这一部分重点掌握SQL性能优化的两大核心工具(EXPLAIN命令、慢查询日志),并拆一个移动代理商结算系统的场景案例。
一、EXPLAIN命令深度解读
EXPLAIN是MySQL等关系型数据库的性能诊断核心工具,通过在SQL语句前添加EXPLAIN关键字,可获取SQL的执行计划,直观看到表访问方式、索引使用情况、查询顺序等关键信息,从而定位性能瓶颈。
1.1 EXPLAIN基本用法
在目标SQL前直接拼接EXPLAIN即可,支持单表查询、多表关联、子查询等各类SQL:
sql
-- 单表查询示例
EXPLAIN SELECT * FROM agent_settlement WHERE agent_id = 'AGT2025001';
-- 多表关联示例
EXPLAIN SELECT s.settlement_id, a.agent_name, s.amount
FROM agent_settlement s
INNER JOIN agent_info a ON s.agent_id = a.agent_id
WHERE s.settlement_month = '2025-11';1.2 EXPLAIN输出字段核心解读(重点必掌握)
EXPLAIN返回结果包含12个字段,其中以下6个是分析性能的核心,其余字段按需了解:
| 字段名 | 核心含义 | 关键取值及性能意义 |
|---|---|---|
| id | 查询中操作表的执行顺序 | 1. id越大,执行优先级越高;2. id相同,按从上到下顺序执行;3. id为NULL:结果集合并(如UNION的临时表) |
| select_type | 查询类型,区分简单/复杂查询 | 1. SIMPLE:简单查询(无subquery/UNION),性能最优;2. PRIMARY:复杂查询最外层查询;3. SUBQUERY:子查询中的第一个SELECT;4. DERIVED:FROM子句中子查询(生成临时表),性能较差 |
| type | 表访问方式(核心性能指标) | 优先级(从优到劣):system > const > eq_ref > ref > range > index > ALL- 优:ref及以上(使用索引);- 差:ALL(全表扫描)、index(全索引扫描),需优化 |
| possible_keys | MySQL可能使用的索引 | 非空表示有潜在可用索引,空则无索引可选 |
| key | MySQL实际使用的索引 | 1. 非空:实际命中索引;2. 空:未使用索引(可能全表扫描);3. 若possible_keys非空但key空,需检查索引是否失效 |
| rows | MySQL预估扫描的行数 | 数值越小越好,数值越大说明扫描数据越多,性能越差 |
1.3 EXPLAIN解读
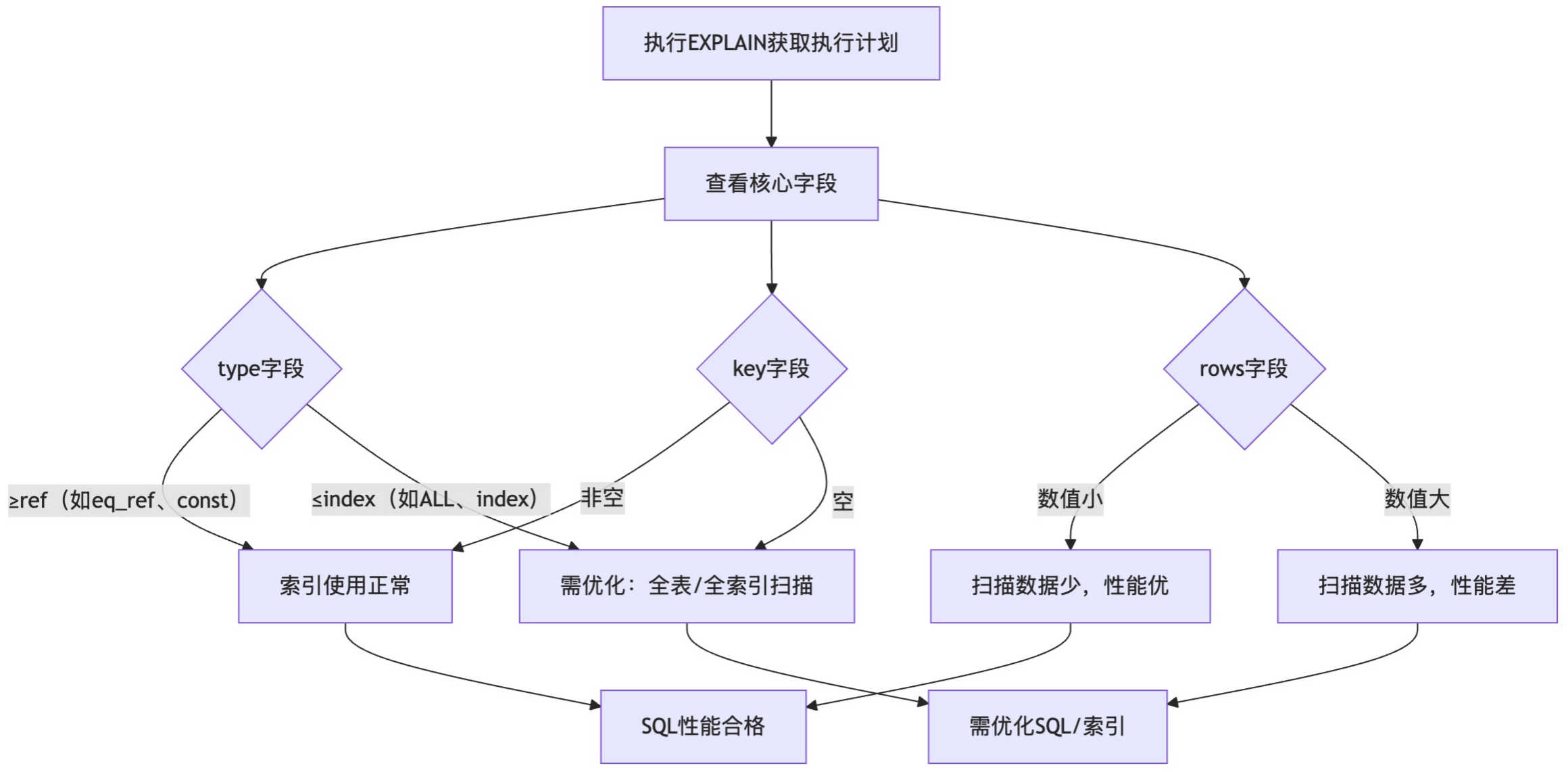
通过type、key、rows三个核心字段可快速判断SQL性能等级,优先确保type达到ref及以上,key非空,rows尽可能小。
二、问题定位:慢查询日志分析
慢查询日志是记录"执行时间超过阈值"的SQL语句的日志文件,是定位系统中低效SQL的"黑匣子",通过分析日志可精准找到需要优化的目标SQL。
