在当今快速发展的数字时代,高质量的数据已成为企业成功的关键因素之一。无论是用于训练机器学习模型、优化SEO策略还是进行市场分析,获取准确且及时的数据至关重要。然而,传统的网页爬虫开发往往伴随着高昂的成本、复杂的维护工作以及对技术团队的高度依赖。面对这些挑战,Bright Data推出了全新的AI Scraper Studio------一款旨在简化并加速多网站数据抓取过程的创新工具。
Bright Data AI Scraper Studio简述
Bright Data AI Scraper Studio是一款革命性的产品,它通过自然语言处理技术(NLP),让用户仅需输入简单的指令即可自动生成功能强大的爬虫脚本。这不仅极大地降低了技术门槛,使得非技术人员也能轻松上手,同时也为专业开发者提供了灵活定制的能力,满足复杂业务场景的需求。
主要特点与优势
Prompt驱动极速爬虫 :用户只需输入如"采集该网站所有产品价格和评价"的自然语言提示,系统即刻生成相应的爬虫脚本。
自愈与扩展性 :集成全球代理网络及解封核心技术,支持一键修复因网站变动导致的问题。
全可见可控 :对于难以完全用prompt描述的情况,用户可通过内置IDE手动调整代码。
自动化交付与调度 :支持多种输出方式(API/Webhook/云端推送),适应不同规模的应用需求。
性价比高:按有效结果计费,避免不必要的开支。
目标对象
● 技术团队(如AI平台、数据服务提供商、风控或情报分析部门)亟需高效采集网页数据,并快速扩展数据覆 盖广度;
● 从事数据科学、机器学习工程或SEO策略的负责人,希望将前沿技术融入业务运营;
● 对"AI驱动的下一代SEO""自动化AEO优化"以及通过智能手段获取商业洞察感兴趣的创新企业或初创团队;
