一.导语
本文主要介绍了神经网络模型训练的基本步骤,主要使用了PyTorch 库,基于Python3的神经网络模型训练。且简要提供了前端GUI操作程序,让训练好的模型得以第一时间发挥作用。最后放有完整源码,可以直接使用,确保放在同一个文件夹里即可。
成果如下
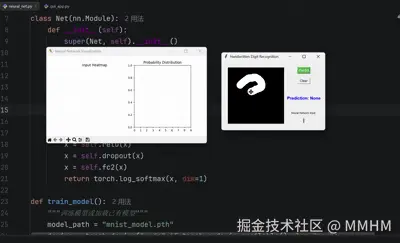
本文目的在于通过这个实际项目,让大家得以理解神经网络的基本结构,和训练过程,以及弄清楚中间发生了什么,理解代码的内容。
话不多说,现在就让我们开始学习!
二.准备必要的库
1.首先需要准备这几个库
javascript
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import os解释一下
1.torch库 可以理解为门用来造 AI 的工具箱
2.torchvision库 计算机视觉工具包,用于下载数据集和处理图片
3.os库 可以理解为文件管理员
三.定义神经网络的结构和思考方式
1.初始化结构
ruby
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
self.fc2 = nn.Linear(128, 10)解释一下
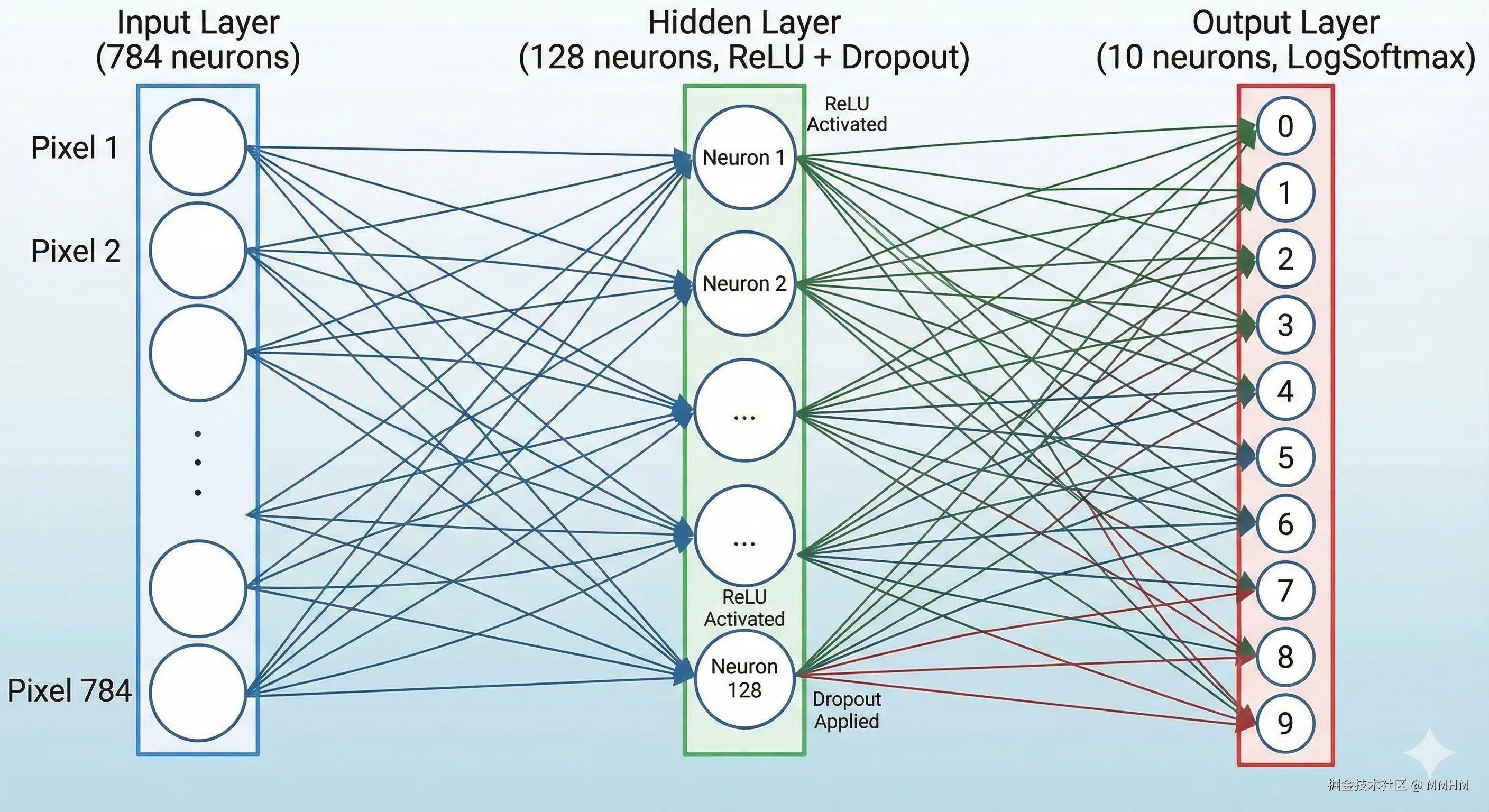
1.self.fc1 = nn.Linear(28 * 28, 128)
这段是输入层 到隐藏层的连接,其中(28*28)是可识别的分辨率,128是隐藏层神经元的数量
2.self.relu = nn.ReLU()
这个是激活函数 ,目的就是过滤掉一些'杂波'的影响,减小其对训练的干扰,相当于给数据增加了一个可被识别的阈值。更重要的是引入非线性,把直线变成折线,让神经网络能够描绘出复杂的形状(比如数字的弯曲边缘)。
3.self.dropout = nn.Dropout(0.2)
这是为了干扰网络训练的机制,目的是防止网络死记硬背从而影响学习效率。0.2 意味着在训练时,随机让 20% 的神经元"罢工" (输出变为 0)。可以让网络学会通过整体特征来认字,极大地防止过拟合。
4.self.fc2 = nn.Linear(128, 10)
这段是隐藏层 到输出层 的连接,其中128是接收那 128 个神经元处理后的特征。10是输出0-9的结果。
最后的结构大致是这样
2.前向传播
ini
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return torch.log_softmax(x, dim=1)可以看作是模型的思考过程,下面解释一下都做了哪些处理,发生了什么
我们的手写图片传入进来时,是一张28*28的方块图像,而我们的fc1()函数识别不了这个大方块。于是我们使用x = x.view(-1, 28 * 28)把这个大方块变为长条形 来让fc1()函数识别。-1表示把每张图都压成 784 的长度,来对图片进行预处理。接着以下都是调用我们上面写的方法self.fc1(),self.relu(),self.dropout(),self.fc2()来处理每一个数据,这就是我们所提及的思考过程。
最后一句return torch.log_softmax(x, dim=1)来算出概率。因为fc2()最后的输出可以是任何数字,并且没有范围限制,我们可以叫做原始得分 。而为了算出概率我们需要百分比的形式,于是我们用到了softmax()函数,Softmax() 是一个数学函数,它能把原始得分转换成总和为 1 的概率分布 。取对数(Log)是为了数学计算更稳定,防止softmax的数据过大或过小导致代码瘫痪。dim=0 是"图"的维度(竖着看),dim=1 是"分类"的维度(横着看)。

dim=0时是跨样本比较,dim=1时是在单个样本中比较概率
整个 forward 函数就是把图片像素 (784个点)一步步浓缩 ,最后变成10个概率值的过程。
四.训练模型
1.准备阶段
python
def train_model():
"""训练模型或加载已有模型"""
