
0. 写在前面:为什么你需要"一个入口"来管多集群、多云、云边?
当集群规模从"单集群运维"迈向"多集群 + 多环境 + 多团队协作",你会很快遇到同一类问题反复出现:
- 集群生命周期:新建/扩缩/替换节点/回收,动作一多就容易出现漂移;
- 应用交付:不同集群、不同环境的发布策略、配置来源、回滚路径不一致;
- 可观测与合规:监控告警、策略准入、审计规则在多集群间难以统一;
- 灾备与迁移:备份、恢复、迁移缺少统一入口与状态视图;
- 渐进式发布与流量治理:发布策略与网格/Ingress/指标分析配置割裂,复用成本高。
Kurator 的思路是把这些"跨集群的共性动作"抽象成 Kubernetes 原生 API(CRD) ,让你通过 kubectl/声明式配置,把多集群治理变成"像部署一个应用一样可复制、可审计、可自动化"。官方仓库对 Kurator 的定位是 Kubernetes-native distributed cloud-native suite。
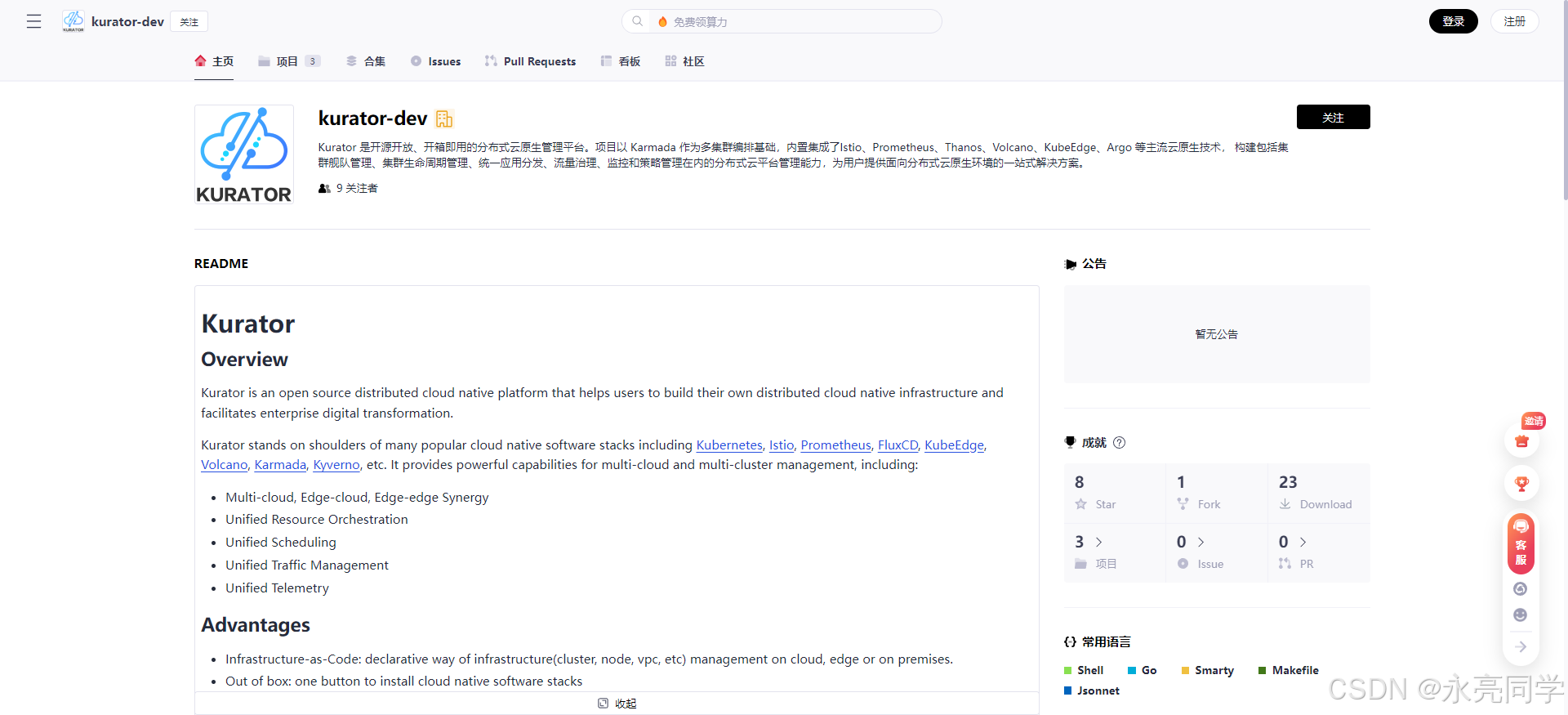
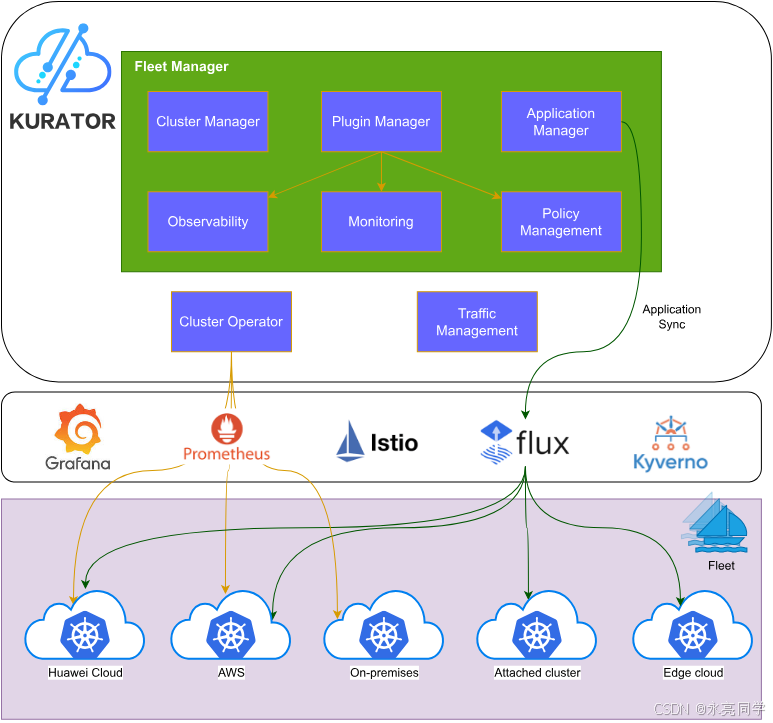
如下是Kurator项目开源首页:
1. Kurator 核心概念速览:用 CRD 把"平台能力"封装成"可声明的对象"
为了后文实操顺畅,先统一几个关键对象/组件的语义(都能在官方文档导航结构中对应到安装与使用章节):
- Kurator CLI :用于安装/验证等辅助操作;官方给出了源码构建与 release 包安装方式,并提供
kurator version的验证方式。 - Cluster Operator:集群侧/管理侧的关键组件之一;官方文档明确其依赖 cert-manager,并给出了 Kind 多集群本地环境脚本与 Helm 安装方式。
- Fleet Manager:以 Fleet 为核心对象,把多集群纳入一个"舰队",并依赖 FluxCD(官方给出 Helm 安装 flux2 的配置片段)。
- Fleet / AttachedCluster / Application:分别代表"舰队""纳管的集群(通过 kubeconfig secret 引入)""统一应用分发对象";官方在应用分发文档给出了多种 source/syncPolicies 的 YAML 示例。
你可以把 Kurator 理解为:
用 Fleet 组织集群,用 Application/Policy/Metric/Backup/Rollout 等 CRD 组织跨集群能力,再用插件把能力下沉到每个成员集群。
Kurator 的价值,在于 统一抽象与统一入口。
2. 从0到1搭环境:用 Kurator 脚本快速拉起本地多集群(Kind)
官方在 Cluster Operator 安装指南里,给出了用 Kurator 脚本创建本地多集群环境的方式:克隆仓库后执行 hack/local-dev-setup.sh,脚本会准备 host cluster 与 member clusters,并提示你通过不同的 kubeconfig 来切换管理与远端集群。
bash
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 创建本地多集群(host + member1 + member2)
hack/local-dev-setup.sh
# 按官方提示切换 kubeconfig(示例)
export KUBECONFIG=/root/.kube/kurator-host.config
# 远端集群 kubeconfig(示例)
# export KUBECONFIG=/root/.kube/kurator-member1.config
# export KUBECONFIG=/root/.kube/kurator-member2.config脚本完成后,官方建议你检查 /root/.kube/ 下生成的配置文件(host、member1、member2)。
当然,如果你要想成功运行Kurator脚本,本地得先要有其Kurator项目源码,米都没有,怎么煮饭。
OK,大家可以跟我的教程步骤一步一步来,演示如下:
1、我们先打开开源项目地址:https://gitcode.com/kurator-dev/kurator
2、点击clone,通过Git插件,将项目进行clone下载
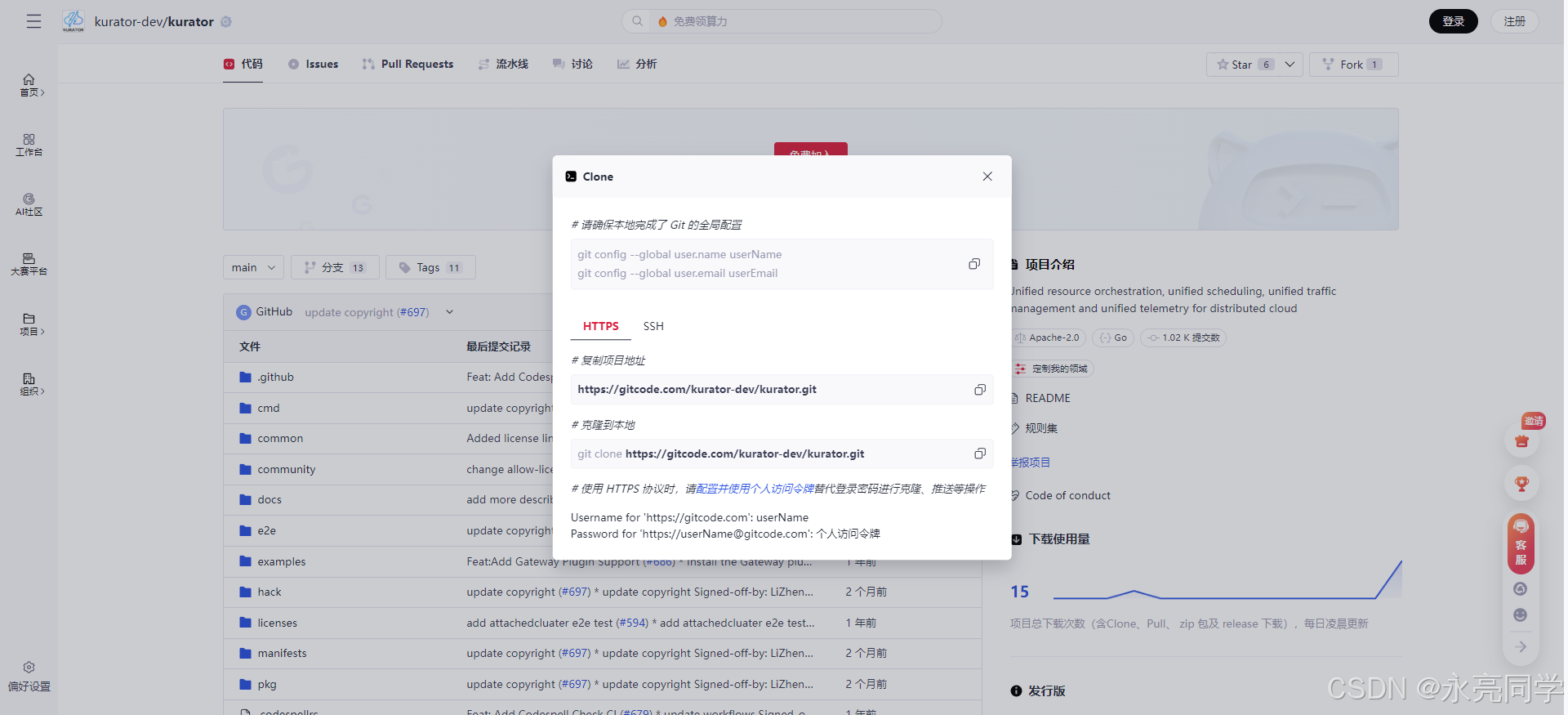
3、执行克隆命令
json
git clone https://gitcode.com/kurator-dev/kurator.git
4、本地项目查看:
如上,我们就成功将项目拉取到本地了。
3. 安装 Kurator CLI:两条路线(源码 / Release 包)
3.1 从源码构建安装
官方给出 make kurator,产物位于 ./out/{your_os},并建议移动到 PATH 目录,例如 /usr/local/bin/。
bash
git clone https://github.com/kurator-dev/kurator.git
cd kurator
make kurator