● Bright Data的新老用户,期望借助AI能力提升爬虫效率,灵活、迅速地应对新页面或全新域名的抓取需求
要解决的问题
● 传统爬虫开发依赖大量人工编码与维护,拓展新网站周期长,难以兼顾规模扩展与系统稳定性;
● 在多站点并行采集场景下,常遭遇代理失效、IP封锁、脚本崩溃及数据格式不一致等工程挑战;
● 面对业务调整或技术升级,现有抓取流程往往需要大量返工,迭代效率低下;
● 市场机会转瞬即逝,爬虫交付速度直接制约业务响应能力与竞争壁垒;
市面上缺少一种门槛低、弹性强、可直接用于生产环境的智能数据采集解决方案。
行业应用场景
某牙星秀-星秀频道
爬取虎牙星秀频道,具有实际业务价值。通过自动化采集并结构化这些公开信息,运营团队或MCN机构可以持续监测平台内容生态变化,分析头部主播在视觉设计(如封面风格、配色、文案)上的共性策略,识别新兴高活跃度主播,辅助达人筛选与合作决策。同时,结合定时任务与数据分析工具,还能构建动态内容情报系统,为自有主播的内容优化、排期调整和流量预判提供数据支撑。这种做法类似于跨境电商公司通过爬虫实时跟踪竞品价格以调整定价策略------只不过在这里,"商品"是直播内容,"价格"是吸引用户点击与停留的视觉与话题竞争力。在合规前提下,此类数据采集能有效提升对数字内容市场的感知力与响应速度。
1.通过https://get.brightdata.com/wubright注册Bright Data账号,进入AI Scraper Studio免费试用。
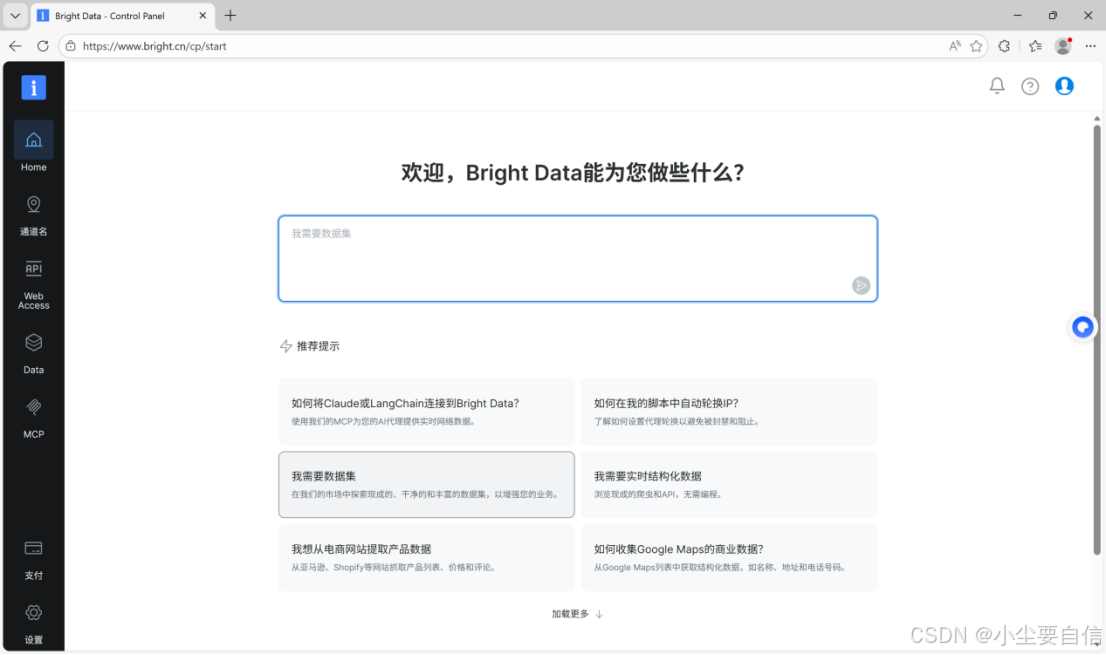
2.选择Data-》数据集商
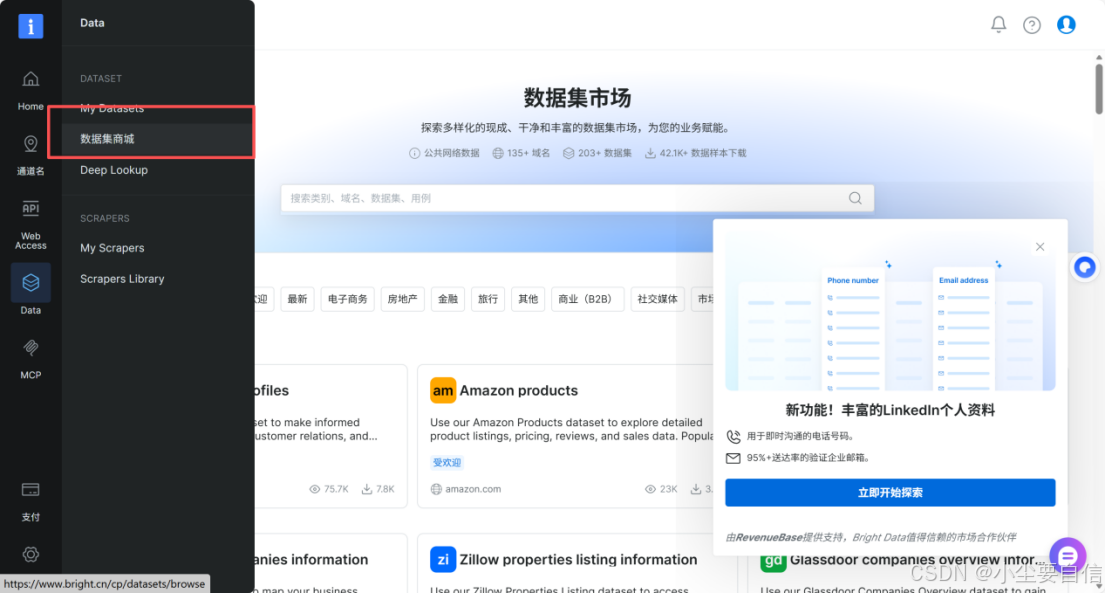
