为什么要实现这3个核心功能?
上一篇我们搭建了基础框架,AI已经能"看到"数据库中有哪些表了。但这还远远不够,今天咱们要让AI变得更聪明,实现3个核心功能:
- 能智能搜索相关的表
- 能深度理解表的结构
- 能安全地执行SQL查询
第一步:filter_table_names() - 智能搜索表名
第1周我们已经能获取所有表名了,但当数据库有几十个表的时候,你得能快速找到相关的表。这就像在图书馆里找书,你不可能一本本翻,得按分类找。
python
@mcp.tool(description="根据关键词搜索相关的表名。支持模糊匹配,不区分大小写。")
def filter_table_names(keyword: str) -> str:
"""根据关键词搜索相关的表名"""
try:
if not keyword or not keyword.strip():
return "请提供搜索关键词"
db_mgr = get_database_manager()
matching_tables = db_mgr.filter_table_names(keyword.strip())
if matching_tables:
table_list = ", ".join(matching_tables)
result = f"搜索关键词 '{keyword}' 找到 {len(matching_tables)} 个相关表:\n"
result += f"匹配的表: {table_list}"
logger.info(f"关键词 '{keyword}' 匹配到: {table_list}")
return result
else:
all_tables = db_mgr.get_table_names()
all_table_list = ", ".join(all_tables) if all_tables else "无"
result = f"搜索关键词 '{keyword}' 没有找到匹配的表。\n"
result += f"数据库中的所有表: {all_table_list}\n"
result += f"建议尝试其他关键词,如表名的一部分。"
logger.info(f"关键词 '{keyword}' 没有找到匹配的表。")
return result
except Exception as e:
error_msg = f"搜索表名失败: {str(e)}"
logger.error(error_msg)
return f"{error_msg}"数据库管理器中的搜索逻辑:
python
def filter_table_names(self, keyword: str) -> List[str]:
"""根据关键词搜索相关表名"""
try:
all_tables = self.get_table_names()
# 不区分大小写的模糊匹配
matching_tables = [
table for table in all_tables
if keyword.lower() in table.lower()
]
return matching_tables
except Exception as e:
logger.error(f"搜索表名失败: {e}")
raise这个功能在大型项目中特别有用,想象一下在一个有100个表的电商系统中快速找到所有支付相关的表!
第二步:schema_definitions() - 深度解析表结构
知道表名还不够,得知道表里有什么字段、什么类型、什么关系。
python
@mcp.tool(description="获取指定表的详细结构信息,包括列、类型、主键、索引、外键等。支持同时查询多个表。")
def schema_info(table_names: List[str]) -> str:
"""获取指定表的详细结构信息"""
try:
if not table_names:
return "请提供要查询的表名"
db_mgr = get_database_manager()
result_parts = []
for table_name in table_names:
try:
schema_info = db_mgr.get_table_schema(table_name)
# 格式化表结构信息
table_section = f"\n{'='*50}\n"
table_section += f"表名:{table_name}\n"
table_section += f"列:{schema_info['columns']}\n"
table_section += f"{'='*50}\n"
# 列信息
column_section = "列信息:\n"
for col in schema_info['columns']:
col_type = col['type']
nullable = "可空" if col['nullable'] else "不可空"
pk_mark = " 主键" if col['is_primary_key'] else ""
default_info = f" (默认: {col['default']})" if col['default'] else ""
table_section += f" • {col['name']}: {col_type} - {nullable}{pk_mark}{default_info}\n"
# 主键信息
if schema_info['primary_keys']:
table_section += f"\n主键: {', '.join(schema_info['primary_keys'])}\n"
# 索引信息
if schema_info['indexes']:
table_section += "\n索引信息:\n"
for idx in schema_info['indexes']:
unique_mark = "唯一索引" if idx.get('unique', False) else "普通索引"
columns = ', '.join(idx['column_names'])
table_section += f" • {idx['name']}: {unique_mark} ({columns})\n"
# 外键信息
if schema_info['foreign_keys']:
table_section += "\n外键关系:\n"
for fk in schema_info['foreign_keys']:
local_cols = ', '.join(fk['constrained_columns'])
ref_table = fk['referred_table']
ref_cols = ', '.join(fk['referred_columns'])
table_section += f" • {local_cols} → {ref_table}.{ref_cols}\n"
result_parts.append(table_section)
except ValueError as e:
result_parts.append(f"\n表 '{table_name}': {str(e)}\n")
except Exception as e:
result_parts.append(f"\n表 '{table_name}' 解析失败: {str(e)}\n")
final_result = '\n'.join(result_parts)
logger.info(f"成功解析 {len(table_names)} 个表的结构")
return final_result
except Exception as e:
error_msg = f"获取表结构信息失败: {str(e)}"
logger.error(error_msg)
return f"{error_msg}"数据库管理器中的解析逻辑:
python
def get_table_schema(self, table_name: str) -> Dict[str, Any]:
"""获取指定表的详细结构信息"""
try:
with self.get_connection() as conn:
inspector = inspect(conn)
# 验证表是否存在
if table_name not in inspector.get_table_names():
raise ValueError(f"表 '{table_name}' 不存在")
# 获取列信息
columns = inspector.get_columns(table_name)
# 获取主键信息
pk_constraint = inspector.get_pk_constraint(table_name)
primary_keys = set(pk_constraint["constrained_columns"])
# 获取索引信息
indexes = inspector.get_indexes(table_name)
# 获取外键信息
foreign_keys = inspector.get_foreign_keys(table_name)
# 格式化列信息
formatted_columns = []
for col in columns:
col_info = {
"name": col["name"],
"type": str(col["type"]),
"nullable": col["nullable"],
"default": col.get("default"),
"is_primary_key": col["name"] in primary_keys
}
formatted_columns.append(col_info)
schema_info = {
"table_name": table_name,
"columns": formatted_columns,
"primary_keys": list(primary_keys),
"indexes": indexes,
"foreign_keys": foreign_keys,
"column_count": len(columns)
}
return schema_info
except Exception as e:
logger.error(f"获取表结构信息失败: {e}")
raise第三步:execute_query() - 安全执行SQL查询
最后这个功能是核心中的核心!让AI能执行SQL查询,但必须确保安全性。我们只允许SELECT查询,并且有完整的防护措施。
python
@mcp.tool(description="安全执行SQL查询语句。只支持SELECT查询,自动添加结果限制,支持参数化查询防止SQL注入。")
def execute_query(query: str, params: dict = None) -> str:
try:
if not query or not query.strip():
return "请提供查询语句"
db_mgr = get_database_manager()
# 如果没有提供参数,设为None
query_params = params if params else None
# 执行查询
result = db_mgr.execute_query(query.strip(), query_params)
if not result:
return "查询结果为空"
#格式化返结果
result_text = "查询结果:\n"
for row in result:
result_text += f"{row}\n"
return result_text
except ValueError as e:
# 安全验证失败
error_msg = f"查询安全验证失败: {str(e)}"
logger.warning(error_msg)
return f"{error_msg}\n\n 提示:本工具只支持 SELECT 查询,且会自动添加安全限制。"
except Exception as e:
error_msg = f"执行查询失败: {str(e)}"
logger.error(error_msg)
return f"{error_msg}"数据库管理器中也要有验证:
python
def _validate_query(self, query: str) -> None:
"""验证查询安全性"""
query_upper = query.upper().strip()
# 检查危险的SQL操作
dangerous_keywords = [
"DROP", "DELETE", "UPDATE", "INSERT", "ALTER", "CREATE", "TRUNCATE"
]
for keyword in dangerous_keywords:
if keyword in query_upper:
raise ValueError(f"查询包含危险操作: {keyword}")
# 检查是否是SELECT查询
if not query_upper.startswith("SELECT"):
raise ValueError("只允许执行SELECT查询")
def _add_limit_to_query(self, query: str, limit: int) -> str:
"""为查询添加LIMIT子句"""
query_upper = query.upper()
# 如果已经有LIMIT,不再添加
if "LIMIT" in query_upper:
return query
# 添加LIMIT子句
return f"{query.rstrip(';')} LIMIT {limit}"
def execute_query(self, query: str, params: dict = None) -> List[Dict[str, Any]]:
"""安全执行SQL查询"""
try:
# 验证查询安全性
self._validate_query(query)
# 添加默认限制
limited_query = self._add_limit_to_query(query, 1000)
with self.get_connection() as conn:
if params:
# 使用参数化查询
result = conn.execute(text(limited_query), params)
else:
# 直接执行查询
result = conn.execute(text(limited_query))
# 获取列名
columns = result.keys()
# 转换为字典列表
rows = []
for row in result:
row_dict = dict(zip(columns, row))
rows.append(row_dict)
return rows
except Exception as e:
logger.error(f"执行查询失败: {e}")
raise第四步:功能验证测试
为了确保所有功能都正常工作,我们创建一个简单的验证脚本。这不是复杂的单元测试,而是帮助读者快速验证功能的工具。
创建验证脚本
python
"""
tests/verify_functions.py - 功能验证脚本
"""
import os
import sys
from pathlib import Path
# 添加项目路径
project_root = Path(__file__).parent.parent
sys.path.insert(0, str(project_root / "src"))
def verify_database_connection():
"""验证数据库连接"""
print("=== 数据库连接验证 ===")
# 设置数据库URL
db_path = project_root / "data" / "test.db"
if not db_path.exists():
print("测试数据库不存在!")
