https://blog.csdn.net/weixin_45655710?type=blog
@浙大疏锦行
DAY 33 MLP 神经网络的训练
知识点回顾:
- PyTorch和桃的安装
2.查看显卡信息的命令行命令(cmd中使用)
3.桃的检查
4.简单神经网络的流程
a.数据预处理(归一化、转换成张量)
b.模型的定义
i.继承nn.Module类
ii.定义每一个层
iii.定义前向传播流程
c.定义损失函数和优化器
d.定义训练流程
e.可视化loss过程
你今天主要学习了基于PyTorch框架实现多层感知机(MLP)来解决鸢尾花分类问题的完整流程,涵盖了环境配置、数据处理、模型构建和训练的核心环节。
核心内容梳理
1. 环境准备与CUDA检查
- 环境配置 :创建了名为
DL的conda环境(Python 3.8),安装了pytorch、scikit-learn等核心依赖;区分了CPU/GPU版本的PyTorch安装,GPU版本需依赖NVIDIA显卡的CUDA/CUDNN组件。 - CUDA验证 :通过
nvidia-smi命令查看显卡支持的最高CUDA版本和显存,通过PyTorch代码检查CUDA是否可用、设备数量/名称、实际安装的CUDA版本。
2. 数据预处理(鸢尾花数据集)
- 加载数据集并划分训练集/测试集(测试集占比20%);
- 对特征数据做MinMaxScaler归一化(神经网络对输入尺度敏感,需统一范围);
- 将NumPy数组转换为PyTorch张量(特征为
FloatTensor,标签为LongTensor,适配分类任务)。
3. MLP模型定义
- 继承
nn.Module构建自定义MLP类,包含:- 输入层(
nn.Linear(4, 10)):4个特征→10个隐藏神经元; - 激活函数(ReLU):引入非线性,解决线性模型表达能力不足的问题;
- 输出层(
nn.Linear(10, 3)):10个隐藏神经元→3个分类结果(无激活,因交叉熵损失内置Softmax);
- 输入层(
- 实现