sudo mv ./out/linux-amd64/kurator /usr/local/bin/3.2 从 Release 包安装(官方示例版本 v0.6.0)
官方示例使用 curl -LO 下载对应版本并解压到 PATH。
bash
curl -LO https://github.com/kurator-dev/kurator/releases/download/v0.6.0/kurator-0.6.0-linux-amd64.tar.gz
sudo tar -zxvf kurator-0.6.0-linux-amd64.tar.gz -C /usr/local/bin/3.3 验证安装
官方给出 kurator version 的输出格式示例。
bash
kurator version当然,如果你对步骤部署有疑问,可以参考官方资料:官方开源文档
4. 安装 Cluster Operator:依赖 cert-manager + 三种安装方式(源码/Release/Helm Repo)
4.1 先装 cert-manager(Cluster Operator 依赖 CA injector)
官方明确:cluster operator 依赖 cert-manager CA injector,并给出了 jetstack chart 的安装命令与版本示例(v1.15.3)。
bash
helm repo add jetstack https://charts.jetstack.io
helm repo update
kubectl create namespace cert-manager
helm install -n cert-manager cert-manager jetstack/cert-manager \
--set crds.enabled=true --version v1.15.34.2 通过 Helm Repo 安装(最贴近"平台化复用"的路径)
官方提供 kurator helm-charts 仓库地址,并给出 kurator/cluster-operator --version=0.6.0 的安装方式。
bash
helm repo add kurator https://kurator-dev.github.io/helm-charts
helm repo update
helm install --create-namespace kurator-cluster-operator kurator/cluster-operator \
--version=0.6.0 -n kurator-system安装后官方建议用 label 选择器检查 Pod Running。
bash
kubectl get pod -l app.kubernetes.io/name=kurator-cluster-operator -n kurator-system小结(工程视角):
- "先 cert-manager"是典型的控制面依赖;
- "helm repo 安装"更适合企业内网镜像/Chart 仓库体系做二次封装;
- 后续 Fleet Manager 也会复用同一套安装风格,降低平台交付成本。🙂
而且,还真别说,官方教程是写的真简洁实用:
5. 安装 Fleet Manager:先装 FluxCD(helm chart)再装 Fleet Manager(helm)
官方文档明确:Fleet manager 依赖 cluster operator;同时依赖 FluxCD,Kurator 使用 fluxcd 社区 helm chart,并给出了一个禁用部分 controller 的 values 配置片段(安装 flux2 chart)。
5.1 安装 FluxCD(flux2)
bash
helm repo add fluxcd-community https://fluxcd-community.github.io/helm-charts
cat <<EOF | helm install fluxcd fluxcd-community/flux2 \
--version 2.7.0 -n fluxcd-system --create-namespace -f -
imageAutomationController:
create: false
imageReflectionController:
create: false
notificationController:
create: false
EOF
kubectl get po -n fluxcd-system5.2 安装 Fleet Manager(Helm Repo 方式)
官方同样提供 kurator helm repo 安装方式:kurator/fleet-manager --version=0.6.0,并给出安装后检查 Pod 的命令。
bash
helm repo add kurator https://kurator-dev.github.io/helm-charts
helm repo update
helm install --create-namespace kurator-fleet-manager kurator/fleet-manager \
--version=0.6.0 -n kurator-system