return False
os.environ['DB_URL'] = f'sqlite:///{db_path}'
try:
from mcp_datatools.database import DatabaseManager
db_mgr = DatabaseManager()
if db_mgr.test_connection():
print("数据库连接成功")
return True
else:
print("数据库连接失败")
return False
except Exception as e:
print(f"数据库连接错误: {e}")
return False
def verify_basic_functions():
"""验证基础功能"""
print("\n=== 基础功能验证 ===")
try:
from mcp_datatools.database import DatabaseManager
db_mgr = DatabaseManager()
# 测试1: 获取表名
print("1. 测试 list_tables() 功能...")
tables = db_mgr.get_table_names()
print(f" 找到 {len(tables)} 个表: {', '.join(tables)}")
# 测试2: 搜索表名
print("2. 测试 filter_table_names() 功能...")
user_tables = db_mgr.filter_table_names('user')
print(f" 搜索 'user' 找到: {user_tables}")
# 测试3: 获取表结构
print("3. 测试 get_table_schema() 功能...")
if tables:
schema = db_mgr.get_table_schema(tables[0])
print(f" 表 '{tables[0]}' 有 {schema['column_count']} 个列")
# 测试4: 执行查询
print("4. 测试 execute_query() 功能...")
result = db_mgr.execute_query("SELECT COUNT(*) as count FROM users")
print(f" 查询结果: {result}")
return True
except Exception as e:
print(f"功能验证失败: {e}")
return False
def main():
"""主验证流程"""
print("MCP DataTools 功能验证")
print("=" * 50)
# 验证数据库连接
db_ok = verify_database_connection()
if db_ok:
# 验证基础功能
func_ok = verify_basic_functions()
if func_ok:
print("\n 所有基础功能验证通过!")
else:
print("\n部分功能验证失败,请检查代码")
else:
print("\n数据库连接失败,请先创建测试数据库")
print("\n" + "=" * 50)
print("验证完成!现在可以在Cursor中测试MCP功能了。")
if __name__ == "__main__":
main()运行验证
bash
# 1. 确保有测试数据
python data/init_sqlite_db.py
# 2. 运行功能验证
python tests/verify_functions.py验证结果示例
css
MCP DataTools 功能验证
==================================================
=== 数据库连接验证 ===
数据库连接成功
=== 基础功能验证 ===
1. 测试 list_tables() 功能...
找到 3 个表: orders, products, users
2. 测试 filter_table_names() 功能...
搜索 'user' 找到: ['users']
3. 测试 get_table_schema() 功能...
表 'orders' 有 3 个列
4. 测试 execute_query() 功能...
查询结果: [{'count': 2}]
所有基础功能验证通过!
