Java Map 详解:原理、实现与使用场景
一、介绍
Map 是 Java 集合框架(java.util)中键值对(Key-Value) 形式的集合接口,与 List/Set 并列(继承自 Collection 的父接口 Iterable,但不直接继承 Collection)。核心特征是:键(Key)唯一且无序(部分实现有序),值(Value)可重复,通过键快速查找值,是日常开发中存储关联数据的核心工具。
特性:
- 键值对映射:每个 Key 对应唯一的 Value,Key 不允许重复(若重复插入,新 Value 会覆盖旧 Value);
- Key 不可变性 :作为 Key 的对象需重写
hashCode()和equals()方法(保证哈希一致性),且建议使用不可变类型(如 String、Integer),避免修改后哈希值变化导致无法查找; - 支持 null:不同实现类对 null 的支持不同(如 HashMap 允许 1 个 null Key + 多个 null Value,Hashtable 不允许 null);
- 无序性(默认):大部分 Map 实现(如 HashMap)不保证键值对的存储 / 遍历顺序,有序实现需显式指定(如 TreeMap、LinkedHashMap)。
二、Map 接口核心方法
Map 定义了键值对操作的核心方法,覆盖增删改查、遍历等场景:
| 方法 | 作用 |
|---|---|
V put(K key, V value) |
添加 / 替换键值对:Key 不存在则新增,存在则替换 Value,返回旧 Value(无则返回 null) |
V get(Object key) |
根据 Key 获取 Value,Key 不存在返回 null |
V remove(Object key) |
删除指定 Key 的键值对,返回被删除的 Value(无则返回 null) |
boolean containsKey(Object key) |
判断是否包含指定 Key |
boolean containsValue(Object value) |
判断是否包含指定 Value(需遍历,效率低) |
int size() |
返回键值对数量 |
boolean isEmpty() |
判断是否为空 |
void clear() |
