引言
国内具身智能领域又迎来重磅消息。
12月18日,"大晓机器人"正式亮相,作为行业级"具身超级大脑","大晓机器人"将以全新研发范式、全新数据采集范式,以及性能领先全球的"开悟"世界模型3.0(Kairos 3.0),精准剖析并响应当前阶段行业在技术突破和商业落地的双重诉求,将前沿技术转化为可落地、可复用的解决方案。
同步发布的还有"具身超级大脑模组A1",通过搭载首创纯视觉无图端到端VLA具身智能模型,让具身智能摆脱了预先地图采集的依赖,能够快速适应复杂的陌生环境------基于这项能力,"大晓机器人"将与国内领先的智能企业达成战略合作,在安防、巡检等工业场景率先部署机器狗。
"大晓机器人"将前沿高新技术转化为可被企业、行业快速落地且易于 复用的通用能力,助力企业、行业在AI时代持续繁荣。
同时,"大晓机器人"也以积极态度拥抱行业合作,与火山引擎开展联合探索,进一步提升在大模型领域的创新力:如结合了火山引擎多模态数据湖解决方案的开悟世界模型3.0,可以有效解决传统单机多脚本模式的链路分散、I/O负载重、资源利用率低、稳定性差、扩展不足等问题。
本文将核心探讨"大晓机器人"与火山引擎,聚焦千万小时级的视频数据处理场景,如何通过多模态数据湖解决方案中的LAS AI数据湖产品,跑通最佳实践全链路,实现开发投入侧和资源利用侧的双重提效。
背景
图片随着具身智能的进一步发展,视频数据正在进入"千万小时"时代,而数据处理规模的变大带来是处理框架的升级。
以具身智能机器狗的工业巡检场景为例,一台机器狗通常搭载多路全景摄像头与深度相机,在持续执行巡检任务时,单天产生的视频数据量即可达到数百GB。在规模化部署机器狗集群的背景下,每月积累的视频数据甚至能突破千万小时。
面对如此海量的数据,传统单机、脚本式的处理流程已经难以为继,千万小时视频不是"多加几台机器"就能处理好的问题。
那如何在保证稳定性、可扩展性的前提下,高效处理千万小时的视频数据?在本文中,我们分享如何利用Daft@火山引擎AI数据湖-Las 搭建大规模的分布式视频处理 Pipeline。
LAS AI 数据湖
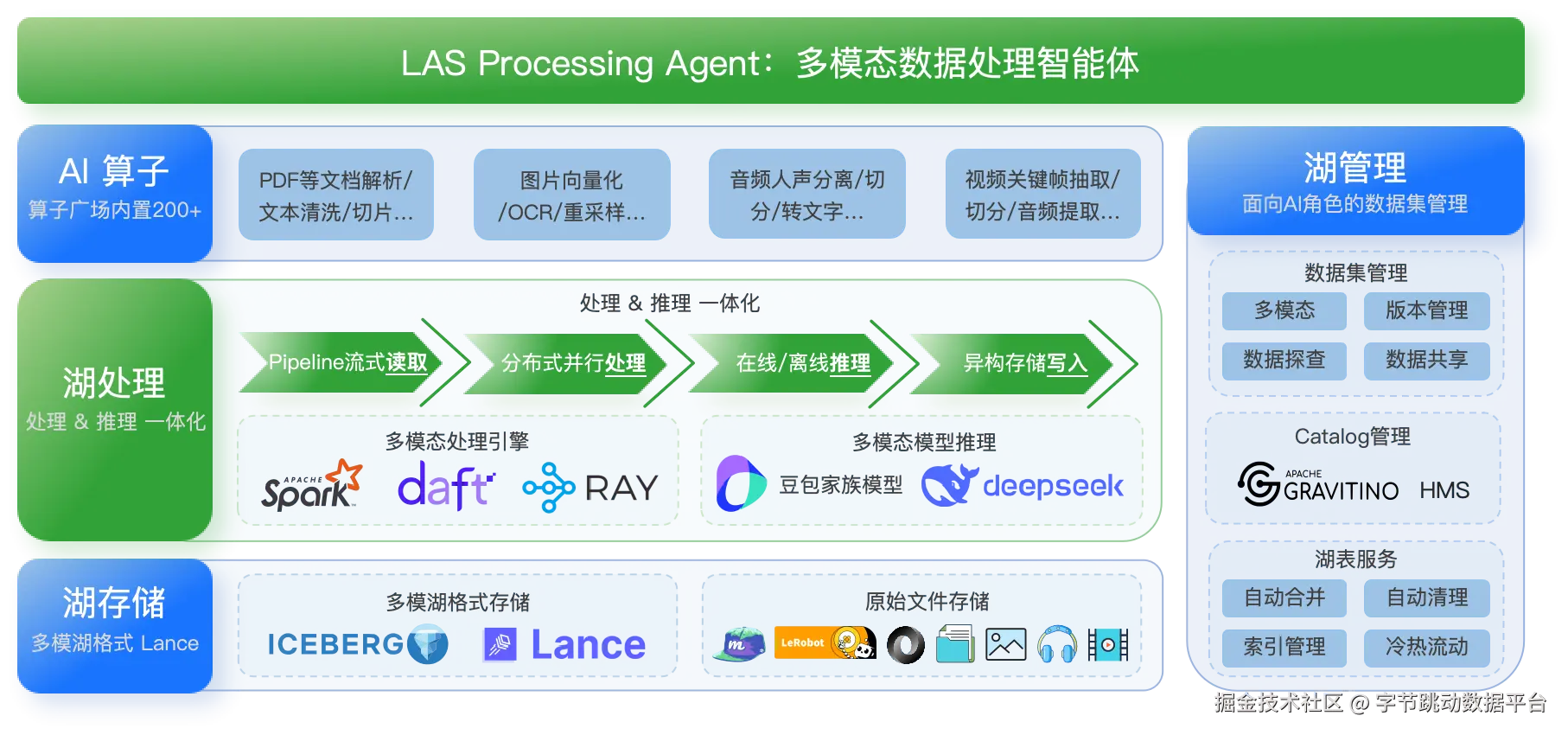
LAS AI 数据湖产品是火山引擎为企业适应AI Agent时代推出的新一代多模态场景解决方案,孵化于字节跳动大模型训练场景,面向多模态数据场景,提供湖存储、湖管理、湖计算三大能力、通过"湖存储Lance+湖计算Daft"为核心要素,针对性解决视频、图片等非结构化数据处理的痛点。
业务场景
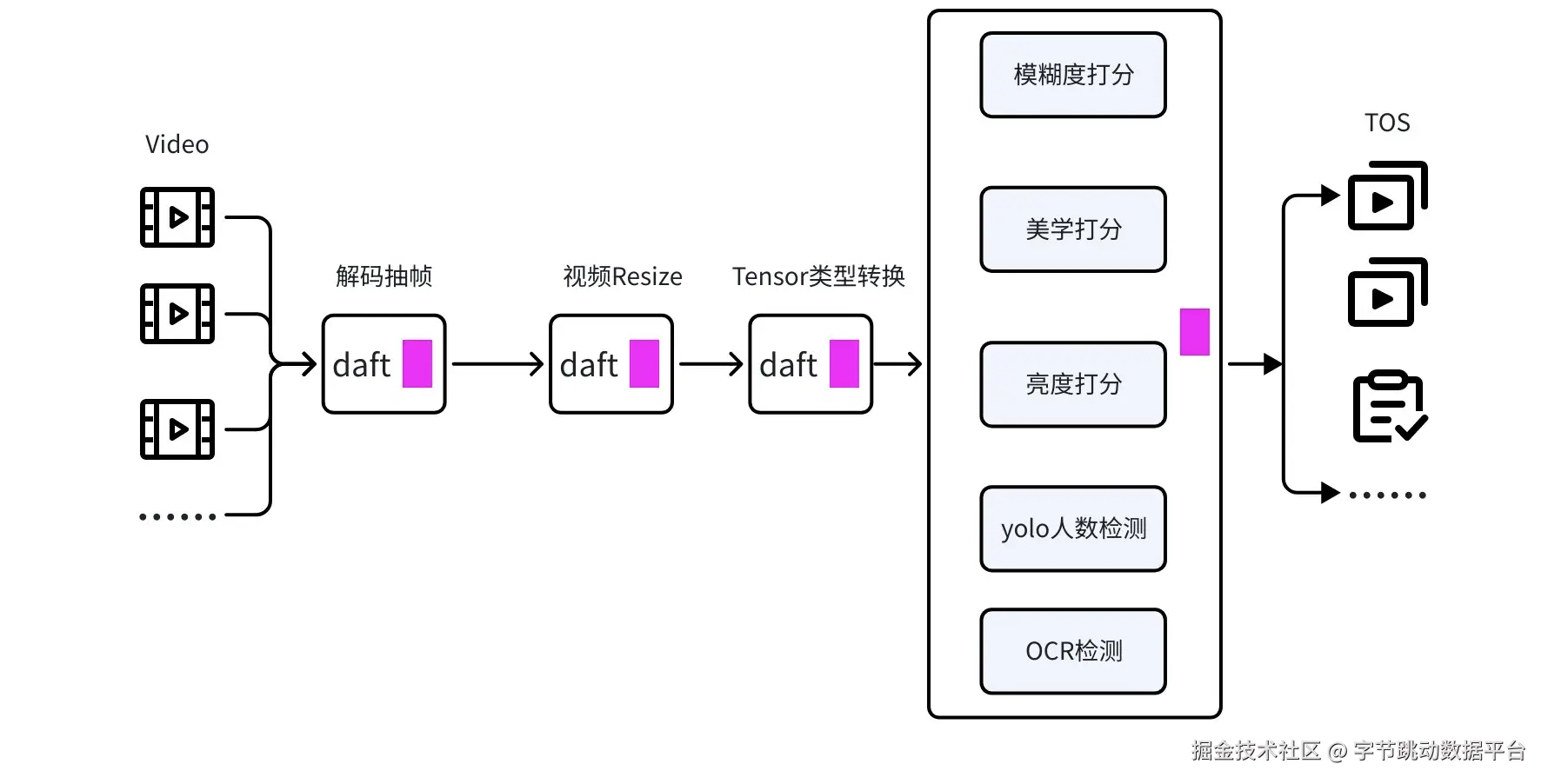
以典型【具身场景】的视频处理链路如下图所示:
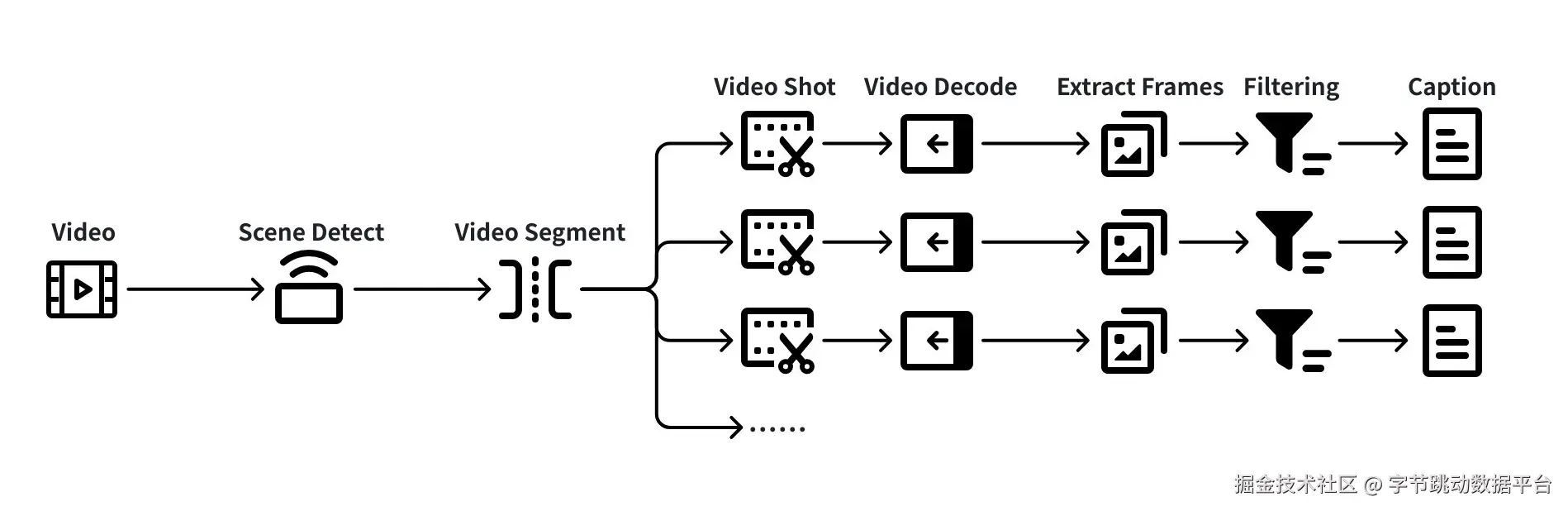
这是一条典型的多阶段视频 ETL 处理链路,每个环节都伴随着异构资源使用、I/O 压力与数据依赖。
架构升级
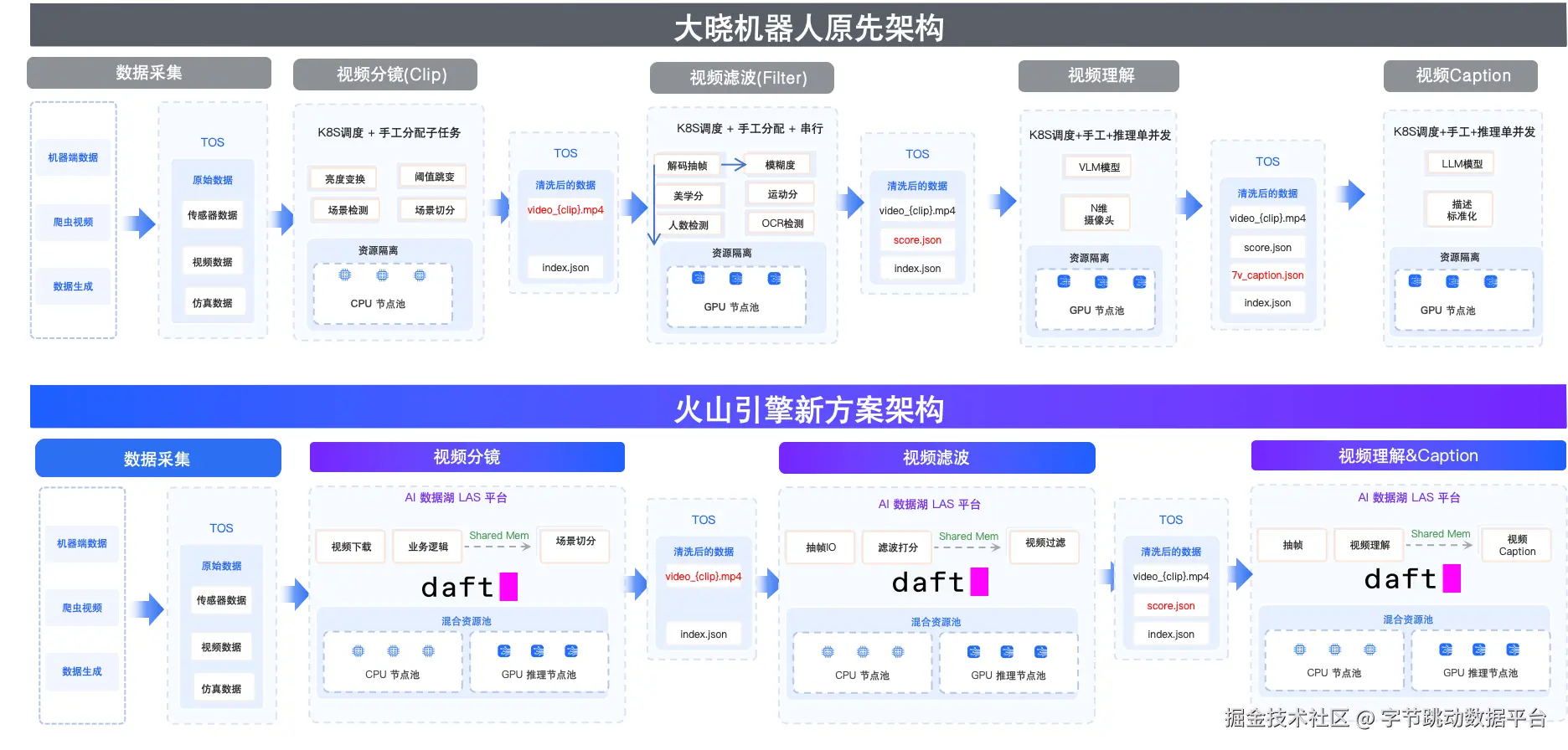
升级前后的收益对比

实现细节
图片在历史方案中,单机多脚本通过中间文件衔接的方式,瓶颈明显:
链路分散:分镜、视频解码&抽帧、过滤、caption生产等步骤往往由不同脚本实现,难以统一管理
I/O 负载沉重:每个步骤都可能产生大量中间文件(临时视频、帧图像、日志等),磁盘与网络经常成为瓶颈
