我们前面pytorch已经实现最简版本resnet
今天我们用c++再写一个更简单的resnet(不用pytorch,也不用cudnn),我们只实现残差虚线部分!
我们在成功的vgg上,添加这个只跨越一次的残差网络,而且与写论文的那个也不同,如下对比:
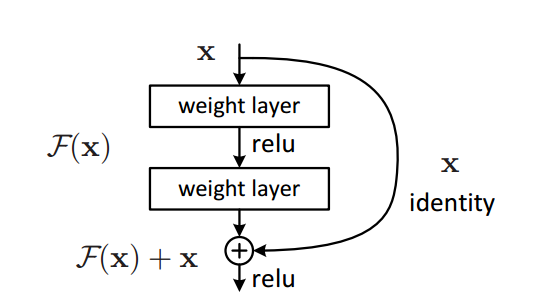
而我的lenet改过来的resnet是:
//初始化各层,resnet最简单版本
init_layer(&input_layer, 0, 4, 0, 0, 32, 32, false);
init_layer(&c1_convolution_layer,4, 12, 3, 3, 32, 32, false);
init_layer(&c11_convolution_layer, 12, 12, 3, 3, 32, 32, false);
init_layer(&s2_pooling_layer, 1, 12, 1, 1, 16, 16, true);
init_layer(&c3_convolution_layer, 12, 16, 3, 3, 16, 16, false);
init_layer(&c31_convolution_layer, 16, 16, 3, 3, 16, 16, false);
init_layer(&s4_pooling_layer, 1, 16, 1, 1, 8, 8, true);
init_layer(&c5_convolution_layer, 16, 120, 8, 8, 1, 1, false);
init_layer(&output_layer, 120, 10, 1, 1, 1, 1, false);
我们在标红的3层间实现残差:画出来如下:
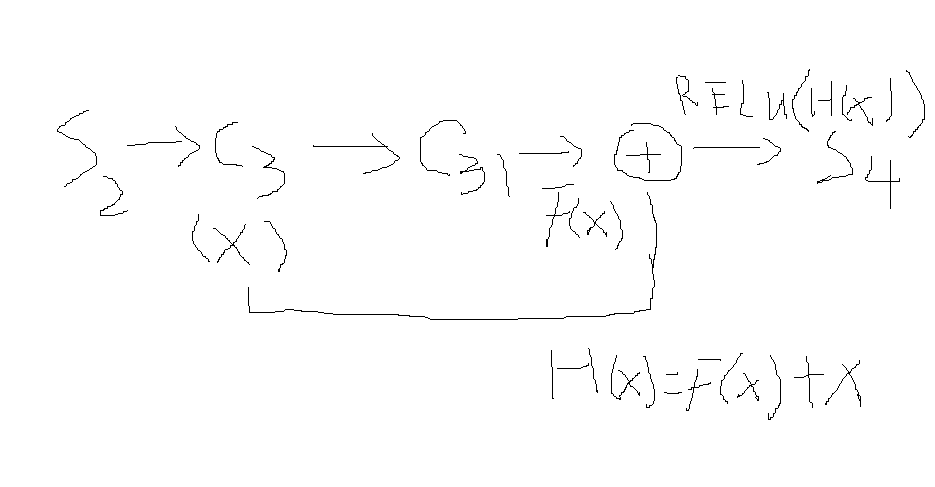
我们这个如果不画图,看上去像lenet,更像vgg,其实我们就是在前面最好的cifar10训练实现71分的版本上继续前进!
其实算不上前进,是倒退了,但实现了resnet,这次resnet最简单的复盘,是上了60分,以前怎么也过不了60分,实线resnet,虚线+实线resnet都不行!
其实从得分看,没必要加resnet,但从数学原理到编程实现,还是有记录下来的价值!
毕竟,网上,你是抄不到的,因为就没有,搜不到!哈哈!
网上的数学推导一大堆,我就不推导了!先看看程序日志:
14:22 2025/11/29
继续干,vgg最好版本产生lr=0.00005,test=71.01,lr=0.00001,test=71.03
11:33 2025/11/30
残差虚线版本添加成功!成绩上了60分,以前很难突破!
我们的vgg版本已经写过博客了,里边有源代码,这里我们只讲添加resnet成功的源代码:
首先,我们添加了:
public://虚线resnet
Layer c31_备用_layer;
并初始化,为什么添加这个备用层,一回就明白了!
c31_备用_layer.map_count = 16;
c31_备用_layer.map_height = 16;
c31_备用_layer.map_width = 16;
c31_备用_layer.map = (Map*)malloc(16 * sizeof(Map));
int single_map_size = 16 * 16 * sizeof(double);
for (int i = 0; i <16; i++){
c31_备用_layer.mapi.error = (double*)malloc(single_map_size);
memset( c31_备用_layer.mapi.error, 0, single_map_size);
}
//添加虚线部分resnet
好,前向传播中,也就是forward函数中,我们只有一个加的动作:
convolution_forward_propagation(&input_layer, &c1_convolution_layer, NULL);
convolution_forward_propagation(&c1_convolution_layer, &c11_convolution_layer, NULL);
max_pooling_forward_propagation(&c11_convolution_layer, &s2_pooling_layer);
convolution_forward_propagation(&s2_pooling_layer, &c3_convolution_layer, NULL);
convolution_forward_propagation(&c3_convolution_layer, &c31_convolution_layer, NULL);
max_pooling_forward_propagationresnet(&c31_convolution_layer, &s4_pooling_layer);
convolution_forward_propagation(&s4_pooling_layer, &c5_convolution_layer);
fully_connection_forward_propagation(&c5_convolution_layer, &output_layer);
上面这个标红的函数,就完成了加的动作,你可以对照上面画的图理解:
void Ccifar10交叉熵lenet5mfcDlg::max_pooling_forward_propagationresnet(Layer* pre_layer, Layer* cur_layer) //checked 2.0
{
// log_exec("max_pooling_forward_propagation");
int map_width = cur_layer->map_width;
int map_height = cur_layer->map_height;
int pre_map_width = pre_layer->map_width;
for (int k = 0; k < cur_layer->map_count; k++)
{
for (int i = 0; i < map_height; i++)
{
for (int j = 0; j < map_width; j++)//resnet第一步,应该是s2,不是c3,但s2是12*16*16,不是24*16*16,so,问题就来了202507230639,还不好解决!不好解决!暂时没好办法!
{
double max_value = pre_layer->mapk.data2 \* i \* pre_map_width + 2\*j+c3_convolution_layer.mapk.data2 \* i \* pre_map_width + 2\*j;//返乡时也要一致
for (int n = 2 * i; n < 2 * (i + 1); n++)
{
for (int m = 2 * j; m < 2 * (j + 1); m++)
{
max_value = MAX(max_value, pre_layer->mapk.datan \* pre_map_width + m+c3_convolution_layer.mapk.datan \* pre_map_width + m);
}
}
cur_layer->mapk.datai \* map_width + j = activation_function::tan_h(max_value);//这里有一个relu,返乡时,恰好就是resnet中的H(x)
}
}
}
}
上面标红的,就是实现了:h(x)=f(x)+x,在c31-》s4执行forward时!
前向网络forward函数改动就这么多,下面我们看反向backward函数:
void Ccifar10交叉熵lenet5mfcDlg::backward_propagation(double* label) //checked
{
for (int i = 0; i < output_layer.map_count; i++)
{
output_layer.mapi.error0 =softmi * activation_function::d_tan_h(output_layer.mapi.data0);
}
fully_connection_backward_propagation(&output_layer, &c5_convolution_layer);//10-120
convolution_backward_propagation(&c5_convolution_layer, &s4_pooling_layer, NULL);//120->24*8*8
max_pooling_backward_propagationresnet(&s4_pooling_layer, &c31_convolution_layer);//16*8*8-》16*16*16
convolution_backward_propagation(&c31_convolution_layer, &c3_convolution_layer);//24*16*16->24*16*16
convolution_backward_propagationresnet虚线(&c3_convolution_layer, &s2_pooling_layer);//24*16*16->12*16*16
max_pooling_backward_propagation(&s2_pooling_layer, &c11_convolution_layer);//12*16*16-》12*32*32
convolution_backward_propagation(&c11_convolution_layer, &c1_convolution_layer);//12*32*32->12*32*32
convolution_backward_propagation(&c1_convolution_layer, &input_layer);//12*32*32->4*32*32
}
反向传播时,上面两个标红的函数,需要调整,来应付前面forward中的"+"号!
这里就要用上我们前面准备的:c31_备用_layer
void Ccifar10交叉熵lenet5mfcDlg::max_pooling_backward_propagationresnet(Layer* cur_layer, Layer* pre_layer) //checked
{
// log_exec("max_pooling_backward_propagation");
int cur_layer_mapwidth = cur_layer->map_width;
int cur_layer_mapheight = cur_layer->map_height;
int pre_layer_mapwidth = pre_layer->map_width;
for (int k = 0; k < cur_layer->map_count; k++)
{
for (int i = 0; i < cur_layer_mapheight; i++)
{
for (int j = 0; j < cur_layer_mapwidth; j++)
{
int index_row = 2 * i;
int index_col = 2 * j;
double max_value = pre_layer->mapk.dataindex_row \* pre_layer_mapwidth + index_col;
for (int n = 2 * i; n < 2 * (i + 1); n++)
{
for (int m = 2 * j; m < 2 * (j + 1); m++)
{
if (pre_layer->mapk.datan \* pre_layer_mapwidth + m > max_value)
{
index_row = n;
index_col = m;
max_value = pre_layer->mapk.datan \* pre_layer_mapwidth + m;
}
else
{
pre_layer->mapk.errorn \* pre_layer_mapwidth + m = 0.0;
}
}
}
//c31_备用_layer.mapi.error
pre_layer->mapk.errorindex_row \* pre_layer_mapwidth + index_col = cur_layer->mapk.errori \* cur_layer_mapwidth + j* activation_function::d_tan_h(max_value);
c31_备用_layer.mapk.errorindex_row \* pre_layer_mapwidth + index_col = cur_layer->mapk.errori \* cur_layer_mapwidth + j;//8*8*16->16*16*16
}
}
}
}
c31_备用_layer的作用就是记录**cur_layer->mapk.errori \* cur_layer_mapwidth + j**这样一个值!他要跳过c31,去前面convolution_backward_propagationresnet虚线(&c3_convolution_layer, &s2_pooling_layer)中捣鼓名堂!
也就是跳过f(x)传到x那边去!我们看第二个标红函数,看他跳过去是怎么作用的!
void Ccifar10交叉熵lenet5mfcDlg:: convolution_backward_propagationresnet虚线(Layer* cur_layer, Layer* pre_layer) //checked checked 2.0 fixed
{
//c3->s2,16*16*16->12*16*16
double** buffer2= new double*12;
for(int i=0;i<12;i++)
buffer2i = new double16\*16;
int connected_index = 0;
int pre_layer_mapsize = pre_layer->map_height * pre_layer->map_width;//16
//更新S4 error
for (int i = 0; i < pre_layer->map_count; i++)
{
memset(pre_layer->map_common, 0, sizeof(double) * pre_layer_mapsize);
for (int j = 0; j < cur_layer->map_count; j++)
{
connected_index = i * cur_layer->map_count + j;
for (int n = 1; n < cur_layer->map_height-1; n++)
{
for (int m = 1; m < cur_layer->map_width-1; m++)
{
int valued_index =( n) * cur_layer->map_width + m;//取中心14*14,c31
double error = cur_layer->mapj.errorvalued_index;
for (int kernel_y = 0; kernel_y < cur_layer->kernel_height; kernel_y++)//3
{
for (int kernel_x = 0; kernel_x < cur_layer->kernel_width; kernel_x++)//3
{
int index_convoltion_map = (n-1 + kernel_y) * pre_layer->map_width + m-1 + kernel_x;//16
int index_kernel = connected_index;
int index_kernel_weight = kernel_y * cur_layer->kernel_width + kernel_x;
pre_layer->map_commonindex_convoltion_map += error * cur_layer->kernelindex_kernel.weightindex_kernel_weight;
}
}
}
}
}
for (int k = 0; k < pre_layer_mapsize; k++)//c31cur中心14*14到达c3,16*16(pre)
{//c31
pre_layer->mapi.errork = pre_layer->map_commonk * activation_function::d_tan_h(pre_layer->mapi.datak);
buffer2ik=activation_function::d_tan_h(pre_layer->mapi.datak);
}
}
//更新 S_x ->> C_x kernel 的 delta_weight
for (int i = 0; i < pre_layer->map_count; i++)//12*16*16
{
for (int j = 0; j < cur_layer->map_count; j++)//24*16*16
{
connected_index = i * cur_layer->map_count + j;
convolution_calcuVggBPplus1(
pre_layer->mapi.data, pre_layer->map_width, pre_layer->map_height,//16 16*12
cur_layer->mapj.error, cur_layer->map_width, cur_layer->map_height,//16 16*16
cur_layer->kernelconnected_index.delta_weight, cur_layer->kernel_width, cur_layer->kernel_height,//3 3
c31_备用_layer.mapj.error,//16 16*16
buffer2i//16*16 *12
);
}
}
//更新C_x 的delta_bias
int cur_layer_mapsize = cur_layer->map_height * cur_layer->map_width;
for (int i = 0; i < cur_layer->map_count; i++)
{
double delta_sum = 0.0;
for (int j = 0; j < cur_layer_mapsize; j++)
{
delta_sum += cur_layer->mapi.errorj;
}
cur_layer->mapi.delta_bias += delta_sum;
}
}
这个函数很大,但作用的地方不多!这里边buffer2和c31_备用_layer.mapi.error要碰撞出火花在convolution_calcuVggBPplus1函数中,我们看他们如何完成操作:
void convolution_calcuVggBPplus1(double* input_map_data, int input_map_width, int input_map_height, double* kernel_data, int kernel_width,
int kernel_height, double* result_map_data, int result_map_width, int result_map_height,double* c33备用,double* c31备用)//c33备用=error,c31备用=buffer
{
// log_exec("convolution_calcu");
double sum = 0.0;
for (int i = 0; i < result_map_height; i++)//3
{
for (int j = 0; j < result_map_width; j++)//3
{
sum = 0.0;
for (int n = 1; n < kernel_height-1; n++)//14
{
for (int m = 1; m < kernel_width-1; m++)//14
{
int index_input_reshuffle = (i-1 + n) * input_map_width + j-1 + m;//
int index_kernel_reshuffle = n * kernel_width + m;//14*14
sum += input_map_dataindex_input_reshuffle * (kernel_dataindex_kernel_reshuffle
+c33备用index_input_reshuffle *c31备用index_input_reshuffle) ;//16*16
}////c33备用*c31备用==error*buffer
}
int index_result_reshuffle = (i) * result_map_width + j;//3*3
result_map_dataindex_result_reshuffle += sum;
}
}
}
在反向传播中**error*buffer=cur_layer->mapk.errori \* cur_layer_mapwidth + j *activation_function::d_tan_h(pre_layer->mapi.datak)**是不是有一种似曾相识的感觉!
只不过是跳过了c31!
over,残差网络虚线部分实现!残差跨越传递,12*16*16到16*16*16叫虚线resnet,那么实线就是:16*16*16到16*16*16的残差跨越传递!
复盘的威力还是巨大的,7月实现以来,算是做个总结,一个上了70分(vgg)!一个上了60分(resnet)!7月初版都要低十分!
我这个一系列实现,你所是lenet就是lenet!
你所是vgg,就是vgg!
你所是resnet,就是resnet!
你说是人脸识别中的deepid,他也有点像,因为他悟道宏观特征与细节特征的结合!
你说他是抄出来的,他就是抄出来的!
你说什么都不是,也就什么都不是!
他只是你自己!
这个世界真的很小,网络上什么都有,都可以学到,抄到,抄成自己的!
你想到了,网上都有,就像另一个自己!
你想不到的,网上还有!
这真是一个好时代!
近期,在网上也看了不少好电影!希望有一天,自己在网上也能留点痕迹!