国产化替代浪潮之下,金仓数据库(即 KingbaseES,业内又常称之为 KES)有着一项独门绝技,那就是出色的 Oracle 兼容能力和强大的内核实力,于是它渐渐成为诸多企业执行核心系统迁移时的优先选择。
KES 的设计思路很有趣,其底层依靠先进的开源内核,上方则紧密契合 Oracle 的语法及行为,这对于开发者而言颇为周到,如此一来,开发者便能够收获云原生时期新技术带来的好处,而且可以把老旧系统迁移所耗费的成本减小到最低限度。
不过要说回来,把 Oracle 或 MySQL 移植到 KES 的时候,各个数据库对标准 SQL 的执行细节存在一些差别,所以难免会遭遇"水土不服"的技术难点。遇到这种情况不要慌,这并非产品有 Bug,更多的是由于不同数据库的设计理念产生冲突,只要深入了解这些机制,不但眼前的难题能够得到解决,而且对于数据库原理的认识也会提升。
本文整理了4个技术场景,分别是对象命名,空值处理,JSON数据处理以及序列管理,经由原理分析并重现代码,带领大家一起避开这些陷阱,从而更好地掌握KingbaseES。 @toc
案例一:明明表存在,为什么报 "relation does not exist"?
现象描述 : 大家可能遇到过这种情况:明明刚建了个表叫 UserInfo,结果用 SELECT * FROM UserInfo 一查,直接报错:ERROR: relation "userinfo" does not exist。这时候你可能会怀疑人生:表呢?我刚建的表呢?
复现代码:
sql
-- 1. 创建一个包含大写字母的表(未加双引号,KES默认会转为小写)
CREATE TABLE UserInfo (id INT, name VARCHAR(20));
-- 2. 尝试查询(此时表名在内部存储为 userinfo)
SELECT * FROM UserInfo; -- 成功,因为 UserInfo 也会被自动转为 userinfo
-- 3. 如果我们在特定的 Schema 下创建表,且使用了双引号保持大小写
CREATE SCHEMA app_v1;