资源利用率差:脚本通常是单视频串行处理,很难充分利用多核或多机资源,更无法灵活按需分配资源
稳定性差:步骤之间缺乏明确的依赖管理机制,一旦某一环出现异常,整个 Pipeline 可能无法恢复
难以扩展:当数据规模从"几百小时"突然增长到"几万、几十万小时"时,链路通常要被"推倒重来"
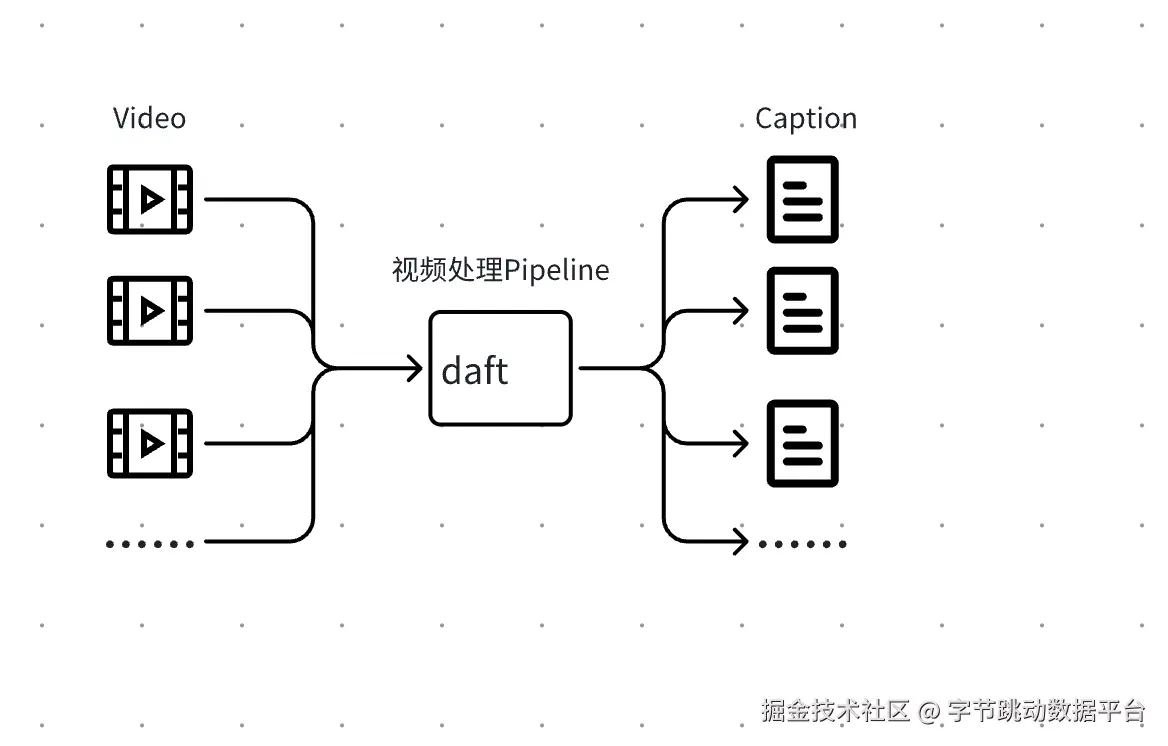
而我们基于LAS AI数据湖产品中内置的计算框架Daft,将整个流程统一抽象为一条 DataFrame 计算链路,配合 Ray 等执行后端实现 批量并行、资源充分利用的执行方式,既保留了 Python 写法的灵活性,又兼顾了工程上的可扩展性。
- 从TOS读取千万小时的视频数据
- 使用PySceneDetect做场景检测,再使用FFmpeg做视频分割,得到分镜后视频片段
- 对每个视频片段做解码和抽帧,得到可以直接输入模型的clip数据
- 调用模型对视频做模糊度、美学等打分,过滤不符合条件的视频
- 对过滤后的视频,调用VLM生成Caption
准备工作
安装依赖包
arduino
pip install "daft[ray]" scenedetect torch torchvision ray PIL transformers vllm qwen_vl_utils步骤1:视频分镜
场景检测
在具身智能机器狗的工业巡检场景中,原始视频通常是长时间连续录制的,其中包含大量语义不同的片段:例如检查管道阀门状态、经过车间走廊、上下楼梯、识别设备指示灯异常、遇到地面障碍物(如工具箱)、通过狭窄通道等。
为了让后续的抽帧、滤波、Caption 等处理更加准确和高效,我们首先对视频进行 场景检测(Shot Detection),将长视频划分成若干语义相对完整的分镜片段。
我们使用 PySceneDetect 对视频内容变化进行检测,它通过以下方式来判断场景切换的位置:
亮度直方图变换
逐帧内容差异(Content Difference)
阈值跳变(Threshold Detector)
通过识别这些边界,我们能够将原始视频精准切割成多个分镜(Scene)。每个分镜都更短、更独立,也更适合作为后续模型的输入单元。
scss
def detect_scenes(self, video_path):
# 检测场景
video = open_video(video_path)
scene_manager.detect_scenes(video)
scenes = []
for start, end in scene_manager.get_scene_list():
scenes.append((start.get_seconds(), end.get_seconds())
return scenes过滤过短片段
在完成场景检测后,我们会对检测到的分镜进行一次质量过滤,丢弃时长不足 4 秒的片段。 之所以进行这一步,是因为过短的场景往往存在以下问题:
- 内容不稳定:可能是瞬时曝光变化、抖动、短暂遮挡导致的误检
- 语义不完整:不足以形成一个可理解的视频语义单元
- 模型输入质量差:抽帧数量不足会影响模糊度判定、美学评估、Caption 效果
- 会降低 Pipeline 吞吐:大量短场景会导致频繁的解码与 FFmpeg 调用,反而增加 overhead
