使用数据库存储结构化数据时,一个比较头疼的问题是对于比较复杂的嵌套型结构化数据,需要拆表,关联,存储起来十分麻烦,特别是对于归档类数据,无形中增加了许多工作量。pgsql在其本身提供了丰富数据类型的基础上,还支持用户自定义类型,一个字,香!

我要存储的是一个包含结构体数组的的结构体:
cpp
typedef struct _k4abt_joint_t
{
k4a_float3_t position;
k4a_quaternion_t orientation;
k4abt_joint_confidence_level_t confidence_level;
} k4abt_joint_t;
typedef struct _k4abt_skeleton_t
{
k4abt_joint_t joints[K4ABT_JOINT_COUNT];
} k4abt_skeleton_t;k4a_float3_t 和 k4a_quaternion_t 都是联合类型,分别代表坐标和旋转四元数,本质上就是一个长度为3和4的浮点数组。k4abt_joint_confidence_level_t 是一个枚举类型,可以直接用 int 存储。
下面我们来看如何在 pgsql 中创建自定义复合类型来简化存储。
首先我们要创建 k4abt_joint_t 结构体的类型。打开pgAdmin 4,我们在 数据库→Schemes→public→Types 路径下右键 Types,选择 Create →Type... 。
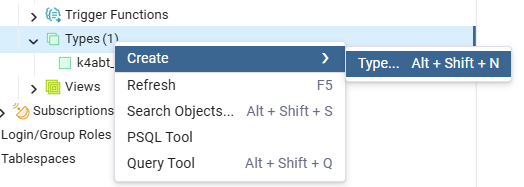
在创建类型窗口中,在 General 选项卡中输入类型名称和注释(可选),然后选择 Definition 选项卡,添加3个字段。
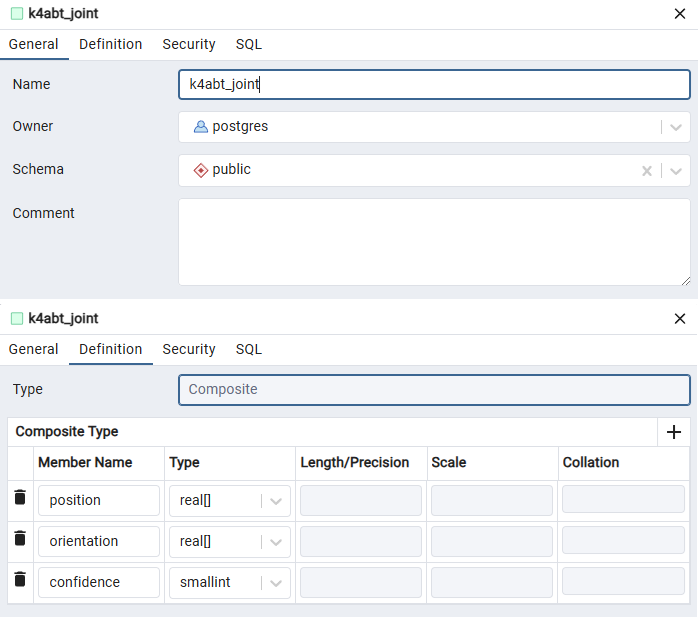
对于 position 和 orientation 字段我们直接使用 real[] 数组来存储,pgsql 的 real 类型就是 c++ 中的 float 类型,4字节的单精度浮点数。对应的 sql 代码如下:
sql
CREATE TYPE public.k4abt_joint AS
(
"position" real[],
orientation real[],
confidence smallint
);接下来,建表。
在 数据库→Schemes→public→Tables 路径下右键 Tables,选择 Create→Table... 。

首先还是在 General 中输入表名和注释(可选),然后在 Columns 选项卡中添加字段。
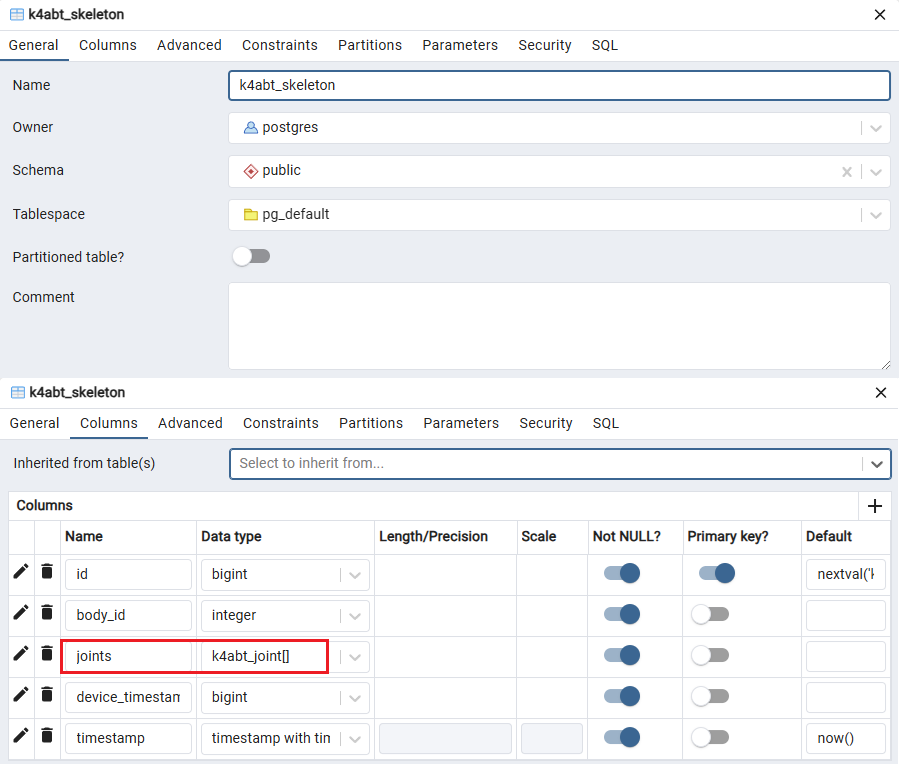
注意 joints 字段,这就是我们要存储的结构体数组,我们用一个字段就把他存储下来了。我们创建了 k4abt_joint 类型,自动就有了它的数组类型 k4abt_joint[] 。建表 sql 代码如下:
sql
CREATE TABLE IF NOT EXISTS public.k4abt_skeleton
(
id bigint NOT NULL DEFAULT nextval('k4abt_skeleton_id_seq'::regclass),
body_id integer NOT NULL,
joints k4abt_joint[] NOT NULL,
device_timestamp bigint NOT NULL,
"timestamp" timestamp with time zone NOT NULL DEFAULT now(),
CONSTRAINT k4abt_skeleton_pkey PRIMARY KEY (id)
)注意到 id 的默认值 nextval('k4abt_skeleton_id_seq'),pgsql 自增主键使用的是 Sequences。建表的时候主键我选的是 bigint 类型,而不是 serial 类型,导致我的主键不会自增,所以后面又手动创建了 Sequence 并给主键添加了默认值。
创建 Sequence 流程也类似,找到 数据库→Schemes→public→Sequences 路径下右键 Sequences,选择 Create→Sequence... 。

然后填写名称,增量,最大最小值等信息。
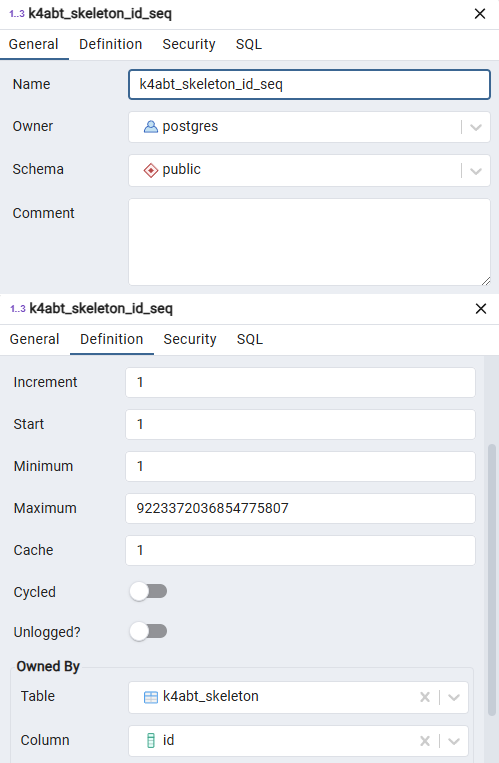
sql 代码如下:
sql
CREATE SEQUENCE IF NOT EXISTS public.k4abt_skeleton_id_seq
INCREMENT 1
START 1
MINVALUE 1
MAXVALUE 9223372036854775807
CACHE 1;
ALTER SEQUENCE public.k4abt_skeleton_id_seq
OWNED BY public.k4abt_skeleton.id;表建好了,接下来就是如何插入数据了。
pgsql 支持用字面量来插入复合类型字段,所谓字面量其实就是用字符串来表示。比如数组使用 '{1,2,3}' 来表示,对象使用 '(1, "Tom", 8)' 来表示。对于数组和对象,必须包裹在单引号 或双引号 中,对于对象嵌套数组的情况,我们可以用不同的引号来包裹,比如 '(1, "{5,6,7}")' 。但是引号只有两种,对于更深层的嵌套该怎么办呢?
答案是转义 !把 " 变成 \" 就可以了。比如我们的例子,插入两个关节数组。
sql
INSERT INTO k4abt_skeleton (body_id,joints,device_timestamp)
VALUES (1, '{"(\"{1,2,3}\",\"{4,3,2,1}\",2)","(\"{4,5,6}\",\"{7,6,5,4}\",1)"}', 1766020874);如果不想写引号嵌套,还可以使用 ARRAY 和 ROW 关键字,他们可以任意嵌套。数组表示为 ARRAY[1,2,3],对象表示为 ROW(1, "Tom")。上面的例子也可以重写如下:
sql
INSERT INTO k4abt_skeleton (body_id,joints,device_timestamp)
VALUES (1, ARRAY[ROW(ARRAY[1,2,3],ARRAY[4,3,2,1],2),ROW(ARRAY[4,5,6],ARRAY[7,6,5,4],1)]::public.k4abt_joint[], 1766020874);注意这种方式我们需要使用 ::public.k4abt_joint[] 来明确指定数组类型。
对于查询则比较简单,数组类型可以直接使用 字段[下标] 的方式查询对应下标的值,需要注意的是 pgsql 里面数组下标是从 1 开始的,不是从 0 开始的。对于对象类型,则需要使用 (字段).名称 的方式来访问对象字段。比如我们可以用下面的 sql 查询第一个关节的位置。
sql
SELECT id, (joints[1]).position FROM k4abt_skeleton LIMIT 1;对于 UPDATE 我们可以精确到修改复合类型的某个字段。访问数组类型字段和 SELECT 相同,而对于对象类型则不再需要 (),比如我们来修改下第一条数据的第一个关节的 x 坐标。
sql
UPDATE k4abt_skeleton SET joints[1].position[1] = 9 WHERE id = 1;最后再给大家贴一个官方文档: https://postgres.ac.cn/docs/current/rowtypes.html
