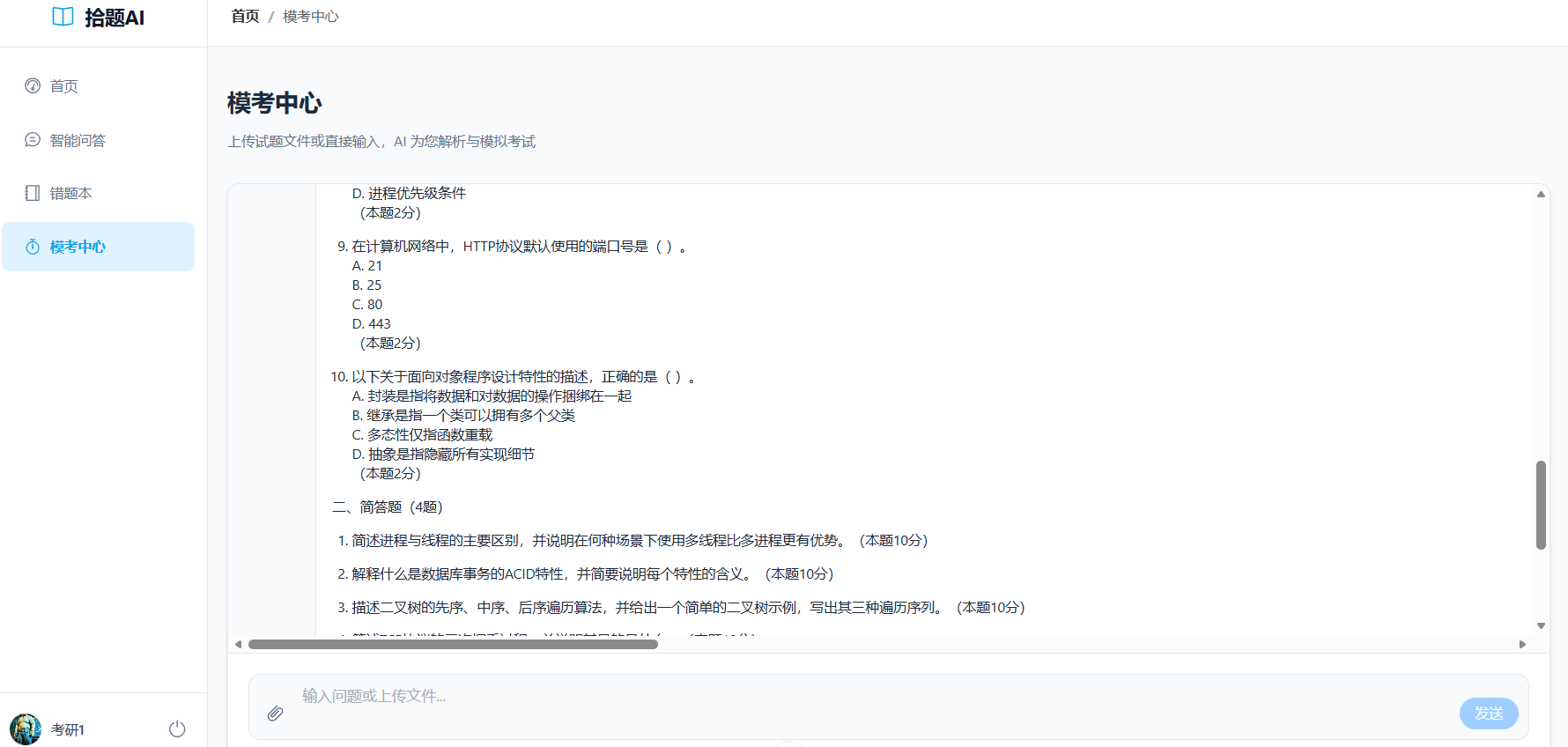
生成报告界面:
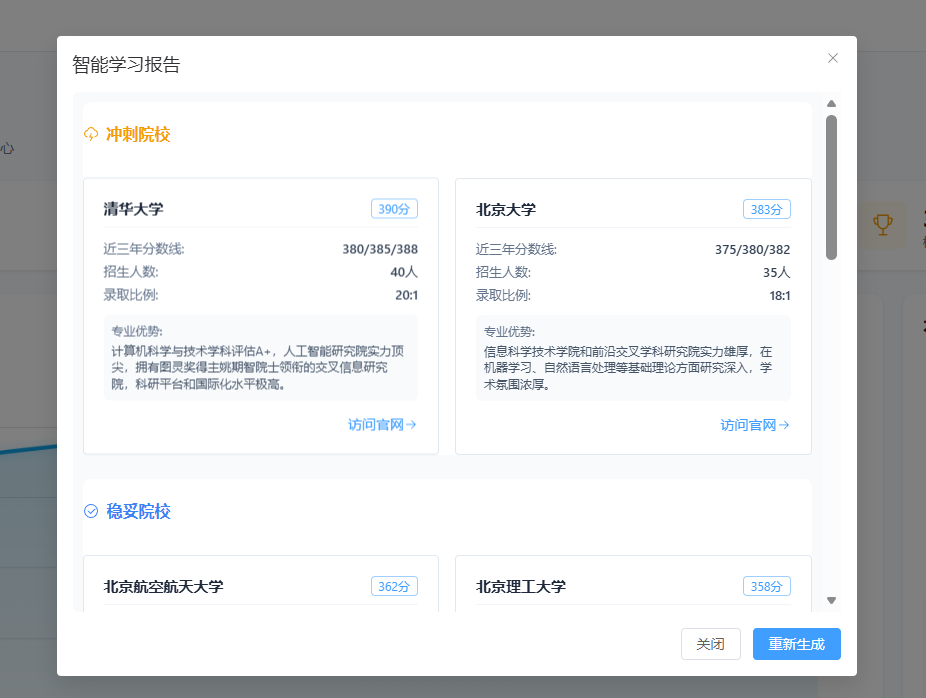
智能问答界;面:
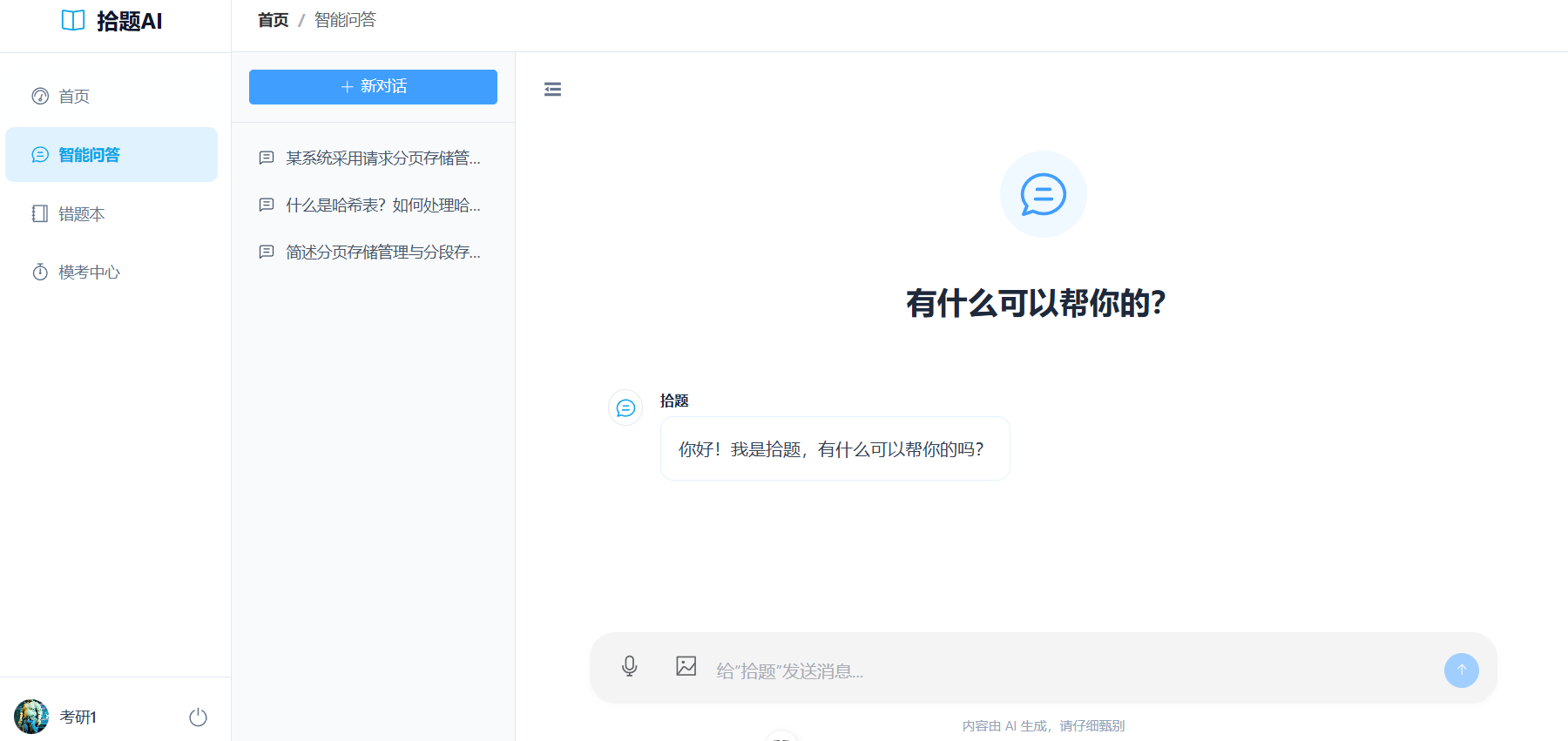
错题本界面:
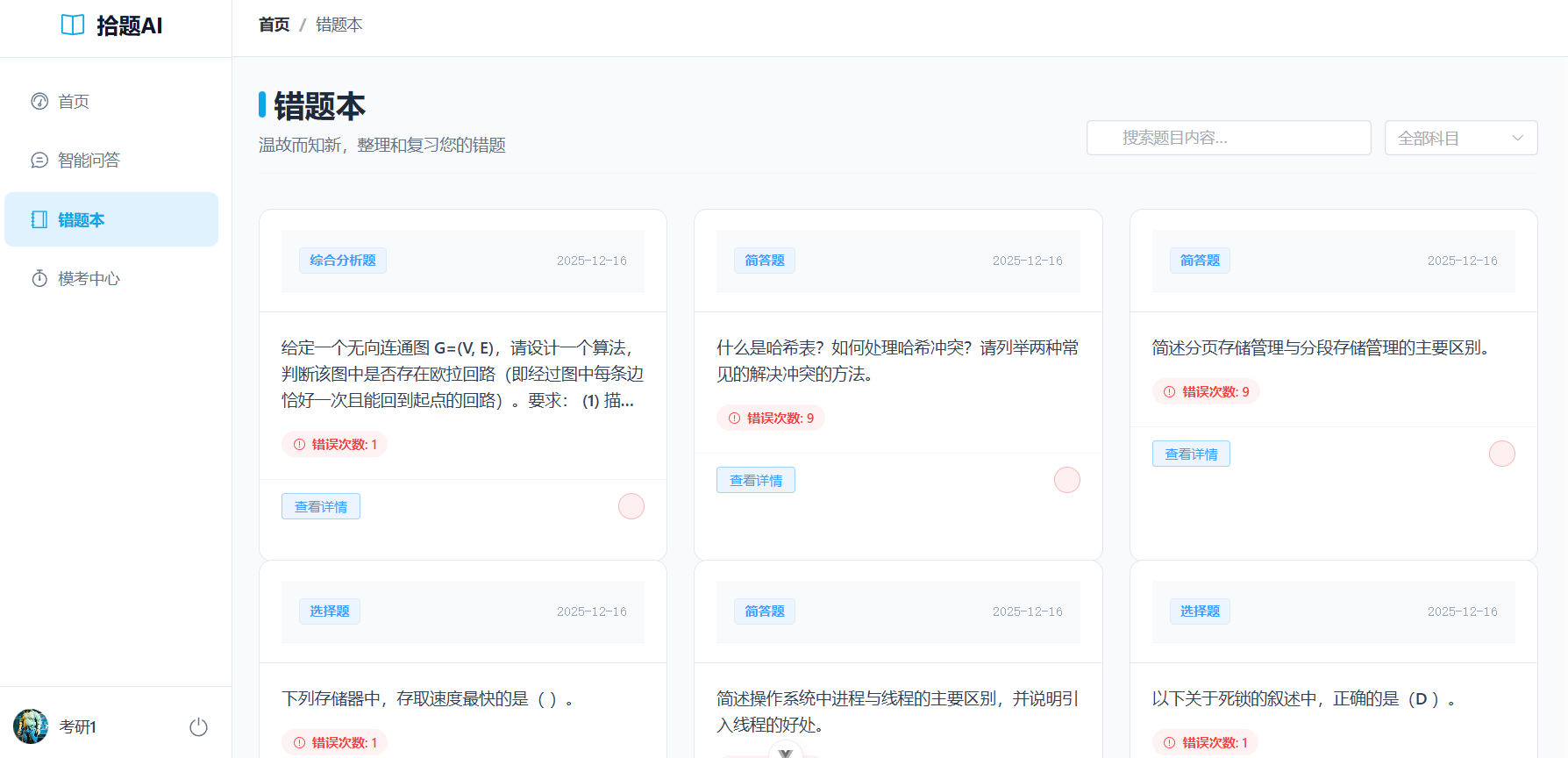
模考中心界面:
个人中心界面:
五. 项目开发收获与总结
作为全栈开发者,除了代码本身,工程化规范也至关重要。
-
接口先行:在开发前,我详细定义了Swagger/OpenAPI文档。例如,明确了流式接口返回的是纯文本还是SSE格式的数据包,避免了联调时的推诿。
-
Git 工作流:我们严格执行Feature Branch模式。每个人在feature/xxx分支开发,禁止直接commit到main。
-
统一的数据清洗:由于 AI 的输出具有不确定性(有时返回 JSON,有时返回 Markdown),我们在后端增加了一层"清洗层",确保前端拿到的数据结构永远是可预期的。