forward方法定义前向传播逻辑(两种写法:显式调用ReLU层/直接用torch.relu)。
4. 模型训练(CPU版本)
- 损失函数:选用
nn.CrossEntropyLoss(适配多分类任务); - 优化器:可选SGD(固定学习率0.01)或Adam(自适应学习率0.001);
- 训练循环核心步骤:
- 前向传播:模型预测训练集输出;
- 计算损失:预测值与真实标签的误差;
- 反向传播:
optimizer.zero_grad()清零梯度(避免累积)→loss.backward()计算梯度→optimizer.step()更新参数; - 记录并打印每100轮的损失值,最后可视化损失曲线。
总结
- 核心流程:深度学习项目的基础范式是「环境配置→数据预处理→模型定义→损失/优化器设置→训练迭代→结果可视化」;
- 关键细节 :神经网络需归一化输入、分类任务标签用
LongTensor、输出层无需激活(交叉熵损失内置Softmax)、训练时必须清零梯度; - 硬件适配:GPU(NVIDIA)通过CUDA加速并行计算,无NVIDIA显卡可先用CPU版本训练,后续迁移到云服务器GPU。
这些内容覆盖了PyTorch实现简单神经网络的全流程,是后续复杂深度学习项目的基础,重点要理解梯度下降、激活函数、损失函数在训练中的作用。
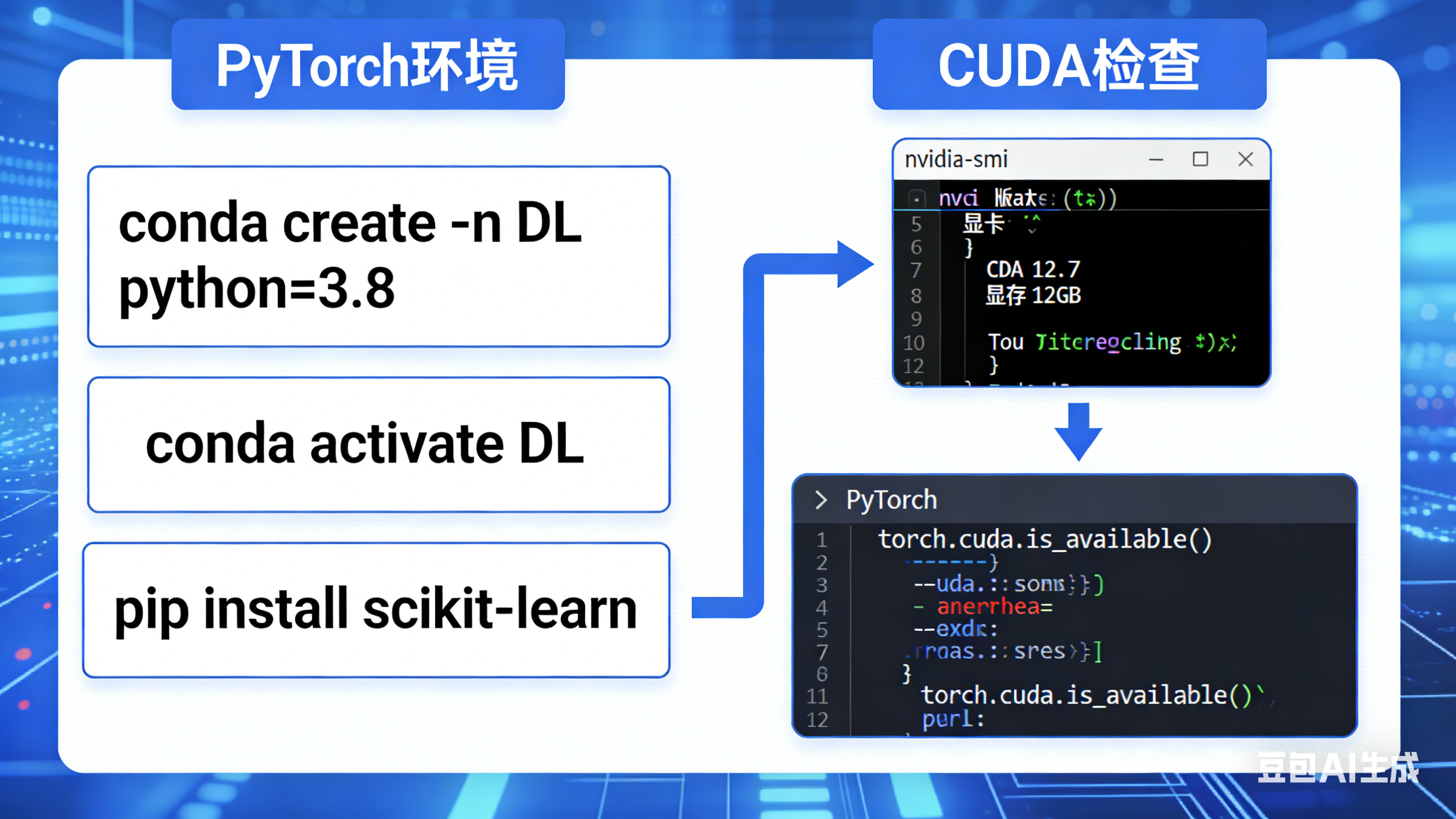
图1:PyTorch环境配置与CUDA检查流程图。展示从创建conda环境到验证CUDA可用性的完整步骤,包含关键命令和代码片段。
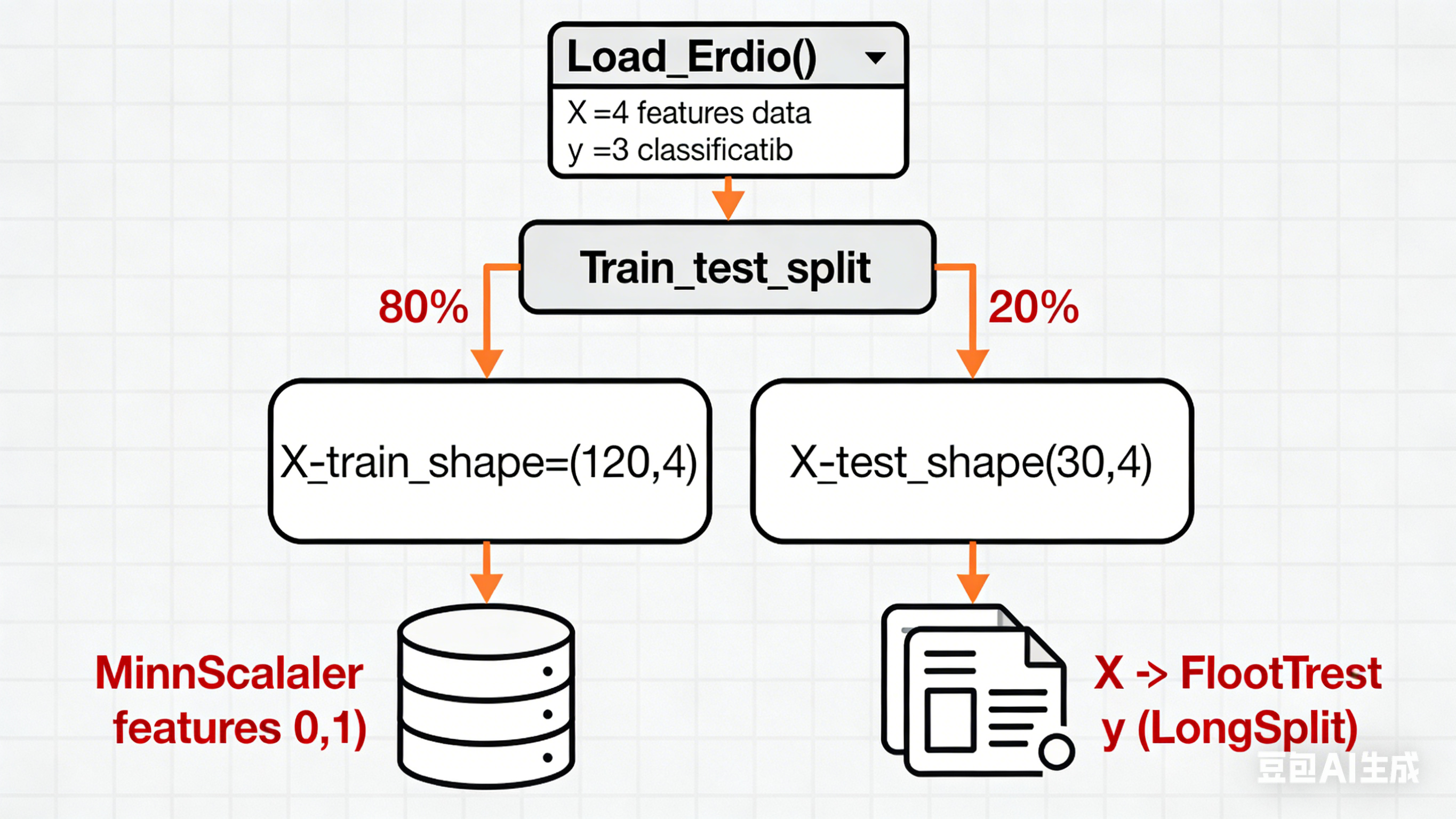
图2:鸢尾花数据集预处理流程图。呈现从数据加载、划分、归一化到张量转换的全过程,标注数据维度变化。
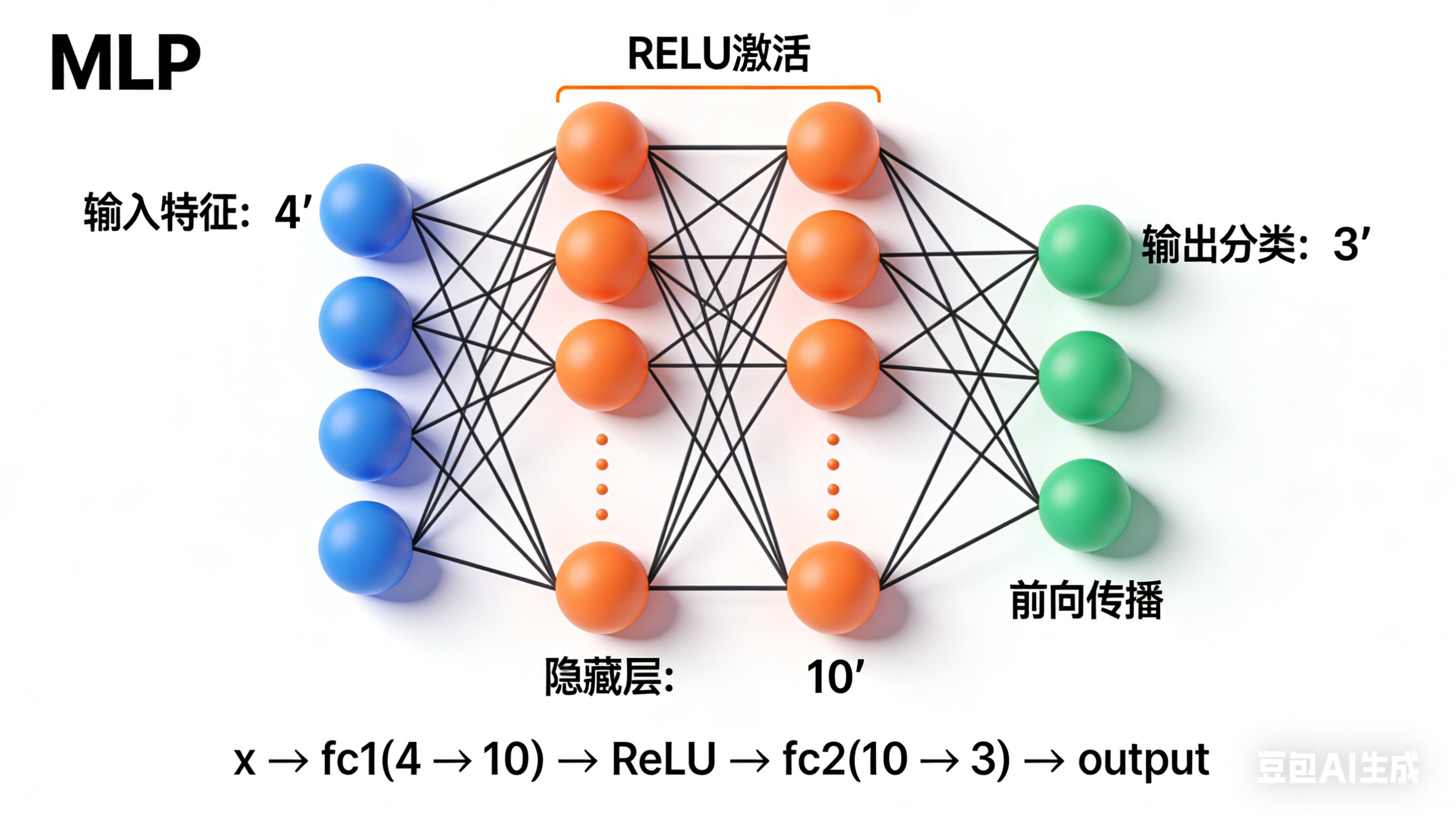
图3:MLP模型架构图。可视化三层神经网络结构,标注各层输入输出维度和激活函数位置。
图4:模型训练循环流程图。展示前向传播、损失计算、反向传播和参数更新的迭代过程,包含关键代码片段。