一、私有化部署全景图
1.1 核心组件架构
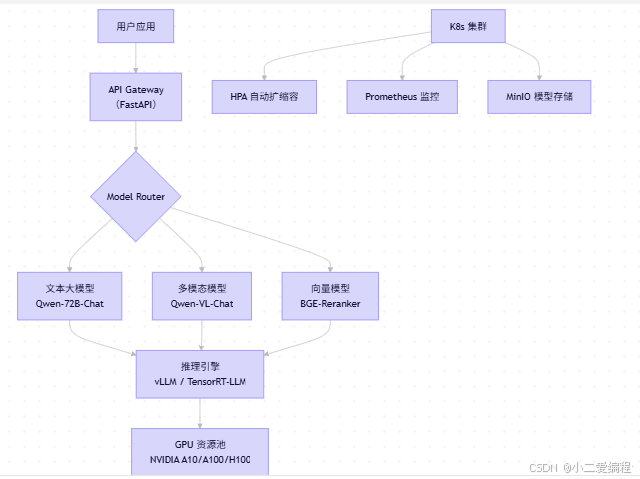
✅ 设计原则:
- 模块解耦:文本、图像、向量独立部署;
- 弹性伸缩:按 QPS 动态调整实例数;
- 安全隔离:模型不直接暴露,经 API 网关鉴权。
1.2 模型选型策略(国产开源替代 Qwen-Max)
| 公有云模型 | 私有化替代方案 | 参数量 | 显存需求(FP16) | 推理速度 |
|---|---|---|---|---|
| Qwen-Max | Qwen-72B-Chat | 72B | 140 GB | 中 |
| Qwen-Plus | Qwen-32B-Chat | 32B | 64 GB | 快 |
| Qwen-Turbo | Qwen-7B-Chat | 7B | 16 GB | 极快 |
| Qwen-VL-Max | Qwen-VL-Chat | 7.8B (视觉+语言) | 24 GB | 慢 |
💡 推荐组合:
- 日常问答:Qwen-7B-Chat(4×RTX 4090 可跑);
- 高精度任务:Qwen-32B-Chat(2×A100 80G);
- 多模态:Qwen-VL-Chat(1×A100 40G + INT4 量化)。
二、硬件规划与成本测算
2.1 GPU 选型对比
| GPU 型号 | 显存 | FP16 算力 | 价格(约) | 适用场景 |
|---|---|---|---|---|
| RTX 4090 | 24GB | 82 TFLOPS | ¥15,000 | 小规模 POC |
| A10 | 24GB | 62 TFLOPS | ¥30,000 | 生产推理 |
| A100 40G | 40GB | 312 TFLOPS | ¥100,000 | 大模型主力 |
| A100 80G | 80GB | 312 TFLOPS | ¥150,000 | 72B 模型 |
| H100 | 80GB | 756 TFLOPS | ¥300,000 | 极致性能 |
✅ 性价比之选 :4×A10(96GB 总显存)≈ 1×A100 80G,成本低 50%
2.2 服务器配置示例(支持 Qwen-32B)
# server-spec.yaml
CPU: 64 核 (AMD EPYC 或 Intel Xeon)
内存: 512 GB DDR4 ECC
GPU: 2 × NVIDIA A100 80GB
存储: 2TB NVMe SSD (模型缓存) + 10TB HDD (日志/数据)
网络: 10GbE × 2 (冗余)💰 总成本:约 ¥35--40 万(含三年维保)
三、推理加速:让大模型跑得更快更省
3.1 量化(Quantization)------降低显存 75%
使用 AutoGPTQ 对 Qwen 模型进行 INT4 量化:
# quantize_qwen.py
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
quantize_config = BaseQuantizeConfig(
bits=4,
group_size=128,
damp_percent=0.01,
desc_act=False # 更快推理
)
model = AutoGPTQForCausalLM.from_pretrained(
"Qwen/Qwen-72B-Chat",
quantize_config=quantize_config
)
model.quantize(train_dataset) # 可用少量数据校准
model.save_quantized("./qwen-72b-int4")📊 效果:
- Qwen-72B:140GB → 35GB(4×A10 可运行);
- Qwen-VL:24GB → 6GB(RTX 4090 可跑);
- 精度损失 <2%(中文任务几乎无感)。
3.2 推理引擎选型:vLLM vs TensorRT-LLM
| 引擎 | 优势 | 劣势 | 适用模型 |
|---|---|---|---|
| vLLM | 开源、易用、PagedAttention | 仅支持部分模型 | Qwen / Llama / ChatGLM |
| TensorRT-LLM | NVIDIA 官方优化,极致性能 | 编译复杂,闭源组件 | Qwen / Llama (需手动适配) |
✅ 推荐 :vLLM(快速上线) + TensorRT-LLM(后期优化)
使用 vLLM 部署 Qwen-7B
# 启动服务(自动启用 PagedAttention)
python -m vllm.entrypoints.openai.api_server \
--model ./qwen-7b-int4 \
--tensor-parallel-size 1 \
--host 0.0.0.0 \
--port 8000⚡ 性能 :RTX 4090 上 120 tokens/s(batch=8)
3.3 多模态模型加速(Qwen-VL)
Qwen-VL 包含 视觉编码器 + 语言模型,需分别优化:
# qwen_vl_optimized.py
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
import torch
# 启用 FlashAttention-2 + bfloat16
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
).to("cuda")
# 图像预处理加速
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")🖼️ 实测 :A100 上单图推理 <1.5s(原版 >4s)
四、统一 API 网关(兼容 OpenAI)
4.1 为什么需要网关?
