在国内,懂技术 ------ 尤其是 AI 技术的年轻人,真的不缺崭露头角的机会。
前段时间,2025 年腾讯广告算法大赛结果揭晓,前 10 名队伍的全部成员都拿到了腾讯的录用意向书,冠军还拿到了 200 万元巨额奖金。

当时,看完选手们的答辩,腾讯公司副总裁蒋杰感慨地说,这届年轻人的知识储备令人惊叹,他们做出来的东西和工业界的实际工作非常接近,没有代差。
如果说大赛考的是一个已经被工业界解决的问题,选手们查查论文、复现方案,拼拼工程把问题解决掉倒也不是什么新鲜事。但看过今年赛题的人都知道,这次摆在桌面上的,是一个仍在探索中的真实难题,没有现成答案,也不存在所谓「最优解」。
也正因如此,比赛真正精彩的部分,其实不在排名本身,而在于:这道题究竟难在哪里?工业界已经做了些什么?而这些年轻人,又给出了哪些实用的解法?
在这篇文章中,我们将结合冠亚军团队的解决方案,来详细聊聊这些问题。
广告推荐
从来不是一件简单的事
一提到广告,很多人都会下意识皱眉。这种情绪其实很正常,没有人喜欢被无关的信息打断。但换个角度看,今天我们习以为常的很多内容和服务之所以能够长期、稳定地存在,本身就离不开广告的支撑。
也正因如此,平台真正想做的,并不是把更多广告塞给用户,而是尽量让广告「少出现一点、对一点」。只有把广告在合适的时间,推给真正可能需要的人,才能减少无效曝光,也减少对其他人的打扰。腾讯广告算法大赛所讨论的,正是如何把这件事做得更克制、更聪明。
在业界,目前主要有两种方法在 PK。一种是已经用了很多年的判别式方法,另一种是最近两三年兴起的生成式方法。
要理解两种方法的差异,我们可以举个例子:假设你是一个新来的班主任,想要根据小明同学的兴趣给他推荐合适的课外书。
在传统的判别式方法里,你的任务很明确:不是理解小明的成长过程,而是判断「这本书适不适合他」。学校会给你一张小明的档案表,以及一张馆藏书单。档案表上记录的是一系列已经被「统计好」的特征,你需要做的,是把这些特征代入模型,给每一本书算一个匹配分数,然后按分数高低排序。

而按照最近兴起的生成式方法,学校换了一种要求。不再让你给书打分,而是直接把小明过去一整年的借阅「流水账」交给你,让你去发现其中的规律,并预测:接下来最可能发生的那一次借书,会是什么样子。

后一种方法之所以兴起,是因为前一种方法在研究多年之后,遇到了很难克服的瓶颈。