==================================================
验证完成!现在可以在Cursor中测试MCP功能了。第五步:功能演示效果
现在让我们看看这些功能在实际使用中的效果:
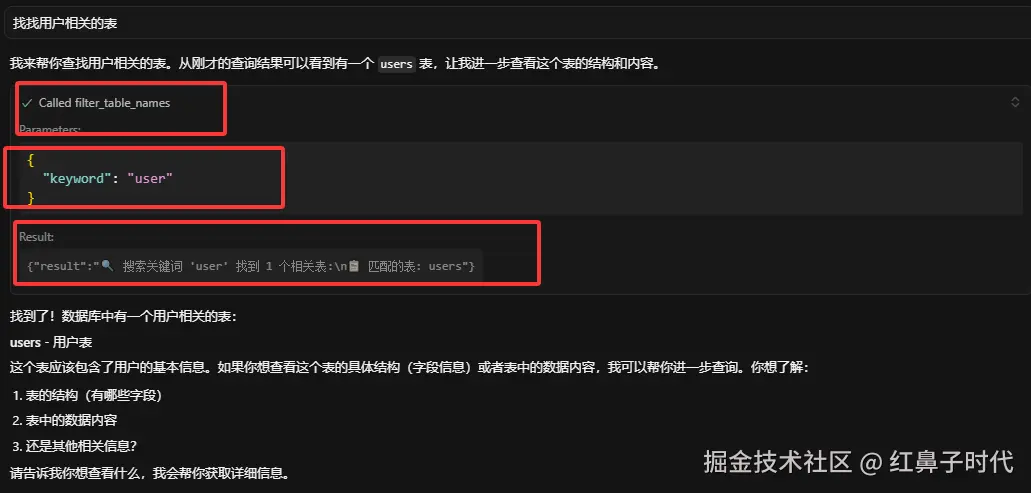
1. 智能搜索表名
试试问AI:"找找用户相关的表"
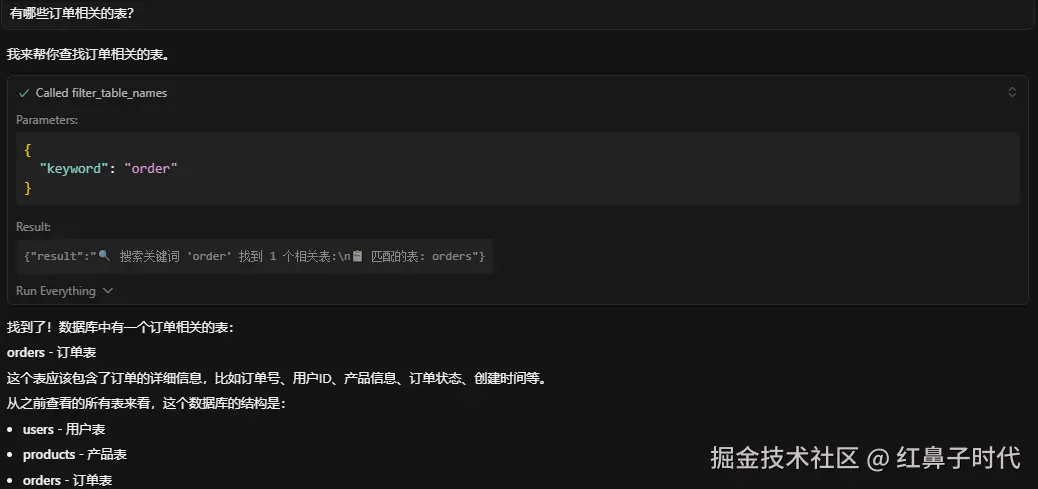
或者问:"有哪些订单相关的表?"