2.1 慢查询日志核心配置(MySQL)
需通过参数开启和配置慢查询日志,支持临时生效(重启失效)和永久生效(修改配置文件):
2.1.1 临时生效(适合测试/排查)
sql
-- 开启慢查询日志(1=开启,0=关闭)
SET GLOBAL slow_query_log = 1;
-- 设置慢查询阈值:执行时间超过2秒的SQL记录(默认10秒,生产建议1-5秒)
SET GLOBAL long_query_time = 2;
-- 记录未使用索引的SQL(排查索引问题时开启,生产不建议长期开,避免日志过大)
SET GLOBAL log_queries_not_using_indexes = 1;
-- 验证配置是否生效
SHOW VARIABLES LIKE 'slow_query%';
SHOW VARIABLES LIKE 'long_query_time';2.1.2 永久生效(生产环境推荐)
修改MySQL配置文件(my.cnf或my.ini),在mysqld节点下添加:
sql
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/mysql-slow.log # 日志存储路径(需授权)
long_query_time = 2
log_queries_not_using_indexes = 0 # 生产关闭,避免日志膨胀
log_throttle_queries_not_using_indexes = 10 # 若开启,限制每秒最多记录10条未索引SQL修改后重启MySQL生效:systemctl restart mysql
2.2 慢查询日志内容解读
慢查询日志每条记录包含执行时间、用户、SQL语句等关键信息,格式示例:
sql
# Time: 2025-12-22T22:00:00.000000Z # 查询执行时间
# User@Host: root[root] @ localhost [] # 执行用户和客户端
# Query_time: 5.876 Lock_time: 0.002 Rows_sent: 100 Rows_examined: 20000 # 核心指标
SET timestamp=1734909600;
# 具体慢查询SQL
SELECT s.*, a.agent_name, p.product_name
FROM agent_settlement s
LEFT JOIN agent_info a ON s.agent_id = a.agent_id
LEFT JOIN product p ON s.product_id = p.product_id
WHERE s.settlement_month = '2025-11' AND s.status = 'UNSETTLED';核心指标解读
-
Query_time:查询执行时间(核心,超过long_query_time阈值才会记录)
-
Lock_time:SQL获取锁的时间(过长说明锁竞争严重)
-
Rows_sent:返回给客户端的行数(业务实际需要的数据量)
-
Rows_examined:MySQL实际扫描的行数(若远大于Rows_sent,说明索引失效或SQL逻辑差)
2.3 慢查询日志分析工具