清空所有键值对 |
Set<K> keySet() |
返回所有 Key 的 Set 集合(视图,修改会同步到原 Map) |
Collection<V> values() |
返回所有 Value 的 Collection 集合(视图) |
Set<Map.Entry<K,V>> entrySet() |
返回键值对(Entry)的 Set 集合(遍历最优方式) |
三、Map 主要实现类
Java 提供了多款 Map 实现类,适配不同的性能、有序性、并发场景,核心如下:
1. HashMap(最常用)
底层实现:JDK 8 前 = 数组(哈希桶)+ 链表;JDK 8 后 = 数组 + 链表 / 红黑树(链表长度 ≥8 转红黑树,≤6 转回链表)。
补充:
HashMap 的底层由「哈希桶数组」+「链表 / 红黑树」组成,核心设计目标是:通过哈希算法将 Key 映射到数组下标,实现 O (1) 级别的快速存取;通过链表 / 红黑树解决「哈希冲突」(不同 Key 哈希值相同的情况)。
- 哈希桶数组(
table):默认初始长度 16(2 的幂),每个下标对应一个「桶」,桶内存储链表或红黑树; - 链表:当多个 Key 哈希到同一桶时,先以链表形式存储;
- 红黑树:当链表长度 ≥8 且数组长度 ≥64 时,链表转为红黑树(查询性能从 O (n) 优化为 O (log n));当红黑树节点数 ≤6 时,转回链表(减少红黑树维护开销)。
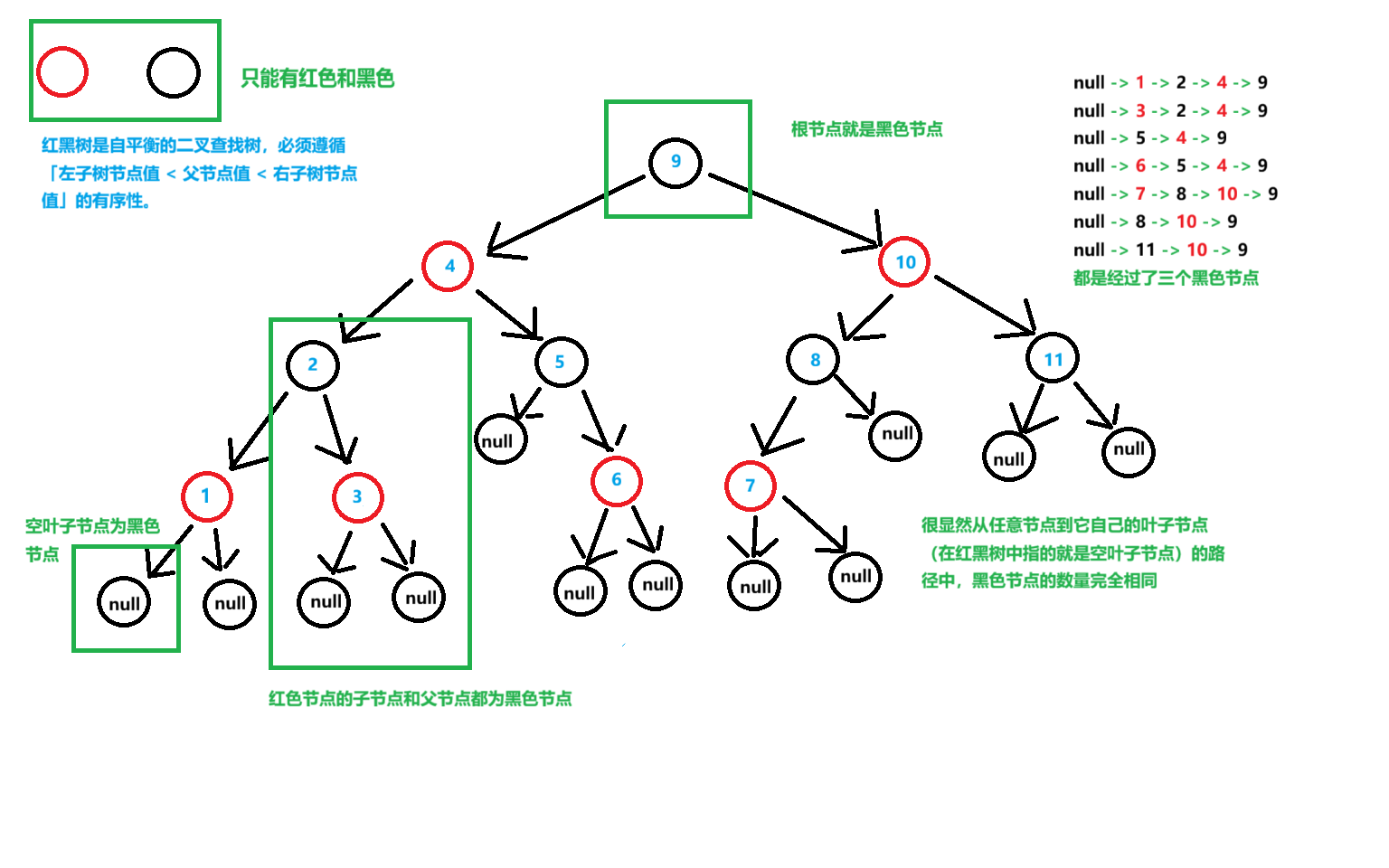
红黑树:
红黑树是带红 / 黑颜色标记的自平衡二叉查找树,也是二叉树的一种,不过有5条规则对树的高度进行限制,增删改查的时间复杂度稳定在O(logn)
补充一下那5条规则:
(1)每个节点只能为黑色或者红色
(2)根节点必须为黑色
(3)所有"空叶子节点"都是黑色
(4)红色节点的父节点和子节点都必须为黑色(你也可以这样理解,不能连续俩红色节点)
(5)从任意节点到它自己所有叶子节点(在红黑树中这个叶子节点就是指的空叶子节点)的路径中,黑色节点的数量完全相同
规则是为了做什么?
保证树的结构不会退化成链表,同时保证增删查改始终是 O (log n)
(补:最长路径的长度 ≤ 2 × 最短路径的长度,两者的差值最大为 最短路径的长度)
什么是桶?
