
🎬 个人主页 :艾莉丝努力练剑
❄专栏传送门 :《C语言》《数据结构与算法》《C/C++干货分享&学习过程记录》
《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
⭐️为天地立心,为生民立命,为往圣继绝学,为万世开太平
🎬 艾莉丝的简介:

文章目录
- [1 ~> 理解硬件](#1 ~> 理解硬件)
-
- [1.1 磁盘、服务器、机柜以及机房](#1.1 磁盘、服务器、机柜以及机房)
-
- [1.1.1 磁盘](#1.1.1 磁盘)
- [1.1.2 服务器、机房](#1.1.2 服务器、机房)
- [1.1.3 题外话:磁盘与磁铁](#1.1.3 题外话:磁盘与磁铁)
-
- [1.1.3.1 盘片上的"地形图":磁畴与比特](#1.1.3.1 盘片上的“地形图”:磁畴与比特)
- [1.1.3.2 硬盘驱动器如何导航这张地图:物理地址](#1.1.3.2 硬盘驱动器如何导航这张地图:物理地址)
- [1.1.3.3 连接硬件与软件:块设备与文件系统](#1.1.3.3 连接硬件与软件:块设备与文件系统)
- [1.1.3.4 描绘出从物理到逻辑的完整链条:](#1.1.3.4 描绘出从物理到逻辑的完整链条:)
- [1.1.3.5 总结](#1.1.3.5 总结)
- [1.2 机械磁盘物理结构](#1.2 机械磁盘物理结构)
- [1.3 磁盘的存储结构](#1.3 磁盘的存储结构)
-
- [1.3.1 存储结构](#1.3.1 存储结构)
- [1.3.2 如何定位扇区:CHS地址定位](#1.3.2 如何定位扇区:CHS地址定位)
- [1.4 磁盘的逻辑结构](#1.4 磁盘的逻辑结构)
-
- [1.4.1 LBA](#1.4.1 LBA)
- [1.4.2 真实的过程](#1.4.2 真实的过程)
- [1.4.3 磁盘寻址方式中 LBA(逻辑块地址) 和 CHS(柱面 - 磁头 - 扇区) 的关系以及它们之间的转换由谁来完成问题](#1.4.3 磁盘寻址方式中 LBA(逻辑块地址) 和 CHS(柱面 - 磁头 - 扇区) 的关系以及它们之间的转换由谁来完成问题)
- [1.4.4 CHS和LBA的相互转换](#1.4.4 CHS和LBA的相互转换)
-
- [1.4.4.1 转换](#1.4.4.1 转换)
- [1.4.4.2 详解转换(了解即可)](#1.4.4.2 详解转换(了解即可))
-
- [1 CHS地址转换为LBA地址](#1 CHS地址转换为LBA地址)
- [2 LBA地址转换为CHS地址](#2 LBA地址转换为CHS地址)
- [1.4.4.3 地址映射的实际应用](#1.4.4.3 地址映射的实际应用)
- [1.4.4.4 认知变化](#1.4.4.4 认知变化)
- [2 ~> Ext系列文件系统核心原理(重点Ext2)](#2 ~> Ext系列文件系统核心原理(重点Ext2))
-
- [2.1 Ext系列文件系统的核心概念](#2.1 Ext系列文件系统的核心概念)
-
- [2.1.1 块(Block)------ 文件数据的存储单位](#2.1.1 块(Block)—— 文件数据的存储单位)
-
- [2.1.1.1 块的核心特性](#2.1.1.1 块的核心特性)
- [2.1.2 inode(索引节点)------ 文件属性的存储单位](#2.1.2 inode(索引节点)—— 文件属性的存储单位)
- [2.1.2.1 inode的核心特性:](#2.1.2.1 inode的核心特性:)
- [2.1.2.2 Ext2 inode的具体结构](#2.1.2.2 Ext2 inode的具体结构)
- [2.1.2.3 inode核心字段解读:](#2.1.2.3 inode核心字段解读:)
- [2.1.3 块组(Block Group)------ 文件系统的分区管理单元](#2.1.3 块组(Block Group)—— 文件系统的分区管理单元)
-
- [2.1.3.1 块组的核心特性:](#2.1.3.1 块组的核心特性:)
- [2.2 Ext2文件系统的整体结构](#2.2 Ext2文件系统的整体结构)
-
- [2.2.1 启动块(Boot Block)](#2.2.1 启动块(Boot Block))
- [2.2.2 块组的内部结构](#2.2.2 块组的内部结构)
-
- [2.2.2.1 超级块(Super Block)](#2.2.2.1 超级块(Super Block))
-
- [2.2.2.1.1 超级块的核心特性](#2.2.2.1.1 超级块的核心特性)
- [2.2.2.2 块组描述符表(Group Descriptor Table,GDT)](#2.2.2.2 块组描述符表(Group Descriptor Table,GDT))
-
- [2.2.2.2.1 块组描述符表的核心特性](#2.2.2.2.1 块组描述符表的核心特性)
- [2.2.2.3.1 块位图的核心规则](#2.2.2.3.1 块位图的核心规则)
- [2.2.2.4 inode位图(inode Bitmap)](#2.2.2.4 inode位图(inode Bitmap))
- [2.2.2.4.1 inode位图的核心规则](#2.2.2.4.1 inode位图的核心规则)
- [2.2.2.5 inode表(inode Table)](#2.2.2.5 inode表(inode Table))
- [2.2.2.5.1 inode表的核心特性](#2.2.2.5.1 inode表的核心特性)
- [2.2.2.6 数据块(Data Blocks)](#2.2.2.6 数据块(Data Blocks))
-
- [2.2.2.6.1 数据块的核心分类](#2.2.2.6.1 数据块的核心分类)
- [2.2.2.6.2 数据块的分配策略](#2.2.2.6.2 数据块的分配策略)
-
- [2.2.2.6.3 数据块的碎片化问题:](#2.2.2.6.3 数据块的碎片化问题:)
- [2.3 Ext2文件的数据存储机制](#2.3 Ext2文件的数据存储机制)
-
- [2.3.1 直接块存储(Direct Blocks)](#2.3.1 直接块存储(Direct Blocks))
- [2.3.2 一级间接块存储(Indirect Blocks)](#2.3.2 一级间接块存储(Indirect Blocks))
- [2.3.3 二级间接块存储(Double Indirect Blocks)](#2.3.3 二级间接块存储(Double Indirect Blocks))
- [2.3.4 三级间接块存储(Triple Indirect Blocks)](#2.3.4 三级间接块存储(Triple Indirect Blocks))
- [2.4 目录与文件名的实现机制](#2.4 目录与文件名的实现机制)
-
- [2.4.1 目录项的结构(ext2_dir_entry)](#2.4.1 目录项的结构(ext2_dir_entry))
- [2.4.2 目录文件的组织结构](#2.4.2 目录文件的组织结构)
- [2.4.3 文件名的查找流程](#2.4.3 文件名的查找流程)
- [2.4.4 文件名的修改与删除机制](#2.4.4 文件名的修改与删除机制)
- [2.4.4.1 文件名的修改](#2.4.4.1 文件名的修改)
- [2.4.4.2 文件名的删除](#2.4.4.2 文件名的删除)
- [2.4.5 目录与文件名的限制](#2.4.5 目录与文件名的限制)
- [2.4.6 路径解析](#2.4.6 路径解析)
- [2.4.7 路径缓存](#2.4.7 路径缓存)
- [2.4.8 挂载分区](#2.4.8 挂载分区)
- [2.4.9 ACM时间(时间戳)](#2.4.9 ACM时间(时间戳))
- [2.5 文件系统总结(四张图搞定)](#2.5 文件系统总结(四张图搞定))
- [3 ~> 面试必考题:软硬链接](#3 ~> 面试必考题:软硬链接)
-
- [3.1 硬连接](#3.1 硬连接)
-
- [3.1.1 最佳实践](#3.1.1 最佳实践)
- [3.1.2 硬链接数](#3.1.2 硬链接数)
- [3.1.3 查看/(根目录)有几个目录?](#3.1.3 查看/(根目录)有几个目录?)
- [3.2 软链接](#3.2 软链接)
- [3.3 软硬连接对比](#3.3 软硬连接对比)
- [3.4 软硬连接的作用](#3.4 软硬连接的作用)
- [3.4.1 硬链接](#3.4.1 硬链接)
- [3.4.2 软连接](#3.4.2 软连接)
- [4 ~> 声明与预告](#4 ~> 声明与预告)
- 本文代码演示
- 结尾

1 ~> 理解硬件
1.1 磁盘、服务器、机柜以及机房
1.1.1 磁盘
- 机械磁盘是计算机中唯一的一个机械设备
- 磁盘:外设
- 慢
- 容量大,价格便宜

这个盘片,大家可以想象成光盘 。不知道大家小时候有没有看过《奥特曼》,艾莉丝看过昭和七奥那个时候的光盘,这个光盘被艾莉丝和艾莉丝的哥哥保护的很好,因为那个光盘有个特点------只要盘面刮花了,下次塞到CD机子里面放《奥特曼》的时候电视机屏幕就会冒雪花,本质就是数据丢失了! 这个盘片是在高速旋转的------差的一分钟8000 ~ 9000转,好的磁盘都是2 ~ 3万转的,不仅是盘片,和盘片一样,机械磁盘中唯二的两种运动的另一个会运动的部件:磁头------也在左右来回摆动,当然,这里插一嘴:由此可见磁盘是个机械设备。 这盘片和磁头能够挨着吗?盘片和磁头当然 不 挨着(悬浮的)。这么说可能有点抽象,这个距离就是稍微一点就会碰上的那种,打个比方:一家飞机在离地一米左右的地方低空飞行------差不多就是这样的意思。
机械硬盘还是西方为主(磁盘有使用寿命,3~5年,企业从西方采购,需要定期更换,全国大部分的数据都在各大企业的硬盘里面,不处理会有信息安全的问题!工信部有要求,所以我们让这些硬盘返厂检修的时候会想办法擦除/销毁磁盘 ,土办法是高温消磁法 ------磁盘里面有磁铁,当然现在有软件消磁法,效率高很多),SSD(固态硬盘,里面没有机械,是纯硬件电路)我国已经发展得很不错了。
- SSD:固态硬盘,造价高,磁盘比SSD便宜很多,没有机械结构。和机械磁盘相比就是更加轻量化,比较好卖,而且最近几年价格也越来越便宜了,老百姓能够买得起了已经。
1.1.2 服务器、机房
这是一个生态和产业链相关的话题,艾莉丝这里一张图讲清楚:

磁头会抖动,从而和盘片(磁头和盘片没有直接接触)发生交互------要解决磁盘的共振问题,服务器要散热(有高温周期),因此机房必须装空调,而且空调夏天的时候必须24小时不停地开着,而且机房还要占土地面积,需要地皮,机房建设的技术难度大、成本特别高(动辄几亿乃至几十亿元)------像北上广深这样"寸土寸金"的大城市,地皮成本太高。
机房建设的地方要离能源更近、地皮也要更加便宜(比如贵州的服务器),为什么服务器会建在比较偏的地方?机房需要电力能源(风力、火力、水力发电),因此服务器一般都是在内蒙古、新疆、西藏(雅鲁藏布江下游水电工程,未来"服务器上高原"),即便把机房建到了偏远地区,机房的造价依旧很高,因此,中小企业没有能力建自己的机房(当时被一些互联网大厂发现了潜在的巨大市场)------要用云服务器得靠云服务器厂商------有能力的大公司搞的云服务器(这样大公司也赚到钱了)。国际上知名的云服务器大厂主要是亚马逊,国内有阿里、腾讯、百度...(生态)------生态和供应链关系。
1.1.3 题外话:磁盘与磁铁
-
机械硬盘是用永磁体驱动机械臂运动(寻道),用电磁铁在盘片上读写磁信号(数据) 的精密磁-电-机械系统。没有对磁铁的精确控制和利用,就没有机械硬盘。
-
对比:固态硬盘(SSD)完全摒弃了磁记录和机械运动,使用半导体闪存芯片存储电荷,因此速度更快、抗震性极佳,但成本/容量比在传统领域不及HDD。

实际上,盘片在物理上是原子级光滑 的,但经过磁化后,在磁头的"眼"中(即通过感应磁场变化),它的表面就像布满了"磁性凸起"。
让我们把机械硬盘的"磁性地图"和Linux的Ext文件系统联系起来,这样就更透彻了:
1.1.3.1 盘片上的"地形图":磁畴与比特
-
磁畴: 盘片涂层上的微小磁性区域。每个磁畴的北极指向代表一个比特位(0或1)。
-
"凸起"的真相: 当磁头读取时,它检测的是磁场方向发生翻转的边界。从一个磁畴的指向切换到另一个指向,会产生一个磁场脉冲信号。
-
"地图"的绘制: 因此,在数据层面上,盘片就像一张由无数个"磁性指向箭头"构成的、极精细的二维点阵地图 。写操作 就是用磁头(电磁铁)在这张地图上"雕刻"箭头的方向;读操作就是磁头在这张地图上"巡逻",感应箭头方向的变化。
1.1.3.2 硬盘驱动器如何导航这张地图:物理地址
硬盘必须有一套坐标系来定位这张地图上的每一个点:
-
柱面: 所有盘片上相同半径的磁道组成的"圆柱"。由音圈电机(永磁体部分控制) 驱动磁头臂径向移动来选择。
-
磁头: 选择哪一个盘片的哪一面。由电路切换。
-
扇区: 一个磁道上分成的一段段"圆弧",是读写的最小物理单位(传统为512字节,现代为4K)。
CHS(柱面 - 磁头 - 扇区) 就是这个地图的三维物理坐标。
1.1.3.3 连接硬件与软件:块设备与文件系统
操作系统(如Linux)并不直接操作 柱面、磁头、扇区 这种物理地址,太复杂了。硬盘控制器会将物理地址翻译成简单的逻辑块地址。
(1)块设备: 硬盘对Linux来说,就是一个"块设备"(如/dev/sda)。它被简单地视为一系列逻辑块的线性数组,每个块有固定的编号(LBA)。操作系统只需要说"读写第2048号块",硬盘的固件就会自动通过音圈电机和旋转找到对应的物理位置。
(2)格式化与文件系统: Ext4这样的文件系统,就是在这些逻辑块之上建立起来的高级数据结构和管理规则。它负责:
-
划分区域: 分出引导块、超级块、inode区、数据块区等。
-
建立索引:
inode就像一本账本,记录文件的属性、权限,以及文件数据具体存储在哪些逻辑块上。 -
管理空间: 记录哪些块空闲(位图),哪些已用。
1.1.3.4 描绘出从物理到逻辑的完整链条:
(1)最底层(物理磁场): 盘片上是磁畴箭头构成的"磁性地形图"。
(2)导航层(磁铁驱动): 音圈电机里的永磁体 驱动磁头臂移动到大致"经度"(柱面);盘片旋转决定"纬度"。磁头上的电磁铁负责读取或改变当地"地形"(箭头方向)。
(3)抽象层(块设备): 硬盘控制器将"磁性地形图"上的特定区域,编上简单的逻辑块号,呈现给操作系统。
(4)逻辑层(文件系统 - Ext4): Ext4文件系统将这些逻辑块组织起来,创建出目录树、文件、日志等我们熟悉的概 念。当您保存一个文档时,Ext4会做以下事情:
-
找一个空闲的
inode来记录文件信息。 -
找到一些空闲的逻辑块来存放文件内容。
-
在
inode中建立映射:"我的数据放在第 1001, 1005, 1050... 号块里"。 -
将这个映射关系下发给硬盘驱动程序。
1.1.3.5 总结
这个"凸起",正是磁记录数据的物理本质 。而Ext系列文件系统,是建立在对这种"凸起"进行规律化管理和抽象之上的高级逻辑结构。
简言之:
-
磁铁(永磁体+电磁铁) 是读写和定位"磁性凸起"的直接工具。
-
硬盘控制器把"磁性凸起地图"翻译成线性逻辑块地址。
-
Ext4文件系统则在这些逻辑块之上,构建出目录和文件的殿堂。
理解了这个链条,uu们应该就能明白为什么磁盘碎片化会影响性能(磁头需要到处跳读"凸起"),以及为什么文件系统损坏可能导致数据丢失(管理"凸起"映射关系的账本inode或位图损坏了)。
1.2 机械磁盘物理结构
机械磁盘的物理结构如下图所示:

1.3 磁盘的存储结构
1.3.1 存储结构
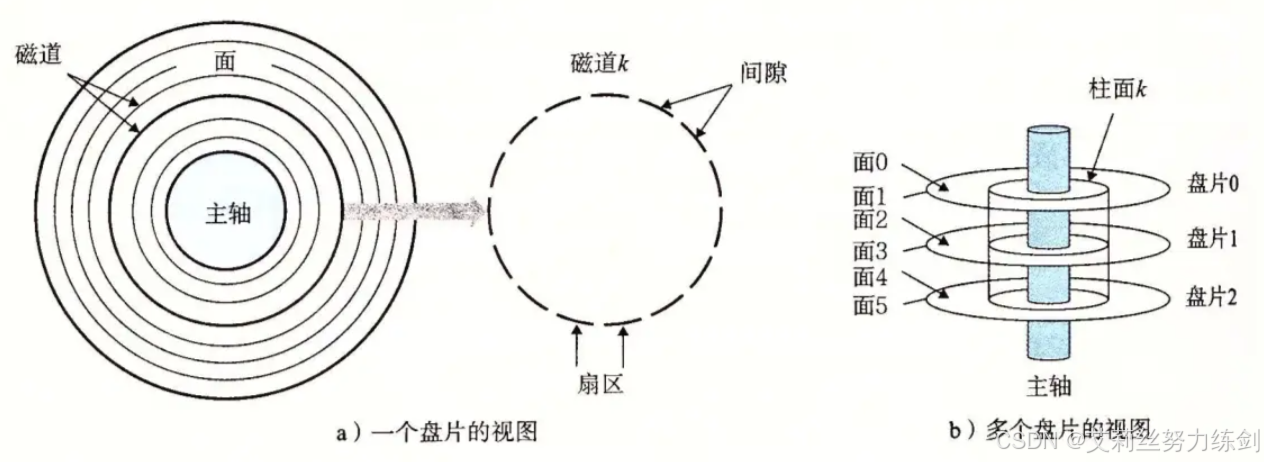
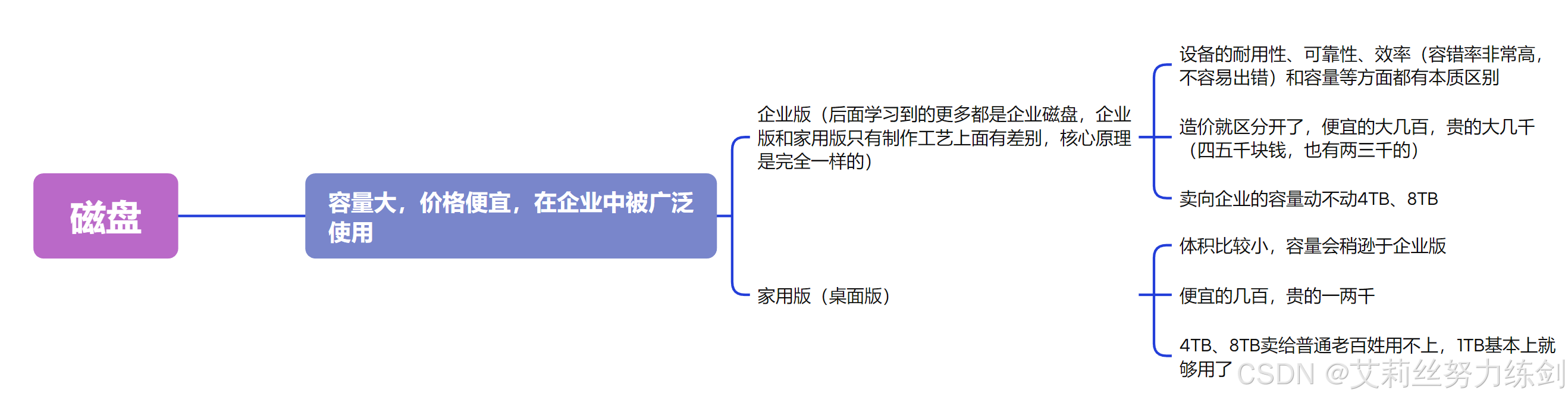
下图这个就是一个盘片:

- 扇区: 扇区是磁盘存储数据的基本单位 ,512字节,块设备(显示器是字符设备)。
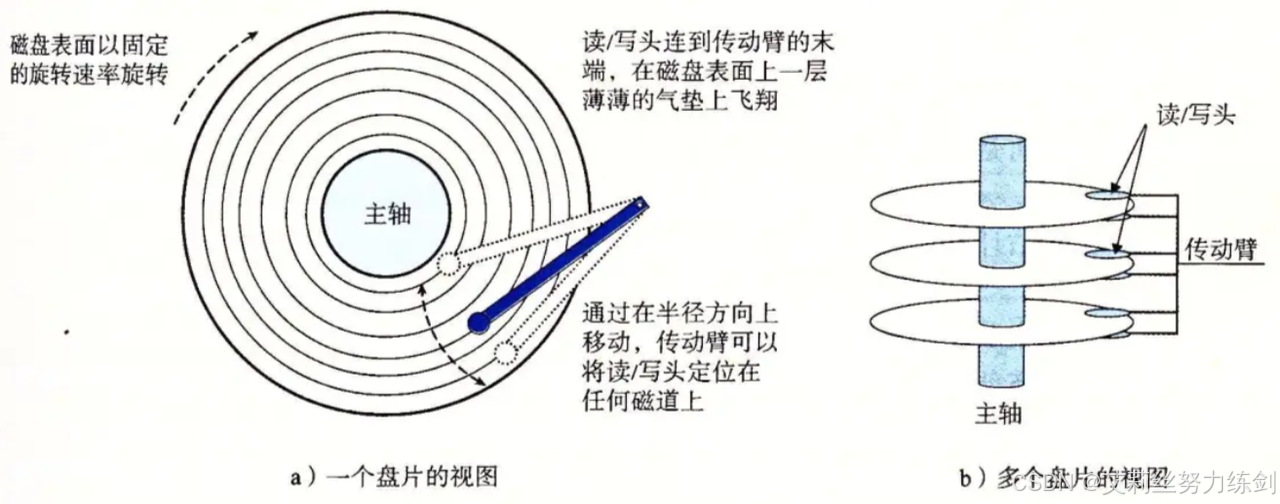
下图是用大模型生成的一幅盘片与磁头的图:

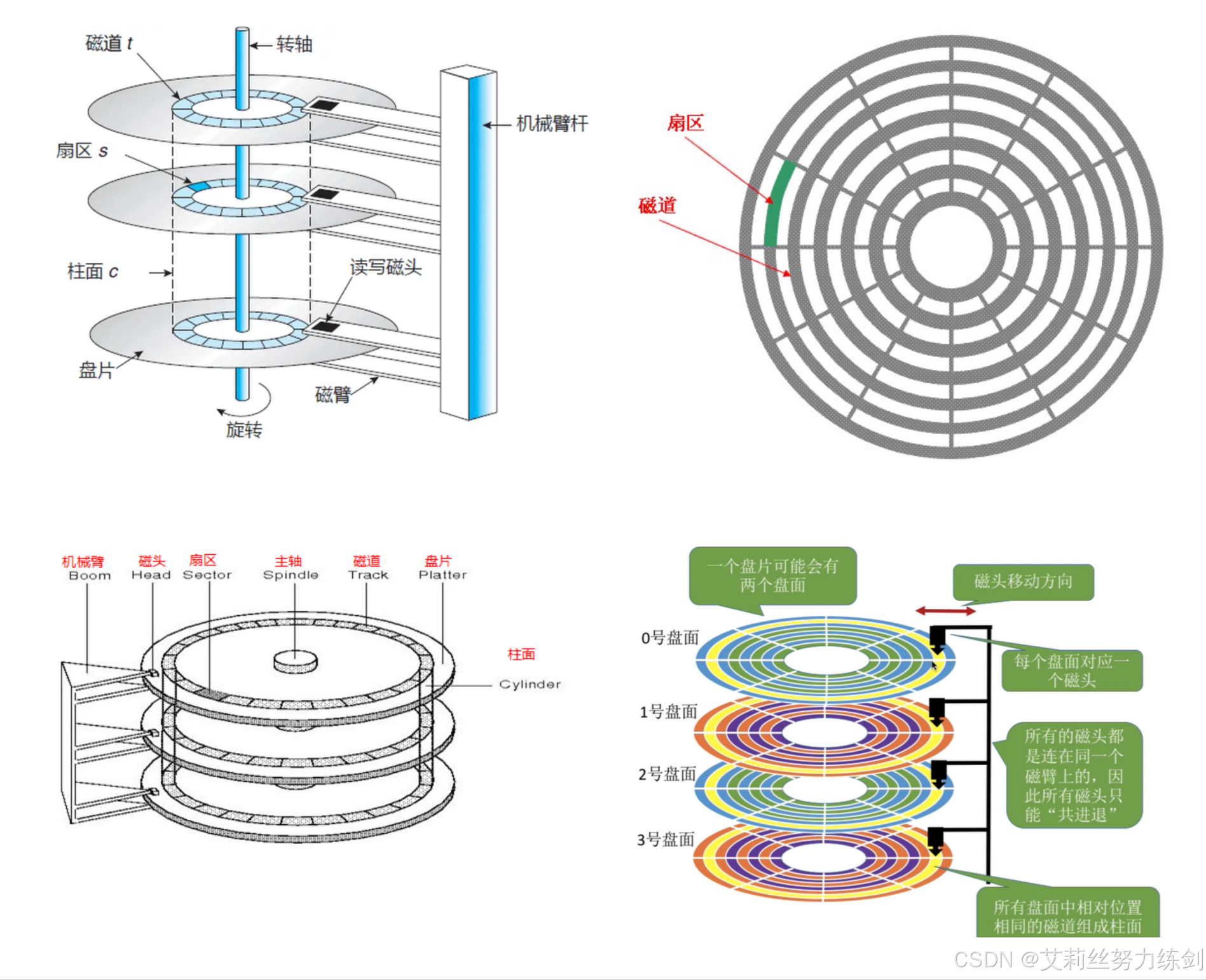
外国人没有咱们的文化底蕴,取不出什么好名字,我们翻译的时候,翻译成了 "扇区" ,很形象,就像一把扇子:

我们可以总结出这样一张思维导图:
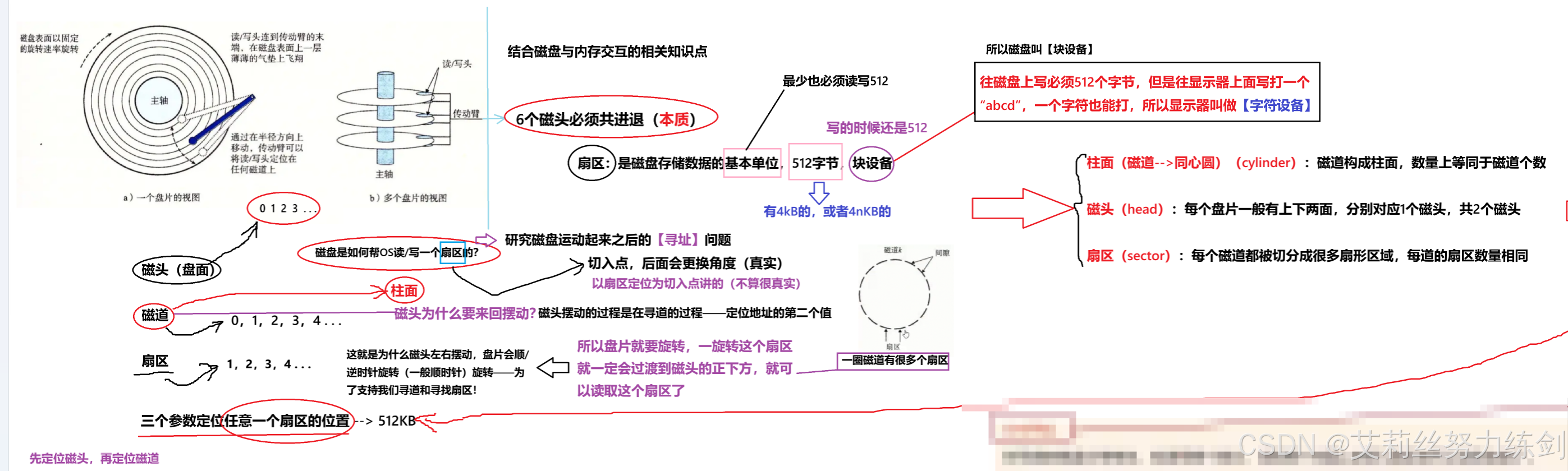
1.3.2 如何定位扇区:CHS地址定位
- 可以先定位磁头(header)
- 确定磁头要访问哪一个柱面(磁道)(cylinder)
- 定位一个扇区(sector)
- CHS地址定位
文件 = 内容 + 属性,都是数据,无非就是占据那几个扇区的问题!能定位一个扇区了,能不能定位多个扇区呢?
我们可以用这样一个命令来
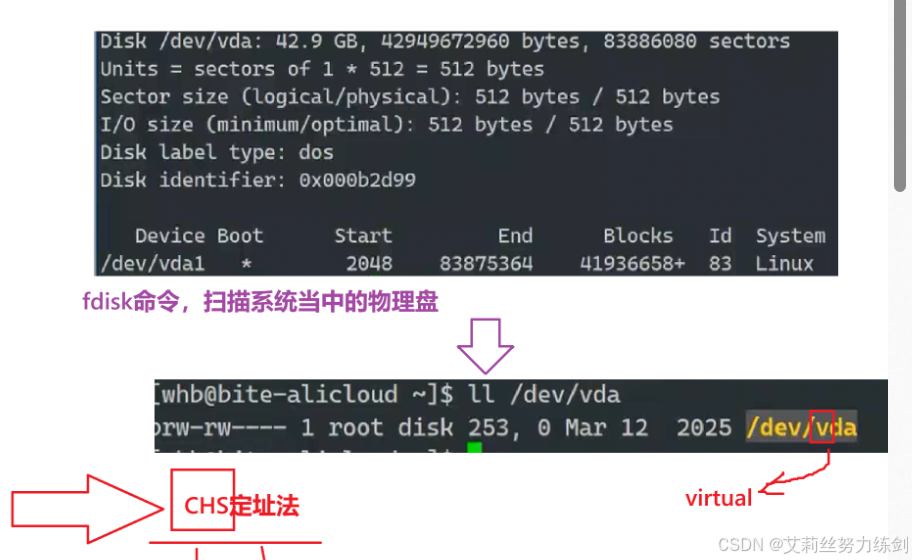
| 术语 | 说明 |
|---|---|
| 扇区(sector) | 从磁盘读出和写入信息的最小单位,通常大小为 512 字节。 |
| 磁头(head) | 每个盘片一般有上下两面,分别对应 1 个磁头 ,共 2 个磁头(每个盘片)。 |
| 磁道(track) | 从盘片外圈往内圈编号,如 0 磁道、1 磁道...。靠近主轴的同心圆用于停靠磁头,不存储数据。 |
| 柱面(cylinder) | 由磁道构成,数量上 等同于磁道个数。 |
| 扇区数(sector) | 每个磁道被切分成很多扇形区域,每道的扇区数量相同。 |
| 圆盘数(platter) | 即 盘片的数量。 |
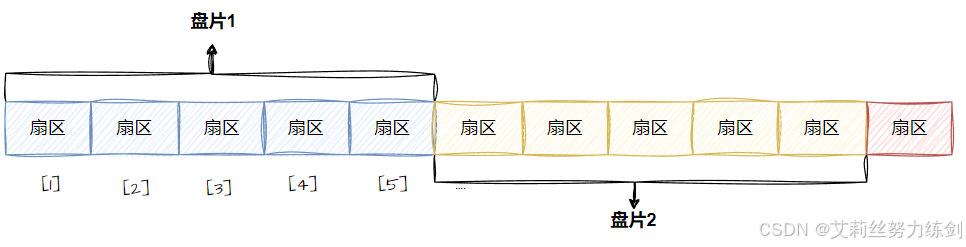
| 细节说明 | 传动臂上的磁头是 共进退 的(这一点在磁盘读写调度中很重要)。 |
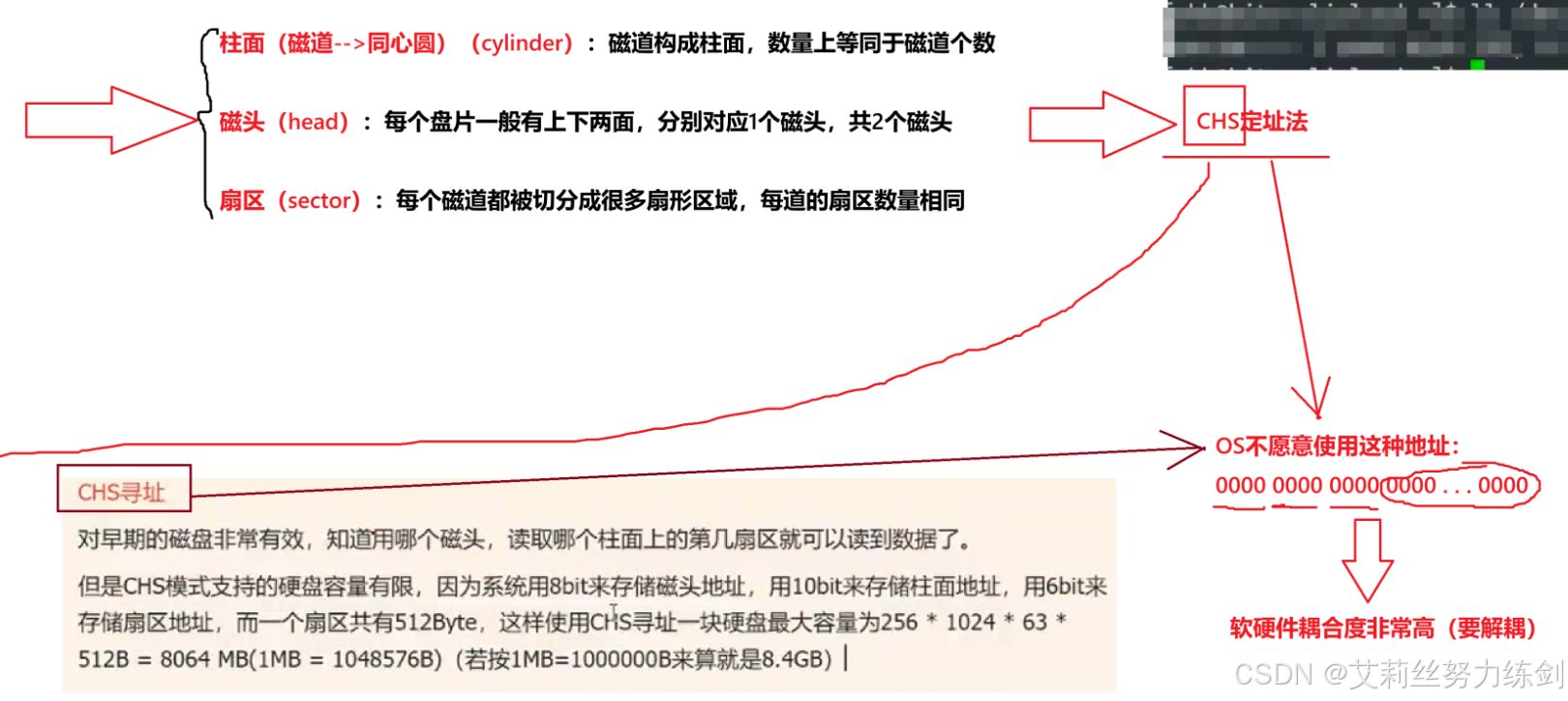
CHS寻址方式: 柱面(cylinder),磁头(head),扇区(sector),显然可以定位数据了,这就是数据定位(寻址)方式之一,CHS寻址方式。
不过,现在的对早期的磁盘非常有效,知道用哪个磁头,读取哪个柱面上的第几扇区就可以读到数据了。但是CHS模式支持的硬盘容量有限 ,因为系统用8bit来存储磁头地址,用10bit来存储柱面地址,用6bit来存储扇区地址,而一个扇区共有512Byte,这样使用CHS寻址一块硬盘最大容量为256* 1024 * 63*512B = 8064MB(1MB=1048576B,若按1MB = 1000000B来算就是8.4GB)
1.4 磁盘的逻辑结构
1.4.1 LBA
只是为了理解,并不完全真实