因此,基于经验与实验,我们选择将 时长小于 4 秒的场景过滤掉,只保留具有完整语义与足够帧数的有效片段,使后续处理更加稳定、可控,也能显著提升模型推理质量。
场景切分
在完成 PySceneDetect 的场景检测后,我们会得到每个分镜的起止时间(timecode)。接下来,需要根据这些时间段将原始视频拆分成多个独立的 clip。
这一步我们使用 FFmpeg 进行切分,它的优势是:
- 切分精准:可按精确时间戳(-ss / -to)截取片段
- 无损处理:通过 -c:v copy 直接拷贝视频流,无需重新编码
- 速度极快:I/O 速度远大于编码速度,几乎可以线性扩展到多进程
- 稳定可靠:FFmpeg 对各种编码格式(H264/H265/MPEG4)兼容性最好
切分后的每个 clip 都是一个独立的视频文件,具有清晰的语义边界,也成为后续"解码抽帧 → 质量过滤 → Caption"的基础输入单元。
python
def _split_and_save_scene(self, scene, video_path, output_dir):
cmd = [
"ffmpeg",
"-loglevel", "error",
"-ss", str(start_sec),
"-to", str(end_sec),
"-i", video_path,
"-c", "copy",
clip_path
]
return clip_pathDaft Explode 增大并发粒度
一个长视频在经过场景检测后往往会被切分成多个场景片段。为提升整体吞吐与资源利用率,我们将"场景检测"和"视频切分"拆分为两个独立的 UDF。
在场景检测阶段,我们将原始的视频级数据展开为场景片段级的数据,使每个场景片段都成为独立的数据行。随后,借助 Daft 的分布式任务调度和并发执行能力,实现大规模的并行视频切分操作。


图片这种设计能够充分利用多核 CPU 的并行能力,显著提升长视频处理效率,同时避免因个别超长视频导致的数据倾斜问题,从而确保整体作业在大规模数据集上也能保持稳定的处理性能。
python
import daft
@daft.udf(return_dtype=daft.DataType.list(daft.DataType.list(daft.DataType.float64())))
class SceneDetectionUDF:
def __init(self, min_duration=4):
self.min_duration = min_duration
def __call__(self, video_path_series):
results = []
video_paths = video_path_series.to_pylist()
for video_path in video_paths:
scenes = self.detect_scenes(video_path)
scenes = self.filter_scenes(scenes, self.min_duration)
results.append(scenes)
return results
python
import daft
@daft.udf(return_dtype=daft.DataType.string())
class VideoSplitUDF:
def __init__(self, output_dir: str):
self.output_dir = output_dir
os.makedirs(output_dir, exist_ok=True)
def __call__(self, video_path_series, scene_series):
results = []
for video_path, scene in zip(video_path_series.to_pylist(), scene_series.to_pylist()):
# 镜头切分
clip_path = self._split_and_save_scene(video_path, scene, self.output_dir)
results.append(clip_path)
return results步骤2:视频滤波
在完成视频分镜之后,我们已经将长时间连续录制的视频拆分为结构更清晰、语义更加独立的 clip。然而,具身场景中海量的原始视频仍然存在大量无效或质量较差的片段,例如:
- 模糊抖动导致的不可用画面
- 强光/逆光造成的过曝、欠曝
- 无主体的空景(空荡的车间走廊、无人值守的设备待机区域、未放置任何物品的空旷仓库通道)
- 画质极低、噪点严重的片段
- 场景过暗或完全黑屏
如果将这些低质量数据直接送入后续模型(例如 Caption、场景理解或训练数据集),不仅会浪费大量 GPU 资源,也会影响模型表现。因此,在大规模视频处理 Pipeline 中,"视频滤波"是确保数据质量的关键步骤。
图片解码抽帧
在对视频输入模型进行推理之前,我们首先需要将视频内容从压缩编码格式转换为可供模型处理的图片帧。 这一步由两部分组成:解码(Decode)和抽帧(Sampling),是整个视频处理最关键的基础操作。
python
import daft
@daft.udf(return_dtype=daft.DataType.struct({
"clip_path": daft.DataType.string(),
"frame_paths": daft.DataType.list(daft.DataType.string())
}), num_cpus=10, concurrency=100)
class FrameSamplerUDF:
"""
帧采样UDF, 从视频clip中采样帧并保存
"""
def __init__(self, max_frames: int = 8, output_dir: str = "./frames"):
self.max_frames = max_frames
self.output_dir = output_dir
os.makedirs(output_dir, exist_ok=True)
def __call__(self, clip_path_series):
results = []
for clip_path in clip_path_series.to_pylist():
# 采样帧
frame_paths = self._sample_frames(clip_path)
results.append({"clip_path": clip_path,"frame_paths": frame_paths})
return results视频打分&过滤