桶就是 HashMap 哈希桶数组里的一个存储单元,负责接收通过哈希计算分配过来的键值对节点,解决哈希冲突的链表 / 红黑树也都是在桶内部形成的。
简单举个例子:
把 HashMap 想象成一个 带编号的快递柜 ,这个快递柜的每个独立格子 就是一个 桶。
- 快递柜 = 哈希桶数组(table)快递柜有很多个格子,每个格子都有自己的编号(比如 0、1、2...15),对应 HashMap 数组的索引。
- 桶 = 快递柜的单个格子每个格子(桶)的作用是存放 "属于自己" 的快递。在 HashMap 中,通过哈希计算,会把键值对节点分配到对应编号的桶里。
- 哈希冲突 = 一个格子里放多个快递
- 理想情况:一个快递(节点)对应一个格子(桶),取件时直接按编号找,速度飞快(对应 HashMap 的 O (1) 存取)。
- 现实情况:可能出现多个快递被分配到同一个格子(不同 Key 计算出相同的数组索引),这就是哈希冲突。这时,HashMap 会在这个桶里用链表把这些节点串起来;如果链表太长(≥8),就会变成红黑树,提升查询效率。
核心特点:
- 存取效率高(平均 O (1) 时间复杂度),基于哈希表快速定位;
- 无序(存储顺序 ≠ 插入顺序);
- 允许 1 个 null Key、多个 null Value;
- 非线程安全(多线程操作可能导致死循环、数据丢失);
- 初始容量 16,负载因子 0.75(扩容阈值 = 容量 × 负载因子,默认 12),扩容时容量翻倍,且重新哈希。
机制详解:
哈希计算与索引定位:
HashMap 高效存取的核心是「将 Key 映射到数组下标」,分为两步:
1.Key 的哈希值计算
为了减少哈希冲突,HashMap 对 Key 的 hashCode() 做了二次哈希(扰动函数):
java
static final int hash(Object key) {
int h;
// 核心逻辑:key.hashCode() ^ (h >>> 16)
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}- 作用:将 Key 的哈希值高 16 位与低 16 位异或,混合高低位特征,减少哈希冲突(尤其数组长度较小时,仅低几位参与取模,混合后能利用高位信息);
- null Key 处理:hash 值固定为 0,因此 null Key 始终映射到数组索引 0。
2.数组索引计算
通过哈希值计算数组下标,利用「位运算替代取模」提升性能(仅当数组长度为 2 的幂时生效):
java
java
// i = 哈希值 & (数组长度 - 1)
int index = hash & (table.length - 1);-
示例:数组长度 16(二进制 10000),
table.length - 1 = 15(二进制 01111);哈希值与 15 按位与,等价于hash % 16,但位运算更快。 -
为什么数组长度是 2 的幂?
→ 保证hash & (length-1)等价于取模,且位运算效率远高于取模;
→ 扩容时,节点新索引要么不变,要么 = 原索引 + 原数组长度(简化扩容迁移逻辑)。
扩容机制:
条件:
- 首次
put时,table为 null,初始化数组(默认长度 16,threshold=16×0.75=12); - 后续
put时,若size > threshold,触发扩容; - 链表长度≥8 但数组长度 < 64 时,优先扩容(而非树化)。
步骤:
java
// 1. 计算新容量:原容量翻倍(始终保持2的幂)
int newCap = oldCap << 1; // 如16→32,32→64...