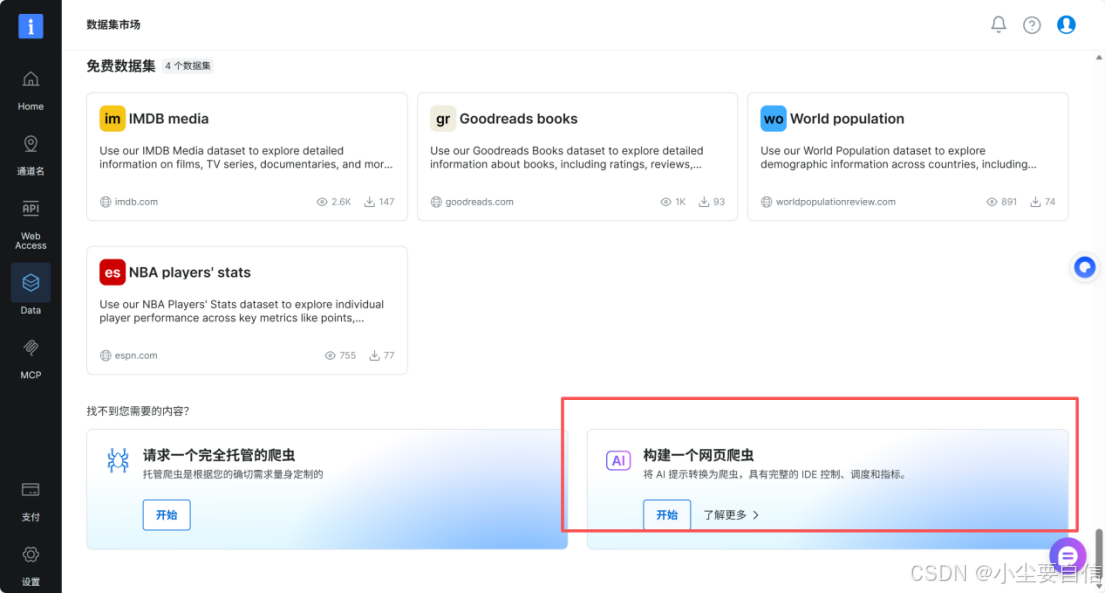
3.往下拉,选择右边 构建一个网页爬虫。
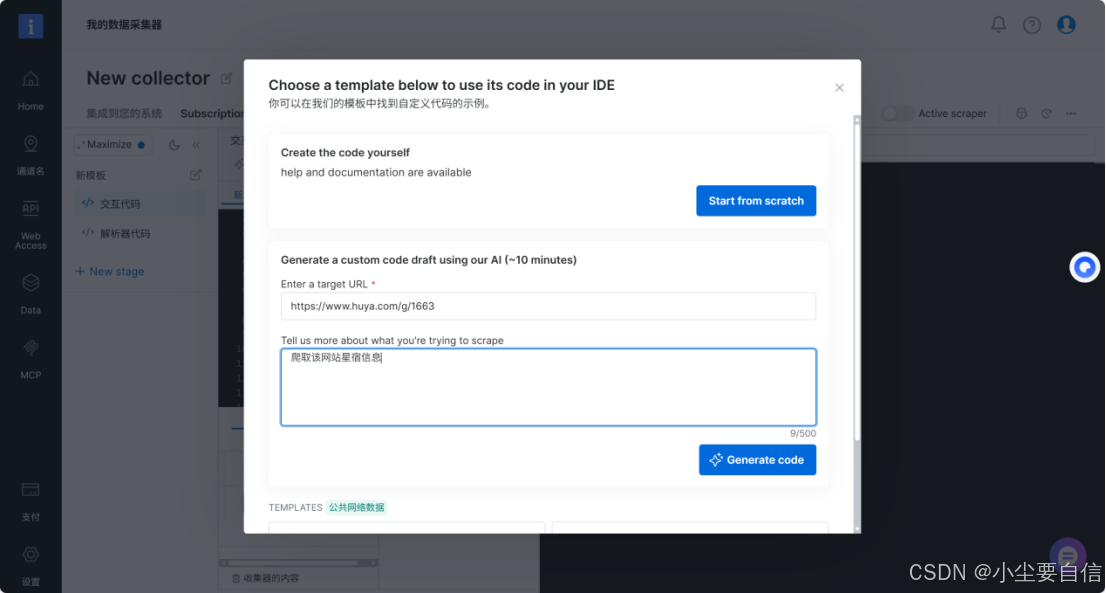
4.输入目标网址URL, 以及想要抓取的内容,运行,Studio自动生成并部署相应爬虫代码。
5.运行成功截图如下所示。
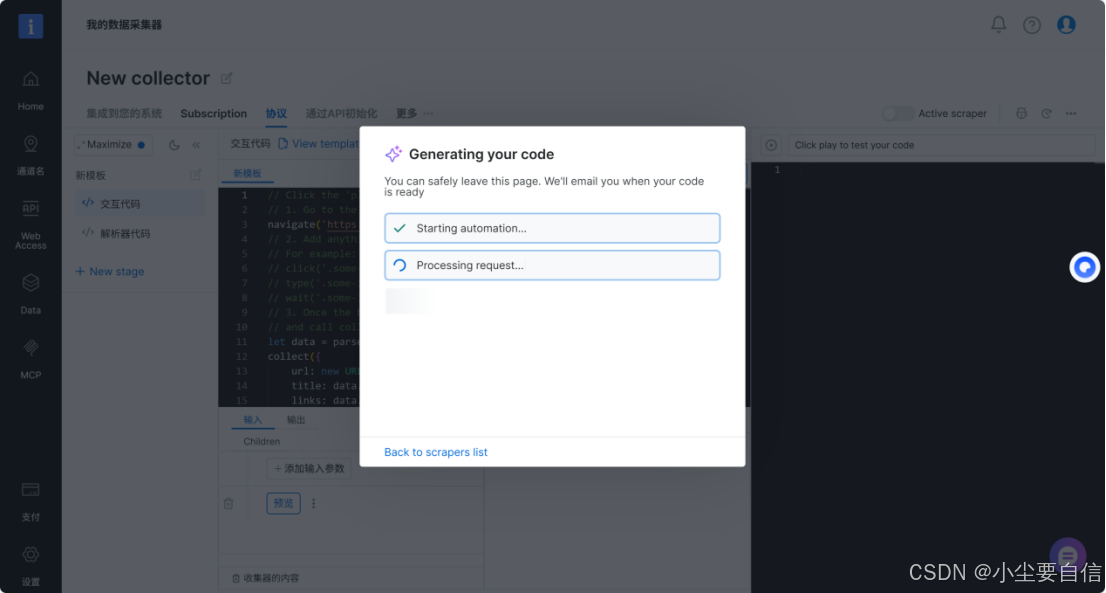
6.成功运行后回出现如下代码信息
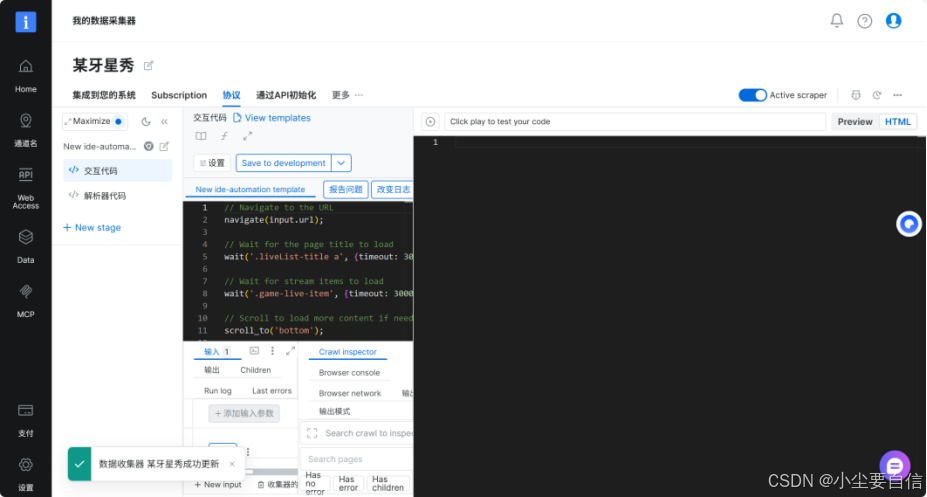
7.选择集成到您的系统。
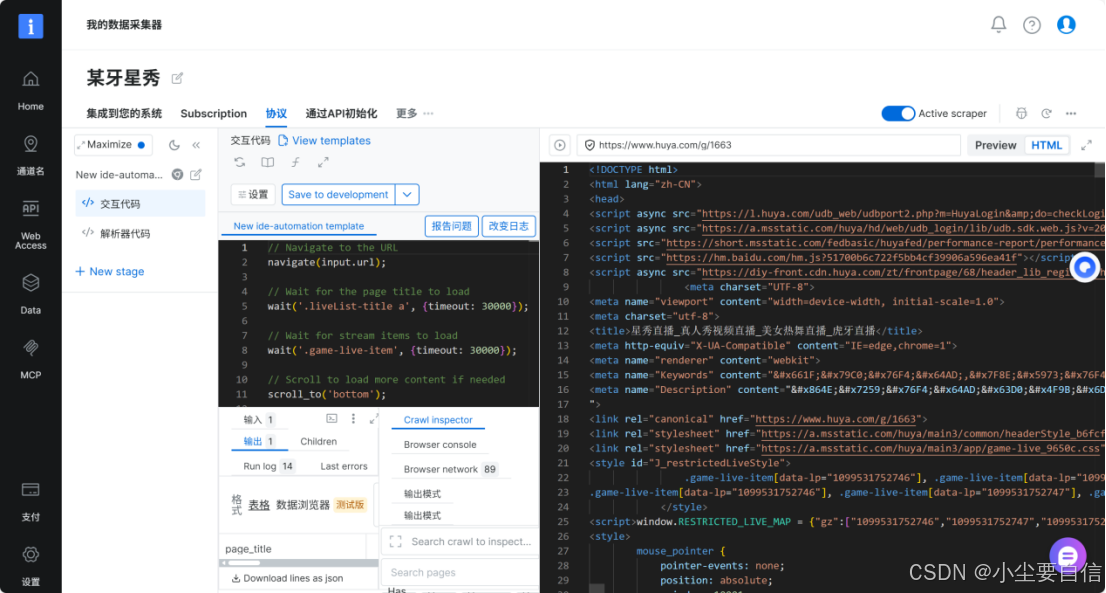
8.跳转到集成您的系统页面,点击start,开始爬取数据信息。
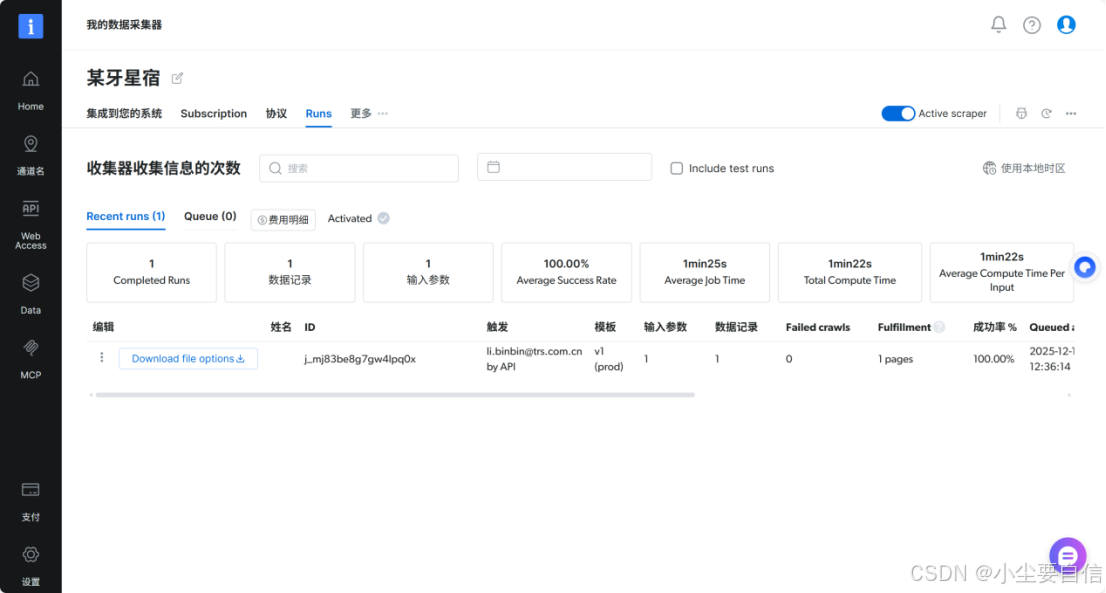
