代码已上传github上,这是github仓库地址,如果项目对你有帮助,欢迎点个Star鼓励!
为什么要支持多数据库?
前两章我们只支持SQLite,但现实中的企业环境需要:
- PostgreSQL - 企业级应用的首选,功能强大
- MySQL - Web应用最流行的数据库
- 配置管理 - 一套代码支持多种环境
今天我们要让MCP DataTools从"玩具"变成"工具"!
第一步:项目结构升级
这次的项目结构更加完善:
bash
mcp-datatools/
├── pyproject.toml # 升级依赖配置
├── docker-compose.db.yml # 数据库环境(可选)
├── config/
│ ├── __init__.py
│ └── settings.py # 应用配置管理
├── src/
│ └── mcp_datatools/
│ ├── __init__.py
│ ├── server.py # 升级的MCP服务器
│ ├── database.py # 多数据库管理器
│ └── utils.py # 公共工具函数
├── tests/
│ └── test_multi_database.py # 多数据库测试
└── data/
├── test.db # SQLite测试数据
└── init_scripts/ # 数据库初始化脚本
├── init_sqlite_db.py # SQLite初始化脚本
├── init_postgresql_db.py # PostgreSQL初始化脚本
└── mysql.sql # MySQL初始化脚本第二步:依赖升级
首先升级pyproject.toml,添加多数据库支持:
toml
# MCP DataTools 项目配置文件
# 这是一个支持多数据库连接的MCP服务器项目
[project]
# 项目基本信息
name = "mcp-datatools"
version = "0.3.0"
description = "A MCP server that connects to multiple databases"
requires-python = ">=3.10" # 最低Python版本要求
# 核心依赖包
dependencies = [
"mcp>=1.0.0", # MCP协议核心库
"sqlalchemy>=2.0.0", # SQLAlchemy ORM,支持多种数据库
"psycopg2-binary>=2.9.0", # PostgreSQL数据库驱动
"pymysql>=1.1.0", # MySQL数据库驱动
"cryptography>=41.0.0", # 加密支持,用于安全连接
"python-dotenv>=1.0.0", # 环境变量管理
"pydantic>=2.0.0", # 数据验证和序列化
"pydantic-settings>=2.10.1", # 配置管理扩展
]
# 可选依赖包(开发环境)
[project.optional-dependencies]
dev = [
"pytest>=7.0.0", # 测试框架
"pytest-asyncio>=0.21.0", # 异步测试支持
"black>=23.0.0", # 代码格式化工具
"isort>=5.12.0", # 导入排序工具
]
# 构建系统配置
[build-system]
requires = ["hatchling"] # 使用hatchling作为构建后端
build-backend = "hatchling.build"
# 打包配置
[tool.hatch.build.targets.wheel]
packages = ["src/mcp_datatools"] # 指定要打包的源码目录
# 命令行脚本配置
[project.scripts]
mcp-datatools = "mcp_datatools.server:main" # 定义命令行入口点
# 测试配置
[tool.pytest.ini_options]
pythonpath = ["src"] # 添加src目录到Python路径
# 代码格式化配置
[tool.black]
line-length = 88 # 每行最大字符数
target-version = ['py310'] # 目标Python版本
# 导入排序配置
[tool.isort]
profile = "black" # 使用black兼容的配置
multi_line_output = 3 # 多行导入的格式第三步:配置管理系统
创建统一的配置管理系统:
python
"""
config/settings.py - 应用配置管理
"""
from pydantic_settings import BaseSettings
from pydantic import Field, ConfigDict
from typing import Dict, Any
class DatabaseConfig(BaseSettings):
"""数据库配置"""
model_config = ConfigDict(env_prefix="DB_")
pool_size : int = Field(default=20, description="连接池大小")
max_overflow: int = Field(default=10, description="连接池最大溢出数")
pool_timeout: int = Field(default=30, description="连接池超时时间")
pool_recycle: int = Field(default=3600, description="连接池回收时间")
echo: bool = Field(default=False, description="是否打印SQL语句")
class AppConfig(BaseSettings):
"""应用配置"""
model_config = ConfigDict(env_prefix="APP_")
name: str = Field(default="MCP DataTools", description="应用名称")
version: str = Field(default="1.0.0", description="应用版本")
log_level: str = Field(default="INFO", description="日志级别")
max_query_results: int = Field(default=1000, description="结果最大查询行数")
# 数据库配置
database: DatabaseConfig = Field(default_factory=DatabaseConfig, description="数据库配置")
# 全局配置实例
config = AppConfig()第四步:多数据库连接管理
升级数据库管理器,支持多种数据库:
python
"""
src/mcp_datatools/database.py - 多数据库管理器
"""
from .utils import setup_project_path
setup_project_path()
from typing import List, Dict, Any
from contextlib import contextmanager
from sqlalchemy import create_engine, inspect, text
from sqlalchemy.exc import SQLAlchemyError
from sqlalchemy.pool import QueuePool
from mcp.server.fastmcp.utilities.logging import get_logger
from config.settings import config
from .utils import mask_password
logger = get_logger(__name__)
class MultiDatabaseManager:
"""多数据库管理器"""
def __init__(self, database_url: str):
"""初始化数据库管理器(必须显式提供 database_url)"""