直接查看日志文件效率低,推荐使用工具快速统计分析:
2.3.1 自带工具:mysqldumpslow(简单易用)
MySQL内置工具,适合快速统计高频慢查询、最慢查询等:
sql
# 统计按执行时间排序的前10条慢查询
mysqldumpslow -s t -t 10 /var/log/mysql/mysql-slow.log
# 统计访问次数最多的前10条慢查询
mysqldumpslow -s c -t 10 /var/log/mysql/mysql-slow.log
# 模糊匹配包含"agent_settlement"的慢查询
mysqldumpslow -g "agent_settlement" /var/log/mysql/mysql-slow.log2.3.2 进阶工具:pt-query-digest(功能强大)
Percona Toolkit中的工具,可生成详细分析报告,支持按时间范围、SQL类型过滤:
sql
# 安装(CentOS示例)
yum install percona-toolkit -y
# 分析慢日志并生成HTML报告(直观易读)
pt-query-digest --report-format html /var/log/mysql/mysql-slow.log > slow_query_report.html
# 分析最近1小时的慢日志
pt-query-digest --since '1 hour ago' /var/log/mysql/mysql-slow.log2.4 慢查询分析思路梳理
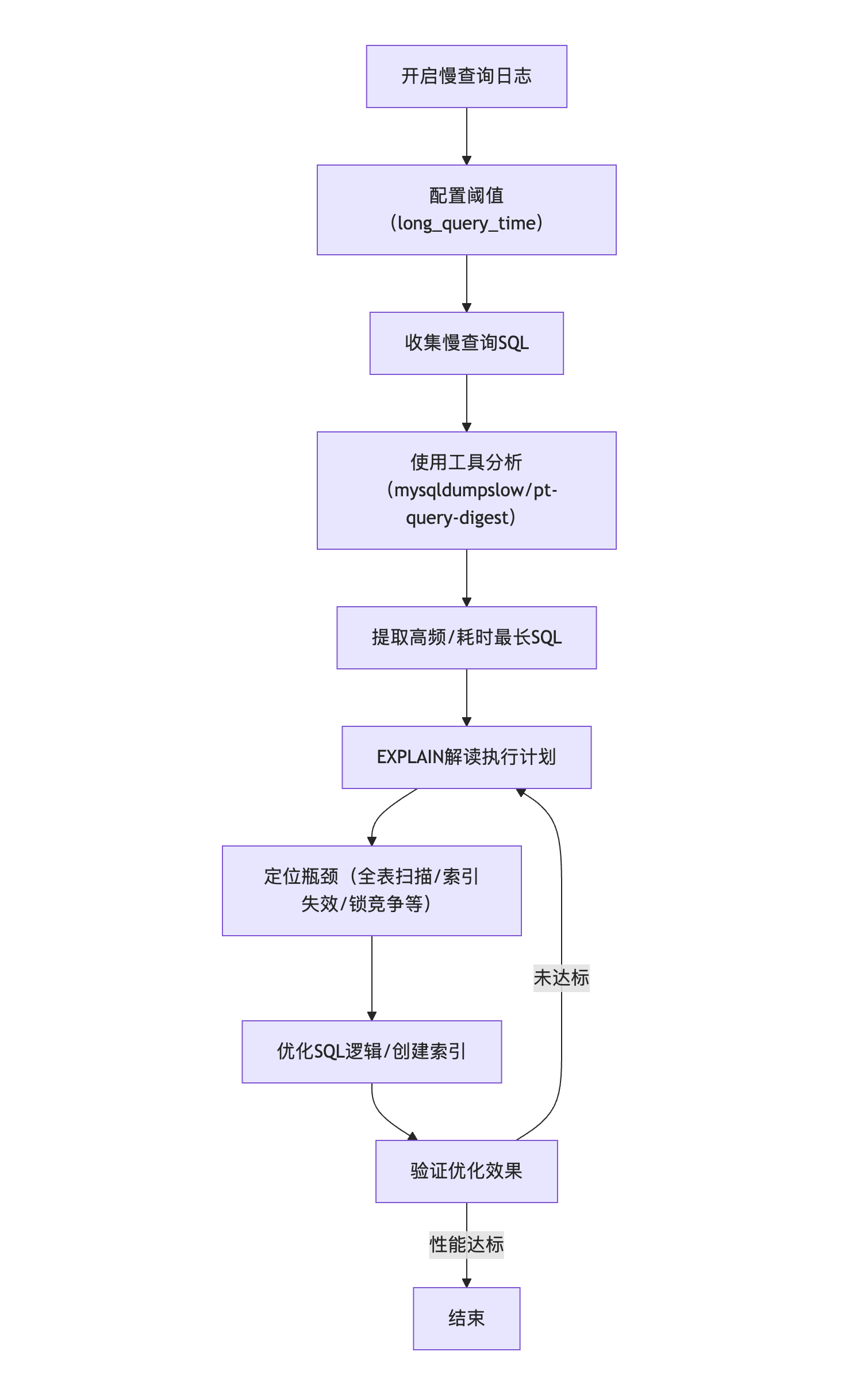
按"开启日志→收集分析→定位瓶颈→优化验证"的步骤,可精准解决慢查询问题。
三、实战拆解:移动代理商结算系统性能优化案例
某移动运营商代理商结算系统,核心功能是每月统计各代理商的业务量(话费充值、流量包销售等)并计算结算金额。随着代理商数量增长(5000+)和业务数据累积(3年历史数据,约1000万条),结算查询接口响应超时(超过5秒),财务人员无法正常对账。
3.1 案例核心表结构
sql
-- 1. 代理商信息表(agent_info):存储代理商基础信息
CREATE TABLE agent_info (
agent_id VARCHAR(20) PRIMARY KEY COMMENT '代理商ID',
agent_name VARCHAR(50) NOT NULL COMMENT '代理商名称',
region VARCHAR(30) NOT NULL COMMENT '所属区域',
status TINYINT NOT NULL COMMENT '状态:1-正常,0-冻结',
create_time DATETIME NOT NULL COMMENT '创建时间'
);
-- 2. 业务明细表(business_detail):存储每笔业务记录(核心大表)
CREATE TABLE business_detail (
id BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID',
agent_id VARCHAR(20) NOT NULL COMMENT '代理商ID',
