目录
文章目录
- 目录
- 模型结构
- 模型参数量计算公式
- 显存资源计算公式
-
- 显存杀手:训练优化器
- 显存优化技术
-
- [Checkpointing activation 显存优化](#Checkpointing activation 显存优化)
- Zero
- 计算公式示例
- 通信资源计算公式
- 算力资源计算公式
- 训练优化思路
- 参考文档
模型结构
当前 LLM 基本上都是 Decoder-Only 的 Transformer 模型,只不过都会进行一些修改。比如对 Attention 的修改衍生出来 Softmax Attention 系列和 Linear Attention 系列。而对 FFN 的修改衍生出了 Dense 模型和 MoE 模型。
以 Llama3.1 LLM 为例,它是开源的最大的 Dense 模型,采用 Decoder-only 架构。
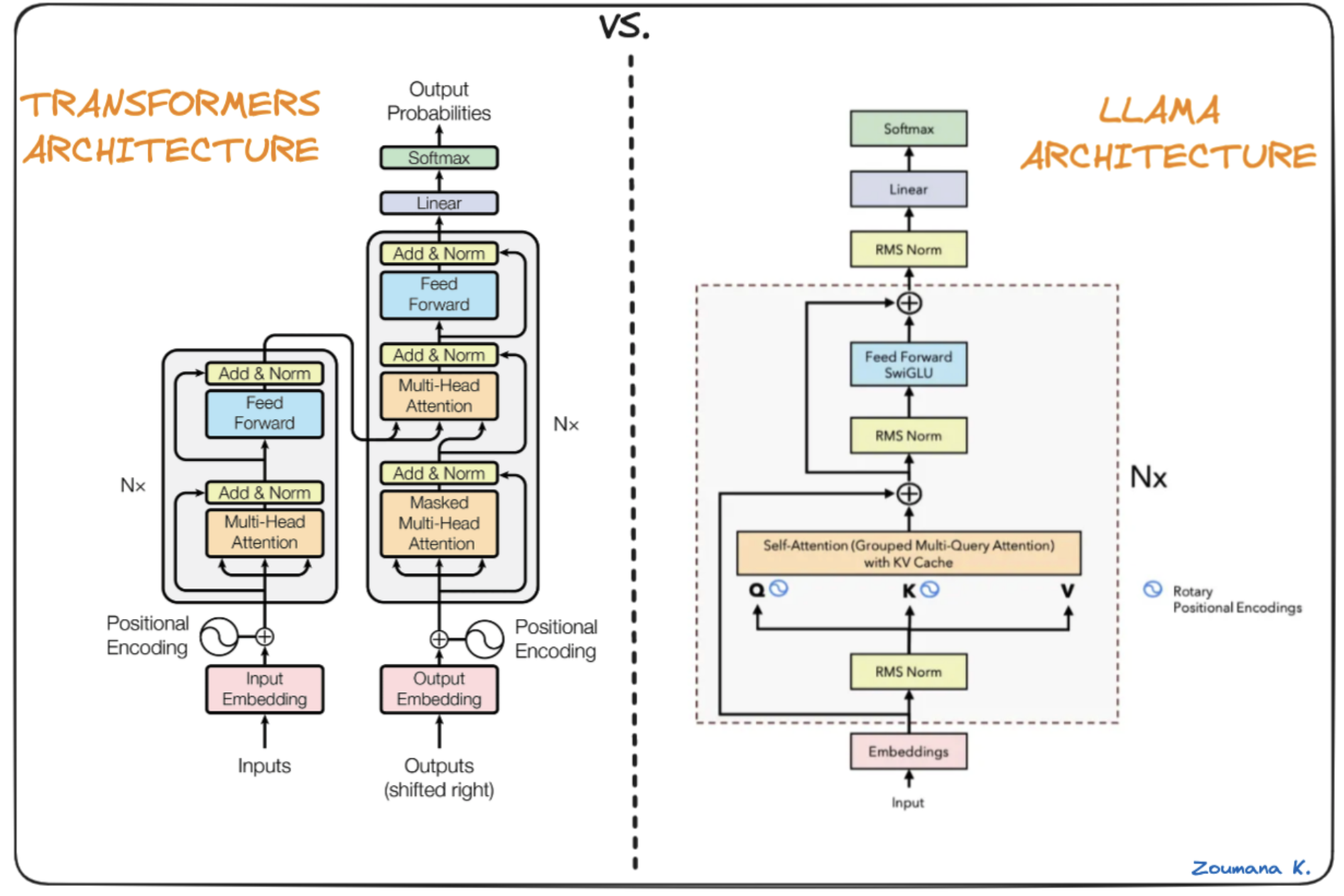
Llama3.1 提供了 3 种不同的模型结构,模型结构也决定了模型能力和模型参数量:
- 8B:聊天、简单问答,推理能力弱,上下文窗口短(4k)。
- 70B:代码生成、多轮对话,长文本(几十k)。
- 405B:数学证明、逻辑建模、专业研究,超长文本(>100k)。
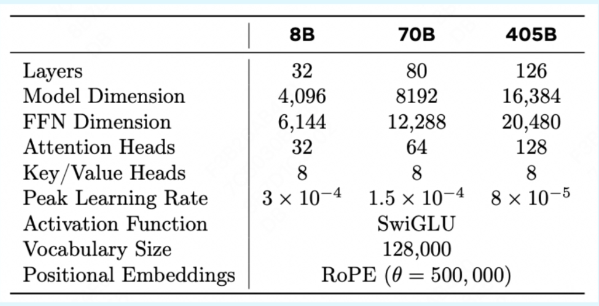
- Layers(层数):Self-Attention 和 FFN 的 Nx 堆叠数量。代表模型的 "深度",层数越多,模型能学习的逻辑推理链越长,例如:复杂数学题、多步骤任务等。405B 126 层远高于 70B 80 层,说明 405B 在深度推理上有更强潜力,但也更难训练,例如:易过拟合、梯度消失。
- Model Dimension / Hidden Dimension(隐藏维度):每个 token 经过 Embedding(词嵌入)后转化的向量的维度(Hidden size),例如:"猫" 字转化为了一个长为 4096 的词向量。这也是 Self-Attention 和 FFN 的输入输出维度。代表模型的 "宽度",值越大表示每个 token 能编码的语义信息越丰富,如区分 "苹果(水果)" 和 "苹果(公司)"。405B 16384 维比 70B 8192 维更大,说明 405B 的 token 能够具有多 2 倍的语义。
- FFN Dimension(前馈网络维度):FFN 中间层的维度,通常是 Model Dimension 的 2~4 倍。FFN 负责对 Self-Attention 输出的 "上下文向量" 进行非线性变换,维度越大,表示模型的非线性表达能力越强。
- Attention Heads(注意力头数):Multi-Head-Attention(多头注意力)机制中的 "并行注意力头" 数量,每个头独立学习不同的注意力模式,如语法依赖、语义关联。头数越多,模型能同时关注的上下文关系就越多样,例如:主语-谓语、原因-结果、对比-转折。405B 128 头是 70B 的 2 倍,说明其对 "复杂上下文关联" 的建模能力更强,如长文档理解、多角色对话。
- Key/Value Heads(键/值头数):仅在 GQA(Grouped Multi-Query Attention 分组查询注意力) 中有效,将 Query Heads 与 Key/Value Heads 分离,减少了参数量,比例为 128/8。传统 MHA(多头注意力)中,Q、K、V 头数相同,而 GQA 中,Q 头数和 Attention Heads 头数相同,而 K/V 头数不定,所有 Q 头共享 K/V 头的输出。例如 70B 有 64 个 Q 头,但只有 8 个 K/V 头。可以在保持性能的同时减少 30%-50% 注意力层参数,降低训练难度。
- Peak Learning Rate(峰值学习率):训练中使用的最大学习率(采用余弦退火等策略动态调整)。模型越大,学习率需越小,避免参数更新幅度过大导致 "震荡不收敛" 的情况。405B 的学习率仅为 8B 的 1/4,说明其训练收敛的难度更大,需更精细的优化策略。
- Activation Function(激活函数):FFN 中的非线性变换函数,决定了模型表达复杂关系的能力。SwiGLU 是 ReLU 的改进版,结合了 Swish 激活和门控机制(GLU),比传统 ReLU 有更强的梯度流动性和表达能力,现已成为了大模型标配。
- Vocabulary Size(词表大小):模型能识别的 "最小语义单元" 的总数(如中文汉字、英文单词、符号的集合)。128000 的词表大小已经覆盖主流国际语言和专业领域术语(如代码、医学词汇)。所有 3 个模型共享词表,说明它们基于同一套 "语言符号系统" 训练,可复用预训练权重(如小模型初始化大模型)。
- Positional Embeddings(位置编码):为 token 添加位置信息的编码方式,解决 Transformer 无法识别序列顺序的问题。RoPE(旋转位置编码)通过三角函数计算位置信息,支持任意长度的上下文窗口,优于传统固定长度的位置编码。θ=500,000 是控制位置编码周期的超参数,值越大,模型对 "长距离位置差异" 的区分能力越强(适合超长文本处理)。
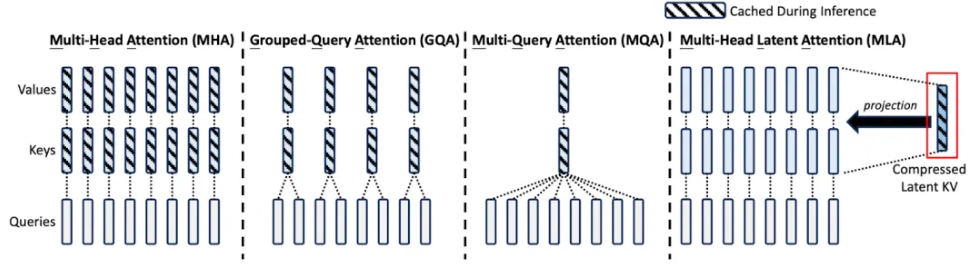
对于 Softmax Attention 系列,目前主要的是 MHA、MQA、GQA 和 MLA:
- MHA:Transformer 模型的标准实现,每个 Attention Head 都有独立的 Q、K、V。现在很少使用,Inference 阶段的问题较多,最主要是 KV Cache 占比最大,并且在 Continuous Batching 阶段 Attention 核心计算无法只用 Tensor Core,存在一定的局限性。
- MQA:所有 Attention Head 共享相同的 K 和 V。计算量和 KV Cache 都是最小的,也是对 Inference 阶段最友好的。但是因为对模型效果影响较大,所以很少使用。
- GQA:对 Attention Head 进行分组,一组 Attention Head 共享相同的 K 和 V。是 MHA 和 GQA 的折衷方案,KV Cache 大小处于 MHA 和 GQA 之间,计算效率也处于两者之间。是当前模型中最常见的的 Attention 方式。
- MLA :DeepSeek 2024 年 5 月在 DeepSeek V2 中提出,并在 DeepSeek V3 中沿用。核心思路是每个 Head 都有独立的 K 和 V,但它们可以投影和反投影到同样的、共享的 Latent KV。KV Cache 和 MQA 相当,明显少于 MHA 和 GQA,但效果还不错,和 MHA 相当。但是也会额外的增加一些计算量。
模型参数量计算公式
模型参数量(矩阵参数量)计算公式如下:
bash
Param_total = num_layers * (
self-Attention # Q, K, V, Output projection
+ FFN * [num_MoE] # Dense or MoE
+ 2 * LayerNorm # LayerNorm γ, β
)
+ embedding
+ LayerNorm
+ Linear
self-Attention = 4 * d_model^2
# 涉及 4 个矩阵:
# 1. Q,形状:(d_model, d_model)
# 2. K,形状:(d_model, d_model)
# 3. V,形状:(d_model, d_model)
# 4. 输出投影矩阵,形状:(d_model, d_model)
FFN = d_model * d_ffn * 2
# 涉及 2 个矩阵
# 1. 升维矩阵,形状:(d_model, d_ffn)
# 2. 降维矩阵,形状:(d_ffn, d_model)
LayerNorm = d_model
# LayerNorm 是一个向量而不是矩阵。有 2 个 γ 和 β
# 1. γ:增益(Scale/Gamma),形状:Gamma = [g₁, g₂, ..., g_{d_model}]
# 2. β:偏置(Shift/Beta),形状:Beta = [b₁, b₂, ..., b_{d_model}]
Embedding = vocab_size * d_model
# 输入层,词表嵌入矩阵,形状: (d_model, vocab_size)
Linear = vocab_size * d_model
# 输出层,将隐藏状态映射回词表嵌入矩阵,形状: (d_model, vocab_size)实际上,LayerNorm γ, β、Linear 和 Embedding 的参数量较小,通常可忽略不计,模型参数量主要由 self-Attention、FFN 和 Layers 决定。
显存资源计算公式
训练场景中 GPU 显存资源由 "静态参数总量" 和 "中间激活值总量" 这 2 各部分组成。
bash
显存资源总量 = 静态参数显存总量 + 中间激活值显存总量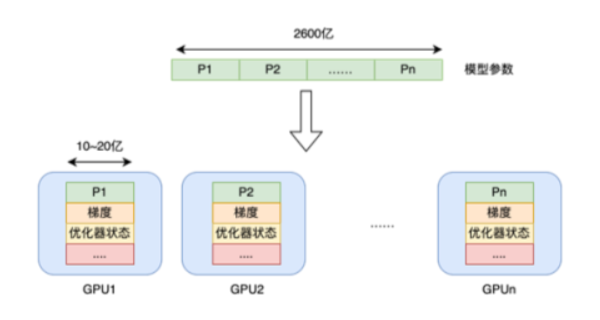
- 模型占用的显存:包括 P 参数、梯度和 Optimizer 状态;
bash
静态参数显存总量(Byte) = (参数量 × 运算精度) × 总参数份数- 参数量 × 运算精度:每个参数使用一个精度的存储空间,将参数量转化为 GB 容量。例如:BF16 的精度为 2Bytes。
- 总参数份数 = 权重份数 + 梯度份数 + 优化器状态份数
- 权重、梯度通常各 1 分参数
- AdamW 优化器需要使用 2 份参数
以 Llama3.1 405B 为例,从理论上估算 GPU 显存的总容量。
- 模型参数量:405B(405×10^9)
- BF16:2Bytes
bash
静态参数显存总量 = 405×10^9 × 2 × 4 = 3240×10^9 Byte = 3240 GB- 中间激活值(Activation)显存总量:包括模型 Transformer layer 层和 Embedding 层的输出,是 Forward 时产生的中间结果,Backward 时需复用这些激活值计算梯度。例如:self-attention 的动态激活值输入数据总量的 2 次方。因为 self-attention 的本质是 "每个人都要和其他人打招呼,并且要记录所有人的打招呼内容",这个记录矩阵的大小需要存储在显存中。
bash
动态激活值总量(Byte) = (批量大小 × 序列长度 x 隐藏维度)^2 × 运算精度 × 层数实际上一个 80G 显存的 H100,算上训练中间的计算状态,也只能存放大概 10~20 亿参数。那么光是存放 Llama3.1 4050 亿参数的模型本身,就需要三四百块 GPU。
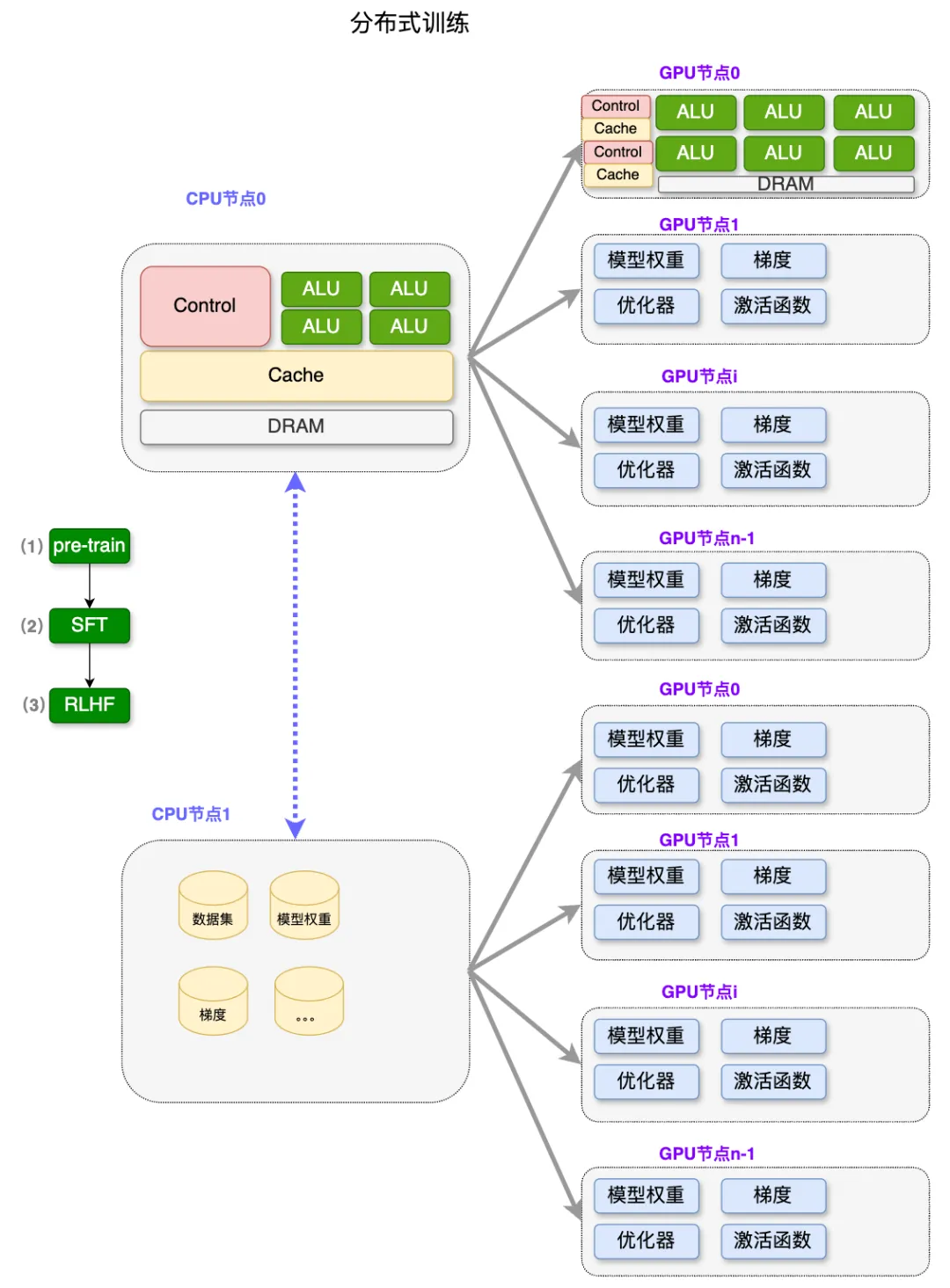
显存杀手:训练优化器
在 AI/ML 中,梯度下降(Gradient Descent)是一种关键的 loss 损失函数极值优化方法,根据使用的数据量不同,梯度下降可以分为 3 种不同的变体:
- Batched 梯度下降(Batch Gradient Descent) :每次更新权重时,使用整个训练集来计算损失函数的梯度。假设有 N 个样本,则每个 Weight 在反向传播后都有 N 个梯度,会先计算 N 个梯度的平均,然后使用平均值更新 Weight。
- 优点:由于使用所有的训练数据,梯度估计非常准确,收敛过程稳定。
- 缺点:当训练数据集很大时,每次计算梯度都非常耗时,而且内存需求高,不适合处理大规模数据。
- 随机梯度下降(Stochastic Gradient Descent,SGD) :每次更新模型参数时,只使用单个训练样本来计算梯度。每个 Weight 在反向传播后都只有 1 个梯度,直接使用这 1 个梯度更新 Weight。
- 优点:只用一个样本进行更新,所以计算速度快,适合大规模数据集,且内存占用较小。
- 缺点:由于梯度是基于单个样本计算的,梯度估计不准确,容易导致梯度更新过程中的 "噪声",使得收敛过程不稳定,并可能在接近最优解时出现振荡。
- Mini-batch 梯度下降(Mini-batch Gradient Descent) :介于 Batched 梯度下降和随机梯度下降之间。每次更新模型参数时,使用一小部分训练数据(即 Mini-batch)来计算梯度。
- 优点:Mini-batch 梯度下降结合了全量梯度下降和随机梯度下降的优点,计算速度比全量梯度下降快,同时比随机梯度下降更加稳定,减少了更新中的"噪声"。
- 缺点:虽然它比 SGD 更稳定,但仍然可能面临一个 mini-batch 中样本不够多,导致梯度估计仍有一定的偏差。
但实际上,上述传统的梯度下降优化算法在 DL 实践中非常低效且复杂。因为每个参数都有自己的 "梯度方向" 和 "学习率步长",有些参数可能需要更快地更新,而另一些则需要更慢、更稳定,如下图所示。
而训练优化器就是一种专用于高效更新 Weight、优化 loss 损失函数的自适应学习率的优化算法,其核心目标是:自适应学习率,即为每个参数自动计算其独特的学习率。
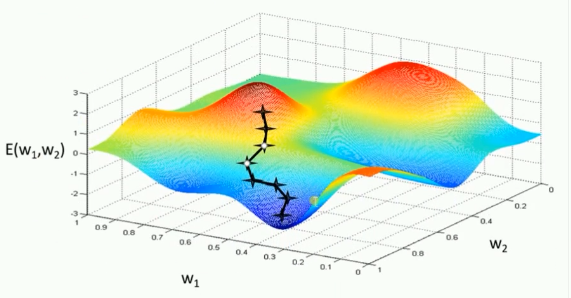
常见的有 Adam(Adaptive Moment estimation,自适应矩估计)优化器,它是一个结合了动量(Momentum)和自适应学习率(RMSprop)技术的优化算法,其旨在让模型训练得更快、更稳,减少人为调参的工作量,广泛用于 DL 的训练场景。
- 动量(Momentum)机制:管理 "梯度方向",在正确的方向加速,而在不稳定方向减速,能够有效缓解局部极小值问题。
- 自适应学习率(RMSprop)机制:管理 "学习率步长",根据历史梯度的大小,为每个参数自适应地调整学习率。例如:如果一个参数的历史梯度一直很大,说明它很不稳定,则应该给它一个很小的学习率,避免它 "跳过头"。
多种优化算法的比较如下图所示。
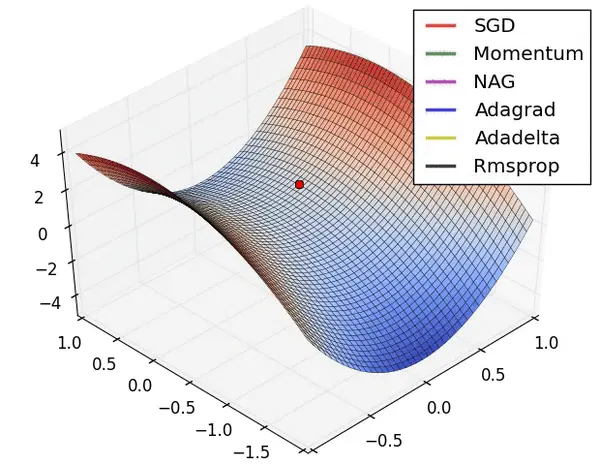
Adam 优化器的核心优势在于能够根据参数的更新历史自适应调整每个参数的学习率,这有助于加快收敛速度并提高训练稳定性。为了实现这一点,Adam 优化器会在 GPU 显存中维护 2 份额外的状态数据(参数矩阵)m_t 和 v_t 直到权重参数更新完成。并且这 2 份状态数据的大小和权重参数量一致,所以在计算 GPU 显存资源时需要乘以优化器的份数。
- 一阶矩(m_t):作用于动量机制,是梯度的一阶指数移动平均,它记住了梯度的主要方向,起到了平滑噪声、正确方向加速的作用。
- 二阶矩(v_t):作用于 RMSProp 机制,是梯度平方的二阶指数移动平均,它记住了梯度的变化幅度,起到了在陡坡小步走、缓坡大步走的作用。
对应的,Adam 优化器有几个关键的超参数可以被调节:
- β₁(Beta1):一阶矩的衰减率,默认为 0.9。控制着"速度"的记忆周期。
- β₂(Beta2):二阶矩的衰减率,通常设置为 0.999。这个值非常接近 1,意味着它对历史梯度平方的记忆很长,这使得学习率调整非常平滑。
- ε(Epsilon):一个非常小的数(如 1e-8),主要是为了防止除以零的错误。
Pytorch 的 Adam 优化器实现:https://docs.pytorch.org/docs/stable/generated/torch.optim.Adam.html
显存优化技术
显存优化技术,包括 ZeRO-1(Distributed Optimizer)Checkpoint Activations、混合精度训练、Kernel Fusion 和 Flash Attention 等。
Checkpointing activation 显存优化
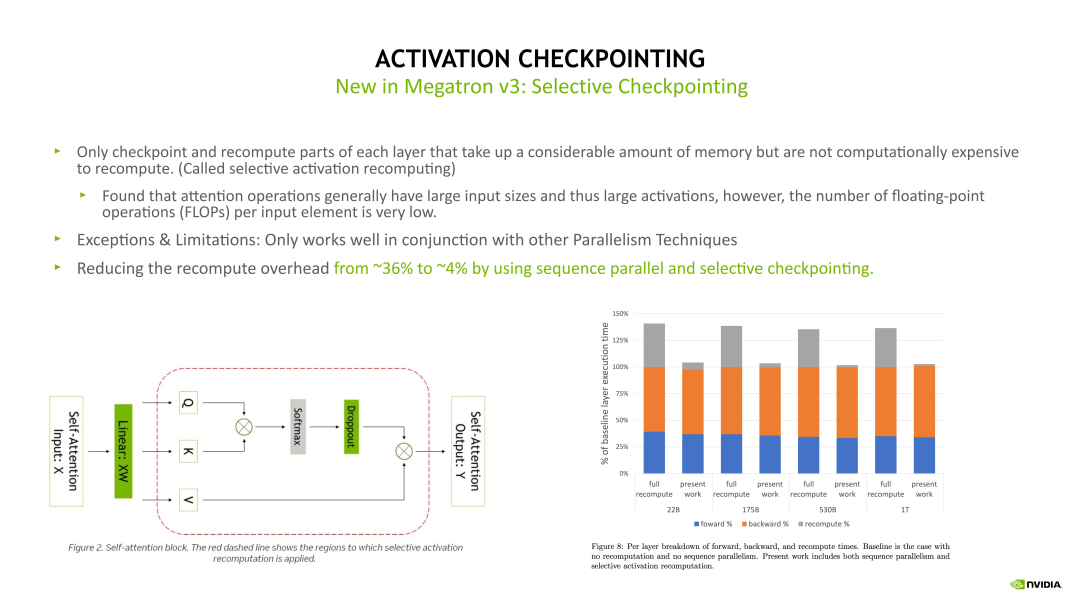
其中 Selective Activation Checkpoint 是目前 Megatron 中用的比较多的,也是比较高效的一个 Checkpoint 技术。Checkpointing activation 就是做重新计算。例如在 Forward 计算时得到的 Activation 不再保留,做 Backward 计算时,对这些 Activation 进行重新计算,这样可以极大程度上减少对 GPU 显存的开销。Checkpointing activation 的实现方式有下边示意图列出来的几种。
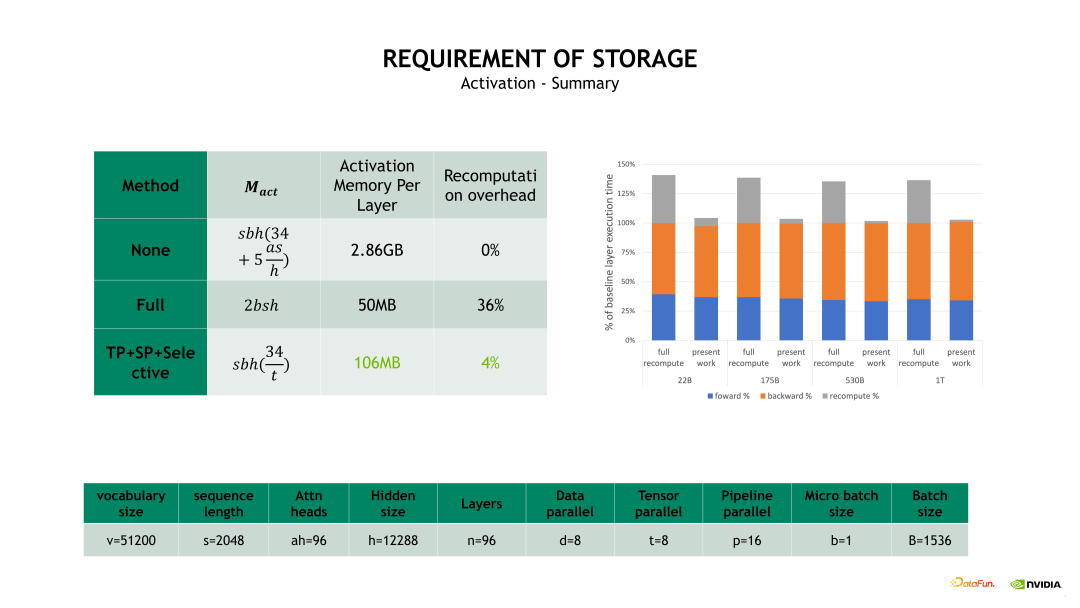
其中一种比较 Native 的实现是 Full checkpointing,也即对 Transformer 的每个层都进行重新计算。例如在最后一层做 Backward 计算时,需要这个 Transformer layer 在 Backward 计算之前重新执行一次 Forward 计算,当重新计算 Forward 后再开始这个层的 Backward 计算。Full checkpointing 对每个 Transformer layer 都打了一个重算点。所以 Full checkpointing 的好处在于将显存开销降低到 O(n) 的复杂度,而不足在于对每个 Transformer layer 都要重新计算一遍,从而带来了近 36% 的额外计算开销。

另一个优化 Activation 的方式是 Sequence Parallelism 加上 Selective checkpointing,将这个重算的开销从 36% 降低到 4%。Selective checkpointing 会选择一些重算性价比高的 OP,对一些计算时间比较小但产生 Activation 占用的显存很大的 OP 进行重算。例如下边示例图左边的 Self-attention 模块,通过对比分析后得出,对 Self-attention 这块做重算的收益是非常高的,因为它的计算量相对会少一点,但它的一些中间结果输出占用的显存开销非常大。因此我们就可以只对这块做重算。对其他的层,例如 Linear 和 Layernorm 层,可以采用其他的优化方法对 Activation 进行优化。
Selective checkpointing 的核心思想是对一些性价比高的 OP 做重算,并与其他的并行优化方法联合使用,达到 1+1>2 的效果。
Zero
在模型训练时,Optimizer 状态是模型固定占用显存的主要部分。假如模型参数量是m,则 Optimizer 的显存开销是 16*m 字节。Zero-1 的思想是在不同的 DP rank 上对 Optimizer 状态做拆分,所以 Distributed Optimizer(Zero-1)在每个 DP rank 占用的显存是 16 * m 除以 DP size,明显降低了显存开销,同时也带来了通信模式的改变。
例如,我们可以直接对梯度做 Reduce-scatter,之后再对自己的那一部分参数做Optimizer 相关的状态更新,Optimizer 状态更新完毕后再用一个 All-gather 操作收集模型权重。这样由 DP 并行的一个 All-reduce 变成了一个 Reduce-scatter 加上一个 All-gather。根据前面的介绍,这个 All-reduce 的通信量是 Reduce-scatter 或 All-gather 的两倍,所以整体的通信量是没有变化的,但通信的次数变多了。
其次,使用比较多的是 Zero-2 和Zero-3。Zero-2 和 Zero-3 需要每次进行额外的 forward 和 backward 计算,并且每次都需要做通信,但是流水线并行会将一个大的 batch 拆分成很多个小的 forward 和 backward,也就会造成大的通信量。所以当同时使用 Zero-2 或 Zero-3 加上流水线并行时,通信量会大幅上升,因此这里不推荐大家同时使用流水线并行和 Zero-2 或 Zero-3,但流水线并行可以和 Zero-1 同时使用。
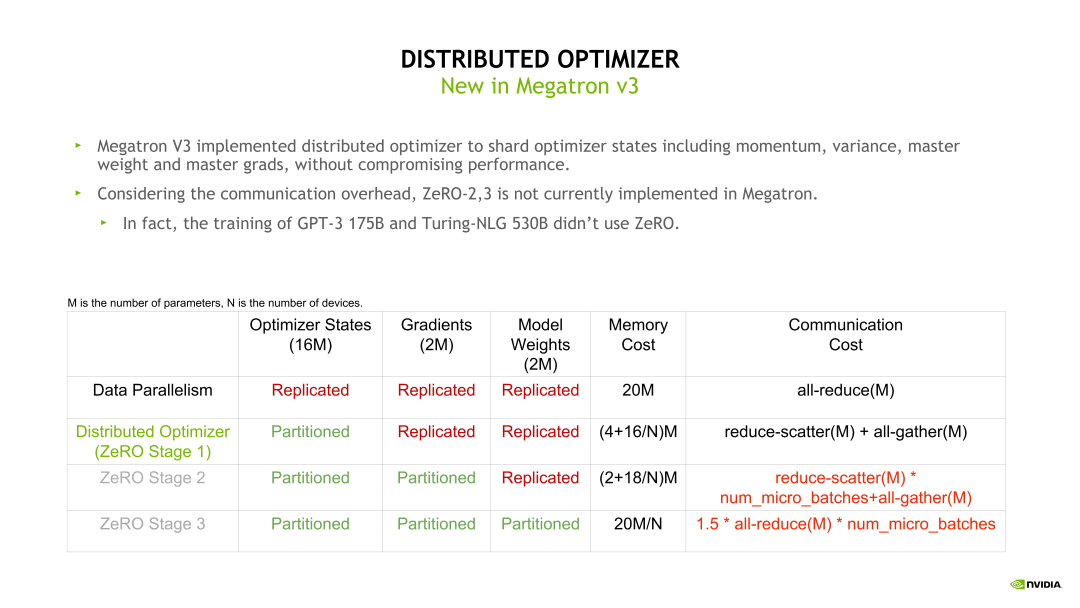
DP 是最常用的并行策略,因为它与其他并行策略正交,实现简单并且通信量相对不是很大,很容易扩展训练的规模。但是 DP 也存在一个比较明显的问题:在每个 DP Group 内都有完整的模型、优化器状态和梯度副本,导致内存开销比较大。
为了解决内存开销大的问题,微软提出了 ZeRO,可以根据不同的程度充分将优化器状态(os)、梯度(g)和模型参数(p)切分到所有的 GPU 中,也就是不同的 DP Group 中会存储不同的优化器状态、梯度和参数切片。
- ZeRO-1(P_os):将优化器状态切分到所有 GPU,每块 GPU 还有全量的模型参数和梯度。先切分优化器状态是因为其占用内存更多,并且与 Forward 和 Backward 的反向传播无关,只影响 Backward 的权重参数更新阶段。由于 ZeRO-1 中每个 GPU 只需要对应部分的平均梯度,而不像传统 DP 那样需要梯度的 all-gather,因此总的通信量不变。也就是说,在极大降低显存开销的情况下并不会增加通信量,所以常见的并行方案中基本都会默认采用 ZeRO-1。
- ZeRO-2(P_os+g):在 ZeRO-1 的基础上进一步切分梯度,切分梯度不影响 Forward 过程。
- ZeRO-3(P_os+g+p):在 ZeRO-2 的基础上进一步切分模型参数,会影响 Forward 阶段,需要 all-gather 所有参数才能计算,会引入更多通信。采用 ZeRO-3 几乎可以将内存需求降低到 1/N,其中 N 表示 GPU 数量。
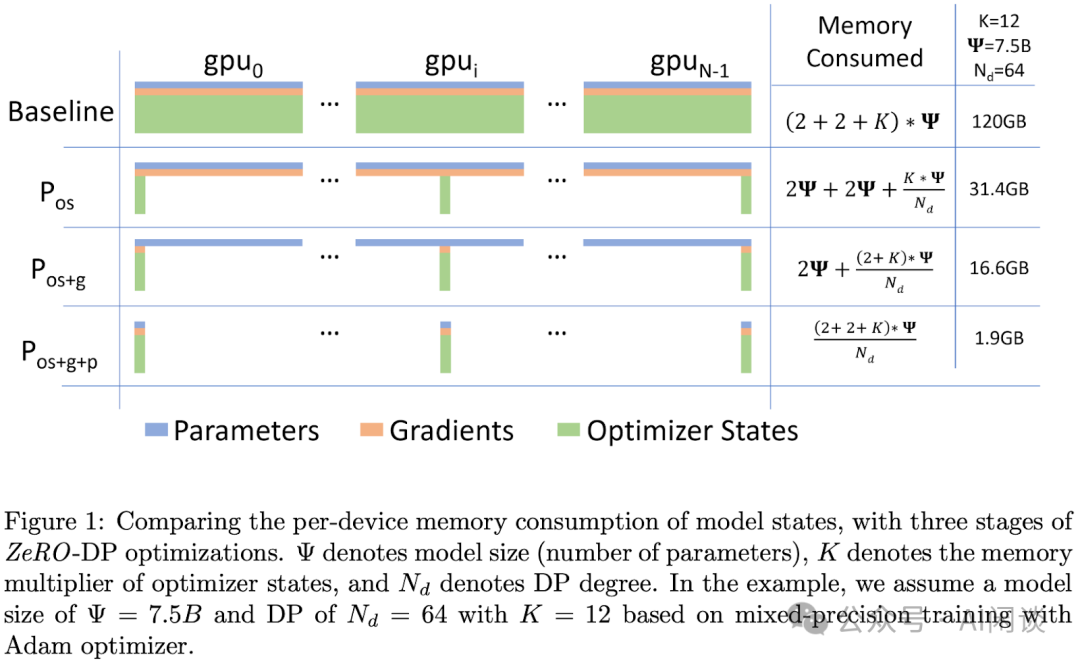
计算公式示例
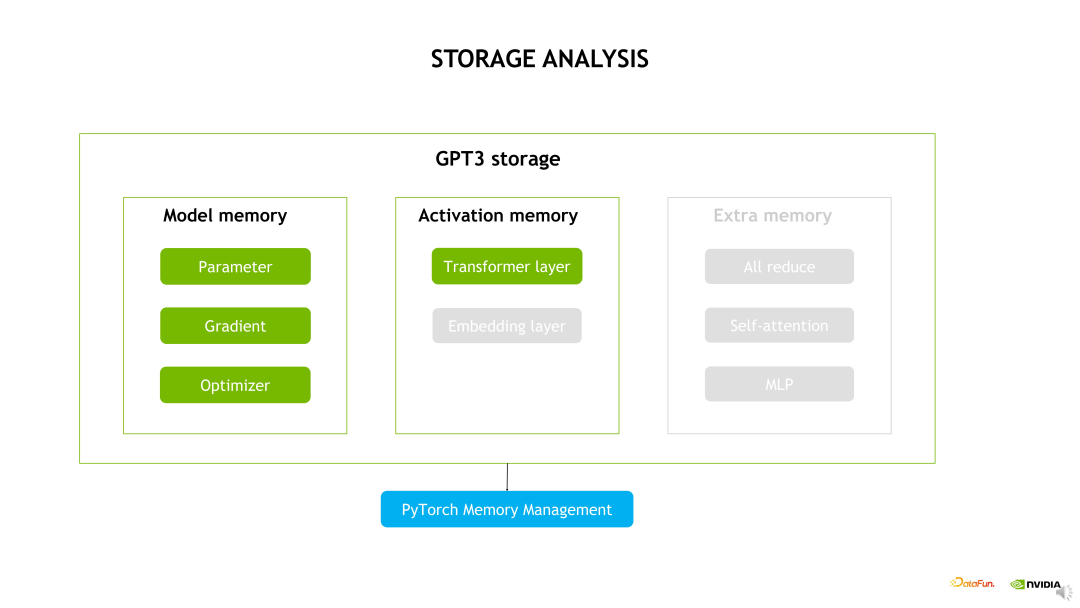
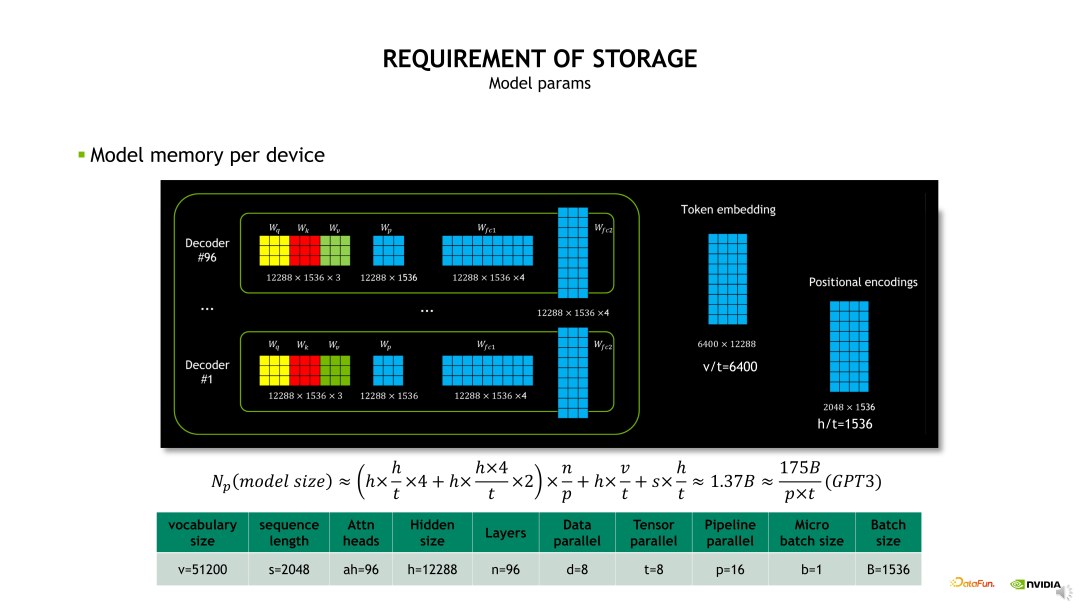
模型参数显存开销,即模型做了 TP 和 PP 拆分后每个 GPU 上会有多大的实际参数。我们先看下 GPT-3 模型的整体构成,模型包含了 96 层 Decoder,在每层 Decoder 内包含一个 QKV 权重、Projection 权重以及两个 FC(Fully Connected Layer,全连接层)
的权重,这样的权重会被重复 96 次,另外包含了 Token Embedding 和 Position Encoding 的权重。当进行TP 拆分时,相当于 QKV 权重和 Projection 权重会除以 t,再挤上两层的 FC 权重也除以 t,t 是TP 拆分的数量。然后进行 PP 拆分,也就是原始的 n 层除以 p,p 是 PP 拆分的 stage 数量,再加上 Token Embedding 和 Position Encoding 也做了 TP 维度的拆分。所以当 TP 等 8,PP 等于 16 时,每个 GPU 上需要存储 1.37B 的参数量。
对于 1.37B 参数量实际占用的显存,当我们使用混合精度时,模型的参数和梯度占用的显存都是 2.74GB。由于 Optimizer 状态占用的显存是 16 倍的参数量,所以 Optimizer 占用的显存是 21.9GB,可以看到主要是 Optimizer 状态占用很大比例的显存开销。
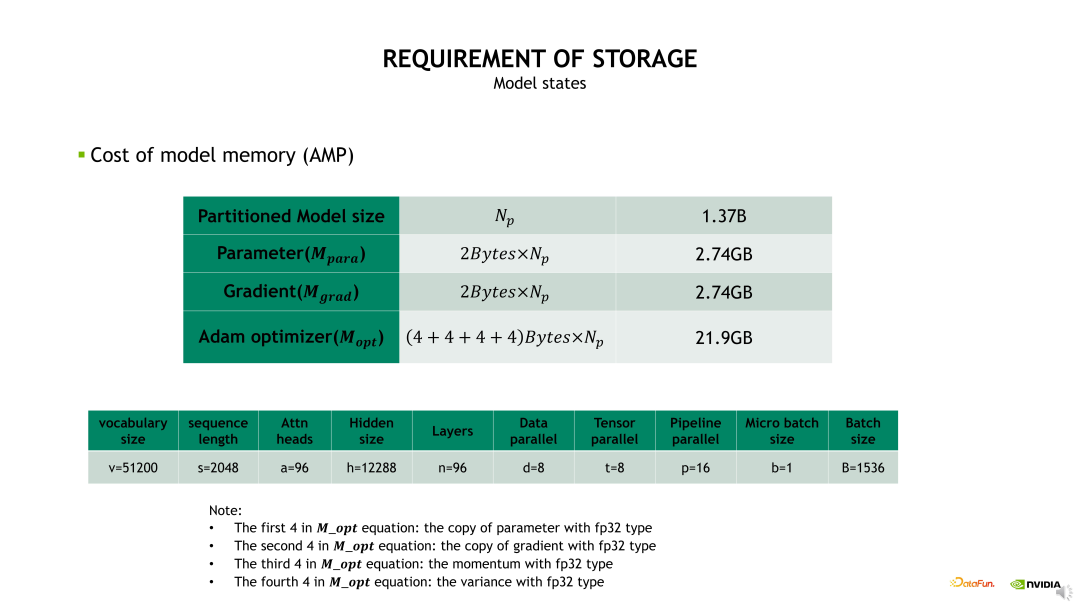
Optimizer 状态的显存开销可以通过前面介绍的 Distributed optimizer 或 Zero 技术进行优化。其中,Zero-1技术可以将 Optimizer 状态做一个 DP 维度的拆分,从而降低显存占用。例如,当DP size 设置为 8 时,Optimizer 状态的显存占用可以从 21.9GB 降低到 2.7GB。
若在 Zero-1 基础上再做 Zero-2,可以将梯度也进行 DP 维度的拆分,梯度的显存占用由 2.74GB 降低到 0.34GB。若再做 Zero-3,可以将参数也做相应的拆分,将其显存占用降低为 0.34GB。
可以看到,当 DP size 等于 8 时,使用 Zero-1 对 Optimizer 状态做拆分就可以带来明显的显存开销降低。相对而言,使用 Zero-2、Zero-3 对梯度和参数做拆分时的显存开销优化不明显,同时会增加非常多的通信 overhead。所以建议如果不是显存特别紧张的条件下,尽量不要用 Zero-3。一方面它带来很大的计算开销和通信开销,另一方面它的优化也会比较难调试。
从另一个角度来说,当模型参数被 TP 和 PP 拆分后,每个 GPU 上的参数和梯度自然地被拆分了,所以它占用的显存也比较小,使用 Zero-1 就能达到一个很好的效果。另外,值得注意的是,我们并不推荐使用 PP 后再叠加 ZeRO-2/3,主要原因是一方面它对显存的进一步优化不是很明显;另一方面是它会带来一定的通信冲突,所以建议大家使用 TP 和 PP 后用 Zero-1 就可以了。
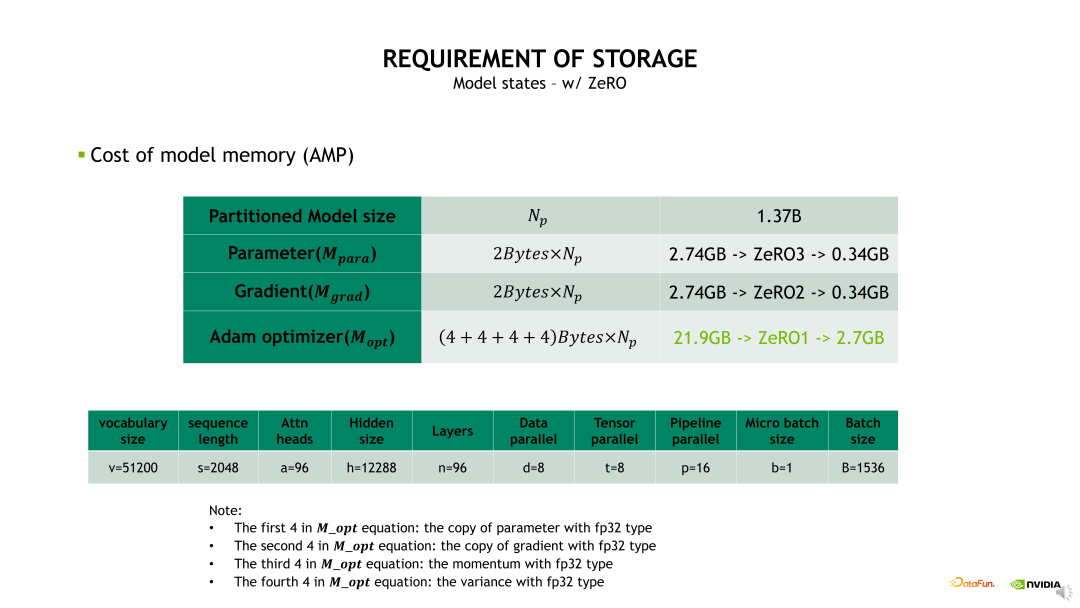
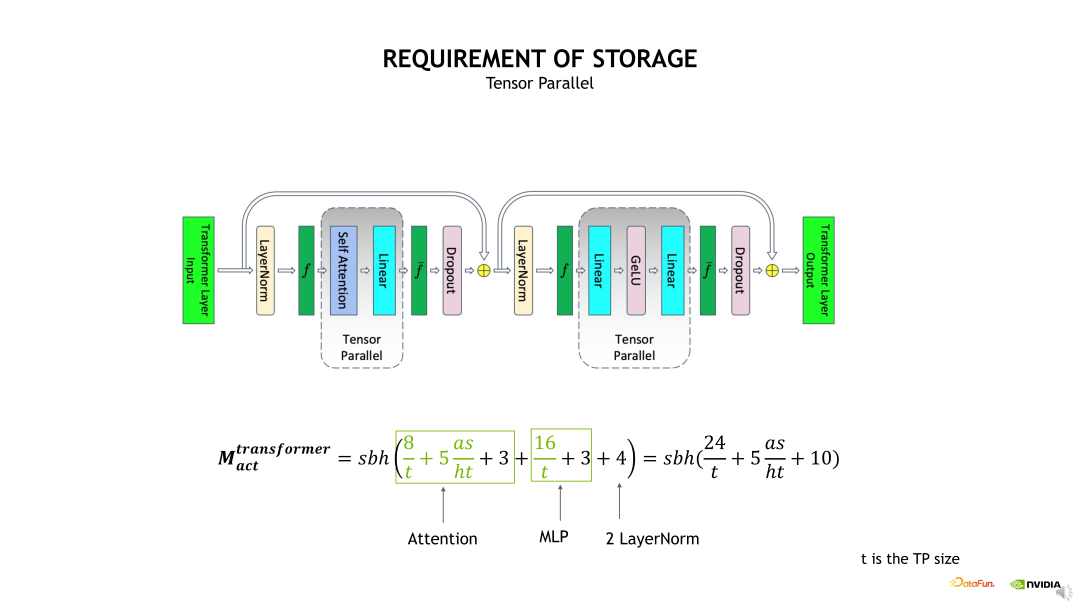
接下来介绍 Activation 显存开销。为简化问题,我们只分析单个 Transformer layer 的 Activation 显存占用。具体的计算方法是考虑每个 OP 计算输出的 shape 大小,将各个 OP 输出的 shape 加起来即可得到预计的显存开销大小。如下边示例图中的公式,从计算公式可以发现一个很大的问题,公式包含了一个s 即 Sequence 长度的平方项,当 s 比较大时,这个显存开销会变得非常恐怖,有必要进行优化。
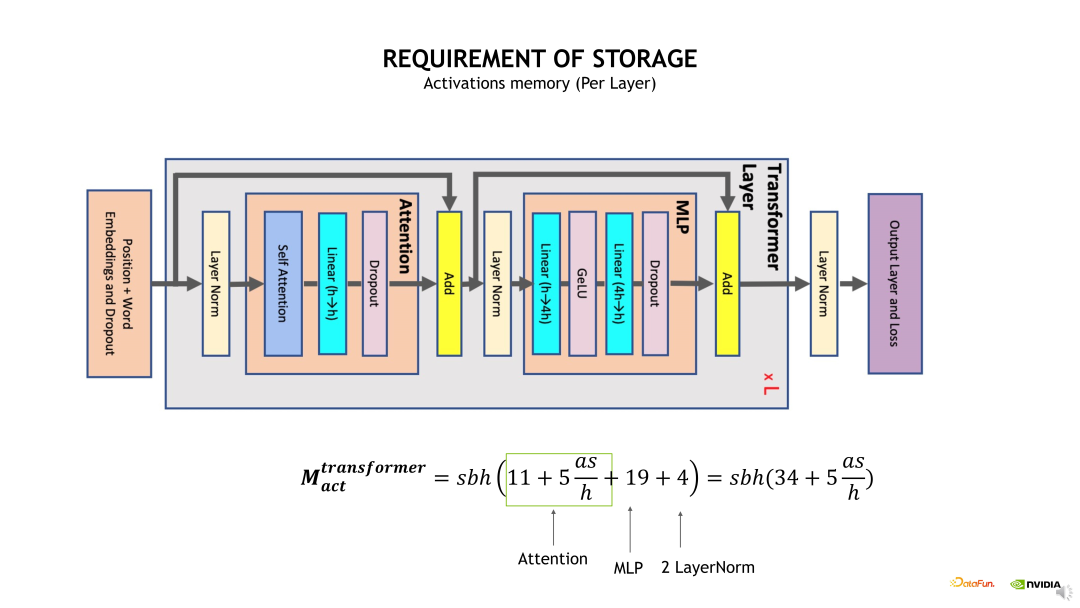
使用前面介绍的 Full checkpointing 优化方法可以有效减少 Activation 显存开销。在 Full checkpointing 中,仅存储每个 Transformer layer 的输出,且中间计算结果在 Backward 时直接重算,从而使得 Activation 显存开销计算变为 2bs*h。
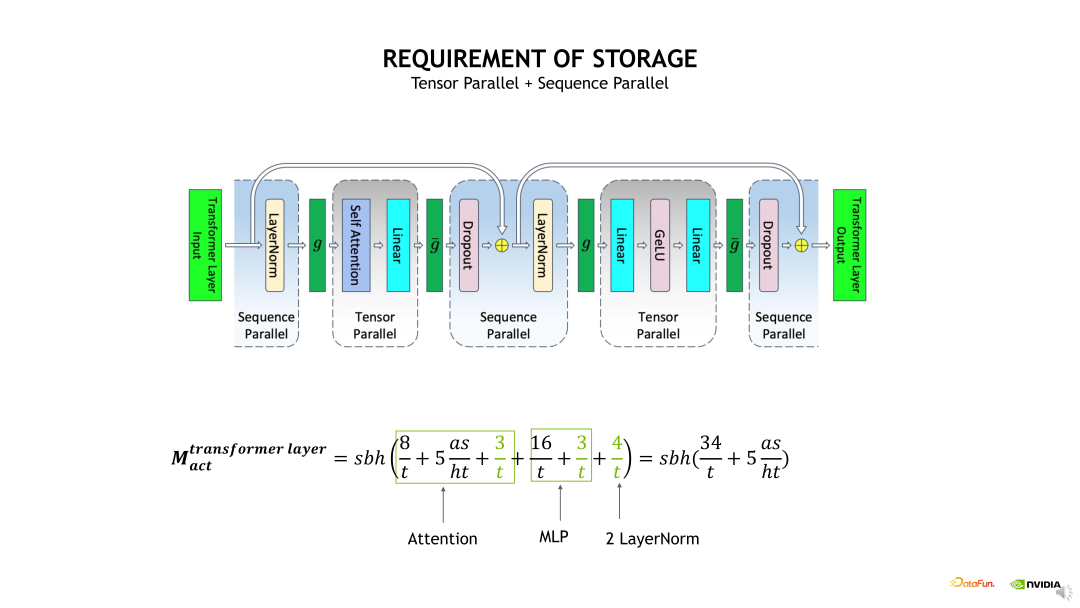
使用 TP 拆分,实际上就是对 Self-attention 和 MLP 进行了 TP 维度的拆分,将相应 QKV 和 FC 计算输出的 shape 除以 t,如果在这个基础上,再加上Sequence Parallelism 的话,会进一步对两个 Layernorm 输出的 shape 除以 t。在这个基础上继续使用 Selective checkpointing 时,就可以将这个 s 的平方给优化掉,因为我们会把这个 Self-attention 的输出 Activation 直接 Drop 掉。
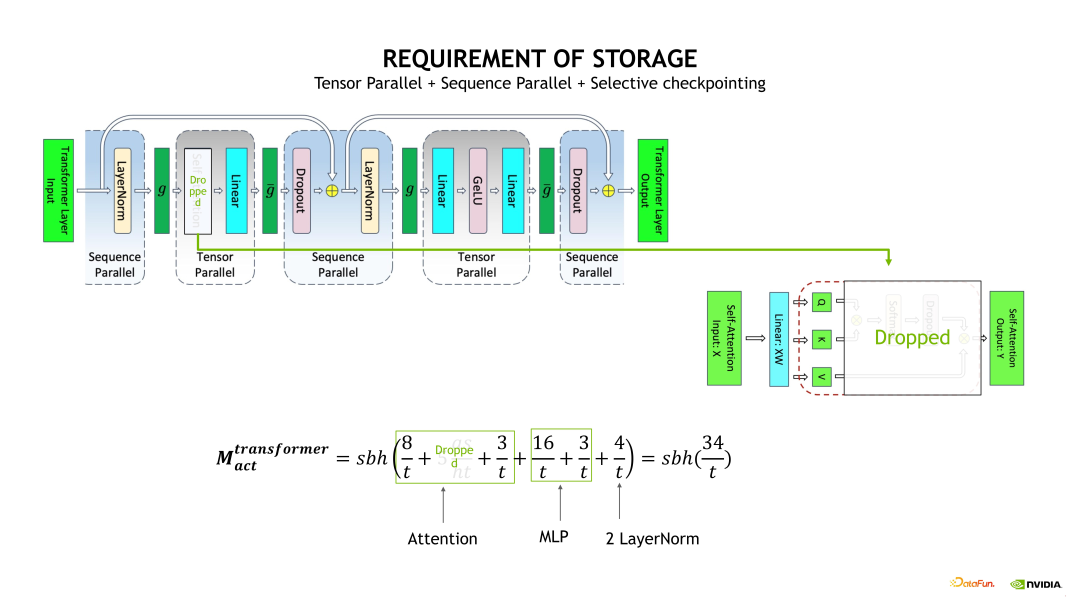
因此,整体的重算开销从 Full checkpointing 时的 36% 降低为TP+SP+Selective checkpointing 时的 4%,相应的显存开销从原先的 2.86GB 降低为 106MB。
通信资源计算公式
量化指标定义
我们知道分布式训练 HPN 中有 2 个网络,在先进 HPN 网络设计中,通常会把计算和存储这 2 个 RDMA 网络进行隔离,避免彼此之间的带宽抢占,所以需要区别讨论。以 DP 为例:
- 计算网络场景:all-reduce 进行梯度聚合,通信量由模型的参数大小和运算精度决定。
- 存储网络场景:DP Dataloader 加载 batch 样本数据,通信量由 DP Group 数量和 Batch size 决定。
这里我们主要讨论计算网络的带宽资源需求问题。并且关注以下指标:
- 每 Step 通信次数:完成一个 Step 训练过程中进行 NCCL 计算通信或 Dataload 存储通信的次数。
- 每 Step 通信量:完成一个 Step 所需要传输的数据量。
- 总计平均通信带宽速率:评估通信带宽速率的整体趋势,但受到极值影响。
- 瞬时最大通信带宽速率:评估过程中最大的通信带宽尖峰速率,取决于并行策略算法。
并行策略通信流程
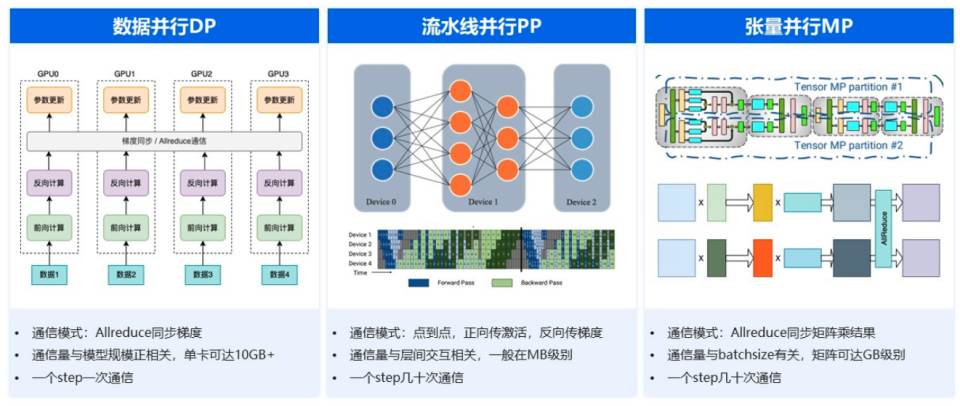
DP:网络上需要对各个 GPU 上的梯度做一次 Allreduce,通信的数据量规模和模型参数规模成正比,对于千亿规模参数的大模型来说数据通信量都是很大的。
- 每 Step 通信次数:通常每 Step 执行 1 次 all-reduce 梯度聚合与同步。但实际上取决于具体的 DP 优化算法,例如:有些优化算法会进行 "梯度累积",若干个 Step 累积一次 all-reduce 通信,以此来用满带宽。
- 每 Step 通信量:与模型参数量成正比,每 Step 通信量(Bytes) = 模型参数量(P) × 运算精度(Bytes/param)。以 Llama3.1 405B 为例,如果每 Step 通信一次,则一张 GPU 需要收发共计 405×10^9 × 2Bytes = 810GB 的数据。
- 单卡每 all-reduce 通信量:单张 GPU 实际通信量需要结合 PP 或 TP 模型切分,取决于每张 GPU 加载的参数大小。通常在 10GB 级别。
PP:在不同 GPU 之间做层间点到点数据传递,传输的内容包括正向计算里的激活值和反向计算里的梯度值。这种通信在一个迭代里至少会发生几十次,但通信量一般不大,对网络的性能要求相对较低。
- 每 Step 通信次数:取决于 Stage 的数量,每 Step 通信次数 = (Stage-1) x 2,正反向各一次。通常具有 16 个 Stage,共计 30 次通信。
- 每 Step 通信量:在不同的 Stage 之间采用 p2p 传递正向激活值和反向梯度,所以每 Step 通信量也取决于模型参数规模。
- 单卡每 p2p 通信量:因为 PP Group 数量众多,而且每 Step 通信次数较多,所以平摊的 PP 单次单卡通信量较小,通常只有 MB 级别。
TP:张量计算结果的大小,不仅和模型有关,也和训练使用的 Batch Size 相关,通常都非常大,并且在一次迭代里会发生很多次这样的 Allreduce。因此张量并行对网络带宽的需求是最大的。
- 每 Step 通信次数:取决于模型结构,例如 Transformer Decode-only 架构中,每 Layer 每 Step 会执行 4 次 all-reduce。以 Llama3.1 405B 模型为例,它有 126 Layers,也就是说每 Step 要执行 504 次 all-reduce。
- 每 Step 通信量 :TP 采用 all-reduce 聚合 Transformer MLP(d_modeld_ffn2)和 Self-Attention(4*d_model^2)与 Input(Batch Size)的矩阵乘结果。所以每 Step 通信量取决于模型结构中的 Layers、Model Dimension、FFN Dimension 和 Batch Size。
- 单卡每 all-reduce 通信量:由于 TP Group 的数量通常为单机 8 卡,所以平摊下来单卡单次通信量非常大,通常为几百几千 GB 级别。
通信量总结
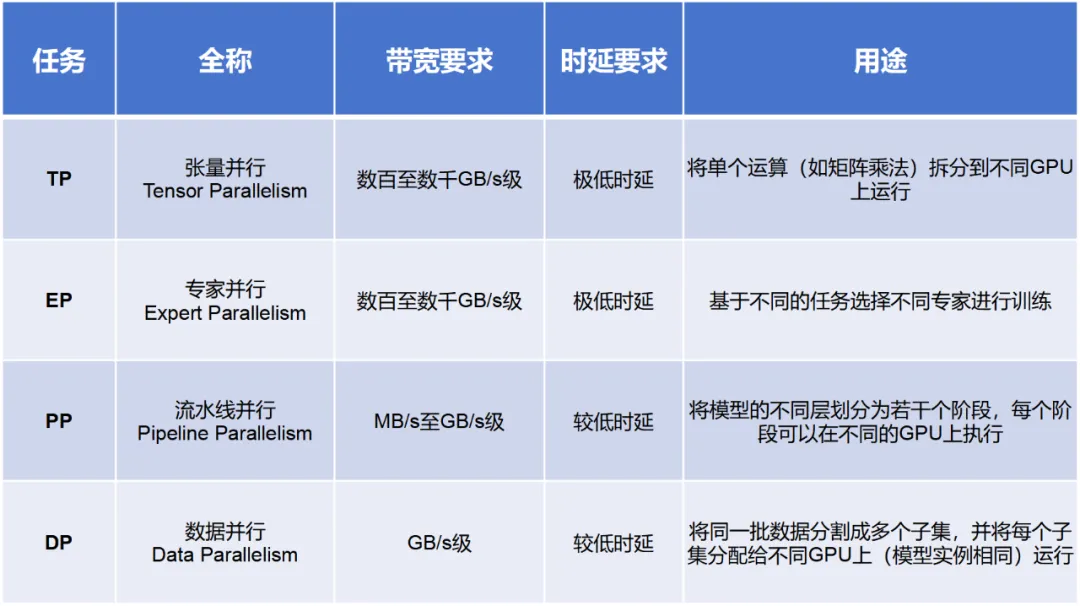
计算公式示例
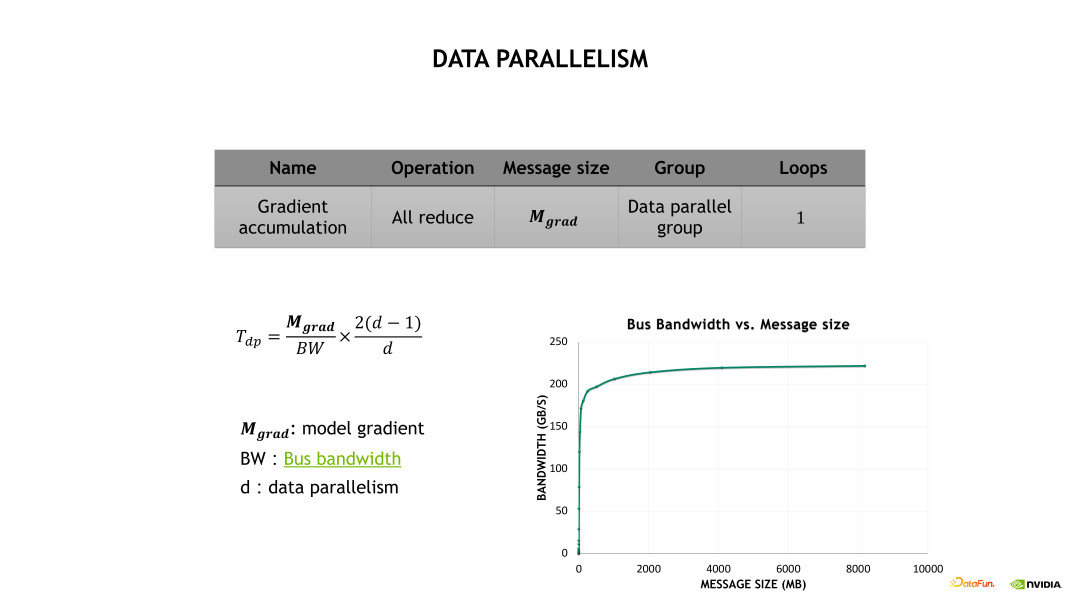
通信开销也分成 DP、TP 和 PP 三个部分。首先看下 DP 的通信开销,如下图所示,DP 的通信开销等于梯度通信的大小除以总线带宽,再乘以一个 All-reduce 系数,其中总线带宽需要根据实际的消息大小去测试出一个总线带宽的估计。
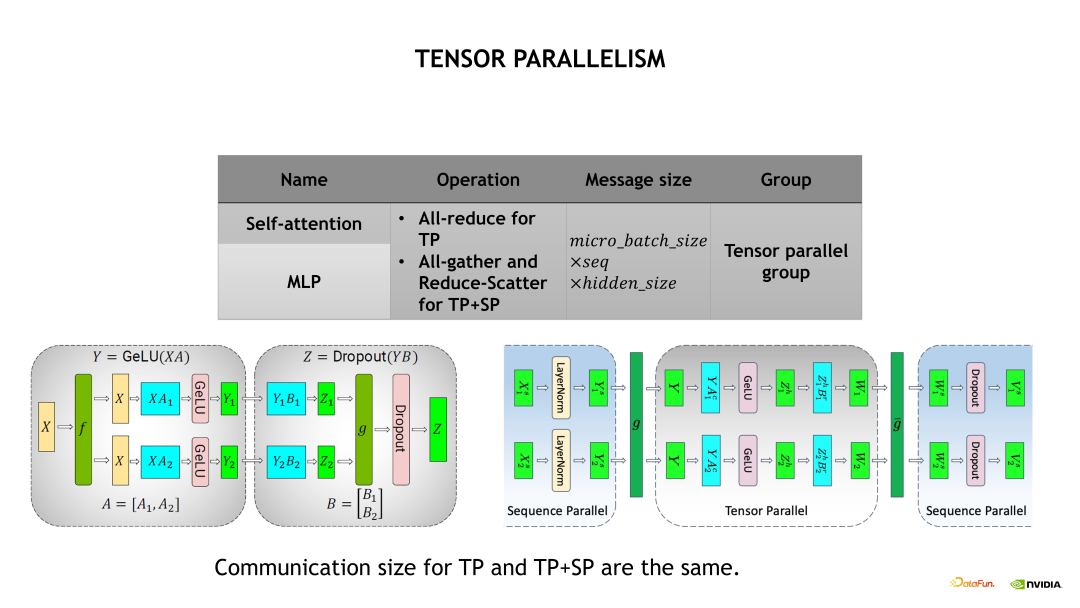
TP 和 TP+SP 两个优化方法的通信量大小是一致的。具体的 TP 通信开销计算如下边示例图中的公式,分成每次 TP 通信量的大小除以实际获得的总线带宽,再乘以一个 All-reduce 系数,再乘以 Self-attention 和 MLP 各做三次通信次数,再乘以 Transformer layer 的层数以及 mini batch 的数量。
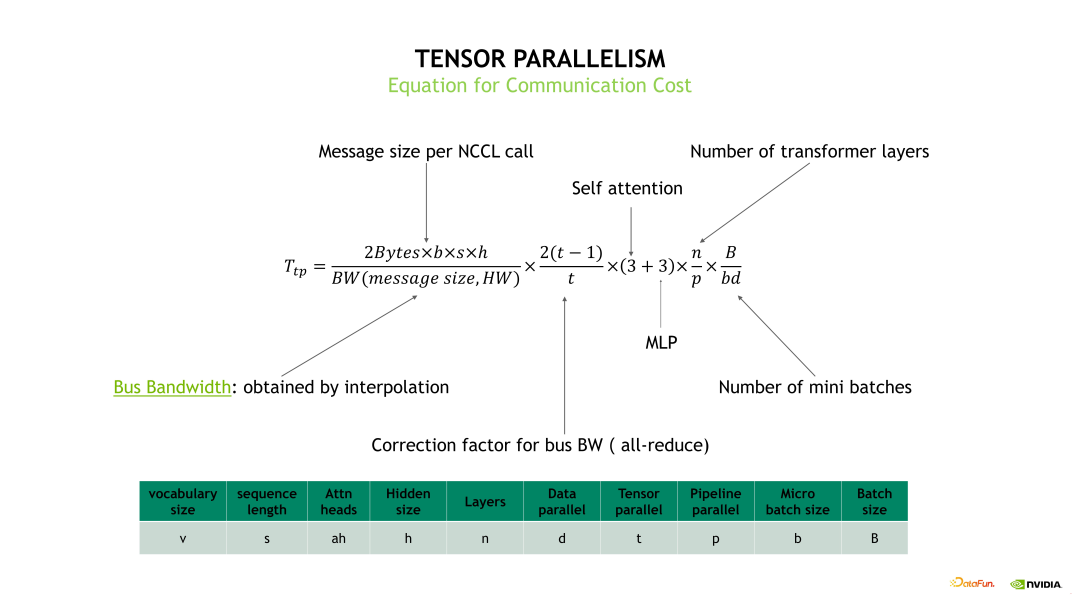
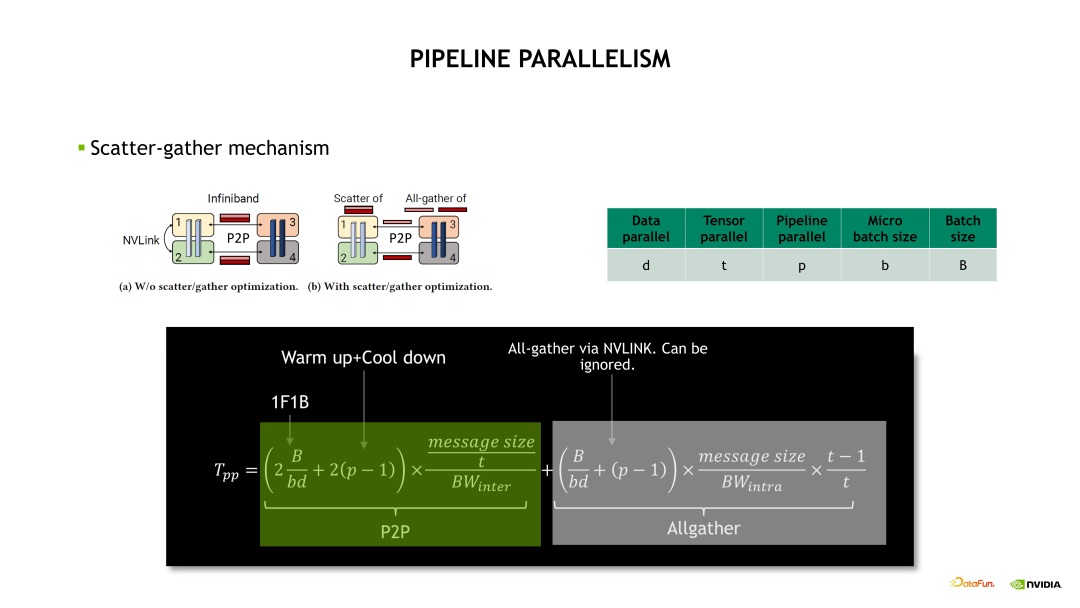
流水线并行的通信开销主要看下边的示例图的绿色部分,具体计算是首先获取单次通信的时间再乘以一个通信的次数。其中,通信次数包括了 1F1B 次数,再加上 Warm up 和 Cool down 的次数。
算力资源计算公式
- 训练所需总算量:
bash
总算量(FLOPs)= 模型参数量(P)× 6 × 样本数据量(T)- 根据 GPT-3 论文中提出的 "6×P×T" 定律,每个 P 在一次 Epoch(处理完所有样本数据量)中需要进行 6×T 次运算,其中 Forward 需要 2×T 次,Backward 需要 4×T 次。
- 总算量单位为 FLOPs(运算次数)表示总量,而不是使用 FLOPS(运算次数/秒)表示速率。
- 单卡每日有效算量:
bash
单卡每日有效算量(FLOPs/day) = 单卡算力(FLOPS)× MFU(模型算力利用率) × 3600*24(秒)- 每日算量单位为 FLOPs/day = FLOPS(运算次数/秒)× 3600*24(秒)
- MFU:实际训练中,因通信、数据加载等开销,GPU 算力无法 100% 利用,常用假设为 40%。Llama3.1 MFU 在 38%-43% 之间。
- 算力成本计算:
bash
算力成本 = 卡数 × 天数 × 单卡日租金
#卡数固定,求天数 = 总算量 / (单卡每日有效算量 × 卡数)
#天数固定,求卡数 = 总算量 / (单卡每日有效算量 × 天数)- 天数固定:市场竞争场景,比如每 30~60 天必须更新一次模型以维持市场地位。
- 卡数固定:存量资源场景,比如使用一期采购的 GPU 卡进行训练。
| H100 | 指标 |
|---|---|
| BF16 | 989T |
| 显存 | 80GB |
| 访存带宽 | 3.35T |
| NVLink 互联 | 900GB |
| RDMA 机间互联 | 400Gb * 8 |
下面以 H100 训练 LLaMA3.1 405B 为例,计算训练一轮(Epoch)所需要的时间和成本:
- 模型参数量:405B(405×10^9)
- 样本数据量:15T tokens(15×10^12)
- BF16 FLOPS:989 T(989×10^12)
- MFU:40%
- 单卡日租金:350 元/卡/天
- 卡数:Meta Llama3.1 405B 使用了约 24000 张 H100。
bash
# 训练所需总算力(FLOPS)= 模型参数量(P)× 6 × 样本数据量(T)
总算量 = 6 × 405×10^9 × 15×10^12 = 6 × 405 × 15 × 10^21 = 36.45×10^24 FLOPs
# 单卡每日有效算力(FLOPS/d) = 单卡算力(FLOPS) × MFU(模型算力利用率)× 3600*24(秒)
单卡每日有效算量 = 989×10^12 × 0.4 × 3600×24 = 989×10^12 × 0.4 × 86400 ≈ 3.43×10^19 FLOPs/day
# 卡数固定,求天数 = 总算力 / (单卡每日有效算力 × 卡数)
天数 = 36.45×10^24 / (3.43×10^19 × 24000) ≈ 45day
# 算力成本 = 卡数 × 天数 × 单卡日租金
算力成本 = 24000 × 45 × 350 = 3亿7千8百万这是一个理想的估计值。因为在实际训练时候不可避免地会遇到一些例如 Checkpoint、Save 与 Load 的时间、节点崩溃及重启时间,或者我们需要取 Debug loss 曲线不正常的时间,因此实际的训练时间会远超过这个理想估计时间。
实际上,Meta LIama3.1 405B 使用 24000 张 H100 总计训练了 54 天,因为 Llama3.1 平均 3h 就会发生一次故障,其中 78% 是硬件问题导致。而 70B 则需要 5k 卡,50 多天进行训练。(论文:https://arxiv.org/pdf/2407.21783)
下图是来 Megatron 论文的公式去计算一个模型训练时需要的计算 FLOPS,例如 GPT-3 175B 模型使用比较合理的 1.5T Tokens 数据量训练,大概需要 128 个 DGX A100 节点,共计 1024 张 A100 卡,在效率比较高的条件下连续训练 120 天。

计算公式示例
示例图左边的是对 Self-attention、FFN 和 Logit 层的计算拆解,主要计算一些 Linear 层的 FLOPS。将这些 FLOPS 加起来就得到单个 Transformer layer 的 FLOPS,然后再乘上 Batch 数量以及层数就能得到整体的模型 FLOPS。
通过模型 FLOPS 可以衡量整个训练系统的效率是否足够好。例如针对 GPT-3 175B 而言,如果它的模型 FLOPS 在 A100 上小于 150 TFLOPS,说明训练可能是有一点问题的,如果小于 120TFLOPS 说明训练肯定有一些比较严重的异常问题,造成速度下降。

训练优化思路
推荐使用混合精度、Flash attention 以及 Megatron 上大量的默认优化 OP。其次是半精度训练选择,比如要选择用 BF16 还是 FP16,对于大模型训练推荐优先考虑 BF16,因为 FP16 会有很多潜在的问题和坑,使用 BF16 会比较稳定,尤其是对 20B 以上的模型,推荐大家只用 BF16。
如果训练运行起来有显存开销问题,可以依次打开这些优化,首先可以尝试使用 Selective activation checkpointing,然后开启 Distributed Optimizer,之后逐渐开启 TP。我们不需要一开始就将 TP 设置成 8,这里有个准则,需要评判 Hidden size 除以 TP 后不能小于 1024,最好要大于 2048,这样会有一个比较好的收益。之后逐渐地去开启 PP。不要一开始就将 PP 设置得很大,然后可以用 Full activation checkpointing。
如果不会遇到 OOM,并且 GBS 能开的足够大,那么尽量使用 DP 去扩展即可。
