Qwen3-8B vLLM 部署实践教程(AutoDL 平台)
实践日期 :2025年12月23日 vLLM 版本 :0.8.5.post1 模型 :Qwen3-8B 平台 :AutoDL(RTX 4090 24GB) 参考教程 :github.com/datawhalech...
目录
1. 项目概述
1.1 什么是 vLLM?
vLLM(Vectorized Large Language Model)是一个高性能的大语言模型推理引擎,由加州大学伯克利分校开发。
vLLM 的核心优势
| 特性 | 说明 |
|---|---|
| PagedAttention | 创新的注意力机制,显著减少显存占用 |
| 高吞吐量 | 比 Hugging Face Transformers 快 10-24 倍 |
| OpenAI 兼容 API | 可以直接替换 OpenAI API,无需修改代码 |
| 连续批处理 | 自动合并多个请求,提高 GPU 利用率 |
1.2 什么是 Qwen3-8B?
Qwen3-8B 是阿里云通义千问团队发布的第三代大语言模型,拥有 80 亿参数。
Qwen3 的特色功能
- 思考模式(Thinking Mode):模型会先进行推理思考,再给出答案
- 多语言支持:支持中文、英文等多种语言
- 长上下文:支持 32K 甚至更长的上下文窗口
1.3 为什么选择 AutoDL?
| 平台 | 优势 | 劣势 |
|---|---|---|
| Google Colab | 免费、易用 | vLLM 多进程不兼容 |
| AutoDL | 国内访问快、按小时计费、环境稳定 | 需要付费 |
| Kaggle | 免费 GPU | 网络限制、时间限制 |
本教程选择 AutoDL 是因为:
- vLLM 在 Jupyter Notebook 环境中存在多进程兼容问题
- AutoDL 提供完整的 Linux 终端环境
- 国内访问 ModelScope 下载模型更快
2. 环境准备
2.1 注册 AutoDL 账号
- 访问 AutoDL 官网
- 注册并完成实名认证
- 充值(建议先充 10-20 元测试)
2.2 创建实例
DataWhale在 AutoDL 平台准备的 Qwen3 的环境镜像,点击下方链接并直接创建 Autodl 示例即可。 www.codewithgpu.com/i/datawhale...
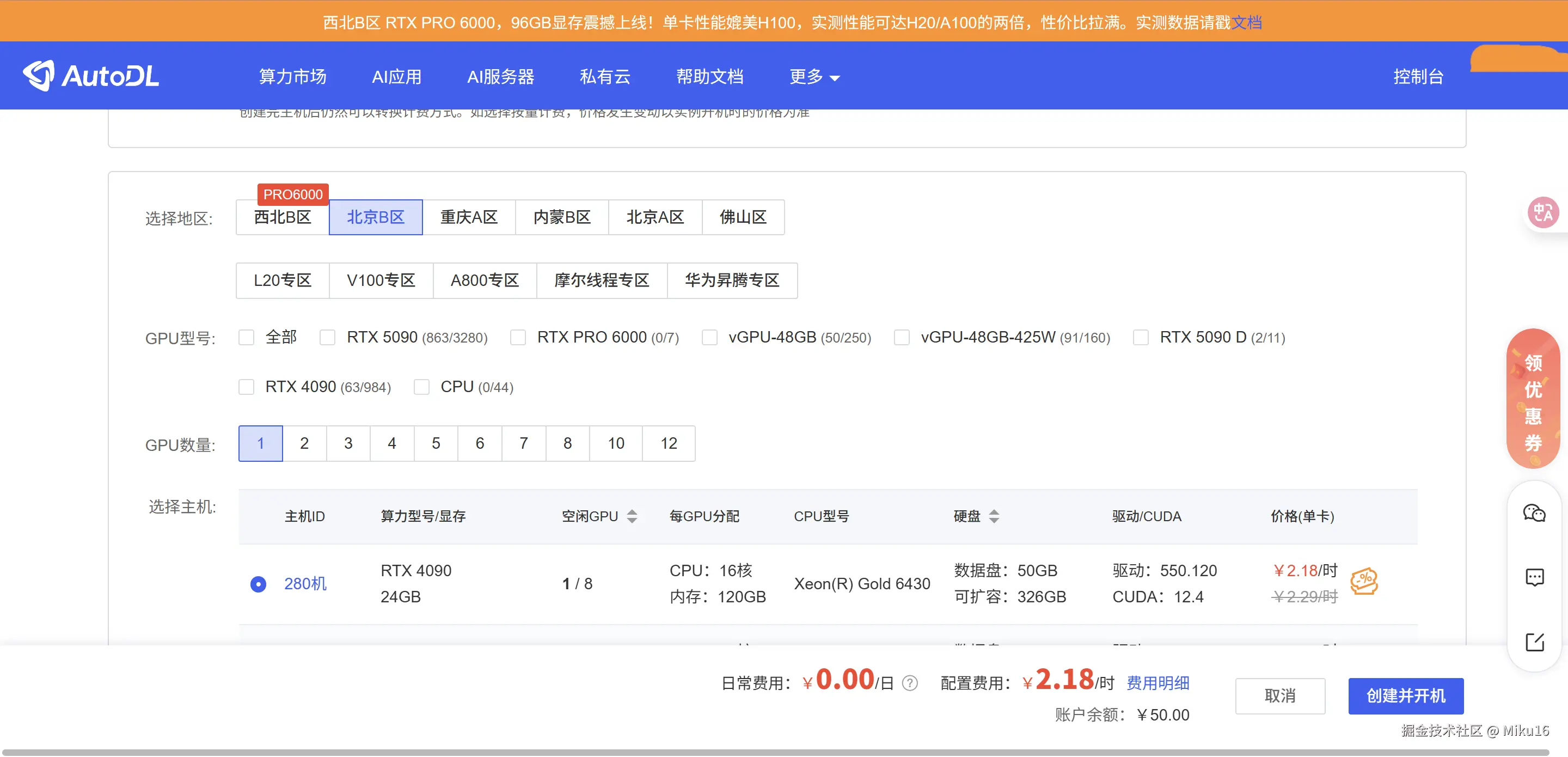
步骤 1:选择 GPU
在 AutoDL 控制台,点击"租用新实例",选择 GPU:
| GPU 型号 | 显存 | 价格(参考) | 是否足够 |
|---|---|---|---|
| RTX 4090 | 24GB | ~2元/小时 | 推荐 |
| RTX 3090 | 24GB | ~1.5元/小时 | 可用 |
| A100 40GB | 40GB | ~4元/小时 | 充裕 |
| RTX 3080 | 10GB | ~0.8元/小时 | 不够 |
显存需求说明:Qwen3-8B 使用 float16 精度约需 16GB 显存,加上 KV Cache 等开销,建议至少 24GB。
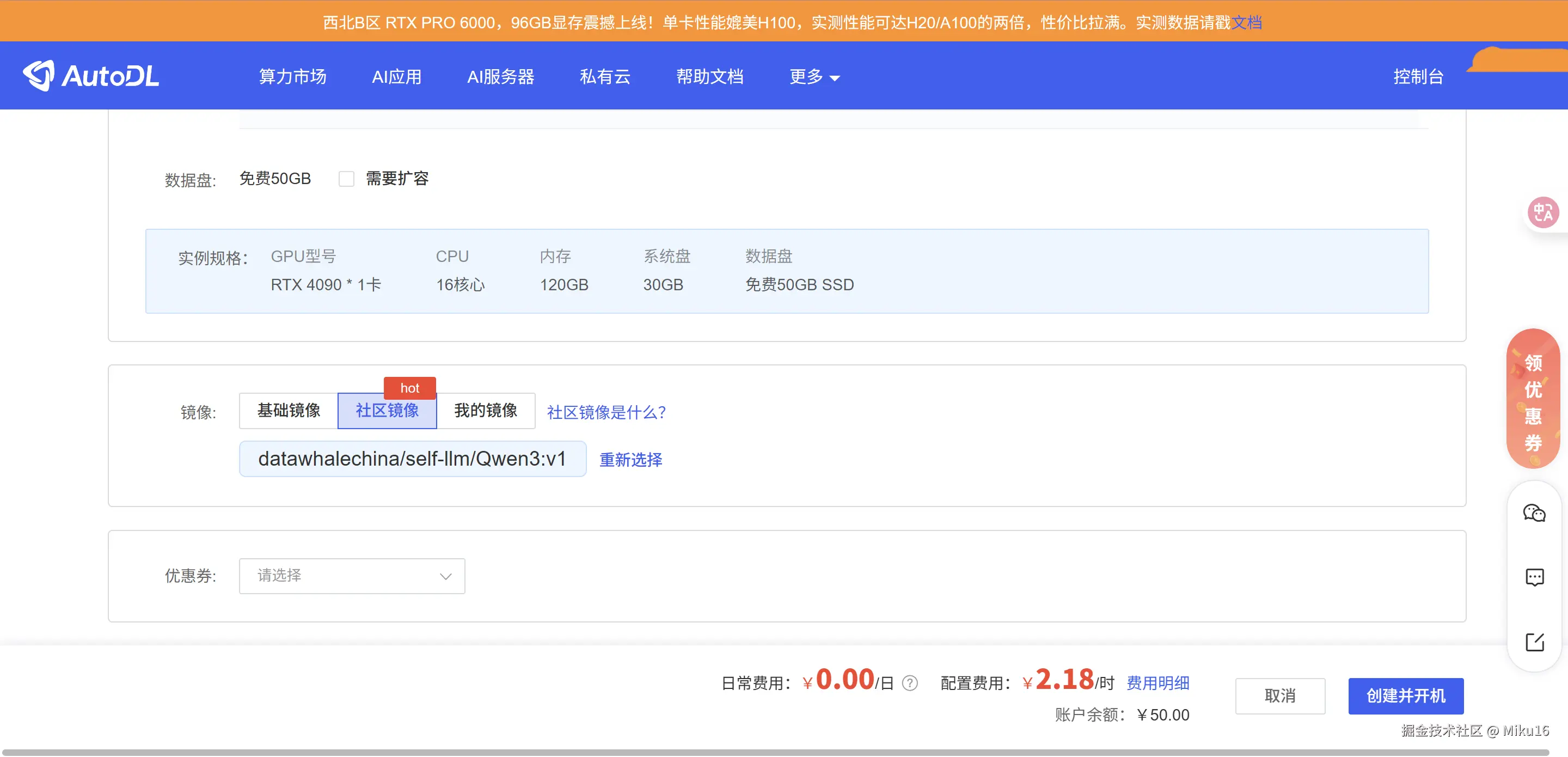
步骤 2:选择镜像
选择社区镜像:datawhalechina/self-llm/Qwen3:v1
这个镜像预装了:
- Python 3.12
- PyTorch + CUDA
- vLLM 0.8.5
- Transformers
- ModelScope
【截图:AutoDL 实例创建页面 - GPU和镜像选择】
步骤 3:创建实例
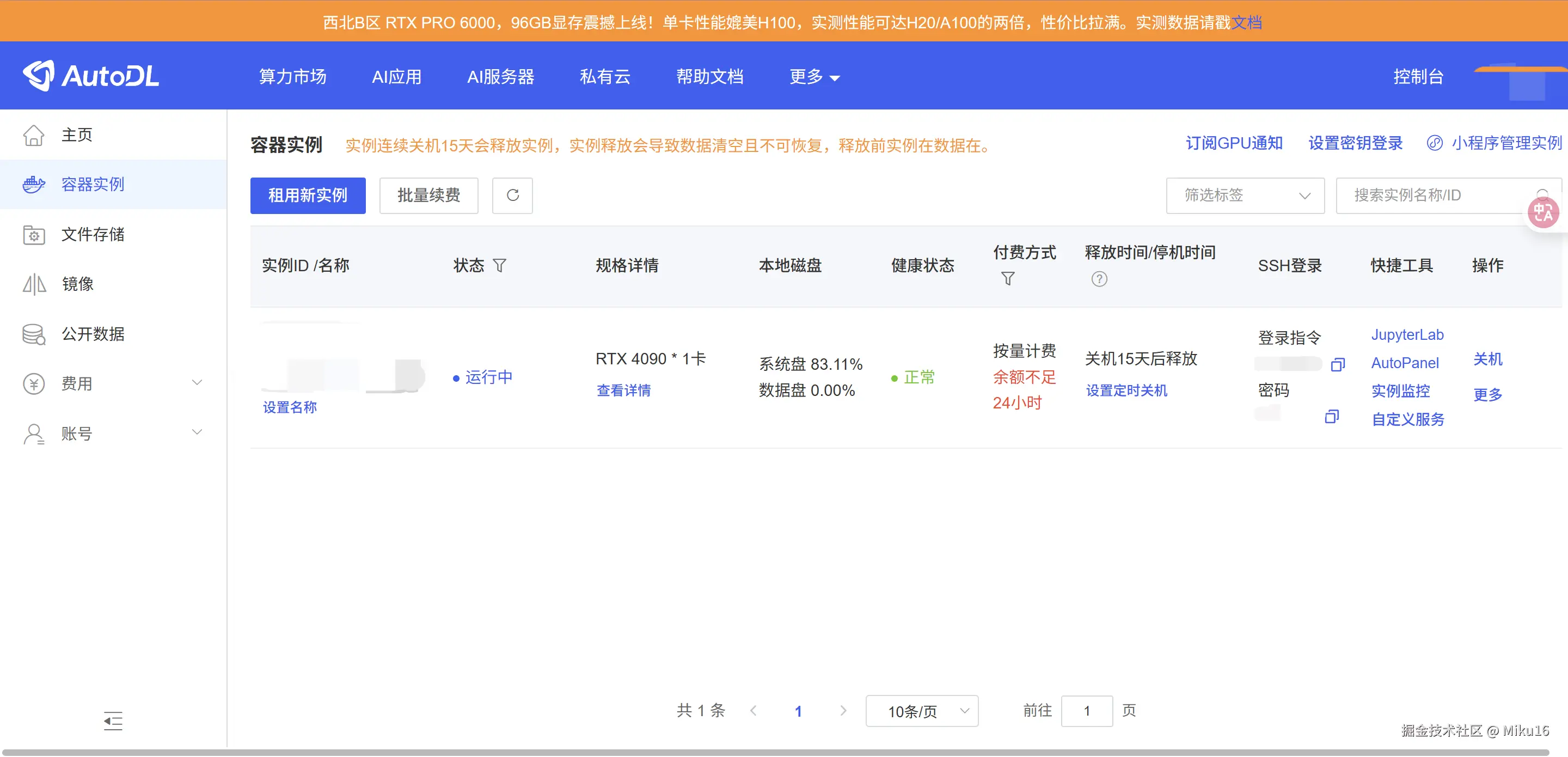
点击"立即创建",等待实例启动(通常 1-2 分钟)。
3. 连接服务器
3.1 获取 SSH 连接信息
实例创建成功后,在控制台可以看到"SSH登录"列,复制其中的登录指令和密码,可以获得下列信息。
- SSH 地址 :例如
region-1.autodl.pro - SSH 端口 :例如
12345 - 用户名 :
root - 密码:创建时设置的密码
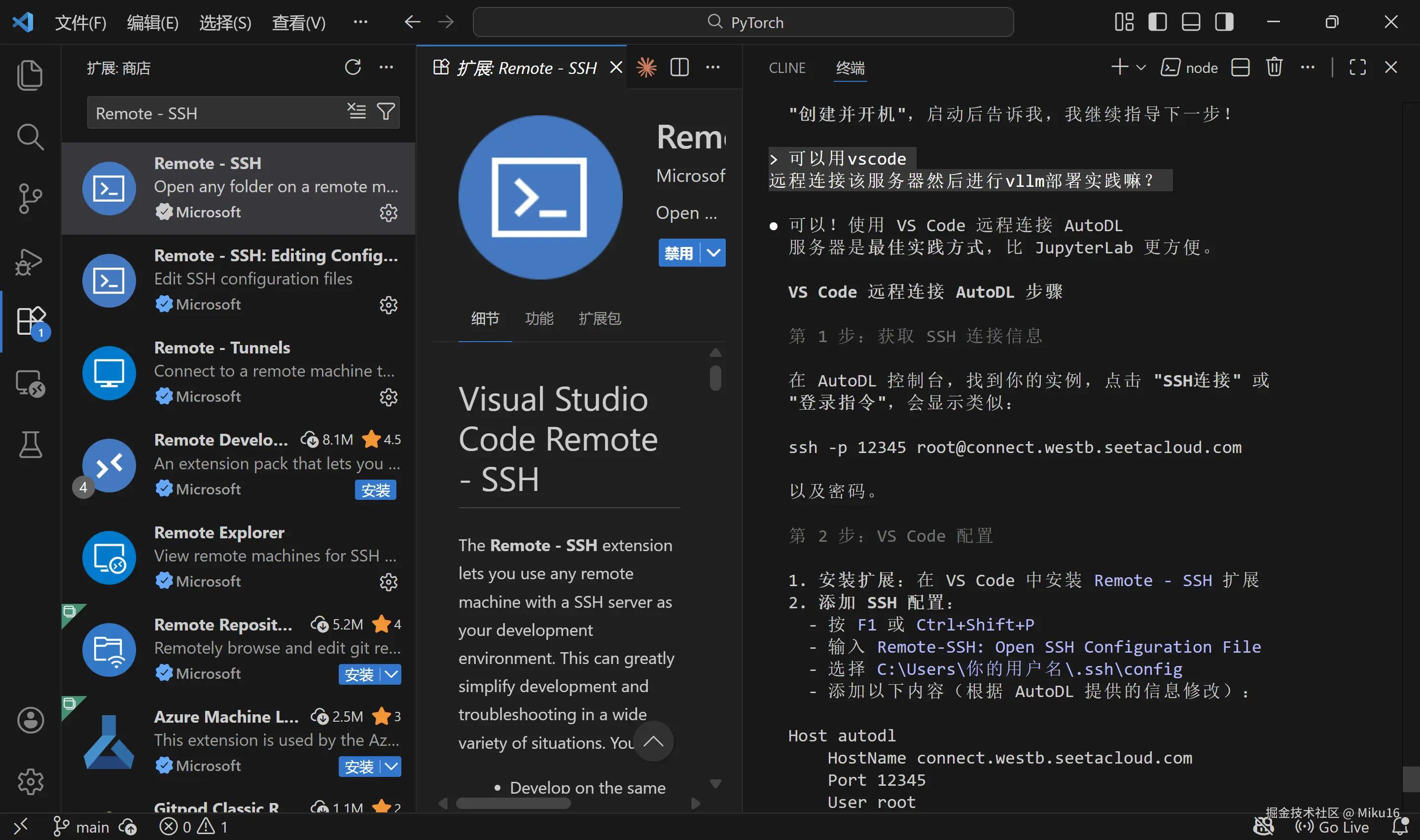
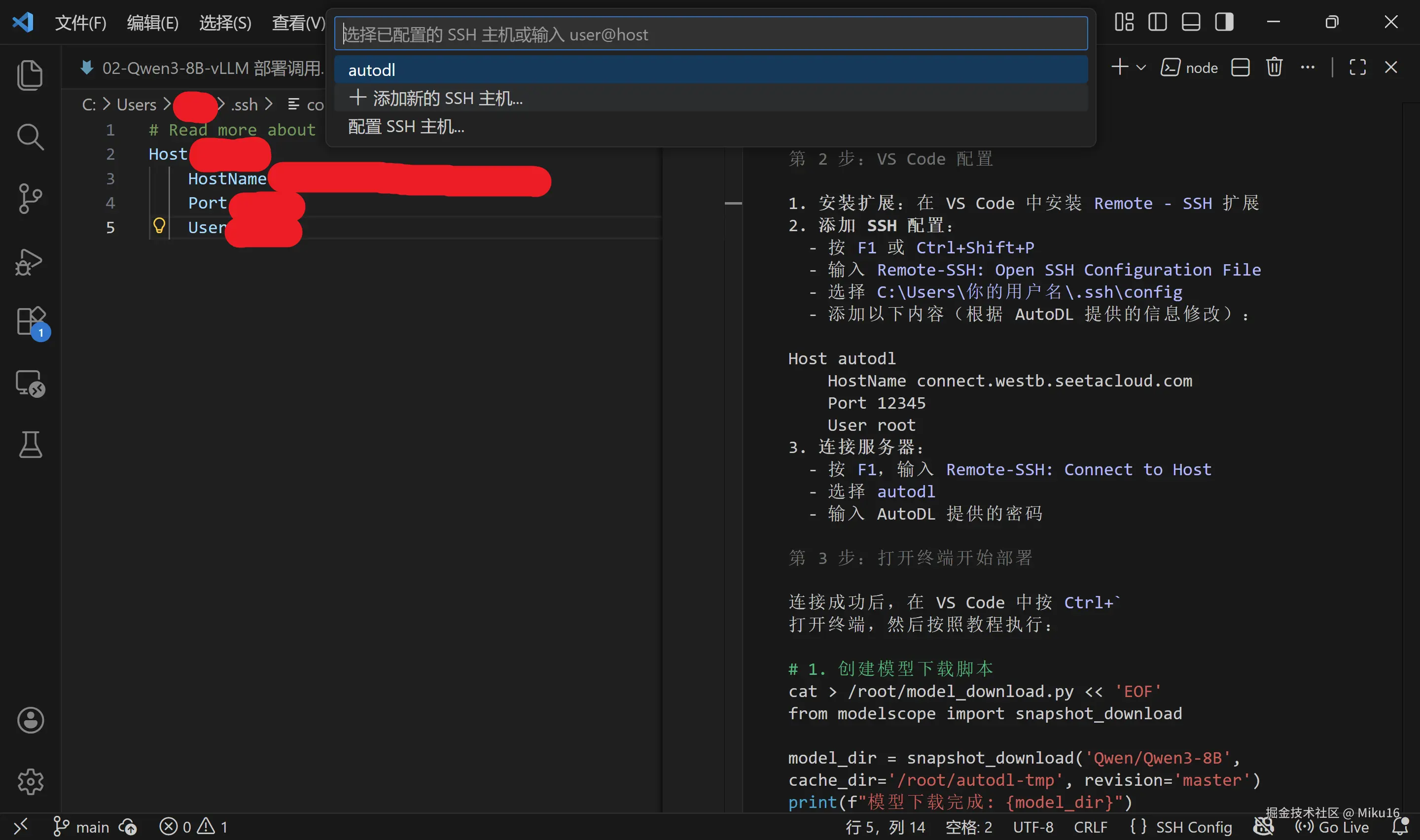
3.2 使用 VS Code 远程连接(推荐)
步骤 1:安装 Remote-SSH 扩展
在 VS Code 中安装 Remote - SSH 扩展。
步骤 2:配置 SSH
按 Ctrl+Shift+P,输入 Remote-SSH: Open SSH Configuration File,选择用户目录下的 config 文件。
添加以下配置:
ssh-config
# ============================================================
# SSH 配置文件说明
# ============================================================
#
# 【文件位置】
# Windows: C:\Users\用户名\.ssh\config
# Linux/Mac: ~/.ssh/config
#
# 【配置格式说明】
# Host: 连接的别名,可以自定义,方便记忆
# HostName: 服务器真实地址(从 AutoDL 控制台获取)
# Port: SSH 端口号(从 AutoDL 控制台获取)
# User: 登录用户名,AutoDL 默认是 root
# ============================================================
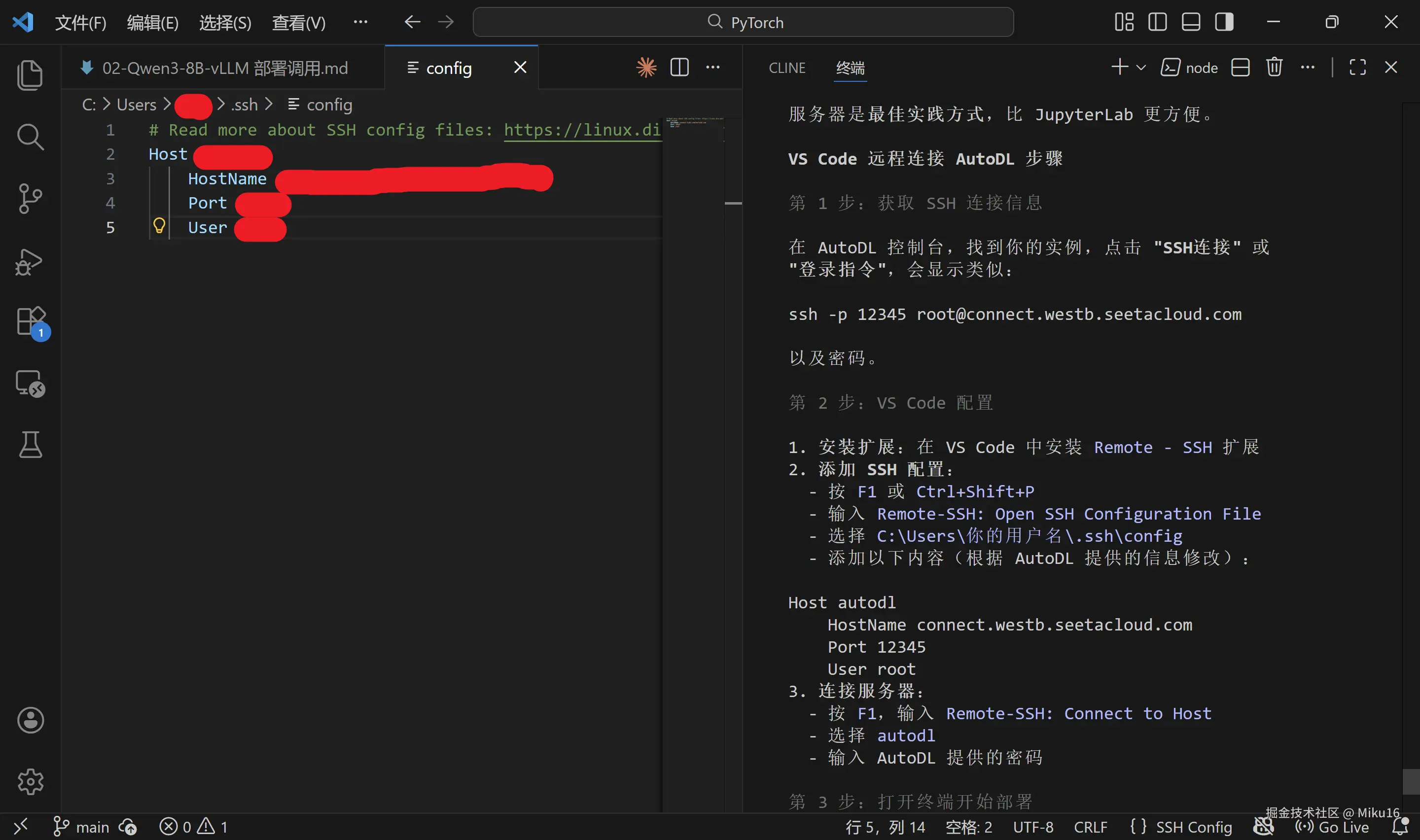
Host autodl-qwen3
HostName region-1.autodl.pro
Port 12345
User root注意 :请将
HostName和Port替换为你实际的 AutoDL 实例信息。
步骤 3:连接服务器
- 按
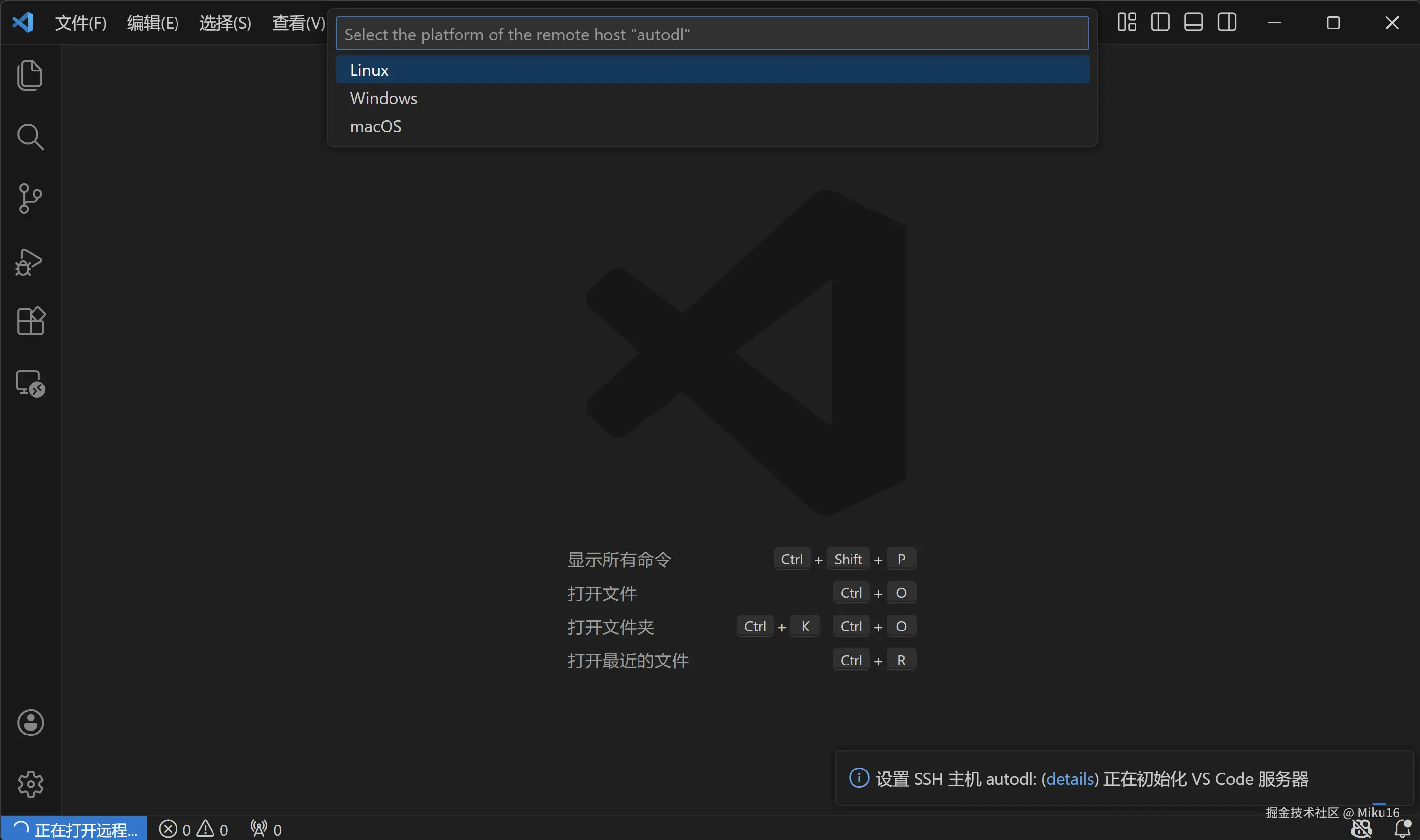
Ctrl+Shift+P,输入Remote-SSH: Connect to Host - SSH主机选择
autodl,平台选择Linux - 输入密码
- 等待连接成功
【截图:VS Code 成功连接 AutoDL】
3.3 打开终端
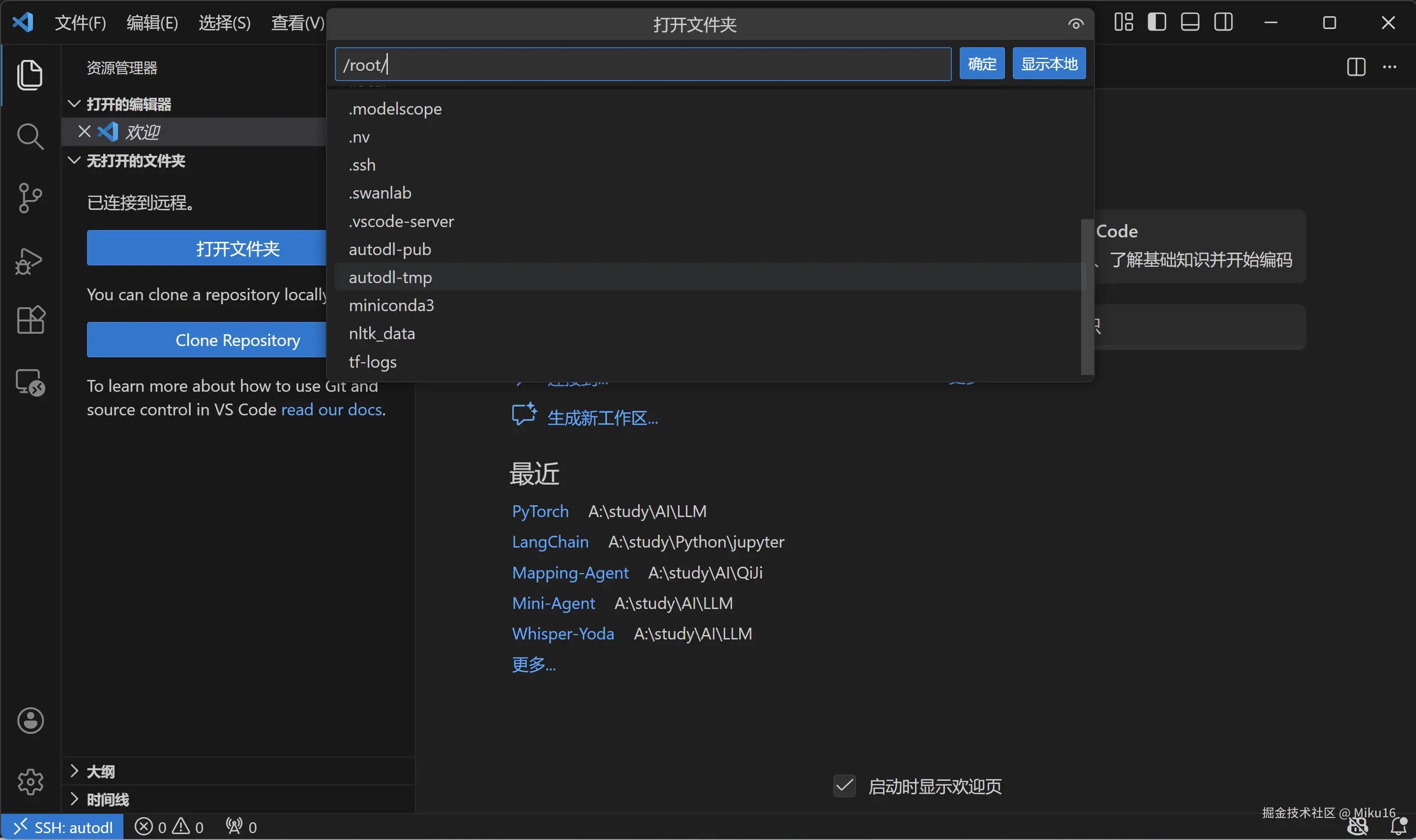
连接成功后,打开/root/autodl-tmp文件夹。
在 VS Code 中按 ``Ctrl+``` 打开终端,你应该看到类似:
bash
root@autodl-container-xxxxx:~#
4. 环境修复
4.1 问题背景
社区镜像中的依赖版本可能存在冲突,需要先修复才能正常使用 vLLM。首先 pip 换源加速下载并安装依赖包。
bash
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope
pip install vllm4.2 检查 vLLM 版本
bash
vllm --version如果出现错误,按以下步骤修复。
4.3 修复依赖冲突
错误 1:NumPy/SciPy 不兼容
错误信息:
bash
ValueError: All ufuncs must have type numpy.ufunc原因:scipy 与 numpy 版本不匹配。
解决方案:
bash
# ============================================================
# 修复 NumPy 和 SciPy 依赖
# ============================================================
#
# 【命令说明】
# pip install: Python 包管理器的安装命令
# --force-reinstall: 强制重新安装,即使已存在也会重装
#
# 【版本选择说明】
# numpy==1.26.4: 指定安装 1.26.4 版本
# - 使用 == 精确指定版本号
# - 1.26.x 是稳定版本,兼容性好
#
# scipy==1.13.1: 指定安装 1.13.1 版本
# - 与 numpy 1.26.x 兼容
# ============================================================
pip install numpy==1.26.4 scipy==1.13.1 --force-reinstall错误 2:RecursionError(递归错误)
错误信息:
makefile
RecursionError: maximum recursion depth exceeded原因:scikit-learn 的编译扩展与新 numpy 不兼容。
解决方案:
bash
# 重新安装 scikit-learn,使其重新编译以适配新的 numpy
pip install scikit-learn --force-reinstall错误 3:Numba 需要 NumPy 2.2 或更低
错误信息:
makefile
ImportError: Numba needs NumPy 2.2 or less. Got NumPy 2.4.原因:安装 scikit-learn 时自动升级了 numpy 到 2.4。
解决方案:
bash
# ============================================================
# 降级 NumPy 到兼容版本
# ============================================================
#
# NumPy 2.2.0 可以同时满足:
# - numba 的要求(<= 2.2)
# - scikit-learn 的要求(>= 1.24.1)
# - scipy 的要求
# ============================================================
pip install numpy==2.2.0 --force-reinstall4.4 验证修复成功
bash
vllm --version预期输出:
ini
INFO 12-23 11:09:14 [__init__.py:239] Automatically detected platform cuda.
0.8.5.post1【截图位置:vLLM 版本验证成功】
请在此处插入终端显示 vllm --version 输出的截图
5. 模型下载
5.1 创建下载脚本
在 /root/autodl-tmp/ 目录下创建 model_download.py 文件,内容如下:
python
# ============================================================
# model_download.py - 模型下载脚本
# ============================================================
#
# 【脚本功能】
# 从 ModelScope(魔搭社区)下载 Qwen3-8B 模型到本地
#
# 【为什么用 ModelScope?】
# - ModelScope 是阿里巴巴的模型托管平台
# - 服务器在国内,下载速度比 Hugging Face 快很多
# - Qwen 模型在 ModelScope 上是官方发布的
#
# 【文件路径】
# /root/autodl-tmp/model_download.py
# ============================================================
# ------------------------------------------------------------
# 导入语句
# ------------------------------------------------------------
from modelscope import snapshot_download
#
# 【Python 导入语法】
# from 模块名 import 函数名
#
# 作用:从 modelscope 库中导入 snapshot_download 函数
# 这样可以直接使用 snapshot_download(),而不需要写 modelscope.snapshot_download()
#
# 【snapshot_download 函数说明】
# - snapshot: 快照,指模型的某个版本
# - download: 下载
# - 功能:下载指定模型的所有文件到本地
# ------------------------------------------------------------
# ------------------------------------------------------------
# 调用下载函数
# ------------------------------------------------------------
model_dir = snapshot_download(
'Qwen/Qwen3-8B', # 参数1:模型标识符(位置参数)
cache_dir='/root/autodl-tmp', # 参数2:缓存目录(关键字参数)
revision='master' # 参数3:版本/分支(关键字参数)
)
#
# 【参数详解】
#
# 1. 'Qwen/Qwen3-8B' (位置参数)
# - 格式:组织名/模型名
# - Qwen: 阿里通义千问团队
# - Qwen3-8B: 第三代,80亿参数
# - 在 ModelScope 上的地址:https://modelscope.cn/models/Qwen/Qwen3-8B
#
# 2. cache_dir='/root/autodl-tmp' (关键字参数)
# - 关键字参数格式:参数名=值
# - 指定下载文件保存的目录
# - /root/autodl-tmp 是 AutoDL 的数据盘
# - 数据盘的数据在关机后会保留
# - 系统盘 /root 的数据关机后可能丢失
#
# 3. revision='master' (关键字参数)
# - 指定要下载的版本
# - 'master' 是主分支,即最新稳定版
# - 也可以指定具体的 commit hash 或 tag
#
# 【返回值】
# model_dir: 字符串,模型实际保存的完整路径
# 例如:/root/autodl-tmp/Qwen/Qwen3-8B
# ------------------------------------------------------------
# ------------------------------------------------------------
# 打印下载结果
# ------------------------------------------------------------
print(f"模型已下载到: {model_dir}")
#
# 【f-string 语法说明】
# f"..." 是 Python 3.6+ 引入的格式化字符串(f-string)
#
# 语法规则:
# - 字符串前加 f 或 F 前缀
# - 花括号 {} 中可以放入变量或表达式
# - Python 会自动将变量的值插入字符串中
#
# 示例:
# name = "Alice"
# age = 25
# print(f"姓名: {name}, 年龄: {age}")
# # 输出:姓名: Alice, 年龄: 25
# ------------------------------------------------------------5.2 开启网络加速(可选)
AutoDL 提供学术资源加速,可以加快下载速度:
bash
# ============================================================
# 开启 AutoDL 学术加速
# ============================================================
#
# 【命令说明】
# source: Shell 内置命令,用于在当前 Shell 中执行脚本
# 与直接执行脚本不同,source 会在当前进程中执行
# 这样脚本中设置的环境变量会保留
#
# /etc/network_turbo: AutoDL 提供的网络加速脚本
#
# 【作用】
# 优化到学术资源(如 ModelScope、Hugging Face)的网络连接
# 可能提升下载速度
# ============================================================
source /etc/network_turbo5.3 运行下载脚本
bash
# ============================================================
# 执行模型下载
# ============================================================
#
# 【命令说明】
# cd: change directory,切换当前工作目录
# cd /root/autodl-tmp 表示切换到 /root/autodl-tmp 目录
#
# &&: 逻辑与操作符
# 作用:前一个命令成功(返回值为0)后才执行下一个命令
# 如果 cd 失败,python 命令不会执行
#
# python: Python 解释器
# python 文件名.py 表示用 Python 执行该脚本
# ============================================================
cd /root/autodl-tmp && python model_download.py预期输出:
ruby
Downloading Model from https://www.modelscope.cn to directory: /root/autodl-tmp/Qwen/Qwen3-8B
...
Downloading [model-00001-of-00005.safetensors]: 100%|==========|
Downloading [model-00002-of-00005.safetensors]: 100%|==========|
...
模型已下载到: /root/autodl-tmp/Qwen/Qwen3-8B下载时间:模型约 16GB,根据网络状况需要 10-30 分钟。
【截图位置:模型下载完成】
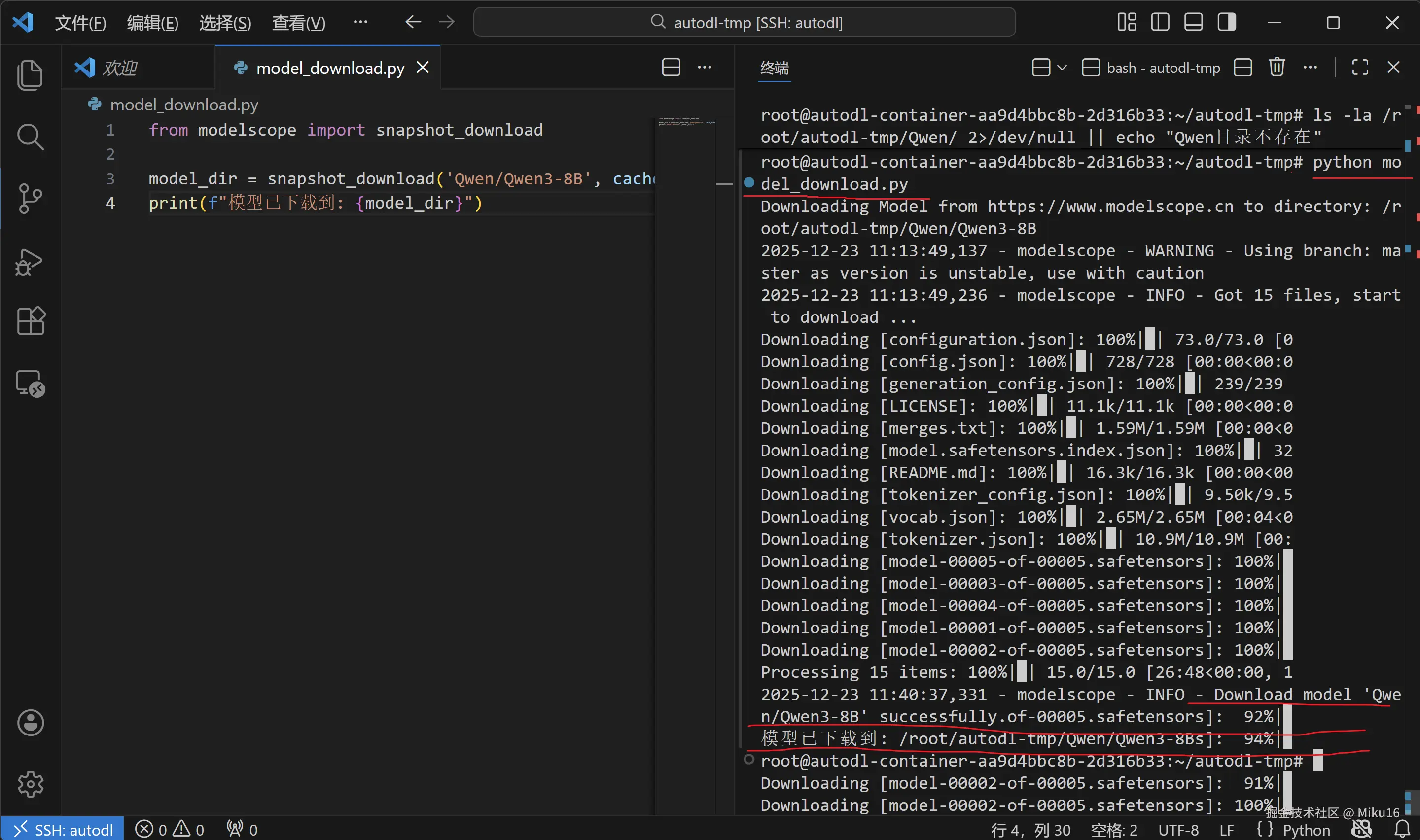
5.4 验证下载
bash
# 查看下载的文件
ls -lh /root/autodl-tmp/Qwen/Qwen3-8B/【ls 命令说明】
bash
# ls: list,列出目录内容
# -l: 长格式显示(显示详细信息:权限、大小、日期等)
# -h: human-readable,以人类可读的格式显示文件大小(KB、MB、GB)
#
# 组合使用:ls -lh 等价于 ls -l -h预期输出:
diff
total 16G
-rw-r--r-- 1 root root 728 Dec 23 11:40 config.json
-rw-r--r-- 1 root root 239 Dec 23 11:40 generation_config.json
-rw-r--r-- 1 root root 3.7G Dec 23 11:35 model-00001-of-00005.safetensors
-rw-r--r-- 1 root root 3.7G Dec 23 11:36 model-00002-of-00005.safetensors
-rw-r--r-- 1 root root 3.7G Dec 23 11:37 model-00003-of-00005.safetensors
-rw-r--r-- 1 root root 3.7G Dec 23 11:38 model-00004-of-00005.safetensors
-rw-r--r-- 1 root root 1.1G Dec 23 11:39 model-00005-of-00005.safetensors
-rw-r--r-- 1 root root 11M Dec 23 11:40 tokenizer.json
...模型文件说明
| 文件 | 大小 | 说明 |
|---|---|---|
config.json |
728B | 模型配置文件(层数、维度、注意力头数等) |
model-*.safetensors |
各约3.7GB | 模型权重文件(分片存储,共5个文件) |
tokenizer.json |
11MB | 分词器配置(词汇表、分词规则等) |
vocab.json |
2.6MB | 词汇表 |
generation_config.json |
239B | 生成配置(默认采样参数等) |
6. Python脚本推理
6.1 创建推理脚本
在 /root/autodl-tmp/ 目录下创建 vllm_model.py 文件,内容如下:
python
# ============================================================
# vllm_model.py - vLLM 本地推理脚本
# ============================================================
#
# 【脚本功能】
# 使用 vLLM 加载 Qwen3-8B 模型,进行本地推理测试
#
# 【文件路径】
# /root/autodl-tmp/vllm_model.py
#
# 【运行方式】
# python vllm_model.py
#
# 【预计运行时间】
# - 首次运行(需要编译):2-3 分钟
# - 后续运行:约 30 秒
# ============================================================
# ============================================================
# 第一部分:导入必要的库
# ============================================================
from vllm import LLM, SamplingParams
#
# 【导入语法说明】
# from 模块名 import 类名1, 类名2
#
# 作用:从 vllm 库中导入两个类
#
# 【导入的类说明】
#
# 1. LLM 类
# - 全称:Large Language Model
# - 作用:大语言模型的封装类
# - 功能:
# - 加载模型权重到 GPU
# - 管理 GPU 显存(PagedAttention)
# - 执行推理生成
# - 处理批量请求
# - 是 vLLM 的核心类
#
# 2. SamplingParams 类
# - 全称:Sampling Parameters(采样参数)
# - 作用:配置文本生成时的采样策略
# - 参数包括:temperature、top_p、top_k 等
from transformers import AutoTokenizer
#
# 【导入说明】
# transformers: Hugging Face 开发的 NLP 库
# AutoTokenizer: 自动分词器类
#
# 虽然 vLLM 内置了分词器,但我们需要用 transformers 的分词器
# 来调用 apply_chat_template() 方法格式化对话
#
# 【为什么需要分词器?】
# 计算机不能直接理解文字,需要将文字转换为数字
# 分词器的作用:
# - 编码:文字 -> 数字(如 "你好" -> [108386, 35946])
# - 解码:数字 -> 文字(如 [108386, 35946] -> "你好")
import os
#
# 【导入说明】
# os: Python 标准库,提供操作系统相关功能
# 这里用于设置环境变量
#
# 常用功能:
# - os.environ: 访问和修改环境变量
# - os.path: 路径操作
# - os.listdir(): 列出目录内容
import json
# ============================================================
# 第二部分:设置环境变量
# ============================================================
os.environ['VLLM_USE_MODELSCOPE'] = 'True'
#
# 【环境变量说明】
#
# os.environ 是一个类似字典的对象,存储所有环境变量
# 可以像字典一样读取和设置:
# 读取:value = os.environ['变量名']
# 设置:os.environ['变量名'] = '值'
#
# VLLM_USE_MODELSCOPE = 'True' 的作用:
# - 告诉 vLLM 使用 ModelScope 作为模型下载源
# - 如果本地没有模型,会从 ModelScope 下载
# - 由于我们已经下载了模型,这个设置主要是保险措施
#
# 【注意】环境变量的值必须是字符串,所以用 'True' 而不是 True
# ============================================================
# 第三部分:定义推理函数
# ============================================================
def get_completion(prompts, model, tokenizer=None, temperature=0.6,
top_p=0.95, top_k=20, min_p=0, max_tokens=4096,
max_model_len=8192):
"""
使用 vLLM 进行文本生成的函数
【Python 函数定义语法】
def 函数名(参数1, 参数2=默认值, ...):
'''文档字符串(docstring)'''
函数体
return 返回值
【参数详解】
prompts: str 或 list[str]
- 输入的提示文本
- 可以是单个字符串:"你好"
- 也可以是字符串列表:["问题1", "问题2"](批量处理)
model: str
- 模型路径或模型名称
- 本地路径:'/root/autodl-tmp/Qwen/Qwen3-8B'
- 或模型ID:'Qwen/Qwen3-8B'(会自动下载)
temperature: float = 0.6
- 温度参数,控制随机性
- 范围 0-2:
- 0: 确定性输出(总是选概率最高的)
- 0.6: 适中的随机性(推荐)
- 1.0+: 更随机、更有创意
top_p: float = 0.95
- 核采样(Nucleus Sampling)参数
- 只从累积概率达到 top_p 的 token 中采样
- 0.95 表示考虑概率最高的 95% 的 token
top_k: int = 20
- Top-K 采样参数
- 只从概率最高的 K 个 token 中采样
max_tokens: int = 4096
- 最大生成 token 数
- 限制输出长度,防止无限生成
max_model_len: int = 8192
- 模型最大上下文长度
- 包括输入和输出的总长度
【返回值】
outputs: list[RequestOutput]
- 生成结果列表
- 每个元素包含 prompt 和 outputs 属性
"""
# --------------------------------------------------------
# 配置停止 token
# --------------------------------------------------------
stop_token_ids = [151645, 151643]
#
# 【停止 token 说明】
#
# 这是一个列表(list),包含两个整数
# 这些数字是 Qwen3 的特殊 token ID:
# - 151645: <|im_end|> 消息结束标记
# - 151643: <|endoftext|> 文本结束标记
#
# 【作用】
# 当模型生成这些 token 时,会停止继续生成
# 相当于告诉模型"可以结束了"
# 如果不设置,模型可能会无限生成下去
# --------------------------------------------------------
# 创建采样参数对象
# --------------------------------------------------------
sampling_params = SamplingParams(
temperature=temperature,
top_p=top_p,
top_k=top_k,
min_p=min_p,
max_tokens=max_tokens,
stop_token_ids=stop_token_ids
)
#
# 【创建对象语法】
# 变量名 = 类名(参数1=值1, 参数2=值2, ...)
#
# SamplingParams 是一个类,调用它会创建一个对象
# 类似于用模具(类)制作一个具体的东西(对象)
# --------------------------------------------------------
# 创建 LLM 对象(加载模型)
# --------------------------------------------------------
llm = LLM(
model=model,
tokenizer=tokenizer,
max_model_len=max_model_len,
trust_remote_code=True
)
#
# 【LLM 构造参数说明】
#
# model: 模型路径
# - 可以是本地路径:'/root/autodl-tmp/Qwen/Qwen3-8B'
# - 也可以是模型ID:'Qwen/Qwen3-8B'(会自动下载)
#
# tokenizer: 分词器
# - None 表示使用模型目录中的分词器
#
# max_model_len: 最大序列长度
# - 8192 表示最多处理 8192 个 token
# - 越大需要越多显存(用于 KV Cache)
#
# trust_remote_code: 是否信任远程代码
# - True 表示允许执行模型仓库中的自定义 Python 代码
# - Qwen 模型有自定义的模型代码,需要开启此选项
#
# 【创建 LLM 对象时会发生什么?】
# 1. 读取 config.json,了解模型结构
# 2. 加载模型权重到 GPU(约 16GB)
# 3. 编译优化计算图(首次较慢,约 1-2 分钟)
# 4. 预热 CUDA Graph(捕获不同长度的计算图)
# 5. 分配 KV Cache(用于存储注意力的中间结果)
# --------------------------------------------------------
# 执行推理
# --------------------------------------------------------
outputs = llm.generate(prompts, sampling_params)
#
# 【方法调用语法】
# 对象.方法名(参数1, 参数2)
#
# llm.generate() 是 LLM 对象的方法
# 作用:根据输入的 prompts 生成文本
#
# 参数:
# - prompts: 输入文本(可以是列表,支持批量处理)
# - sampling_params: 采样参数对象
#
# 返回值:
# - outputs: 一个列表,包含每个输入的生成结果
return outputs
# ============================================================
# 第四部分:主程序
# ============================================================
if __name__ == "__main__":
"""
【if __name__ == "__main__" 详解】
这是 Python 的标准写法,几乎每个可执行脚本都有
【原理】
每个 Python 文件都有一个内置变量 __name__
- 直接运行时:__name__ 的值是 "__main__"
- 被导入时:__name__ 的值是模块名(如 "vllm_model")
【好处】
- 脚本可以直接运行
- 也可以被其他脚本导入使用其中的函数
- 两种用法互不干扰
"""
# --------------------------------------------------------
# 定义模型路径
# --------------------------------------------------------
model = '/root/autodl-tmp/Qwen/Qwen3-8B'
#
# 这是模型文件所在的目录
# 包含 config.json、model-*.safetensors、tokenizer.json 等文件
# --------------------------------------------------------
# 加载分词器
# --------------------------------------------------------
tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False)
#
# 【类方法调用语法】
# 类名.方法名(参数)
#
# from_pretrained 是 AutoTokenizer 的类方法(class method)
# 类方法不需要先创建对象就可以调用
#
# 【参数说明】
# model: 模型路径,会读取其中的 tokenizer.json 等文件
# use_fast=False: 使用标准分词器(而非快速分词器)
#
# 【返回值】
# tokenizer: 分词器对象,可以用于:
# - tokenizer.encode("文本"): 将文本转为 token ID
# - tokenizer.decode([ids]): 将 token ID 转回文本
# - tokenizer.apply_chat_template(): 格式化对话
# --------------------------------------------------------
# 定义用户输入
# --------------------------------------------------------
prompt = "给我一个关于大模型的简短介绍。"
# --------------------------------------------------------
# 构建对话消息
# --------------------------------------------------------
messages = [
{"role": "user", "content": prompt}
]
#
# 【数据结构说明】
#
# messages 是一个列表(list)
# 列表用方括号 [] 表示,元素用逗号分隔
#
# 列表中的每个元素是一个字典(dict)
# 字典用花括号 {} 表示,格式为 {键: 值, 键: 值, ...}
#
# 这里的字典有两个键值对:
# - "role": "user" 表示说话的角色是用户
# - "content": prompt 表示说话的内容
#
# 【OpenAI 消息格式】
# 这是 OpenAI API 定义的标准对话格式
# 支持的角色(role):
# - "system": 系统提示(设定AI的行为)
# - "user": 用户消息
# - "assistant": AI助手的回复
# --------------------------------------------------------
# 使用模板格式化对话
# --------------------------------------------------------
text = tokenizer.apply_chat_template(
messages, # 对话消息列表
tokenize=False, # 不进行分词,返回字符串
add_generation_prompt=True, # 添加生成提示
enable_thinking=True # 开启思考模式
)
#
# 【apply_chat_template 方法说明】
#
# 作用:将对话消息转换为模型期望的特定格式
# 不同模型有不同的对话格式,这个方法会自动处理
#
# 【参数详解】
#
# messages: 对话消息列表
#
# tokenize=False:
# - False: 返回格式化后的字符串(人类可读)
# - True: 返回 token ID 列表(数字序列)
#
# add_generation_prompt=True:
# - True: 在末尾添加 assistant 的开始标记
# - 这告诉模型"现在该你回答了"
#
# enable_thinking=True: (Qwen3 特有参数)
# - True: 开启思考模式
# - 模型会先生成思考过程 <think>...</think>
# - 然后再生成最终答案
# - 类似于 DeepSeek-R1 和 o1 的推理能力
# --------------------------------------------------------
# 调用推理函数
# --------------------------------------------------------
outputs = get_completion(
text, # 格式化后的输入文本
model, # 模型路径
tokenizer=None, # 使用模型自带的分词器
temperature=0.6, # 温度参数
top_p=0.95, # 核采样参数
top_k=20, # Top-K 采样参数
min_p=0 # 最小概率阈值
)
#
# 【思考模式推荐参数】
# 官方推荐的思考模式采样参数:
# - temperature=0.6:适中的随机性
# - top_p=0.95:保留 95% 概率质量的 token
# - top_k=20:只考虑概率前 20 的 token
# --------------------------------------------------------
# 打印结果
# --------------------------------------------------------
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, \nResponse: {generated_text!r}")
#
# 【for 循环语法】
# for 变量 in 可迭代对象:
# 循环体
#
# outputs 是一个列表,for 循环会遍历其中每个元素
# 每次循环,output 变量会被赋值为列表中的一个元素
#
# 【访问对象属性】
# output.prompt: 获取 output 对象的 prompt 属性
# output.outputs: 获取 outputs 属性(是一个列表)
# output.outputs[0]: 获取第一个元素
# output.outputs[0].text: 获取其 text 属性
#
# 【f-string 中的 !r】
# {变量!r} 使用 repr() 格式化
# repr() 会显示字符串的"原始"形式,包括特殊字符6.2 运行推理脚本
bash
cd /root/autodl-tmp && python vllm_model.py首次运行说明:
| 阶段 | 耗时 | 说明 |
|---|---|---|
| 模型加载 | ~30秒 | 读取 16GB 模型权重到 GPU |
| 编译优化 | ~60秒 | vLLM 编译和优化计算图 |
| CUDA Graph | ~30秒 | 捕获不同输入长度的计算图 |
| 推理 | ~10秒 | 实际生成文本 |
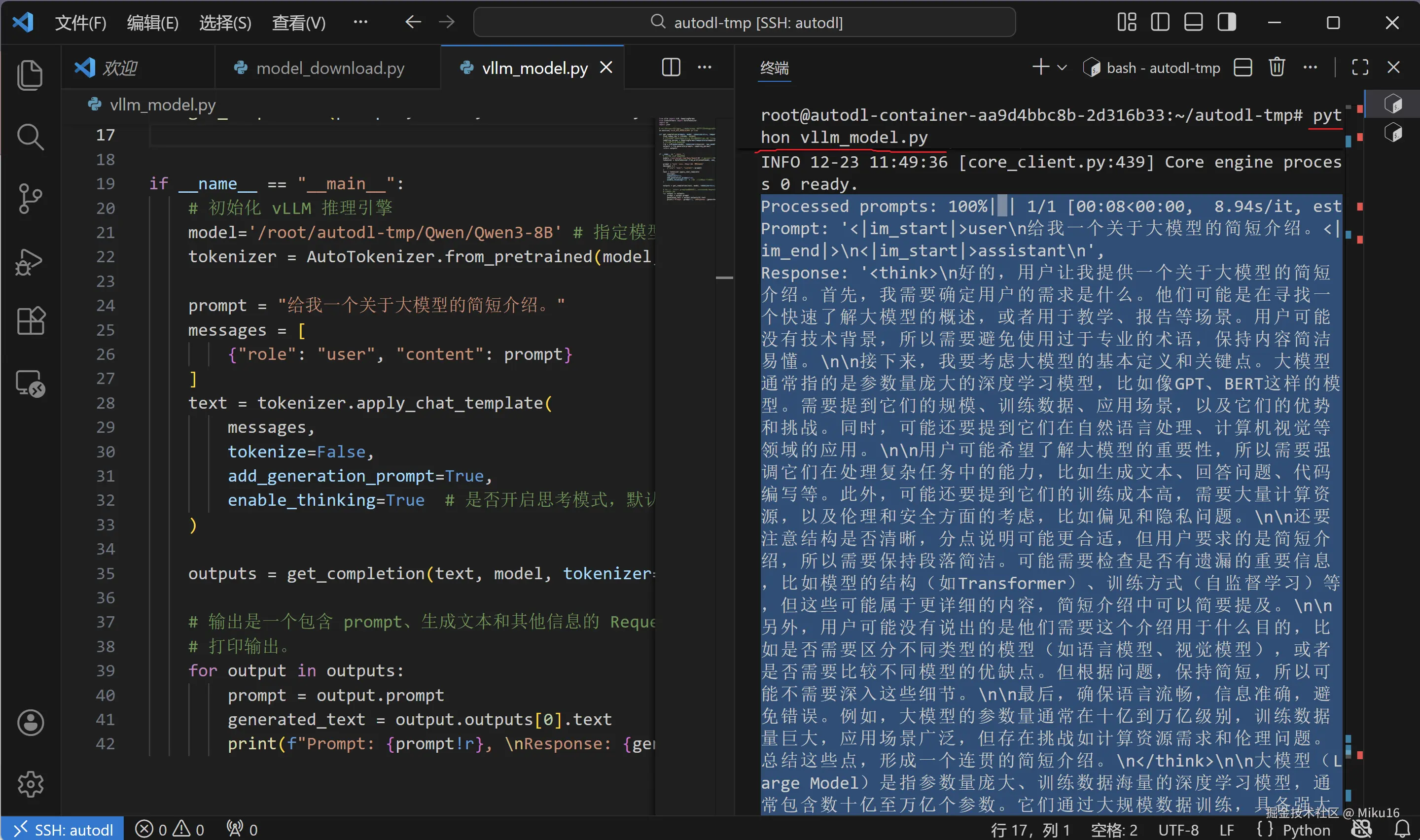
预期输出:
ini
INFO 12-23 11:45:25 [__init__.py:239] Automatically detected platform cuda.
INFO 12-23 11:45:40 [config.py:717] This model supports multiple tasks...
...
INFO 12-23 11:47:30 [gpu_model_runner.py:1329] Starting to compile...
INFO 12-23 11:49:03 [monitor.py:33] torch.compile takes 52.65 s in total
INFO 12-23 11:49:36 [gpu_model_runner.py:1686] Graph capturing finished in 31 secs
INFO 12-23 11:49:36 [core.py:159] init engine took 119.94 seconds
Prompt: '<|im_start|>user\n给我一个关于大模型的简短介绍。<|im_end|>\n<|im_start|>assistant\n',
Response: '<think>\n嗯,用户问的是大模型的简短介绍...\n</think>\n\n大模型是...'【截图位置:Python 脚本推理成功】
6.3 补充:不启用思考模式的推理脚本
在 /root/autodl-tmp/ 目录下创建 vllm_without_thinking.py 文件,内容如下:
python
# ============================================================
# vllm_without_thinking.py - 不启用思考模式的 vLLM 推理脚本
# ============================================================
#
# 【与 vllm_model.py 的区别】
# - enable_thinking=False:不启用思考模式
# - temperature=0.7:非思考模式推荐参数
# - top_p=0.8:非思考模式推荐参数
#
# 【文件路径】
# /root/autodl-tmp/vllm_without_thinking.py
# ============================================================
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
import os
import json
# 自动下载模型时,指定使用modelscope;否则,会从HuggingFace下载
os.environ['VLLM_USE_MODELSCOPE']='True'
def get_completion(prompts, model, tokenizer=None, temperature=0.6, top_p=0.95, top_k=20, min_p=0, max_tokens=4096, max_model_len=8192):
stop_token_ids = [151645, 151643]
# 创建采样参数。temperature 控制生成文本的多样性,top_p 控制核心采样的概率,top_k 选择概率最高的k个标记
sampling_params = SamplingParams(temperature=temperature, top_p=top_p, top_k=top_k, min_p=min_p, max_tokens=max_tokens, stop_token_ids=stop_token_ids)
# 初始化 vLLM 推理引擎
llm = LLM(model=model, tokenizer=tokenizer, max_model_len=max_model_len, trust_remote_code=True)
outputs = llm.generate(prompts, sampling_params)
return outputs
if __name__ == "__main__":
# 初始化 vLLM 推理引擎
model='/root/autodl-tmp/Qwen/Qwen3-8B' # 指定模型路径
tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False) # 加载分词器
prompt = "你是谁?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # 是否开启思考模式,默认为 True
)
# ============================================================
# 【非思考模式推荐参数】
# temperature=0.7:比思考模式稍高,增加创意性
# top_p=0.8:比思考模式稍低,更聚焦
# top_k=20:保持不变
# ============================================================
outputs = get_completion(text, model, tokenizer=None, temperature=0.7, top_p=0.8, top_k=20, min_p=0, max_tokens=4096)
# 输出是一个包含 prompt、生成文本和其他信息的 RequestOutput 对象列表。
# 打印输出。
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r},Response: {generated_text!r}")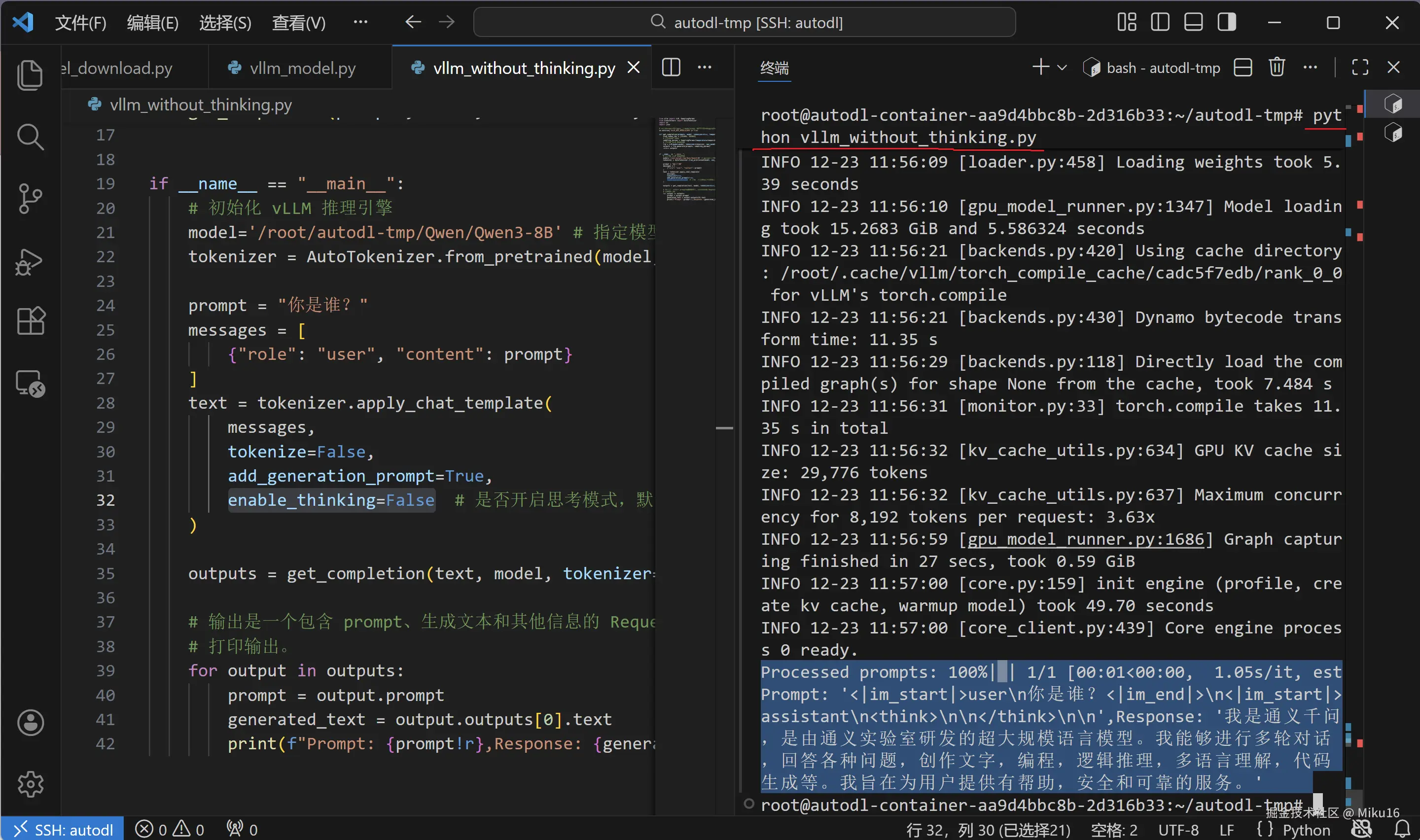
【思考模式 vs 非思考模式对比】
| 参数 | 思考模式 (enable_thinking=True) |
非思考模式 (enable_thinking=False) |
|---|---|---|
temperature |
0.6 | 0.7 |
top_p |
0.95 | 0.8 |
top_k |
20 | 20 |
| 输出特点 | 包含 <think>...</think> 思考过程 |
直接输出答案,无思考过程 |
| 适用场景 | 复杂推理、数学题、逻辑分析 | 简单问答、创意写作、快速响应 |
7. 启动API服务器
7.1 vLLM 服务器简介
vLLM 可以启动一个兼容 OpenAI API 的 HTTP 服务器,这样你就可以:
- 使用 HTTP 请求调用模型
- 使用 OpenAI Python SDK 调用
- 集成到任何支持 OpenAI API 的应用中
7.2 启动服务器命令
bash
# ============================================================
# 启动 vLLM OpenAI 兼容 API 服务器
# ============================================================
#
# 【命令格式】
# 环境变量=值 命令 参数1 参数2 ...
#
# 【环境变量】
# VLLM_USE_MODELSCOPE=true
# - 设置在命令前,只对这个命令生效
# - 命令结束后环境变量不保留
# - 告诉 vLLM 使用 ModelScope 作为模型源
#
# 【vllm serve 命令】
# vllm 是命令行工具
# serve 是子命令,表示启动 API 服务器
# ============================================================
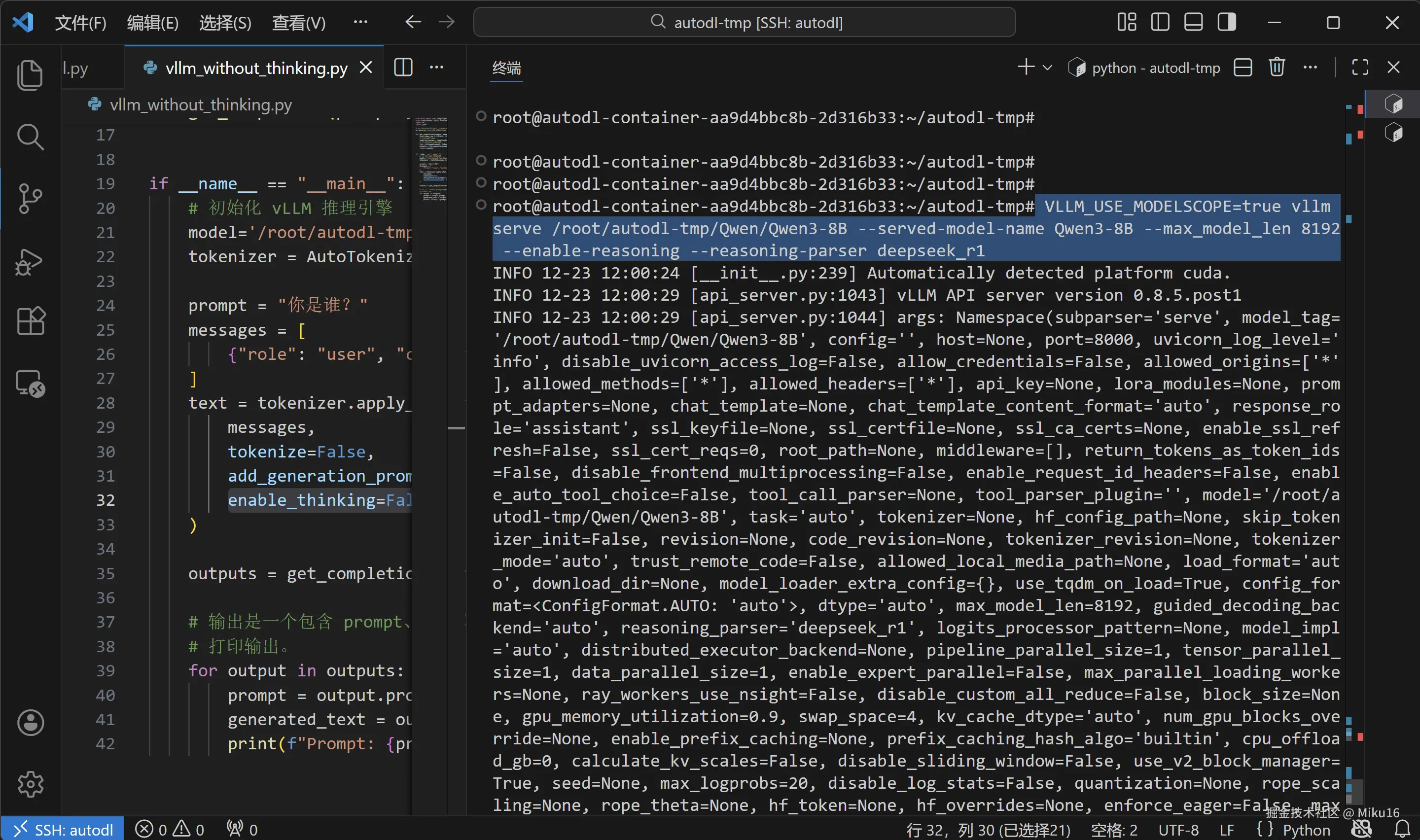
VLLM_USE_MODELSCOPE=true vllm serve /root/autodl-tmp/Qwen/Qwen3-8B \
--served-model-name Qwen3-8B \
--max_model_len 8192 \
--enable-reasoning \
--reasoning-parser deepseek_r1【命令参数详解】
| 参数 | 值 | 说明 |
|---|---|---|
| 第一个参数 | /root/autodl-tmp/Qwen/Qwen3-8B |
模型路径(位置参数) |
--served-model-name |
Qwen3-8B |
API 中使用的模型名称 |
--max_model_len |
8192 |
最大上下文长度 |
--enable-reasoning |
(无值) | 启用推理/思考模式 |
--reasoning-parser |
deepseek_r1 |
思考内容解析器 |
【反斜杠 \ 的作用】
bash
# 在 Shell 中,反斜杠 \ 用于换行续写
# 它告诉 Shell "命令还没结束,下一行是继续"
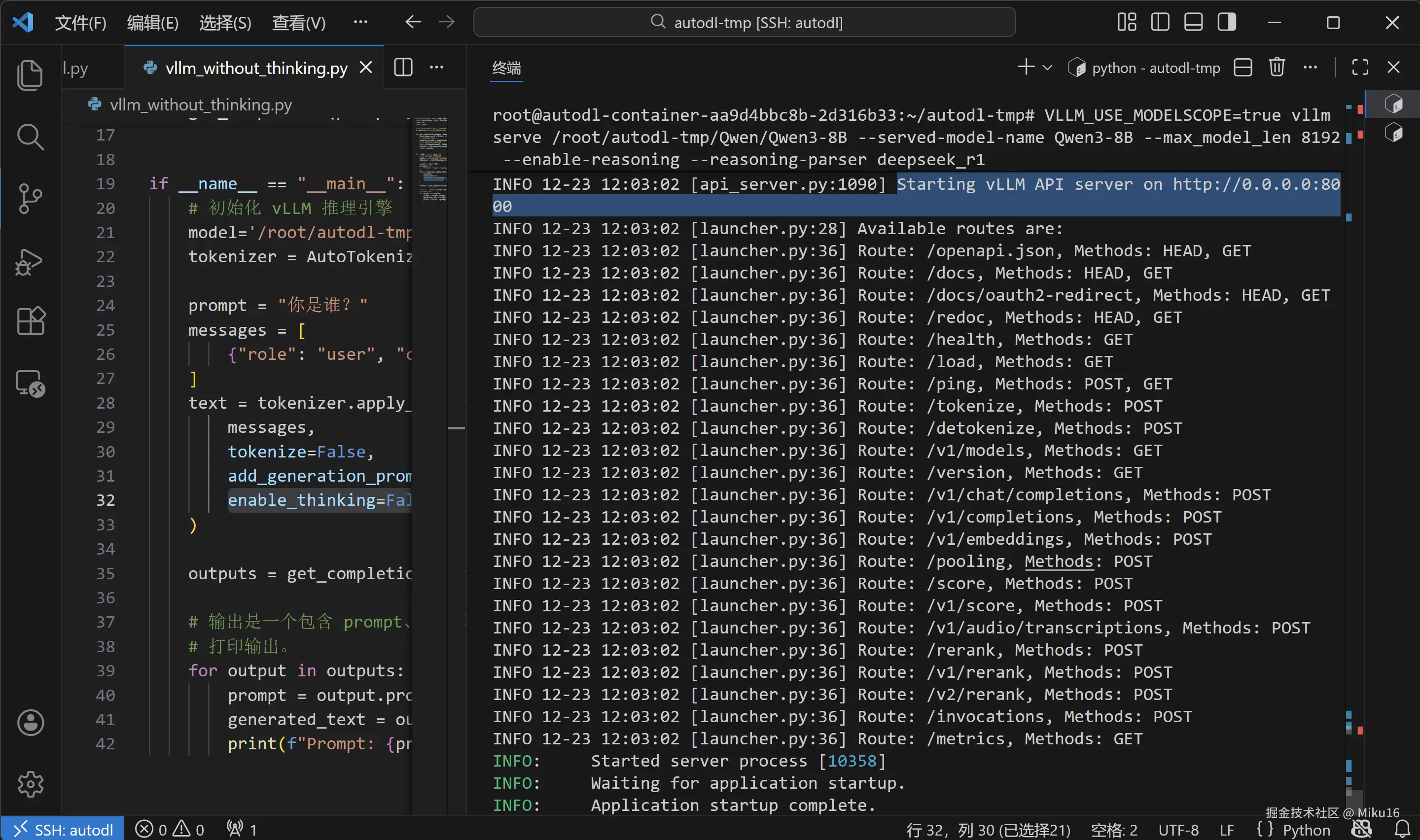
# 这样可以把很长的命令分成多行,更容易阅读7.3 启动输出说明
启动成功后,你会看到类似输出:
yaml
INFO 12-23 12:00:24 [__init__.py:239] Automatically detected platform cuda.
INFO 12-23 12:00:29 [api_server.py:1043] vLLM API server version 0.8.5.post1
...
INFO 12-23 12:03:02 [launcher.py:36] Route: /v1/chat/completions, Methods: POST
INFO 12-23 12:03:02 [launcher.py:36] Route: /v1/completions, Methods: POST
INFO 12-23 12:03:02 [launcher.py:36] Route: /v1/models, Methods: GET
...
INFO: Started server process [10358]
INFO: Waiting for application startup.
INFO: Application startup complete.API 端点说明
| 端点 | 方法 | 说明 |
|---|---|---|
/v1/models |
GET | 获取可用模型列表 |
/v1/chat/completions |
POST | 对话补全(推荐使用) |
/v1/completions |
POST | 文本补全 |
/v1/embeddings |
POST | 获取文本嵌入向量 |
/health |
GET | 健康检查 |
/metrics |
GET | Prometheus 监控指标 |
【截图:vLLM 服务器启动成功】
8. API接口测试
重要提示 :启动服务器后,需要打开一个新终端来测试 API。 服务器终端需要保持运行,不要关闭。
8.1 使用 curl 测试
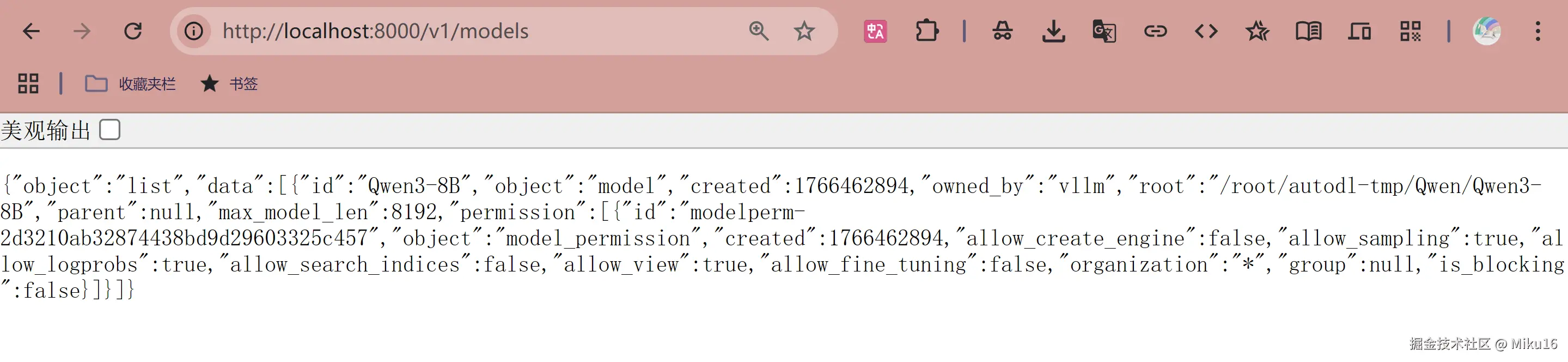
测试 1:检查模型列表
bash
# ============================================================
# 获取可用模型列表
# ============================================================
#
# 【curl 命令说明】
# curl: Client URL,命令行 HTTP 客户端工具
# 用于发送 HTTP 请求并显示响应
#
# 【命令格式】
# curl [选项] URL
#
# 这里没有额外选项,发送一个简单的 GET 请求
# ============================================================
curl http://localhost:8000/v1/models预期输出:
json
{
"object": "list",
"data": [
{
"id": "Qwen3-8B",
"object": "model",
"created": 1703318400,
"owned_by": "vllm"
}
]
}测试 2:发送对话请求
bash
# ============================================================
# 发送对话补全请求
# ============================================================
#
# 【curl 参数说明】
# -H: Header,设置 HTTP 请求头
# -d: Data,设置请求体(POST 数据)
#
# 当使用 -d 参数时,curl 自动使用 POST 方法
# ============================================================
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-8B",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己"}
]
}'预期输出(格式化后):
json
{
"id": "chat-xxx",
"object": "chat.completion",
"created": 1703318500,
"model": "Qwen3-8B",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "你好!我是通义千问...",
"reasoning_content": "用户在打招呼并询问我的身份..."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 10,
"completion_tokens": 50,
"total_tokens": 60
}
}【响应字段说明】
| 字段 | 说明 |
|---|---|
id |
请求唯一标识符 |
choices[0].message.content |
模型的回复内容 |
choices[0].message.reasoning_content |
模型的思考过程 |
usage.prompt_tokens |
输入消耗的 token 数 |
usage.completion_tokens |
输出消耗的 token 数 |
finish_reason |
结束原因(stop=正常结束) |
8.2 使用 Python 测试
创建测试脚本
在 /root/autodl-tmp/ 目录下创建 test_api.py 文件,内容如下:
python
# ============================================================
# test_api.py - vLLM API 测试脚本
# ============================================================
#
# 【脚本功能】
# 使用 OpenAI Python SDK 调用 vLLM 服务器
#
# 【文件路径】
# /root/autodl-tmp/test_api.py
#
# 【为什么能用 OpenAI SDK?】
# vLLM 的 API 与 OpenAI API 格式完全兼容
# 只需要修改 base_url 指向本地服务器即可
# 这意味着任何使用 OpenAI API 的代码,几乎不用修改就能用 vLLM
# ============================================================
# ============================================================
# 导入 OpenAI 客户端
# ============================================================
from openai import OpenAI
#
# 【安装方式】
# pip install openai
#
# 【说明】
# openai 是 OpenAI 官方 Python SDK
# 虽然叫 "openai",但它可以连接任何兼容的 API 服务器
# ============================================================
# 创建客户端
# ============================================================
client = OpenAI(
base_url="http://localhost:8000/v1", # API 基础地址
api_key="sk-xxx" # API 密钥
)
#
# 【参数说明】
#
# base_url: API 的基础 URL
# - 默认值是 "https://api.openai.com/v1"(OpenAI 官方)
# - 修改为本地 vLLM 服务器地址
# - localhost:8000 是 vLLM 默认监听的地址和端口
# - /v1 是 API 版本路径
#
# api_key: API 密钥
# - 调用 OpenAI 官方需要真实的 API Key
# - 调用 vLLM 不验证密钥,但参数不能省略
# - 随便填一个字符串即可,如 "sk-xxx"
# ============================================================
# 发送对话请求
# ============================================================
chat_outputs = client.chat.completions.create(
model="Qwen3-8B",
messages=[
{"role": "user", "content": "什么是深度学习?"}
]
)
#
# 【方法调用链说明】
# client.chat.completions.create(...)
#
# 结构:
# - client: OpenAI 客户端对象
# - .chat: 聊天相关的 API 命名空间
# - .completions: 补全相关的操作
# - .create(): 创建一个新的对话补全
#
# 【参数说明】
#
# model: str(必需)
# - 要使用的模型名称
# - 必须与 vLLM 启动时的 --served-model-name 一致
#
# messages: list[dict](必需)
# - 对话消息列表
# - 每个消息是字典,包含 role 和 content
# ============================================================
# 打印完整响应
# ============================================================
print("【完整响应对象】")
print(chat_outputs)
# ============================================================
# 提取主要内容
# ============================================================
print("\n" + "=" * 50)
print("【模型回复】")
print(chat_outputs.choices[0].message.content)
#
# 【访问响应内容】
# chat_outputs.choices[0].message.content
#
# 层级结构:
# chat_outputs # ChatCompletion 对象
# .choices # 选项列表(通常只有一个)
# [0] # 第一个选项(索引从 0 开始)
# .message # 消息对象
# .content # 消息文本内容
# ============================================================
# 获取思考过程(如果有)
# ============================================================
# hasattr(对象, 属性名): 检查对象是否有某个属性
# 返回 True 或 False
if hasattr(chat_outputs.choices[0].message, 'reasoning_content'):
reasoning = chat_outputs.choices[0].message.reasoning_content
# 检查 reasoning 是否有值(不是 None 或空字符串)
if reasoning:
print("\n【思考过程】")
print(reasoning)运行测试脚本
bash
python /root/autodl-tmp/test_api.py预期输出:
ini
【完整响应对象】
ChatCompletion(id='chat-xxx', choices=[...], model='Qwen3-8B', ...)
==================================================
【模型回复】
深度学习是机器学习的一个分支,它使用多层神经网络...
【思考过程】
用户在询问深度学习的定义。我需要给出一个清晰、准确的解释...8.3 简洁版 OpenAI SDK 测试脚本
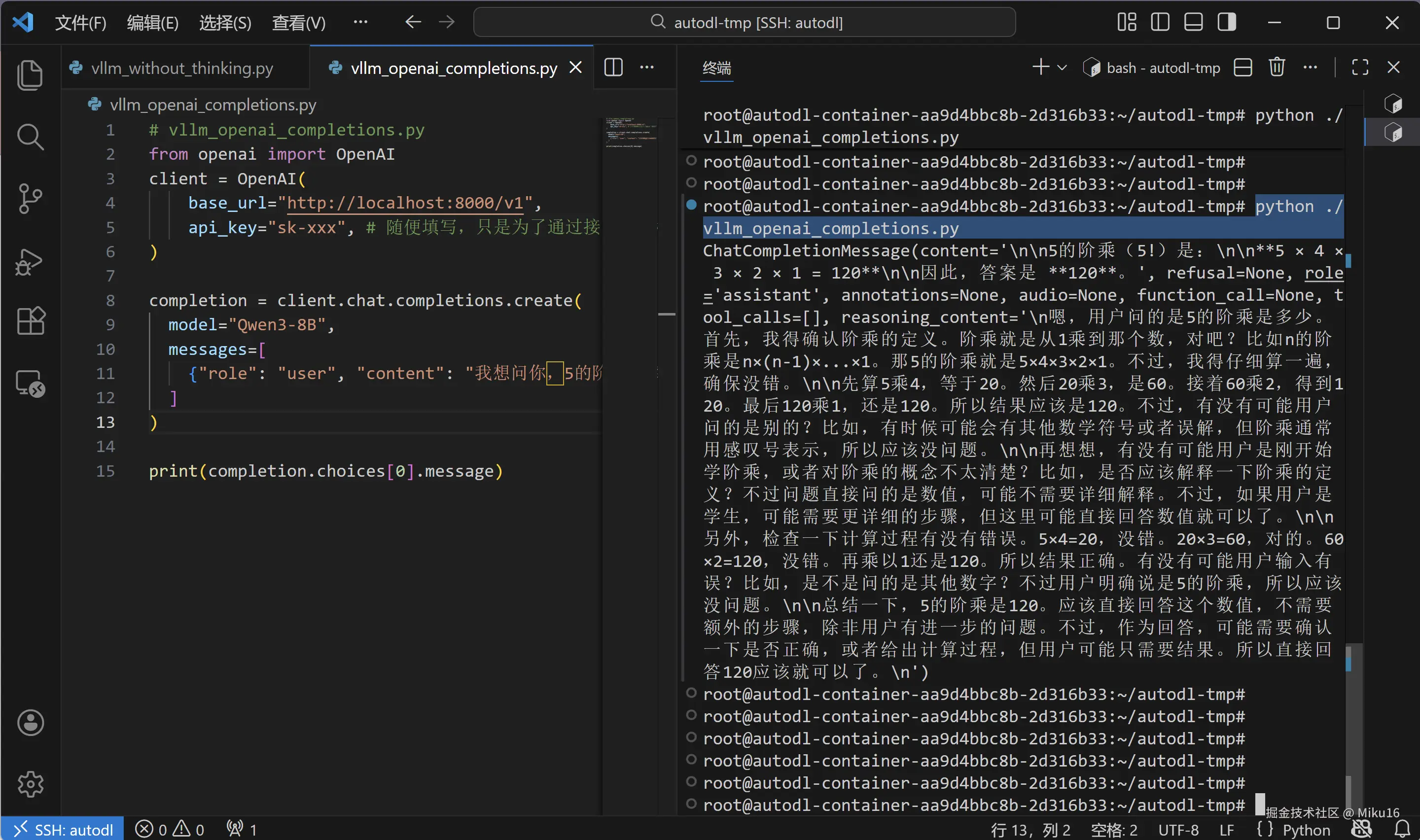
vllm_openai_completions.py
在 /root/autodl-tmp/ 目录下创建 vllm_openai_completions.py 文件,这是一个启用思考模式的简洁版本:
python
# ============================================================
# vllm_openai_completions.py - 简洁版 OpenAI SDK 测试(启用思考模式)
# ============================================================
#
# 【文件路径】
# /root/autodl-tmp/vllm_openai_completions.py
#
# 【特点】
# - 代码简洁,适合快速测试
# - 在 content 末尾添加 <think>\n 触发思考模式
# ============================================================
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="sk-xxx", # 随便填写,只是为了通过接口参数校验
)
completion = client.chat.completions.create(
model="Qwen3-8B",
messages=[
{"role": "user", "content": "我想问你,5的阶乘是多少?<think>\n"}
# ============================================================
# 【思考模式触发方式】
# 在 content 末尾添加 <think>\n 可以触发模型的思考模式
# 模型会先进行推理思考,然后给出答案
# ============================================================
]
)
print(completion.choices[0].message)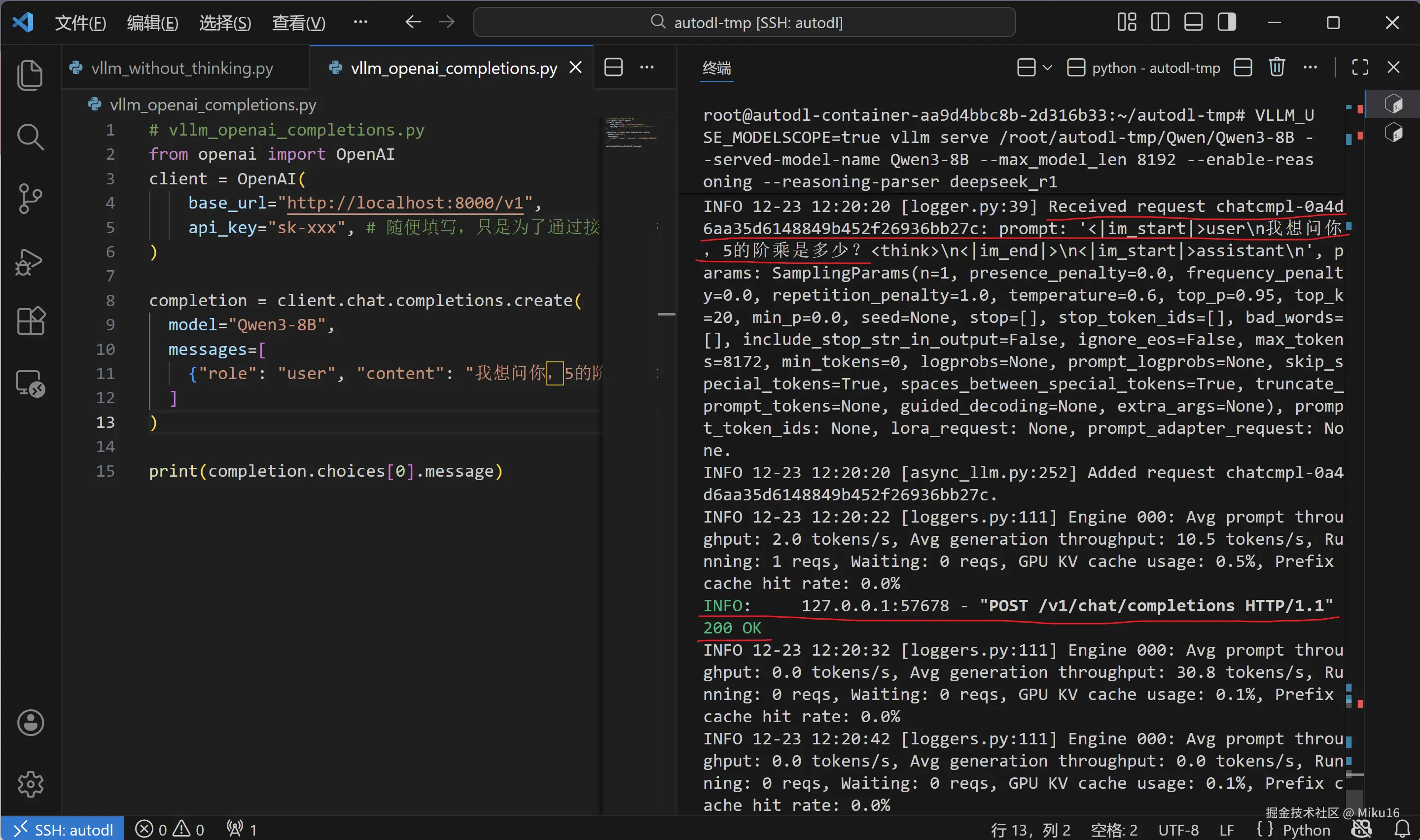
vllm_openai_chat_completions.py
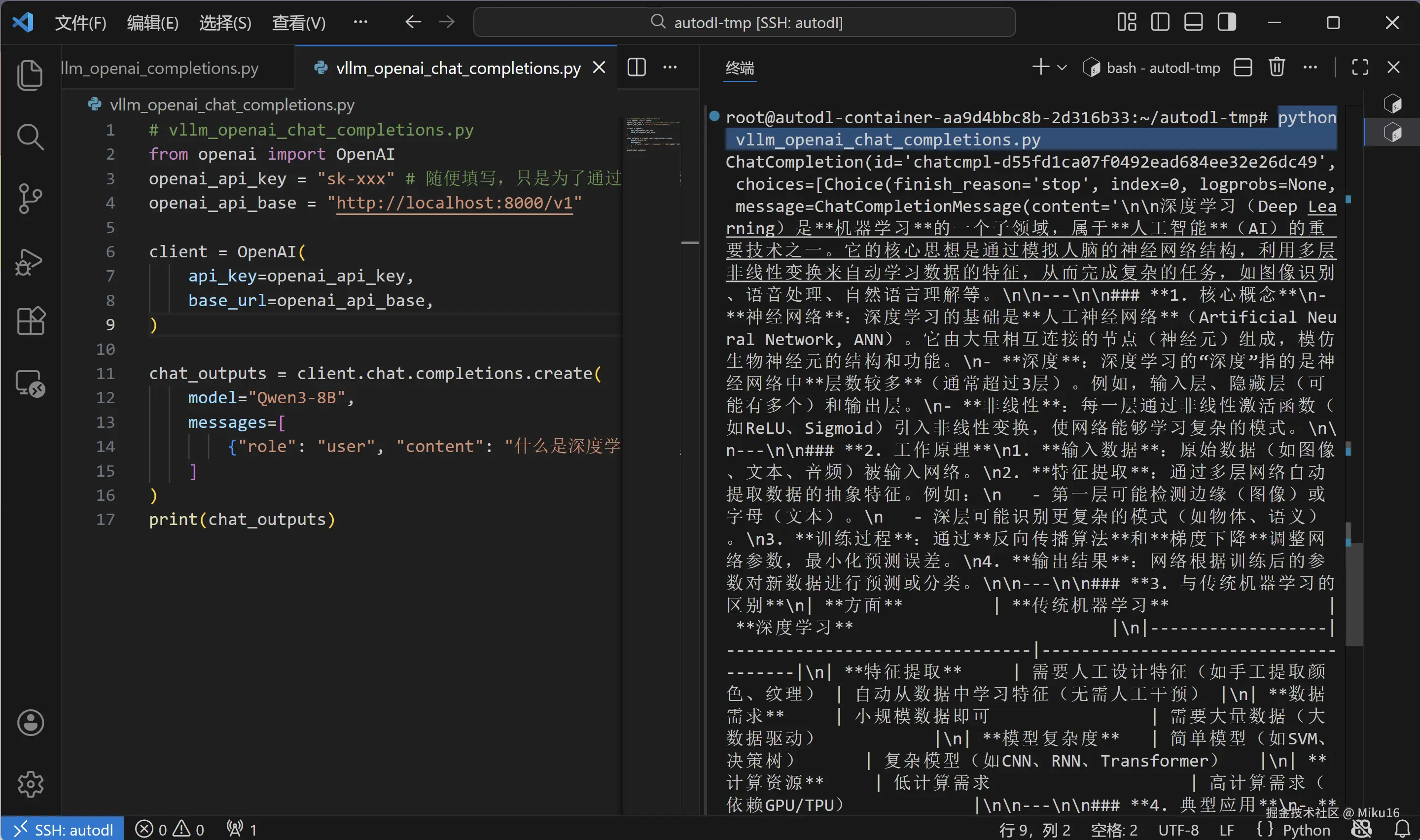
在 /root/autodl-tmp/ 目录下创建 vllm_openai_chat_completions.py 文件,这是另一个简洁版本:
python
# ============================================================
# vllm_openai_chat_completions.py - 简洁版 OpenAI SDK Chat 测试
# ============================================================
#
# 【文件路径】
# /root/autodl-tmp/vllm_openai_chat_completions.py
#
# 【特点】
# - 使用变量存储 API 配置,便于修改
# - 不启用思考模式的普通对话测试
# ============================================================
from openai import OpenAI
openai_api_key = "sk-xxx" # 随便填写,只是为了通过接口参数校验
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_outputs = client.chat.completions.create(
model="Qwen3-8B",
messages=[
{"role": "user", "content": "什么是深度学习?"},
]
)
print(chat_outputs)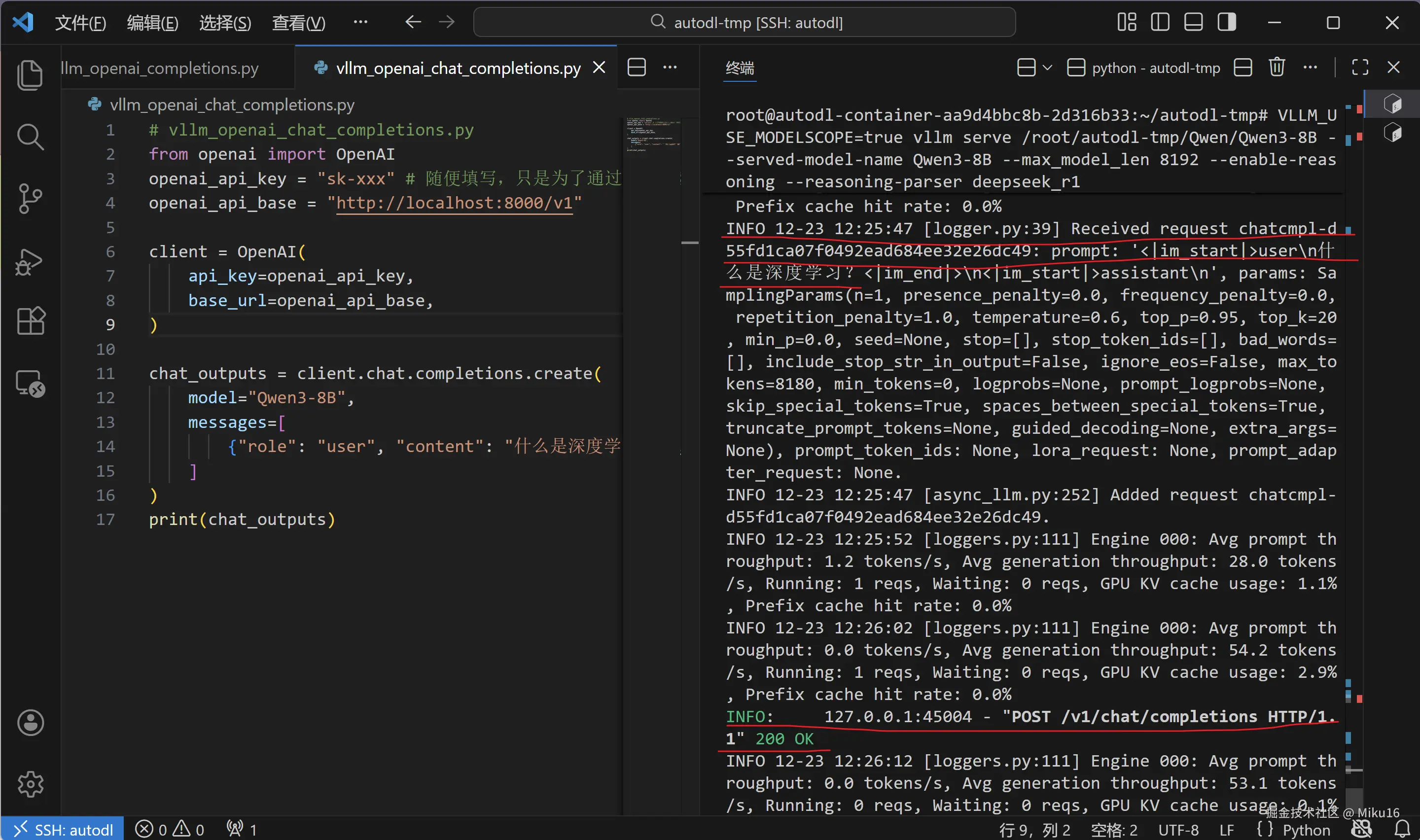
【三个 API 测试脚本对比】
| 脚本名称 | 功能 | 思考模式 | 输出内容 |
|---|---|---|---|
test_api.py |
完整版测试 | 由服务器配置决定 | 完整响应 + 提取内容 + 思考过程 |
vllm_openai_completions.py |
简洁版 | 是(手动触发) | 只打印 message |
vllm_openai_chat_completions.py |
简洁版 | 否 | 只打印完整响应 |
9. 常见问题与解决
9.1 环境相关问题
问题 1:NumPy 版本冲突
错误信息:
bash
ValueError: All ufuncs must have type numpy.ufunc解决方案:
bash
pip install numpy==1.26.4 scipy==1.13.1 --force-reinstall问题 2:Numba 不兼容
错误信息:
makefile
ImportError: Numba needs NumPy 2.2 or less. Got NumPy 2.4.解决方案:
bash
pip install numpy==2.2.0 --force-reinstall问题 3:递归深度超限
错误信息:
makefile
RecursionError: maximum recursion depth exceeded解决方案:
bash
pip install scikit-learn --force-reinstall9.2 模型下载问题
问题 4:下载速度慢
解决方案:
- 开启 AutoDL 学术加速:
bash
source /etc/network_turbo- 使用后台下载:
bash
# nohup: no hangup,忽略挂断信号,命令在后台运行
# > download.log: 将标准输出重定向到文件
# 2>&1: 将标准错误也重定向到同一文件
# &: 放到后台运行
nohup python model_download.py > download.log 2>&1 &
# 查看下载进度
tail -f download.log
# tail -f: 实时显示文件末尾的新内容
# 按 Ctrl+C 退出查看(不会停止下载)9.3 推理问题
问题 5:显存不足(OOM)
错误信息:
csharp
torch.cuda.OutOfMemoryError: CUDA out of memory解决方案:
bash
# 方案 1:减小上下文长度
vllm serve ... --max_model_len 4096
# 方案 2:降低 GPU 显存利用率
vllm serve ... --gpu-memory-utilization 0.8问题 6:API 服务器无响应
检查步骤:
bash
# 1. 检查服务器是否运行
ps aux | grep vllm
# 2. 检查端口是否监听
netstat -tlnp | grep 8000
# 3. 测试健康检查接口
curl http://localhost:8000/health9.4 为什么不能在 Colab 中运行?
问题:vLLM 在 Jupyter Notebook 中报错
错误信息:
makefile
RuntimeError: Cannot re-initialize CUDA in forked subprocess原因解释:
Jupyter Notebook 使用 fork() 创建子进程,但 CUDA 不允许在 fork 后的进程中重新初始化。vLLM 需要多进程工作,这与 Notebook 环境不兼容。
解决方案:使用提供终端环境的平台(如 AutoDL)
10. 学习总结
10.1 完成的任务清单
| 步骤 | 内容 | 状态 |
|---|---|---|
| 1 | 创建 AutoDL 实例(RTX 4090 24GB) | Done |
| 2 | 配置 VS Code 远程 SSH 连接 | Done |
| 3 | 修复环境依赖问题(numpy 2.2.0) | Done |
| 4 | 下载 Qwen3-8B 模型(~16GB) | Done |
| 5 | Python 脚本推理测试(思考模式) | Done |
| 6 | 启动 vLLM OpenAI 兼容 API 服务器 | Done |
| 7 | 使用 curl 和 Python 测试 API | Done |
10.2 核心知识点回顾
Python 语法速查表
| 语法 | 示例 | 说明 |
|---|---|---|
| 变量赋值 | x = 10 |
不需要声明类型 |
| 字符串 | "hello" 或 'hello' |
单引号双引号等价 |
| 列表 | [1, 2, 3] |
有序集合,可修改 |
| 字典 | {"key": "value"} |
键值对集合 |
| 导入模块 | import os |
导入整个模块 |
| 导入部分 | from os import path |
只导入特定内容 |
| 函数定义 | def func(arg): |
定义函数 |
| 默认参数 | def func(x=10): |
参数有默认值 |
| f-string | f"值是{x}" |
格式化字符串 |
| for 循环 | for i in list: |
遍历可迭代对象 |
| if 条件 | if x > 0: |
条件判断 |
| 索引访问 | list[0] |
获取第一个元素 |
| 属性访问 | obj.attr |
获取对象属性 |
| 方法调用 | obj.method() |
调用对象方法 |
采样参数对照表
| 参数 | 思考模式 | 非思考模式 | 说明 |
|---|---|---|---|
temperature |
0.6 | 0.7 | 控制随机性 |
top_p |
0.95 | 0.8 | 核采样阈值 |
top_k |
20 | 20 | 候选 token 数 |
enable_thinking |
True | False | 是否显示思考过程 |
10.3 关键命令速查
bash
# ==================== 环境修复 ====================
# 修复 numpy 版本
pip install numpy==2.2.0 --force-reinstall
# 验证 vLLM
vllm --version
# ==================== 模型下载 ====================
# 下载模型
cd /root/autodl-tmp && python model_download.py
# 查看模型文件
ls -lh /root/autodl-tmp/Qwen/Qwen3-8B/
# ==================== 推理测试 ====================
# Python 脚本推理
python /root/autodl-tmp/vllm_model.py
# ==================== API 服务器 ====================
# 启动服务器
VLLM_USE_MODELSCOPE=true vllm serve /root/autodl-tmp/Qwen/Qwen3-8B \
--served-model-name Qwen3-8B \
--max_model_len 8192 \
--enable-reasoning \
--reasoning-parser deepseek_r1
# 测试 API(在新终端)
curl http://localhost:8000/v1/models
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "Qwen3-8B", "messages": [{"role": "user", "content": "你好"}]}'
# Python 测试
python /root/autodl-tmp/test_api.py
# ==================== 服务器管理 ====================
# 停止服务器:在服务器终端按 Ctrl+C
# 后台运行服务器
nohup vllm serve ... > vllm.log 2>&1 &
# 查看后台进程
ps aux | grep vllm
# 终止后台进程
kill <进程ID>10.4 下一步学习建议
-
尝试其他模型
- Qwen2.5-7B-Instruct(更小,速度更快)
- DeepSeek-R1-Distill(强推理能力)
- Llama-3-8B(英文能力强)
-
学习模型量化
- 使用 AWQ/GPTQ 量化减少显存占用
- INT4 量化可以在 8GB 显存上运行 8B 模型
-
构建应用
- 使用 Gradio 创建 Web 聊天界面
- 使用 LangChain 构建 RAG 应用
- 集成到你自己的项目中
-
学习微调
- 使用 LoRA 进行高效微调
- 定制你自己的领域模型
参考资料
本文档基于 2025 年 12 月 23 日的实践编写 vLLM 版本:0.8.5.post1 模型:Qwen/Qwen3-8B 平台:AutoDL RTX 4090 24GB