我们知道,磁带上面可以存储数据,我们可以把磁带 "拉直" ,形成线性结构------


那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在一起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

这样每一个扇区,就有了一个线性地址(其实就是数组下标 ),这种地址叫做 LBA。
我们总结一下,形成这样一张思维导图:
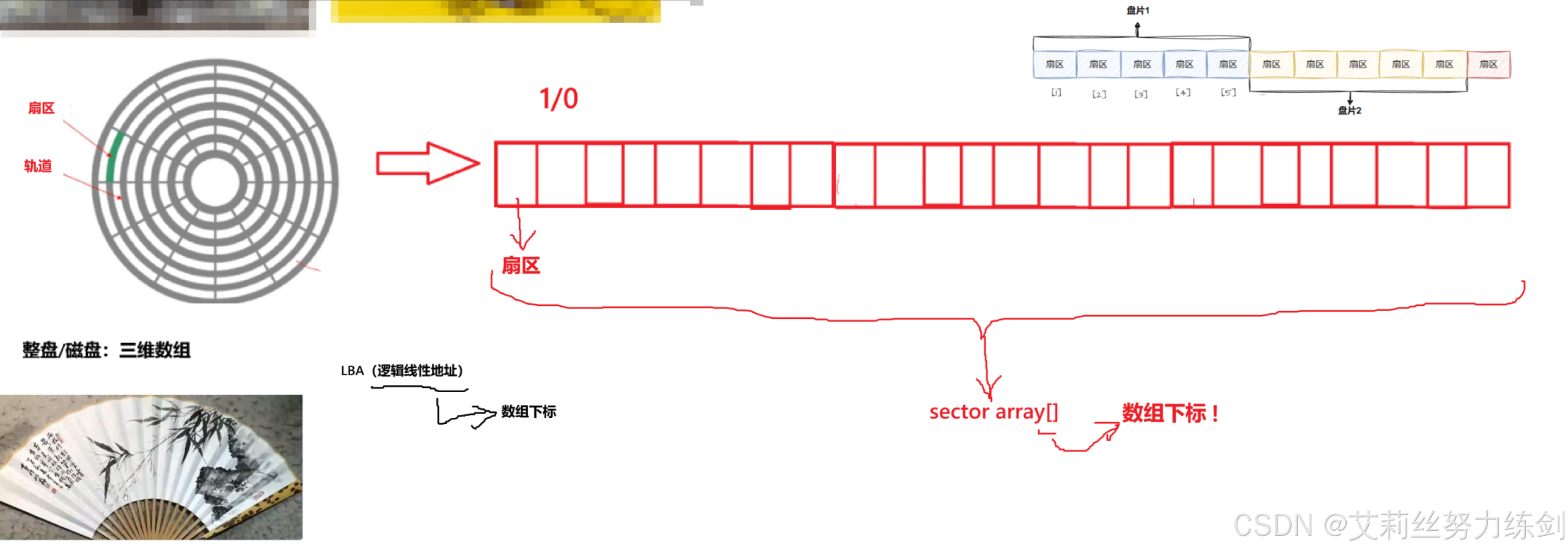
1.4.2 真实的过程
前面其实有这样一个细节:传动臂上的磁头是共进退的。
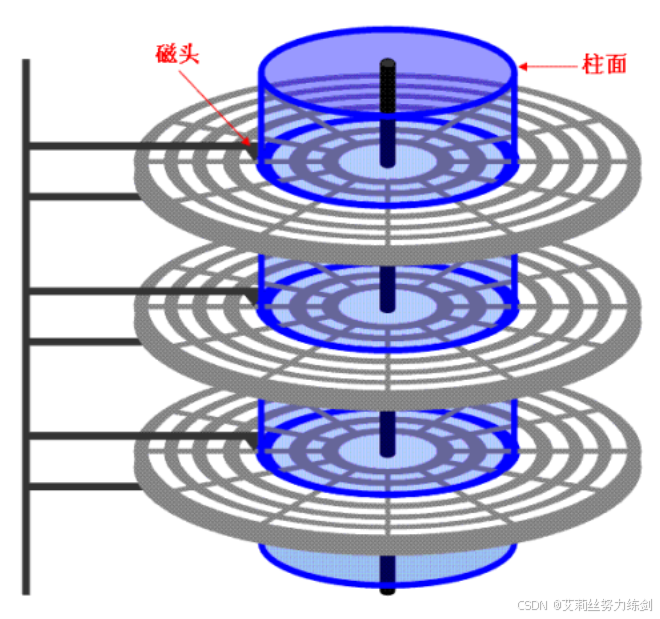
柱面是一个逻辑上的概念,其实就是每一面上,相同半径的磁道(同心圆)逻辑上构成柱面。
所以,磁盘物理上分了很多面,但是在我们看来,逻辑上,磁盘整体是由"柱面"卷起来的,这个构成就有点类似于大家可能吃过的那种果丹皮------

所以,磁盘的真实情况是:
- 磁道: 某一盘面的某一个磁道展开:

即:一维数组。
- 柱面: 整个磁盘所有盘面的同一个磁道,即柱面展开是个二维数组:
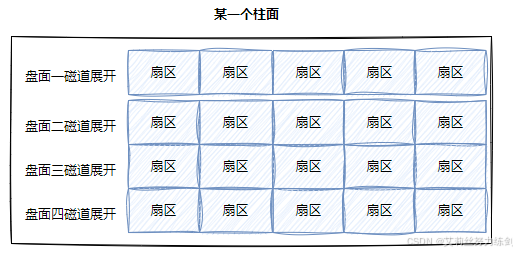
相当于我们把这个柱面想这样裁剪开:
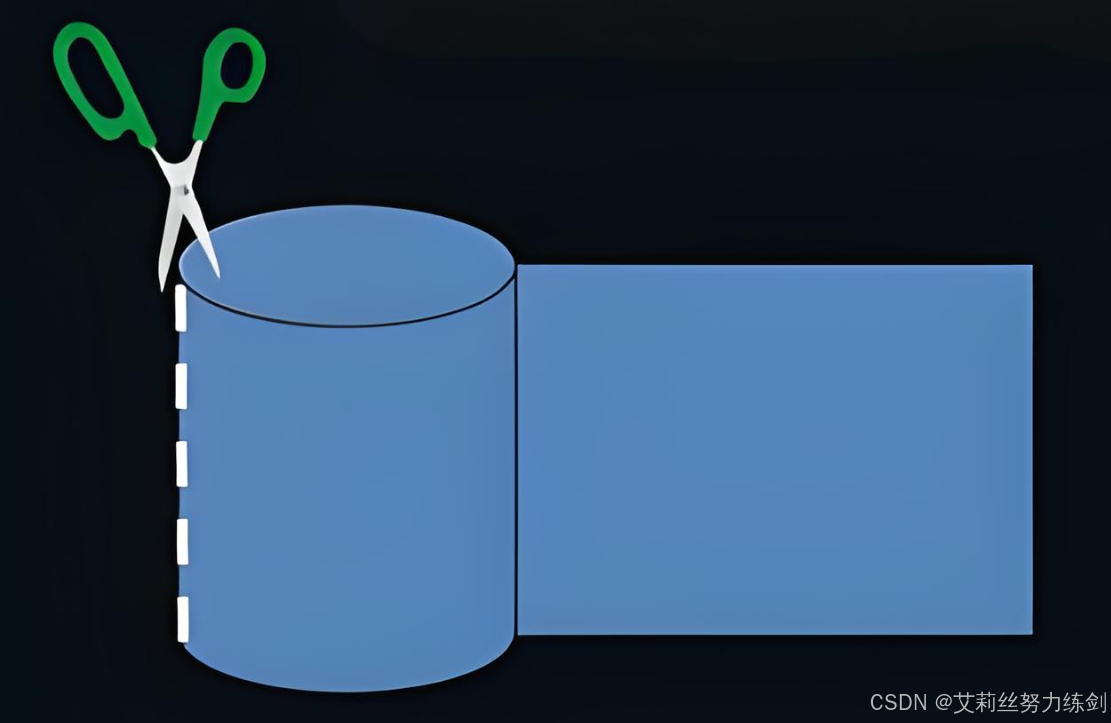
柱面上的每个磁道,扇区个数是一样的------这不就是二维数组吗?
- 整盘: 我们大胆假设一下,根据前面的规律,这个整盘大概率是个三维数组。
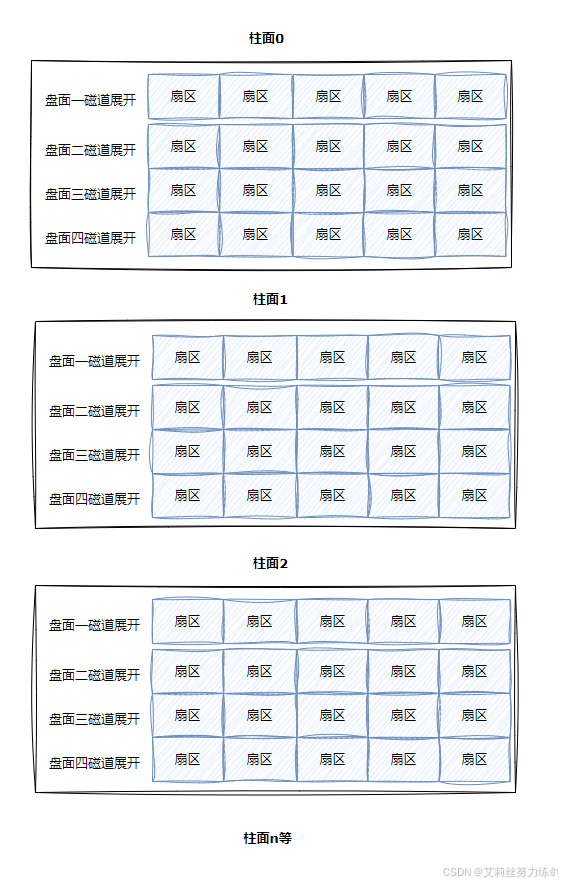
整个磁盘不就是多张二维的扇区数组表(三维数组)吗?
因此,寻址一个扇区: 先找到哪一个柱面(Cylinder),在确定柱面内哪一个磁道(其实就是磁头位置,Head),在确定扇区(Sector),所以就有了 CHS。
我们之前学过C / C++的数组,在我们看来,其实全部都是一维数组:

所以,每一个扇区都有一个下标 ,我们叫做 LBA(Logical Block Address)地址 ,其实就是线性地址。怎么计算得到这个LBA地址呢?
1.4.3 磁盘寻址方式中 LBA(逻辑块地址) 和 CHS(柱面 - 磁头 - 扇区) 的关系以及它们之间的转换由谁来完成问题