if not database_url or not isinstance(database_url, str) or not database_url.strip():
raise ValueError("必须显式提供 database_url")
self.database_url = database_url.strip()
self.engine = None
self.db_type = self._detect_database_type()
self._connect()
def _detect_database_type(self) -> str:
"""检测数据库类型"""
url = self.database_url.lower()
if url.startswith("postgresql://") or url.startswith("postgres://"):
return "postgresql"
elif url.startswith("mysql://") or url.startswith("mysql+"):
return "mysql"
elif url.startswith("sqlite://"):
return "sqlite"
else:
return "unknown"
def _connect(self) -> None:
"""连接数据库"""
try:
# 根据数据库类型调整配置
if self.db_type == "sqlite":
# SQLite使用最简配置,避免复杂的连接池
self.engine = create_engine(
self.database_url,
echo=config.database.echo,
connect_args={"check_same_thread": False} # 允许多线程
)
else:
# PostgreSQL和MySQL使用完整连接池配置
self.engine = create_engine(
self.database_url,
poolclass=QueuePool, # 明确指定队列式连接池
pool_size=config.database.pool_size,
max_overflow=config.database.max_overflow,
pool_timeout=config.database.pool_timeout,
pool_recycle=config.database.pool_recycle,
echo=config.database.echo
)
logger.info(f"成功连接到 {self.db_type} 数据库: {mask_password(self.database_url)}")
except Exception as e:
logger.error(f"连接数据库时出错: {str(e)}")
raise
@contextmanager
def get_connection(self):
"""获取数据库连接的上下文管理器"""
if not self.engine:
raise RuntimeError("数据库未连接")
conn = self.engine.connect()
try:
yield conn
finally:
conn.close()
def get_database_info(self) -> Dict[str, Any]:
"""获取数据库信息"""
try:
with self.get_connection() as conn:
info = {
"type": self.db_type,
"url": mask_password(self.database_url),
"tables_count": len(self.get_table_names()),
}
# 只为非SQLite数据库显示连接池信息
if self.db_type != "sqlite":
if hasattr(self.engine, 'pool'):
try:
pool_info = {}
# 统一尝试获取各种连接池信息
if hasattr(self.engine.pool, 'size'):
pool_info["size"] = self.engine.pool.size()
if hasattr(self.engine.pool, 'checkedout'):
pool_info["checked_out"] = self.engine.pool.checkedout()
if hasattr(self.engine.pool, 'overflow'):
pool_info["overflow"] = self.engine.pool.overflow()
# 对于checked_in,不同的连接池实现可能不同
if hasattr(self.engine.pool, 'checked_in'):
pool_info["checked_in"] = self.engine.pool.checked_in()
elif hasattr(self.engine.pool, 'checkedin'):
pool_info["checked_in"] = self.engine.pool.checkedin()
else:
# 如果都没有,计算可用连接数
if "size" in pool_info and "checked_out" in pool_info:
pool_info["checked_in"] = pool_info["size"] - pool_info["checked_out"]
info["connection_pool"] = pool_info if pool_info else None
except Exception as pool_error:
logger.warning(f"获取连接池信息失败: {pool_error}")
info["connection_pool"] = None
else:
info["connection_pool"] = None
else:
# SQLite 不显示连接池信息
info["connection_pool"] = None
return info
except Exception as e:
logger.error(f"获取数据库信息失败: {e}")
return {"type": self.db_type, "error": str(e)}
def get_table_names(self) -> List[str]:
"""获取数据库中的所有表名"""
try:
with self.get_connection() as conn:
inspector = inspect(conn)
table_names = inspector.get_table_names()
return table_names
except SQLAlchemyError as e:
logger.error(f"获取表名失败: {e}")
raise
def test_connection(self) -> bool:
"""测试数据库连接"""
try:
with self.get_connection() as conn:
result = conn.execute(text("SELECT 1")).scalar()
return result == 1
except Exception as e:
logger.error(f"测试数据库连接时出错: {str(e)}")
return False
def filter_table_names(self, keyword: str) -> List[str]:
"""根据关键词搜索相关表名"""
try:
all_tables = self.get_table_names()
matching_tables = [
table for table in all_tables
if keyword.lower() in table.lower()
]
return matching_tables
except Exception as e:
logger.error(f"搜索表名失败: {e}")
raise
def get_table_schema(self, table_name: str) -> Dict[str, Any]:
"""获取指定表的详细结构信息"""
try:
with self.get_connection() as conn:
inspector = inspect(conn)
# 验证表是否存在
if table_name not in inspector.get_table_names():
raise ValueError(f"表 '{table_name}' 不存在")
# 获取列信息
columns = inspector.get_columns(table_name)
# 获取主键信息
pk_constraint = inspector.get_pk_constraint(table_name)
primary_keys = set(pk_constraint["constrained_columns"])
# 获取索引信息
indexes = inspector.get_indexes(table_name)
# 获取外键信息
foreign_keys = inspector.get_foreign_keys(table_name)
# 格式化列信息
formatted_columns = []
for col in columns:
col_info = {
"name": col["name"],
"type": str(col["type"]),
"nullable": col["nullable"],
"default": col.get("default"),
"is_primary_key": col["name"] in primary_keys
}
formatted_columns.append(col_info)
schema_info = {
"table_name": table_name,
"columns": formatted_columns,
"primary_keys": list(primary_keys),
"indexes": indexes,
"foreign_keys": foreign_keys,
"column_count": len(columns)
}
return schema_info
except Exception as e:
logger.error(f"获取表结构信息失败: {e}")
raise
def _validate_query(self, query: str) -> None:
"""验证查询安全性"""
query_upper = query.upper().strip()
# 检查危险的SQL操作
dangerous_keywords = [
"DROP", "DELETE", "UPDATE", "INSERT", "ALTER", "CREATE", "TRUNCATE"
]
for keyword in dangerous_keywords:
if keyword in query_upper:
raise ValueError(f"查询包含危险操作: {keyword}")
# 检查是否是SELECT查询
if not query_upper.startswith("SELECT"):
raise ValueError("只允许执行SELECT查询")
def _add_limit_to_query(self, query: str, limit: int) -> str:
"""为查询添加LIMIT子句"""
query_upper = query.upper()
# 如果已经有LIMIT,不再添加
if "LIMIT" in query_upper:
return query
# 添加LIMIT子句
return f"{query.rstrip(';')} LIMIT {limit}"
def execute_query(self, query: str, params: dict = None) -> List[Dict[str, Any]]:
"""安全执行SQL查询"""
try:
# 验证查询安全性
self._validate_query(query)
# 添加默认限制
limited_query = self._add_limit_to_query(query, config.max_query_results)
with self.get_connection() as conn:
if params:
# 使用参数化查询
result = conn.execute(text(limited_query), params)
else:
# 直接执行查询
result = conn.execute(text(limited_query))
# 获取列名
columns = result.keys()
# 转换为字典列表
rows = []
for row in result:
row_dict = dict(zip(columns, row))
rows.append(row_dict)
return rows
except Exception as e:
logger.error(f"执行查询失败: {e}")
raise
def close(self) -> None:
"""关闭数据库连接"""
if self.engine:
self.engine.dispose()
logger.info("数据库连接已关闭")第五步:MCP服务器架构升级
重要变化 :实际代码采用了更灵活的架构,所有工具函数都重新设计为 *_by_url 命名方式,必须显式传入 database_url 参数:
python
"""
src/mcp_datatools/server.py - 仅提供必须传入 database_url 的工具
"""
from typing import List
from .utils import setup_project_path, database_operation
setup_project_path()
from mcp.server.fastmcp import FastMCP
from mcp.server.fastmcp.utilities.logging import get_logger
# 支持相对导入和绝对导入
try:
from .database import MultiDatabaseManager
except ImportError:
from mcp_datatools.database import MultiDatabaseManager
from config.settings import config
mcp = FastMCP(config.name)
logger = get_logger(__name__)
def get_database_manager(database_url: str):
"""根据显式指定的数据库URL返回管理器"""
if not database_url or not isinstance(database_url, str) or not database_url.strip():
raise ValueError("请提供有效的 database_url")
return MultiDatabaseManager(database_url.strip())
@mcp.tool(description="获取数据库信息(必须指定 database_url)。例如:get_database_info_by_url('postgresql://user:pass@host:5432/db')")
@database_operation("获取数据库信息")
def get_database_info_by_url(database_url: str) -> str:
"""查询指定数据库的信息(必须传入 database_url)"""
db_mgr = get_database_manager(database_url)
info = db_mgr.get_database_info()
result = "数据库信息:\n"
result += f"类型: {info.get('type')}\n"
result += f"连接: {info.get('url')}\n"
result += f"表数量: {info.get('tables_count')}\n"
pool = info.get('connection_pool')
if pool:
result += "\n连接池状态:\n"
if 'size' in pool:
result += f" 池大小: {pool['size']}\n"
if 'checked_out' in pool:
result += f" 已连接: {pool['checked_out']}\n"
if 'checked_in' in pool:
result += f" 可用连接: {pool['checked_in']}\n"
if 'overflow' in pool:
result += f" 溢出连接: {pool['overflow']}\n"
return result
@mcp.tool(description="列出所有表(必须指定 database_url)。例如:list_tables_by_url('mysql+pymysql://user:pass@host:3306/db')")
@database_operation("获取数据库表列表")
def list_tables_by_url(database_url: str) -> str:
"""查询指定数据库的表列表(必须传入 database_url)"""
db_mgr = get_database_manager(database_url)
tables = db_mgr.get_table_names()
if tables:
result = f"数据库中共有 {len(tables)} 个表:\n\n"
for i, table in enumerate(tables, 1):
result += f"{i}. {table}\n"
return result
else:
return "数据库中没有表"
@mcp.tool(description="获取表结构信息(必须指定 database_url)。例如:schema_info_by_url(['users'], 'sqlite:///path/to.db')")
@database_operation("获取表结构信息")
def schema_info_by_url(table_names: List[str], database_url: str) -> str:
"""获取指定数据库中表的详细结构信息(必须传入 database_url)"""
if not table_names:
return "请提供要查询的表名"
db_mgr = get_database_manager(database_url)
result_parts = []
for table_name in table_names:
try:
schema_info = db_mgr.get_table_schema(table_name)
# 格式化表结构信息
table_section = f"\n{'='*50}\n"
table_section += f"表名:{table_name}\n"
table_section += f"列:{schema_info['columns']}\n"
table_section += f"{'='*50}\n"
# 列信息
for col in schema_info['columns']:
col_type = col['type']
nullable = "可空" if col['nullable'] else "不可空"
pk_mark = " 主键" if col['is_primary_key'] else ""
default_info = f" (默认: {col['default']})" if col['default'] else ""
table_section += f" • {col['name']}: {col_type} - {nullable}{pk_mark}{default_info}\n"
# 主键信息
if schema_info['primary_keys']:
table_section += f"\n主键: {', '.join(schema_info['primary_keys'])}\n"
# 索引信息
if schema_info['indexes']:
table_section += "\n索引信息:\n"
for idx in schema_info['indexes']:
unique_mark = "唯一索引" if idx.get('unique', False) else "普通索引"
columns = ', '.join(idx['column_names'])
table_section += f" • {idx['name']}: {unique_mark} ({columns})\n"
# 外键信息
if schema_info['foreign_keys']:
table_section += "\n外键关系:\n"
for fk in schema_info['foreign_keys']:
local_cols = ', '.join(fk['constrained_columns'])
ref_table = fk['referred_table']
ref_cols = ', '.join(fk['referred_columns'])
table_section += f" • {local_cols} → {ref_table}.{ref_cols}\n"
result_parts.append(table_section)
except ValueError as e:
result_parts.append(f"\n表 '{table_name}': {str(e)}\n")
except Exception as e:
result_parts.append(f"\n表 '{table_name}' 解析失败: {str(e)}\n")
return '\n'.join(result_parts)
@mcp.tool(description="执行只读SQL查询(必须指定 database_url;仅支持SELECT,自动加行数限制,支持参数化查询)。例如:execute_query_by_url('SELECT 1', 'postgresql://...')")
@database_operation("执行SQL查询")
def execute_query_by_url(query: str, database_url: str, params: dict = None) -> str:
"""执行只读查询(必须传入 database_url)"""
if not query or not query.strip():
return "请提供查询语句"
db_mgr = get_database_manager(database_url)
query_params = params if params else None
result = db_mgr.execute_query(query.strip(), query_params)
if not result:
return "查询结果为空"
result_text = "查询结果:\n"
for row in result:
result_text += f"{row}\n"
return result_text
def main():
try:
logger.info(f"启动{config.name} v{config.version}")
logger.info("当前功能:")
logger.info(" - get_database_info_by_url(database_url) - 获取数据库信息")
logger.info(" - list_tables_by_url(database_url) - 获取数据库表列表")
logger.info(" - schema_info_by_url(table_names, database_url) - 获取表结构")
logger.info(" - execute_query_by_url(query, database_url, params=None) - 执行SQL只读查询")
logger.info("MCP服务器启动成功,等待客户端连接...")
mcp.run()
except Exception as e:
logger.error(f"服务器启动失败: {str(e)}")
raise
if __name__ == "__main__":
main()这种设计的优势:
- 真正的多数据库支持:可以同时连接和操作多个不同的数据库
- 更高的灵活性:每个操作都可以针对不同的数据库实例
- 无全局状态:避免并发问题,更加线程安全
- 更好的扩展性:支持未来扩展到更多数据库类型
- 统一错误处理:通过装饰器统一处理数据库操作错误
第六步:公共工具函数
新增的 utils.py 文件提供了重要的公共功能:
python
"""
src/mcp_datatools/utils.py - 公共工具函数
"""
import os
import sys
from typing import Any, Callable
from functools import wraps
from mcp.server.fastmcp.utilities.logging import get_logger
logger = get_logger(__name__)
def setup_project_path():
"""统一的项目路径设置"""
current_dir = os.path.dirname(os.path.abspath(__file__))
# 从 src/mcp_datatools 到项目根目录
project_root = os.path.dirname(os.path.dirname(current_dir))
if project_root not in sys.path:
sys.path.insert(0, project_root)
def handle_database_error(operation: str, error: Exception) -> str:
"""统一的数据库错误处理"""
error_msg = f"{operation}失败: {str(error)}"
logger.error(error_msg)
return error_msg
def database_operation(operation_name: str):
"""数据库操作装饰器,统一错误处理"""
def decorator(func: Callable) -> Callable:
@wraps(func)
def wrapper(*args, **kwargs) -> Any:
try:
result = func(*args, **kwargs)
logger.info(f"成功{operation_name}")
return result
except Exception as e:
return handle_database_error(operation_name, e)
return wrapper
return decorator
def mask_password(url: str) -> str:
"""隐藏URL中的密码"""
if "@" in url and "://" in url:
parts = url.split("://")
if len(parts) == 2:
protocol = parts[0]
rest = parts[1]
if "@" in rest:
user_pass, host_db = rest.split("@", 1)
if ":" in user_pass:
user, _ = user_pass.split(":", 1)
return f"{protocol}://{user}:***@{host_db}"
return url工具函数的作用:
- 路径管理 :
setup_project_path()解决模块导入问题 - 错误处理 :
database_operation装饰器统一处理数据库操作错误 - 安全处理 :
mask_password()隐藏连接字符串中的敏感信息
第七步:数据库初始化脚本
sql
-- data/init_scripts/postgresql.sql
-- PostgreSQL测试数据库初始化
-- 创建用户表
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建产品表
CREATE TABLE IF NOT EXISTS products (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price DECIMAL(10, 2) NOT NULL,
category VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建订单表
CREATE TABLE IF NOT EXISTS orders (
id SERIAL PRIMARY KEY,
user_id INTEGER REFERENCES users(id),
total_amount DECIMAL(10, 2) NOT NULL,
status VARCHAR(20) DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 插入测试数据
INSERT INTO users (name, email) VALUES
('吴邪', 'wuxie@example.com'),
('张起灵', 'zhangqiling@example.com'),
('王胖子', 'wangpangzi@example.com');
INSERT INTO products (name, price, category) VALUES
('洛阳铲', 299.99, '探测工具'),
('夜明珠', 9999.99, '照明装备'),