CREATE TABLE app_v1."UserInfo" (id INT, name VARCHAR(20));
-- 4. 此时直接查询,或者不加双引号查询
SELECT * FROM app_v1.UserInfo;
-- 报错:relation "app_v1.userinfo" does not exist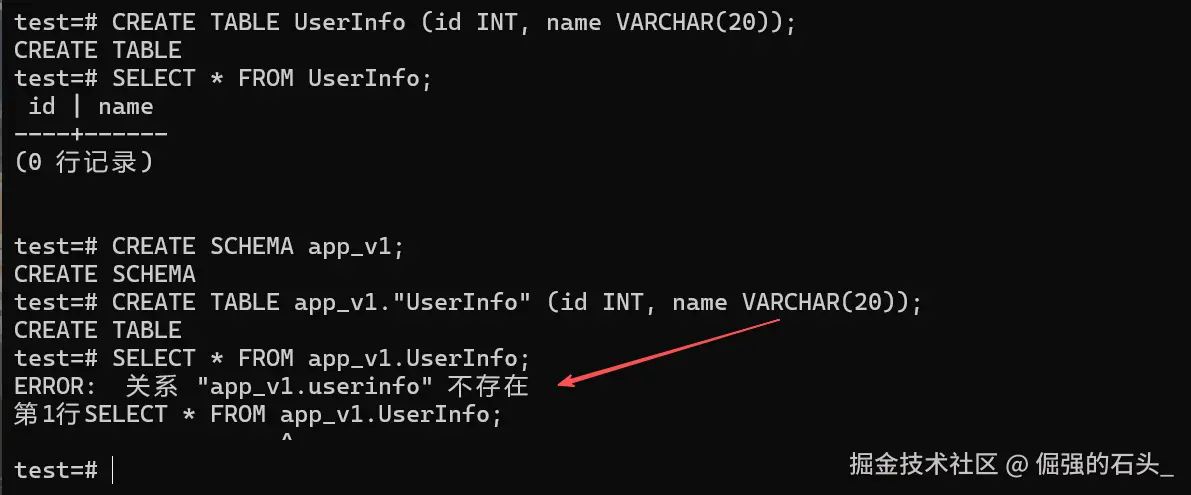
原因分析 : 这是由于KES(处于PG模式或者默认设置时)要遵循SQL标准所致,标准表明,如果未给标识符加上双引号,系统就会自动将其转换为小写。
在创建表时,如果你用上了双引号(譬如说 "UserInfo"),那么系统就会严格按照你所写的大小写来进行存储,等到执行查询的时候,假使你嫌麻烦没有加上双引号,而系统又把表名转换成小写来实施比对,这样必然就查不到相关内容。
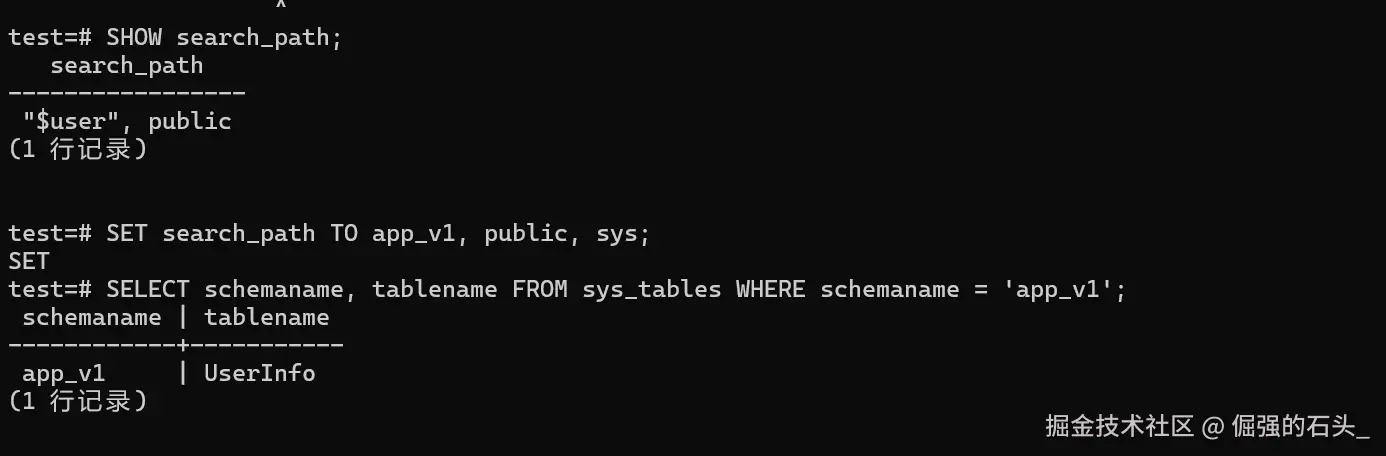
search_path(搜索路径)常会陷入一些问题,你的表若既未处于 public 也未在当前用户的 Schema 下,就务必明确指定 Schema。
解决方法:
-
统一规范:最省心的办法,就是表名、字段名全用小写,别用双引号,大家都轻松。
-
检查
search_path:sqlSHOW search_path; -- 如果你的表在 app_v1 模式下,需要设置: SET search_path TO app_v1, public, sys; -
精准查询 :实在搞不清表名到底存成啥样了?直接查系统表,一看便知:
sqlSELECT schemaname, tablename FROM sys_tables WHERE schemaname = 'app_v1';
案例二:写入的空字符串凭空消失了?(空串与 NULL)
现象描述 : 很多从 MySQL 转过来的兄弟习惯用 ''(空字符串)代表"没东西"。结果写入数据后,用 WHERE content = '' 死活查不到数据,换成 IS NULL 反倒查出来了。这就很迷:我的空字符串去哪了?
