Golang 切片 (Slice) 底层机制核心剖析
1. 核心数据结构
切片本身并不存储数据,而是底层数组的一个"视图"或描述符。其底层结构(reflect.SliceHeader)仅占用 3 个机器字长(64位系统为24字节):
-
Data(指针) :指向底层数组中切片起点的真实内存地址。
-
Len(长度) :切片当前可访问的有效元素个数。
-
Cap(容量) :底层数组从 Data 指针位置开始,到其物理空间末尾的总容量。
2. Len 与 Cap 的设计哲学
相比较于C语言的数组,为什么golang中还有len和cap的说法,既然底层已经占据了cap的内存,len不是多此一举吗?
分离 Len 与 Cap 的核心目的是兼顾性能 与安全:
-
Cap (性能缓冲) :用于向操作系统"批发"内存。避免频繁的
append操作每次都触发高昂的系统调用和内存分配(平摊开销)。 -
Len (语义与安全) :划定有效数据的逻辑边界。拦截对已分配但未初始化(或已废弃)内存区域的访问,防止脏数据泄漏。
3. 切片表达式与底层坐标系
在表达式 arr[low : high : max] 中,三个参数均代表相对于原数组的物理索引,而非直接的长度或容量数值。
-
指针偏移 :新切片的
Data指针指向arr[low]。low之前的元素从新切片的视野中被永久剥离。 -
长度计算 :
Len = high - low -
容量计算 :
Cap = max - low(max绝对不能超过原底层数组的最大容量)
应用场景 :完整切片表达式主要用于内存隔离 ,限制切片的 Cap,强制其在未来 append 时触发扩容,从而避免意外覆盖底层数组中的后续数据。
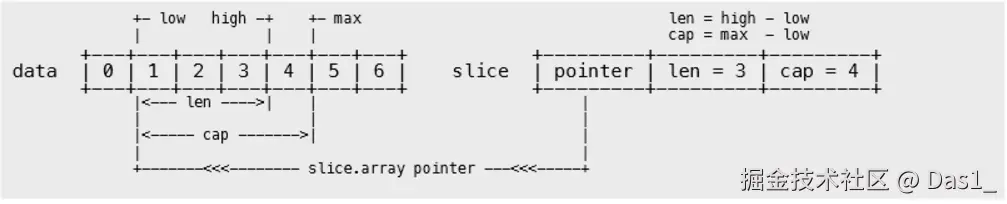
对于max的理解
max实际上是一个相对于原数组的索引,表示slice在原数组上的最大右边界索引,而不是直接指定新切片的容量数字。
写 arr[1:4:7] 时,底层其实是在说:"把索引 1 作为起点,索引 4 作为当前视口的终点,并且把索引 7 作为底层物理空间的绝对禁区(不能达到或越过索引 7)
ini
var arr = [...]int{0, 1, 2, 3, 4, 5, 6}
slice1 := arr[1:4:5] // 左闭右开区间,最大容量为 5
// slice1 => [1 2 3]
fmt.Println(slice1)
slice2 := arr[1:4:7]
// high <= max <= cap 虽然 1 + 7 = 8 > 7=cap,但是这里不会报错
// slice2 => [1 2 3]
fmt.Println(slice2)4. 扩容机制 (Append)
切片长度增加时存在两种截然不同的物理行为:
-
假扩容(在 Cap 范围内) :底层不分配任何新内存。切片仅仅是向后推移其右边界(
Len增加),占用底层数组中预留的Cap空间,原地写入新数据。 -
真扩容(超出 Cap) :触发内存重分配。Runtime 申请一块全新、更大的连续内存,将旧底层数组的数据全量拷贝至新内存,追加新元素,最后将切片的
Data指针修改为指向新内存(旧数组无引用后被 GC 收回)。
当真扩容发生时,slice追加的数组超出了原数组的cap,go内部创建一个新的数组,此时该slice的引用地址不再是arr
scss
var arr = [...]int{1, 2, 3, 4}
fmt.Println(arr) //[1 2 3 4]
slice1 := arr[:]
fmt.Println(slice1) //[1 2 3 4]
slice1 = append(slice1, []int{5, 6, 7}...)
fmt.Println(slice1) //[1 2 3 4 5 6 7]
slice1 = append(slice1, 8)
slice1[0] = 888
fmt.Println(slice1) // [888 2 3 4 5 6 7 8]
fmt.Println(arr) // [1 2 3 4]而假扩容时,则仍是在原数组上进行追加而已
ini
var arr = [6]int{1,2,3,4}
fmt.Println(arr) //[1,2,3,4,0,0]
slice := arr[:4]
fmt.Println(slice) //[1,2,3,4]
slice = append(slice,5)
fmt.Println(arr) //[1,2,3,4,5,0]
fmt.Println(slice) //[1,2,3,4,5]5. 参数传递机制:为何能修改原数组?
Go 语言所有参数传递均为严格的值传递(拷贝) 。
-
数组传参:拷贝整个数组的全部元素(全量复印)。在函数内修改副本,原数组毫无影响。
-
切片传参 :仅拷贝
SliceHeader(指针、Len、Cap 的拷贝)。-
表现为"引用"的根本原因:复印件中的
Data指针与原件指向同一块底层数组内存。因此修改元素会穿透到原数组。 -
核心陷阱 :在函数内对切片执行
append,虽然可能修改底层数据,但无法改变外部切片的Len和Cap(因为修改的是副本里的字段)。若触发了"真扩容",内部切片将指向新数组,与外部彻底脱轨。
-
简单来说:- 因为切片是个引用类型,所以它作为参数传递给函数,函数操作的实质是底层数组
go
func main() {
var slice = make([]int,3,5) //len=3,cap=5
fmt.Println(slice) //[0,0,0]
slice2:=slice[:5] //slice实现了对slice的扩容,切片长度变为5
fmt.Println(slice2) //[0,0,0,0,0]
slice[0] = 999 //这里slice和slice的index=0位置都是999 因为他们引用的底层数组的index=0位置都是999
fmt.Println(slice)
fmt.Println(slice2)
AddOne(slice) //[8888,0,0]
fmt.Println(slice) //[8888,0,0]
fmt.Println(slice2) //[8888,0,0,0]
}
func AddOne(s []int){
s[0] = 8888
fmt.Println(s)
}6. 对于slice 的 slice
在 Go 语言中,每一次切片操作都会建立一个 "全新的相对坐标系" 。当你对一个 slice 再次进行切片时,所有的索引(low、high、max)都是基于当前这个 slice 的起点(索引 0) 来计算的,它根本不关心最底层的数组是从哪里开始的。
ini
var arr = [...]int{0, 1, 2, 3, 4, 5, 6}
slice1 := arr[1:4:5] // 左闭右开区间,最大容量为 5
// slice1 => [1 2 3]
slice3 := slice1[1:3:4]
fmt.Println(slice3)
// slice3 => [2 3] 这里的从slice[1]开始
slice4 := slice1[1:4]
// slice4 => [2 3 4]
fmt.Println(slice4)