2. 深度解析表结构
问AI:"users表的结构是什么样的?" 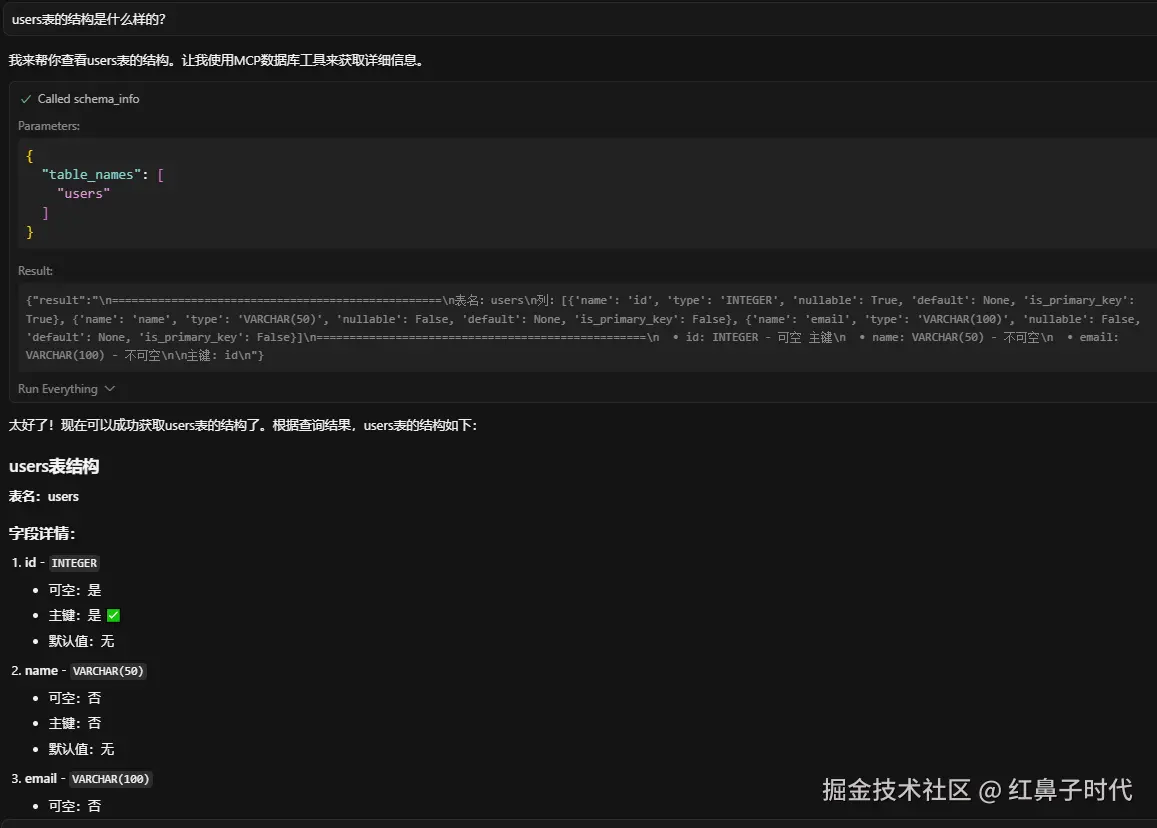
3. 安全执行SQL查询
简单查询: "查询users表中的所有数据" AI执行:SELECT * FROM users 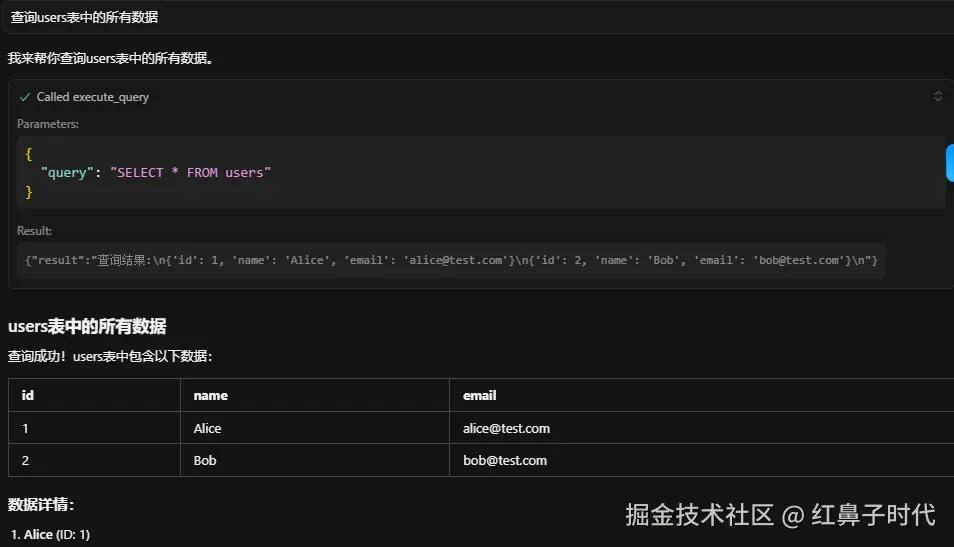
条件查询: "查询价格大于1000的产品" AI执行:SELECT * FROM products WHERE price > 