kubectl get pod -l app.kubernetes.io/name=kurator-fleet-manager -n kurator-system6. 可选但强烈建议:安装 Minio(用于 Thanos/Velero 本地验证)
官方在 Minio 安装页说明:Kurator 使用 bitnami minio helm chart,并给出包含 defaultBuckets: thanos,velero 的 values 示例,以及如何获取 MINIO_SERVICE_IP、创建 Thanos/Velero 所需 secret 的命令。
bash
cat <<EOF | helm install minio oci://registry-1.docker.io/bitnamicharts/minio \
-n monitoring --create-namespace -f -
auth:
rootPassword: minio123
rootUser: minio
defaultBuckets: thanos,velero
accessKey:
password: minio
secretKey:
password: minio123
service:
type: LoadBalancer
EOF
kubectl get po -n monitoring
# 生成 thanos objstore secret(可选)
export MINIO_SERVICE_IP=$(kubectl get svc --namespace monitoring minio \
--template "{{ range (index .status.loadBalancer.ingress 0) }}{{ . }}{{ end }}")
cat <<EOF > objstore.yaml
type: S3
config:
bucket: "thanos"
endpoint: "${MINIO_SERVICE_IP}:9000"
access_key: "minio"
insecure: true
signature_version2: false
secret_key: "minio123"
EOF
kubectl create secret generic thanos-objstore --from-file=objstore.yml=./objstore.yaml
# 生成 velero 所需 secret(可选)
kubectl create secret generic minio-credentials \
--from-literal=access-key=minio --from-literal=secret-key=minio123官方架构设计展示:
7. 进入正题:创建最小可用 Fleet,把两个成员集群纳入"统一治理面"
在多个插件(策略/备份/发布等)的文档里,Kurator 都采用一致的"纳管套路":
- 用 kubeconfig 文件创建 Secret(每个成员集群一个);
- 创建
AttachedCluster对象引用该 Secret; - 创建
Fleet对象,把多个AttachedCluster组合起来; kubectl wait fleet ...等待 Fleet Ready。
例如在 Rollout 插件安装指南中,官方给出了创建 secret + AttachedCluster 的 YAML 模板与 kubectl apply -f - <<EOF 的方式。
7.1 创建访问成员集群的 Secret
bash
kubectl create secret generic kurator-member1 \
--from-file=kurator-member1.config=/root/.kube/kurator-member1.config
kubectl create secret generic kurator-member2 \
--from-file=kurator-member2.config=/root/.kube/kurator-member2.config7.2 创建 AttachedCluster(纳管对象)
bash
kubectl apply -f - <<EOF
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: kurator-member1
namespace: default
spec:
kubeconfig:
name: kurator-member1
key: kurator-member1.config
---
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: kurator-member2
namespace: default
spec:
kubeconfig:
name: kurator-member2
key: kurator-member2.config
EOF到这里为止,你已经把"多集群接入"变成了标准 K8s 对象:
Secret(凭据) + AttachedCluster(引用) = 可审计、可复用、可 GitOps 的纳管入口。🙂
