Day 45 简单CNN@浙大疏锦行
探究修改卷积神经网络(CNN)的深度与宽度,以及改变学习率调度器对模型训练效果的影响。
模型结构修改
相比于课程中的基础3层CNN,本次实验进行了以下改进:
- 增加深度:增加了一个卷积块(Block 4),使网络变为4层卷积结构。
- 增加宽度 :通道数逐层递增为
32 -> 64 -> 128 -> 256。 - 特征图变化 :
- 输入: 32x32
- Block 1: 16x16 (Pool后)
- Block 2: 8x8 (Pool后)
- Block 3: 4x4 (Pool后)
- Block 4: 2x2 (Pool后)
- Flatten: 256 * 2 * 2 = 1024 维
- 目的:更深的网络理论上能提取更抽象、更高级的语义特征,适合处理稍微复杂一点的图像分类任务。
调度器修改
- 原方案 :
ReduceLROnPlateau(当指标不再下降时被动降低学习率)。 - 新方案 :
CosineAnnealingLR(余弦退火调度器)。 - 原理:学习率按照余弦函数曲线随 Epoch 逐渐下降。
- 优势 :
- 不需要设置
patience等阈值参数,全程平滑调整。 - 在训练初期保持较高学习率探索,后期快速收敛到局部最优。
- 相比阶梯式下降,余弦退火通常能带来更平滑的收敛曲线。
- 不需要设置
python
# 1. 数据预处理与增强
# 训练集增强
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 测试集标准化
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
python
# 2. 定义改进后的CNN模型 (4层卷积)
class ModifiedCNN(nn.Module):
def __init__(self):
super(ModifiedCNN, self).__init__()
# Block 1: 3 -> 32
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2, 2) # 32x32 -> 16x16
# Block 2: 32 -> 64
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2, 2) # 16x16 -> 8x8
# Block 3: 64 -> 128
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.pool3 = nn.MaxPool2d(2, 2) # 8x8 -> 4x4
# Block 4 (新增): 128 -> 256
self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(256)
self.relu4 = nn.ReLU()
self.pool4 = nn.MaxPool2d(2, 2) # 4x4 -> 2x2
# 全连接层
# 最终特征图大小为 2x2,通道数为 256
self.fc1 = nn.Linear(256 * 2 * 2, 512)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.bn1(self.conv1(x))))
x = self.pool2(self.relu2(self.bn2(self.conv2(x))))
x = self.pool3(self.relu3(self.bn3(self.conv3(x))))
x = self.pool4(self.relu4(self.bn4(self.conv4(x))))
x = x.view(-1, 256 * 2 * 2) # 展平
x = self.dropout(self.relu4(self.fc1(x)))
x = self.fc2(x)
return x
model = ModifiedCNN().to(device)
print(model)
python
# 3. 定义训练函数 (包含绘图)
def train_model(model, train_loader, test_loader, criterion, optimizer, scheduler, epochs):
model.train()
train_acc_history = []
test_acc_history = []
train_loss_history = []
test_loss_history = []
lrs = [] # 记录学习率变化
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
# 训练阶段
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
train_acc_history.append(epoch_train_acc)
train_loss_history.append(epoch_train_loss)
# 测试阶段
model.eval()
test_loss = 0
correct_test = 0
total_test = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
test_acc_history.append(epoch_test_acc)
test_loss_history.append(epoch_test_loss)
# 记录当前学习率
current_lr = optimizer.param_groups[0]['lr']
lrs.append(current_lr)
# 更新学习率 (CosineAnnealingLR 需要在每个 epoch 后 step)
scheduler.step()
print(f'Epoch {epoch+1}/{epochs} | LR: {current_lr:.6f} | '
f'Train Acc: {epoch_train_acc:.2f}% | Test Acc: {epoch_test_acc:.2f}%')
# 绘图
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.plot(train_acc_history, label='Train Acc')
plt.plot(test_acc_history, label='Test Acc')
plt.title('Accuracy')
plt.legend()
plt.subplot(1, 3, 2)
plt.plot(train_loss_history, label='Train Loss')
plt.plot(test_loss_history, label='Test Loss')
plt.title('Loss')
plt.legend()
plt.subplot(1, 3, 3)
plt.plot(lrs, label='Learning Rate')
plt.title('Learning Rate Schedule')
plt.legend()
plt.tight_layout()
plt.show()
return epoch_test_acc
python
# 4. 开始训练
# 使用 CrossEntropyLoss
criterion = nn.CrossEntropyLoss()
# 使用 Adam 优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 使用 CosineAnnealingLR 调度器
# T_max 设置为 epochs,表示一个周期的长度
epochs = 20
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=0.00001)
print("开始训练 ModifiedCNN (4层卷积 + CosineAnnealingLR)...")
train_model(model, train_loader, test_loader, criterion, optimizer, scheduler, epochs)实验结果
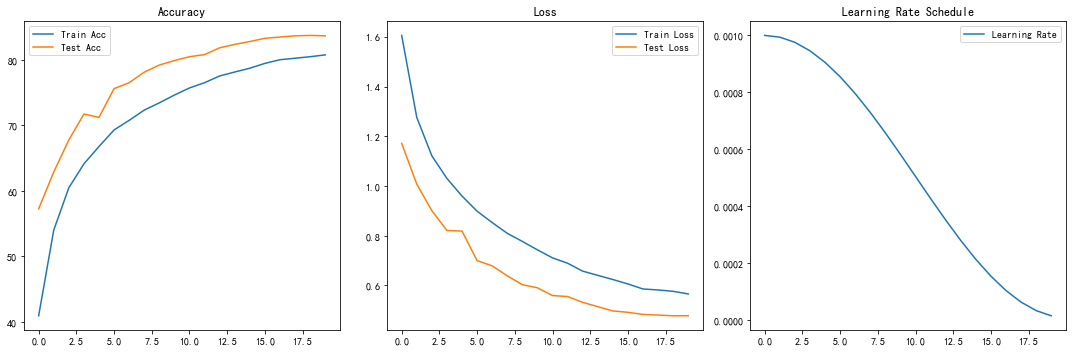
根据实际训练结果(20 Epochs):
- 最终指标 :
- Test Acc: 83.64% (最高)
- Train Acc: 80.73%
- 现象分析 :
- 泛化能力强:测试集准确率始终高于训练集。这主要归功于训练时使用了强力的数据增强(RandomCrop, Rotation, ColorJitter)以及 Dropout 层。训练时的"噪声"增加了学习难度,而测试时模型处于 Eval 模式(无 Dropout,无增强),因此表现更佳。
- 收敛性 :配合
CosineAnnealingLR,学习率从0.001平滑降至1.6e-5。在最后几个 Epoch,虽然学习率很低,但准确率仍有微小提升(从 83% 提升到 83.6%),说明模型在局部极小值附近收敛得很好。
- 结论 :改进后的 4 层卷积结构配合余弦退火策略,在 CIFAR-10 上达到了约 83.6% 的准确率,且未出现过拟合,证明了模型结构改进和训练策略的有效性。
.001平滑降至1.6e-5`。在最后几个 Epoch,虽然学习率很低,但准确率仍有微小提升(从 83% 提升到 83.6%),说明模型在局部极小值附近收敛得很好。
- 结论 :改进后的 4 层卷积结构配合余弦退火策略,在 CIFAR-10 上达到了约 83.6% 的准确率,且未出现过拟合,证明了模型结构改进和训练策略的有效性。