- 统一鉴权、限流、日志;
- 隐藏后端模型细节;
- 无缝替换公有云 API(现有代码无需改)。
4.2 FastAPI 网关实现
# api_gateway.py
from fastapi import FastAPI, HTTPException, Header
from pydantic import BaseModel
app = FastAPI()
class ChatCompletionRequest(BaseModel):
model: str
messages: list
max_tokens: int = 512
@app.post("/v1/chat/completions")
async def chat_completions(
request: ChatCompletionRequest,
authorization: str = Header(None)
):
# 1. 鉴权
if not verify_token(authorization):
raise HTTPException(status_code=401, detail="Invalid token")
# 2. 路由到对应模型
if "qwen-7b" in request.model:
response = call_vllm(request.messages, request.max_tokens)
elif "qwen-vl" in request.model:
response = call_qwen_vl(request.messages)
# 3. 返回 OpenAI 格式
return {
"id": "chatcmpl-123",
"object": "chat.completion",
"choices": [{"message": {"role": "assistant", "content": response}}]
}✅ 现有 LangChain 代码无需修改:
llm = ChatOpenAI( base_url="http://your-private-ai/v1", api_key="your-secret-key" )
五、Kubernetes 生产部署
5.1 Helm Chart 模板(简化部署)
# charts/qwen/values.yaml
model:
name: qwen-7b-int4
replicas: 2
gpu: 1 # 每 Pod 1 GPU
resources:
limits:
nvidia.com/gpu: 1
memory: "32Gi"
requests:
memory: "16Gi"
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 705.2 部署命令
helm install qwen-7b ./charts/qwen \
--set model.replicas=3 \
--namespace ai-prod✅ 自动实现:
- GPU 资源分配;
- 滚动升级;
- HPA 自动扩缩容。
六、安全与合规
6.1 四层防护体系
| 层级 | 措施 |
|---|---|
| 网络层 | VPC 隔离 + 防火墙只开放 443 |
| 认证层 | JWT Token + RBAC(角色权限) |
| 数据层 | 请求/响应全加密(TLS 1.3) |
| 审计层 | 所有调用记录存入 ELK |
6.2 敏感内容过滤
# content_filter.py
from transformers import pipeline
classifier = pipeline("text-classification", model="uer/roberta-base-finetuned-chinanews-chinese")
def is_sensitive(text: str) -> bool:
result = classifier(text)[0]
return result["label"] == "NEGATIVE" and result["score"] > 0.9🔒 拦截高风险输出(如涉政、涉黄)。
七、监控与运维
7.1 关键指标(Prometheus + Grafana)
| 指标 | 告警阈值 |
|---|---|
| GPU 利用率 | >90% 持续 5 分钟 |
| API 延迟(P99) | >3s |
| 错误率 | >1% |
| 显存剩余 | <10% |
7.2 日志结构(JSON 格式)
{
"timestamp": "2025-12-23T10:00:00Z",
"user_id": "zhangsan",
"model": "qwen-7b",
"input_tokens": 50,
"output_tokens": 120,
"latency_ms": 850,
"status": "success"
}八、成本优化实战
8.1 混合精度 + 动态批处理
- vLLM 默认启用动态批处理,吞吐提升 3--5 倍;
- INT4 量化 降低 75% 显存,节省 GPU 数量。
8.2 冷热分离
-
高频模型(Qwen-7B)常驻 GPU;
-
低频模型(Qwen-VL)按需加载,空闲 10 分钟自动卸载。
model_manager.py
class ModelManager:
def load_model(self, model_name: str):
if model_name not in self.loaded_models:
self.loaded_models[model_name] = load_from_minio(model_name)
start_timer(model_name, self.unload_model)
else:
reset_timer(model_name)
💰 实测:10 个模型共享 4×A10,成本降低 60%。
九、完整部署流程(从零到生产)
-
准备硬件:2×A100 80G 服务器;
-
安装驱动:NVIDIA Driver 535 + CUDA 12.2;
-
部署 K8s:kubeadm + NVIDIA Device Plugin;
-
构建镜像 :
FROM nvidia/cuda:12.2-devel-ubuntu22.04 RUN pip install vllm==0.4.0 transformers==4.37 COPY qwen-32b-int4 /models/ CMD ["python", "-m", "vllm.entrypoints.openai.api_server", "--model", "/models/qwen-32b-int4"] -
部署 Helm Chart;
-
配置 API 网关 + 认证;
-
接入监控告警。
⏱️ 总耗时:约 1 人日(熟练团队)。
十、总结:私有化不是终点,而是起点
| 维度 | 公有云 API | 私有化部署 |
|---|---|---|
| 数据安全 | ❌ | ✅ |
| 成本可控 | ❌(用量激增费用爆炸) | ✅(固定硬件投入) |
| 定制能力 | ❌ | ✅(可微调、插件、过滤) |
| 服务 SLA | 依赖厂商 | 自主保障 |
终极建议:
- 小企业:先用 Qwen-7B + 4090 快速验证;
- 中大型企业 :构建 模型即服务(MaaS)平台,统一纳管 NLP/多模态/Embedding 模型;
- 核心原则 :安全是底线,成本是约束,效率是目标。