一、引言
在大模型与检索增强生成(RAG)技术普及的当下,向量检索已从逐渐从小众能力跃升为通用需求。关系型数据库作为企业数据架构的核心,长期以来以结构化数据管理、ACID 事务、成熟的 SQL 生态为核心优势,但在非结构化数据(文本、图片、音频)的语义检索场景中存在天然短板。
MySQL 作为全球使用最广泛的关系型数据库,也顺应这一趋势完成了向量检索能力的迭代,MySQL 8.4.0 首次引入原生VECTOR类型和 HNSW 向量索引,将向量检索纳入标准功能体系;而对于存量的 8.0.x 低版本用户,也可通过 "字符串存储 + 自定义函数" 的兼容方案实现向量检索。今天我们将以 MySQL 为核心,由浅入深解析关系型数据库融合向量检索的技术逻辑、版本特性差异、兼容架构设计,以及可落地的实战案例,完整呈现这一数据库领域的重要演进方向。

二、MySQL的向量检索能力
1. 传统 MySQL 的能力缺口
MySQL 作为经典的关系型数据库,擅长处理具有明确 schema 的结构化数据(数值、字符串、日期等),支持精准的 SQL 条件查询、关联查询和事务管理。但在 AI 时代,企业 80% 以上的数据为非结构化数据(用户评论、产品文档、客服对话等),这类数据的核心价值在于语义内涵而非显性特征,传统 MySQL 的处理痛点极为突出:
- 非结构化数据只能以TEXT/BLOB类型存储,无法理解其语义;
- 检索依赖关键词匹配(LIKE/ 全文索引),无法实现语义相似性检索;
- 无法与大模型联动,支撑 RAG、智能问答、内容推荐等新兴业务;
- 需与独立向量数据库(如 Milvus、Chroma)联动,增加架构复杂度和运维成本。
2. 向量检索的补位价值
向量检索的核心是将非结构化数据通过 Embedding 模型转化为高维向量,利用 "向量空间距离越近、语义越相似" 的特性实现语义匹配。将向量检索能力融入 MySQL,可带来三大核心价值:
- 架构简化:无需额外部署独立向量数据库,在现有 MySQL 架构中统一管理结构化数据 + 向量数据,降低运维成本;
- 能力互补:支持 "SQL 条件过滤 + 向量相似性检索" 的复合查询,例如 "查询 2024 年发布的、与'MySQL 向量检索'语义相似的技术文档";
- 生态兼容:依托 MySQL 成熟的事务机制、备份策略和生态工具(如 binlog、主从复制),保障向量数据的安全性和稳定性。
3. MySQL 向量检索的技术演进
MySQL 的向量检索能力演进分为两个阶段,适配不同版本用户的需求:
3.1 MySQL 8.0.x(全系列),不包含原生的向量能力,需要兼容实现:
- 实现方案:字符串存储向量 + 自定义函数计算相似度
- 优势:无需升级、适配存量系统
- 局限性:无原生索引,仅适合中小规模数据
3.2 MySQL 8.4.0+,支持内置的向量能力
- 实现方式:内置VECTOR类型、HNSW 向量索引、VECTOR_DISTANCE函数
- 优势:性能优、检索效率高、原生集成
- 局限性:需升级数据库,存量系统改造成本高
三、MySQL 向量检索原生特性
MySQL 8.4.0 是向量检索能力的里程碑版本,首次将向量功能纳入核心标准,以下是其核心特性解析:
1. 原生向量数据类型:VECTOR
- 支持自定义向量维度(最大支持 32768 维),适配主流 Embedding 模型(如all-MiniLM-L6-v2的 384 维、BERT 的 768 维);
- 存储优化:针对高维向量做了内存对齐和压缩,存储效率优于普通数组类型;
语法示例:重点关注VECTOR类型字段声明
python
-- 创建含768维向量字段的表
CREATE TABLE tech_docs (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content TEXT NOT NULL,
publish_date DATE NOT NULL,
tag VARCHAR(50) NOT NULL,
embedding VECTOR(768) NOT NULL -- 768维向量字段
);2. 原生向量索引:HNSW
MySQL 8.4.0 引入分层导航小世界(HNSW)索引,这是当前业界性能最优的近似最近邻(ANN)算法之一:
- 支持余弦距离(COSINE)、欧氏距离(L2)、曼哈顿距离(MANHATTAN)三种核心距离计算方式;
- 可配置核心参数(m邻接节点数、ef_construction构建时搜索范围),平衡检索精度与速度;
语法示例:
python
-- 为向量字段创建HNSW索引(余弦距离)
CREATE INDEX idx_tech_docs_embedding ON tech_docs
USING HNSW (embedding) WITH (
metric_type = 'COSINE', -- 距离计算方式
m = 16, -- 每个节点的邻接数
ef_construction = 64 -- 构建索引时的探索范围
);3. 原生相似度计算:VECTOR_DISTANCE函数
- 用于计算两个向量的距离值,值越小表示语义越相似;
- 余弦相似度 = 1 - VECTOR_DISTANCE(向量1, 向量2, 'COSINE');
语法示例:
python
-- 计算查询向量与文档向量的余弦相似度
SELECT
title,
1 - VECTOR_DISTANCE(embedding, '[0.123,0.456,...]', 'COSINE') AS similarity
FROM tech_docs
ORDER BY similarity DESC;四、MySQL 向量检索兼容实现
对于无法升级到 8.4.0 的存量 MySQL 8.0.x 用户,需通过 "兼容架构" 实现向量检索,以下案例适配所有 MySQL 8.0.x 版本,包含数据库初始化、数据入库、复合查询、可视化全流程,可直接落地。
1. 兼容性说明
在不支持原生特性的情况下,我们要做针对性的兼容性处理:
1.1 兼容架构核心逻辑
第一层:向量存储层
- 放弃原生VECTOR类型,改用TEXT类型存储向量,格式为 "逗号分隔的浮点数字符串"(如0.123,0.456,...,0.789);
- 向量维度选择 384 维(all-MiniLM-L6-v2模型),平衡语义精度与计算成本;
- 新增向量归一化处理:入库前将向量归一化(模长 = 1),简化后续相似度计算。
第二层:相似度计算层
- 创建自定义 MySQL 函数calc_cosine_similarity,手动实现余弦相似度计算:
- 余弦相似度 = 向量点积 / (向量1模长 × 向量2模长)
- 归一化后向量的模长 = 1,相似度可简化为 "向量点积",大幅提升计算效率。
第三层:检索层
- 放弃原生向量索引,采用 "暴力检索":先通过 SQL 过滤结构化条件(如发布时间、标签),再对过滤后的数据集计算向量相似度;
- 适合中小规模数据(<1 万条),大规模数据建议升级 MySQL 或引入分布式检索引擎。
1.2 兼容架构关键组件
- 向量转换函数:处理向量数组 ↔ 字符串相互转换,通过 Python 函数embedding_to_str/str_to_embedding实现
- 自定义相似度函数:计算余弦相似度,新增MySQL 函数calc_cosine_similarity
- 结构化索引:加速条件过滤,对publish_date/tag创建普通索引
- 复合查询逻辑:过滤优先/检索优先,通过SQL 条件 + 相似度排序
1.3 兼容架构核心流程

2. 核心代码说明
2.1 数据库配置与初始化
python
import pymysql
import numpy as np
import matplotlib.pyplot as plt
from sentence_transformers import SentenceTransformer
from datetime import date
from typing import List, Tuple
# ===================== 1. 数据库配置与连接 =====================
DB_CONFIG = {
"host": "localhost",
"user": "root",
"password": "**********",
"database": "数据库名称",
"charset": "utf8mb4"
}
# 初始化Embedding模型(生成384维向量,降低计算成本)
model = SentenceTransformer('D:/modelscope/hub/models/sentence-transformers/all-MiniLM-L6-v2')
VECTOR_DIM = 384 # 向量维度
# ===================== 2. 工具函数 =====================
def get_mysql_connection():
"""创建并返回MySQL连接"""
conn = pymysql.connect(**DB_CONFIG)
conn.autocommit(False)
return conn
def init_database():
"""初始化数据库表结构(兼容低版本MySQL)"""
conn = get_mysql_connection()
cursor = conn.cursor()
# 1. 创建表:向量存储为字符串(逗号分隔的float值)
cursor.execute("""
DROP TABLE IF EXISTS tech_docs;
""")
cursor.execute("""
CREATE TABLE tech_docs (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content TEXT NOT NULL,
publish_date DATE NOT NULL,
tag VARCHAR(50) NOT NULL,
embedding TEXT NOT NULL -- 向量存储为字符串:"x1,x2,...x384"
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
""")
# 2. 创建结构化字段索引(向量无原生索引,用暴力检索)
cursor.execute("""
CREATE INDEX idx_tech_docs_publish_date ON tech_docs(publish_date);
""")
cursor.execute("""
CREATE INDEX idx_tech_docs_tag ON tech_docs(tag);
""")
# 3. 创建自定义余弦相似度计算函数(核心兼容逻辑)
cursor.execute("""
DROP FUNCTION IF EXISTS calc_cosine_similarity;
""")
cursor.execute("""
CREATE FUNCTION calc_cosine_similarity(vec1 TEXT, vec2 TEXT)
RETURNS FLOAT
DETERMINISTIC
BEGIN
DECLARE dot_product FLOAT DEFAULT 0.0;
DECLARE norm1 FLOAT DEFAULT 0.0;
DECLARE norm2 FLOAT DEFAULT 0.0;
DECLARE i INT DEFAULT 1;
DECLARE v1 FLOAT;
DECLARE v2 FLOAT;
-- 拆分向量为数组并计算点积、模长
WHILE i <= %d DO
SET v1 = CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(vec1, ',', i), ',', -1) AS FLOAT);
SET v2 = CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(vec2, ',', i), ',', -1) AS FLOAT);
SET dot_product = dot_product + (v1 * v2);
SET norm1 = norm1 + (v1 * v1);
SET norm2 = norm2 + (v2 * v2);
SET i = i + 1;
END WHILE;
-- 计算余弦相似度(避免除以0)
IF norm1 = 0 OR norm2 = 0 THEN
RETURN 0.0;
ELSE
RETURN dot_product / (SQRT(norm1) * SQRT(norm2));
END IF;
END;
""" % VECTOR_DIM)
conn.commit()
cursor.close()
conn.close()
print("数据库表、索引、自定义函数初始化完成!")2.2 数据入库与向量处理
python
def embedding_to_str(embedding: List[float]) -> str:
"""将向量数组转为逗号分隔的字符串"""
return ','.join(map(str, embedding))
def str_to_embedding(embedding_str: str) -> np.ndarray:
"""将字符串转回向量数组"""
return np.array([float(x) for x in embedding_str.split(',')])
def insert_docs(docs: List[dict]):
"""插入文档数据(生成向量并入库)"""
conn = get_mysql_connection()
cursor = conn.cursor()
for doc in docs:
# 生成384维向量并转为字符串
embedding = model.encode(doc["content"], normalize_embeddings=True).tolist() # 归一化提升相似度计算精度
embedding_str = embedding_to_str(embedding)
# 插入数据
cursor.execute("""
INSERT INTO tech_docs (title, content, publish_date, tag, embedding)
VALUES (%s, %s, %s, %s, %s)
""", (doc["title"], doc["content"], doc["publish_date"], doc["tag"], embedding_str))
conn.commit()
cursor.close()
conn.close()
print(f"成功插入{len(docs)}条文档数据!")2.3 复合查询实现
python
def hybrid_query_filter_first(query_text: str, publish_date_after: date, top_k: int = 2) -> List[Tuple]:
"""过滤优先:先按发布时间过滤,再向量检索"""
# 生成查询向量并转为字符串
query_embedding = model.encode(query_text, normalize_embeddings=True).tolist()
query_embedding_str = embedding_to_str(query_embedding)
conn = get_mysql_connection()
cursor = conn.cursor()
# 使用自定义函数计算余弦相似度
cursor.execute("""
SELECT
title, content, publish_date, tag,
calc_cosine_similarity(embedding, %s) AS similarity,
1 - calc_cosine_similarity(embedding, %s) AS distance
FROM tech_docs
WHERE publish_date >= %s
ORDER BY similarity DESC -- 相似度越高越靠前
LIMIT %s
""", (query_embedding_str, query_embedding_str, publish_date_after, top_k))
results = cursor.fetchall()
cursor.close()
conn.close()
return results
def hybrid_query_search_first(query_text: str, target_tag: str, top_k: int = 3) -> List[Tuple]:
"""检索优先:先向量检索Top-K,再过滤标签"""
# 生成查询向量并转为字符串
query_embedding = model.encode(query_text, normalize_embeddings=True).tolist()
query_embedding_str = embedding_to_str(query_embedding)
conn = get_mysql_connection()
cursor = conn.cursor()
# 先暴力检索Top-K(按相似度排序)
cursor.execute("""
SELECT
title, content, publish_date, tag,
calc_cosine_similarity(embedding, %s) AS similarity,
1 - calc_cosine_similarity(embedding, %s) AS distance
FROM tech_docs
ORDER BY similarity DESC
LIMIT %s
""", (query_embedding_str, query_embedding_str, top_k))
raw_results = cursor.fetchall()
cursor.close()
conn.close()
# 过滤标签
filtered_results = [r for r in raw_results if r[3] == target_tag]
return filtered_results2.4 结果可视化与输出
python
def plot_similarity(results: List[Tuple], title: str):
"""绘制相似度分布柱状图(图片输出)"""
if not results:
print("无数据可绘制图表!")
return
# 提取数据
doc_titles = [r[0][:10] + "..." for r in results] # 标题截断
similarities = [round(r[4], 4) for r in results] # 相似度
distances = [round(r[5], 4) for r in results] # 距离
# 设置中文字体
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 创建子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 子图1:余弦相似度
ax1.bar(doc_titles, similarities, color="#34A853", alpha=0.8)
ax1.set_title(f"{title} - 余弦相似度")
ax1.set_xlabel("文档标题")
ax1.set_ylabel("相似度(越大越相似)")
ax1.grid(axis="y", linestyle="--", alpha=0.7)
for i, v in enumerate(similarities):
ax1.text(i, v + 0.01, f"{v}", ha="center")
# 子图2:余弦距离
ax2.bar(doc_titles, distances, color="#4285F4", alpha=0.8)
ax2.set_title(f"{title} - 余弦距离")
ax2.set_xlabel("文档标题")
ax2.set_ylabel("距离值(越小越相似)")
ax2.grid(axis="y", linestyle="--", alpha=0.7)
for i, v in enumerate(distances):
ax2.text(i, v + 0.01, f"{v}", ha="center")
plt.tight_layout()
plt.savefig(f"{title.replace(' ', '_')}.png", dpi=300, bbox_inches="tight")
plt.show()
print(f"相似度图表已保存为:{title.replace(' ', '_')}.png")
def print_formatted_results(results: List[Tuple], scene_name: str):
"""格式化输出检索结果"""
print(f"\n===== {scene_name} 查询结果 =====")
if not results:
print("无符合条件的结果!")
return
for i, res in enumerate(results):
title, content, publish_date, tag, similarity, distance = res
print(f"\n【结果{i+1}】")
print(f"标题:{title}")
print(f"标签:{tag}")
print(f"发布时间:{publish_date}")
print(f"余弦相似度:{similarity:.4f}(越大越相似)")
print(f"余弦距离:{distance:.4f}(越小越相似)")
print(f"内容:{content[:100]}...")2.5 主流程执行
python
# ===================== 3. 主流程执行 =====================
if __name__ == "__main__":
# 步骤1:初始化数据库
init_database()
# 步骤2:准备测试数据
test_docs = [
{
"title": "RAG技术核心原理与实践",
"content": "RAG技术通过检索外部知识增强大模型生成能力,解决幻觉问题,是当前大模型落地的核心技术之一",
"publish_date": date(2024, 5, 10),
"tag": "RAG"
},
{
"title": "MySQL向量检索兼容方案",
"content": "低版本MySQL可通过字符串存储向量,自定义函数计算余弦相似度,实现基础的向量检索能力",
"publish_date": date(2024, 6, 15),
"tag": "向量数据库"
},
{
"title": "PostgreSQL pgvector插件实战",
"content": "pgvector为PostgreSQL提供向量存储和检索能力,支持余弦、欧氏等多种距离计算方式,适配RAG场景",
"publish_date": date(2024, 7, 20),
"tag": "向量数据库"
},
{
"title": "大模型微调技术LoRA实战",
"content": "LoRA通过低秩适配实现高效微调,无需训练整个模型参数,大幅降低大模型微调的硬件成本",
"publish_date": date(2023, 12, 5),
"tag": "大模型"
}
]
# 步骤3:插入测试数据
insert_docs(test_docs)
# 步骤4:场景A - 过滤优先查询
query_a = "MySQL向量检索"
publish_date_a = date(2024, 1, 1)
results_a = hybrid_query_filter_first(query_a, publish_date_a, top_k=2)
print_formatted_results(results_a, "场景A(过滤优先)")
plot_similarity(results_a, "场景A - MySQL向量检索文档相似度分布")
# 步骤5:场景B - 检索优先查询
query_b = "大模型应用"
target_tag_b = "RAG"
results_b = hybrid_query_search_first(query_b, target_tag_b, top_k=3)
print_formatted_results(results_b, "场景B(检索优先)")
plot_similarity(results_b, "场景B - 大模型应用-RAG文档相似度分布")输出结果:
数据库表、索引、自定义函数初始化完成!
成功插入4条文档数据!
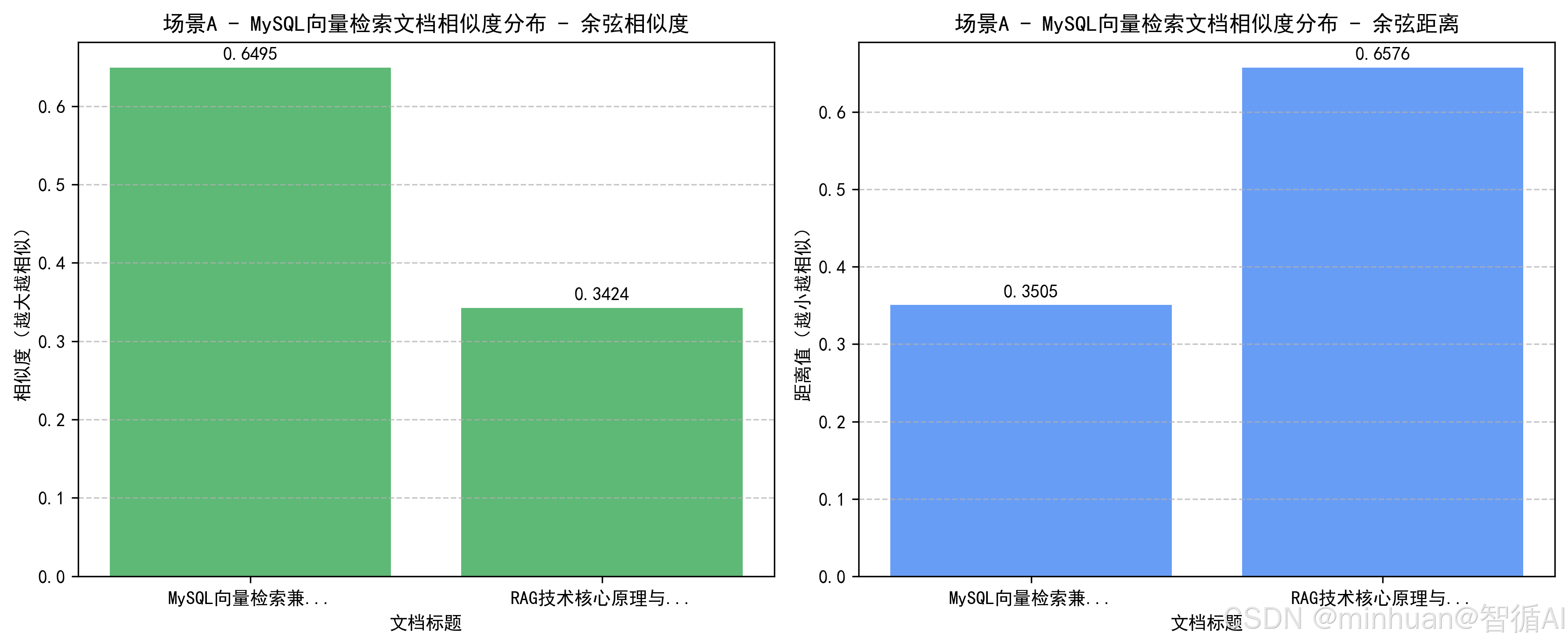
===== 场景A(过滤优先) 查询结果 =====
【结果1】
标题:MySQL向量检索兼容方案
标签:向量数据库
发布时间:2024-06-15
余弦相似度:0.6495(越大越相似)
余弦距离:0.3505(越小越相似)
内容:低版本MySQL可通过字符串存储向量,自定义函数计算余弦相似度,实现基础的向量检索能力...
【结果2】
标题:RAG技术核心原理与实践
标签:RAG
发布时间:2024-05-10
余弦相似度:0.3424(越大越相似)
余弦距离:0.6576(越小越相似)
内容:RAG技术通过检索外部知识增强大模型生成能力,解决幻觉问题,是当前大模型落地的核心技术之一...
相似度图表已保存为:场景A_-_MySQL向量检索文档相似度分布.png
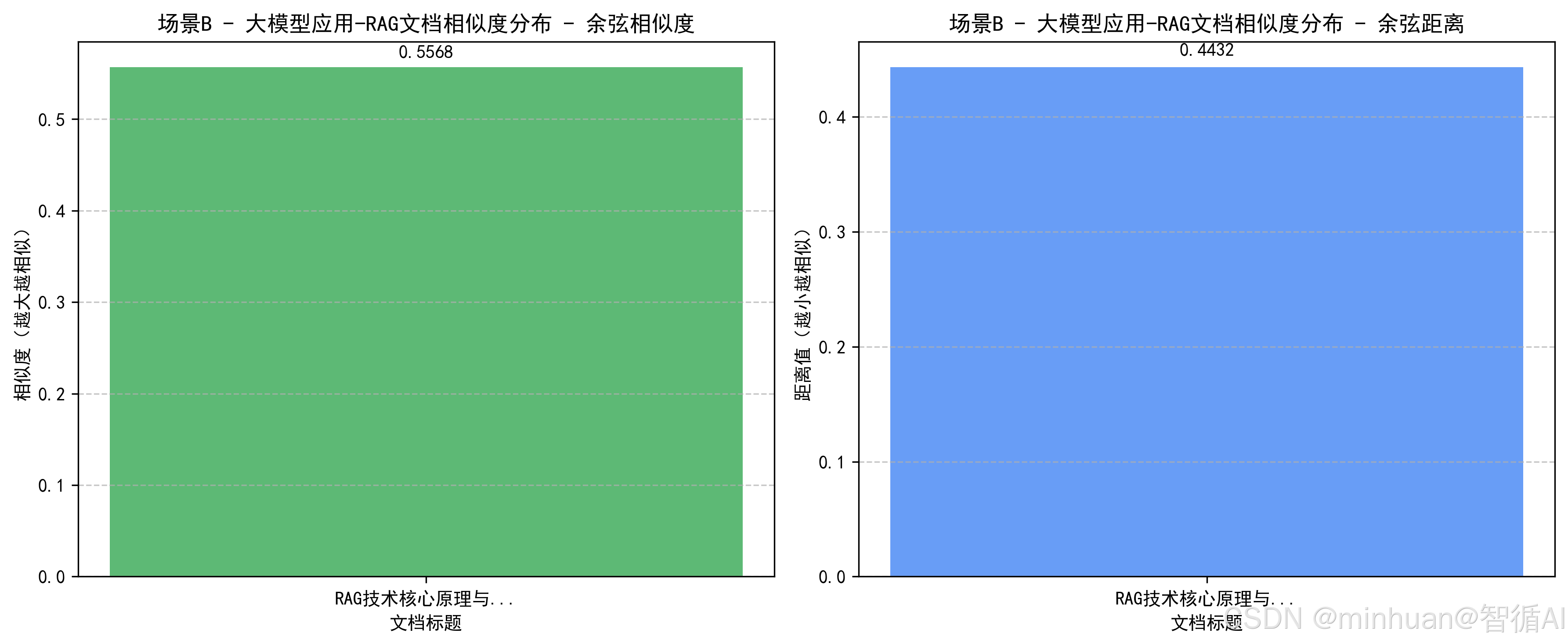
===== 场景B(检索优先) 查询结果 =====
【结果1】
标题:RAG技术核心原理与实践
标签:RAG
发布时间:2024-05-10
余弦相似度:0.5568(越大越相似)
余弦距离:0.4432(越小越相似)
内容:RAG技术通过检索外部知识增强大模型生成能力,解决幻觉问题,是当前大模型落地的核心技术之一...
相似度图表已保存为:场景B_-_大模型应用-RAG文档相似度分布.png
数据入库参考:

五、总结
MySQL 向量检索能力的融入,标志着关系型数据库从结构化数据管理向结构化 + 非结构化数据统一管理的转型。对于我们开发版本兼容选择来说:
- 若使用 MySQL 8.4.0+,优先采用原生VECTOR类型和 HNSW 索引,享受最优性能;
- 若使用 8.0.x 低版本,可通过 "字符串存储 + 自定义函数" 的兼容架构,快速落地向量检索能力;
无论哪种方案,都能在现有 MySQL 架构中实现 "SQL 条件过滤 + 向量语义检索" 的复合能力,无需重构数据架构,大幅降低 AI 应用的落地成本。向量检索终将成为 MySQL 的标准功能,使得我们在不改变现有数据架构的前提下,快速拥抱大模型和语义检索技术,释放数据的深层价值。