LBA,1000,CHS必须要!LBA地址转成CHS地址,CHS如何转换成为LBA地址。
OS只需要使用LBA就可以了!!LBA地址转成CHS地址,CHS如何转换成为LBA地址 。谁来做呢?磁盘自己来做! 固件(硬件电路,伺服系统)。
核心要点: 上面这些怎么理解?
1、LBA(Logical Block Addressing)
-
线性地址,将整个磁盘的所有扇区从 0 开始依次编号。
-
现代操作系统只需要使用 LBA就可以访问磁盘,无需关心具体的物理结构。
2、CHS(Cylinder-Head-Sector)
-
三维地址,通过柱面(Cylinder)、磁头(Head)、扇区(Sector) 三个参数定位扇区。
-
这是早期操作系统直接使用的物理寻址方式。
3、转换的必要性
-
虽然操作系统使用 LBA,但磁盘内部的物理结构仍然是 CHS 形式的(磁头在盘片上移动、旋转)。
-
因此,需要将 LBA 地址转换为磁盘实际能理解的 CHS 地址,才能正确读写数据。
4、谁来转换?
-
这个转换不是由操作系统完成 ,而是由磁盘自身的固件(硬件电路和伺服系统) 自动完成的。
-
操作系统只需发送 LBA 地址,磁盘接收到后,内部固件会将其转换成对应的 CHS 位置,然后执行读写操作。
为什么这么说?
-
现代磁盘对外提供一个简单的 LBA 接口,隐藏了内部复杂的物理结构。
-
磁盘固件负责管理坏道、地址映射、以及 LBA 到物理位置的转换,确保操作系统看到的是一块连续、可靠的逻辑地址空间。
简单类比:
就像你寄快递只需要写收件人的地址(LBA),而不需要知道快递公司内部如何分拣、运输(CHS)。快递公司(磁盘固件)会自动把你的地址转换成内部的路由信息。
1.4.4 CHS和LBA的相互转换
1.4.4.1 转换
CHS转成LBA:
-
磁头数 * 每磁道扇区数=单个柱面的扇区总数
-
LBA = 柱面号C * 单个柱面的扇区总数 + 磁头号H * 每磁道扇区数 + 扇区号S - 1 -
即:LBA=柱面号C*(磁头数每磁道扇区数)+磁头号H每磁道扇区数+扇区号S-1
-
扇区号通常是从1开始的,而在LBA中,地址是从0开始的
-
柱面和磁道都是从0开始编号的
-
总柱面,磁道个数,扇区总数等信息,在磁盘内部会自动维护,上层开机的时候,会获取到这些参数。
LBA转成CHS:
-
柱面号C = LBA //(磁头数*每磁道扇区数)【就是单个柱面的扇区总数】
-
磁头号H =(LBA % ((磁头数*每磁道扇区数))// 每磁道扇区数
-
扇区号S = (LBA%每磁道扇区数)+ 1
-
"//":表示除取整
1.4.4.2 详解转换(了解即可)
CHS与LBA地址的转换是磁盘固件的核心功能之一,转换的前提是已知磁盘的三个关键参数:磁头数(H_total)、每磁道扇区数(S_total)、柱面数(C_total)------这些参数由磁盘固件在开机时上报给操作系统,操作系统将其保存,用于后续的地址转换(实际转换由磁盘固件完成,操作系统仅需传递LBA地址)。
补充说明:单个柱面的扇区总数 = 磁头数(H_total) × 每磁道扇区数(S_total),这是转换公式的核心中间量。
1 CHS地址转换为LBA地址
转换逻辑:先计算目标柱面之前所有柱面的总扇区数,再计算目标磁头在当前柱面内的扇区偏移量,最后加上目标扇区在当前磁道内的偏移量(注意扇区号从1开始,需减1),公式如下:
L B A = C × ( H t o t a l × S t o t a l ) + H × S t o t a l + ( S − 1 ) LBA = C × (H_{total} × S_{total}) + H × S_{total} + (S - 1) LBA=C×(Htotal×Stotal)+H×Stotal+(S−1)
参数说明:
-
C:CHS地址中的柱面号(从0开始)
-
H:CHS地址中的磁头号(从0开始)
-
S:CHS地址中的扇区号(从1开始)
-
H_total:磁盘总磁头数
-
S_total:每磁道扇区数
示例:已知磁盘H_total=4,S_total=63,CHS地址为(10, 2, 5),转换为LBA地址:
L B A = 10 × ( 4 × 63 ) + 2 × 63 + ( 5 − 1 ) = 10 × 252 + 126 + 4 = 2520 + 126 + 4 = 2650 LBA = 10 × (4×63) + 2×63 + (5-1) = 10×252 + 126 + 4 = 2520 + 126 + 4 = 2650 LBA=10×(4×63)+2×63+(5−1)=10×252+126+4=2520+126+4=2650
2 LBA地址转换为CHS地址
转换逻辑:反向推导CHS转LBA的公式,先通过LBA地址计算目标柱面号,再计算目标磁头号,最后计算目标扇区号(注意扇区号需加1,从1开始),公式如下:
-
柱面号: C = L B A / / ( H t o t a l × S t o t a l ) C = LBA // (H_{total} × S_{total}) C=LBA//(Htotal×Stotal)(
//表示整除,取整数部分) -
磁头号: H = ( L B A % ( H t o t a l × S t o t a l ) ) / / S t o t a l H = (LBA \% (H_{total} × S_{total})) // S_{total} H=(LBA%(Htotal×Stotal))//Stotal(
%表示取余) -
扇区号: S = ( L B A % S t o t a l ) + 1 S = (LBA \% S_{total}) + 1 S=(LBA%Stotal)+1
示例:已知磁盘H_total=4,S_total=63,LBA地址=2650,转换为CHS地址:
-
C = 2650 // (4×63) = 2650 // 252 = 10
-
余数 = 2650 % 252 = 2650 - 10×252 = 130
-
H = 130 // 63 = 2
-
S = (130 % 63) + 1 = 4 + 1 = 5
转换结果为CHS(10, 2, 5),与前文示例一致,验证了公式的正确性。
1.4.4.3 地址映射的实际应用
在Linux系统中,操作系统和文件系统始终使用LBA地址访问磁盘,具体流程如下:
-
1、文件系统需要读写数据时,计算出目标数据所在的LBA地址(基于文件的块地址转换)。
-
2、操作系统将LBA地址发送给磁盘控制器(IDE/SATA/SCSI控制器)。
-
3、磁盘控制器通过磁盘固件,将LBA地址转换为CHS地址,定位到具体的物理扇区。
-
4、磁头读写目标扇区的数据,并将数据返回给操作系统,再由操作系统传递给文件系统。
这一过程对文件系统和应用程序完全透明,开发者无需关注CHS与LBA的转换细节,只需专注于LBA地址的管理------这也是文件系统能够跨不同物理结构磁盘兼容的核心原因。
1.4.4.4 认知变化
所以,从此往后,在磁盘使用者看来,根本就不关心CHS地址,而是直接使用LBA地址,磁盘内部自己转换。
从现在开始,磁盘就是一个元素为扇区的一维数组,数组的下标就是每一个扇区的LBA地址。OS使用磁盘,就可以用一个数字访问磁盘扇区了。
2 ~> Ext系列文件系统核心原理(重点Ext2)
Ext系列文件系统是Linux系统的原生文件系统家族,由Remy Card等人开发,最早于1992年推出Ext1,随后逐步迭代出Ext2(1993年)、Ext3(2001年)、Ext4(2008年)。其中,Ext2是整个系列的基础,Ext3在Ext2的基础上增加了日志功能(Journal),Ext4则进一步优化了性能、容量和可靠性,但三者的核心设计理念(块管理、inode管理、块组管理等)完全一致。本文将以Ext2为核心,详细阐述Ext系列文件系统的核心原理。
核心前提: 文件的本质是 "数据 + 属性"(本质都是数据),其中数据是文件的实际内容(如文本、图片、代码等),属性是文件的描述信息(如文件名、大小、所有者、权限、创建时间等)。Ext系列文件系统的核心设计目标,就是高效管理文件的"数据"和"属性",实现数据的快速定位、读写和维护。
2.1 Ext系列文件系统的核心概念
在理解Ext2文件系统的结构之前,需先掌握三个核心概念:块(Block)、inode(索引节点)、块组(Block Group)------这三个概念是Ext2文件系统的基石,贯穿于文件系统的整个设计与实现过程。
2.1.1 块(Block)------ 文件数据的存储单位
块是Ext系列文件系统中文件数据的最小存储单位,也是文件系统读写数据的最小单位。块是基于磁盘扇区的逻辑封装------由于磁盘扇区(512字节)过小,若直接以扇区为单位存储文件,会导致文件的块数过多,增加地址管理的复杂度和磁头的寻道次数,降低读写效率。因此,Ext2文件系统将多个连续的扇区组合成一个"块",作为文件数据的存储单位。
2.1.1.1 块的核心特性
-
块大小可配置: 块的大小在文件系统格式化时确定,一旦确定无法修改,主流大小为4KB(默认值),也可配置为1KB、2KB、8KB。块大小的选择需结合磁盘容量和应用场景:小容量磁盘适合选择小 block(如1KB),避免块浪费;大容量磁盘适合选择大 block(如4KB、8KB),提升读写效率。
-
块的编号: 块的编号以分区为单位,从0开始依次编号(块0、块1、块2......),每个块有一个唯一的块号------文件系统通过块号定位到具体的块,再通过块号与LBA地址的转换,实现对磁盘扇区的访问。
-
块与扇区的对应关系: 块由连续的扇区组成,块大小必须是扇区大小(512字节)的整数倍。例如:4KB块对应8个连续的512字节扇区,块号为n的块,对应的LBA地址范围为n×8 ~ (n+1)×8 - 1。
-
块的类型: Ext2文件系统中的块分为两类:数据块(Data Block)和管理块(如超级块、位图块、inode表块等),其中数据块用于存储文件的实际内容,管理块用于存储文件系统的管理信息。
示例:通过Linux系统的stat命令,可查看文件的块相关信息:
bash
[whb@bite-alicloud stdio]$ stat main.c
File: 'main.c'
Size: 488 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 1052007 Links: 1
Access: (0664/-rw-rw-r--) Uid: (1000/ whb) Gid: (1000/ whb)
Modify: 2024-10-17 19:06:11.139423737 +0800
Change: 2024-10-17 19:06:11.139423737 +0800
Birth: -解读:该文件大小为488字节,占用8个IO Block(即4KB块,8×512字节=4096字节),即使文件大小不足4KB,也会占用一个完整的块------这是块存储的"空间浪费"特性,也是平衡效率与空间的trade-off。
2.1.2 inode(索引节点)------ 文件属性的存储单位
inode(Index Node,索引节点)是Ext系列文件系统中存储文件属性的核心结构,每个文件对应一个唯一的inode,inode中存储了文件的所有属性信息(除文件名外),以及文件数据所在的数据块的地址------通过inode,文件系统可以将文件的属性与数据关联起来,实现文件的访问。
2.1.2.1 inode的核心特性:
-
inode的唯一性: inode的编号以分区为单位,从1开始依次编号(inode 1、inode 2、inode 3......),每个inode有一个唯一的inode号------这是文件的唯一标识,比文件名更核心(文件名可修改,但inode号不变)。
-
inode的大小固定: inode的大小在文件系统格式化时确定,默认为128字节,也可配置为256字节。无论文件的大小和类型如何,其对应的inode大小始终一致------这是因为inode的结构是固定的,仅存储文件的属性和数据块地址,不存储文件内容。
-
inode不存储文件名: 这是Ext系列文件系统的关键设计之一------文件名存储在目录文件的数据块中,而非inode中。inode与文件名的对应关系由目录管理,这也是软硬链接实现的基础。
-
inode的数量固定: inode的总数量在文件系统格式化时确定,与块的总数量成正比(通常为块总数的1/16或1/32)。若分区中需要存储大量小文件(每个文件占用一个inode),可能会出现"inode耗尽但块仍有剩余"的情况,此时无法创建新文件,需重新格式化分区并调整inode数量。
2.1.2.2 Ext2 inode的具体结构
bash
Ext2文件系统的inode结构由C语言结构体定义(内核源码中的ext2_inode结构体),包含了文件的所有属性和数据块地址,核心字段如下(简化版,保留关键字段):
struct ext2_inode {
__le16 i_mode; /* 文件模式:区分文件类型(普通文件、目录、链接等)和权限 */
__le16 i_uid; /* 文件所有者的UID(低16位) */
__le32 i_size; /* 文件大小(字节) */
__le32 i_atime; /* 最后访问时间(时间戳) */
__le32 i_ctime; /* inode创建时间(时间戳) */
__le32 i_mtime; /* 文件内容最后修改时间(时间戳) */
__le32 i_dtime; /* 文件删除时间(时间戳) */
__le16 i_gid; /* 文件所属组的GID(低16位) */
__le16 i_links_count; /* 硬链接数 */
__le32 i_blocks; /* 文件占用的数据块数(以512字节为单位) */
__le32 i_flags; /* 文件标志(如只读、隐藏等) */
__le32 i_block[EXT2_N_BLOCKS]; /* 数据块地址指针数组(核心字段) */
__le32 i_generation; /* 文件版本(用于NFS) */
__le32 i_file_acl; /* 文件ACL(访问控制列表)地址 */
__le32 i_dir_acl; /* 目录ACL地址 */
__le32 i_faddr; /* 碎片地址 */
/* 其他OS相关的扩展字段... */
};
/* 数据块指针数组的大小:12个直接块 + 1个一级间接块 + 1个二级间接块 + 1个三级间接块 = 15个 */
#define EXT2_NDIR_BLOCKS 12 /* 直接块指针数量 */
