文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 编写网站访问量程序](#2.1 编写网站访问量程序)
- [2.2 编译网站访问量程序](#2.2 编译网站访问量程序)
-
- [2.2.1 构建类路径](#2.2.1 构建类路径)
- [2.2.2 编译源程序](#2.2.2 编译源程序)
- [2.3 将源程序达成jar包](#2.3 将源程序达成jar包)
- [2.4 使用 spark-submit 提交作业](#2.4 使用 spark-submit 提交作业)
- [2.5 查看统计结果文件](#2.5 查看统计结果文件)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本次实战基于 Spark RDD 编程模型,使用 Scala 语言开发网站访问日志分析程序,实现对 31 万余条记录中每月访问量的统计与降序输出。通过编写、编译、打包及提交完整流程,成功在 Spark 集群上运行任务,并将结果持久化至 HDFS,完整展示了 Spark 应用从开发到部署的标准化操作。
2. 实战步骤
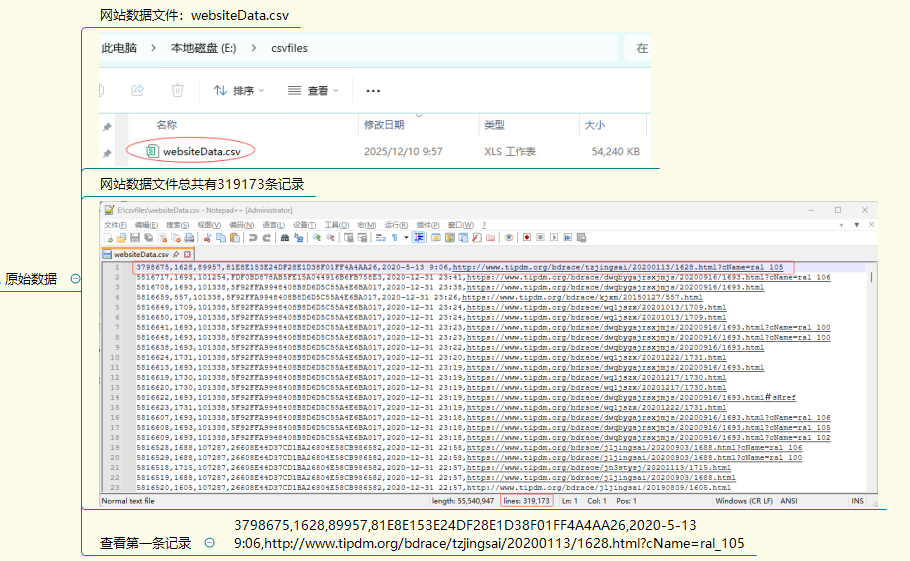
- 查看原始数据
2.1 编写网站访问量程序
-
执行命令:
vim RDDWebsiteVisits.scala
 scala
scalaimport org.apache.spark.{SparkConf, SparkContext} /** * 功能:统计网站访问量 * 作者:华卫 * 日期:2025年12月20日 */ object WebsiteVisits { def main(args: Array[String]): Unit = { // 创建Spark配置对象 val conf = new SparkConf() .setAppName("SparkRDDWebsiteVisits") // 设置应用名称 // 基于Spark配置对象创建Spark容器对象 val sc = new SparkContext(conf) // 定义输入路径 val inputPath = "hdfs://master:9000/websitevisits/input" // 定义输出路径 val outputPath = "hdfs://master:9000/websitevisits/output" // 统计每月访问量 val wt = sc.textFile(inputPath) .map(line => line.split(",")(4)) .map(datetime => datetime.split(" ")(0)) .map(date => date.split("-")) .map(fields => (fields(0) + "-" + fields(1), 1)) .reduceByKey(_ + _) .sortBy(_._2, false) // 在控制台输出每月访问量统计结果 wt.collect.foreach(println) // 将每月访问量统计结果写入指定文件 wt.saveAsTextFile(outputPath) // 停止Spark容器,结束任务 sc.stop } }
2.2 编译网站访问量程序
2.2.1 构建类路径
- 执行命令:
CP=$(find $SPARK_HOME/jars -name "*.jar" | tr '\n' ':')

2.2.2 编译源程序
- 执行命令:
scalac -cp "$CP" RDDWebsiteVisits.scala
- 执行命令:
ll Web*
2.3 将源程序达成jar包
- 执行命令:
jar cf RDDWebsiteVisits.jar WebsiteVisits*.class

2.4 使用 spark-submit 提交作业
- 执行命令:
spark-submit --master spark://master:7077 --class WebsiteVisits RDDWebsiteVisits.jar
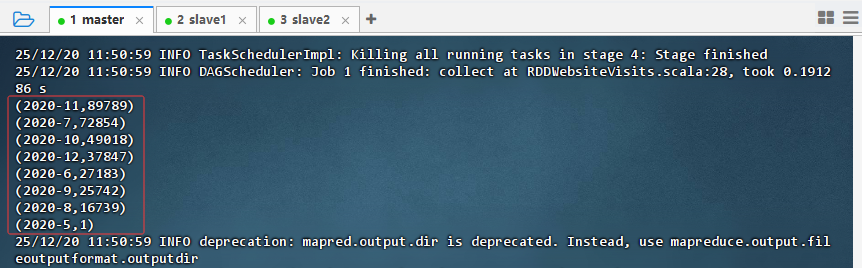
2.5 查看统计结果文件
- 执行命令:
hdfs dfs -ls /websitevisits/output
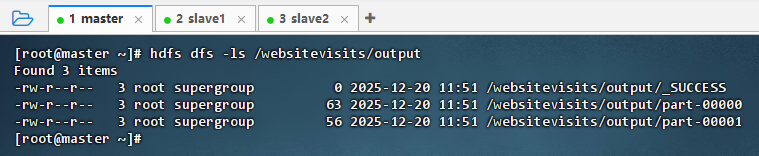
- 执行命令:
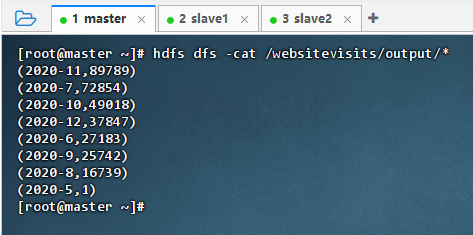
hdfs dfs -cat /websitevisits/output/*
3. 实战总结
- 本次实战完整实现了基于 Scala 的 Spark RDD 网站访问量统计任务。通过精准提取日志中的时间字段,构造
(年-月, 1)键值对,利用reduceByKey聚合月度访问次数,并按降序排序输出。关键在于掌握 Spark 应用的编译---打包---提交 全流程:使用find + tr正确构建 classpath 解决依赖问题,生成.class文件后打包为 JAR,再通过spark-submit指定主类提交至集群。整个过程体现了 Spark 分布式计算在日志分析场景中的高效性与可靠性,也为后续开发复杂数据处理任务奠定了坚实基础。