在完成"解码抽帧"后,我们会得到 clip 的一系列代表性帧。接下来,需要利用模型对这些帧进行质量评估,以判断该视频片段是否值得进入后续高成本的 Caption 或训练数据构建阶段。
这一环节就是 视频滤波的核心 ------ 基于模型的质量评分(Scoring)与过滤(Filtering)。
python
import daft
@daft.udf(return_dtype=daft.DataType.struct({"clip_path": daft.DataType.string(), "passed": daft.DataType.bool(), "scores": daft.DataType.python()}), num_gpus=0.2, num_cpus=10, concurrency=200)
class FrameFilterUDF:
def __init__(self, target_size: tuple = (320, 320), threshold: float = 100.0):
...
# 加载模型
self.model = self._load_model()
def __call__(self, frames_data_series):
results = []
for frames_data in frames_data_series.to_pylist():
result = self._score_predict(frame_data)
results.append(result)
return results步骤3:视频理解&Caption
图片在经历「分镜 → 解码抽帧 → 质量过滤」之后,我们最终保留下来的 clip 都是 语义稳定、画质合格、可读性强的高质量视频片段。这些片段将进入整个 Pipeline 的第三个核心阶段:视频理解与 Caption 生成。
Caption 生成的目标,是让模型能够自动为每个视频片段生成一段自然语言描述,使视频从"未结构化视觉数据"变成"可检索、可索引、可训练的语义数据"。
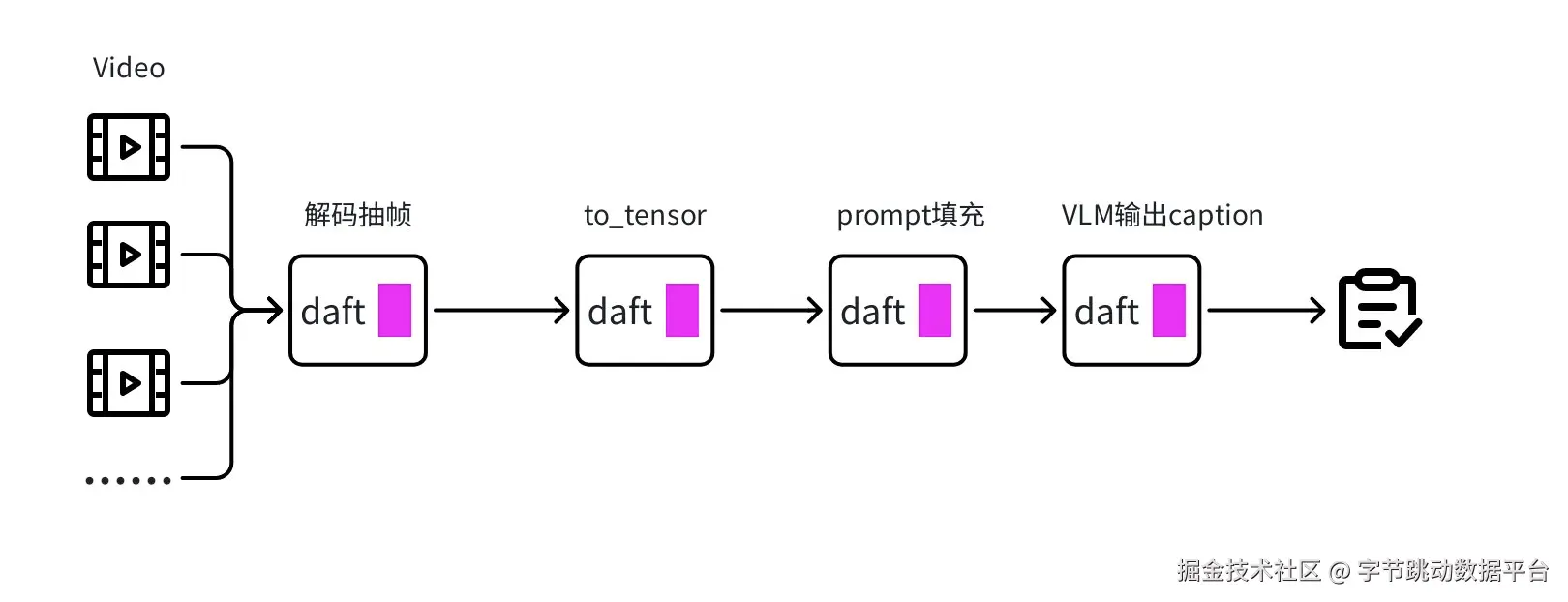
Caption强化
python
import daft
@daft.udf(return_dtype=daft.DataType.string(), num_gpus=1, num_cpus=20, concurrency=800)
class VideoCaptionUDF:
def __init__(self, model_path):
self.model = self._load_caption_model(model_path)
self.prompt = """基于上述理解,用一段简洁自然的语言描述当前视频场景。不要加入无法从视频判断的内容。请先理解视频片段的具身智能巡检场景,再生成一段客观准确的说明。分析内容包括:
- 环境类型与结构(如车间/仓库/管道区、空间结构是否为狭窄通道/楼梯、设施布局)
- 周围对象(设备、障碍物、环境元素)的相对位置和状态(如阀门开关状态、指示灯颜色、地面杂物位置)
- 关键标识与异常(如设备状态标识、安全警示标识、设施异常情况)
- 环境条件(光照、地面状况、空间约束)
- 重要动态变化或潜在风险(如设备状态变化、新出现的障碍物、机器狗自身姿态变化)