从例子里可以看出,传统判别式方法,更像是把小明压缩成一张「人设表」,在书和人之间算匹配度,然后用一种级联的「漏斗」去筛选。这种方式在早期非常有效,但后来,随着系统不断加入新的手工特征、更多统计维度、更复杂的级联模型,效果提升却越来越有限,尤其是在冷启动方面。
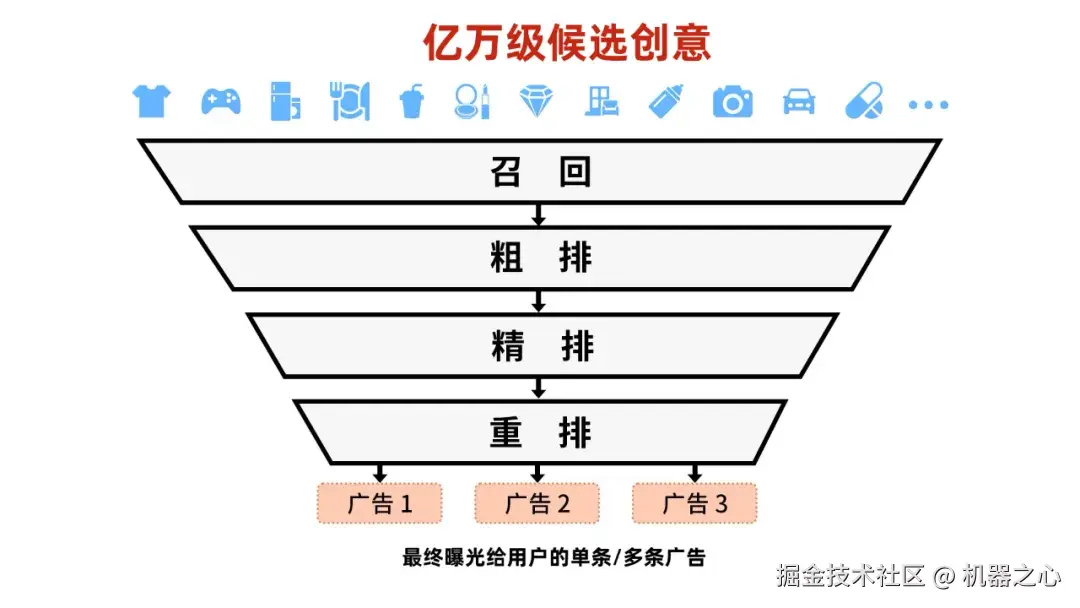
传统判别式方法的级联架构,像漏斗一样对广告层层筛选。
原因并不是工程师不努力,而是这种范式本身就存在很大的局限,包括特征挖掘遇上天花板,模型架构无法有效建模世界知识、推理用户意图、吸收多领域多模态用户行为信息,级联架构把目标拆碎并带来误差累积等。这就造成一个局面:算法工程师已经很难通过简单地增加特征或扩大现有模型规模来获得预期效果。
而生成式方法换了一种思路。它不急着给小明下结论,而是直接看他一整段时间的借阅记录,去理解兴趣是如何变化的,并顺着这个过程,预测「下一步最可能发生什么」。
对应到广告场景里,这意味着系统不再只判断「点不点」某个广告,而是尝试回答:在此时此刻,这个人最不反感、也最可能有用的广告,会是什么。
生成式模型本身的一些特质,使得它们擅长回答这类问题,包括处理长时间跨度的行为序列的能力,可以直接利用大模型中已经学到的世界知识和多模态先验等。
腾讯广告算法大赛所关注的,正是这一代方法,而且考虑到多模态信息在此类场景中的重要性,他们把赛题确定为「全模态生成式推荐」。

目前,业界已经涌现出了一些优秀工作,有些成功地将传统级联架构中的某个组件替换为了生成式模型,比如 Google TIGER、Meta HSTU;还有些探索了端到端的生成式推荐,比如快手的 OneRec、腾讯的单模型框架 GPR。值得注意的是,HSTU 首次在推荐中观察到了 Scaling Law,这说明推荐系统也可以「吃到 scaling 的红利」。
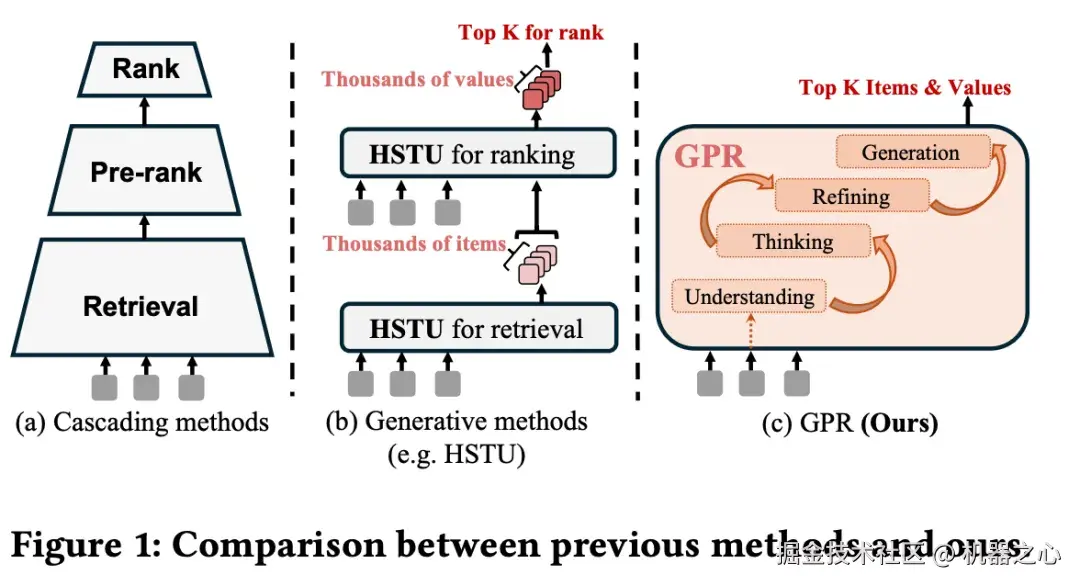
传统级联方法、用生成式模型替代部分组件的方法以及端到端生成式方法(腾讯 GPR)对比图。图源:arxiv.org/pdf/2511.10...
不过,这一领域依然存在很多挑战,比如工业级动态词表带来的训练 / 推理双重爆炸、毫秒级延迟与巨量算力的矛盾、大尺寸模型性能尚未得到充分验证等。