如下是官方的文档说明:
8. 统一应用分发:用 Application CR 把 Git/Kustomize/Helm 一次性下发到 Fleet
Kurator 的应用分发文档给了非常典型的 Application 示例:
spec.source.gitRepository指向源码仓库;spec.syncPolicies[*].destination.fleet指定要分发到哪个 Fleet;kustomization.path指定仓库内路径;- 还给了
helmRepository + helm、gitRepository + helm的组合示例。
8.1 GitRepo + Kustomize 示例(官方 YAML 片段)
yaml
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: gitrepo-kustomization-demo
namespace: default
spec:
source:
gitRepository:
interval: 3m0s
ref:
branch: master
timeout: 1m0s
url: https://github.com/stefanprodan/podinfo
syncPolicies:
- destination:
fleet: quickstart
kustomization:
interval: 5m0s
path: ./deploy/webapp
prune: true
timeout: 2m0s
- destination:
fleet: quickstart
kustomization:
targetNamespace: default
interval: 5m0s
path: ./kustomize
prune: true
timeout: 2m0s应用分发文档中对应的操作命令是:先 apply 预制的 attachedClusters 与 fleet,再 apply 示例 Application。
bash
kubectl apply -f examples/application/common/
kubectl apply -f examples/application/gitrepo-kustomization-demo.yaml8.2 HelmRepo + HelmRelease 示例(官方 YAML 片段)
官方还给出 helmRepository 作为 source、helm 作为 syncPolicies 的示例,并展示了 values 里配置 redis、ingress className 等参数。
yaml
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: helmrepo-helmrelease-demo
namespace: default
spec:
source:
helmRepository:
interval: 5m
url: https://stefanprodan.github.io/podinfo
syncPolicies:
- destination:
fleet: quickstart
helm:
releaseName: podinfo
chart:
spec:
chart: podinfo
interval: 50m
install:
remediation:
retries: 3
values:
redis:
enabled: true
repository: public.ecr.aws/docker/library/redis
tag: 7.0.6
ingress:
enabled: true
className: nginx8.3 用标签选择器做"差异化分发"(同源应用分到不同集群)
应用分发文档还给出了一个关键实践点:先给 AttachedCluster 打标签,再运行带 selector 的 Application,从而实现"同源不同落点"的策略化分发。官方示例包括:
kubectl label attachedcluster kurator-member1 env=test、... env=dev,以及应用 selector demo 的 apply 命令。
bash
kubectl label attachedcluster kurator-member1 env=test
kubectl label attachedcluster kurator-member2 env=dev
kubectl apply -f examples/application/cluster-selector-demo.yaml运维作用分析(基于官方机制推导):
- 你可以把"环境差异"从 CI/CD 流水线里抽出来,沉到"集群对象标签 + 应用策略对象";
- 这会让发布链路更通用,平台侧只维护少量通用模板,环境差异通过标签/选择器收敛。🙂
最后,我们再结合如下这张,技术架构图起来理解:
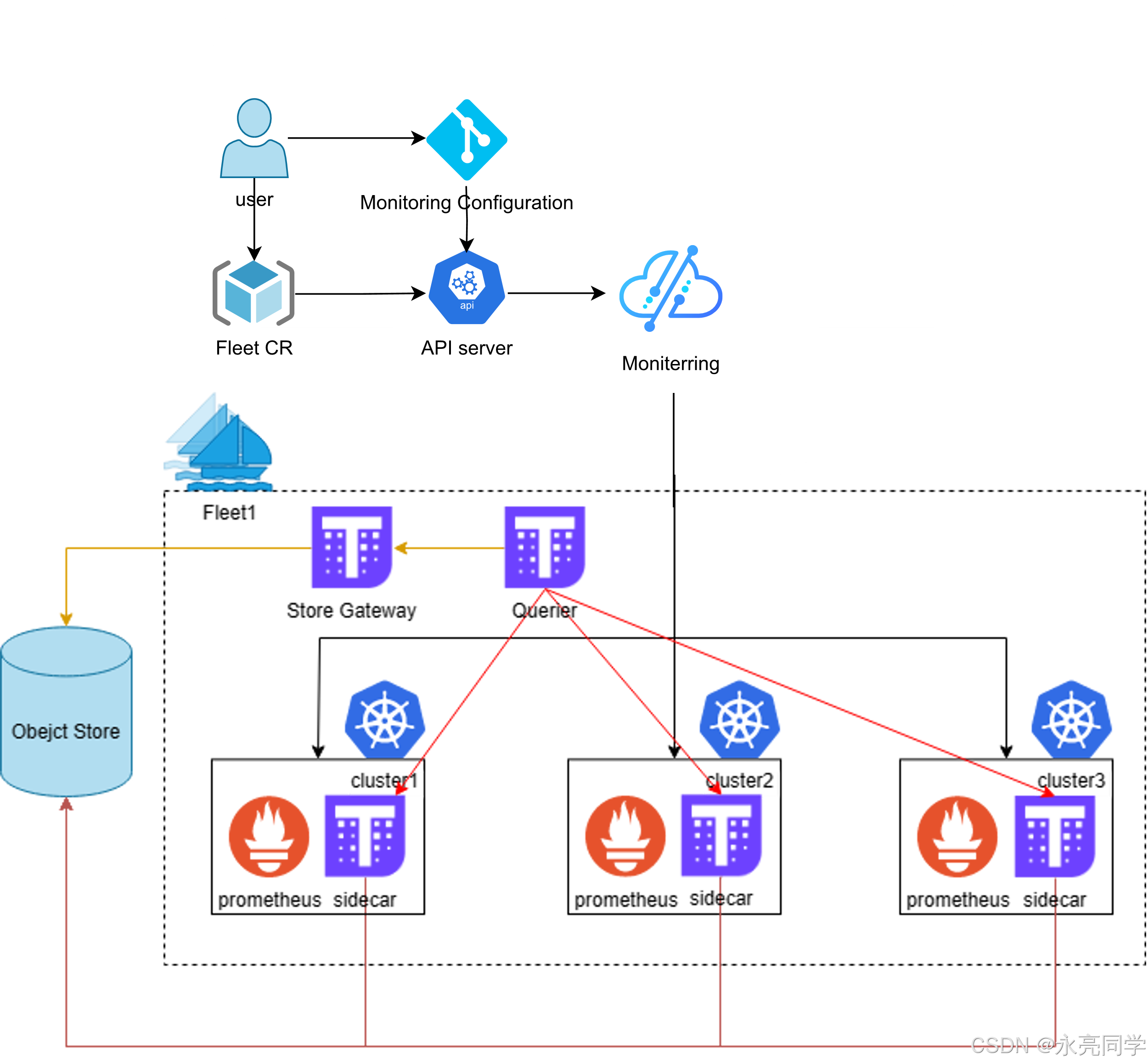
9. 统一监控:Fleet Metric 插件一键落 Thanos + Grafana,并用 Application 扩展监控配置