基于上述理解,用一段简洁自然的语言描述当前视频场景。不要加入无法从视频判断的内容。"""
def __call__(self, frames_data_series):
frames_data_list = frames_data_series.to_pylist()
for frame_data in frames_data_list:
# 生成描述
caption = self._generate_caption(frame_data)
results.append(caption)
return results步骤4:Daft的Pipeline流式调度
图片在前面的三个步骤(分镜、滤波、Caption)中,我们已经拆解了千万小时视频处理的三个关键能力。但真正让整个系统具备"工程落地能力"的,是最后一步 ------ 通过 Daft on Ray 将所有步骤串联成一条高吞吐、可扩展的流式处理 Pipeline。
- 初始化Ray Cluster
- 配置 Daft 使用 Ray 作为执行引擎
ini
import daft
def main():
"""完整视频处理Pipeline"""
daft.context.set_runner_ray()
# 从TOS扫描.mp4视频文件
io_config = IOConfig(s3=S3Config(...))
s3_path = "s3://bucket/test_path/**/*.mp4"
output_s3_path = "s3://bucket/output/parquet/"
df = daft.from_glob_path(s3_path, io_config=io_config).select('path').with_column_renamed('path', 'video_path')
# 步骤1: 场景检测
df = df.with_column("scene_list", scene_detect_udf(col("video_path")))
# 将数据从视频维度展开到镜头维度
df = df.explode(col("scene_list"))
df = df.with_column("clip_path", video_split_udf(col("video_path"), col("scene_list"))) # 步骤2:视频切分
df = df.with_column("frames", frame_sampler_udf(col("clip_path"))) # 步骤3: 帧采样
df = df.with_column("filtered", frame_filter_udf(col("frames"))) # 步骤4: 视频滤波
df = df.with_column("caption", caption_udf(col('frames'))) # 步骤5: 视频描述生成
# 结果保存到parquet,上传到TOS
df.write_parquet(output_s3_path, io_config=io_config)步骤5:GPU任务的Checkpoint
图片在大规模分布式视频处理场景中,单次 Pipeline 运行往往持续数天甚至数周;链路中包含大量 GPU 推理、视频解码与分布式写入操作,运行时间本身即具有 长周期、阶段性累积 的特点。同时,工程中不可避免会出现以下情况:
- 运行时间过长,需要人工"暂停 / 校准 / 调参"
- 中途需要进行集群扩容 / 缩容 / 升级
- 模型版本变更,需要从某个 stage 重新开始
- 调度策略需要动态调整(batch size、并行度、concurrency)
- 资源成本过高,需要中断以切换到低峰时段运行
因此,该系统的 Pipeline 必须具备 可控中断 → 可恢复执行 的能力。为此,我们基于Parquet append-only 设计了Checkpoint 机制,并在每个阶段启动时通过 Anti Join 自动过滤已完成任务。
csharp
def generate_resume_result_daft(input_df, processed_df, join_key):
if processed_df is None:
return input_df
if join_key is None:
return input_df
processed_df = processed_df.select(join_key).distinct()
filtered_df = input_df.join(processed_df, on=join_key, how='anti')
return filtered_dfDaft优化实践
实践1:CPU使用超100%的情况,Daft为何还能加速
前期在使用视频分镜场景中CPU利用率已经到了100%,但是集成了Daft之后端到端的处理依然收获了20%的收益。
这里主要的原因是 OMP_NUM_THREADS 环境变量的隔离带来的影响
在处理或者推理过程中,经常会用到Pytorch 或者Numpy的库,内置会用OMP_NUM_THREADS来控制线程池的大小,如果没有显示控制该环境变量,默认每个进程都会利用节点上的所有的cores,会带来资源争抢,带来线程上下文切换成本比较高
所以这里设置的num_cpus的为一个合理值就显得比较重要
如果 actor 内部使用多线程库(如 numpy、PyTorch):配置 num_cpus=30 会让这些库使用更多线程(OMP_NUM_THREADS=30),可能提高单个 actor 的性能,但也可能导致线程竞争。
如果 actor 是单线程或 I/O 密集型:配置 num_cpus=1 或 num_cpus=10 对实际性能影响不大,但 num_cpus=1 可以让更多 actor 并发运行,提高整体吞吐量。
实践2:视频类型如何能够做到ZeroCopy
Daft使用的Arrow类型作为算子间的传递形式,Arrow可以实现ZeroCopy能力,减少数据在不同算子之间的传递成本,但是Arrow只是支持固定类型的Type,如果是一个Python的复杂类型还是需要面临着拷贝,所以在这里将视频的数据内容转换为了Tensor类型,Tensor类型是原生可支持的Arrow类型(前提是size比较小的视频或者图片)
Note:这里有个Tradeoff,如果是比较小视频,如果想达成同一个视频会同时被多个数据流算子处理,则需要被显示的拷贝到不同的算子中,尽量增大处理并发, 如果是大视频,则尽量将算子Fusion,然后减少视频的多次拷贝
实践3:在Daft场景中如何增大吞吐
