写在前面:本项目参考 7天用Go从零实现Web框架Gee教程,下面的内容全部参考自该网站。主要是记录我在学习过程中的所思所想,如有存在问题还请多多指教。
在 Day2 实现了 Context 之后,我们可以开始设计动态路由了,今天设计完成之后,Gee将具有解析动态路由的能力。
Trie 树简介
在之前的设计中,我们的路由是由一张路由表存储的,结构为:
go
type router struct {
handlers map[string]HandlerFunc
}索引非常高效,但是有一个弊端,键值对的存储的方式,只能用来索引静态路由。那如果我们想支持类似于/hello/:name这样的动态路由怎么办呢?所谓动态路由,即一条路由规则可以匹配某一类型而非某一条固定的路由。例如/hello/:name,可以匹配/hello/geektutu、hello/jack等。
实现动态路由最常用的数据结构,被称为前缀树(Trie树),也就是说每一个节点的所有子节点都拥有相同的前缀。这种结构非常适用于路由匹配,比如我们定义了如下路由规则:
- /:lang/doc
- /:lang/tutorial
- /:lang/intro
- /about
- /p/blog
- /p/related
我们用前缀树来表示,是这样的。
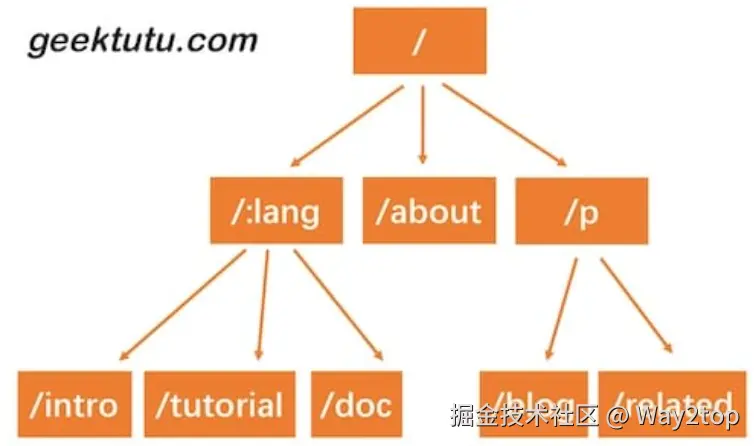
HTTP请求的路径恰好是由/分隔的多段构成的,因此,每一段可以作为前缀树的一个节点。我们通过树结构查询,如果中间某一层的节点都不满足条件,那么就说明没有匹配到的路由,查询结束。
接下来我们实现的动态路由具备以下两个功能。
-
参数匹配
:。例如/p/:lang/doc,可以匹配/p/c/doc和/p/go/doc。 -
通配
*。例如/static/*filepath,可以匹配/static/fav.ico,也可以匹配/static/js/jQuery.js,这种模式常用于静态服务器,能够递归地匹配子路径。
Tire 树实现
首先我们需要设计树上的每个节点应该存储的信息:
go
type node struct {
pattern string // 待匹配路由,录入 /p/:lang
part string // 路由中的一部分,例如 :lang
children []*node // 子节点,例如 [doc, tutorial, intro]
isWild bool // 是否精确匹配,part 含有 : 或 * 时为 true
}这四个值的含义值得说一下,这对于后续一些功能实现的逻辑理解有很大帮助。
首先,children 是最好理解的,它表示该节点的所有孩子结点。
接下来是 isWild。如果某个节点包含 : 或者 *,那么我们说它是的 isWild 为 true,代表可以进行模糊匹配。
然后是 pattern 和 part,这里结合例子具体说明这二者的含义。假设开发者准备注册一条 GET 路由:
css
r.GET("/p/:lang/doc", handler)此时服务刚启动,还没有注册任何路由,此时的 Tire 树:
ini
(root)
part="" // 根节点没意义
pattern="" // 不是路由
children=[] // 空接下来,"p/:lang/doc" 会被拆开,变为 "p", ":lang", "doc"。接下来开始往下构建 Tire树,最终,Tire 的结构如下:
ini
(root)
└── p
└── :lang
└── doc
part="doc"
pattern="/p/:lang/doc"注册完成后 Trie 的真实状态如下:
sql
节点 part pattern
--------------------------
p ""
:lang ""
doc "/p/:lang/doc"可以这么精炼总结 node 的 part 和 pattern:
- part :节点当前这一层对应的路径片段(Trie 树中每个节点的值),例如
/hello/:name中:name就是第二层节点的 part。 - pattern :完整路由,只有叶子节点才存,表示从根节点走到该节点对应的完整注册路径,例如
/hello/:name。
part 是当前节点的片段, pattern 是从根到该节点形成的完整路由(仅 叶子节点 存)。
接下来,我们要开始给 node 写一些方法了。
对于路由来说,最重要的当然是注册与匹配了。开发服务时,注册路由规则,映射handler;访问时,匹配路由规则,查找到对应的handler。因此,Trie 树需要支持节点的插入与查询。插入功能很简单,递归查找每一层的节点,如果没有匹配到当前part的节点,则新建一个,有一点需要注意,/p/:lang/doc只有在第三层节点,即doc节点,pattern才会设置为/p/:lang/doc。p和:lang节点的pattern属性皆为空。因此,当匹配结束时,我们可以使用n.pattern == ""来判断路由规则是否匹配成功。例如,/p/python虽能成功匹配到:lang,但:lang的pattern值为空,因此匹配失败。查询功能,同样也是递归查询每一层的节点,退出规则是,匹配到了*,匹配失败,或者匹配到了第len(parts)层节点。
go
func (n *node) insert(pattern string, parts []string, height int) {
// 如果当前结点的深度(height)恰好为 parts 的长度,那么说明 parts 已经走到最后一个路由了,直接将 pattern 赋值给当前节点的 pattern
if len(parts) == height {
n.pattern = pattern
return
}
// 如果 len(parts) != height,说明还没有遍历完parts,直接取出当前深度的路由 parts[height]
part := parts[height]
child := n.matchChild(part) // 返回 n 结点的孩子节点中和 part 匹配的节点;注意,这里的 n 的孩子结点实际上就是 height 这一层,不是 height+1 层
if child == nil {
child = &node{part: part, isWild: part[0] == ':' || part[0] == '*'}
n.children = append(n.children, child)
}
// 递归处理,直到 pattern 走到底
child.insert(pattern, parts, height+1)
}
func (n *node) search(parts []string, height int) *node {
// 如果 pattern 走到最后一个 part 了,或者当前节点的part以 * 为前缀
if len(parts) == height || strings.HasPrefix(n.part, "*") {
// 如果当前节点的 pattern 为空,说明不是合法路由,匹配失败
if n.pattern == "" {
return nil
}
// 如果 pattern 不为空,说明匹配成功
return n
}
// 如果 pattern 还没走完6
part := parts[height]
// 匹配所有匹配的节点并返回给 children
children := n.matchChildren(part)
// DFS:对每条可能路径继续往下试
for _, child := range children {
// 递归调用 search 来找出 child 下匹配的节点
result := child.search(parts, height+1)
if result != nil {
return result
}
}
return nil
}其中,matchChild 输入一个 part(路由中的一部分,例如 /p/python 中的 python),返回一个匹配的节点,matchChildren 则是返回所有匹配的节点:
go
// 输入一个 part(路由中的一部分,例如 /p/python 中的 python),返回一个匹配的节点
func (n *node) matchChild(part string) *node {
for _, child := range n.children {
if child.part == part || child.isWild {
return child
}
}
return nil
}
// 匹配算法,匹配孩子节点中所有可以匹配成功的节点(动态路由或者静态路由);这个主要用于查找
// 输入一个 part(路由中的一部分,例如 /p/python 中的 python),返回匹配的节点列表
func (n *node) matchChildren(part string) []*node {
nodes := make([]*node, 0)
for _, child := range n.children {
if child.part == part || child.isWild {
nodes = append(nodes, child)
}
}
return nodes
}Router
在实现了 Trie树的插入和查找之后,我们就可以把 Trie 树应用到路由中去了。我们使用 roots 来存储每种请求方式的 Trie 树根节点。使用 handlers 存储每种请求方式的 HandlerFunc。getRoute 函数中,还解析了 : 和 * 两种匹配符的参数,返回一个 map。
例如/p/go/doc匹配到/p/:lang/doc,解析结果为:{lang: "go"},/static/css/geektutu.css匹配到/static/*filepath,解析结果为{filepath: "css/geektutu.css"}。
go
package gee
import (
"net/http"
"strings"
)
type router struct {
roots map[string]*node
handlers map[string]HandlerFunc
}
// roots key eg, roots['GET'] roots['POST']
// handlers key eg, handlers['GET-/p/:lang/doc'], handlers['POST-/p/book']
func newRouter() *router {
return &router{
// roots 的 key 是请求方式,值是具体的请求路径
// eg: key = "GET", value = *node(Trie树的根节点,下面挂路径段)
roots: make(map[string]*node),
// handlers 的 key 是查找 handler 的唯一标识
// eg: key = "GET-/user", value = HandlerFunc (真正执行的函数)
handlers: make(map[string]HandlerFunc),
}
}
// parsePattern 只做一件事:把路径字符串转化为 parts 数组(例如,"/p/:lang/doc" → ["p", ":lang", "doc"])
func parsePattern(pattern string) []string {
vs := strings.Split(pattern, "/")
parts := make([]string, 0)
for _, item := range vs {
if item != "" {
parts = append(parts, item)
//parsePattern 中遇到 * 就 break,是因为 * 表示"匹配剩余所有路径",逻辑上不允许再有更深的路由层级。
// 举个例子,开发者设计了路由 /static/*filepath
// 假设这里遇到了 * 并且不 break,会发生什么?比如设计了 /static/*filepath/abc
// 如果不 break,会得到 ["static", "*filepath", "abc"]
// 那么当一个真实的请求来了的时候,例如 /static/css/main.css
// 你希望 *filepath = "css/main/css"
// 但是如果 Trie 里还有一层 "abc",那意味着你既让 *filepath 吃掉剩余所有路径,又要求后面必须再匹配 "abc",这在语义上是自相矛盾的
// 一句话总结就是,* 不是模糊匹配一个节点,而是终止 Trie 深度的兜底规则
// : 和 * 是不同的,: 是吃一段,* 是吃剩下所有段
// : 是占一个坑,* 是兜底首尾
if item[0] == '*' {
break
}
}
}
return parts
}
// 注册路由
func (r *router) addRoute(method string, pattern string, handler HandlerFunc) {
parts := parsePattern(pattern)
key := method + "-" + pattern
_, ok := r.roots[method]
if !ok {
r.roots[method] = &node{}
}
r.roots[method].insert(pattern, parts, 0)
r.handlers[key] = handler
}
// getRoute 输入请求方式和路径,返回匹配到的路由节点及 params
func (r *router) getRoute(method string, path string) (*node, map[string]string) {
// 资源路径 pattern 被拆分为 parts(例如,"/p/:lang/doc" → ["p", ":lang", "doc"])
searchParts := parsePattern(path)
params := make(map[string]string) // params 记录的就是动态路由匹配出来的参数,也就是 path 里 :name 或 *filepath 对应的实际值。
root, ok := r.roots[method] // 仅仅判断开发者有没有给该请求方法注册路由,例如有没有给 GET/POST 请求注册过路由
// 如果连这个请求方法都没注册过,直接返回 nil
if !ok {
return nil, nil
}
// 如果注册过,接下来就开始正式进行动态路由匹配
n := root.search(searchParts, 0)
// n != nil 说明匹配到了路由
if n != nil {
// 匹配到了之后,把匹配到的 pattern 先解析为 parts
parts := parsePattern(n.pattern)
// 然后遍历解析后的 parts,去判断是不是动态参数(:) 或者通配符(*)
for index, part := range parts {
// 如果遇到路由以 : 开头,说明这部分是动态匹配的
// 例如 :name,取掉冒号 part[1:] -> "name",
if part[0] == ':' {
params[part[1:]] = searchParts[index]
// params["name"] = "way2top"
// params 的 key 是动态路由取掉冒号,value 是实际的路由
}
// 如果是 *,那么把剩下所有的路径拼成一个字符串写入 params
if part[0] == '*' && len(part) > 1 {
params[part[1:]] = strings.Join(searchParts[index:], "/")
break
}
}
return n, params
}
return nil, nil
}
// 根据 Context 查找 handler 并调用
func (r *router) handle(c *Context) {
// n 是前缀树中匹配到的路由节点,例如请求 "/hello/way2top" 匹配到注册路由 "/hello/:name"
// params 是具体的匹配值,例如 { "name": "way2top" }
n, params := r.getRoute(c.Method, c.Path)
if n != nil {
c.Params = params
key := c.Method + "-" + n.pattern
r.handlers[key](c)
} else {
c.String(http.StatusNotFound, "404 NOT FOUND: &s\n", c.Path)
}
}Context 与 handle 的变化
在 HandlerFunc 中,希望可以访问到解析的参数,因此,需要对 Context 增加一个属性和方法,来提供对路由参数的访问。我们将解析后的参数存储到 Params 中,通过 c.Param("lang") 的方式获取到对应值。
go
type Context struct {
Writer http.ResponseWriter
Req *http.Request
Path string // 请求资源路径
Method string // 请求方式
Params map[string]string // 提供对路由参数的访问(router.go 中的 getRoute 返回的 params 就存储在这里)
StatusCode int // 状态码
}
// Param 可以取出 Context 中的 Params 的值,传入对应的 key 返回 Params[key]
func (c *Context) Param(key string) string {
value, _ := c.Params[key]
return value
}实际上,在 router.go 下的 getRoute 返回的 params 就存储在 Context.Params 中。
实现了这些之后,就可以修改框架的使用样例,来测试动态路由功能了:
javascript
// main.go
func main() {
r := gee.New()
r.GET("/", func(c *gee.Context) {
c.HTML(http.StatusOK, "<h1>Hello Gee</h1>")
})
r.GET("/hello", func(c *gee.Context) {
// expect /hello?name=geektutu
c.String(http.StatusOK, "hello %s, you're at %s\n", c.Query("name"), c.Path)
})
r.GET("/hello/:name", func(c *gee.Context) {
// expect /hello/geektutu
c.String(http.StatusOK, "hello %s, you're at %s\n", c.Param("name"), c.Path)
})
r.GET("/assets/*filepath", func(c *gee.Context) {
c.JSON(http.StatusOK, gee.H{"filepath": c.Param("filepath")})
})
r.Run(":9999")
}测试结果如下:
bash
Gee on main via v1.24.3
❯ curl http://localhost:9999/
<h1>Hello Gee</h1>%
Gee on main via v1.24.3
❯ curl http://localhost:9999/hello
hello , you're at /hello
Gee on main via v1.24.3
❯ curl http://localhost:9999/hello/way2top
hello way2top, you're at /hello/way2top
Gee on main via v1.24.3
❯ curl http://localhost:9999/assets/go
{"filepath":"go"}
Gee on main via v1.24.3
❯ curl http://localhost:9999/assets/go/goroutine
{"filepath":"go/goroutine"}对于前三天的内容,我们总结一下。
Gee 框架从最底层的 HTTP 请求模型出发,首先通过让 Engine 实现 http.Handler 来统一接管所有进入服务的请求,解决"请求从哪里进来、由谁负责处理"的问题;随后引入 Context,将原本零散的 http.Request、ResponseWriter、路径、方法、状态码以及响应构造逻辑全部收敛到一次请求对应的对象中,使 Handler 只关心"业务表达"而不再关心 HTTP 细节;在此基础上,为了解决静态路由无法表达真实业务路径的问题,引入基于 Trie 的路由系统,将路径按段拆分为节点,用 part 表示当前节点的匹配规则,用 pattern 仅在完整路由处标记"这是一条可被命中的路由",从而在请求到来时完成路径匹配、动态参数解析,并将解析结果写入 Context.Params,最终使一次请求在进入 Handler 之前,就已经完成了方法分发、路由定位和参数绑定,形成了一条清晰、可扩展、职责分离的请求处理链路。
下面附上数据流:
scss
HTTP 请求
↓
Engine.ServeHTTP
↓
new Context(一次请求一个)
↓
Router.getRoute(Trie 匹配 + 参数解析)
↓
Context.Params 填充
↓
HandlerFunc(c)