你有没有好奇过,ChatGPT 是怎么既能写诗,又能翻译外语,讲起量子力学来还像个老教授一样一套一套的?
这都得归功于2017年,Google团队发表的一篇名为《Attention Is All You Need》的论文,彻底改变了人工智能的历史进程。在此之前,AI处理长文本如同"即使只有7秒记忆的金鱼",而Transformer的出现赋予了机器"过目不忘"的能力。今天我们来理解语言模型如何实现智能表现!
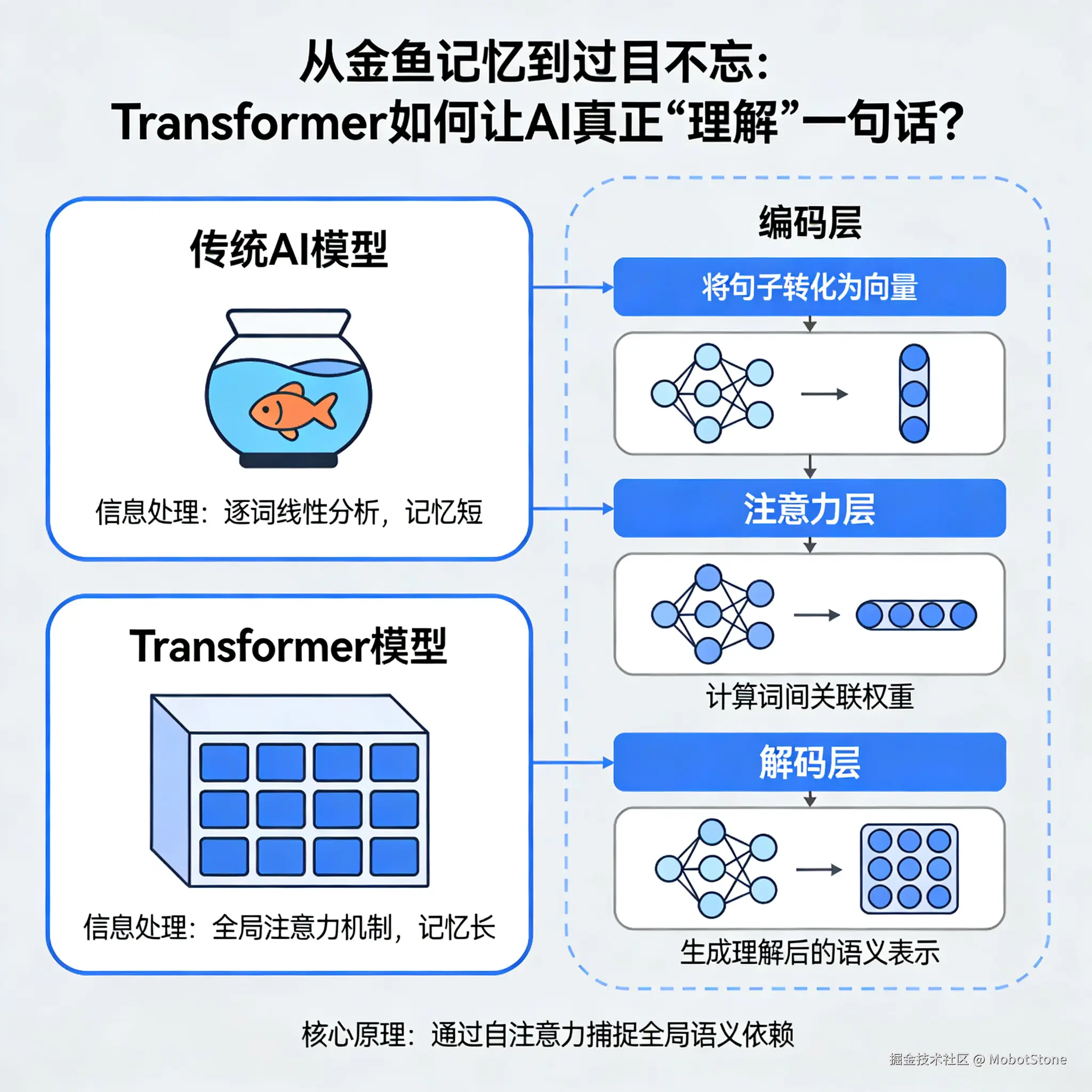
核心机制:一切在于注意力机制(Attention Mechanism)
阅读这句话时:
"猫坐在垫子上,因为它很柔软。" vs. "猫坐在垫子上,因为它很累了。"
在第一句中,你会瞬间理解"它"指代"垫子"(因为垫子柔软);而在第二句中,"它"指代"猫"(因为猫会累)。 人类大脑能精准聚焦 于关键信息并消除歧义。旧有的AI模型(如RNN)往往在处理到句子末尾时就忘记了开头的"猫",导致指代错误。 Transformers的运作方式 则如同拥有"上帝视角":它不再受线性阅读限制,而是以闪电速度计算句子中所有词语之间的关联权重,瞬间判断出"柔软"与"垫子"的相关度高达90%,而与"猫"的相关度仅为10%。
自我注意力的突破性革新
旧式模型逐词解析(读完A才读B),效率低下且难以捕捉长距离依赖。而Transformers同步观测所有词语。每个词都会自问:
"在这句话中,哪些词与我相关?我对它们的'关注度'该分配多少?"
通过查询(Query)、键(Key)、值(Value)三个向量的巧妙运算,词语间动态织出了一张复杂的"关系网"。为了理解这三个概念,我们可以将其比作图书馆检索系统:
- Query (查询) :你手中的书单(比如你想找关于"猫"的信息)。
- Key (键) :图书馆书脊上的标签(每本书的内容索引)。
- Value (值) :书中实际的知识内容。
当"猫"发出Query时,它会与全句所有词的Key进行匹配。如果Key匹配度高(点积运算结果大),模型就会提取更多的Value信息。
- "它"与"垫子"产生强关联(匹配度高,提取大量特征)
- "猫"与"坐"建立逻辑连接(主谓关系清晰)
信息流动流水线:分步解析
① 输入嵌入 (Input Embeddings):将词语转化为数字表征
计算机不认识汉字,只认识数字。模型将词语转为高维向量。
- 实例:在GPT-3模型中,每个词被转化为一个长度为12,288维的向量。
- 数学直觉:在这种高维空间中,语义相近的词距离更近。经典的向量运算案例是:国王−男人+女人≈女王。这证明了模型不是在死记硬背,而是理解了词语间的空间几何关系。
② 位置编码 (Positional Encoding):补足词序信息
由于Transformer是并行处理(一次性吃进所有词),它天然不知道顺序。就像把一本书拆散页扔在地上。
- 解决方案:给每个词打上独特的"时间戳"或"页码"。通过正弦和余弦函数的波形叠加,模型能区分"张三打了李四"与"李四打了张三"截然不同的含义,理解"猫"在"坐"之前。
③ 自注意力 (Self-Attention):动态社交网络 🎉
这不是简单的"看一眼",而是多头注意力(Multi-Head Attention) 。
-
具象理解:想象有96个不同的"阅读专家"同时在看这句话。
-
专家A关注语法结构(主谓宾);
-
专家B关注指代关系("它"是谁);
-
专家C关注情绪色彩(是褒义还是贬义)。
最终,这些专家把各自的观察结果汇总,形成对这个词全面而立体的理解。
-
④ 前馈网络 (Feed-Forward Networks):深度信息加工
每个词的表征经迷你神经网络转换,这是模型的"记忆库"。
- 功能 :如果注意力层是在"收集线索",这一层就是在"查阅百科全书"。它将提取的特征(如"柔软")映射到更广阔的知识空间,强化细节理解(如: "柔软" → 舒适感、纺织品、易变形等关联概念)。
⑤ 层叠堆叠:从语法到意图
Transformer架构通常重复构建12层(BERT-Base)、96层(GPT-3)甚至更多。
- 浅层(1-10层) :处理基础语法,如识别名词、动词。
- 中层(10-50层) :理解语义关联,如逻辑推理、因果关系。
- 深层(50+层) :提炼抽象概念,如讽刺、隐喻、幽默感或特定领域的专业知识。
- 数据支撑:研究表明,层数越深,模型对抽象概念的线性可分性越强。
⑥ 输出层:生成智能回应
最终将高维向量映射回人类词汇表(通常约50,000+个词)。
-
机制 :输出的是概率分布。例如,对于"天空是__",模型可能会预测:
-
蓝色 (85%)
-
灰蒙蒙 (10%)
-
广阔 (4%)
-
绿色 (0.001% - 极低概率)
模型根据这些概率(结合温度参数Temperature)选择最合适的词作为回答。
-
设计优势:为何超越传统模型
- 并行计算的胜利:传统RNN必须读完第一个词才能读第二个,训练像跑马拉松。Transformer利用GPU的大规模并行计算能力,就像一支千人团队同时阅读文章的不同段落。这使得训练万亿参数级模型(如GPT-4)从"不可能"变为"现实"。
- 长距关联 (Long-Range Dependencies) :RNN大约只能记住前100个词的上下文,在这个距离外就会发生"梯度消失"。而Transformer的上下文窗口(Context Window)可轻松达到128k甚至100万token(如Gemini 1.5 Pro),意味着它能读完《红楼梦》全书后,依然记得第一章的伏笔。
- 可扩展性 (Scalability) :缩放定律 (Scaling Laws) 证明,单纯增加数据规模、算力和模型层数,智能水平就会呈现指数级跃迁,涌现出意想不到的能力(如在未专门训练的情况下学会编程)。
思维模拟本质:如何"理解"语言
虽非人类那样的生物意识,但通过三步信息处理实现了极高保真的"类智能":
- 收集线索(注意力机制像雷达一样扫描全网关联);
- 信号融合(通过百层网络的非线性变换,将简单词汇升维成复杂概念);
- 模式预测(基于海量人类文本的统计规律,预测下一个最合理的字)。
如同精密编排的数据舞蹈,当舞步足够复杂与精准时,便呈现出"思考"的优雅姿态。
跨领域应用:通用智能架构
Transformer已不仅仅是语言模型,它成为了AI界的"大一统理论":
- 图像生成:DALL·E和Stable Diffusion将图像切片视为"单词",利用Transformer学习像素间的关联,从而无中生有地创造画作。
- 生命科学革命 :DeepMind的AlphaFold将氨基酸序列视为"文本",利用Transformer预测蛋白质的三维结构。它在短短几年内预测了超过2亿种蛋白质结构,解决了生物学界困扰50年的难题,加速了新药研发。
- 自动驾驶与音视频:特斯拉等公司使用Vision Transformers (ViT) 处理摄像头数据,理解道路上的动态场景,让汽车学会"看路"。
Transformers正成为AI的元学习引擎,凭灵活的注意力机制驱动着从原子尺度到宇宙尺度的全领域创新。