复现代码:
sql
CREATE TABLE t_str_test (id INT, content VARCHAR(50));
-- 插入一条空字符串
INSERT INTO t_str_test VALUES (1, '');
-- 尝试查询空字符串
SELECT * FROM t_str_test WHERE content = '';
-- 结果:0 条数据(在 Oracle 模式下)
-- 尝试查询 NULL
SELECT * FROM t_str_test WHERE content IS NULL;
-- 结果:1 条数据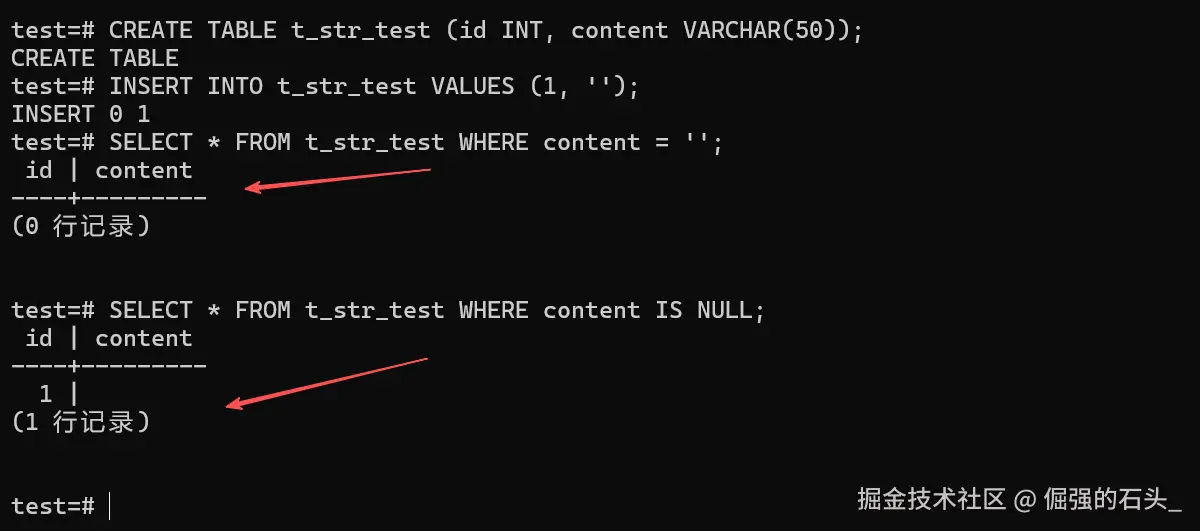
原因分析 : 这是 KES 为适配 Oracle 模式 所专门设计的,在 Oracle 系统当中,空字符串 '' 和 NULL 实际上是相同概念,二者可以相互替代。
KES 有一个名为 ora_input_emptystr_isnull 的参数,用于控制相关行为,该参数处于开启状态(默认值为 on)时,向其中插入空字符串时,系统会自动将其在底层转换为 NULL,这样做主要是方便那些习惯使用 Oracle 的用户在迁移过程中更为顺畅。
解决方法:
-
入乡随俗 :既然用了 KES 的 Oracle 模式,咱们最好就按 Oracle 的规矩来,用
IS NULL判断空内容,习惯了也挺好。 -
改参数(特殊情况) :如果你非得保留空字符串的语义(比如为了兼容 MySQL 的老业务),那也可以在会话级或者系统级把这个参数关掉:
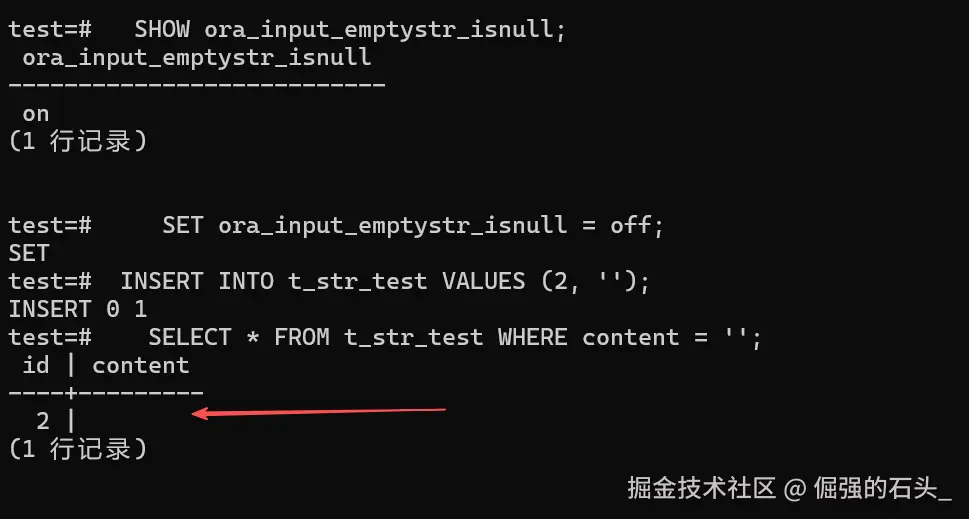
sql-- 查看当前参数 SHOW ora_input_emptystr_isnull; -- 关闭自动转换(仅当前会话生效) SET ora_input_emptystr_isnull = off; -- 再次测试 INSERT INTO t_str_test VALUES (2, ''); SELECT * FROM t_str_test WHERE content = ''; -- 此时能查到 id=2 的记录
案例三:JSON 函数返回 NULL?(JSON 路径匹配规则)
现象描述 : 现在业务里用 JSON 的情况越来越多了,KES 对这块支持也不错。但经常有兄弟抱怨:用 JSON_VALUE 或 JSON_QUERY 取数据时,明明看着数据就在那儿,怎么取出来全是 NULL?
