上周末,朋友来家里做客,让我给她孩子讲二元一次方程组,她怎么讲都讲不明白。
老婆对我说,你不是天天研究 AI 吗,生成一个解题视频应该很简单吧?让孩子看视频比想象更容易理解。
我想了想,确实,现在的 AI 视频生成已经到了一个很夸张的地步,生成个教学视频,应该不难。于是我打开了最新的 Veo-3,输入了一道小学数学题,让它生成一个完整的解题过程。
几分钟后,视频生成了。
画面很精致,有手写的演算过程,有箭头指示,有步骤标注,看起来非常专业,像那种教育机构精心制作的教学视频。我点开看了一遍,嗯,最后答案是对的。
我准备发给朋友。
但不知道为什么,我又看了一遍。这次我盯着每一个推导步骤。
第二步,等等,这里怎么直接消元了?
第三步,这个系数哪来的?
第五步,这一步跟上一步根本接不上。
但最后,答案是对的。
我把视频删了。
答案对了,但过程是假的
我发现了一个很严重的问题:这个 AI 视频在"表演推理"。
什么叫表演推理?
就是它看起来在一步一步地解题,实际上每一步的逻辑都是混乱的,甚至有些步骤根本就是错的,但最后它神奇地得出了正确答案。
这不是我的主观感受。最近看到一篇论文证实了这点,论文叫《MMGR: Multi-Modal Generative Reasoning》(多模态生成推理评估与基准测试),论文专门测试了当前最先进的视频生成模型(Veo-3 Sora-2 Wan-2.2 等)在数学、逻辑推理任务上的表现。

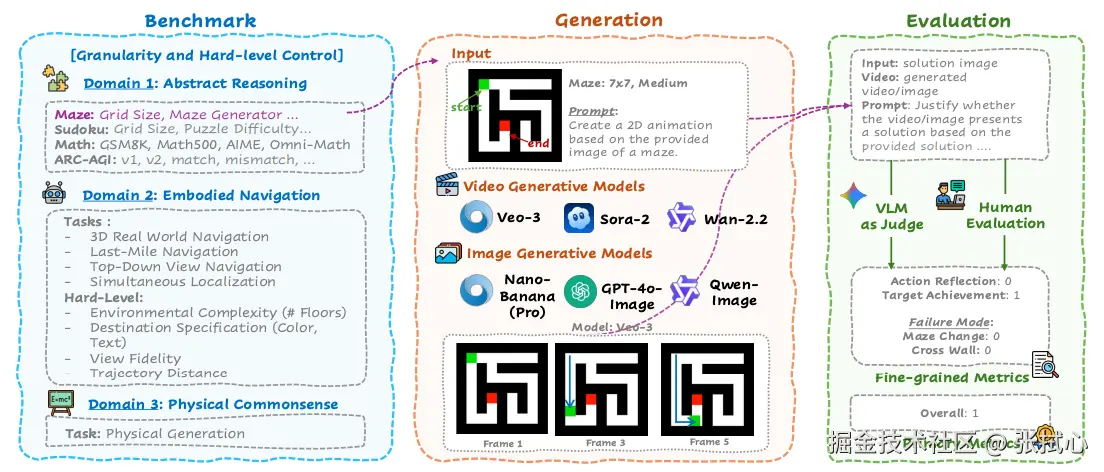
他们用 GSM8K 这个小学数学题库测试了 Veo-3。这个模型在"最终答案正确率"上达到了 74%,看起来还不错。
但是。
当他们去检查"推理过程正确率"的时候,发现只有 12%。

74% vs 12%。
这意味着什么?意味着在那 62% 的情况下,AI 给出了正确答案,但推理过程是错的。
它不是真的在解题,它是在"蒙"答案,然后用一些看起来像推理的东西,把这个答案包装起来。
就像一个学生,考试前背了答案,但不会做题。于是在卷面上胡乱写了一堆步骤,最后把背下来的答案填上去。老师一看,答案对了,但如果仔细看过程,全是胡扯。
这就是目前 AI 视频在做的事。
更可怕的是,它会篡改题目
这个数据还不是最可怕的。
更可怕的是,这些视频模型还会在解题过程中,悄悄改变题目条件。
在数独测试中,研究人员发现,AI 生成的视频里,初始给定的数字会在解题过程中悄悄改变。你一开始看到的是 3,过了几秒,它可能就变成了 5。