在"Enable multi cluster Monitoring with fleet"文档里,官方给出两段关键操作:
kubectl apply -f examples/fleet/metric/metric-plugin.yaml创建带 metric 插件的 Fleet;kubectl wait fleet quickstart ... Ready等待就绪;- 通过
kubectl get po验证 Thanos 与 Grafana Pod Running; - 进一步用 Application 把 avalanche + ServiceMonitor 分发到 Fleet。
bash
kubectl apply -f examples/fleet/metric/metric-plugin.yaml
kubectl wait fleet quickstart --for='jsonpath='{.status.phase}'=Ready'
kubectl get po
# 示例输出包含:default-thanos-query、default-thanos-storegateway、grafana 等然后用 Application 下发监控 demo(官方给出了完整 YAML 模板,source 指向 kurator-dev/kurator 仓库,path 指向 ./examples/fleet/metric/monitor-demo)。
bash
cat <<EOF | kubectl apply -f -
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: metric-demo
namespace: default
spec:
source:
gitRepository:
interval: 3m0s
ref:
branch: main
timeout: 1m0s
url: https://github.com/kurator-dev/kurator
syncPolicies:
- destination:
fleet: quickstart
kustomization:
interval: 5m0s
path: ./examples/fleet/metric/monitor-demo
prune: true
timeout: 2m0s
EOF运维作用分析(基于官方流程推导):
- 监控"底座能力"(Thanos/Grafana)由 Fleet 插件统一下沉;
- 监控"业务侧配置"(ServiceMonitor/目标工作负载)由 Application 统一分发;
- 两者都进入 GitOps/声明式闭环,跨集群一致性更容易保证。
而且,如下架构流程,我们也可以学到一些精髓。
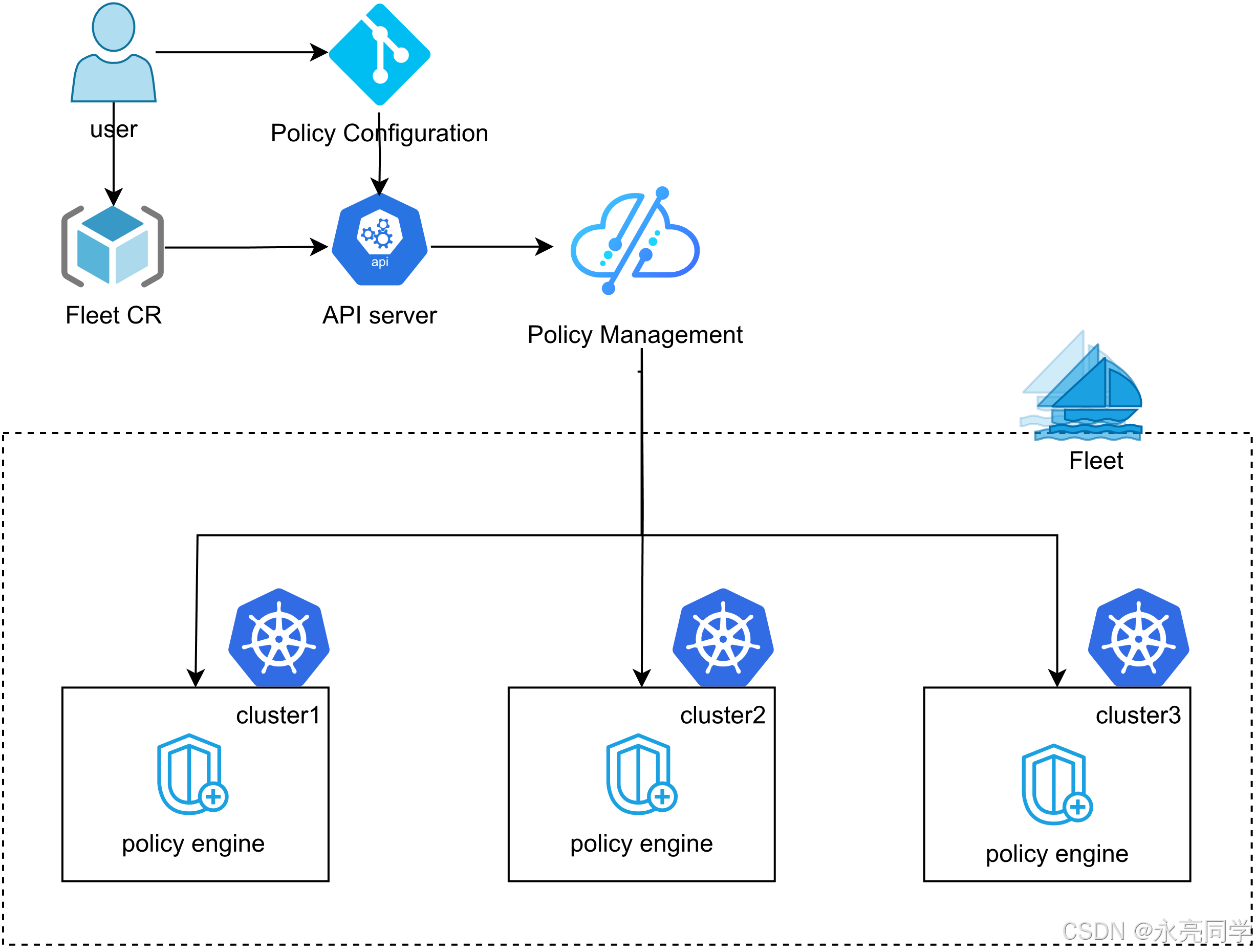
10. 统一策略管理:Fleet + Kyverno(Policyreport 验证)
"Policy Management"文档明确:Fleet 的多集群策略管理构建在 Kyverno 之上,并给出了从创建 Fleet(启用 baseline pod security check)到验证 policyreport 的完整步骤。
10.1 创建启用策略能力的 Fleet
bash
kubectl apply -f examples/fleet/policy/kyverno.yaml
kubectl wait fleet quickstart --for='jsonpath='{.status.phase}'=Ready'10.2 下发"bad pod"示例并验证 policyreport
官方用 Application 来分发策略验证示例(path 指向 ./examples/fleet/policy/badpod-demo),然后在成员集群上检查 policyreport。
bash
cat <<EOF | kubectl apply -f -
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: kyverno-policy-demo
namespace: default
spec:
source:
gitRepository:
interval: 3m0s
ref:
branch: main
timeout: 1m0s
url: https://github.com/kurator-dev/kurator
syncPolicies:
- destination:
fleet: quickstart
kustomization:
interval: 5m0s
path: ./examples/fleet/policy/badpod-demo
prune: true
timeout: 2m0s
EOF
kubectl get policyreport --kubeconfig=/root/.kube/kurator-member1.config官方还给出通过 kubectl describe pod ... | grep PolicyViolation 查看事件中 Kyverno 拒绝原因的方式。
11. 统一备份/恢复/迁移:Fleet Backup 插件(Velero)+ 统一状态视图