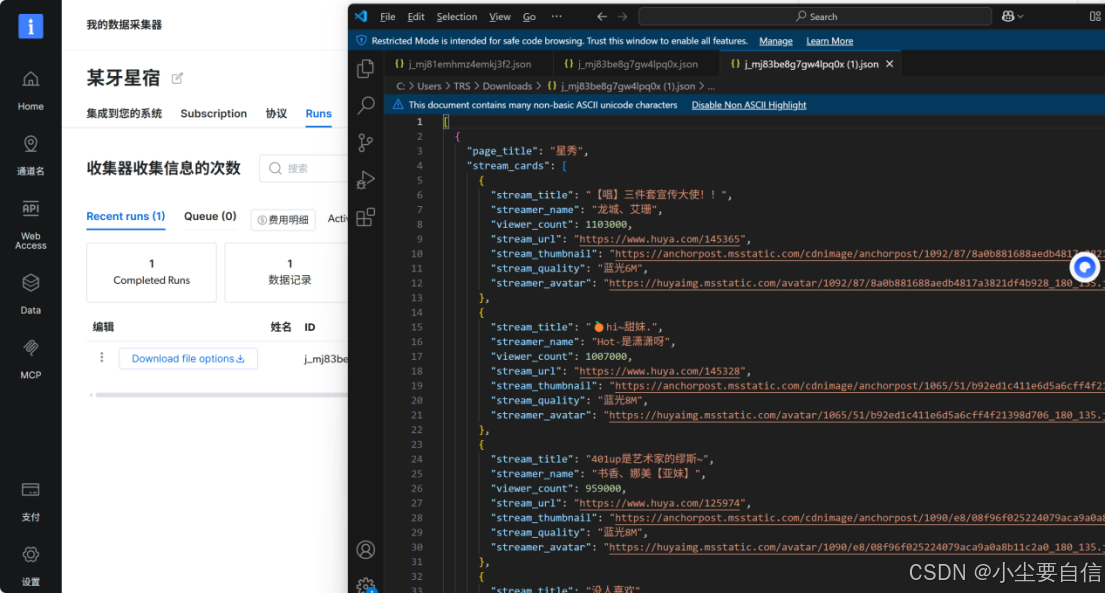
9.爬取成功后,点击下载爬取结果为json,内容如下图所示。
总结
数据的价值不在于"能否获取",而在于"多快、多稳、多智能地获取"。
Bright Data AI Scraper Studio 正在将曾经复杂、脆弱、高成本的网页爬虫,转变为一种像调用 API 一样简单、可靠且可扩展的服务。无论你是开发者、数据分析师还是业务决策者,现在都可以告别手动写爬虫的繁琐时代------只需一句话,让 AI 为你采集世界。立即注册Bright Data AI Scraper Studio免费试用(https://get.brightdata.com/wubright注册Bright Data账号,用这个链接就会2美元体验金),体验最新AI驱动爬虫,每月 可有5000次免费请求。