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS /* 一级间接块指针索引 */
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) /* 二级间接块指针索引 */
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) /* 三级间接块指针索引 */
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) /* 总指针数量:15 */2.1.2.3 inode核心字段解读:
-
i_mode: 16位字段,高4位表示文件类型(如0x8表示普通文件、0x4表示目录、0x2表示符号链接等),低12位表示文件权限(所有者、所属组、其他用户的读/写/执行权限)。
-
i_size: 文件的实际大小(字节),对于普通文件,该值为文件内容的字节数;对于目录文件,该值为目录数据块的大小(通常为4KB)。
-
时间戳字段: i_atime(访问时间)、i_mtime(修改时间)、i_ctime(创建时间)、i_dtime(删除时间),均以Unix时间戳(从1970年1月1日00:00:00 UTC开始的秒数)存储,Linux系统通过这些时间戳管理文件的生命周期。
-
i_links_count: 文件的硬链接数,默认值为1(创建文件时),每创建一个硬链接,该值加1;每删除一个硬链接,该值减1,当该值为0时,文件的inode和数据块被释放(真正删除文件)。
-
i_blockEXT2_N_BLOCKS: 核心字段,用于存储文件数据所在的数据块地址指针,共15个指针,分为4种类型(直接块、一级间接块、二级间接块、三级间接块),用于支持不同大小的文件存储------这是Ext2文件系统支持大文件的关键设计。
2.1.3 块组(Block Group)------ 文件系统的分区管理单元
Ext2文件系统将整个磁盘分区划分为若干个大小相等的"块组"(Block Group),每个块组包含一组连续的块,所有块组的结构完全一致------这种设计的核心目的是分散文件系统的管理信息,避免因单个管理块损坏导致整个文件系统瘫痪,同时减少磁头的寻道次数(文件的inode和数据块尽量放在同一个块组中)。
2.1.3.1 块组的核心特性:
-
块组大小固定: 块组的大小由块大小和块组内的块数决定,默认情况下,每个块组包含8192个块(如4KB块,块组大小为8192×4KB=32MB),块组的数量 = 分区总块数 ÷ 每个块组的块数。
-
块组结构一致: 每个块组都包含超级块、块组描述符表、块位图、inode位图、inode表、数据块六个部分,其中超级块和块组描述符表在多个块组中存在备份,确保文件系统的可靠性。
-
块组的编号: 块组从0开始依次编号(块组0、块组1、块组2......),每个块组的起始块号 = 块组编号 × 每个块组的块数。
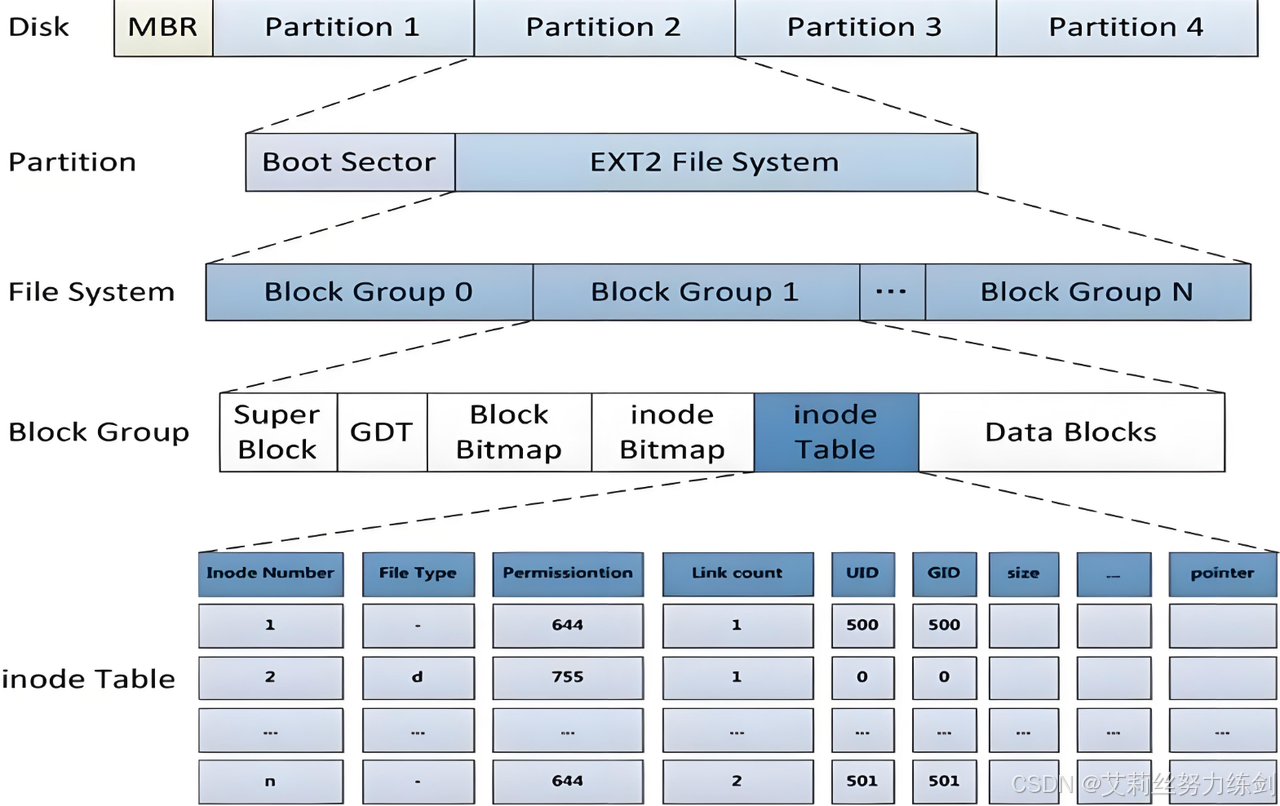
2.2 Ext2文件系统的整体结构
Ext2文件系统的整体结构以块组为基础,从磁盘分区的起始位置开始,依次分为启动块(Boot Block)和多个块组(Block Group 0、Block Group 1、......、Block Group N),具体结构如下:
2.2.1 启动块(Boot Block)
启动块位于磁盘分区的最起始位置(块0),大小固定为1KB(由PC标准规定),用于存储磁盘分区信息和操作系统的引导程序(如GRUB),不属于Ext2文件系统的管理范围,任何文件系统都不能修改启动块------若启动块损坏,将导致操作系统无法引导。
2.2.2 块组的内部结构
每个块组(Block Group)的内部结构从起始位置开始,依次为超级块、块组描述符表、块位图、inode位图、inode表、数据块,各部分的功能如下:
2.2.2.1 超级块(Super Block)
超级块是Ext2文件系统的"总控中心",存储整个文件系统的全局管理信息,用于描述文件系统的整体状态和参数,是文件系统正常工作的核心------若超级块损坏,整个文件系统将无法挂载和使用。
2.2.2.1.1 超级块的核心特性
-
备份机制: 超级块在块组0中一定存在,同时会在其他块组(通常是块组编号为2的幂的块组,如块组1、2、4、8......)中存在备份,备份的目的是当块组0的超级块损坏时,可通过备份的超级块恢复文件系统。
-
大小固定: 超级块的大小固定为1个块(如4KB块,超级块大小为4KB),存储在块组的第一个块(块组起始块号 + 1)。
-
核心存储信息: 超级块的结构由ext2_super_block结构体定义(内核源码),核心信息如下(下面这个属于简化版):
c
struct ext2_super_block {
__le32 s_inodes_count; /* 文件系统的总inode数 */
__le32 s_blocks_count; /* 文件系统的总块数 */
__le32 s_r_blocks_count; /* 保留块数(仅root用户可使用) */
__le32 s_free_blocks_count; /* 空闲块数 */
__le32 s_free_inodes_count; /* 空闲inode数 */
__le32 s_first_data_block; /* 第一个数据块的块号(通常为1) */
__le32 s_log_block_size; /* 块大小的日志值(用于计算块大小) */
__le32 s_log_frag_size; /* 碎片大小的日志值 */
__le32 s_blocks_per_group; /* 每个块组的块数 */
__le32 s_frags_per_group; /* 每个块组的碎片数 */
__le32 s_inodes_per_group; /* 每个块组的inode数 */
__le32 s_mtime; /* 文件系统最后挂载时间(时间戳) */
__le32 s_wtime; /* 文件系统最后写入时间(时间戳) */
__le16 s_mnt_count; /* 文件系统挂载次数 */
__le16 s_max_mnt_count; /* 最大挂载次数(超过后需检查文件系统) */
__le16 s_magic; /* 魔法数(Ext2的魔法数为0xEF53,用于识别文件系统类型) */
__le16 s_state; /* 文件系统状态(正常、错误、只读等) */
__le16 s_errors; /* 错误处理方式(忽略、恢复、panic等) */
__le16 s_minor_rev_level; /* 次版本号 */
__le32 s_lastcheck; /* 最后一次检查文件系统的时间(时间戳) */
__le32 s_checkinterval; /* 检查文件系统的时间间隔(秒) */
__le32 s_creator_os; /* 创建文件系统的操作系统 */
__le32 s_rev_level; /* 主版本号 */
__le16 s_def_resuid; /* 保留块的默认UID */
__le16 s_def_resgid; /* 保留块的默认GID */
/* 其他扩展字段... */
};关键解读: s_magic(魔法数)是识别文件系统类型的核心字段,Ext2的魔法数为0xEF53,操作系统挂载分区时,会读取超级块的魔法数,判断该分区的文件系统类型是否为Ext2;s_blocks_per_group和s_inodes_per_group用于确定每个块组的块数和inode数,是块组管理的基础。
2.2.2.2 块组描述符表(Group Descriptor Table,GDT)
块组描述符表用于存储每个块组的描述信息,每个块组对应一个块组描述符(ext2_group_desc结构体),所有块组描述符组成块组描述符表------文件系统通过块组描述符表,可快速定位每个块组的位图、inode表、数据块的位置。
2.2.2.2.1 块组描述符表的核心特性
-
备份机制: 与超级块类似,块组描述符表在块组0中存在,同时在其他有超级块备份的块组中存在备份,确保块组描述信息不丢失。
-
大小计算: 块组描述符的大小为32字节,块组描述符表的大小 = 块组数量 × 32字节,通常占用1~多个块(如块组数量为100,块组描述符表大小为3200字节,占用1个4KB块)。
-
块组描述符的核心结构:
c
struct ext2_group_desc {
__le32 bg_block_bitmap; /* 块位图的块号 */
__le32 bg_inode_bitmap; /* inode位图的块号 */
__le32 bg_inode_table; /* inode表的起始块号 */
__le16 bg_free_blocks_count;/* 该块组的空闲块数 */
__le16 bg_free_inodes_count;/* 该块组的空闲inode数 */
__le16 bg_used_dirs_count; /* 该块组的目录数 */
__le16 bg_pad; /* 填充字段(对齐) */
__le32 bg_reserved[3]; /* 保留字段 */
};关键解读: bg_block_bitmap、bg_inode_bitmap、bg_inode_table是核心字段,分别指向该块组的块位图、inode位图、inode表的块号------通过这三个字段,文件系统可快速定位到块组内的管理结构,实现块和inode的分配与释放。
块位图(Block Bitmap)
Block Bitmap中记录着DataBlock中哪个数据块已经被占用,哪个数据块没有被占用。
块位图用于管理该块组内的数据块和管理块的分配状态,记录哪些块已被占用、哪些块没有被占用------块位图的大小为1个块(如4KB块,块位图大小为4KB),每个bit位对应一个块(bit位与块号一一对应)。
2.2.2.3.1 块位图的核心规则
-
bit位的编号与块组内的块编号一一对应(bit 0对应块组内的第0块,bit 1对应块组内的第1块,......,bit n对应块组内的第n块)。
-
bit位的值为0,表示对应的块空闲,可用于分配;bit位的值为1,表示对应的块已被占用(用于存储数据或管理信息)。
-
块位图的分配与释放: 当需要分配一个块时,文件系统会扫描块位图,查找值为0的bit位(空闲块),找到后将该bit位设为1(标记为占用),并计算出对应的块号,分配给需要的结构(如数据块、管理块);当需要释放一个块时,文件系统会找到该块对应的bit位,将其设为0(标记为空闲),完成块的释放。为了提升分配效率,Linux内核会维护一个空闲块链表,记录最近空闲的块,避免每次分配都扫描整个位图------这是Ext2文件系统在块分配上的优化策略。
-
块位图的损坏影响: 块位图是块分配与释放的核心,若块位图损坏,会导致文件系统无法准确识别哪些块空闲、哪些块占用,可能出现重复分配块(多个文件占用同一个块,导致数据覆盖损坏)或块泄漏(块被标记为占用但实际未使用,无法被重新分配,造成磁盘空间浪费)。此时需通过e2fsck工具扫描磁盘,重建块位图,恢复文件系统的正常使用。
2.2.2.4 inode位图(inode Bitmap)
inode位图与块位图的设计逻辑完全一致,核心作用是管理该块组内inode的分配状态,记录哪些inode已被占用、哪些inode空闲------inode位图的大小同样为1个块(如4KB块,inode位图大小为4KB),每个bit位对应一个inode(bit位与inode号一一对应)。
2.2.2.4.1 inode位图的核心规则
-
bit位的编号与块组内的inode编号一一对应(bit 0对应块组内的第0个inode,bit 1对应块组内的第1个inode,......,bit n对应块组内的第n个inode)。需要注意的是,inode编号以分区为单位,块组内的inode编号 = 块组编号 × 每个块组的inode数 + 块组内的偏移量。
-
bit位的值为0,表示对应的inode空闲,可用于分配(创建新文件时分配inode);bit位的值为1,表示对应的inode已被占用(对应某个已存在的文件)。
-
inode位图的分配与释放: 创建新文件时,文件系统会扫描inode位图,查找值为0的bit位,找到后将该bit位设为1,分配对应的inode号,并初始化inode的属性(如所有者、权限、创建时间等);删除文件时,当文件的硬链接数(i_links_count)减至0,文件系统会将该文件对应的inode位图bit位设为0,释放inode,同时释放该inode指向的数据块。
-
inode位图的备份: 与块位图不同,inode位图没有单独的备份机制,每个块组的inode位图仅存储在该块组内------若某块组的inode位图损坏,会导致该块组内的inode分配状态丢失,可能出现inode重复分配或泄漏,需通过e2fsck工具重建inode位图。
示例:假设某块组的inode位图为4KB(32768个bit位),每个块组的inode数为32768,则该inode位图可管理32768个inode,刚好对应一个块组的inode总量------这是Ext2文件系统的默认设计,确保inode位图的大小与块组内的inode数匹配,避免空间浪费。
2.2.2.5 inode表(inode Table)
inode表是块组内存储所有inode的连续块集合,每个inode占用固定大小的空间(默认128字节或256字节),inode表的起始块号由块组描述符的bg_inode_table字段指定,inode表的大小 = 每个块组的inode数 × inode大小,通常占用多个连续的块。
2.2.2.5.1 inode表的核心特性
-
inode的存储顺序: inode表内的inode按inode编号顺序存储,即inode表的第一个inode对应块组内的第0个inode(分区内inode编号 = 块组编号×inode数 + 0),第二个inode对应块组内的第1个inode,以此类推------这种顺序存储方式便于文件系统通过inode编号快速定位到inode在表中的位置,提升访问效率。
-
inode表的定位方式: 文件系统要访问某个inode时,先根据inode编号计算出该inode所属的块组(块组编号 = inode编号 ÷ 每个块组的inode数),再找到该块组的块组描述符,通过bg_inode_table字段获取inode表的起始块号,最后计算出inode在表中的偏移量(偏移量 = (inode编号 % 每个块组的inode数) × inode大小),从而定位到该inode的具体位置,读取其内容。
-