1000 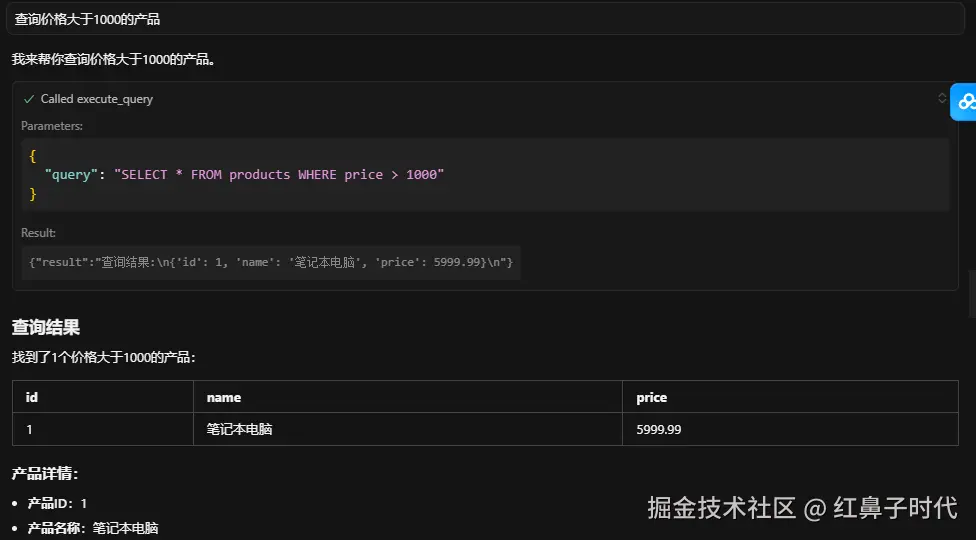
复杂查询: "查询每个用户的订单数量" AI可以执行JOIN查询 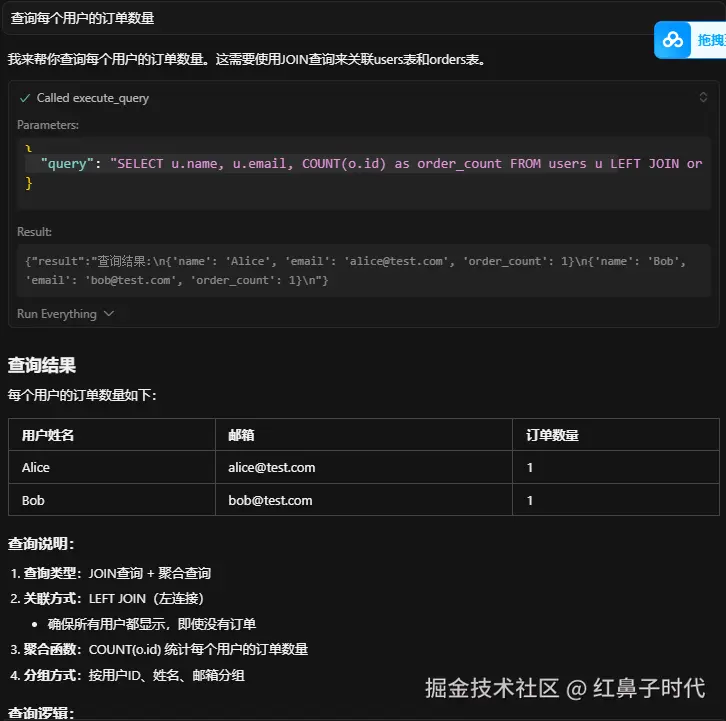
总结与预告
第2篇我们成功实现了3个核心功能:表搜索、结构分析、安全SQL执行,让AI能够理解数据库结构并执行复杂查询。第3篇将实现PostgreSQL、MySQL等主流数据库支持,加上基础连接池配置和Docker部署,让这个工具真正走向生产环境。