复现代码:
sql
-- 假设表中有一条 JSON 数据:{"Name": "Kingbase", "Version": "V8R6"}
CREATE TABLE t_json (info jsonb);
INSERT INTO t_json VALUES ('{"Name": "Kingbase", "Version": "V8R6"}');
-- 尝试提取 Name 字段
SELECT JSON_VALUE(info, '$.name') FROM t_json;
-- 结果:NULL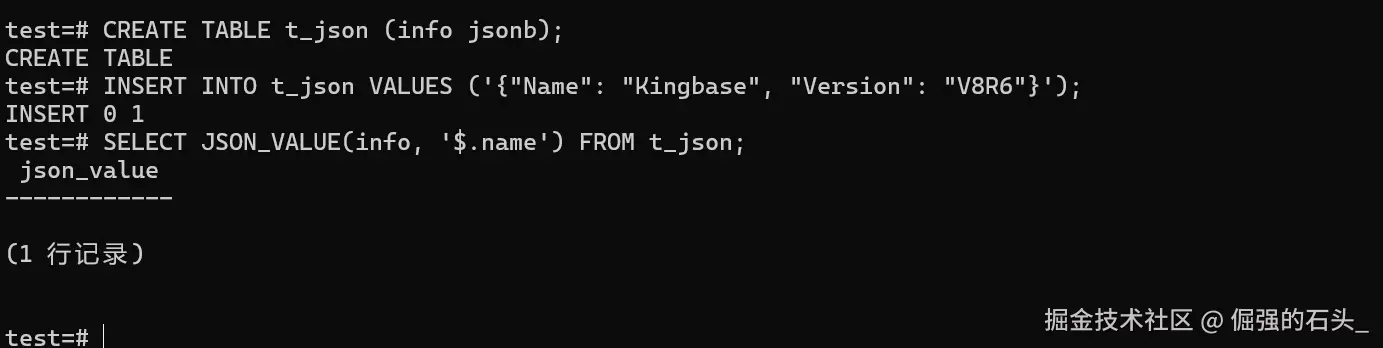
原因分析:
这也真不是系统出 Bug 了,通常是因为咱们写的路径匹配规则太严格。
大小写敏感 :JSON 标准表明,Key(键名)属于大小写敏感范畴,前面例子中的数据含有 "Name"(大写N),而查询路径却是 $.name(小写n),二者显然无法对应,所以默认情形下,相关函数会默默给出 NULL。
路径层级:要是路径层级搞错了(比如少写了一层对象嵌套),那肯定也摸不到值。
解决方法:
-
对齐大小写 :写 SQL 的时候细心点,JSON 路径必须跟数据里的 Key 一模一样。
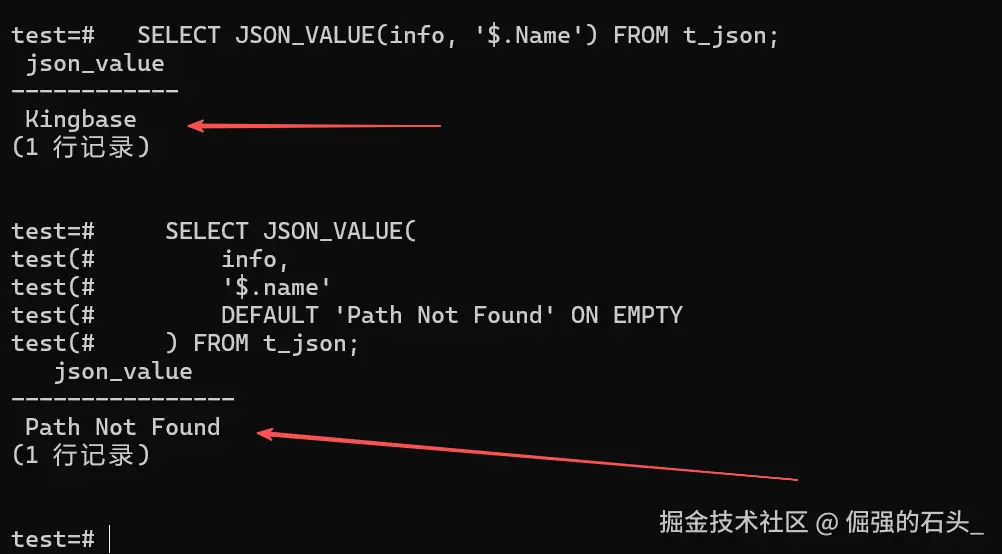
sql-- 正确写法:使用 "Name" SELECT JSON_VALUE(info, '$.Name') FROM t_json; -- 结果:Kingbase -
用
ON EMPTY查因 :为了搞清楚到底是"没找到"还是"值本身就是 NULL",可以用DEFAULT ... ON EMPTY这个语法来探探底。sqlSELECT JSON_VALUE( info, '$.name' DEFAULT 'Path Not Found' ON EMPTY ) FROM t_json; -- 结果:Path Not Found
案例四:迁移后插入数据报错 "Duplicate key"?(序列同步机制)
现象描述 : 数据刚从别的库导进 KES,表里明明已经有 100 条数据了(ID 从 1 到 100)。这时候应用发起一条 INSERT(不指定 ID,想用自增),结果崩了,直接报主键冲突 duplicate key value violates unique constraint。这啥情况?新来的数据还能跟旧数据打架?
复现代码:
sql