inode表的空闲管理: inode表的空闲状态由inode位图管理,当inode位图标记某个inode为空闲时,该inode在inode表中的空间可被重新使用,创建新文件时会覆盖该inode的原有内容(如属性、数据块地址等)------但需注意,若原有文件的数据块未被释放(如硬链接数未减至0),则该inode指向的数据块仍会被保留,避免数据丢失。
-
inode表的损坏影响: inode表损坏会导致文件的属性丢失(如文件名无法关联到数据、文件权限异常、文件大小错误等),若损坏的inode对应关键文件(如系统文件),可能导致系统无法正常运行。此时可通过e2fsck工具尝试恢复inode表,若无法恢复,可能导致对应文件永久丢失。
补充说明: Ext2文件系统的inode表默认占用块组内的连续块,这种连续存储方式可减少磁头的寻道次数,提升inode的访问速度------这是因为磁头可一次性读取inode表的多个连续块,无需频繁移动磁头定位分散的块。
2.2.2.6 数据块(Data Blocks)
数据块是块组内用于存储文件实际内容的区域,也是块组中占用空间最大的部分(其余部分为管理块,仅占用少量空间),数据块的分配与释放由块位图管理,文件的所有实际内容(如文本、图片、代码等)都存储在数据块中,目录文件的内容(文件名与inode号的对应关系)也存储在数据块中。
2.2.2.6.1 数据块的核心分类
根据存储内容的不同,Ext2文件系统的数据块可分为三类,分别对应不同的文件类型和使用场景:
-
普通文件数据块: 用于存储普通文件的实际内容(如.txt、.c、.exe等文件),是最常用的数据块类型。普通文件的数据块由该文件的inode中的i_block数组指向,文件系统通过inode找到对应的数据块,读取或写入文件内容。普通文件的数据块可分为直接块、一级间接块、二级间接块、三级间接块,具体实现将在后续章节详细阐述。
-
目录文件数据块: 用于存储目录文件的内容------目录文件本质上是一种特殊的文件,其内容并非用户数据,而是该目录下所有文件(包括子目录)的"目录项"(directory entry),每个目录项记录了文件名与对应的inode号,以及目录项的相关属性(如目录项长度、文件类型等)。目录文件的数据块同样由其inode的i_block数组指向,文件系统通过目录文件的数据块,可实现文件名到inode号的映射,进而访问文件的属性和内容。
-
特殊文件数据块: 用于存储特殊文件的内容,如符号链接文件、设备文件、管道文件等。其中,符号链接文件的数据块存储的是目标文件的路径(若路径较短,可直接存储在inode的i_block数组中,无需占用独立的数据块);设备文件、管道文件等特殊文件不存储实际数据,其数据块通常为空,仅通过inode的属性标识文件类型和相关参数。
2.2.2.6.2 数据块的分配策略
Ext2文件系统采用 "就近分配" 和 "连续分配" 相结合的策略分配数据块,核心目的是减少磁头的寻道次数,提升文件的读写效率,具体策略如下:
-
连续分配优先: 创建文件时,文件系统会尽量为文件分配连续的 data 块------连续的数据块可让磁头一次性读取多个块,无需频繁移动磁头定位分散的块,大幅提升读写速度。例如:创建一个1MB的文件(块大小4KB),文件系统会分配256个连续的数据块,存储该文件的内容。
-
就近分配补充: 若当前块组内没有足够的连续空闲块,文件系统会优先在同一块组内分配空闲块(即使不连续),避免跨块组分配------因为同一块组内的块物理位置相近,磁头移动距离短,访问速度快;若当前块组内无空闲块,再在其他块组分配空闲块。
-
预分配机制: 对于正在写入的文件,Ext2文件系统会预分配多个连续的空闲块,供文件后续写入使用------这种机制可避免文件随写入量增加而出现数据块分散(碎片化)的情况,确保文件的读写效率。预分配的块若未被使用,文件关闭后会被释放,避免空间浪费。
2.2.2.6.3 数据块的碎片化问题:
数据块碎片化是所有文件系统都会面临的问题,指的是一个文件的数据块分散在磁盘的不同位置(非连续),导致磁头需要频繁移动定位各个数据块,大幅降低读写效率。Ext2文件系统通过以下方式缓解碎片化问题:
-
采用连续分配和就近分配策略,尽量减少数据块的分散。
-
实现块缓存机制,将常用的数据块缓存到内存中,减少磁盘访问次数,间接缓解碎片化带来的效率损失。
-
提供e2defrag工具,可对碎片化严重的文件系统进行整理,将分散的数据块整理为连续块,提升读写效率。
补充说明:Ext2文件系统不支持动态碎片整理(如Ext4的在线碎片整理功能),需在文件系统卸载后,通过e2defrag工具进行离线整理------这是Ext2与Ext4的主要区别之一,也是Ext2在现代大容量磁盘中应用逐渐减少的原因之一。
2.3 Ext2文件的数据存储机制
Ext2文件系统通过inode的i_block数组(15个指针)管理文件的数据块,根据文件大小的不同,采用四种不同的存储方式:直接块存储、一级间接块存储、二级间接块存储、三级间接块存储------这种分层存储方式既保证了小文件的访问效率,又支持大文件的存储,是Ext2文件系统的核心设计之一。
核心前提:每个数据块指针(i_block数组中的每个元素)占用4字节,可存储一个块号(32位),因此每个指针可指向一个数据块;若块大小为4KB,则每个数据块可存储1024个块号(4KB ÷ 4字节/个 = 1024个)------这是计算不同存储方式支持最大文件大小的关键依据。
2.3.1 直接块存储(Direct Blocks)
直接块存储是Ext2文件系统中最基础、最高效的存储方式,适用于小文件(通常为小于48KB的文件,块大小4KB时)。inode的i_block数组前12个指针(i_block0 ~ i_block11)为直接块指针,每个指针直接指向存储文件内容的数据块------文件系统通过这12个指针,可直接定位到文件的数据块,无需额外的间接查找,访问效率最高。
直接块存储的核心特点:
-
访问效率高:无需间接查找,通过inode的直接块指针可直接定位到数据块,磁头移动次数最少,适合小文件的频繁读写。
-
存储容量有限:块大小为4KB时,12个直接块可存储的最大文件大小 = 12 × 4KB = 48KB;若块大小为8KB,最大可存储96KB------仅能满足小文件的存储需求,无法存储大文件。
-
适用场景:系统中的大多数文件(如配置文件、日志文件、小型脚本等)均为小文件,适合采用直接块存储,可充分发挥其访问高效的优势。
示例:一个大小为30KB的文件(块大小4KB),需要占用8个数据块(30KB ÷ 4KB ≈ 8个),文件系统会将这8个数据块的块号,依次存储在inode的i_block0 ~ i_block7中,剩余的4个直接块指针(i_block8 ~ i_block11)设为0(未使用);当读取该文件时,文件系统直接通过这8个指针,定位到对应的数据块,读取文件内容。
2.3.2 一级间接块存储(Indirect Blocks)
当文件大小超过直接块存储的最大容量(如48KB,块大小4KB)时,Ext2文件系统会使用一级间接块存储------inode的i_block数组第13个指针(i_block12)为一级间接块指针,该指针不直接指向存储文件内容的数据块,而是指向一个"一级间接块",该间接块中存储的是多个数据块的块号(而非文件内容),文件系统通过间接块中的块号,可定位到文件的数据块。
一级间接块存储的核心逻辑:
-
文件系统分配一个空闲块作为一级间接块,将该块的块号存储在inode的
i_block[12]中。 -
将文件超出直接块容量的部分,存储在多个数据块中,将这些数据块的块号,依次写入一级间接块中(每个块号占用4字节)。
-
读取文件时,文件系统先通过i_block12找到一级间接块,读取间接块中的数据块块号,再通过这些块号定位到数据块,读取文件内容。
一级间接块存储的容量计算(块大小4KB):
-
一级间接块可存储的块号数量 = 4KB ÷ 4字节/个 = 1024个。
-
一级间接块可存储的文件容量 = 1024 × 4KB = 4096KB = 4MB。
-
直接块 + 一级间接块的总容量 = 48KB + 4MB = 4144KB ≈ 4.05MB。
一级间接块存储的特点:
-
访问效率略低:相比直接块存储,多了一次间接查找(先找间接块,再找数据块),磁头需要多移动一次,访问时间略有增加。
-
存储容量提升:可存储比直接块大得多的文件,满足中等大小文件的存储需求(如小型文档、图片等)。
-
空间开销:需要额外占用一个块作为一级间接块,即使间接块中仅存储少量块号,也会占用一个完整的块------这是间接存储的空间开销。
2.3.3 二级间接块存储(Double Indirect Blocks)
当文件大小超过直接块 + 一级间接块的总容量(约4.05MB,块大小4KB)时,Ext2文件系统会使用二级间接块存储------inode的i_block数组第14个指针(i_block13)为二级间接块指针,该指针指向一个"二级间接块",二级间接块中存储的是多个一级间接块的块号,每个一级间接块中再存储多个数据块的块号,通过两层间接查找,定位到文件的数据块。
二级间接块存储的核心逻辑:
-
文件系统分配一个空闲块作为二级间接块,将该块的块号存储在inode的i_block13中。
-
分配多个空闲块作为一级间接块,将这些一级间接块的块号,依次写入二级间接块中。
-
将文件超出直接块 + 一级间接块容量的部分,存储在多个数据块中,将这些数据块的块号,依次写入各个一级间接块中。
-
读取文件时,文件系统先通过i_block13找到二级间接块,读取一级间接块的块号;再通过一级间接块的块号,找到一级间接块,读取数据块的块号;最后通过数据块的块号,定位到数据块,读取文件内容。
二级间接块存储的容量计算(块大小4KB):
-
二级间接块可存储的一级间接块块号数量 = 4KB ÷ 4字节/个 = 1024个。
-
每个一级间接块可存储1024个数据块块号,因此二级间接块可存储的数据块总数 = 1024 × 1024 = 1048576个。
-
二级间接块可存储的文件容量 = 1048576 × 4KB = 4194304KB = 4096MB = 4GB。
-
直接块 + 一级间接块 + 二级间接块的总容量 = 48KB + 4MB + 4GB ≈ 4.004GB。
二级间接块存储的特点:
-
访问效率较低:需要两次间接查找(二级间接块→一级间接块→数据块),磁头移动次数增加,访问时间进一步延长。
-
存储容量大幅提升:可存储GB级别的大文件,满足大多数应用场景的需求(如大型文档、视频、压缩包等)。
-
空间开销增加:需要额外占用一个二级间接块和多个一级间接块,空间开销比一级间接块存储更大。
2.3.4 三级间接块存储(Triple Indirect Blocks)
当文件大小超过直接块 + 一级间接块 + 二级间接块的总容量(约4.004GB,块大小4KB)时,Ext2文件系统会使用三级间接块存储------inode的i_block数组第15个指针(i_block14)为三级间接块指针,该指针指向一个"三级间接块",三级间接块中存储的是多个二级间接块的块号,每个二级间接块中存储多个一级间接块的块号,每个一级间接块中再存储多个数据块的块号,通过三层间接查找,定位到文件的数据块。
三级间接块存储的核心逻辑:
-
文件系统分配一个空闲块作为三级间接块,将该块的块号存储在inode的i_block14中。
-
分配多个空闲块作为二级间接块,将这些二级间接块的块号,依次写入三级间接块中。
-
分配多个空闲块作为一级间接块,将这些一级间接块的块号,依次写入各个二级间接块中。
-
将文件超出直接块 + 一级间接块 + 二级间接块容量的部分,存储在多个数据块中,将这些数据块的块号,依次写入各个一级间接块中。
-
读取文件时,文件系统需经过三次间接查找(三级间接块→二级间接块→一级间接块→数据块),才能定位到数据块,读取文件内容。
三级间接块存储的容量计算(块大小4KB):
-
三级间接块可存储的二级间接块块号数量 = 4KB ÷ 4字节/个 = 1024个。
-
每个二级间接块可存储1024个一级间接块块号,每个一级间接块可存储1024个数据块块号,因此三级间接块可存储的数据块总数 = 1024 × 1024 × 1024 = 1073741824个。
-
三级间接块可存储的文件容量 = 1073741824 × 4KB = 4294967296KB = 4194304MB = 4096GB = 4TB。
-
Ext2文件系统支持的最大文件容量(块大小4KB) = 直接块 + 一级间接块 + 二级间接块 + 三级间接块 = 48KB + 4MB + 4GB + 4TB ≈ 4.004TB。
三级间接块存储的特点:
-
访问效率最低: 需要三次间接查找,磁头移动次数最多,访问时间最长------因此,大文件的读写速度远低于小文件。
-
存储容量极大: 可存储TB级别的超大文件,满足大型应用的存储需求(如数据库文件、大型视频文件、磁盘镜像等)。
-
空间开销最大: 需要额外占用一个三级间接块、多个二级间接块和一级间接块,空间开销显著增加------但对于超大文件而言,这种空间开销是可接受的。
补充说明: Ext2文件系统的最大文件容量与块大小直接相关,块大小越大,支持的最大文件容量越大------例如,块大小为8KB时,三级间接块可存储的最大文件容量为16TB,可满足更大容量文件的存储需求。但块大小越大,小文件的空间浪费越严重(如1字节的小文件,也会占用一个8KB的块),因此块大小的选择需平衡空间利用率和文件容量需求。
2.4 目录与文件名的实现机制
前文已提及,Ext2文件系统的inode不存储文件名,文件名的存储与管理由目录文件负责------目录文件本质上是一种特殊的文件,其inode的i_mode字段标记为目录类型(0x4),其数据块中存储的是该目录下所有文件(包括子目录)的目录项(directory entry),每个目录项记录了文件名与对应的inode号,以及目录项的相关属性,从而实现文件名到inode的映射,进而关联到文件的属性和数据。
2.4.1 目录项的结构(ext2_dir_entry)
Ext2文件系统的目录项由C语言结构体ext2_dir_entry定义(内核源码中),每个目录项的大小不固定(根据文件名长度动态调整),核心字段用于记录文件名、inode号和目录项信息,具体结构如下(简化版):
c
struct ext2_dir_entry {
__le32 inode; /* 目录项对应的文件/目录的inode号 */
__le16 rec_len; /* 目录项的总长度(字节),用于定位下一个目录项 */
__le8 name_len; /* 文件名的长度(字节),不包括结束符 */
__le8 file_type; /* 文件类型(与inode的i_mode高4位一致) */
char name[EXT2_NAME_LEN]; /* 文件名(最大长度255字节) */