product_id VARCHAR(20) NOT NULL COMMENT '产品ID(话费/流量包等)',
business_time DATETIME NOT NULL COMMENT '业务发生时间',
amount DECIMAL(10,2) NOT NULL COMMENT '业务金额',
status TINYINT NOT NULL COMMENT '业务状态:1-成功,0-失败'
);
-- 3. 结算规则表(settlement_rule):存储不同产品的结算比例
CREATE TABLE settlement_rule (
product_id VARCHAR(20) PRIMARY KEY COMMENT '产品ID',
settlement_ratio DECIMAL(5,2) NOT NULL COMMENT '结算比例(如0.05=5%)',
update_time DATETIME NOT NULL COMMENT '规则更新时间'
);
-- 4. 结算表(agent_settlement):存储每月结算结果
CREATE TABLE agent_settlement (
settlement_id BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '结算ID',
agent_id VARCHAR(20) NOT NULL COMMENT '代理商ID',
settlement_month VARCHAR(7) NOT NULL COMMENT '结算月份(如2025-11)',
total_business_amount DECIMAL(12,2) NOT NULL COMMENT '总业务金额',
settlement_amount DECIMAL(12,2) NOT NULL COMMENT '结算金额',
status TINYINT NOT NULL COMMENT '结算状态:0-未结算,1-已结算',
create_time DATETIME NOT NULL COMMENT '创建时间'
);3.2 问题定位:慢查询日志分析
通过开启慢查询日志,使用pt-query-digest分析后,定位到核心慢查询SQL:
sql
-- 财务对账时查询2025年11月未结算代理商的结算明细
SELECT
a.agent_id,
a.agent_name,
s.settlement_month,
s.total_business_amount,
s.settlement_amount,
COUNT(b.id) AS business_count
FROM agent_settlement s
INNER JOIN agent_info a ON s.agent_id = a.agent_id
INNER JOIN business_detail b ON s.agent_id = b.agent_id
INNER JOIN settlement_rule r ON b.product_id = r.product_id
WHERE s.settlement_month = '2025-11'
AND s.status = 0
AND DATE_FORMAT(b.business_time, '%Y-%m') = '2025-11'
AND b.status = 1
GROUP BY a.agent_id, s.settlement_month;慢查询核心指标
Query_time: 6.23s,Lock_time: 0.003s,Rows_sent: 120,Rows_examined: 185000
分析:Rows_examined(18.5万)远大于Rows_sent(120),说明存在大量无效扫描,需进一步用EXPLAIN分析执行计划。
3.3 执行计划分析(EXPLAIN解读)
对上述慢查询执行EXPLAIN,核心输出结果如下:
| id | select_type | table | type | possible_keys | key | rows |
|---|---|---|---|---|---|---|
| 1 | SIMPLE | s | ALL | NULL | NULL | 5000 |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 1 |
| 1 | SIMPLE | b | ALL | NULL | NULL | 180000 |
| 1 | SIMPLE | r | eq_ref | PRIMARY | PRIMARY | 1 |
EXPLAIN结果分析(瓶颈定位)
-
agent_settlement表(别名s):type=ALL(全表扫描),possible_keys和key均为NULL,无索引可用,需扫描5000行;
-
business_detail表(别名b):type=ALL(全表扫描),无索引可用,需扫描18万行(核心瓶颈);
-
agent_info和settlement_rule表:type=eq_ref,使用主键索引,性能正常。
3.4 优化方案落地
针对上述瓶颈,从"索引优化"和"SQL逻辑优化"两方面入手:
3.4.1 索引优化(核心解决全表扫描问题)
根据查询条件和关联条件,创建合适的索引:
sql
-- 1. 为agent_settlement表创建复合索引:结算月份+状态(查询条件)+代理商ID(关联条件)
CREATE INDEX idx_settlement_month_status_agent ON agent_settlement(settlement_month, status, agent_id);
-- 2. 为business_detail表创建复合索引:代理商ID(关联条件)+业务时间(查询条件)+状态(查询条件)
CREATE INDEX idx_agent_businesstime_status ON business_detail(agent_id, business_time, status);
-- 3. 说明:复合索引遵循"最左前缀原则",查询条件需包含索引前导字段才能命中索引3.4.2 SQL逻辑优化(避免函数操作导致索引失效)
原SQL中DATE_FORMAT(b.business_time, '%Y-%m') = '2025-11'对索引字段business_time使用函数,会导致索引失效,修改为范围查询:
sql
-- 优化后的SQL
SELECT
a.agent_id,
a.agent_name,
s.settlement_month,
s.total_business_amount,
s.settlement_amount,
COUNT(b.id) AS business_count
FROM agent_settlement s
INNER JOIN agent_info a ON s.agent_id = a.agent_id
INNER JOIN business_detail b ON s.agent_id = b.agent_id
INNER JOIN settlement_rule r ON b.product_id = r.product_id
WHERE s.settlement_month = '2025-11'
AND s.status = 0
AND b.business_time >= '2025-11-01 00:00:00' -- 范围查询,命中索引
AND b.business_time < '2025-12-01 00:00:00'
AND b.status = 1
GROUP BY a.agent_id, s.settlement_month;3.5 优化效果验证
3.5.1 EXPLAIN验证执行计划
优化后再次执行EXPLAIN,核心结果变化:
-
agent_settlement表:type=ref,key=idx_settlement_month_status_agent,rows=120(精准扫描未结算记录);
-
business_detail表:type=range,key=idx_agent_businesstime_status,rows=1500(范围扫描2025-11的业务数据);
3.5.2 性能指标对比
| 指标 | 优化前 | 优化后 | 优化效果 |
|---|---|---|---|
| Query_time | 6.23s | 0.08s | 提升78倍 |
| Rows_examined | 185000 | 1620 | 扫描行数减少99.1% |
| 接口响应时间 | 超时(>5s) | 0.12s | 正常响应,满足业务需求 |
3.6 优化总结
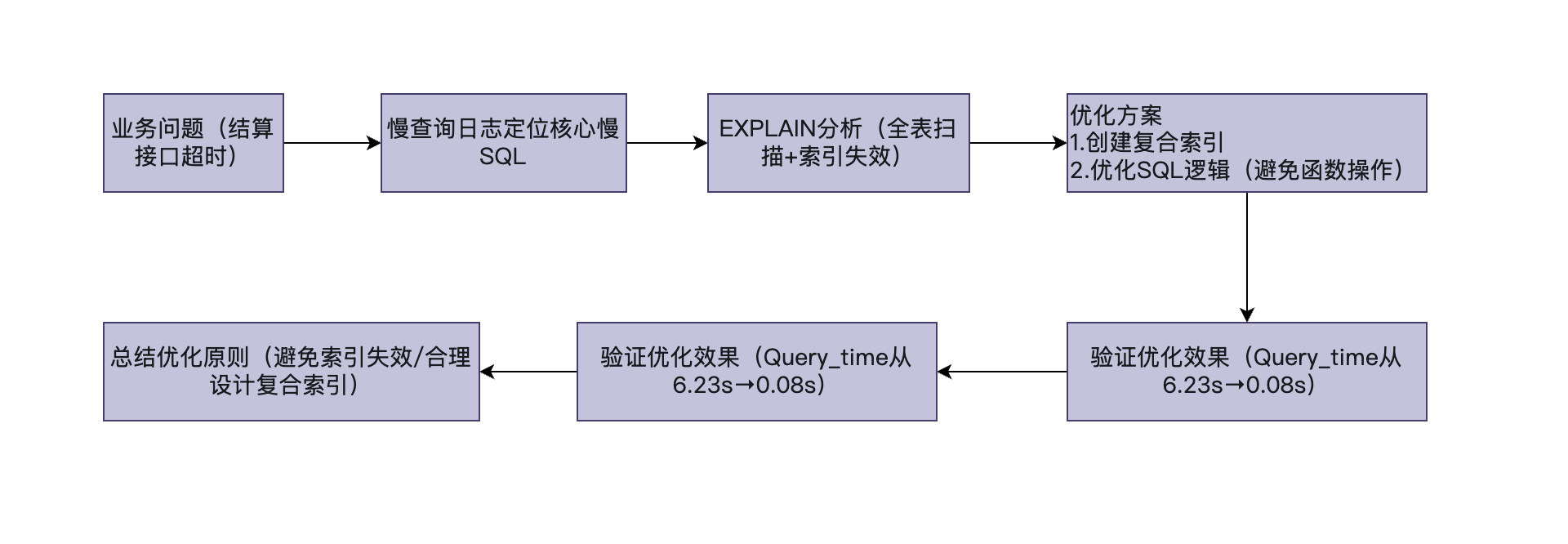
移动代理商结算系统的性能瓶颈源于"全表扫描"和"索引失效",通过"慢查询日志定位目标SQL"→"EXPLAIN分析执行计划找瓶颈"→"创建复合索引+优化SQL逻辑"的闭环流程,实现了性能的大幅提升。
核心原则:
-
避免对索引字段使用函数/表达式,防止索引失效;
-
多条件查询优先创建复合索引,遵循最左前缀原则;
-
大表关联查询需确保关联字段有索引,减少表扫描行数。
四、核心知识点梳理
-
EXPLAIN核心:关注type(访问方式)、key(实际索引)、rows(扫描行数),优先确保type≥ref;
-
慢查询日志:核心是正确配置阈值和存储路径,用工具(pt-query-digest)高效提取慢SQL;
-
优化核心思路:先定位(慢日志+EXPLAIN),再优化(索引优化+SQL逻辑优化),最后验证效果;
-
实战关键:复合索引的合理设计、避免索引失效场景(函数操作、隐式类型转换等)。