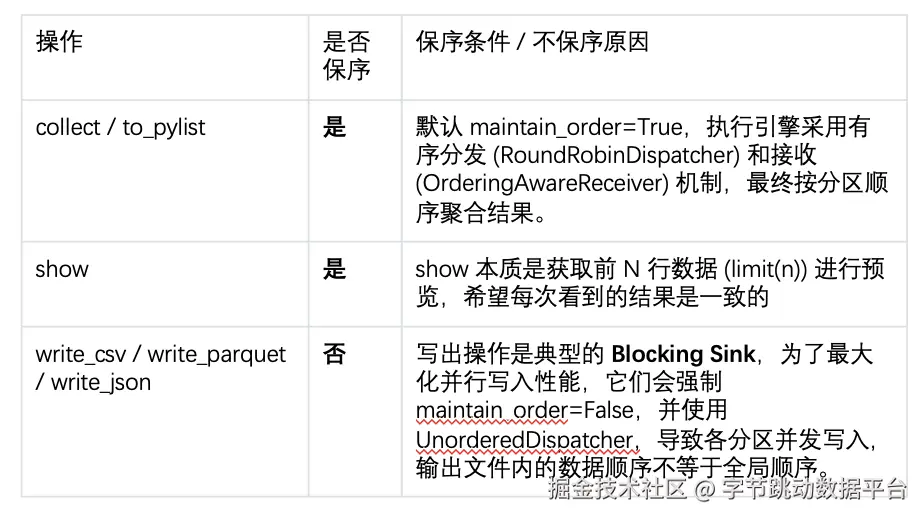
Daft执行侧在算子间传递数据时支持有序和无序两种
无序更有利于高吞吐的场景,例如数据处理同时写回某个数据源中。
有序则会发生在show这种小数据量数据探查的 场景以及本身算子要求有序的场景例如 TopN,Order等算子
实践4:视频分镜步骤的分布式加速
在千万小时视频处理中,分镜(场景切分) 是非常关键的前置步骤,会直接影响后续解码、抽帧、过滤、Caption 的处理成本。一个长视频往往有多个场景,需要切分为多个视频片段,单进程串行处理会成为整个 Pipeline 的第一道性能瓶颈。在大规模数据下,处理速度会迅速跌入不可接受的范围。
为提升整体吞吐,我们将分镜流程拆分为两个阶段,并通过 数据打散(Daft的explode函数)+ 分布式并发 实现加速:
在场景检测阶段,我们将原始的视频级数据展开为场景片段级的数据,使每个场景片段都成为独立的数据行
随后,借助 Daft 的分布式任务调度和并发执行能力,实现大规模的并行视频切分操作
这种模式将处理粒度从"视频级"提升到"场景级",有效消除长视频带来的数据倾斜问题,使切分吞吐量随可用 CPU 核数近似线性增长,大幅提升整体视频处理 Pipeline 的性能与稳定性。
实践5:基于Daft解耦解码/抽帧与 GPU 推理,构建异步流水线提升GPU使用率
在大规模视频处理中,一个常见的性能瓶颈来自于 解码/抽帧与 GPU 推理强耦合。
如果按照传统方式执行:
- 解码一段视频
- 抽帧
- 把帧送入 GPU 做模型推理
- 再返回 CPU 等下一段解码
这将导致 GPU 很长时间处于"等待 CPU 准备数据"状态,而不是持续推理。 在千万小时视频规模下,这种串行方式会让 GPU 实际利用率跌到 20%--40%,极大浪费算力资源。
因此,我们将解码/抽帧的任务单独抽成一个UDF,与下游的滤波和Caption生成的GPU推理任务解耦开,通过Daft的流式调度能力,消除了串行场景下 IO/CPU处理 与 GPU推理 的等待关系,使得GPU算子能够源源不断的获取数据进行推理。
最终效果
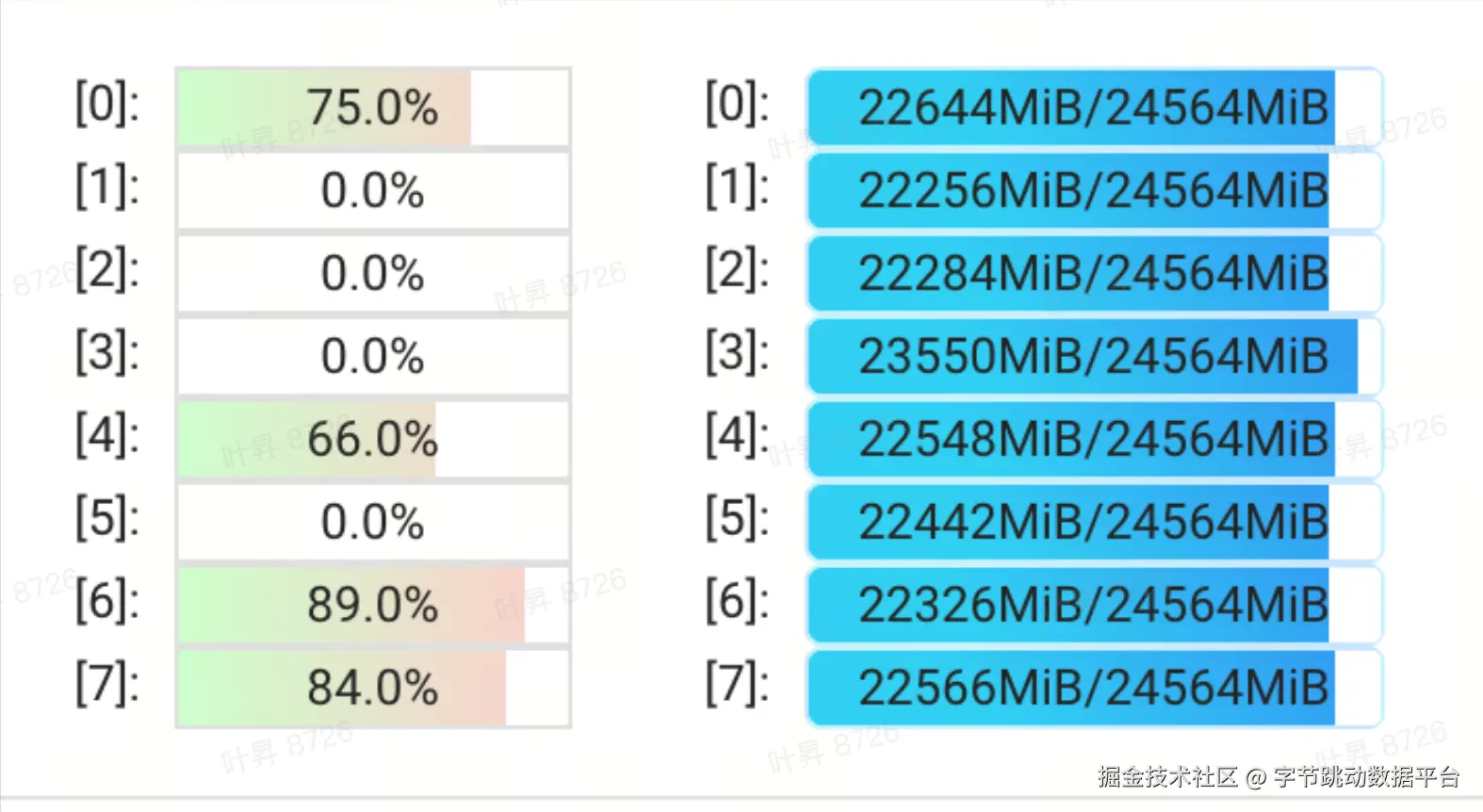
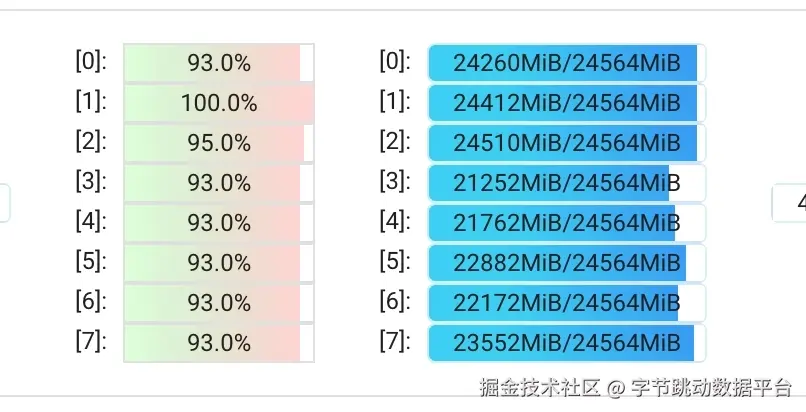
图片经过以上优化,CPU和GPU的资源使用率都有显著提升
CPU 利用率显著提升:由原先的 40%~60% 波动状态提升至 稳定满载(100%)运行
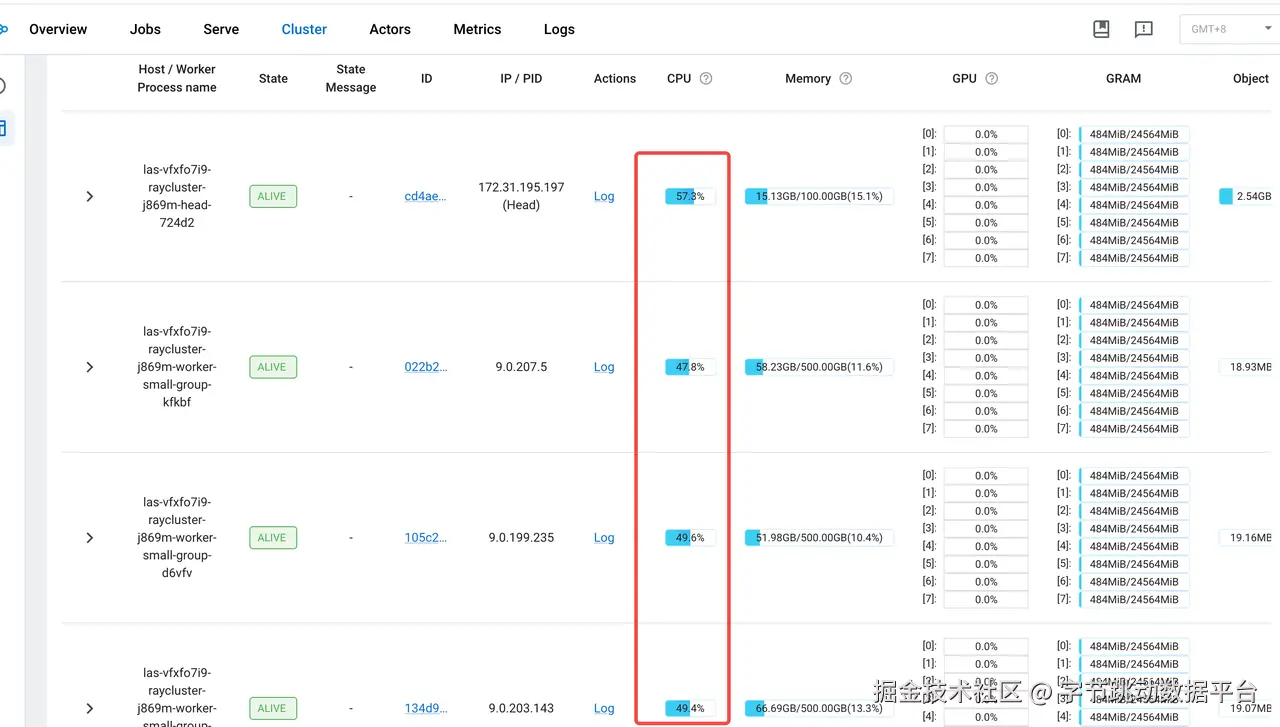
GPU 利用率显著提升:由原先因等待 I/O 而长期处于低负载状态,提升至 稳定 90%+ 的高利用率区间
总结
图片图片在本次合作中,"大晓机器人"依托专业技术沉淀,专注于世界模型工具链的构建与应用,其技术范围涵盖物理AI数据闭环、生成式世界引擎及闭环仿真等等;火山引擎多模态数据湖解决方案则基于LAS AI数据湖产品,充分发挥在多模态数据预处理领域的优势,为"大晓机器人"的整个研发体系构建了坚实的技术基座。
通过"云+模型"的深度协同,"大晓机器人"携手火山引擎已经跑通传统脚本式处理在扩展性、稳定性、吞吐上的攻克路径,为企业和行业带来面向海量视频数据的"通用基础设施"解决方案,帮助包括具身智能、智能驾驶等在内的多个涉及视频处理的技术领域,实现研发和资源双重提效。