};
/* 文件类型定义(file_type字段的值) */
#define EXT2_FT_UNKNOWN 0 /* 未知类型 */
#define EXT2_FT_REG_FILE 1 /* 普通文件 */
#define EXT2_FT_DIR 2 /* 目录文件 */
#define EXT2_FT_SYMLINK 7 /* 符号链接文件 */
#define EXT2_FT_BLKDEV 8 /* 块设备文件 */
#define EXT2_FT_CHRDEV 9 /* 字符设备文件 */
#define EXT2_FT_FIFO 10 /* 管道文件 */
#define EXT2_FT_SOCK 11 /* 套接字文件 */
/* 文件名最大长度 */
#define EXT2_NAME_LEN 255目录项核心字段解读:
-
inode:核心字段,存储该目录项对应的文件或目录的inode号------通过该inode号,文件系统可定位到对应的inode,进而访问文件的属性和数据。例如:目录项中inode号为100,对应分区内的inode 100,文件系统通过inode 100可找到该文件的数据块,读取文件内容。 -
rec_len:目录项的总长度(字节),包括该目录项的所有字段(inode、rec_len、name_len、file_type、name),用于定位下一个目录项------由于文件名长度不同,目录项的长度也不同,通过rec_len字段,文件系统可从当前目录项的起始位置,跳过当前目录项,找到下一个目录项的起始位置(当前目录项起始地址 + rec_len = 下一个目录项起始地址)。 -
name_len:文件名的实际长度(字节),不包括字符串结束符('\0')------例如:文件名为"test.txt",长度为8字节,name_len字段的值为8,name数组中仅存储前8个字符,剩余空间填充为0(不占用实际存储,仅用于对齐)。 -
file_type:文件类型,与inode的i_mode字段高4位的值一致------文件系统可通过该字段快速判断文件类型,无需访问inode,提升效率。例如:file_type为2,表示该目录项对应一个目录文件;file_type为1,表示对应一个普通文件。 -
name:存储文件名的字符数组,最大长度为255字节(EXT2_NAME_LEN定义)------Ext2文件系统支持的最大文件名长度为255字节,超过该长度的文件名无法创建。
2.4.2 目录文件的组织结构
每个目录文件(包括根目录)的数据块中,存储着多个目录项,这些目录项按顺序排列,通过rec_len字段相互关联,形成一个链表结构------目录文件的第一个目录项和第二个目录项是固定的,分别为"."(当前目录)和"..."(父目录),其余目录项为该目录下的文件和子目录。
目录文件的固定目录项:
-
"
."(当前目录):目录项的inode号等于当前目录文件的inode号------通过该目录项,可访问当前目录的属性(如目录的所有者、权限、创建时间等)。例如:当前目录的inode号为2,那么"."目录项的inode字段的值为2。 -
"
.."(父目录,上级目录):目录项的inode号等于当前目录的父目录的inode号------通过该目录项,可访问父目录的内容,实现目录的层级导航。例如:根目录(/)的父目录是其自身,因此根目录中"..."目录项的inode号等于根目录的inode号(通常为2);/home目录的父目录是/目录,因此/home目录中"..."目录项的inode号等于/目录的inode号(2)。
目录文件的组织结构示例(以/root目录为例):
-
/root目录的inode号为100,其数据块中存储的目录项依次为:
目录项1:name=".",inode=100(当前目录,/root),file_type=2(目录)。
-
目录项2:name="...",inode=2(父目录,/),file_type=2(目录)。
-
目录项3:name="test.txt",inode=101(普通文件),file_type=1(普通文件)。
-
目录项4:name="docs",inode=102(子目录),file_type=2(目录)。
-
当用户访问/root/test.txt文件时,文件系统的查找流程为:
先找到根目录(/)的inode(inode号2),访问根目录的数据块,找到name="root"的目录项,获取其inode号100。
-
通过inode号100,找到/root目录的inode,访问其数据块,找到name="test.txt"的目录项,获取其inode号101。
-
通过inode号101,找到test.txt文件的inode,访问其数据块,读取文件内容。
2.4.3 文件名的查找流程
用户在Linux系统中输入一个路径(如/root/docs/report.pdf)时,文件系统需要通过多次目录查找,找到对应的inode,进而访问文件内容------这个过程本质上是遍历路径中的每个目录,查找对应的目录项,获取inode号,逐步定位到目标文件,具体流程如下(以/root/docs/report.pdf为例):
-
定位根目录(/):根目录的inode号是固定的(通常为2),文件系统直接通过inode号2,找到根目录的inode,访问其数据块。
-
查找"root"目录:在根目录的数据块中,遍历所有目录项,查找name="root"的目录项,获取该目录项的inode号(假设为100)。
-
定位"root"目录:通过inode号100,找到/root目录的inode,访问其数据块。
-
查找"docs"目录:在/root目录的数据块中,遍历所有目录项,查找name="docs"的目录项,获取该目录项的inode号(假设为102)。
-
定位"docs"目录:通过inode号102,找到/root/docs目录的inode,访问其数据块。
-
查找"report.pdf"文件:在/root/docs目录的数据块中,遍历所有目录项,查找name="report.pdf"的目录项,获取该目录项的inode号(假设为103)。
-
定位目标文件:通过inode号103,找到report.pdf文件的inode,访问其数据块,读取文件内容,完成查找。
查找流程的优化:
上述查找流程需要多次遍历目录项,若目录下的文件数量较多(如成千上万个子文件),遍历目录项的效率会很低------为了解决这个问题,Ext2文件系统支持"目录哈希表"(可选功能),将目录项按文件名的哈希值存储,查找时通过文件名的哈希值,可快速定位到对应的目录项,无需遍历所有目录项,大幅提升查找效率。此外,Linux内核还会缓存常用目录的目录项,减少磁盘访问次数,进一步优化查找速度。
2.4.4 文件名的修改与删除机制
由于文件名存储在目录项中,而非inode中,因此文件名的修改和删除,本质上是修改或删除目录文件中的目录项,不影响inode和文件的数据块------这是Ext系列文件系统的关键特性,也是软硬链接实现的基础。
2.4.4.1 文件名的修改
修改文件名时,文件系统无需修改目标文件的inode(inode号、属性、数据块地址等均不变),仅需找到该文件对应的目录项,修改目录项中的name字段(文件名)和name_len字段(文件名长度),同时调整目录项的rec_len字段(若文件名长度变化,目录项长度也需调整)------整个过程仅修改目录文件的数据块,效率极高。
示例:将/root/test.txt文件重命名为/root/test_new.txt,文件系统的操作流程为:
找到/root目录的数据块,遍历目录项,找到name="test.txt"的目录项(inode号101)。将该目录项的name字段改为"test_new.txt",name_len字段改为12("test_new.txt"的长度为12)。调整该目录项的rec_len字段(若文件名长度增加,rec_len字段需增大,占用更多空间;若长度减少,rec_len字段可减小,释放多余空间)。修改完成,文件的inode号(101)、属性、数据块均不变,仅文件名发生变化。
2.4.4.2 文件名的删除
删除文件名时,文件系统同样无需删除目标文件的inode和数据块,仅需找到该文件对应的目录项,将其标记为"空闲",并将该目录项的空间释放给其他目录项使用------具体操作分为两种情况:
-
情况一:文件的硬链接数大于1: 删除目录项后,将该文件的inode中的i_links_count字段减1(硬链接数减1),由于硬链接数仍大于0,文件的inode和数据块不会被释放,其他硬链接仍可通过对应的目录项访问该文件。
-
情况二:文件的硬链接数等于1: 删除目录项后,将该文件的inode中的i_links_count字段减至0,此时文件系统会标记该inode为空闲(修改inode位图),并释放该inode指向的数据块(修改块位图),文件的内容才会真正被删除。
补充说明:删除文件名后,若文件的inode和数据块未被释放(硬链接数大于0),即使原目录项已被删除,仍可通过其他硬链接的目录项访问文件;若文件的inode和数据块已被释放,即使目录项未被彻底清除,也无法恢复文件内容------因为数据块可能已被其他文件覆盖。
2.4.5 目录与文件名的限制
Ext2文件系统对目录和文件名有明确的限制,这些限制由文件系统的设计决定,具体如下:
-
文件名长度限制: 最大文件名长度为255字节(EXT2_NAME_LEN定义),超过该长度的文件名无法创建------这是因为目录项的name数组最大长度为255字节,无法存储更长的文件名。需要注意的是,这里的长度是字节数,而非字符数,对于中文文件名(每个中文占用3字节UTF-8编码),最大可存储85个中文(255 ÷ 3 = 85)。
-
目录层级限制: Ext2文件系统对目录的层级没有明确的硬限制,但实际使用中,目录层级不宜过深(建议不超过10层)------因为目录层级越深,文件名的查找流程越长(需要遍历更多目录),访问效率越低;同时,过深的目录层级也会增加管理难度。
-
文件名字符限制: 文件名可包含除"/"和"\0"以外的所有字符------"/"用于分隔目录和文件名,是路径的分隔符,无法作为文件名的一部分;"\0"是字符串结束符,用于标识文件名的结束,也无法作为文件名的一部分。此外,建议避免使用特殊字符(如*、?、<、>等)作为文件名,以免影响命令行操作。
-
目录下文件数量限制: 一个目录下的最大文件数量(包括子目录)由该目录的数据块大小和目录项大小决定------例如,块大小为4KB,每个目录项平均大小为32字节(文件名长度16字节),则一个数据块可存储128个目录项;若目录有多个数据块,可存储更多文件。但实际使用中,一个目录下的文件数量不宜过多(建议不超过1000个),否则会导致目录项查找效率过低。
2.4.6 路径解析
问题:打开当前工作目录文件,查看当前工作目录文件的内容?当前工作目录不也是文件吗?我们访问当前工作目录不也是只知道当前工作目录的文件名吗?要访问它,不也得知道当前工作目录的inode吗?
实际上,任何文件,都有路径。访问目标文件,比如:/home/whb/code/test/test/test.c,都要从根目录开始,依次打开每一个目录,根据目录名,依次访问每个目录下指定的目录,直到访问到test.c。这个过程叫做Linux路径解析。
注意:
- 所以,我们知道了:访问文件必须要有目录 + 文件名 = 路径的原因,
- 根目录固定文件名,inode号,无需查找,系统开机之后就必须知道
2.4.7 路径缓存
Linux中,在内核中维护树状路径结构的内核结构体叫做:struct dentry。
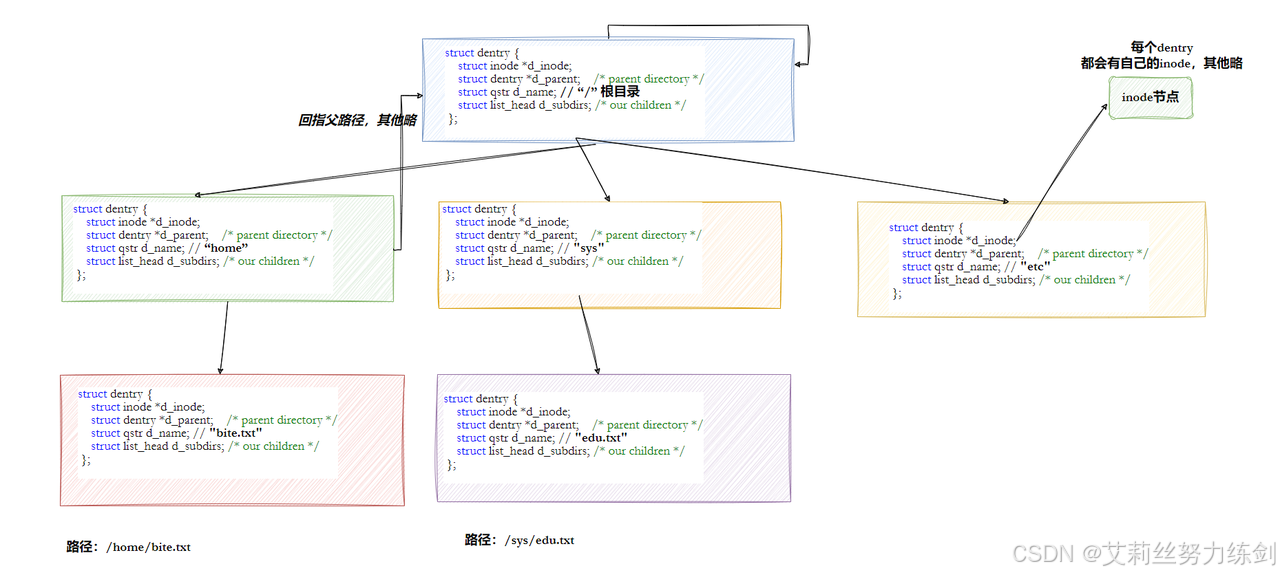
2.4.8 挂载分区
分区写入文件系统,无法直接使用,需要和指定的目录关联(把指定的分区和Linux中的指定目录关联起来),进行挂载才能使用 ,所以,可以根据访问目标文件的 "路径前缀" 准确判断我在哪一个分区,理解到这个层面就行啦。
2.4.9 ACM时间(时间戳)
时间戳这个功能我们早在《【Linux指令 (三)】从理解到熟悉:探索Linux底层逻辑与指令的高效之道,理解Linux系统理论核心概念与基础指令》一文中就点过了,这里不再赘述。
下面解释一下文件的三个时间(ACM):
Access:最后访问时间Modify:文件内容最后修改时间Change:属性最后修改时间
2.5 文件系统总结(四张图搞定)
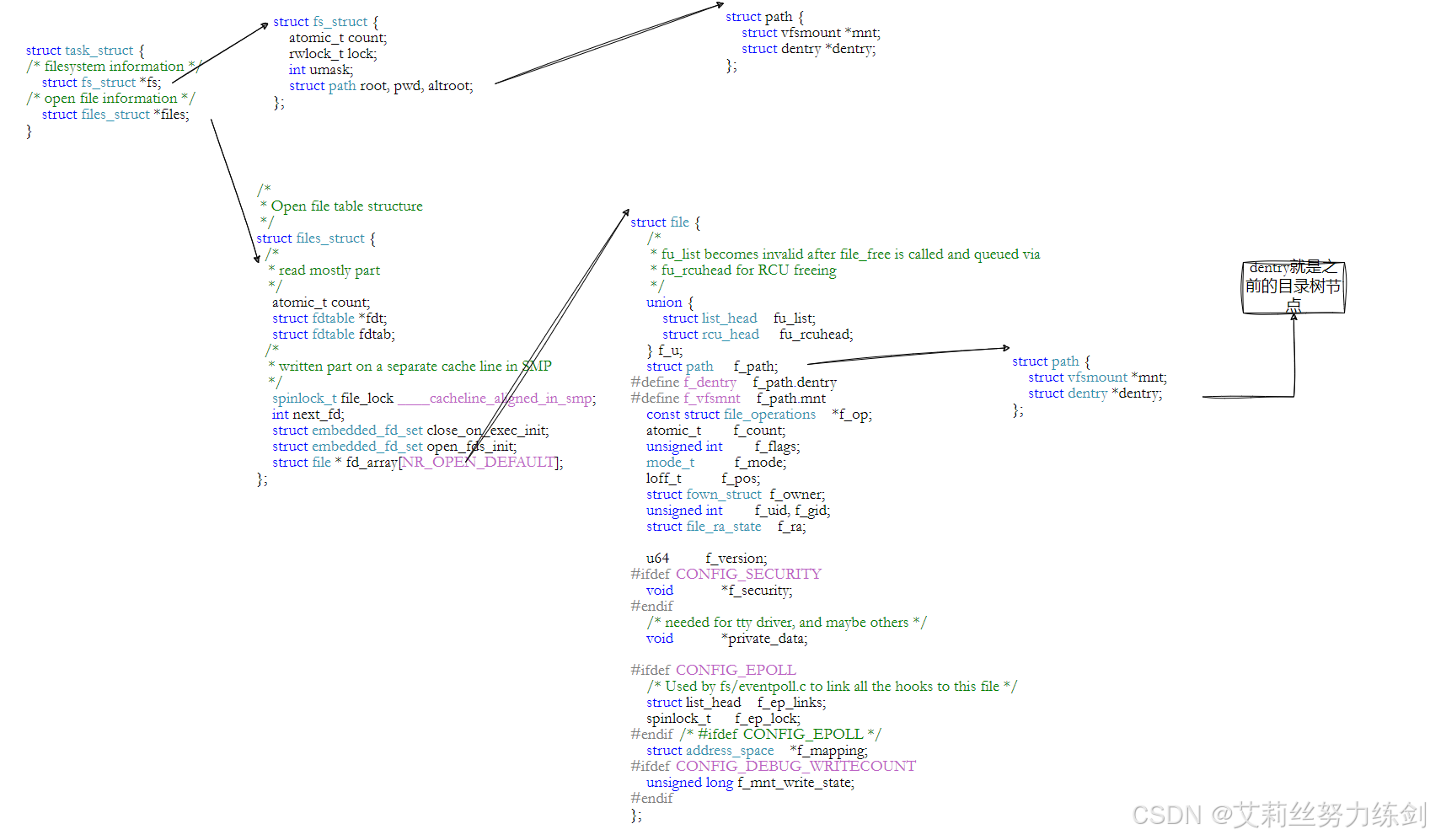
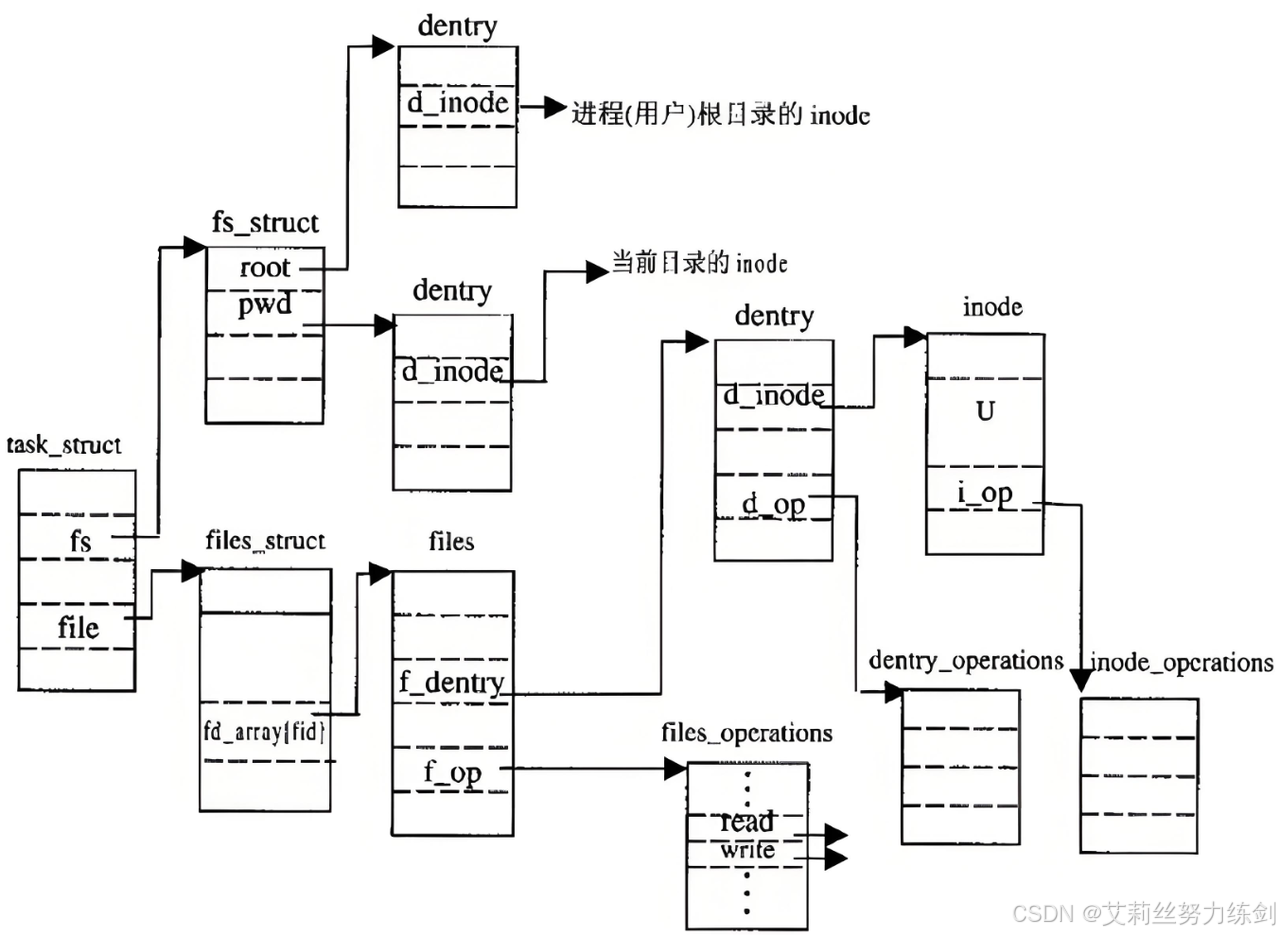
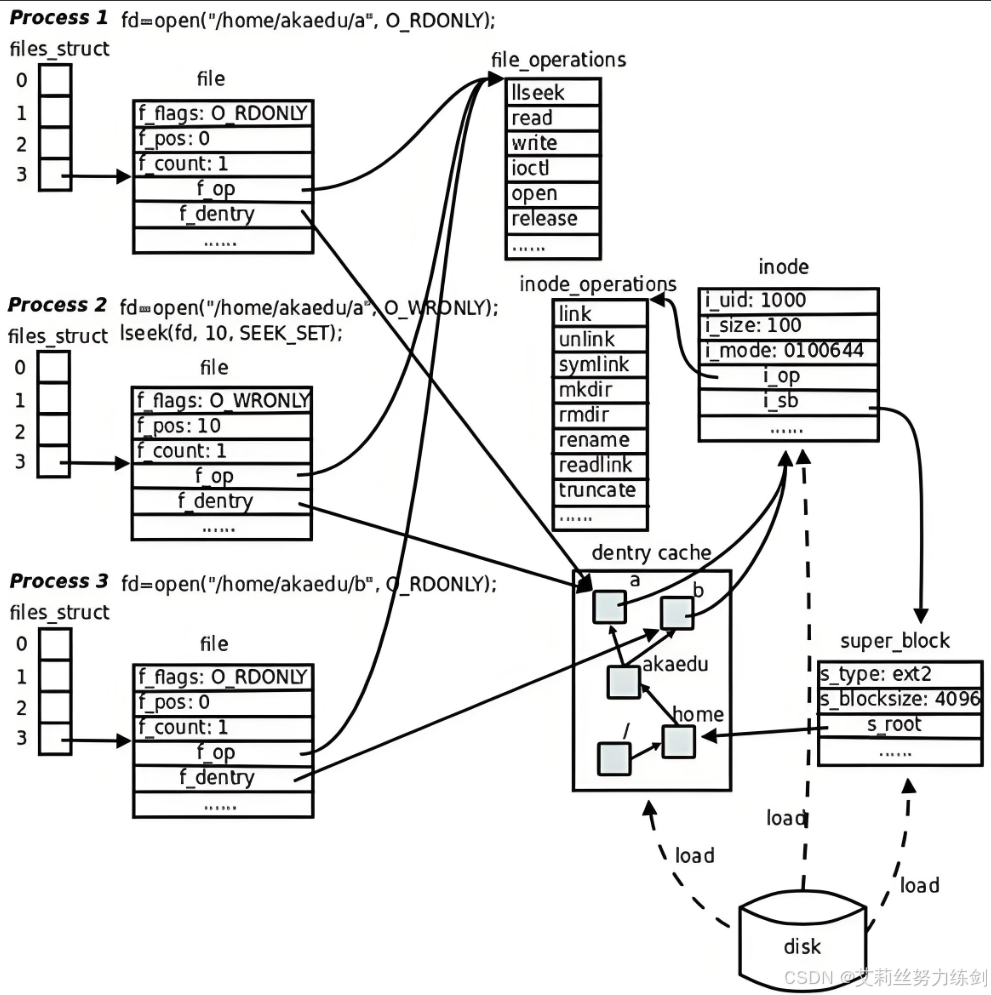
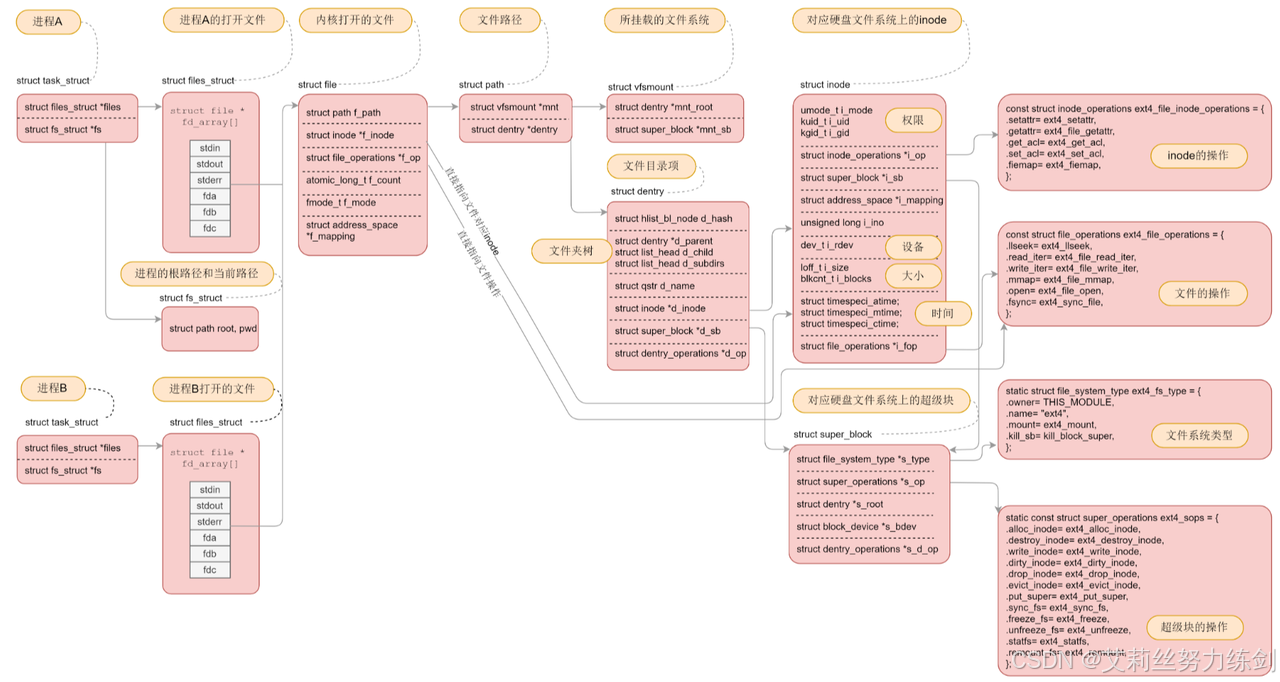
3 ~> 面试必考题:软硬链接
3.1 硬连接
3.1.1 最佳实践
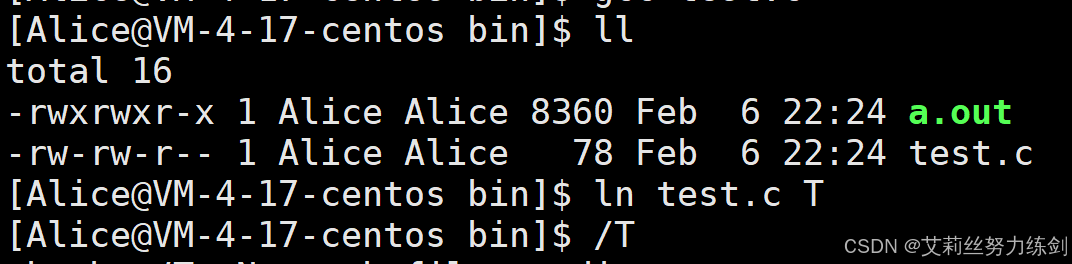
我们知道,真正找到磁盘上文件的并不是文件名,而是inode。其实在linux中可以让多个文件名对应于同一个inode:
bash
[root@localhost linux]# touch abc
[root@localhost linux]# ln abc def
[root@localhost linux]# ls -li abc def
263466 abc
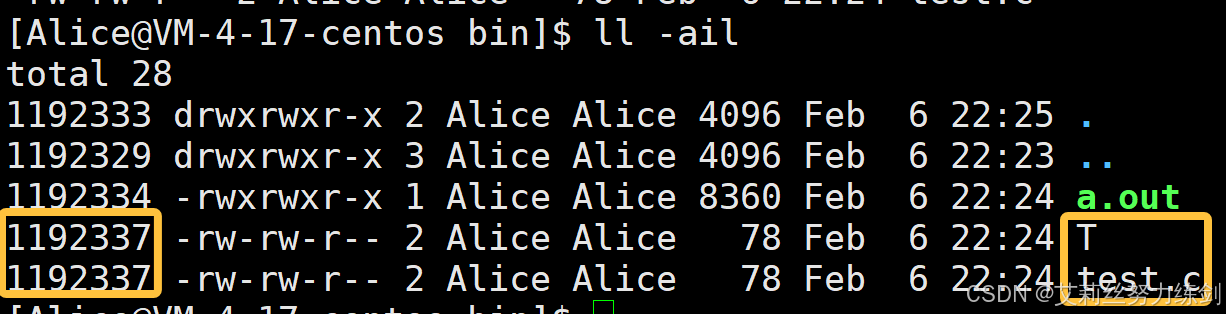
263466 def- abc和def的链接状态完全相同(inode完全一样,是同一个文件的不同别名),他们被称为指向文件的硬链接。内核记录了这个连接数,inode263466的硬连接数为2。
3.1.2 硬链接数
硬链接数这个话题我们在Linux指令那里没有谈,权限那里没有谈,到了文件这里我们终于明白了:哦!这个是硬链接数!因为硬链接可以理解为同一个文件的不同别名,那么这个硬链接数就很像是C++智能指针(像shared_ptr)那里学过的引用计数 !所以如下图,艾莉丝把T------test.c的别名------删除,硬链接数就-1,其实就是引用计数------inode一样,看有多少个指针指向这个文件,这里是两个,test.c和T。
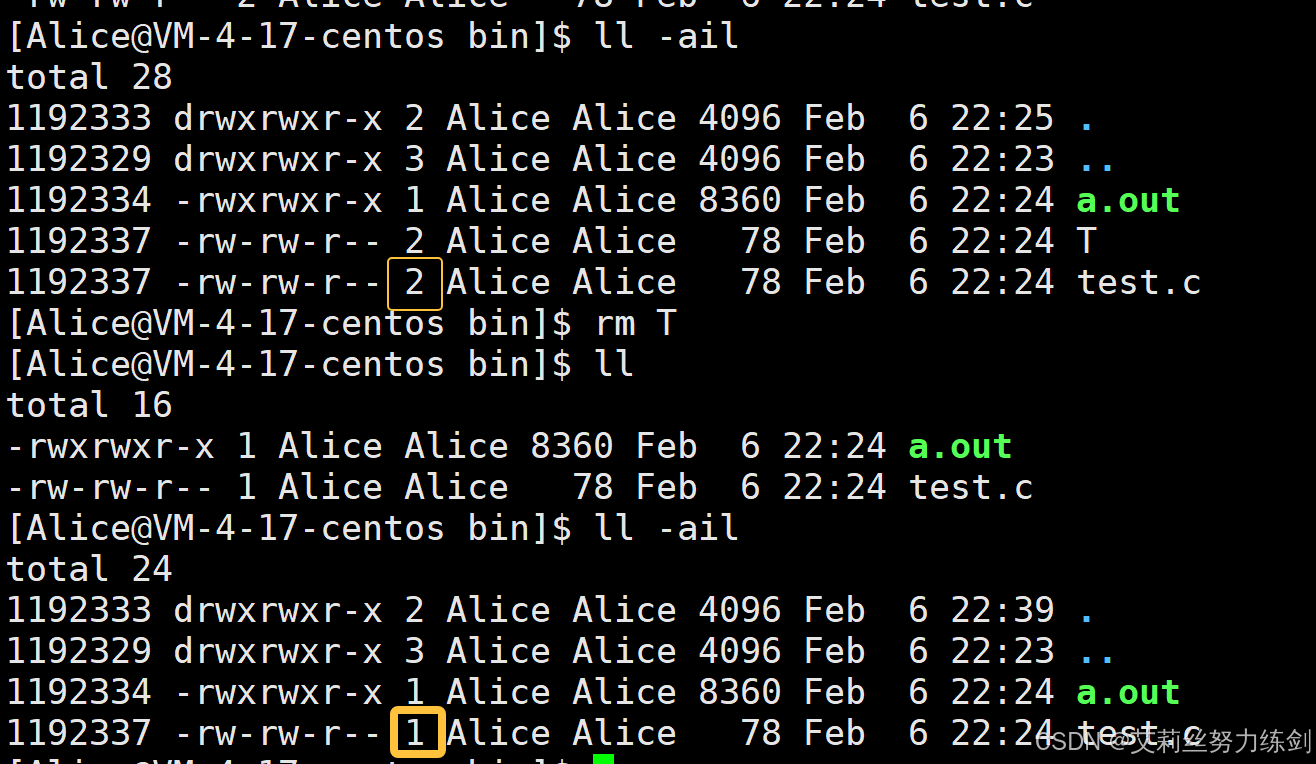
- 我们在删除文件时干了两件事情:(1)在目录中将对应的记录删除;(2)将硬连接数 - 1,文件删除一个,引用计数还在,如果为0,则将对应的磁盘释放。
3.1.3 查看/(根目录)有几个目录?
目录数量 = 硬链接数 - 2(减掉的一个是当前路径". ",还有一个根目录自己的目录名"/")