// 2. 计算新扩容阈值:newThr = newCap × loadFactor
int newThr = oldThr << 1;
// 3. 创建新数组(长度newCap)
Node<K,V>[] newTab = (Node<K,V>[]) new Node[newCap];
table = newTab;
// 4. 迁移原数组节点到新数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = table[j]) != null) {
table[j] = null; // 释放原数组引用(帮助GC)
// 情况1:桶内仅一个节点,直接计算新索引并放入
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 情况2:桶内是红黑树,拆分红黑树并迁移
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 情况3:桶内是链表,拆分链表(优化:无需重新哈希,仅判断高位)
else {
// 链表拆分规则:新索引 = 原索引 或 原索引 + oldCap
Node<K,V> loHead = null, loTail = null; // 原索引节点
Node<K,V> hiHead = null, hiTail = null; // 原索引+oldCap节点
Node<K,V> next;
do {
next = e.next;
// 核心判断:哈希值的第n位(oldCap的二进制位)是否为0
if ((e.hash & oldCap) == 0) {
// 第n位为0 → 新索引=原索引
if (loTail == null) loHead = e;
else loTail.next = e;
loTail = e;
} else {
// 第n位为1 → 新索引=原索引+oldCap
if (hiTail == null) hiHead = e;
else hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 放入新数组
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}使用示例:
java
Map<String, Integer> hashMap = new HashMap<>();
hashMap.put("Java", 1);
hashMap.put("Python", 2);
Integer value = hashMap.get("Java"); // 获取值:1
hashMap.put("Java", 3); // 替换值,旧值 1 被覆盖各操作逻辑:
1.存
先定位桶 → 无冲突则新增节点 → 有冲突则按链表 / 红黑树处理 → 替换重复 Key 的 Value → 检查扩容。
2.取
定位桶 → 桶头匹配直接返回 → 红黑树 / 链表遍历匹配 → 未找到返回 null。
3.删
定位待删除节点 → 按链表 / 红黑树规则删除 → 更新 size 和 modCount。
2. LinkedHashMap
底层实现:HashMap + 双向链表(维护插入 / 访问顺序)。
补充:
LinkedHashMap 完全复用 HashMap 的哈希桶数组、节点哈希 / 扩容 / 树化等逻辑,仅通过「双向链表」改造节点结构、新增头尾指针,实现有序性。
- 哈希桶层:和 HashMap 完全一致,负责通过哈希快速定位节点,解决哈希冲突(链表 / 红黑树);
- 双向链表层 :所有节点通过
before/after指针串联,head指向最早节点,tail指向最新节点,专门维护遍历顺序; - 节点复用:LinkedHashMap 的 Entry 继承 HashMap.Node,因此哈希桶里的节点同时属于「哈希链表 / 红黑树」和「双向链表」,一个节点两个 "身份"。
什么是节点?
在 LinkedHashMap(以及 HashMap)中,节点(Node/Entry) 是存储「键值对(Key-Value)」的最小单元 ------ 就像快递包裹本身,而桶是放包裹的格子、双向链表是串包裹的绳子。
举个具体的例子:
比如你往 LinkedHashMap 里存 put("手机", 1999)、put("耳机", 299)、put("充电器", 99):
-
每个键值对对应一个「节点」:
节点 1:Key = 手机,Value=1999;
节点 2:Key = 耳机,Value=299;
节点 3:Key = 充电器,Value=99。
-
这些节点会按哈希规则被分配到不同的桶(比如手机→3 号格、耳机→5 号格、充电器→3 号格):
3 号桶里有两个节点(手机 + 充电器),用链表串起来;5 号桶只有耳机节点。
-
同时,这三个节点会被双向链表串成
head→手机→耳机→充电器→tail(插入顺序);如果调用get("手机"),节点 1 会被挪到尾部,链表变成head→耳机→充电器→手机→tail(访问顺序)。
核心特点:
- 继承 HashMap 的所有特性,额外保证「有序性」;
- 有序模式:
- 插入顺序(默认):遍历顺序 = 插入顺序;
- 访问顺序:调用
get()/put()后,该键值对移至链表尾部(可实现 LRU 缓存);
- 非线程安全,性能略低于 HashMap(维护链表开销)。
使用示例(LRU 缓存):
java
// 初始容量16,负载因子0.75,访问顺序模式
Map<String, Integer> lruMap = new LinkedHashMap<>(16, 0.75f, true);
lruMap.put("a", 1);
lruMap.put("b", 2);
lruMap.get("a"); // 访问后,"a" 移至尾部
// 遍历顺序:b → a(访问顺序)
for (Map.Entry<String, Integer> entry : lruMap.entrySet()) {
System.out.println(entry.getKey());
}3. TreeMap
底层实现:红黑树(自平衡的二叉查找树)。
核心特点:
- 有序:默认按 Key 的自然顺序(如 Integer 升序、String 字典序),或自定义 Comparator 排序;
- 无 null Key(会抛 NullPointerException),允许 null Value;
- 存取效率 O (log n)(红黑树查找 / 插入),低于 HashMap;
- 非线程安全;
- 适合需要排序的场景(如按 Key 范围查询)。
使用示例(自定义排序):
java
// 按 Key 降序排序
Map<Integer, String> treeMap = new TreeMap<>((k1, k2) -> k2 - k1);
treeMap.put(3, "c");
treeMap.put(1, "a");
treeMap.put(2, "b");
// 遍历顺序:3 → 2 → 1
for (Integer key : treeMap.keySet()) {
System.out.println(key);
}4. Hashtable(古老的线程安全实现)
底层实现:数组 + 链表(JDK 8 未优化红黑树)。
补充:
Hashtable 无红黑树优化(全程仅数组 + 链表),线程安全通过「方法级 synchronized」实现,是典型的 "简单粗暴" 的线程安全哈希表设计。
- 哈希桶数组:默认初始长度 11(非 2 的幂,区别于 HashMap),每个下标对应一个桶,桶内存储链表;
- 链表:所有哈希冲突的节点(Key 哈希到同一桶)通过
next指针串联,无红黑树优化,链表过长时查询性能退化至 O (n); - 线程安全:所有核心方法(put/get/remove)都加
synchronized锁,锁粒度为整个 Hashtable 对象。
核心特点:
- 线程安全(方法级
synchronized锁),但锁粒度大,性能差; - 不允许 null Key/Value(抛 NullPointerException);
- 初始容量 11,负载因子 0.75,扩容时容量 = 原容量 ×2 +1;
- 基本被 ConcurrentHashMap 替代,仅兼容旧代码时使用。
机制详解:
哈希计算与扩容:
-
Key 的哈希计算(无扰动优化)
Hashtable 的哈希计算逻辑简单,无 HashMap 的 "高低位异或" 扰动优化,且直接使用
key.hashCode()(不允许 null Key):java// 计算Key的哈希值(简化版) int hash = key.hashCode(); // 计算数组索引(取模,而非位运算) int index = (hash & 0x7FFFFFFF) % table.length; -
扩容机制(区别于HashMap):
Hashtable 扩容触发后,新容量 = 原容量 × 2 + 1(而非 HashMap 的翻倍)
java// 1. 计算新容量:原容量 ×2 +1(如 11→23,23→47...) int newCapacity = table.length * 2 + 1; // 2. 计算新扩容阈值:newThr = (int)(newCapacity × loadFactor) int newThreshold = (int)(newCapacity * loadFactor); // 3. 创建新数组(长度newCapacity) Entry<?,?>[] newTable = new Entry<?,?>[newCapacity]; // 4. 迁移原数组节点到新数组(重新计算索引,拷贝链表) for (int i = 0; i < table.length; i++) { Entry<K,V> e = (Entry<K,V>)table[i]; if (e != null) { table[i] = null; // 释放原数组引用 do { Entry<K,V> next = e.next; // 重新计算新索引(取模) int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = (Entry<K,V>)newTable[index]; newTable[index] = e; e = next; } while (e != null); } } // 5. 替换数组和阈值 table = newTable; threshold = newThreshold;差异总结:
- 容量增长规则:
2n+1(保证素数,理论减少哈希冲突,但无实际性能优势),HashMap 是2n(2 的幂,位运算优化); - 索引重计算:每次扩容都需对所有节点重新取模,无 HashMap 的 "高位判断" 优化,扩容开销更大;
- 触发条件:
count ≥ threshold(HashMap 是size > threshold),更早触发扩容。
- 容量增长规则:
5. ConcurrentHashMap(并发安全)
底层实现:JDK 8 前 = 分段锁(Segment 数组 + HashMap);JDK 8 后 = 数组 + 链表 / 红黑树 + CAS + synchronized(锁哈希桶,粒度更细)。
补充:
- 哈希桶层:与 HashMap 一致(数组长度为 2 的幂,链表≥8 转红黑树),但数组 / 节点关键字段(
table/val/next)用volatile保证多线程可见性; - 并发控制层:
- 无竞争时:用 CAS 操作新增节点(无锁);
- 有竞争时:对「单个哈希桶」加
synchronized锁(仅锁住冲突的桶,其他桶可并行操作); - 扩容时:用
ForwardingNode标记桶状态,多线程协同扩容(避免单线程扩容瓶颈);
- 节点特性:
Node节点的val/next为volatile,保证修改后其他线程能立即感知。
核心特点:
- 线程安全(高并发):JDK 8 后锁粒度为「单个哈希桶」,并发性能远高于 Hashtable;
- 支持 1 个 null Key(JDK 8 后)、多个 null Value;
- 存取效率接近 HashMap(并发场景下);
- 迭代器是 "弱一致性",不会抛
ConcurrentModificationException; - 适合高并发读写的场景(如分布式缓存、业务核心数据存储)。
扩容机制(多线程协同)
当 size > 容量 × 负载因子(默认初始容量 16,负载因子 0.75,阈值 12),且当前数组(table)无其他扩容操作时触发。
ConcurrentHashMap 扩容由「触发线程 + 其他访问线程」协同完成,避免单线程扩容瓶颈:
- 触发条件:
size > sizeCtl(同 HashMap); - 扩容流程:
- 创建
nextTable(容量翻倍); - 遍历
table桶,将桶节点迁移到nextTable; - 迁移时,将原桶头节点替换为
ForwardingNode(标记扩容中); - 其他线程访问该桶时,检测到
ForwardingNode,会暂停当前操作,协助扩容;
- 创建
- 核心优势:多线程并行迁移不同桶,大幅提升扩容效率。
使用示例:
java
Map<String, String> concurrentMap = new ConcurrentHashMap<>();
// 多线程安全写入
new Thread(() -> concurrentMap.put("thread1", "data1")).start();
new Thread(() -> concurrentMap.put("thread2", "data2")).start();
// 安全读取
System.out.println(concurrentMap.get("thread1"));6. Properties(配置文件专用)
底层实现:继承 Hashtable,Key/Value 均为 String 类型。
补充:
Properties 完全复用 Hashtable 的哈希表核心逻辑(数组 + 链表、方法级 synchronized 锁、禁止 null 值),仅在其基础上增加「Key/Value 强制为 String 类型」和「配置文件读写」的扩展方法。
核心存储层 :完全复用 Hashtable 的 table 数组(初始容量 11,扩容规则 2n+1)、Entry 链表节点,线程安全通过方法级 synchronized 实现;
扩展层:
- 类型约束:Key/Value 实际使用时强制为 String(虽底层仍存储 Object,但
setProperty()/getProperty()限定为 String); - 配置继承:通过
defaults实现配置复用(当前配置无 Key 时,从默认配置集查找); - IO 能力:
load()/store()方法解析 / 生成.properties格式的配置文件(键值对以key=value换行存储)。
核心特点:
- 专为读取配置文件(.properties)设计,支持
load()/store()方法读写文件; - 线程安全(继承 Hashtable 的 synchronized 方法);
- 常用场景:读取系统配置、项目配置文件。
操作原理:
配置文件加载(load ())
load() 是 Properties 最核心的扩展方法,用于从 .properties 文件 / 输入流解析键值对:
java
// 示例:加载配置文件
Properties props = new Properties();
props.load(new FileInputStream("config.properties"));解析:
- 按行读取输入流,忽略注释行(以
#/!开头)和空行; - 解析每行的
key=value格式(支持:/ 空格 作为分隔符),去除首尾空格; - 调用
put(key, value)(继承 Hashtable)将键值对存入哈希表; - 全程加
synchronized锁,保证线程安全。
配置获取(getProperty ())
getProperty() 是 String 专属的获取方法,支持默认配置集查找:
java
String url = props.getProperty("db.url");