11.1 能力概览(官方定义)
"Unified Backup, Restore, and Migration"文档指出:Kurator 提供跨 Fleet 多集群的统一备份/恢复/迁移方案,并通过与 Velero 集成提供"一键方案 + 统一状态视图"。
11.2 安装 Backup 插件:对象存储是前置条件(Minio/OBS)
在"Install Backup Plugin"里,官方强调备份依赖 Velero 且需要 Object Storage;同时给出 Minio(本地验证)与 OBS(云对象存储示例)两条配置路径,并说明 Minio 仅用于验证、生产建议使用云厂商存储。
以 OBS 为例,官方提供创建 AK/SK secret 的命令:
bash
kubectl create secret generic obs-credentials \
--from-literal=access-key={YOUR_ACCESS_KEY} \
--from-literal=secret-key={YOUR_SECRET_KEY}以 Minio 为例,官方给出创建带 backup 插件的 Fleet YAML(包含 bucket/provider/endpoint/region/secretName),并提示 endpoint 取值取决于你的 Minio service IP(可参考 Minio 安装页的取 IP 方法)。
bash
kubectl apply -f - <<EOF
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: quickstart
namespace: default
spec:
clusters:
- name: kurator-member1
kind: AttachedCluster
- name: kurator-member2
kind: AttachedCluster
plugin:
backup:
storage:
location:
bucket: velero
provider: aws
endpoint: http://172.18.255.200:9000
region: minio
secretName: minio-credentials
EOF11.3 验证插件安装:检查 velero Pod 与 BackupStorageLocation
官方给出两步验证:
kubectl get pod -n velero --kubeconfig=...检查 velero 相关 Pod Running;kubectl get backupstoragelocations.velero.io ...观察 PHASE 为 Available。
bash
kubectl get pod -n velero --kubeconfig=/root/.kube/kurator-member1.config
kubectl get backupstoragelocations.velero.io -A --kubeconfig=/root/.kube/kurator-member1.config11.4 执行一次"统一备份":Immediate / Scheduled(官方示例)
"Unified Backup"文档说明:支持 Immediate 与 Scheduled 两类方式;并给出示例:先部署测试应用,再 apply 备份对象,最后 kubectl get backups... -o yaml 查看 status 里跨集群的备份详情。
bash
# 部署测试应用(跨 fleet 两集群)
kubectl apply -f examples/backup/app-backup-demo.yaml
# 立即备份示例(按 label 选择资源)
kubectl apply -f examples/backup/backup-select-labels.yaml
kubectl get backups.backup.kurator.dev select-labels -o yaml
# 定时备份示例(cron 表达式)
kubectl apply -f examples/backup/backup-schedule.yaml
kubectl get backups.backup.kurator.dev schedule -o yaml官方还特别说明:在 kind 环境下做 PV 备份会受到 restic 约束影响(官方指出这是一个已知问题),因此示例主要用 busybox;真实集群可以选择带 PV 的示例。
灾备运维价值分析(基于官方 status 结构推导):
- Backup CRD 的
status.backupDetails为每个集群记录phase/completionTimestamp/expiration等信息(官方示例 YAML 中展示了两集群各自的 Completed 状态);- 这让"我这一份备份在每个集群是否都成功"变得可查询、可自动化告警、可审计。
12. 统一发布与流量治理:Rollout 插件(Flagger)+ 多集群一致的渐进式发布
12.1 官方能力定义:统一 Rollout 系统 + 扩展 Application 配置