-- 1. 创建序列和表
CREATE SEQUENCE seq_user_id START 1;
CREATE TABLE t_user (
id INT DEFAULT nextval('seq_user_id') PRIMARY KEY,
name VARCHAR(20)
);
-- 2. 模拟数据迁移(显式插入 ID)
INSERT INTO t_user (id, name) VALUES (1, 'Alice');
INSERT INTO t_user (id, name) VALUES (2, 'Bob');
-- 3. 此时序列 seq_user_id 的当前值(last_value)依然是 1(或者未定义)
-- 4. 应用尝试隐式插入(依赖默认值)
INSERT INTO t_user (name) VALUES ('Charlie');
-- 错误:键值 "(id)=(1)" 已经存在
原因分析: 这其实是数据库序列(Sequence)的标准行为,没啥好奇怪的。
导数据时(以迁移工具为例),一般会显式指定ID执行插入操作,此情形下,并不会自动推动相关联的序列。
等到后面自己跑起来,开始依赖 default nextval(...) 的时候,序列还是会从初始值(譬如说 1)开始发放,这必然会造成与表里已有的 ID 冲突。
解决方法 : 迁移搞定后,千万别忘了重置序列,把它拨到当前表里最大 ID 的位置。
sql
-- 修正序列值
SELECT setval('seq_user_id', (SELECT MAX(id) FROM t_user));
-- 再次插入成功
INSERT INTO t_user (name) VALUES ('Charlie'); -- ID 将变为 3总结与更多资源
看了上面这几个例子,大家应该也发现了,很多看似"奇葩"的现象,其实是 KingbaseES 为了在标准化 和兼容性之间找平衡而做的精心设计。只要把这些技术细节摸透,你在数据库开发和迁移的时候就能游刃有余,少踩很多坑。
KingbaseES 毕竟是成熟的企业级数据库,诊断工具和文档支持都挺全的。如果你对它的底层原理、更多高级玩法(像读写分离、集群高可用这些)感兴趣,或者真在项目里碰到了硬骨头,欢迎来咱们的官方技术社区逛逛!
👉 金仓数据库官方博客站 :kingbase.com.cn/explore 在这里你可以找到更多资深专家的技术干货、原理解析和最佳实践文档。