就是在这样的探索阶段,选手们拿到了这个赛题。对于没有接触过广告业务的他们来说,这个赛题极具挑战性。
首先从数据规模来看,赛题对应的是超大规模数据场景:涉及千万级广告、千万级用户,以及同样规模的交互序列,但可用于训练的计算资源却是有限的,这要求模型在效果与效率之间做出权衡。
其次,数据本身的结构也非常复杂。选手拿到的是经过脱敏处理的用户全模态历史行为数据,包含文本、图像以及用户与广告之间的协同行为信息,同时还存在特征缺失、行为序列时间跨度大的问题,需要在不完整信息下建模长期与短期行为。
在任务层面,复赛赛题并非单一目标优化,而是同时涉及曝光、点击与转化等多个隐式目标,并且存在近半数的冷启动 item,这进一步提高了建模难度。
接下来我们就看看,本届大赛的冠亚军团队是怎么解决这些问题的。
冠军 Echoch:让推荐系统真正理解
用户「此时此刻」想要什么
冠军 Echoch 团队由来自华中科技大学、北京大学、中国科学技术大学的同学组成。在答辩中,他们从特征工程、模型设计、语义 ID、训推加速四个角度介绍了自己的方案。

三级会话体系 + 周期编码 + 时间差分桶:让模型拥有节奏感
同一个行为,在不同时间和状态下,含义可能完全不一样。比如同样是点一个广告,早上看到可能是随便点点,晚上可能更容易下单;5 分钟前点过一双鞋可能是刚感兴趣,3 天前点过的鞋可能已经不喜欢了。所以 Echoch 团队努力去解决的第一个大问题是:如何让推荐系统拥有「时间感」和「节奏感」,知道用户「此时此刻」处于什么状态。
为了解决这个问题,他们提出了三种方法,从不同角度来描述用户行为的特征,分别是:三级会话体系、周期编码和时间差分桶。
所谓的三级会话体系如下图所示,它解决的问题是怎么组织用户的各种行为:是刚点开,随手划两下;还是已经刷了一会儿,兴趣在变化;还是之前刷过,现在又回来刷了。这样的区分有助于系统判断「用户现在想干嘛」,从而决定推荐的时机和节奏。

而周期编码的作用则是找到时间点的规律,让模型感知此刻是用户常刷的高峰期,还是偶尔点开的空档,从而决定推荐的内容类型。时间差分桶是为了让模型分清「新鲜度」,即某个商品是「刚刚感兴趣」还是「早就看过」,从而决定历史行为的参考权重。
这几个维度的信息叠加在一起,可以让推荐系统既贴着用户的作息周期,又更好地把握新鲜度和轰炸感,在合适的时间推合适的内容。