// 带默认值:若Key不存在,返回默认值"jdbc:mysql://localhost"
String url = props.getProperty("db.url", "jdbc:mysql://localhost");查找逻辑:
- 调用 Hashtable 的
get(key)获取值,强转为 String; - 若值为 null 且
defaults不为 null,递归从defaults中查找; - 若仍为 null,返回指定的默认值(或 null)。
配置存储(store ())
store() 用于将配置写入文件 / 输出流,生成标准 .properties 文件:
java
props.store(new FileOutputStream("config.properties"), "DB Config");写入逻辑:
- 先写入注释(可选)和当前时间戳;
- 遍历哈希表的 Entry 链表,按
key=value格式逐行写入; - 全程加
synchronized锁,保证写入过程不被打断。
基础操作(put/remove)
Properties 未重写 Hashtable 的 put()/remove() 方法,完全复用其逻辑:
setProperty(key, value)本质是调用put(key, value),仅限定参数为 String;- 所有操作均加
synchronized锁,线程安全但并发性能差(同 Hashtable)。
使用示例:
java
Properties props = new Properties();
// 读取配置文件
props.load(new FileInputStream("config.properties"));
String url = props.getProperty("db.url"); // 获取配置值四、Map 常见使用场景
| 场景 | 推荐实现类 |
|---|---|
| 日常开发、无排序、高读写性能 | HashMap |
| 需要有序(插入 / 访问顺序)、LRU 缓存 | LinkedHashMap |
| 需要按 Key 排序、范围查询 | TreeMap |
| 高并发读写、线程安全 | ConcurrentHashMap |
| 配置文件读写 | Properties |
| 旧代码兼容、低并发线程安全 | Hashtable |
五、Map 遍历方式(性能对比)
Map 遍历的核心是操作 entrySet()/keySet()/values(),推荐优先级:
entrySet 遍历(最优):直接获取键值对,无需二次查询,性能最高;
java
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
}迭代器遍历(支持删除) :适合遍历中删除元素,避免 ConcurrentModificationException;
java
Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, Integer> entry = it.next();
if (entry.getValue() == 2) {
it.remove(); // 安全删除
}
}keySet + get () 遍历(低效):需二次哈希查询,性能最差,不推荐;
java
for (String key : map.keySet()) {
Integer value = map.get(key); // 额外哈希查询
}Lambda 遍历(简洁):JDK 8+ 支持,代码简洁,性能接近 entrySet;
java
map.forEach((key, value) -> System.out.println(key + ":" + value));六、注意事项
- Key 的哈希与相等性:
- 自定义对象作为 Key 时,必须重写
hashCode()和equals()(保证相同对象哈希值相同,不同对象哈希值尽量不同); - 避免使用可变对象作为 Key(如 ArrayList),修改后哈希值变化会导致无法查找。
- 自定义对象作为 Key 时,必须重写
- HashMap 扩容优化:
- 已知元素数量时,提前指定初始容量(如
new HashMap<>(100)),避免频繁扩容(扩容需重新哈希,开销大); - 负载因子默认 0.75 是性能与内存的平衡,无需轻易修改。
- 已知元素数量时,提前指定初始容量(如
- 并发安全:
- HashMap/LinkedHashMap/TreeMap 非线程安全,多线程修改需手动加锁(如
Collections.synchronizedMap()),或直接使用 ConcurrentHashMap; - ConcurrentHashMap 不支持
null Key(JDK 7)/ 支持 1 个 null Key(JDK 8+),需注意空值处理。
- HashMap/LinkedHashMap/TreeMap 非线程安全,多线程修改需手动加锁(如
- TreeMap 排序:
- 自定义对象作为 Key 时,需实现
Comparable接口,或创建 TreeMap 时指定 Comparator,否则抛ClassCastException。
- 自定义对象作为 Key 时,需实现
七、总结
Map 是 Java 中存储键值对的核心集合,核心实现类各有侧重:
- HashMap:性能均衡,适合绝大多数无排序、非并发场景;
- LinkedHashMap:有序 + HashMap 特性,适合缓存场景;
- TreeMap:排序 + 范围查询,适合有序键值对场景;
- ConcurrentHashMap:高并发安全,适合核心业务的并发存储;
- Properties:配置文件专用,简单易用。
七、总结
Map 是 Java 中存储键值对的核心集合,核心实现类各有侧重:
- HashMap:性能均衡,适合绝大多数无排序、非并发场景;
- LinkedHashMap:有序 + HashMap 特性,适合缓存场景;
- TreeMap:排序 + 范围查询,适合有序键值对场景;
- ConcurrentHashMap:高并发安全,适合核心业务的并发存储;
- Properties:配置文件专用,简单易用。
选择时需根据「有序性、并发要求、性能、业务场景」四大维度权衡,同时注意 Key 的不可变性和遍历方式的性能优化。
附表:
| JDK 版本 | 核心变化点 | 涉及 Map 实现类 | 详细说明 |
|---|---|---|---|
| JDK 1.0 | 初始版本发布 | Hashtable | 1. 引入 Hashtable,底层为「数组 + 链表」,方法级 synchronized 保证线程安全;2. 不支持 null Key/Value,初始容量 11,扩容规则 2n+1;3. 无红黑树、无扰动哈希、无并发优化。 |
| JDK 1.2 | 集合框架重构 | HashMap、TreeMap | 1. 引入 HashMap,替代 Hashtable 成为非线程安全哈希表首选;- 底层「数组 + 链表」,初始容量 16(2 的幂),负载因子 0.75;- 支持 1 个 null Key、多个 null Value;- 实现扰动哈希(高低位异或)、位运算索引计算;2. 引入 TreeMap,底层红黑树,支持 Key 自然排序 / 自定义排序,无 null Key;3. 引入 LinkedHashMap(HashMap 子类),双向链表维护插入 / 访问顺序。 |
| JDK 1.4 | 配置增强 | Properties | 1. 基于 Hashtable 扩展,强化 .properties 配置文件读写能力;2. 新增 loadFromXML()/storeToXML() 方法,支持 XML 格式配置。 |
| JDK 5.0 | 泛型支持 | 所有 Map 实现类 | 1. 引入泛型(Map<K,V>),替代原始 Object 类型,避免强制类型转换;2. 优化 TreeMap 比较器,支持 Comparator<? super K> 泛型约束。 |
| JDK 6.0 | 性能微调 | HashMap、Hashtable | 1. 优化 HashMap 哈希算法,减少哈希冲突概率;2. 调整 Hashtable 扩容阈值计算逻辑,提升低容量场景性能。 |
| JDK 7.0 | 并发优化 | ConcurrentHashMap | 1. 重写 ConcurrentHashMap,底层「分段锁(Segment)+ HashMap」;- 分段锁粒度为 Segment(默认 16 个),并发度远高于 Hashtable;- 不支持 null Key/Value,避免并发场景空指针歧义;2. HashMap 优化扩容逻辑,减少扩容时的哈希冲突。 |
| JDK 8.0 | 核心重构(里程碑) | HashMap、ConcurrentHashMap、LinkedHashMap | 1. HashMap 重大升级:- 链表长度 ≥8 且数组长度 ≥64 时,链表转红黑树(查询从 O (n)→O (log n));- 红黑树节点数 ≤6 时,转回链表(降低维护开销);- 优化扩容机制,多线程扩容(但仍非线程安全);- 简化扰动哈希逻辑(key.hashCode() ^ (h >>> 16));2. ConcurrentHashMap 重构:- 废弃分段锁,改用「CAS + synchronized 锁单个哈希桶」,并发粒度更细;- 支持 1 个 null Key(区别于 JDK 7),兼容 HashMap 用法;- 引入红黑树优化(同 HashMap);3. LinkedHashMap 优化:- 强化 LRU 场景性能,访问顺序模式下节点迁移效率提升;4. 新增 Lambda 遍历(forEach() 方法),简化遍历写法。 |
| JDK 9.0 | 工厂方法增强 | 所有 Map 实现类 | 1. 引入不可变 Map 工厂方法:- Map.of()(最多 10 个键值对)、Map.ofEntries()(不限数量);- 不可变 Map 不支持增删改,无 null Key/Value,性能更高。 |
| JDK 11.0 | 性能与安全优化 | ConcurrentHashMap、HashMap | 1. 优化 ConcurrentHashMap 扩容逻辑,多线程协同扩容效率提升;2. 修复 HashMap 极端哈希值下的性能退化问题;3. 增强不可变 Map 的序列化安全性。 |
| JDK 17.0 | 长期支持版优化 | 所有 Map 实现类 | 1. 稳定化不可变 Map 实现,修复多线程下的弱一致性问题;2. 优化 TreeMap 红黑树旋转逻辑,减少排序耗时;3. 废弃 Hashtable 部分过时方法(如 elements()),推荐 ConcurrentHashMap 替代。 |