【前瞻创想】Kurator云原生实战:打造企业级分布式云原生基础设施的完整指南与深度实践
- 【前瞻创想】Kurator云原生实战:打造企业级分布式云原生基础设施的完整指南与深度实践
- 摘要
-
- [1. Kurator概述与核心价值](#1. Kurator概述与核心价值)
-
- [1.1 什么是Kurator:分布式云原生平台定义](#1.1 什么是Kurator:分布式云原生平台定义)
- [1.2 Kurator的技术架构与核心组件](#1.2 Kurator的技术架构与核心组件)
- [1.3 Kurator在企业数字化转型中的战略地位](#1.3 Kurator在企业数字化转型中的战略地位)
- [2. Kurator环境搭建与基础配置](#2. Kurator环境搭建与基础配置)
-
- [2.1 环境准备与依赖安装](#2.1 环境准备与依赖安装)
- [2.2 Kurator源码获取与编译](#2.2 Kurator源码获取与编译)
- [2.3 基础集群初始化与验证](#2.3 基础集群初始化与验证)
- [3. Fleet多集群管理深度实践](#3. Fleet多集群管理深度实践)
-
- [3.1 Fleet架构解析与核心概念](#3.1 Fleet架构解析与核心概念)
- [3.2 多集群资源统一编排与调度](#3.2 多集群资源统一编排与调度)
- [3.3 跨集群服务发现与通信实现](#3.3 跨集群服务发现与通信实现)
- [4. GitOps在边缘计算中的创新应用](#4. GitOps在边缘计算中的创新应用)
-
- [4.1 GitOps理念与Kurator的融合](#4.1 GitOps理念与Kurator的融合)
- [4.2 FluxCD与Helm应用分发实践](#4.2 FluxCD与Helm应用分发实践)
- [4.3 边缘节点自动化配置与管理](#4.3 边缘节点自动化配置与管理)
- [5. Karmada集成与跨集群弹性伸缩](#5. Karmada集成与跨集群弹性伸缩)
-
- [5.1 Karmada与Kurator架构融合](#5.1 Karmada与Kurator架构融合)
- [5.2 跨集群工作负载分发策略](#5.2 跨集群工作负载分发策略)
- [5.3 动态弹性伸缩实现与优化](#5.3 动态弹性伸缩实现与优化)
- [6. Volcano调度架构与批处理优化](#6. Volcano调度架构与批处理优化)
-
- [6.1 Volcano核心组件与调度原理](#6.1 Volcano核心组件与调度原理)
- [6.2 队列管理与资源隔离实践](#6.2 队列管理与资源隔离实践)
- [6.3 AI/ML工作负载调度优化案例](#6.3 AI/ML工作负载调度优化案例)
- [7. Kurator网络架构与故障排查](#7. Kurator网络架构与故障排查)
-
- [7.1 多集群网络连通性设计](#7.1 多集群网络连通性设计)
- [7.2 隧道技术在边缘场景的应用](#7.2 隧道技术在边缘场景的应用)
- [7.3 常见网络问题诊断与解决方法](#7.3 常见网络问题诊断与解决方法)
- [8. Kurator未来展望与最佳实践](#8. Kurator未来展望与最佳实践)
-
- [8.1 Kurator技术路线图分析](#8.1 Kurator技术路线图分析)
- [8.2 企业落地Kurator的关键成功因素](#8.2 企业落地Kurator的关键成功因素)
- [8.3 分布式云原生技术发展趋势](#8.3 分布式云原生技术发展趋势)
【前瞻创想】Kurator云原生实战:打造企业级分布式云原生基础设施的完整指南与深度实践
摘要
本文深入解析开源分布式云原生平台Kurator的技术架构与实践应用,从环境搭建到多集群管理,从边缘计算到批处理调度,全方位展现Kurator如何帮助企业构建统一的云原生基础设施。通过Fleet多集群管理、Karmada集成、Volcano调度优化等核心功能的深度实践,结合企业真实场景案例,揭示Kurator在多云、边缘云和混合云环境中的独特价值。文章不仅提供可落地的技术方案,还从架构设计角度剖析分布式云原生技术的演进趋势,为企业数字化转型提供前瞻性指导。
1. Kurator概述与核心价值
1.1 什么是Kurator:分布式云原生平台定义

Kurator是一个开源的分布式云原生平台,它站在众多流行云原生软件栈的肩膀上,包括Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等。Kurator的核心价值在于帮助企业构建自己的分布式云原生基础设施,加速企业数字化转型进程。在当今多云、混合云和边缘计算成为主流的背景下,Kurator提供了统一的管理平面,解决了资源分散、管理复杂、运维困难等行业痛点。
与传统的单一集群管理工具不同,Kurator从设计之初就以分布式架构为核心,支持多云、边缘云、边缘-边缘协同等多种场景。它不仅仅是一个工具集合,而是一个有机整合的平台,通过标准化的接口和统一的数据模型,将不同环境下的云原生能力无缝连接起来,为企业提供端到端的解决方案。
1.2 Kurator的技术架构与核心组件
Kurator的技术架构参考图:
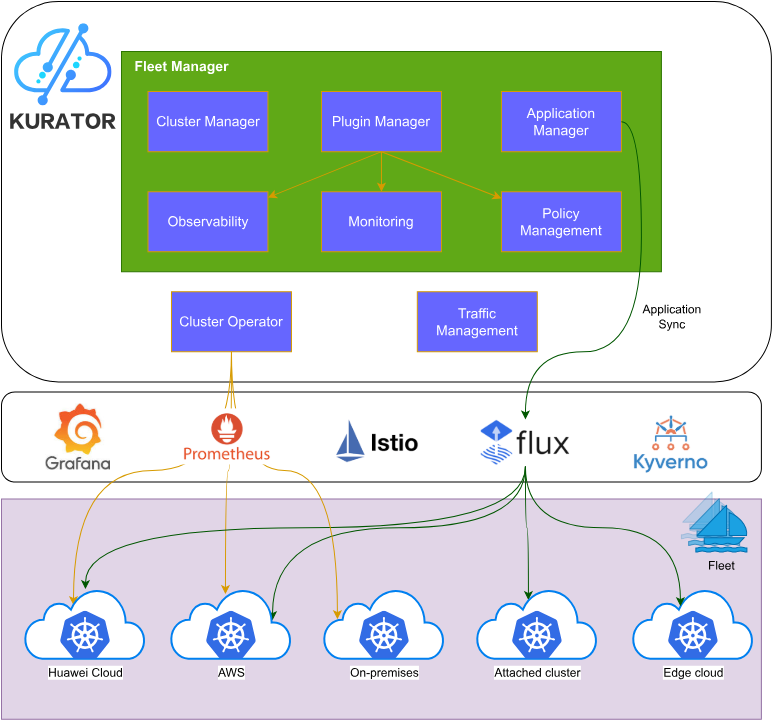
Kurator的架构设计体现了"分层解耦、能力复用"的思想。底层是基础设施层,支持公有云、私有云、边缘节点等多种环境;中间是能力抽象层,将Kubernetes、Karmada、KubeEdge等开源项目的能力进行标准化封装;上层是业务应用层,提供统一的API和服务接口。
核心组件包括:
- Fleet Manager:负责多集群的统一管理和资源编排
- GitOps Engine:基于FluxCD的声明式配置管理
- Policy Engine:基于Kyverno的策略管理和合规检查
- Edge Controller:基于KubeEdge的边缘节点管理
- Batch Scheduler:基于Volcano的批处理作业调度
- Service Mesh Integration:与Istio集成的流量管理
这些组件不是简单的堆砌,而是通过精心设计的接口和数据流进行深度集成,形成了一个有机的整体。例如,Fleet Manager不仅管理集群注册和注销,还负责跨集群的服务发现、身份同步和策略统一,这在实际企业环境中具有极高的价值。
1.3 Kurator在企业数字化转型中的战略地位
在企业数字化转型过程中,云原生技术已经从"可选项"变成了"必选项"。然而,许多企业面临着云原生技术栈复杂、学习曲线陡峭、运维成本高等挑战。Kurator通过提供"开箱即用"的云原生软件栈和统一的管理界面,大大降低了企业采用云原生技术的门槛。
更重要的是,Kurator支持基础设施即代码(Infrastructure-as-Code)的理念,允许企业以声明式的方式管理集群、节点、VPC等基础设施资源。这种模式不仅提高了运维效率,还增强了系统的可预测性和可审计性,符合现代IT治理的要求。在金融、制造、零售等传统行业中,这种能力对于实现安全、可控的数字化转型至关重要。
2. Kurator环境搭建与基础配置
2.1 环境准备与依赖安装
在开始搭建Kurator环境之前,需要准备以下基础环境:
- 一台或多台Linux服务器(推荐Ubuntu 20.04+或CentOS 7+)
- Kubernetes集群(版本1.20+)
- Docker或containerd运行时
- Git、curl、wget等基础工具
- 足够的CPU、内存和存储资源
首先安装必要的依赖:
bash
# Ubuntu/Debian系统
sudo apt-get update
sudo apt-get install -y git curl wget jq make gcc
# CentOS/RHEL系统
sudo yum install -y git curl wget jq make gcc
# 安装kubectl
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
chmod +x kubectl
sudo mv kubectl /usr/local/bin/还需要确保Kubernetes集群已经正确配置,可以通过kubectl cluster-info命令验证集群状态。
2.2 Kurator源码获取与编译
获取Kurator源码有两种方式,根据要求使用wget命令:
bash
# 使用wget获取源码
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
unzip main.zip
cd kurator-main
# 或者使用git clone
# git clone https://github.com/kurator-dev/kurator.git
# cd kurator
下载下来以后,我们解压即可看到源码啦!
编译Kurator组件:
bash
# 安装Go依赖(如果尚未安装)
wget https://golang.org/dl/go1.18.linux-amd64.tar.gz
sudo tar -C /usr/local -xzf go1.18.linux-amd64.tar.gz
export PATH=$PATH:/usr/local/go/bin
# 编译Kurator
make build编译完成后,会在_output/bin/目录下生成可执行文件。也可以使用Docker镜像方式运行,这样可以避免环境依赖问题:
bash
# 构建Docker镜像
make docker-build
# 验证构建结果
docker images | grep kurator2.3 基础集群初始化与验证
初始化Kurator集群需要创建必要的CRD(Custom Resource Definitions)和系统组件:
bash
# 应用Kurator CRD
kubectl apply -f config/crd/bases
# 部署Kurator控制器
kubectl apply -f config/default
# 验证部署状态
kubectl get pods -n kurator-system部署完成后,可以通过以下命令验证Kurator是否正常工作:
bash
# 检查Kurator API资源
kubectl api-resources | grep kurator
# 创建测试Fleet资源
cat <<EOF | kubectl apply -f -
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: test-fleet
spec:
clusters:
- name: member1
kubeconfigSecret: member1-kubeconfig
EOF
# 验证Fleet状态
kubectl get fleet test-fleet -o yaml如果看到Fleet资源状态为"Ready",说明Kurator基础环境搭建成功。这一步是后续所有高级功能的基础,必须确保每个组件都正常运行。
3. Fleet多集群管理深度实践
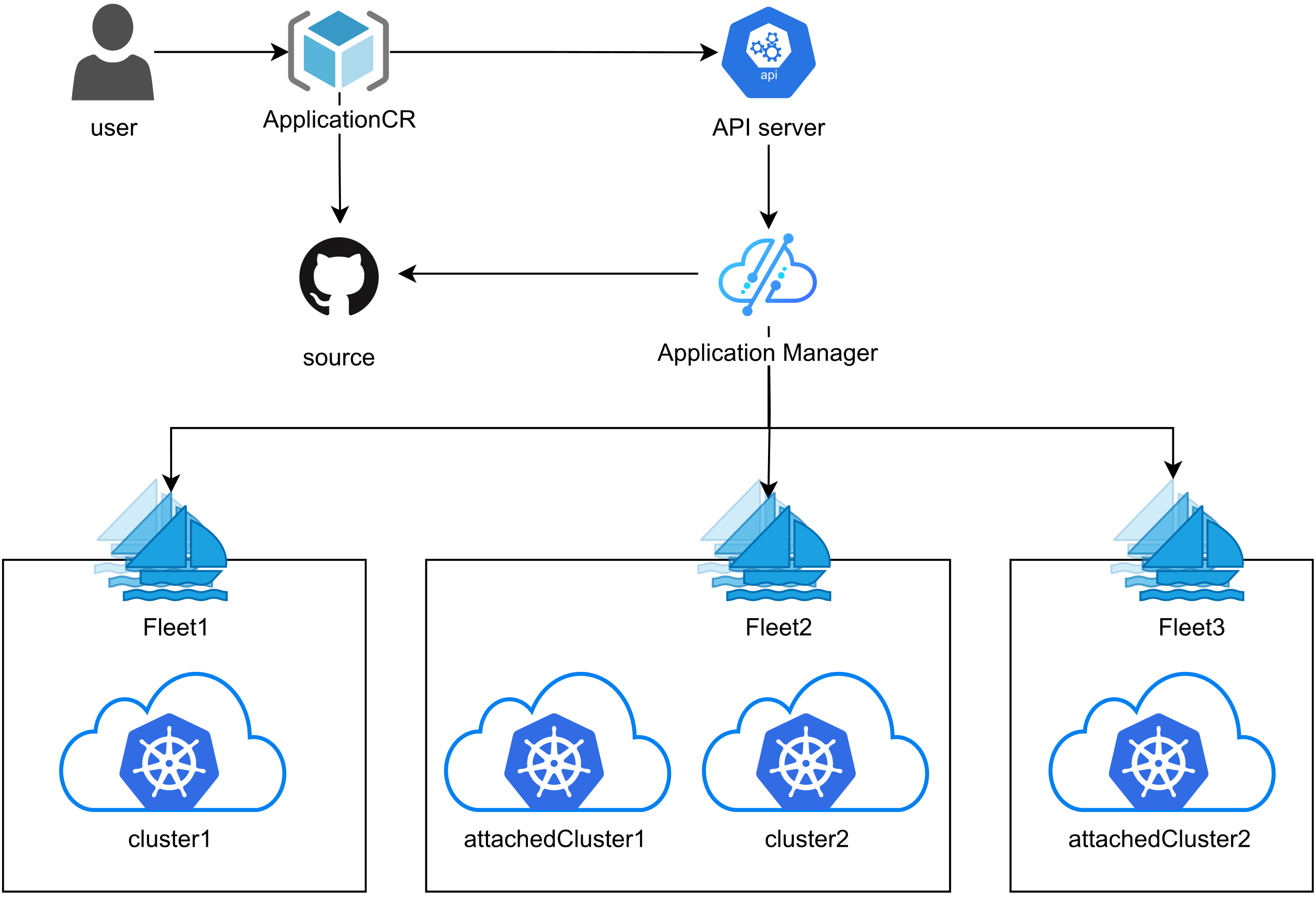
Fleet 的集群注册过程,可以看看下图的过程:
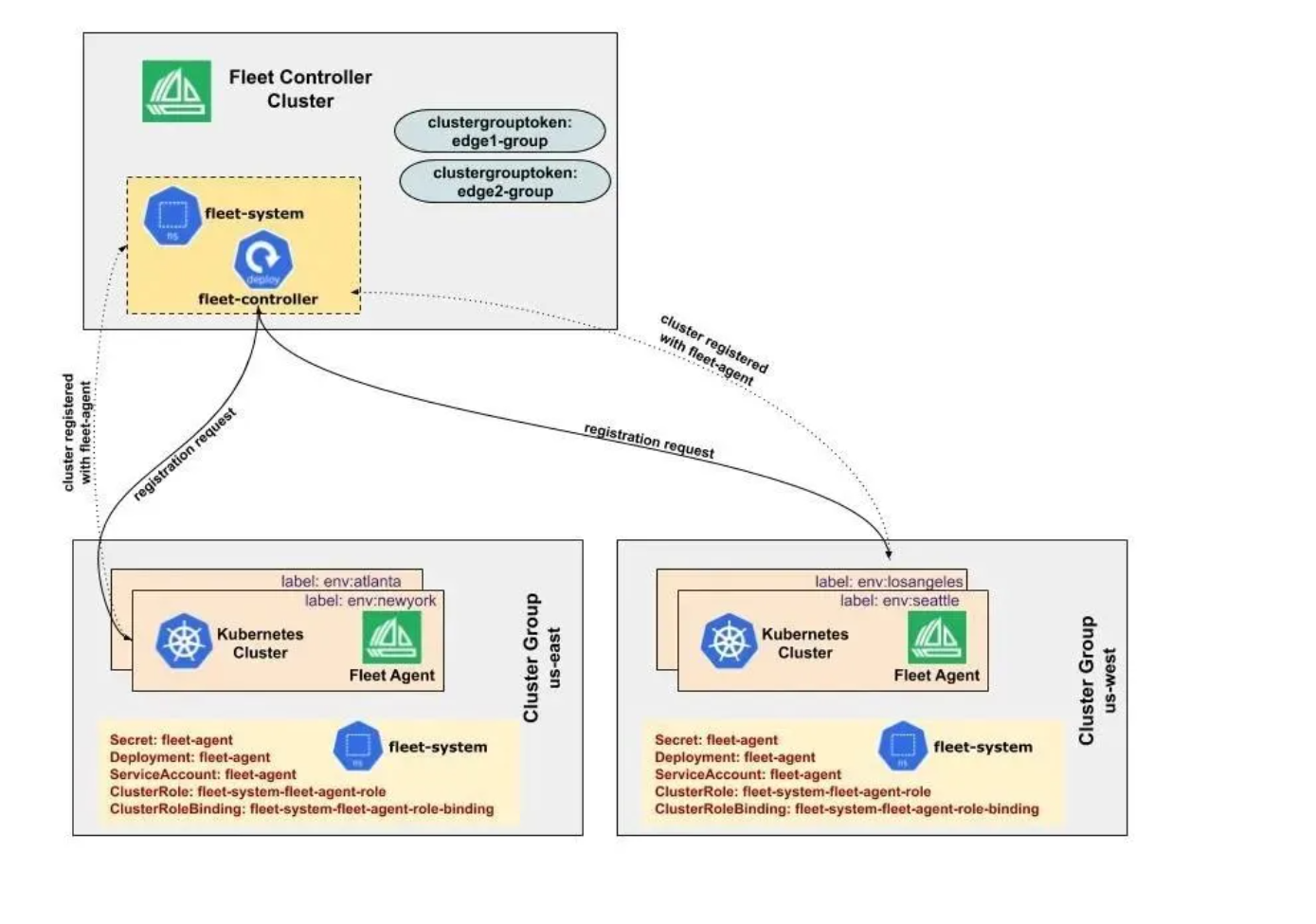
3.1 Fleet架构解析与核心概念
Fleet架构参考图,朋友们可以详看下图:
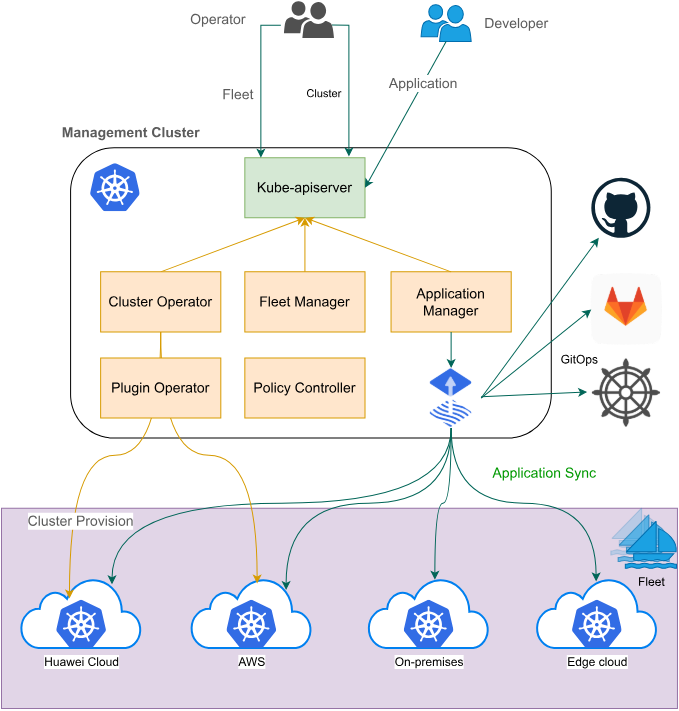
Fleet是Kurator中用于管理多集群的核心抽象,它不仅仅是一个集群集合,更是一个逻辑上的管理单元。Fleet架构包含以下几个关键概念:
- Fleet Controller:负责协调Fleet内所有集群的生命周期
- Cluster Registration:支持集群注册和注销到Fleet
- Resource Propagation:定义资源如何在Fleet内各集群间同步
- Policy Enforcement:确保所有集群遵循统一的策略
Fleet的设计哲学是"同质化管理,异构化执行"。这意味着在管理层面,所有集群被视为一个逻辑整体;在执行层面,每个集群可以根据自身特性进行差异化处理。这种设计特别适合混合云场景,例如同时管理AWS、Azure和私有云集群。
在架构上,Fleet Controller运行在中心集群(Hub Cluster)上,通过安全的网络连接与成员集群(Member Clusters)通信。通信采用基于证书的身份验证和TLS加密,确保安全性。Fleet Controller会定期同步各集群的状态,处理资源分发和策略执行。
3.2 多集群资源统一编排与调度
Kurator通过Fleet实现了多集群资源的统一编排。下面是一个实际案例:在电商大促期间,需要在多个区域部署相同的应用,但每个区域的资源配置可能不同。
yaml
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
meta
name: ecommerce-app
spec:
selector:
fleet: production-fleet
topology:
- cluster: us-east-1
replicas: 10
resources:
requests:
memory: "512Mi"
cpu: "500m"
- cluster: eu-west-1
replicas: 8
resources:
requests:
memory: "512Mi"
cpu: "500m"
- cluster: ap-southeast-1
replicas: 6
resources:
requests:
memory: "256Mi"
cpu: "250m"
template:
deployment:
meta
name: frontend
spec:
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend
image: ecommerce/frontend:v1.2
ports:
- containerPort: 80这个Application定义展示了如何在不同集群中部署相同的应用,但根据区域流量和成本考虑,配置不同的副本数和资源请求。Kurator会自动将这个定义转换为各个集群中的具体Deployment资源,并确保状态一致。
3.3 跨集群服务发现与通信实现
在多集群环境中,服务发现和通信是最具挑战性的问题之一。Kurator通过Fleet提供了统一的服务发现机制。核心思想是:在Fleet内,相同名称的Service被视为同一个逻辑服务,无论它们部署在哪个物理集群中。
实现跨集群服务通信需要解决以下几个问题:
- 服务注册与发现
- 跨集群DNS解析
- 网络连通性
- 负载均衡策略
Kurator的解决方案是结合CoreDNS和Service Mesh技术。下面是一个跨集群服务发现的配置示例:
yaml
apiVersion: networking.kurator.dev/v1alpha1
kind: ServiceExport
meta
name: user-service
spec:
serviceRef:
name: user-service
namespace: default
fleet: global-fleet
---
apiVersion: networking.kurator.dev/v1alpha1
kind: ServiceImport
meta
name: user-service-import
spec:
serviceRef:
name: user-service
namespace: default
fleet: global-fleet
ports:
- port: 80
protocol: TCPServiceExport将本地服务暴露给Fleet,ServiceImport则从Fleet导入远程服务。Kurator会在后台自动配置DNS记录和网络路由,使得应用代码无需修改即可访问跨集群服务。这种设计大大简化了微服务架构在多集群环境中的部署复杂度。
4. GitOps在边缘计算中的创新应用
边缘计算中的 GitOps,详见下面参考图:
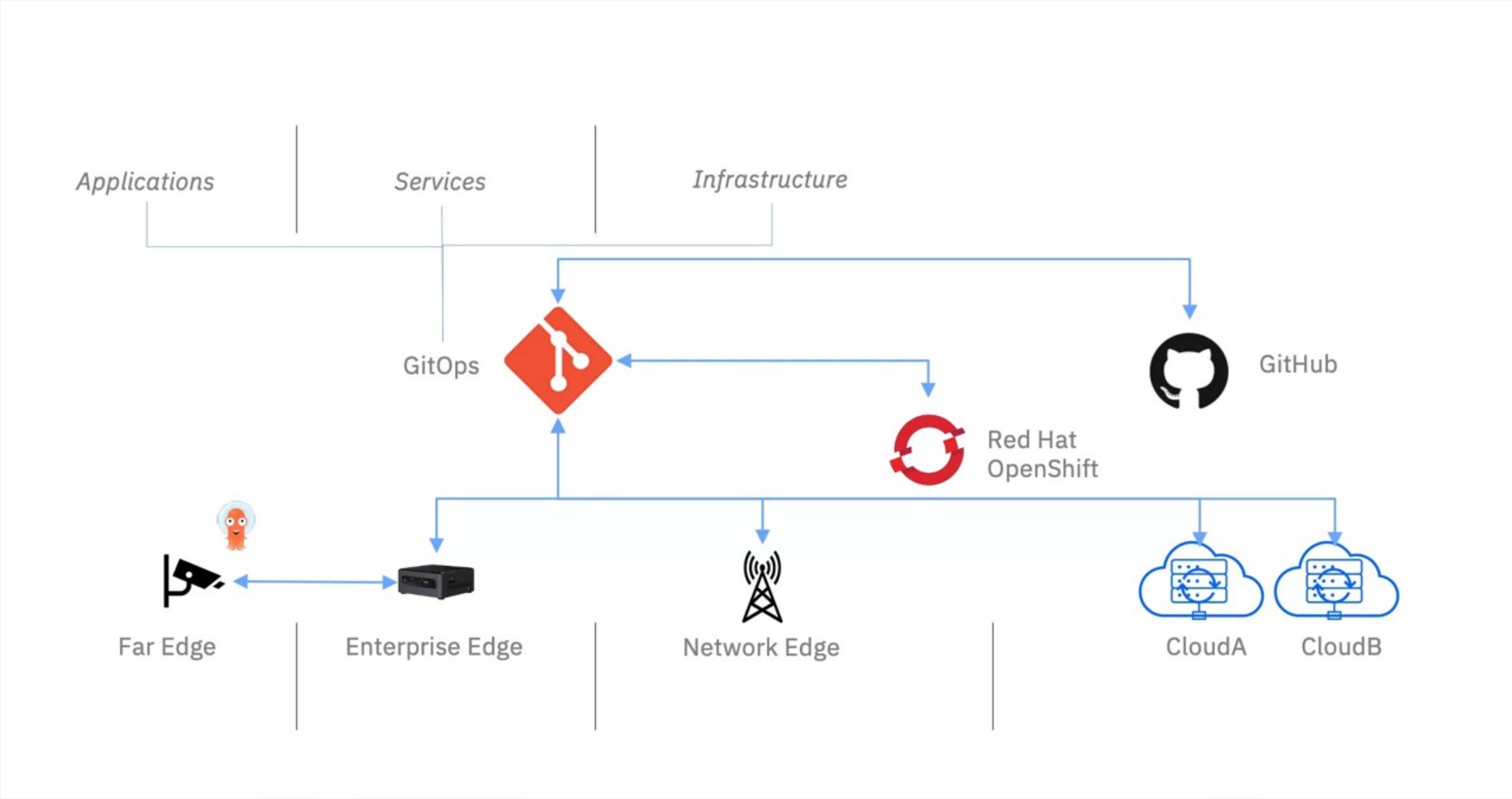
4.1 GitOps理念与Kurator的融合
GitOps是一种以Git仓库作为单一事实源的运维模式,它将基础设施和应用配置声明式地存储在Git中,并通过自动化工具确保运行环境与Git中的声明状态一致。Kurator将GitOps理念深度集成到其架构中,特别是在边缘计算场景中展现了独特价值。
在边缘计算环境中,网络不稳定、节点资源有限、地理位置分散是常态。传统的中心化管理方式往往难以应对这些挑战。GitOps的声明式特性和最终一致性保证,为边缘计算提供了理想的管理模型。Kurator基于FluxCD构建了强大的GitOps引擎,支持多集群、多环境的配置同步。
Kurator对GitOps的创新在于将边缘节点也纳入GitOps工作流。传统的GitOps主要关注集群层面的配置,而Kurator扩展到了节点和设备层面。通过KubeEdge的云边协同能力,Kurator可以将Git仓库中的配置自动同步到边缘节点,即使在网络断开的情况下,边缘节点也能基于本地缓存继续运行,并在网络恢复后自动同步状态差异。
4.2 FluxCD与Helm应用分发实践
FluxCD Helm 应用的示意图:
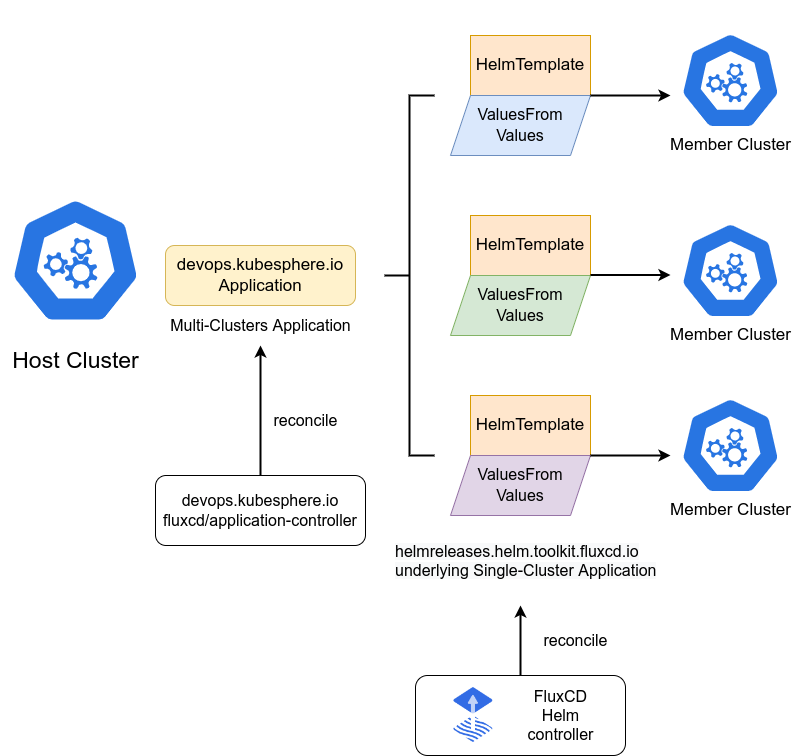
Kurator集成了FluxCD作为GitOps引擎,支持Helm Chart的自动化部署。下面是一个完整的FluxCD Helm应用分发配置示例:
yaml
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
meta
name: kurator-charts
namespace: flux-system
spec:
interval: 1m0s
url: https://kurator-dev.github.io/charts
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: monitoring-stack
namespace: monitoring
spec:
chart:
spec:
chart: kube-prometheus-stack
sourceRef:
kind: HelmRepository
name: kurator-charts
version: "30.0.1"
interval: 5m
targetNamespace: monitoring
values:
prometheus:
prometheusSpec:
replicas: 2
resources:
requests:
memory: 400Mi
cpu: 200m
grafana:
adminPassword: "admin123"
persistence:
enabled: true
size: 10Gi这个配置定义了两个关键资源:HelmRepository指定了Chart仓库的位置,HelmRelease定义了如何部署具体的Helm Chart。Kurator会自动监控Git仓库的变化,当检测到配置更新时,会自动应用变更到目标集群。这种模式确保了所有环境的配置一致性,大大减少了人为错误。
在边缘场景中,可以通过Fleet机制将相同的HelmRelease分发到多个边缘集群,但根据边缘节点的资源限制,动态调整values中的资源配置。例如,边缘节点可能只需要单副本的Prometheus,而中心集群需要多副本高可用部署。
4.3 边缘节点自动化配置与管理
边缘计算的特殊性要求配置管理必须考虑离线场景和资源限制。Kurator通过结合KubeEdge和GitOps,实现了边缘节点的自动化配置管理。下面是一个边缘应用部署的完整示例:
yaml
apiVersion: apps.kurator.dev/v1alpha1
kind: EdgeApplication
meta
name: edge-ai-inference
spec:
selector:
fleet: edge-fleet
nodeLabels:
edge-type: industrial
topologyPolicy: PreferClosest
template:
deployment:
metadata:
name: ai-inference
spec:
selector:
matchLabels:
app: ai-inference
template:
meta
labels:
app: ai-inference
spec:
containers:
- name: inference
image: edge-ai/inference:v1.0
resources:
limits:
cpu: "1"
memory: "512Mi"
nvidia.com/gpu: "1"
volumeMounts:
- name: model-cache
mountPath: /models
volumes:
- name: model-cache
hostPath:
path: /var/lib/edge/models
syncPolicy:
automated:
prune: true
selfHeal: true
retryInterval: 5m这个EdgeApplication定义包含了几个关键特性:
- 节点选择器:只部署到标记为"industrial"类型的边缘节点
- 拓扑策略:PreferClosest策略确保应用部署在离数据源最近的节点
- 资源限制:明确指定GPU资源需求,适应边缘AI场景
- 同步策略:支持自动修复和定期重试,适应边缘网络不稳定的特性
通过GitOps工作流,运维人员只需将这个配置提交到Git仓库,Kurator就会自动将应用部署到符合条件的边缘节点。当边缘节点离线时,本地KubeEdge组件会缓存配置,待网络恢复后自动同步。这种模式大大简化了大规模边缘节点的管理复杂度。
5. Karmada集成与跨集群弹性伸缩

5.1 Karmada与Kurator架构融合
Karmada 架构参考图:
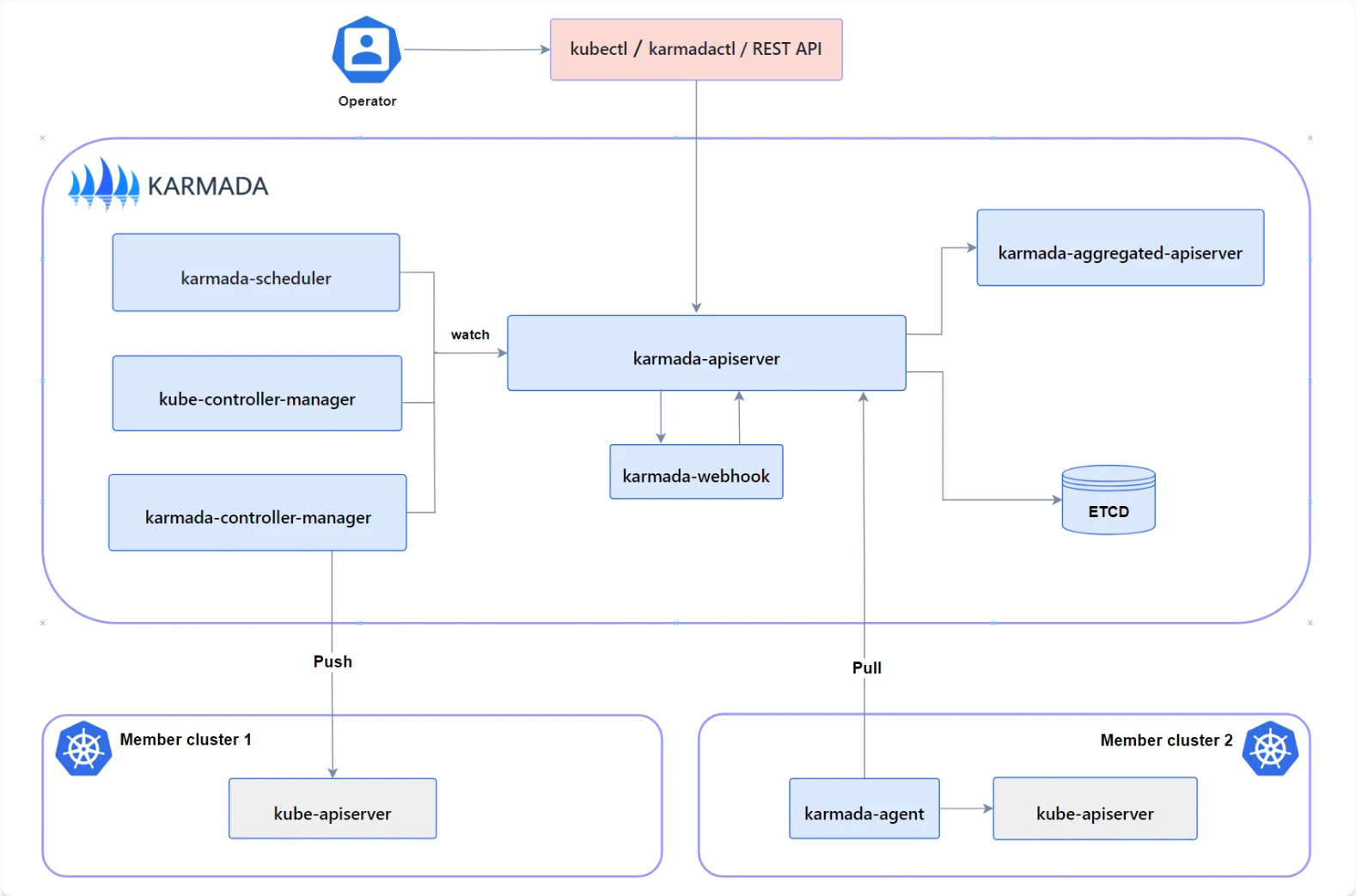
Karmada是CNCF的多集群调度项目,专注于跨集群的工作负载分发和弹性伸缩。Kurator深度集成了Karmada,将其作为多集群调度的核心引擎。这种集成不是简单的功能叠加,而是架构层面的深度融合。
Kurator通过Fleet抽象与Karmada的Cluster资源进行映射,将Karmada的调度策略能力暴露给Kurator用户。同时,Kurator为Karmada提供了更友好的API和UI,降低了使用门槛。在架构上,Kurator的Fleet Controller负责管理集群注册和基本配置,而Karmada的调度器负责具体的工作负载分发决策。
这种融合带来了几个关键优势:
- 统一的管理体验:用户无需学习两套独立的系统
- 增强的调度策略:结合Kurator的拓扑感知和Karmada的弹性伸缩
- 简化的运维流程:自动化的集群加入和配置同步
在实现层面,Kurator通过自定义适配器将Fleet API转换为Karmada API,确保两个系统之间的无缝协作。这种设计保留了Karmada的核心能力,同时提供了更符合企业需求的抽象层。
5.2 跨集群工作负载分发策略
Kurator 统一应用分发参考图:
Karmada提供了多种工作负载分发策略,Kurator在此基础上增加了企业级的增强功能。下面是一个复杂的跨集群部署策略示例:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: global-service-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: global-service
placement:
clusterAffinity:
clusterNames:
- us-east-cluster
- eu-west-cluster
- ap-southeast-cluster
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weights:
us-east-cluster: 50
eu-west-cluster: 30
ap-southeast-cluster: 20
spreadConstraints:
- maxGroups: 3
topologyKey: region
- maxGroups: 2
topologyKey: provider这个PropagationPolicy定义了一个跨三个区域的部署策略:
- 副本分配:按照权重比例分配副本(50%-30%-20%)
- 拓扑分散:确保服务跨区域和跨云提供商部署
- 故障隔离:通过spreadConstraints限制单点故障影响范围
在Kurator中,用户可以将这个策略与Fleet结合,实现更智能的部署决策。例如,可以根据实时流量数据动态调整权重,或者在某个区域出现故障时自动将流量转移到其他区域。
5.3 动态弹性伸缩实现与优化
跨集群弹性伸缩是Kurator和Karmada集成的核心价值之一。传统的单集群HPA(Horizontal Pod Autoscaler)只能在单个集群内扩展,而Kurator支持跨集群的弹性伸缩。下面是一个跨集群HPA的实现示例:
yaml
apiVersion: autoscaling.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
meta
name: hpa-propagation
spec:
resourceSelectors:
- apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
name: global-hpa
placement:
clusterAffinity:
clusterNames:
- cluster-a
- cluster-b
- cluster-c
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
meta
name: global-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
minReplicas: 10
maxReplicas: 100
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: External
external:
metric:
name: request-per-second
selector:
matchLabels:
service: frontend
target:
type: AverageValue
averageValue: 100这个配置实现了两个关键功能:
- 跨集群HPA传播:将HPA策略自动应用到所有目标集群
- 多维度伸缩指标:结合CPU利用率和外部指标(请求量)进行伸缩决策
在实际优化中,需要考虑以下因素:
- 伸缩滞后:跨集群伸缩需要时间,需要设置合理的冷却期
- 成本优化:在公有云环境中,根据区域价格动态调整副本分布
- 数据局部性:确保扩展的副本靠近数据源,减少跨区域数据传输
Kurator通过智能调度算法和实时监控数据,自动优化这些参数,为企业提供成本效益最优的弹性伸缩方案。
6. Volcano调度架构与批处理优化
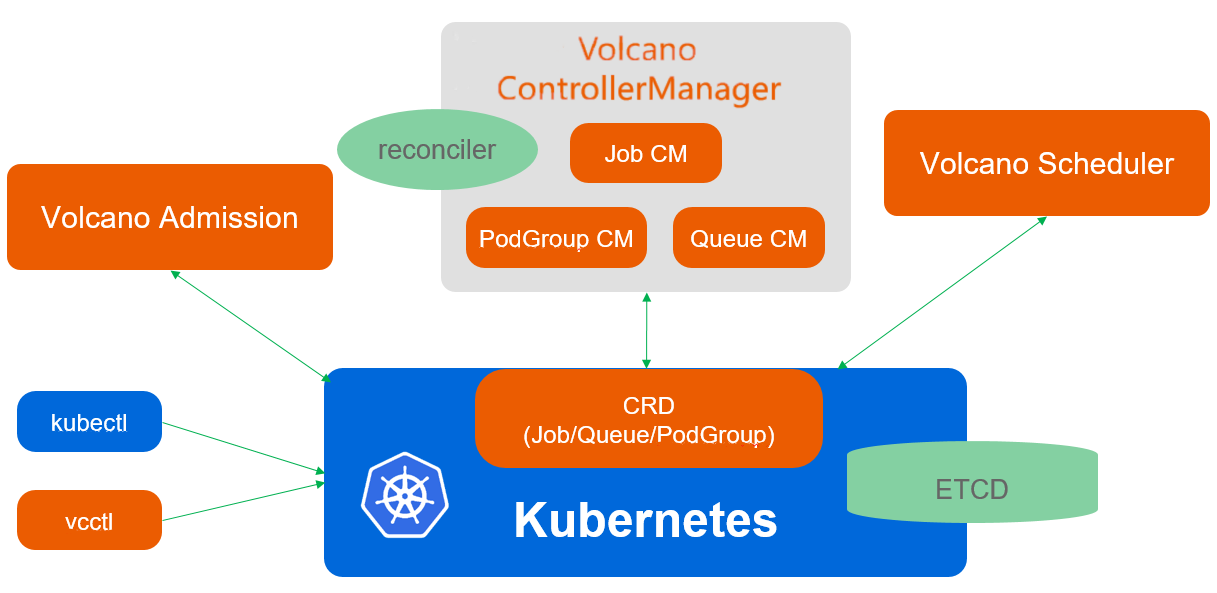
Volcano调度架构参考图:
6.1 Volcano核心组件与调度原理
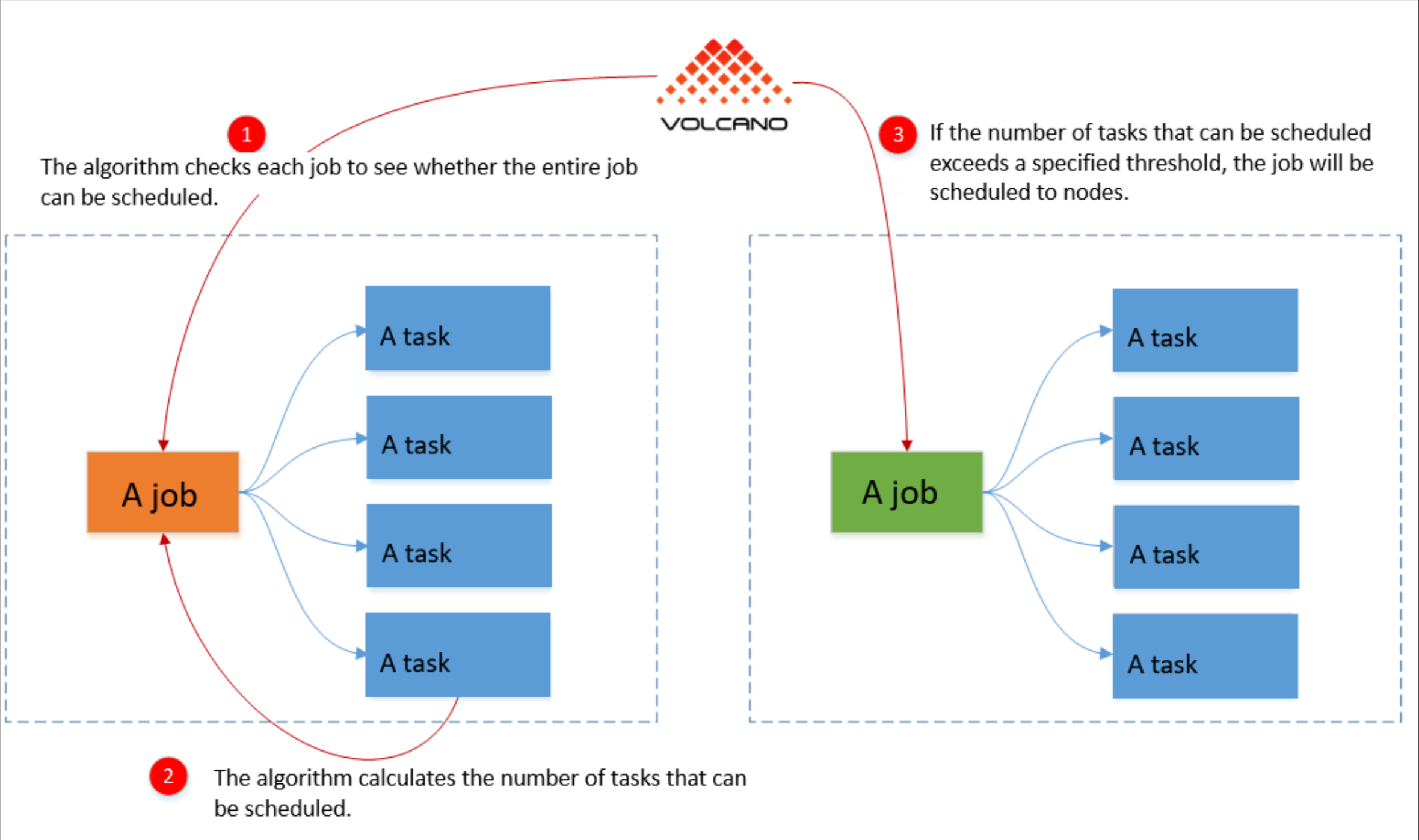
Volcano分组调度参考图,详见下图:
Volcano是CNCF的批处理调度项目,专注于AI/ML、大数据和HPC工作负载的调度优化。Kurator集成了Volcano作为其批处理工作负载的调度引擎,提供了超越原生Kubernetes调度器的能力。
Volcano的核心架构包括三个关键组件:
- Scheduler:基于多级队列和公平调度的智能调度器
- Controller Manager:管理Volcano自定义资源的控制器
- Admission Controller:在Pod创建前进行策略验证
Volcano的调度原理基于"两阶段调度"模型:
- 队列调度:决定作业进入哪个队列
- 作业调度:在队列内决定作业的执行顺序和资源分配
这种设计特别适合混合工作负载场景,例如同时运行训练作业和推理服务。通过队列隔离,可以确保关键业务不受批处理作业的影响。
在Kurator中,Volcano被深度集成到多集群调度框架中。Kurator的Fleet Controller会将Volcano Queue和Job资源自动分发到合适的集群,而Volcano Scheduler则在集群内部进行细粒度的资源分配。这种分层调度架构既保证了全局资源利用率,又满足了局部调度策略的需求。
6.2 队列管理与资源隔离实践
在企业环境中,不同团队、不同优先级的作业需要严格的资源隔离。Volcano通过Queue和PodGroup实现了多维度的资源隔离。下面是一个企业级队列配置示例:
yaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: high-priority
spec:
weight: 5
capability:
cpu: "100"
memory: "500Gi"
reclaimable: true
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: low-priority
spec:
weight: 1
capability:
cpu: "50"
memory: "200Gi"
reclaimable: false
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
meta
name: training-job-pg
spec:
minMember: 8
minTaskMember:
- name: worker
minMember: 6
- name: ps
minMember: 2
scheduleTimeoutSeconds: 300
queue: high-priority这个配置实现了:
- 两级队列:高优先级队列获得5倍于低优先级队列的资源权重
- 资源配额:为每个队列设置硬性资源上限
- 作业保障:PodGroup确保训练作业所需的最小节点数
在Kurator的多集群环境中,可以将高优先级队列部署在性能更好的集群(如GPU集群),而低优先级队列部署在成本优化的集群。Kurator的调度策略可以根据作业类型、资源需求和成本因素,自动选择最合适的集群。
6.3 AI/ML工作负载调度优化案例
AI/ML工作负载对调度器提出了特殊要求:Gang Scheduling(全有或全无)、拓扑感知(NUMA、GPU直连)、数据局部性等。下面是一个TensorFlow分布式训练作业的优化配置:
yaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: tf-dist-training
spec:
minAvailable: 8
schedulerName: volcano
queue: ai-training
tasks:
- replicas: 6
name: worker
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:2.8.0-gpu
resources:
limits:
nvidia.com/gpu: 1
cpu: "4"
memory: "16Gi"
env:
- name: TF_CONFIG
valueFrom:
configMapKeyRef:
name: tf-config
key: worker
nodeSelector:
node-type: gpu-optimized
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: volcano.sh/task-spec
operator: In
values: [worker]
topologyKey: kubernetes.io/hostname
- replicas: 2
name: ps
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:2.8.0-cpu
resources:
limits:
cpu: "8"
memory: "32Gi"
env:
- name: TF_CONFIG
valueFrom:
configMapKeyRef:
name: tf-config
key: ps
nodeSelector:
node-type: cpu-optimized这个Job配置包含了多个优化点:
- Gang Scheduling:minAvailable确保所有Pod同时调度,避免部分启动导致的资源浪费
- 异构资源分配:为worker分配GPU资源,为parameter server分配CPU资源
- 反亲和性:确保worker Pod分散在不同物理节点,提高容错性
- 拓扑感知:通过nodeSelector选择最适合的节点类型
在Kurator中,这个Job可以被Fleet策略自动分发到具有GPU资源的集群,并通过Volcano的调度算法确保最优的资源利用率。对于大规模训练作业,Kurator还支持跨集群的分布式训练,通过高速网络互联多个集群的GPU资源,实现前所未有的训练速度。
7. Kurator网络架构与故障排查
7.1 多集群网络连通性设计
多集群环境中的网络连通性是最大的技术挑战之一。Kurator采用了分层网络架构,针对不同场景提供最优解决方案:
- 中心-边缘网络:使用KubeEdge的云边隧道,支持NAT穿透和断连重连
- 集群间网络:基于Service Mesh(Istio)的服务网格,实现跨集群服务通信
- 混合云网络:结合云提供商的VPC对等连接和SDN技术,实现无缝网络扩展
在边缘场景中,Kurator使用KubeEdge的EdgeMesh组件,它支持多种网络模式:
- EdgeNode模式:边缘节点直接通信,减少云中心压力
- CloudHub模式:通过云中心中转,适用于严格安全要求的环境
- Hybrid模式:根据网络条件自动切换,提供最佳性能
Kurator的网络设计遵循"零信任"原则,所有跨集群通信都经过mTLS认证和授权。通过ServiceAccount和Namespace的相同性管理,确保只有授权的服务才能跨集群访问。
7.2 隧道技术在边缘场景的应用
边缘计算环境通常面临复杂的网络条件:NAT、防火墙、不稳定连接等。Kurator通过KubeEdge的隧道技术解决了这些挑战。核心组件包括:
- CloudStream:云侧流服务,管理所有隧道连接
- EdgeStream:边侧流代理,处理本地连接
- Tunnel Gateway:隧道网关,支持多种隧道协议(WebSocket、QUIC等)
下面是一个隧道配置的示例:
yaml
apiVersion: edge.kurator.dev/v1alpha1
kind: TunnelConfig
meta
name: factory-tunnel
spec:
edgeClusters:
- name: factory-beijing
edgeNodes:
- node1
- node2
tunnelType: websocket
keepaliveInterval: 30s
reconnectInterval: 5s
bandwidthLimit: 10Mbps
encryption:
enabled: true
algorithm: AES-256-GCM
qos:
highPriority:
ports: [22, 443]
dscp: 46
normalPriority:
ports: [80, 8080]
dscp: 0这个配置定义了一个工厂环境的隧道:
- 连接管理:自动重连和保活机制,适应不稳定网络
- 安全加密:端到端加密,保护敏感数据
- QoS策略:为关键端口(SSH、HTTPS)提供高优先级
- 带宽控制:限制总带宽,避免影响其他业务
在实际部署中,Kurator会根据网络条件自动选择最优隧道协议。例如,在高丢包率环境中,QUIC协议可能比WebSocket表现更好。这种智能选择大大提高了边缘连接的可靠性。
7.3 常见网络问题诊断与解决方法
多集群和边缘环境中的网络问题往往复杂难解。Kurator提供了多层次的诊断工具和方法:
1. 基础连通性检查
bash
# 检查集群间网络连通性
kurator diagnose network --fleet=production-fleet
# 检查边缘节点连接状态
kubectl get nodes -l node-role.kubernetes.io/edge -o wide2. 服务发现诊断
bash
# 检查跨集群服务DNS解析
kubectl run -it --rm debug --image=busybox:1.28 --restart=Never -- nslookup user-service.global.svc.cluster.local
# 检查ServiceExport/Import状态
kubectl get serviceexport -A
kubectl get serviceimport -A3. 隧道连接分析
bash
# 检查KubeEdge隧道状态
kubectl exec -it cloudcore-pod -- cloudcore --inspect-tunnels
# 查看边缘节点连接日志
kubectl logs edgecore-pod -n kubeedge4. 高级网络诊断
bash
# 使用Kurator网络诊断工具
kurator netdiag --cluster=member1 --destination=member2 --port=443
# 抓包分析(需要特权容器)
kubectl run -it --rm tcpdump --image=nicolaka/netshoot --restart=Never -- tcpdump -i any host 10.0.0.1 -w /tmp/capture.pcap常见问题及解决方案:
- DNS解析失败:检查CoreDNS配置和跨集群DNS同步
- 服务不可达:验证ServiceExport/Import配置和网络策略
- 隧道频繁断开:调整keepalive参数和重连策略
- 高延迟:优化网络拓扑,使用边缘节点直连模式
Kurator的诊断框架不仅提供工具,还包含知识库和自动修复建议。例如,当检测到DNS问题时,系统会自动建议检查CoreDNS配置和Fleet的DNS同步策略。这种智能诊断大大缩短了故障恢复时间。
8. Kurator未来展望与最佳实践
8.1 Kurator技术路线图分析
Kurator作为一个快速发展的开源项目,其技术路线图体现了分布式云原生技术的未来方向。基于社区讨论和贡献趋势,Kurator未来将重点发展以下几个方向:
1. 边缘AI原生支持
- 集成更多边缘AI框架(TensorFlow Lite、PyTorch Mobile)
- 支持模型版本管理和A/B测试
- 优化边缘-云协同推理工作流
2. 多云成本优化
- 跨云资源调度的成本感知算法
- 自动化的资源回收和缩容策略
- 详细的成本分析和预算控制
3. 安全增强
- 零信任架构的深度集成
- 机密计算支持(Intel SGX、AMD SEV)
- 合规性自动化检查(GDPR、HIPAA等)
4. 开发者体验优化
- 低代码/无代码应用部署界面
- 本地开发环境与生产环境同步
- 智能故障预测和自愈
这些发展方向不仅反映了技术趋势,也体现了企业实际需求。特别是边缘AI和成本优化,将成为未来2-3年内企业采用分布式云原生技术的关键驱动力。
8.2 企业落地Kurator的关键成功因素
企业在采用Kurator时,需要考虑多个维度的因素,以下是几个关键成功因素:
1. 架构设计原则
- 渐进式采用:从非核心业务开始,逐步扩展到核心系统
- 能力建设:培养内部云原生专家团队,不只是依赖外部支持
- 标准化先行:在实施前制定清晰的标准和规范,避免碎片化
2. 组织变革管理
- 跨职能团队:建立包含开发、运维、安全、业务的跨职能团队
- 技能提升:投资于团队的云原生技能培训
- 流程重构:调整现有的IT流程,适应GitOps和声明式管理
3. 技术实施策略
bash
# 推荐的企业实施路径
# 阶段1:单集群验证
kurator install --components=core
# 阶段2:多集群扩展
kurator fleet create production --clusters=cluster1,cluster2
# 阶段3:边缘节点集成
kurator edge register factory-node --fleet=production
# 阶段4:全面GitOps
kurator gitops enable --repo=https://github.com/company/gitops-repo4. 度量与优化
- 建立关键性能指标(KPI):部署速度、故障恢复时间、资源利用率
- 定期架构评审:每季度评估架构演进和优化机会
- 成本透明化:让业务团队了解技术决策的成本影响
企业在实施过程中,应避免"大爆炸"式迁移,而是采用迭代式方法,每个迭代都交付可测量的业务价值。同时,要特别关注安全合规要求,确保Kurator的配置符合企业治理策略。
8.3 分布式云原生技术发展趋势
展望未来,分布式云原生技术将沿着几个关键方向演进,Kurator作为这一领域的代表项目,其发展路径也反映了这些趋势:
1. 从"多集群"到"无集群"
未来的应用开发者将不再关心应用部署在哪个集群,甚至不关心集群的存在。Kurator正在向这个方向发展,通过抽象层屏蔽基础设施复杂性,让开发者专注于业务逻辑。
2. 边缘-云协同计算
边缘计算不会取代云计算,而是与之协同。Kurator的边缘-云协同架构将更加成熟,支持:
- 数据分层存储和处理
- 模型训练在云,推理在边缘
- 自适应计算任务调度
3. AI驱动的运维自动化
Kurator将集成更多AI/ML能力,实现:
- 智能容量预测和自动扩展
- 异常检测和根因分析
- 配置优化建议
4. 开放生态与标准统一
随着CNCF项目的成熟,Kurator将更加注重标准兼容性:
- 与Crossplane集成,实现统一的基础设施管理API
- 支持OpenTelemetry,提供统一的可观测性
- 遵循GitOps工作流标准,确保工具链互操作性
这些趋势表明,分布式云原生技术正在从技术驱动转向业务价值驱动。Kurator作为连接技术和业务的桥梁,其价值不仅在于技术实现,更在于如何帮助企业实现业务创新和数字化转型。未来的成功将属于那些能够将技术能力转化为业务洞察和竞争优势的企业。