"Unified Rollout"文档说明:Kurator 在 Fleet 支撑下提供跨多集群统一 Rollout,并通过 Flagger 实现;同时扩展 Kurator Application 配置,使应用与 Rollout 配置能在一个地方声明。
同时 Rollout 文档对架构做了明确描述:Rollout Controller 负责管理 Fleet 并渲染 Flagger 配置;并解释了 primary/canary 的角色,以及通过 service selector + virtual service 迁移流量的方式。
12.2 安装 Rollout 插件:在 Fleet 中配置 plugin.flagger
"Install Rollout Plugin"给出创建 Fleet 的 YAML:plugin.flagger.publicTestloader 与 trafficRoutingProvider: istio,并明确 trafficRoutingProvider 当前支持 Istio/Kuma/Nginx。
bash
kubectl apply -f -<<EOF
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: quickstart
namespace: default
spec:
clusters:
- name: kurator-member1
kind: AttachedCluster
- name: kurator-member2
kind: AttachedCluster
plugin:
flagger:
publicTestloader: true
trafficRoutingProvider: istio
EOF安装验证方式:在成员集群的 istio-system 命名空间检查 flager/testloader Pod Running。
bash
kubectl get pod -n istio-system --kubeconfig=/root/.kube/kurator-member1.config
kubectl get pod -n istio-system --kubeconfig=/root/.kube/kurator-member2.config12.3 Istio Canary 快速上手:前置条件 + 一条命令部署示例
"Istio Canary Deployment"文档列出前置条件:Kubernetes v1.27.3+、Istio v1.18+、Prometheus、Ingress Gateway、已安装 Kurator Rollout Plugin;并给出了 Istio 安装、Prometheus addon 安装、Gateway YAML。
安装 Istio(示例命令):
bash
export KUBECONFIG=/root/.kube/kurator-member1.config
istioctl manifest install --set profile=default
kubectl get po -n istio-system --kubeconfig=/root/.kube/kurator-member1.config安装 Prometheus addon(示例命令):
bash
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.20/samples/addons/prometheus.yaml
kubectl get po -n istio-system --kubeconfig=/root/.kube/kurator-member1.config创建 Ingress Gateway(官方 YAML):
bash
kubectl apply -f -<<EOF
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: public-gateway
namespace: istio-system
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
EOF
kubectl get gateway -n istio-system --kubeconfig=/root/.kube/kurator-member1.config随后,官方给出"一条命令"部署 canary 示例应用:
bash
kubectl apply -f examples/rollout/canary.yaml
kubectl get application rollout-demo -oyaml并展示了 Application.spec.syncPolicies.rollout 的结构示例(包含 metrics、webhooks、trafficRouting、gateways/hosts 等),说明 Kurator 可在此处自定义 rollout 策略;同时给出查看 canary 状态的命令:
bash
kubectl get canary -n webapp --kubeconfig=/root/.kube/kurator-member1.config发布运维价值分析(基于官方字段解释推导):