3.2 软链接
硬链接是通过inode引用另外一 个文件,软链接是通过名字引用另外一个文件,但实际上,新的文件和被引用的文件的inode不同,应用常见上可以想象成一个快捷方式。在shell中的做法是这样的:
bash
[root@localhost linux]# ln -s abc.s abc
[root@localhost linux]# ls -li
263563 -rw-r--r--. 2 root root 0 9⽉ 15 17:45 abc
261678 lrwxrwxrwx. 1 root root 3 9⽉ 15 17:53 abc.s -> abc
263563 -rw-r--r--. 2 root root 0 9⽉ 15 17:45 def
3.3 软硬连接对比
-
软连接是独立的文件(快捷方式)
-
硬链接只是文件名和目标文件
inode的映射关系(别名)
3.4 软硬连接的作用
3.4.1 硬链接
.和..就是硬链接,映射目标目录- 文件备份
3.4.2 软连接
- 类似Windows创建的快捷方式,普通的用户不懂什么目录、什么文件系统,问软连接有什么用就是在问创建快捷方式有什么用------为了快速查找!
4 ~> 声明与预告
非常抱歉,uu们,时间匆忙,这篇博客有那么一点点水,像是将磁盘抽象化之后本该重点介绍的块、分区、inode、EXT2文件系统,像文件系统的这张图也没有介绍:
也没有拿出源码来看底层是怎么写的,为什么要有路径?目录是文件吗?路径解析、路径缓存都是怎么实现的?挂载虽然是运维要求的知识,但是我们学习开发知识的程序猿也要了解一下!很重要的面试题,软硬链接的实验也做得马马虎虎,还没有最佳实践。
因此,艾莉丝在发布这篇博客之后,1~2周内会重新更新文件IO、EXT系列文件系统的博客,敬请期待!是完全干货的博客呦!
本文代码演示
readdir.c
c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
// readdir mydir
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory>\n", argv[0]);
exit(EXIT_FAILURE);
}
DIR *dir = opendir(argv[1]); // 系统调用,自行查阅
if (!dir) {
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) { // 系统调用,自行查阅
// Skip the "." and ".." directory entries
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0) {
continue;
}
printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);
}
closedir(dir);
return 0;
}结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主"一键四连"哦!
往期回顾:
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა
