前言
论文阅读解析:【论文阅读】【yolo系列】YOLOv10: Real-Time End-to-End Object Detection
YOLOV8的解析:【yolov8系列】yolov8的目标检测、实例分割、关节点估计的原理解析
工程方面,没有阅读yolov10官方的github工程,而是yolov5/8的官方工程 ultralytics。
ultralytics 工程支持yolo主系列的版本的训练,当然也包括yolov10。于是相较于原论文中的设计,部分操作和结构并没有保持完全一致。本篇博客以ultralytics工程的实现细节为主,记录yolov10在实现上的细节。1 模型结构简介
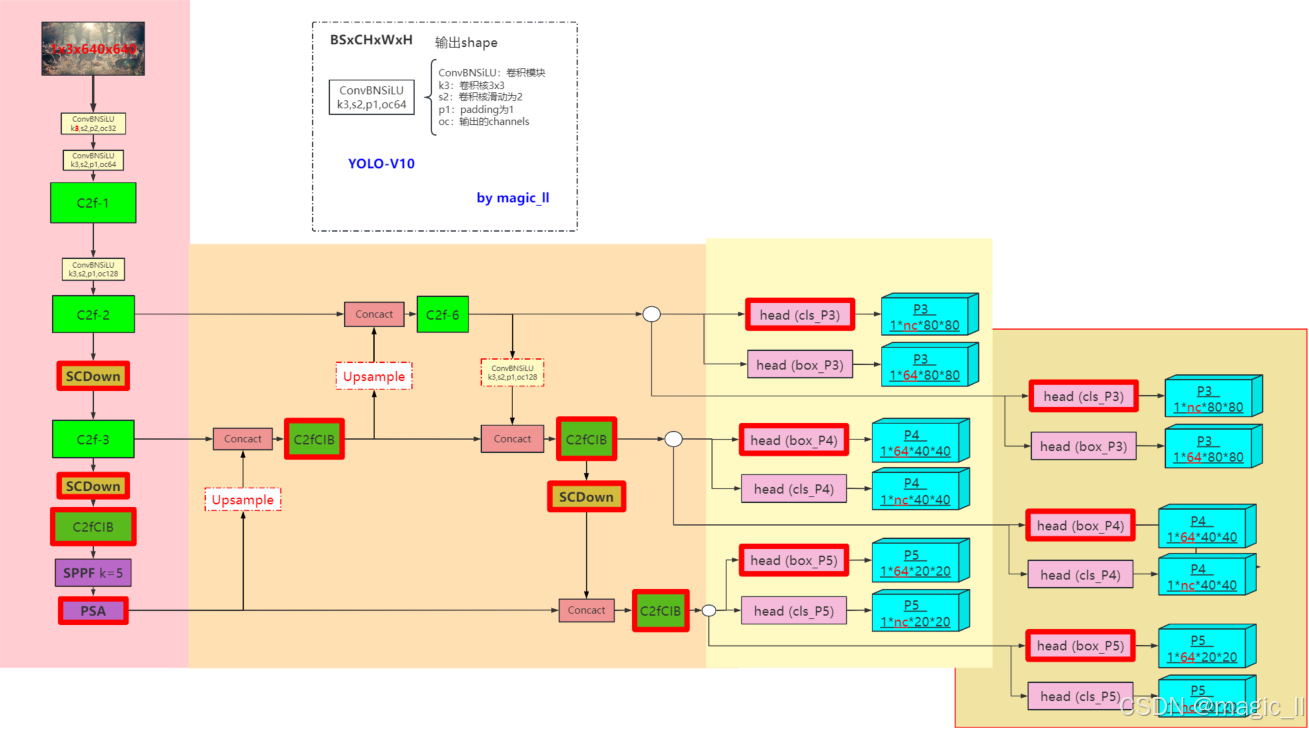
YOLOV10的结构如下图
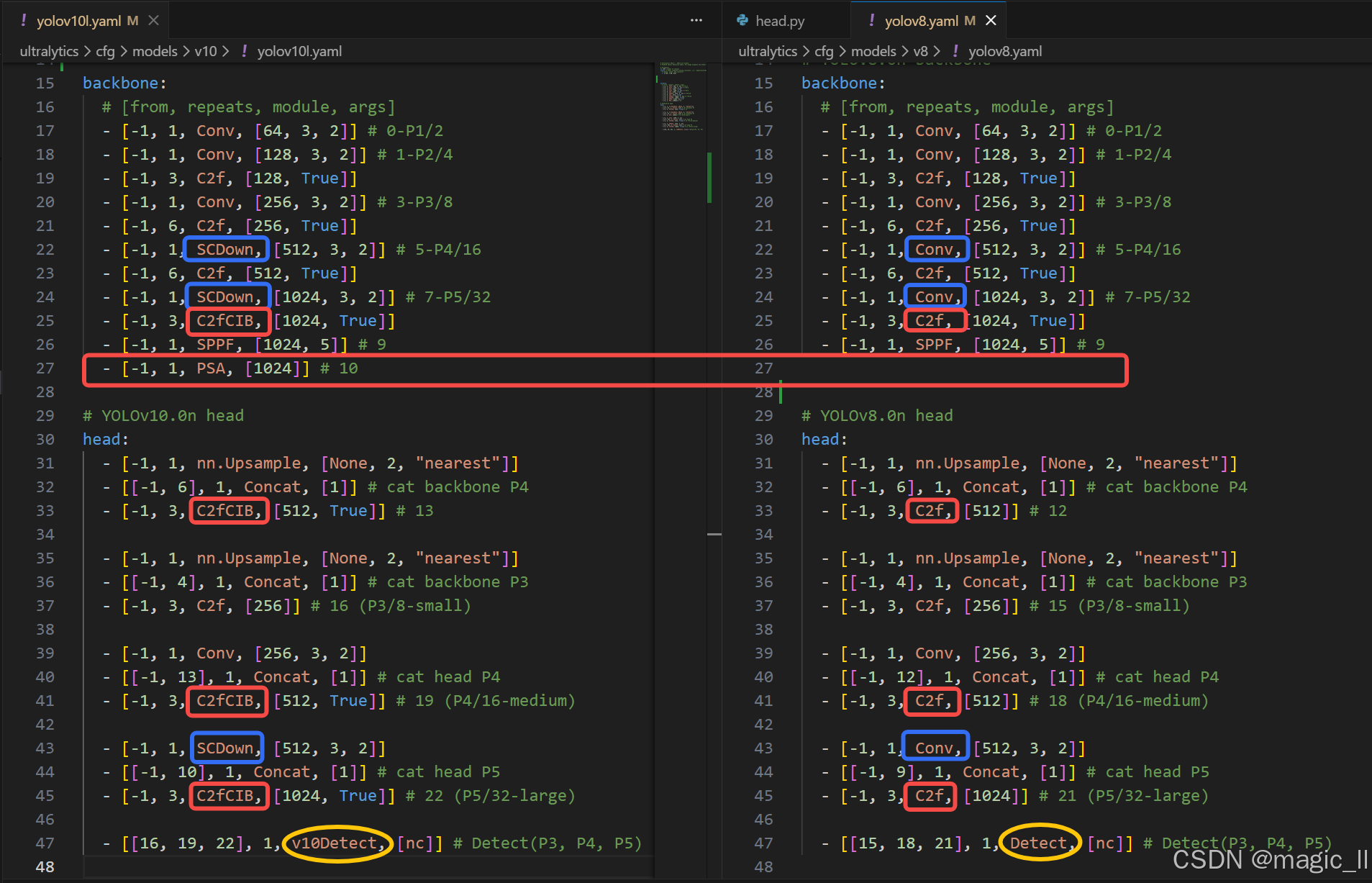
工程中的yolov10和yolov8的网络结构的配置文件的对比
YOLOv10 论文中改进
详细内容可参考 YOLOV10论文解析第三章节 Methodology。在工程 ultralytics 中,论文中的内容并没有完全使用。
- 无 NMS 训练的一致双重分配、一致性匹配度量标准
- 【精度驱动】C2fCIB 中大核心卷积:C2fCIB 替代 C2f。ultralytics 定义了该模块 但实际没有使用
- 【精度驱动】部分自注意力(PSA)
- 【效率驱动】C2fCIB 中的结构重参数化。ultralytics 定义了该模块 但实际没有使用
- 【效率驱动】空间通道解耦式降采样:SCDown 代替了 Conv下采样
- 【效率驱动】分类任务头的轻量化:DWConv中 代替了 Conv 前向计算
- 【效率驱动】基于秩的模块化设计。 ultralytics 实际没有使用
工程中实际实现内容如下
- C2fCIB 模块
- PSA(部分自注意力)模块
- SCDown 模块
- DWconv 模块
- 任务头模块 &(无 NMS 训练的一致双重分配、一致性匹配度量标准)
2 C2fCIB 模块
在介绍 C2fCIB 模块前,需要重提下
- DWConv。在yolov10中多处使用 深度可分离卷积,该卷积较早之前就提出,是较为基础的卷积,这里不展开讲述。
- C2f。C2f 的介绍在 yolov8 的详解中的3.1.2章节记录
- C2fCIB。在YOLOV10中使用。该模块在C2f 模块的基础上,使用 CIB 模块替换了 Bottleneck 模块,那只需要对比 CIB 与 Bottleneck 的实现。工程中在【
ultralytics/nn/modules/block.py】中实现了 C2fCIB。
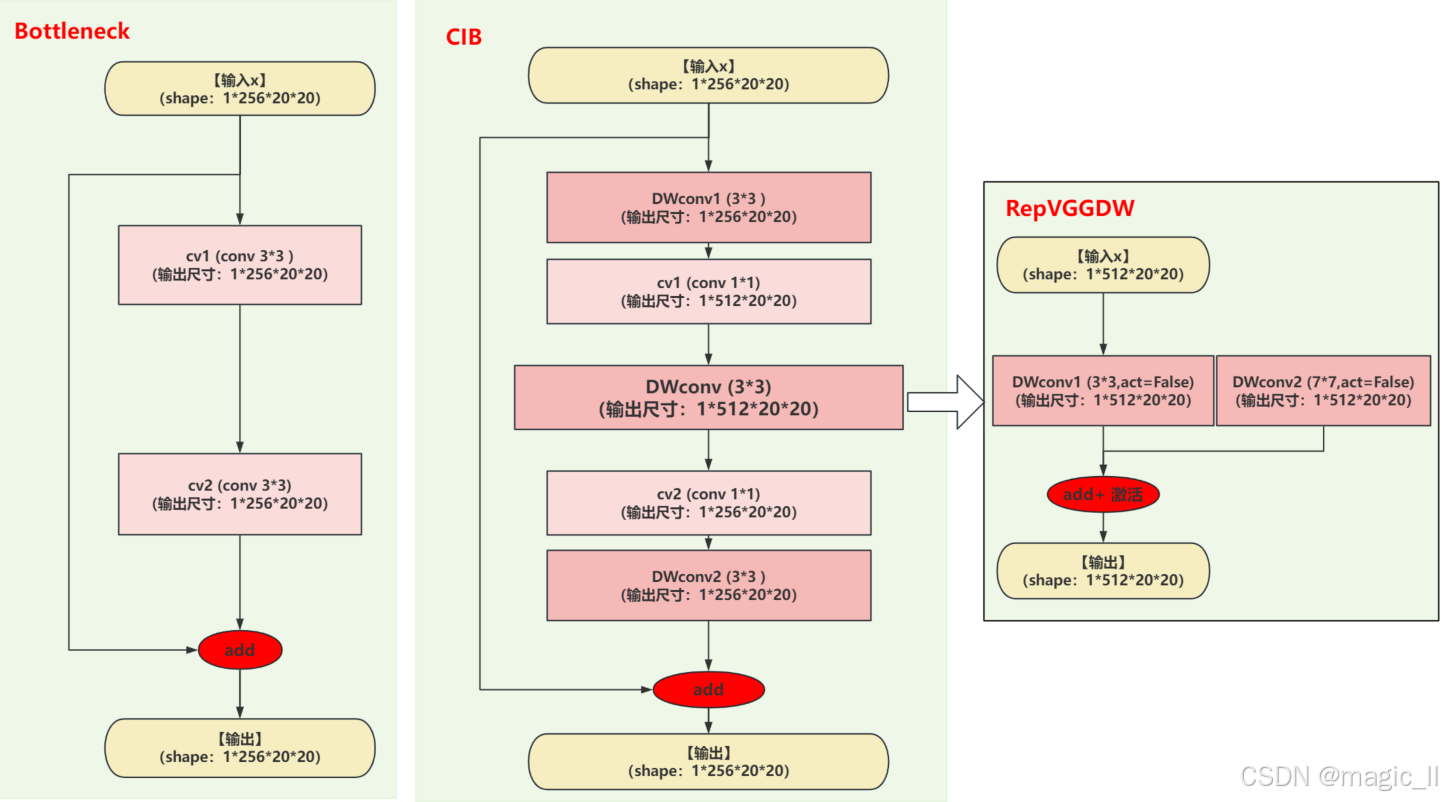
2.1 CIB 与 Bottleneck 结构对比
上图左1为 Bottleneck 模块结构;中间的为 CIB 模块结构;右侧为 RepVGGDW,可将 CIB 最中间层替换。
Bottlenet:
层 输出 shape 参数量 计算量 (FLOP) Conv3×3, C→C N×C×H×W 3×3×C×C = 9 C² 3×3×C×C×H×W×N = 9 C² H W N Conv3×3, C→C N×C×H×W 3×3×C×C = 9 C² 3×3×C×C×H×W×N = 9 C² H W N 总计 --- 18 C² 18 C² H W N CIB:
层 输出 shape 参数量 计算量 (FLOP) DWConv3×3, C groups N×C×H×W 3×3×1×C = 9 C 3×3×1×C×H×W×N = 9 C H W N PWConv1×1, C→2C N×2C×H×W 1×1×C×2C = 2 C² 1×1×C×2C×H×W×N = 2 C² H W N DWConv3×3, 2C groups N×2C×H×W 3×3×1×2C = 18 C 3×3×1×2C×H×W×N = 18 C H W N PWConv1×1, 2C→C N×C×H×W 1×1×2C×C = 2 C² 1×1×2C×C×H×W×N = 2 C² H W N DWConv3×3, C groups N×C×H×W 3×3×1×C = 9 C 3×3×1×C×H×W×N = 9 C H W N 总计 --- 4 C² + 36 C (4 C² + 36 C) H W N RepVGGDW:
- 将CIB最中间增加一个分支 使用DWConv7*7,和原有的DWConv3*3,就组成了 RepVGGDW。这样的话,参数增加了 98C,计算量增加了 98 CHWN。
- 该模块为论文中描述的 C2fCIB 中的大核卷积,使用了7*7的深度可分离卷积。在推理时,该模块会进行 结构重参数化。
- 在工程中,没有使用 DWConv7*7 分支。
2.2 CIB 与 Bottleneck 能力对比
两层的 3×3 直筒只给出"最原始"的局部线性+非线性叠加;
五层深度可分离瓶颈在几乎 1/3 的计算成本 下,提供了更深非线性、更大感受野、通道扩缩容量、内置正则四重优势,因而成为轻量高性能模型的首选单元。
参数 / 计算效率
指标 A 结构 B 结构 B/A 比值(C=32 为例) 参数量 18 C² 4 C² + 36 C ≈ 0.30 计算量 18 C² HWN (4 C² + 36 C) HWN ≈ 0.30 → B 用约 30 % 的参数 & 计算量 就完成了更长的非线性变换链路。
表征能力
- 非线性层数 :A 只有 2 层激活,B 有 5 层激活(每层卷积后都接非线性)。
更深的光滑非线性曲面带来更强的函数逼近能力。- 通道扩展:B 在中间把通道升到 2 C,给了 3×3 DW 更丰富的"独立滤波器bank",而 A 全程通道数不变,没有这种"扩张-压缩"的容量缓冲。
- 感受野:A 固定 5×5;B 更大的感受野,却没用更大 kernel,仅靠深度可分离堆叠就拿到更大视野,利于捕获远距离空间依赖。
正则与泛化
- DW 卷积本身每组只处理 1 个通道,天然地把参数量拆成"空间-通道"两段,相当于在通道维度引入分组正则,降低过拟合风险。
- 1×1 PW 负责跨通道信息融合,可视为低秩投影(bottleneck),进一步起到参数压缩 + 正则作用。
实际部署友好
- 计算密度低:DW 卷积的乘法密度(每像素乘加数)远低于普通卷积,对移动端/缓存更友好。
- 可插入残差:B 结构输入输出通道一致,天然适合做成残差边,训练更深网络时梯度更稳。
3 PSA 模块
全名Partial self-attention (PSA),在脚本【
ultralytics/nn/modules/block.py】中定义。
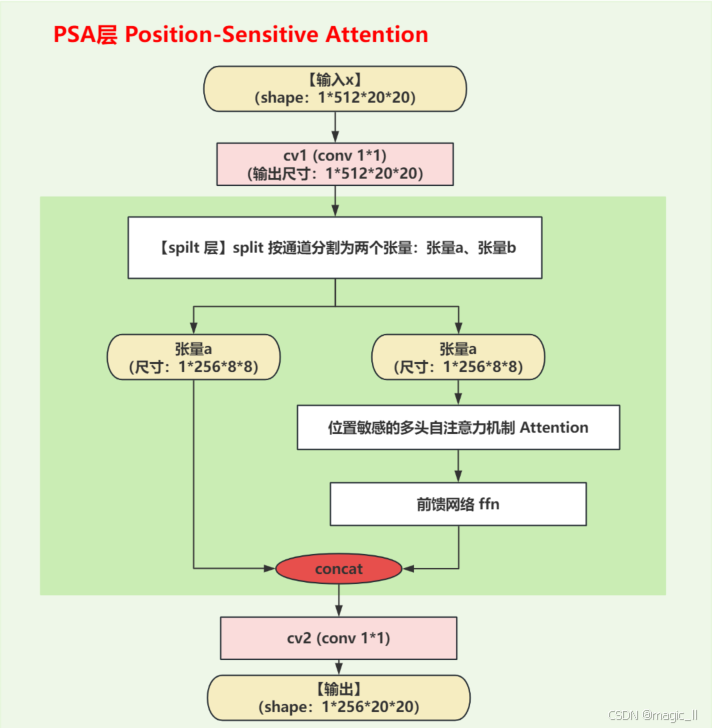
该模块核心的为 位置敏感的多头自注意力子模块 Attention层,然后正常的跟个前馈神经网络,做特征再提取。
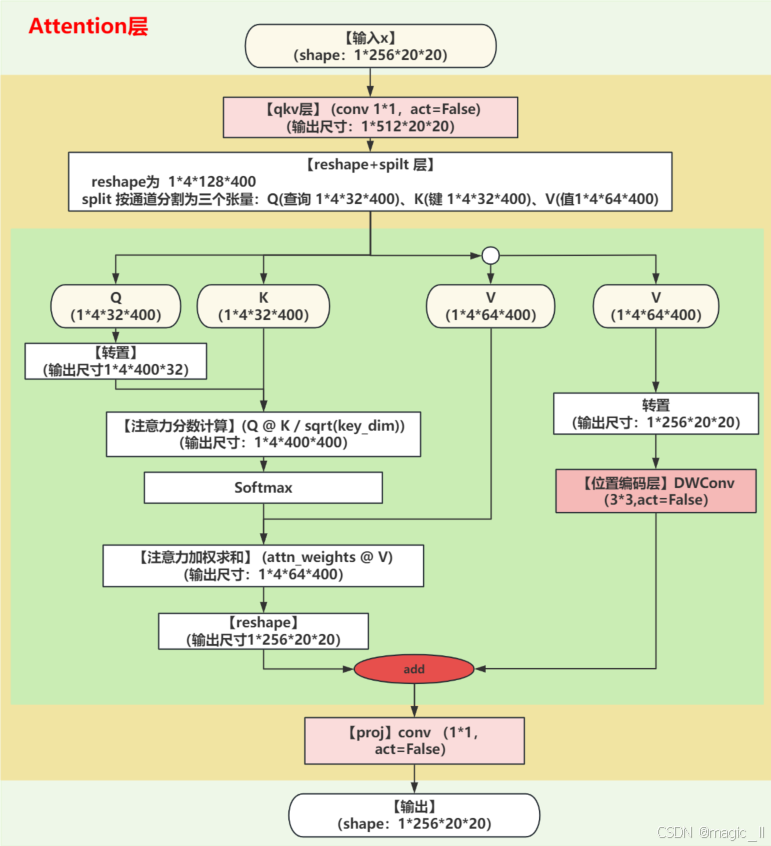
3.1 Attention层
理解Attention模块中具体的结构,以及多头、qkv操作,图中为yolov10实际的参数数值,详细分析维度变化过程如下:
- 【初始化参数计算(num_heads=4) 】
假设输入通道数dim=256,注意力头数num_heads=4,注意力比例attn_ratio=0.5:
- 每个 V注意头的维度: head_dim = dim/num = 256 / / 4 = 64 \text{head\_dim = dim/num} = 256//4=64 head_dim = dim/num=256//4=64
- Q/K的维度: key_dim = int(head_dim*attn_ratio) = i n t ( 64 ∗ 0.5 ) = 32 \text{key\_dim = int(head\_dim*attn\_ratio)}=int(64*0.5) = 32 key_dim = int(head_dim*attn_ratio)=int(64∗0.5)=32
- 所有头的Q/K总维度: nh_kd = key_dim * num_heads = 32 ∗ 4 = 128 \text{nh\_kd = key\_dim * num\_heads} = 32*4 =128 nh_kd = key_dim * num_heads=32∗4=128
- qkv卷积的输出通道数: h=dim + nh_kd * 2 = 256 + 128 ∗ 2 = 512 \text{h=dim + nh\_kd * 2} = 256 + 128 * 2 = 512 h=dim + nh_kd * 2=256+128∗2=512
- 【qkv卷积与维度变化】
- 输入x的维度:B, C, H, W = B, 256, H, W
- qkv卷积输出:B, 256, H, W → B, 512, H, W
- 【分割 q、k、v(关键步骤) 】
具体操作为 reshape 和 切片:
- reshape维度变化:B, 512, H, W → B, 4, 32\*2+64, N = B, 4, 128, N (N = H×W)
- 分割后维度:
- q : B , 4 , 32 , N q: B, 4, 32, N q:B,4,32,N (4个注意力头,每个头的Q为32维)
k : B , 4 , 32 , N k: B, 4, 32, N k:B,4,32,N (4个注意力头,每个头的K为32维)
v : B , 4 , 64 , N v: B, 4, 64, N v:B,4,64,N (4个注意力头,每个头的V为64维)- 这里清晰地体现了注意力头数的作用:
self.num_heads=4决定了第2维的大小为4- 每个注意力头独立拥有自己的Q、K、V空间
- 所有注意力头并行处理不同的特征子空间
- 【注意力计算过程】
- Q转置:B, 4, 32, N → B, 4, N, 32
- 注意力分数计算:Q^T @ K → B, 4, N, 32 @ B, 4, 32, N = B, 4, N, N
- Softmax归一化:保持维度不变 B, 4, N, N
- 加权求和:V @ attn^T → B, 4, 64, N @ B, 4, N, N = B, 4, 64, N
- reshape回原始通道数:B, 4, 64, N → B, 256, H, W
- 【位置编码与输出】
- 位置编码:对 V 进行3×3深度卷积 B, 256, H, W → B, 256, H, W
- 残差连接:注意力输出 + 位置编码
- 投影层:保持通道数不变 B, 256, H, W → B, 256, H, W
【维度变化总结表】(num_heads=4)
操作 张量 维度变化 输入 x B, 256, H, W qkv卷积 qkv B, 256, H, W → B, 512, H, W 重塑 qkv_reshaped B, 512, H, W → B, 4, 128, N 分割Q q B, 4, 32, N 分割K k B, 4, 32, N 分割V v B, 4, 64, N Q转置 q.transpose B, 4, 32, N → B, 4, N, 32 注意力分数 q@k B, 4, N, 32 @ B, 4, 32, N → B, 4, N, N 加权求和 v@attn B, 4, 64, N @ B, 4, N, N → B, 4, 64, N 重塑 - B, 4, 64, N → B, 256, H, W 位置编码 pos_encoding B, 256, H, W → B, 256, H, W 输出 x B, 256, H, W
【注意力头的核心作用】
- 特征空间分解 &多角度关注:将256维的特征空间分解为4个64维的子空间,每个头专注于不同的特征模式(不同的注意力模式),增强模型的表达能力
- 并行处理:4个注意力头并行计算,提高模型的并行能力
- 维度效率 :通过降维注意力(Q/K使用32维而非64维)提高计算效率
通过这种多注意力头的设计,YOLOv10的Attention模块能够在保持计算效率的同时,有效捕捉不同尺度和角度的特征依赖关系。
3.2 FFN 层
self.ffn前馈神经网络确实采用了先升维再降维的设计模式,在Transformer、Vision Transformer以及现代卷积神经网络中被广泛应用,是一种兼顾性能与效率的设计选择。
pythonself.ffn = nn.Sequential( Conv(self.c, self.c*2, 1), # 升维:c → 2c Conv(self.c*2, self.c, 1, act=False) # 降维:2c → c )【结构细节】:
- 输入x 的维度 1,256,20,20
- 升维阶段 conv 1×1:
- 输出维度 1,512,20,20
- 作用:
增加特征空间维度,提升模型的表达能力
引入更多非线性变换(通过Conv模块中的激活函数)- 降维阶段 conv 1*1:
- 输出维度 1,256,20,20
- 作用:
保持输出维度与输入一致,便于外部的残差连接
最后一层没有激活函数(act=False),让后续操作决定输出特性
【技术优势】:
- 高效计算:使用1×1卷积进行维度变换,计算量远小于3×3等大卷积
- 特征增强 :中间升维过程能够捕捉更丰富的特征交互
- 残差友好:输入输出维度一致,便于添加残差连接
- 参数高效:相比直接使用大通道数,这种结构在参数总量增加不多的情况下提升性能
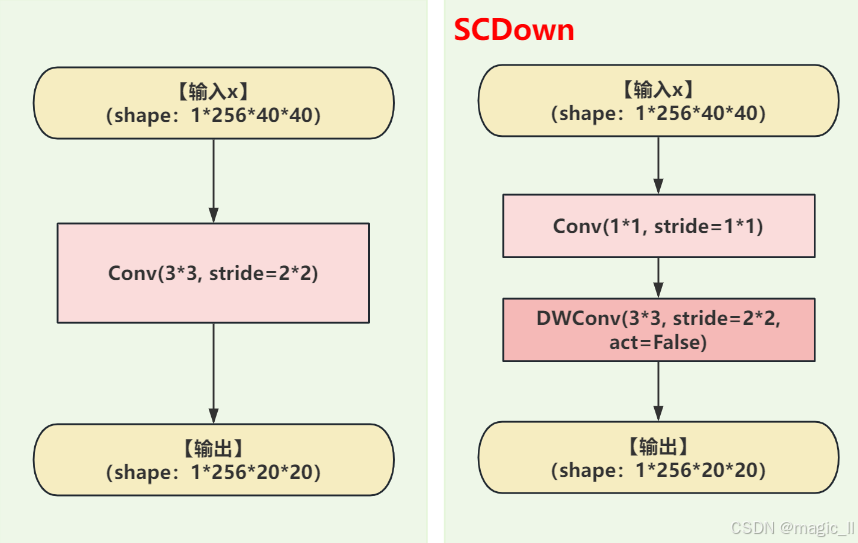
4 SCDown 下采样
- yolov8中的下采样:conv(3*3, stride=2*2)。
- yolov10中下采样:conv(1*1)、DWconv(3*3,stride=2*2,act=False)。更少的参数、更少的计算量。yolov10中将下采样拆解,
- 先使用 point-wise conv 进行通道信息交错融合
- 再使用DWconv 降低尺寸。不加激活,保留线性传递,防止小目标/边缘信息被激活截断。
与其它下采样对比
模块 参数量 计算量 激活次数 感受野 信息保留 conv(3×3/s2) 9 C C′ 9/2 C C′ HWN 1 3×3 中 SCDown C C′ + 9 C′ (C C′ + 9/4 C′) HWN 1(仅 PW 后) 3×3 高 MaxPool+Conv C C′ C C′ HWN 1 2×2 低(不可学习)
5 一致性双重分配(Consistent Dual Assignments)
NMS 曾长期稳坐检测后处理头把交椅,却避免不掉额外耗时;诸多替代方案轮番上阵,又常牵出新麻烦。YOLOv10 的一致性双重分配策略,轻巧化解了上述两难。
【无 NMS 的核心:一致性双重分配】
- 训练时同时放两份检测头
- One-to-Many Head(OTM):负责学习,一个 gt 匹配多个 anchor,保证监督信号充足。 (与yolov8保持一致思想)
- One-to-One Head(OTO):负责无冗余输出,一个 gt 只匹配分数最高的 1 个 anchor,模拟推理场景。
- 两个头共用同一套特征,用统一匹配度量
m = s α ⋅ I o U β ( α = β = 0.5 ) m = s^α · IoU^β (α=β=0.5) m=sα⋅IoUβ(α=β=0.5)
训练损失加权求和,让 OTM 学到的特征对 OTO 同样有效;论文里两头的匹配一致性可达 95% 以上 。- 推理时只启用 OTO 头,天然没有重复框,于是把 NMS 彻底省掉 。
【Detect 模块结构 】
(输入:3 层特征 P3/8, P4/16, P5/32)
分支 组成 输出通道 激活 备注 共享 Stem 2×DWConv3×3 + 1×PWConv1×1 256 SiLU 先统一通道数 OTM 头 1×PWConv → 2×DWConv3×3 → Reg/Cls 1×1 4A+C 无 A=anchor 数 OTO 头 同 OTM 结构,独立权重 4A+C 无 仅训练时更新
- 两个头各自输出 (reg, cls) 后,分别与 gt 做标签分配,各自算损失;反向传播只更新对应分支权重。
- 因为 OTO 头在训练阶段就被迫"只挑最高分",所以推理直接拿它输出即可,无需再做 NMS 。
【训练阶段样本分配】
- OTM 头:沿用 YOLOv8 的 Task-Aligned 策略
把 head 输出的所有预测框 decode 成原图坐标,然后通过规则选取 top-10 的框 → 正样本;其余负样本。- OTO 头:同一度量,但强制 top-1
每个 gt 只在所有 anchor 里选 t 最大的那一个作为正样本,其余一律负样本。- 损失函数 单头的loss与yolov8保持一致
L = L_OTM + λ·L_OTO ,λ 默认 1.0
L_OTM 负责让网络"看得多、学得好";L_OTO 负责让网络"不打架、无冗余"【推理阶段使用流程(真正部署时) 】
整个过程没有 NMS、没有 Top-K、没有排序,CPU 后处理耗时 < 0.1 ms 。
- 输入图片 → Letterbox resize → 640×640
- Backbone + Neck → 拿到 3 层特征
- 只启用 OTO 头 → 直接输出 1×(4+1+C)×H×W 的 tensor
- 置信度阈值 0.25 过滤 → 解码坐标 → 输出最终框
收益小结
- 延迟:相比 YOLOv9-C 省掉 NMS,整体推理延迟 ↓ 46% 。
- 精度:密集场景(人群、车流)召回率 ↑ 8%,不再因 NMS 阈值误删框 。
- 部署:ONNX/TensorRT 导出时,模型图里连 NMS 节点都没有,端侧落地零额外算子。
一句话:YOLOv10 把"学的时候多给信号,用的时候只留一个最高分"做成双重头,用训练一致性代替后处理 NMS,从而真正端到端。