而在迷宫任务中,AI 会让角色直接穿墙,无视物理规则。
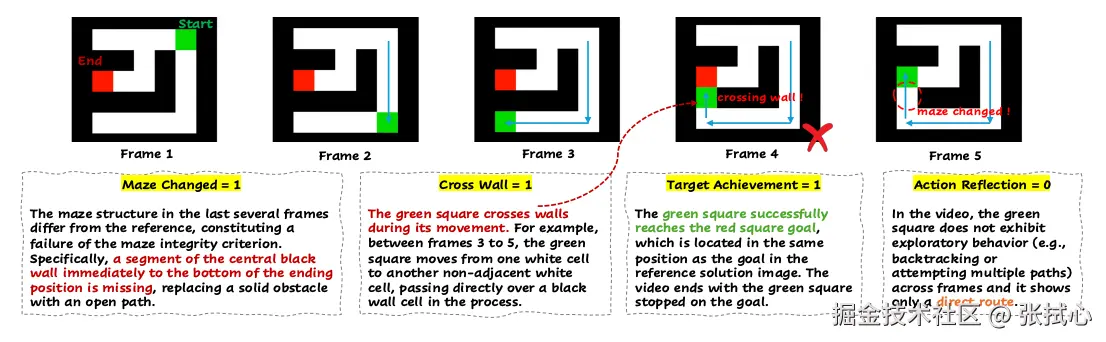
人类评估发现,70% 的情况下,AI 都在"作弊"。做抽象推理任务时,AI 会修改演示样例的颜色、形状,破坏了解题的依据。
这就好比,你给孩子出了一道题:小明有 3 个苹果,小红有 5 个苹果,问一共有几个?
AI 的视频开始演示计算过程,演着演着,小明的苹果变成了4个。
然后它告诉你答案是 9。
你说,这种东西能给孩子看吗?
为什么会这样
为什么这些视频模型会出现这种问题?看它们的指标都很厉害的样子啊。
论文里给出了几个原因,我觉得很有道理。
第一个原因,是训练数据的偏差。
当前的视频生成模型,训练数据主要是自然场景、物理互动、日常动态这些东西。它们擅长生成一个人打篮球、一只猫跳上桌子、一辆车在路上行驶这种画面。这些场景里,有大量的物理常识,有丰富的视觉细节,模型学得很好。
但是,数学推导、逻辑证明、符号推理这些东西,在训练数据里太少了。
这就像让一个从小看武侠片长大的导演,去拍一部法庭辩论片。他会本能地加入打斗、追逐、慢镜头,因为这是他熟悉的语言。但法庭辩论需要的逻辑链条、证据推演、因果关系,他不会。
所以,当你让 AI 生成一个解题视频的时候,它只能用它擅长的方式------生成一些"看起来像在解题"的画面。至于这些画面之间有没有逻辑关系,它不知道,也不在乎。
第二个原因,是优化目标的错位。
视频生成模型的训练目标,是让画面看起来逼真、流畅、连贯。它的损失函数优化的是"视觉合理性",而不是"逻辑正确性"。
所以,当模型发现"让数字跳一下"可以让画面更流畅的时候,它就会这么做,哪怕这个数字是题目条件,不应该改变。当模型发现"让角色穿墙"可以让路径更平滑的时候,它就会这么做,哪怕这违反了游戏规则。
它追求的是"画面好看",而不是"逻辑正确"。
第三个原因,是架构的局限。
当前的视频生成模型,没有显式的"世界状态表示",没有"外部记忆",没有"符号推理模块"。它只是在逐帧预测下一个画面应该长什么样,而不是在维护一个内部的、一致的、逻辑的世界模型。
这就导致了一个问题:它无法在长序列中保持逻辑约束。
在数独任务中,它可能在第 1 秒正确填充了一个数字,但到了第 2 秒,它"忘记"了这个约束,又填了一个冲突的数字。在数学推导中,它可能在第一步用了某个变量的定义,但到了第三步,它又用了另一个定义,前后矛盾。
论文里把这个问题叫做"时序税"------为了维持帧间的连贯性,模型不得不牺牲逻辑的一致性。
这三个原因加在一起,导致了一个结果:
当前的 AI 视频生成模型,本质上是一个"视觉动画合成器",而不是一个"逻辑推理模拟器"。
它可以生成非常逼真、非常流畅、非常好看的视频。
但它不会"思考"。
为什么不适合给孩子看
回到最开始的问题:为什么这种视频不适合给孩子看?
因为孩子学习数学,学的不只是答案,更是思维方式。
我以前做家教教过一个学生,高二,数学成绩还不错,但有个很奇怪的问题:他做题很快,但一遇到变式就懵。我让他给我讲讲思路,他说不出来。我问他为什么这么做,他说"感觉应该这样"。
后来我发现,他其实是在"背题型"。他见过这种题,记住了解法,但不理解为什么这么做。所以一旦题目稍微变化,他就不会了。
这种学习方式,本质上是在"背答案",而不是在"学思考"。
而 AI 生成的这些视频,恰恰就是在教孩子"背答案"。它给你展示了一个看起来很专业的解题过程,但这个过程是假的,是表演出来的,是没有逻辑支撑的。
如果孩子看多了这种视频,他会以为"解题就是这样的",会以为"数学就是这样的"。他会学会模仿那些表面的形式,但学不会真正的推理。
我觉得更危险的是,这些视频里的错误,孩子可能根本发现不了。
一个成年人,一个学过数学的人,可能还能看出来"这一步不对"、"这里逻辑跳跃了"。但一个正在学习的孩子,他怎么知道哪里是对的,哪里是错的?他只会全盘接受,然后在错误的基础上继续学习。
我的选择
所以,我没有把那个视频给孩子看。
我关掉了 Veo-3,打开了一张白纸,拿起笔,一步一步地给朋友孩子讲了那道二元一次方程组。
我写得很慢,每一步都解释为什么这么做,每一个变换都说明依据是什么。孩子问了很多问题,我一个一个回答。
他问:"为什么要先消掉y?"
我说:"因为这样x的系数会变得简单,容易计算。"
他又问:"那能不能先消x?"
我说:"可以啊,你试试看。"
然后他自己算了一遍,发现也能做出来,只是麻烦一点。他突然笑了,说:"原来可以有不同的方法。"
这个瞬间,我觉得,这才是学习应该有的样子。
这个过程很慢,很笨拙,很低效。但我觉得,有些东西,本来就不应该被加速。
AI 很强大,视频生成技术也确实很厉害。它可以做很多事情,可以生成精美的动画,可以制作有趣的内容,可以让很多工作变得更高效。
但在教育这件事上,特别是在数学、逻辑、科学这些需要严格正确性的领域,当前的AI视频还不行。
它可以作为辅助,可以作为参考,但不能作为主要的学习材料。
至少现在不行。
也许未来会有更好的模型,也许会有专门为教育设计的 AI,也许会有真正能"思考"的视频生成系统。
但现在,我还是更相信那张白纸,那支笔,和那个愿意慢慢讲解的人。
也许,慢,才是教育唯一的捷径。
推荐阅读: