一、实验内容
基于cartPole环境,实验2.4 TRPO/PPO效果,并于朴素AC、策略梯度比较。
PPO通俗理解:不见兔子不撒鹰,兔子代表优势,优势>0就提高动作概率,否则降低动作概率。
相较而言,策略梯度未建模优势,朴素AC算法倒是建模了优势,两者区别是:
① 朴素AC缺乏Trust-region 保护
② 朴素AC的核心是log动作概率;PPO的核心是两个策略的动作比值。似乎PPO更直接粗暴。
二、实验目标
2.1 确定实验流程
2.2 编码策略模型
2.3 编码价值模型
2.4 编码PPO算法
2.5 观测收益与loss变化情况
2.6 与朴素AC、策略梯度对比
三、实验过程
2.1 实验流程
见附件完整代码
2.2 策略模型
python
class PolicyNet(torch.nn.Module):
"""
input: state
output:action distribution
"""
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)2.3 价值模型
python
class ValueNet(torch.nn.Module):
"""
input: state
output: state value
"""
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)2.4 PPO算法
python
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 值函数目标
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
# 值函数gap
td_delta = td_target - self.critic(states)
# 计算优势
advantage = rl_utils.compute_advantage(self.gamma, self.lmbda,
td_delta.cpu()).to(self.device)
# 老模型的sa概率,ppo分母
old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach()
# epochs:episode复用次数
for _ in range(self.epochs):
# 新模型的sa概率,ppo分子
log_probs = torch.log(self.actor(states).gather(1, actions))
# 概率增益
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps,
1 + self.eps) * advantage # 截断
# actor损失
actor_loss = torch.mean(-torch.min(surr1, surr2))
# critic损失
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
self.actorLoss.append(actor_loss.item())
self.criticLoss.append(critic_loss.item())四、实验结果
结论先行:
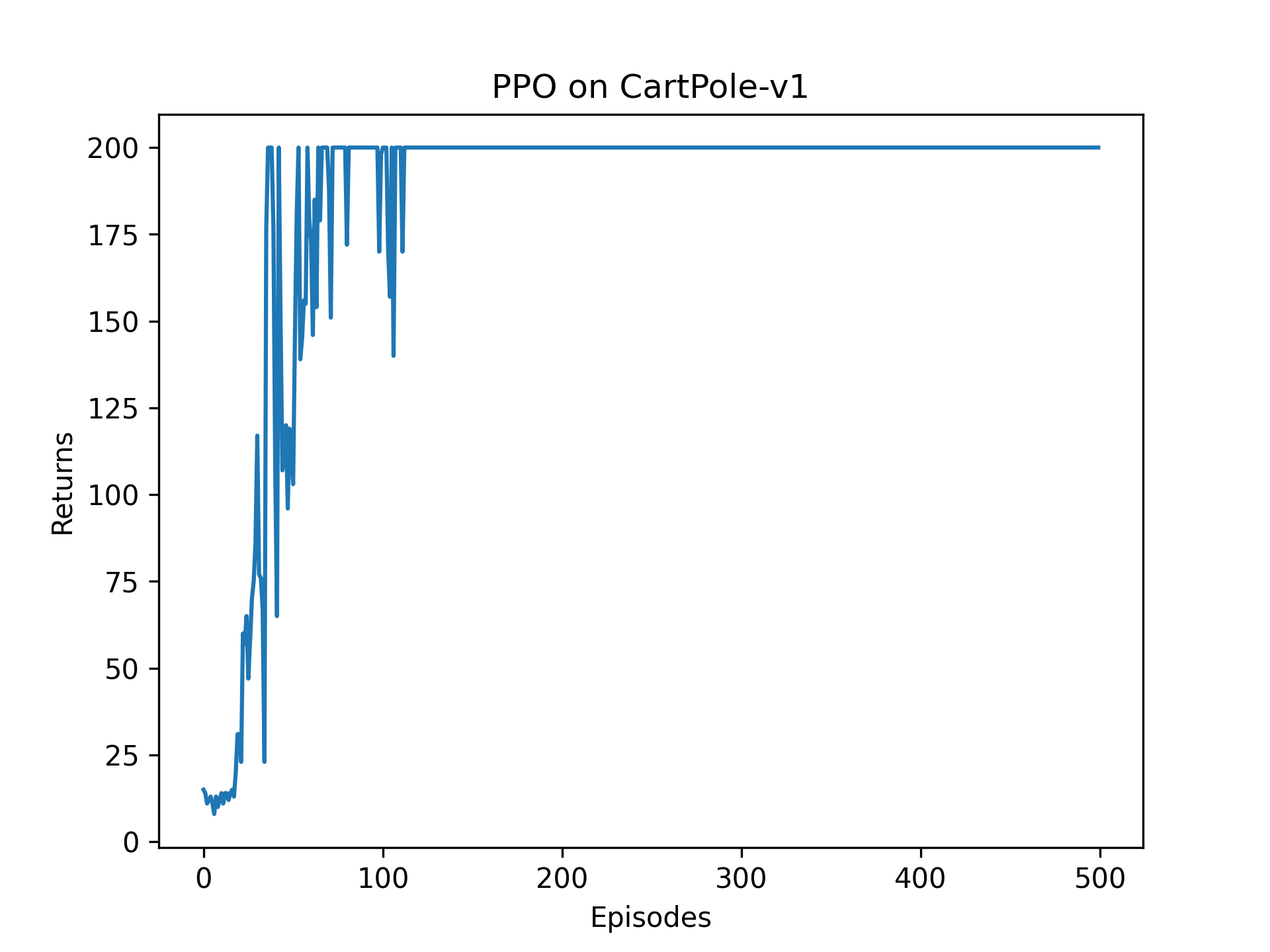
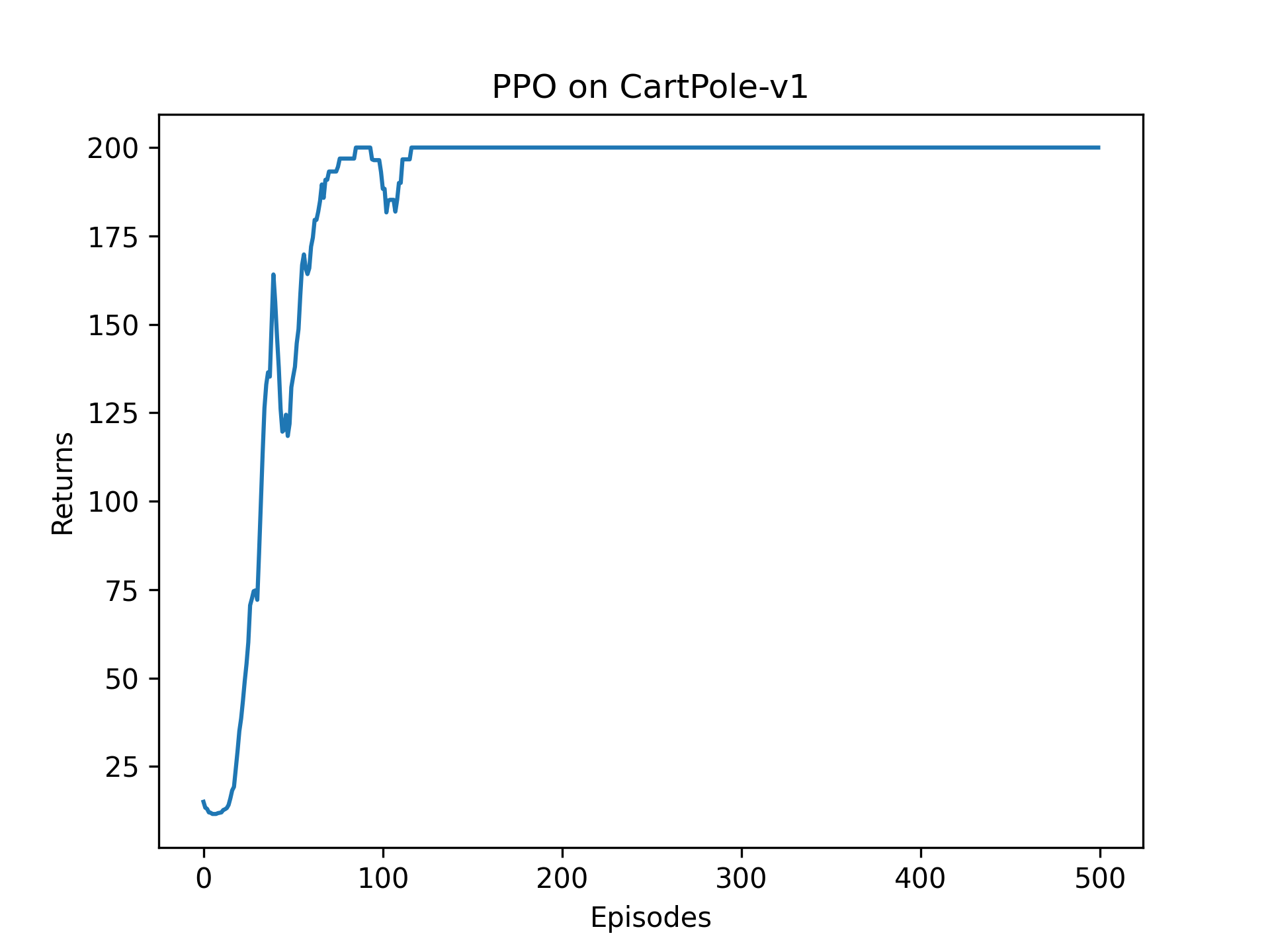
① PPO效果非常经验,尾部几乎没有毛刺,比朴素AC、策略梯度明显优越。
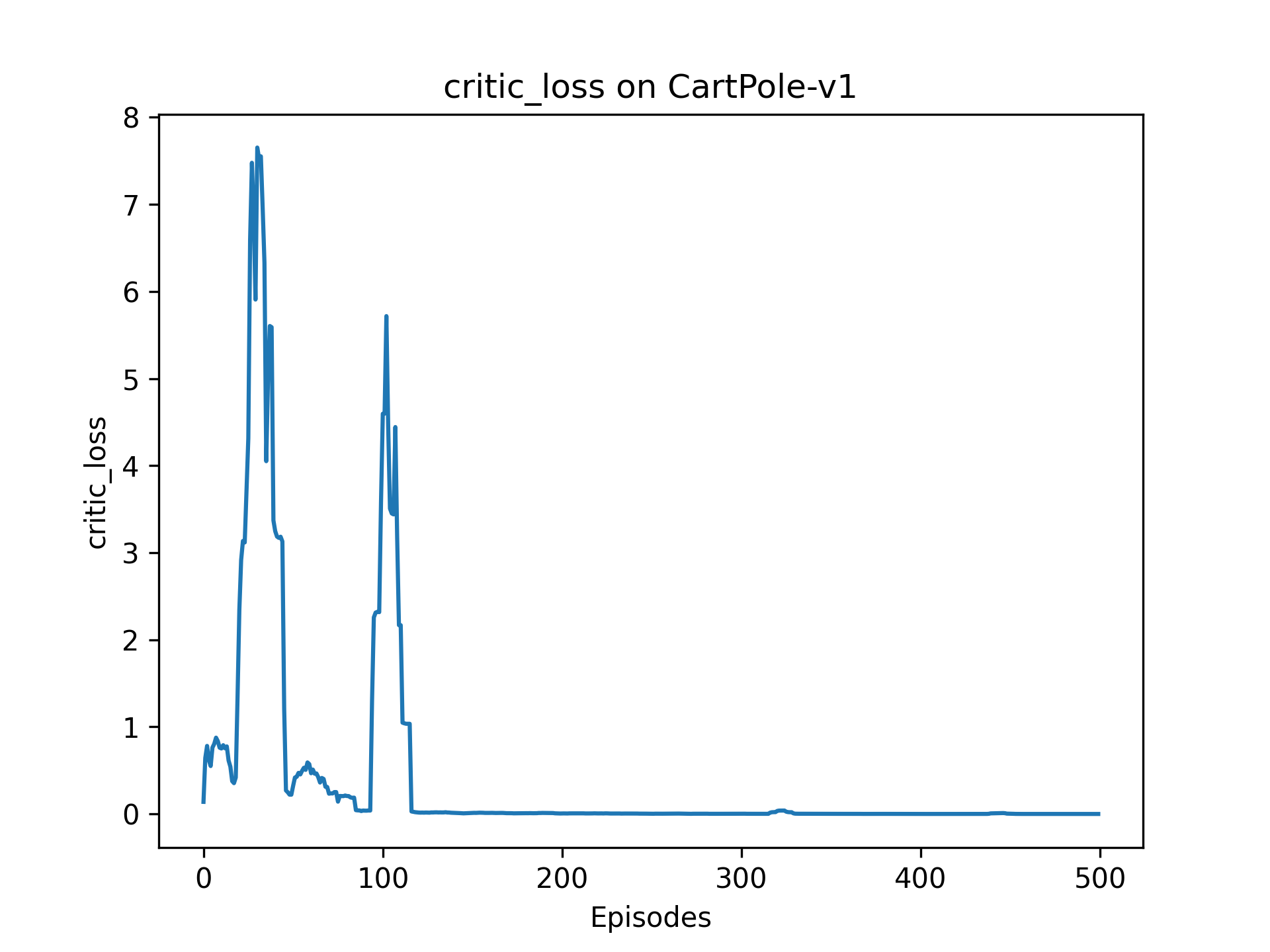
② criticLoss先震荡,然后收敛到0,符合预期。
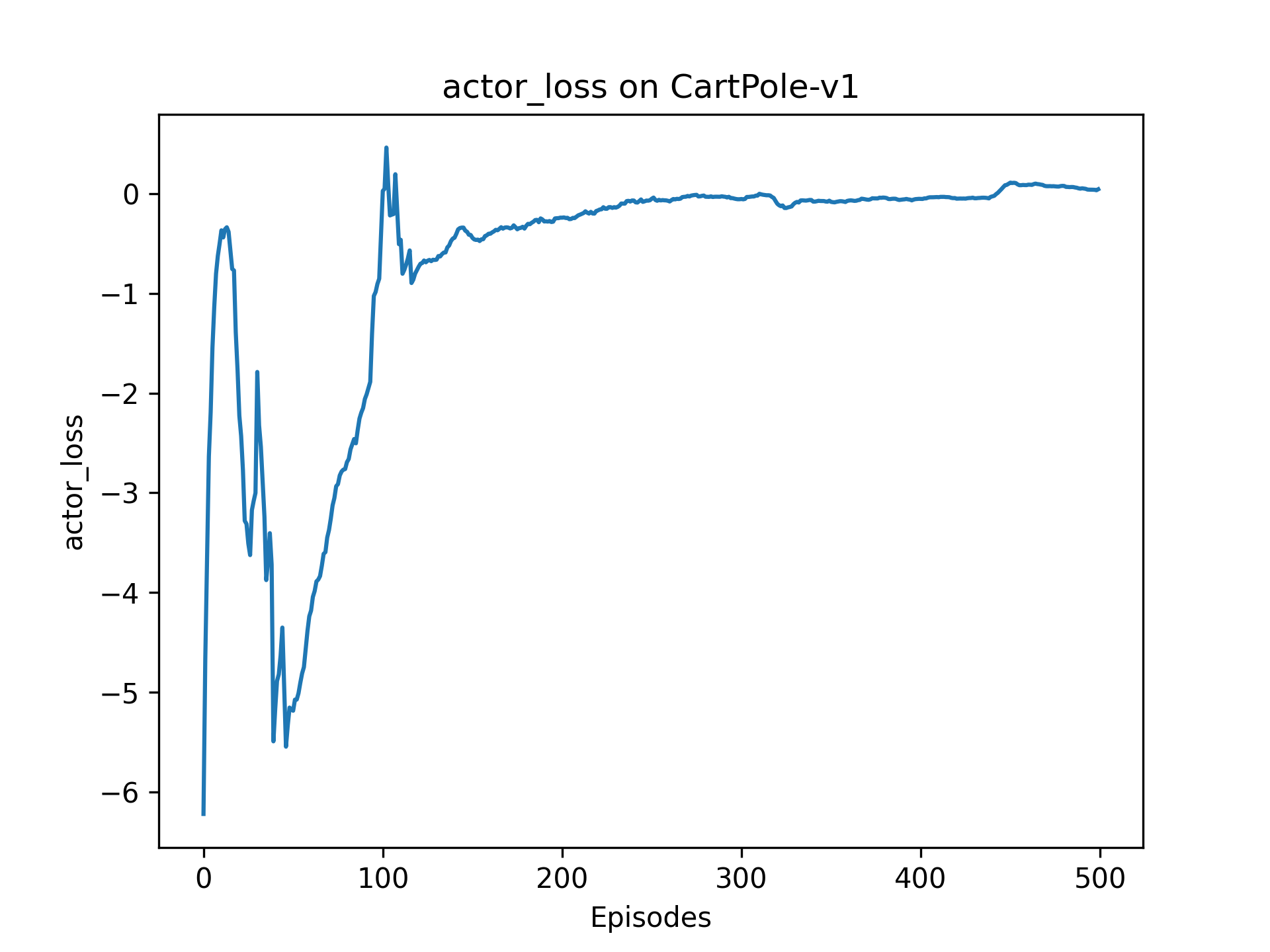
③ actorLoss先震荡,然后收敛到0,但是整体呈现上升趋势,需要思考原因。
4.1 累计收益
4.2 平滑收益
4.3 策略损失
4.4 价值损失
注:eps = 0.03比较好