- Rollout 策略与应用分发同属一个 Application 声明,意味着你可以把"发布策略"像"应用配置"一样纳入版本管理;
trafficAnalysis.metrics + webhooks让"是否继续放量"具备可观测依据(文档明确 metrics 可用内置类型或自定义),减少纯人工判断。
当然,如果我们有任何疑问,我们可以提Issues,向官方求解。
13. 机房/边缘场景的集群生命周期治理:On-Premise 声明式扩缩与替换节点
如果你的目标是"分布式云原生平台"(跨云、跨边、跨机房),集群生命周期往往不能只靠托管集群,还会涉及自建机房或边缘节点。Kurator 在 "On-Premise Kubernetes Cluster Lifecycle Management" 文档中给出:可在 on-premise servers 上 声明式地增加/删除/替换多个 worker 节点,并强调扩缩时不要修改 hostname(避免同一服务器多名字导致问题)。
13.1 声明式扩容(Scaling up)与缩容(Scaling down)
官方给出一个 custommachine 片段:
- 移除 node1 表示缩容;
- 增加 node2/node3 表示扩容;
然后通过kubectl apply -f examples/infra/my-customcluster/scale.yaml重新应用声明,Kurator 会创建 scale-up/scale-down pod 执行操作,并给出通过 grep pod 名称观察执行过程的方法。
bash
kubectl apply -f examples/infra/my-customcluster/scale.yaml
# 观察扩容执行 pod
kubectl get pod -A | grep -i scale-up
# 观察缩容执行 pod
kubectl get pod -A | grep -i scale-down生命周期治理价值分析(基于官方流程推导):
- 扩缩动作从"手工进机器/脚本散落"收敛为"声明式对象 + 可观测的执行 pod";
- 对平台团队而言,这更接近"把交付物标准化",有利于形成统一 SOP 与审计链路。
而且针对其开源项目,我们也可以查看其下载活跃值:
14. 清理与回收:让"试用环境"可一键回滚(官方给出完整卸载路径)
官方在多个章节都提供了 cleanup 方式。例如策略管理页给出:删除 Application、删除 Fleet、helm uninstall fleet-manager/cluster-operator、必要时删除 CRD/namespace/cert-manager、kind delete cluster 等。
典型清理命令(按官方示例组合):
json
# 删除示例对象
kubectl delete application kyverno-policy-demo
kubectl delete fleet quickstart
# 卸载 kurator 组件
helm uninstall kurator-fleet-manager -n kurator-system
helm uninstall kurator-cluster-operator -n kurator-system
# 清理 fluxcd(如按官方方式安装)
helm delete fluxcd -n fluxcd-system
kubectl delete ns fluxcd-system --ignore-not-found15. 实战结语:用 Kurator 组织"平台能力"的三条落地建议(不拼工具堆叠,拼一致性)
结合本文基于官方文档跑通的链路(Fleet 纳管 → Application 分发 → Monitoring/Policy/Backup/Rollout 插件下沉 → On-Prem 扩缩),我给出三条更偏"平台工程落地"的建议(仅做工程推导,不额外宣称官方未描述能力):
-
把"集群/舰队/应用/策略/备份/发布"统一视为"可版本化对象"
你会自然获得:可审计(Git 记录)、可回滚(回退提交)、可复制(环境复制)------这与官方大量采用
kubectl apply -f ...、Application/Fleet/Backup等 CRD 的范式是一致的。 -
先做"通用底座插件下沉",再做"业务配置 Application 分发"
官方监控与策略的文档都体现了这个层次:Fleet 插件负责装 Thanos/Grafana、Kyverno;Application 负责把 monitor-demo、badpod-demo 这类"业务侧配置"下发到各集群。
-
把"渐进式发布"与"可观测指标"绑定,形成可自动化的发布护栏
官方 Rollout(Flagger)文档明确了 metrics/webhooks/trafficRouting 的配置与解释路径,这意味着你可以在平台层形成统一发布策略模板,让每个团队以较低成本复用同一套放量逻辑。
最后,附上相关开源学习地址:
- Kurator分布式云原生开源社区地址:https://gitcode.com/kurator-dev
- Kurator分布式云原生项目部署指南:https://kurator.dev/docs/setup/