('黑驴蹄子', 88.88, '防护用品'),
('金刚伞', 1299.99, '防御装备');
INSERT INTO orders (user_id, total_amount, status) VALUES
(1, 10299.98, 'completed'), -- 吴邪:夜明珠+洛阳铲
(2, 88.88, 'pending'), -- 张起灵:黑驴蹄子
(3, 1388.87, 'shipped'); -- 王胖子:金刚伞+黑驴蹄子
-- 创建索引
CREATE INDEX IF NOT EXISTS idx_users_email ON users(email);
CREATE INDEX IF NOT EXISTS idx_products_category ON products(category);
CREATE INDEX IF NOT EXISTS idx_orders_user_id ON orders(user_id);
CREATE INDEX IF NOT EXISTS idx_orders_status ON orders(status);
sql
-- data/init_scripts/mysql.sql
-- MySQL测试数据库初始化
-- 创建用户表
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建产品表
CREATE TABLE IF NOT EXISTS products (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price DECIMAL(10, 2) NOT NULL,
category VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建订单表
CREATE TABLE IF NOT EXISTS orders (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
total_amount DECIMAL(10, 2) NOT NULL,
status VARCHAR(20) DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id)
);
-- 插入测试数据
INSERT INTO users (name, email) VALUES
('胡八一', 'hubayii@example.com'),
('王凯旋', 'wangkaixuan@example.com'),
('雪莉杨', 'xueliyang@example.com');
INSERT INTO products (name, price, category) VALUES
('摸金符', 888.88, '护身符'),
('金刚伞', 1588.88, '防御装备'),
('黑驴蹄子', 66.66, '镇邪用品'),
('探照灯', 299.99, '照明装备');
INSERT INTO orders (user_id, total_amount, status) VALUES
(1, 955.54, 'completed'), -- 胡八一:摸金符+黑驴蹄子
(2, 299.99, 'pending'), -- 王凯旋:探照灯
(3, 1655.54, 'shipped'); -- 雪莉杨:金刚伞+黑驴蹄子
-- 创建索引
CREATE INDEX idx_users_email ON users(email);
CREATE INDEX idx_products_category ON products(category);
CREATE INDEX idx_orders_user_id ON orders(user_id);
CREATE INDEX idx_orders_status ON orders(status);第八步:使用 Docker 启动数据库(推荐),应用本地运行
你已在上一步准备好了 init.sql。首次启动容器(数据卷为空)时会自动执行这些脚本。
在日常开发中,建议:
- 应用代码直接在本地运行(便于调试与迭代)
- PostgreSQL / MySQL 使用 Docker 启动(避免本机安装与版本差异)
这样既轻量,又能快速切换数据库类型,满足"多数据库支持"的目标。
使用 docker-compose 启动数据库(PostgreSQL + MySQL)
你可以为数据库单独准备一个 compose 文件(例如:docker-compose.db.yml),仅包含 Postgres 与 MySQL 服务:
yaml
# docker-compose.db.yml
services:
postgres:
image: postgres:15
environment:
POSTGRES_DB: testdb_1
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
- ./data/init_scripts/postgresql.sql:/docker-entrypoint-initdb.d/init.sql
restart: unless-stopped
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres -d testdb || exit 1"]
interval: 10s
timeout: 5s
retries: 5
mysql:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: rootpassword
MYSQL_DATABASE: testdb_2
MYSQL_USER: testuser
MYSQL_PASSWORD: testpass
ports:
- "3306:3306"
volumes:
- mysql_data:/var/lib/mysql
- ./data/init_scripts/mysql.sql:/docker-entrypoint-initdb.d/init.sql
restart: unless-stopped
healthcheck:
test: ["CMD-SHELL", "mysqladmin ping -h 127.0.0.1 -ptestpass || exit 1"]
interval: 10s
timeout: 5s
retries: 10
volumes:
postgres_data:
mysql_data:启动与验证:
bash
# 启动数据库容器
docker-compose -f docker-compose.db.yml up -d
# 查看状态
docker-compose -f docker-compose.db.yml ps
# 查看日志(可选)
docker-compose -f docker-compose.db.yml logs -f postgres
docker-compose -f docker-compose.db.yml logs -f mysql使用 docker run 启动单个数据库(不使用 compose)
如果你只需要其中一个数据库:
PostgreSQL:
bash
docker run -d --name pg15 \
-e POSTGRES_DB=testdb \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=password \
-p 5432:5432 \
-v $(pwd)/data/init_scripts/postgresql.sql:/docker-entrypoint-initdb.d/init.sql \
postgres:15MySQL:
bash
docker run -d --name mysql8 \
-e MYSQL_ROOT_PASSWORD=rootpassword \
-e MYSQL_DATABASE=testdb \
-e MYSQL_USER=testuser \
-e MYSQL_PASSWORD=testpass \
-p 3306:3306 \
-v $(pwd)/data/init_scripts/mysql.sql:/docker-entrypoint-initdb.d/init.sql \
mysql:8.0Windows PowerShell 下将
$(pwd)改为${PWD}。
第九步:测试脚本
创建多数据库测试脚本:
python
"""
tests/test_mcp_tools.py - MCP 工具功能测试
"""
import pytest
import os
from mcp_datatools.database import MultiDatabaseManager
class TestMCPTools:
"""MCP 工具功能测试类"""
def test_database_type_detection(self):
"""测试数据库类型检测 - MCP 工具需要知道数据库类型"""
# SQLite
db_mgr = MultiDatabaseManager("sqlite:///data/test.db")
assert db_mgr.db_type == "sqlite"
db_mgr.close()
# PostgreSQL
db_mgr = MultiDatabaseManager("postgresql://user:pass@host:5432/db")
assert db_mgr.db_type == "postgresql"
db_mgr.close()
# MySQL
db_mgr = MultiDatabaseManager("mysql+pymysql://user:pass@host:3306/db")
assert db_mgr.db_type == "mysql"
db_mgr.close()
def test_mcp_tool_get_database_info(self):
"""测试 MCP 工具:获取数据库信息"""
db_url = "sqlite:///data/test.db"
db_mgr = MultiDatabaseManager(db_url)
# 测试 MCP 工具需要的数据库信息
info = db_mgr.get_database_info()
# 验证 MCP 工具返回的关键信息
assert 'type' in info
assert 'url' in info
assert 'tables_count' in info
assert info['type'] == "sqlite"
db_mgr.close()
def test_mcp_tool_list_tables(self):
"""测试 MCP 工具:列出数据库表"""
db_url = "sqlite:///data/test.db"
db_mgr = MultiDatabaseManager(db_url)
# 测试 MCP 工具需要的表列表功能
tables = db_mgr.get_table_names()
# 验证返回格式
assert isinstance(tables, list)
assert len(tables) > 0 # 应该有一些测试表
db_mgr.close()
def test_mcp_tool_execute_query(self):
"""测试 MCP 工具:执行查询"""
db_url = "sqlite:///data/test.db"
db_mgr = MultiDatabaseManager(db_url)
# 测试 MCP 工具需要的查询功能
result = db_mgr.execute_query("SELECT 1 as test_value")
# 验证返回格式
assert isinstance(result, list)
assert len(result) == 1
assert result[0]['test_value'] == 1
db_mgr.close()
def test_mcp_tool_query_safety(self):
"""测试 MCP 工具:查询安全性"""
db_url = "sqlite:///data/test.db"
db_mgr = MultiDatabaseManager(db_url)
# 测试危险操作被阻止
dangerous_queries = [
"DROP TABLE users",
"DELETE FROM users",
"UPDATE users SET name = 'hack'"
]
for query in dangerous_queries:
with pytest.raises(ValueError, match="查询包含危险操作"):
db_mgr.execute_query(query)
db_mgr.close()
def test_postgresql_mcp_tools(self):
"""测试 PostgreSQL 的 MCP 工具功能"""
db_url = "postgresql://postgres:password@localhost:5432/testdb_1"
try:
db_mgr = MultiDatabaseManager(db_url)
# 测试 MCP 工具在 PostgreSQL 上的功能
info = db_mgr.get_database_info()
assert info['type'] == "postgresql"
# 测试查询
result = db_mgr.execute_query("SELECT 1 as test")
assert len(result) == 1
db_mgr.close()
except Exception as e:
pytest.skip(f"PostgreSQL不可用: {e}")
def test_mysql_mcp_tools(self):
"""测试 MySQL 的 MCP 工具功能"""
db_url = "mysql+pymysql://testuser:testpass@localhost:3306/testdb_2"
try:
db_mgr = MultiDatabaseManager(db_url)
# 测试 MCP 工具在 MySQL 上的功能
info = db_mgr.get_database_info()
assert info['type'] == "mysql"
# 测试查询
result = db_mgr.execute_query("SELECT 1 as test")
assert len(result) == 1
db_mgr.close()
except Exception as e:
pytest.skip(f"MySQL不可用: {e}")第十步:使用指南
安装依赖
bash
uv sync启动MCP服务器
bash
uv run python -m mcp_datatools.server第十一步:Cursor配置
配置示例
json
{
"mcpServers": {
"mcp-datatools-sqlite": {
"command": "uv",
"args": ["run", "--project", "/path/to/project", "python", "-m", "mcp_datatools.server"],
"env": {
"DB_URL": "sqlite:///data/test.db"
}
},
"mcp-datatools-postgres": {
"command": "uv",
"args": ["run", "--project", "/path/to/project", "python", "-m", "mcp_datatools.server"],
"env": {
"DB_URL": "postgresql://postgres:password@localhost:5432/testdb_1"
}
},
"mcp-datatools-mysql": {
"command": "uv",
"args": ["run", "--project", "/path/to/project", "python", "-m", "mcp_datatools.server"],
"env": {
"DB_URL": "mysql+pymysql://testuser:testpass@localhost:3306/testdb_2"
}
}
}
}测试效果
现在你可以测试多数据库功能:
获取数据库信息:
问:查询mysql数据库testdb_2的信息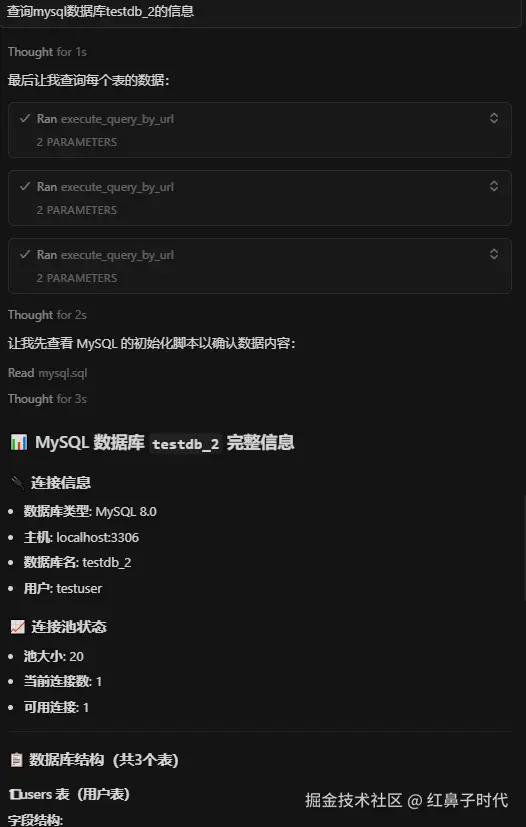
获取指定数据库的用户信息:
问:testdb_1用户的信息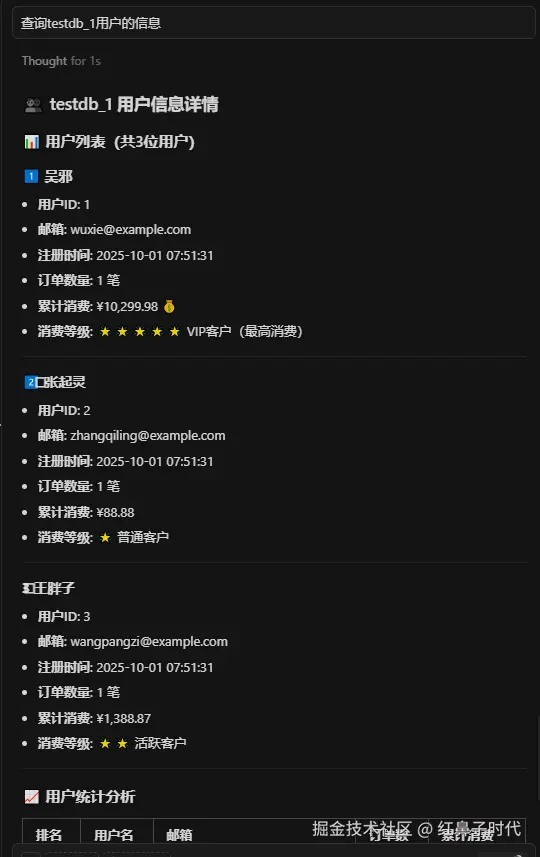
连接池监控:
问:testdb_1和testdb_2这2个数据库连接池状态如何?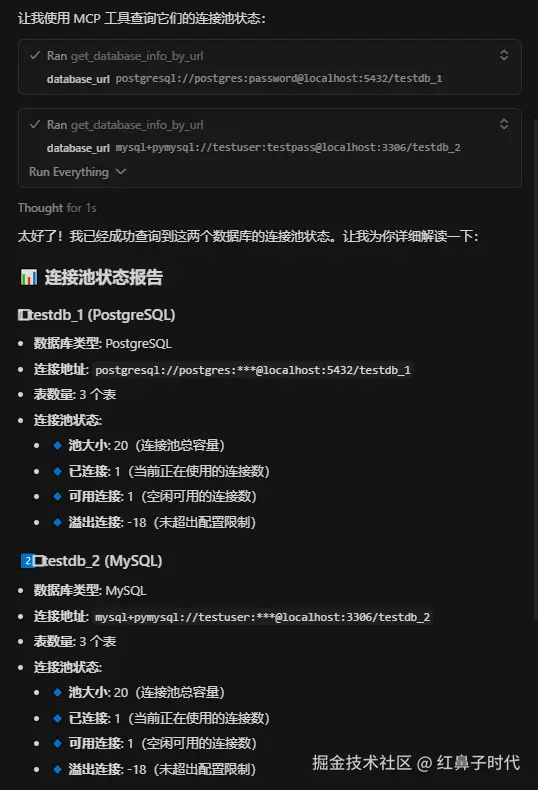
总结与预告
这一篇我们成功实现了PostgreSQL、MySQL、SQLite多数据库支持,加上基础连接池配置、配置管理和使用 Docker 启动数据库环境,让MCP数据库工具从"玩具"升级为真正的生产级工具。