点击和转化:一个模型,两套策略
到了复赛阶段,大赛的规则其实发生了一些变化:在初赛中,选手们只需要预测「点击」行为;但到了复赛,他们需要同时预测「点击」与「转化」两种行为。
这就带来了一个问题:两种行为的目标与权重差异巨大,但模型只能生成一个统一的用户画像,推荐时左右为难。
对此,Echoch 团队给出的解决方案是让同一个模型,能根据「想让用户点击」还是「想让用户购买」自动切换推荐策略,而不是一套画像硬撑两个目标。
除此之外,他们在模型设计层面还发现了一个问题,就是用 HSTU 作为基座模型会遇到显存瓶颈和性能瓶颈。经过调查,他们发现这个问题的本质是 HSTU 需要靠「外挂补丁」去了解时间和行为信息,这样不但显存和计算成本很高,效果也开始停滞。于是,他们把基座模型换成了 LLM,因为 LLM 天生就有一个叫 RoPE 的位置编码机制,就像自带了「时间感」,这样时间和行为就不再是负担。结果不仅线上得分提升不少,显存占用也减少 5G 左右。
引入随机性,让冷门广告也有曝光机会
对于 Echoch 团队来说,语义 ID 层面的核心问题在于:用传统的聚类方法给广告编号,热门广告占据了大部分「好位置」,冷门广告被挤到角落,几乎没有被推荐的机会。
对此,他们给出的解法是:在编码的最后一层,故意引入一些随机性,让码表使用更均匀,从而让更多广告能被模型真正看到、参与训练。这种方法效果显著:长尾物品训练关注度提升了 190 倍,码表利用率从 81.2% 提升至 100%,Gini 系数(衡量曝光分布的不平等程度的指标)从 0.53 降至接近于 0。
引入 Muon 优化器,训练又快又稳定
前面提到,HSTU 首次证明,推荐系统也能吃到 scaling 的红利。但对于选手来说,训练更大的模型却没有那么容易,因为他们可以调动的计算资源是有限的。模型一大就面临显存不够用、训练不稳定的问题。
为了不在模型规模上妥协,Echoch 引入了 Muon 优化器。与需要为每个参数额外存储 2 份历史信息的 AdamW 相比,Muon 通过 Newton-Schulz 迭代把梯度矩阵变成正交矩阵,省掉了记录二阶动量的显存开销,显存占用实测锐减 45%,收敛速度提升 40%。
亚军 leejt:大数据,大模型
scaling is all you need
亚军 leejt 团队成员来自中山大学。在答辩中,他们从数据处理、模型训练、模型推理与后训练等几个角度介绍了自己的方案。

共享词表 + 哈希编码:巧妙处理超大规模数据
和 LLM 一样,全模态生成式广告推荐的底层逻辑也是 next-token 预测,但两者面对的 token 世界规模完全不同。语言模型的词表只有十几万,而且是静态的;而在广告推荐中,如果把每个广告都视作一个 token,词表规模会迅速膨胀到千万甚至上亿级。即便在比赛这种受控环境下,广告数量也超过了 1800 万。如果为每个广告分配独立的嵌入向量,显存很快就会爆掉。
因此,leejt 团队在数据处理阶段做的第一件事,就是压缩词表规模。他们发现,接近一半的广告交互频次极低,既难以学到稳定表示,又大量消耗显存,于是将这些低频广告映射到共享词表中;同时再通过 ID 哈希,把原始广告 ID 压缩成更紧凑的表示。这两步基本解决了模型「训不起来」的问题。
此外,这里还涉及对多模态特征的取舍与压缩。面对维度极高、噪声较重的多模态向量,leejt 并没有选择直接堆进模型,而是先用 SVD 做降维去噪,再通过 RQ-KMeans 将连续向量离散为语义 ID(SID),把高维连续空间压缩成可控的离散表示。与此同时,对于缺失率高、线下验证效果不佳的模态特征,他们选择直接舍弃,而不是让模型为低质量信息付出建模成本。
session 划分 + 异构时序图:数据脏乱差也不怕
除了数据规模,真正让团队感到棘手的,还有数据本身的复杂性。
用户行为序列看似很长,但仔细分析会发现,很多序列其实是多个 session 拼接而成,如果不显式建模 session 边界,模型会把跨天、跨兴趣阶段的行为当成连续偏好来学,噪声极大;此外,大量商品是冷启动或低频,同时多模态特征维度高、缺失多、噪声重,如果直接输入模型,只会放大不确定性。
leejt 给出的解法是:主动补充序列之外的信息结构。一方面,他们通过时间特征和 session 划分,让模型知道哪些行为是「刚刚发生的」,哪些只是历史残留;另一方面,他们引入了异构时序图,把用户、广告以及语义层面的节点连接在一起。当某个用户或广告自身信息不足时,模型可以通过与其相邻的用户、相似广告和语义簇来「借信号」,用群体行为来弥补个体数据的稀疏。这一步的本质,是把原本只能在一条序列上盲猜的问题,转化成在一个关系网络中有依据地推断。
极致的工程优化:把 GPU 利用率拉到 100%
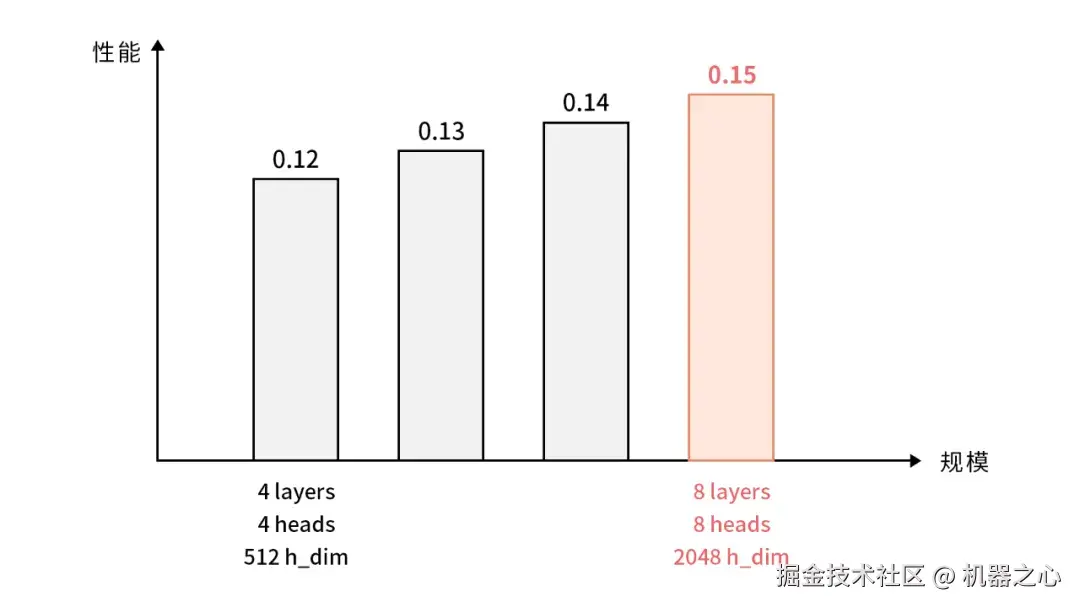
和 Echoch 团队一样,在有限的算力上训出更大更有效的模型也是 leejt 团队的核心目标。这方面,他们确实做得很成功,把模型从 4 层 512 维扩展到 8 层 2048 维,带来了百分位级别的性能提升。
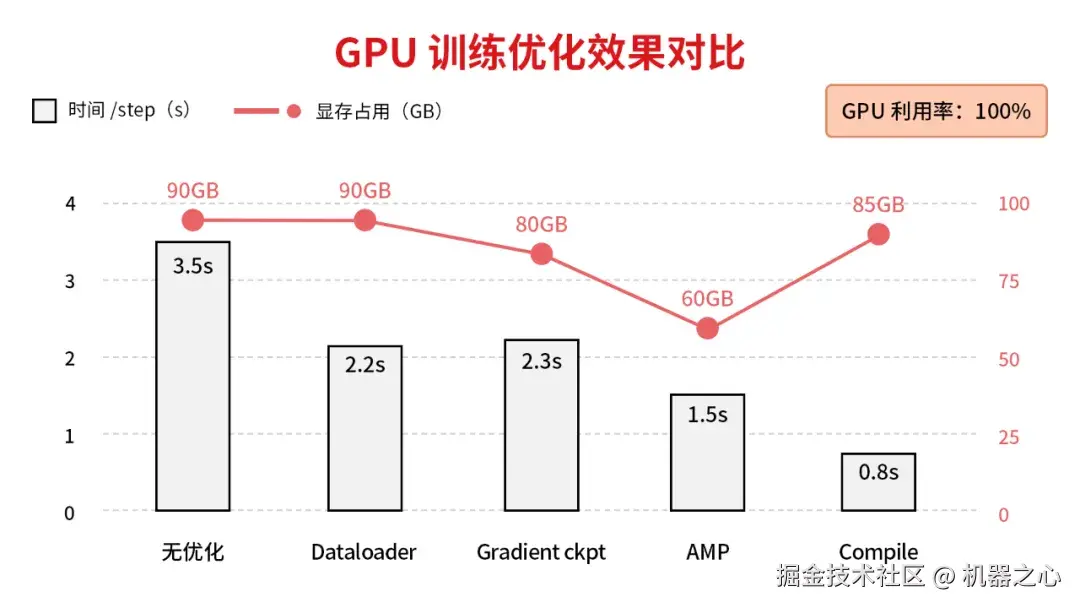
团队的解法是从多个环节挤出效率空间:混合精度训练、梯度检查点、torch.compile 图编译,以及把所有数据预处理都放进 Dataloader 里让数据加载和模型计算完全并行。这套方法效果显著:每步训练时间从 3.5 秒压缩到 0.8 秒,GPU 利用率拉满到 100%,省下来的时间和空间全部用来把模型做大做深,最终验证了团队的核心信念 ------Scaling is all you need。
腾讯广告算法大赛
让技术理想照进现实的起点
从这次比赛来看,全模态生成式广告推荐确实不是一个简单的问题。但年轻一代给出了非常有价值的思路。这些方案既有扎实的工程功底,也有对问题本质的深刻理解。
从业界实践来看,从判别式到生成式的演进正在平稳推进。蒋杰提到,腾讯内部已经尝试在召回和粗排阶段用生成式模型替代传统的判别式模型,并且取得了不错的效果,这些收益在财报的营收数据上也有所体现。这说明生成式推荐不只是学术界的热门话题,而是真正能落地、能创造商业价值的技术方向。
为了适应这种趋势,腾讯广告内部也在积极布局。蒋杰提到,未来,他们的数据将全面多模态化,内部广告系统也将全面 Agent 化。同时,为了支持整个社区的发展,腾讯广告会将本次大赛的数据开源,让更多研究者和开发者能够在真实场景的数据上探索和验证自己的想法。
而生成式广告推荐的想象空间,其实远超这次大赛所考察的范围。比赛关注的还是「从候选池里挑出最合适的广告」,但未来可能出现即时生成的广告 ------ 不再是从现有素材中检索,而是根据用户当下的兴趣、场景、情绪,实时生成个性化的广告文案、图片甚至视频。到那时,「千人千面」才算真正名副其实。
当然,这中间还有很多技术难点需要克服。腾讯广告算法大赛,正是这样一个让技术理想照进现实的起点。
期待明年还能看到如此精彩的赛事。