model_path = "mnist_model.pth"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
if os.path.exists(model_path):
print("发现已保存的模型,正在加载...")
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval()
return model, device3-5行代码主要是决定用 CPU 还是 显卡 (CUDA) 跑模型。然后把主程序Net()搬到上面去跑。model.load_state_dict(torch.load(model_path, map_location=device))这段代码就是实际上加载的过程。用load_state_dict()把model_path里存储的权重参数加载到Net()里。然后用model.eval()关闭Dropout()也就是上文提到的干扰机制,从而让模型满功率运行。
2.数据处理与下载
ini
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)现在我们开始对数据进行处理,而这个处理流程我们就先叫做transform。后面的Compose([...])负责把 多个处理步骤串联起来执行。
-
第一步
transforms.ToTensor()负责把数据转换为浮点数,让神经网络更好地处理数据。 -
第二步
transforms.Normalize((0.1307,), (0.3081,))是让上一步得到的数据减去均值 ,除以标准差 。让数值变成了以 0 为中心的正负数,分布在x轴上下。这一步就是把数据标准化 ,来让数据的分布更标准,能让神经网络收敛得更快(学得更快)。0.1307和0.3081是 MNIST 数据集的官方统计数据。
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)这一串代码是用来下载数据。它会自动检查 ./data 文件夹里有没有MNIST数据。有就会读取,没有就会去自动下载。(train=True表示要下载的是用于学习的训练集)。
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True) 有了数据之后,我们要把数据运给网络,但不能一次全部运完。于是我们用batch_size=64把图片分为64个一组,一组一组地运输。shuffle=True意思是在每 Epoch开始时,把图片打乱,因为MNIST数据集里的图片排列一般是有序的。打乱后,网络每次看到的都是随机的数字图片,从而逼迫它去学习数字本身的特征。
这一步是必须的,防止网络过拟合。
3.训练循环(核心一步)
scss
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
model.train()
epochs = 6
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch {epoch + 1}/{epochs} | Batch {batch_idx} | Loss: {loss.item():.4f}')
print("训练完成,正在保存模型...")
torch.save(model.state_dict(), model_path)
model.eval()
return model, device经过了上面的 搭建网络 和 处理数据 我们终于到了训练环节,让我们来逐一了解发生了什么事情。
首先是两个比较重要的部分,对应着1-2行的代码
1.optimizer = optim.Adam(...)这部分负责修改神经网络的参数model.parameters()。后面的lr=0.001我们管它叫做学习率 ,可以理解为模型的修改幅度,之所以是0.001是因为我们既不 希望模型修改幅度过大导致预测结果和真实答案 之间的差距(Loss)过大以至于影响学习,也不 希望模型修改幅度过小导致训练极其低效,而 0.001这个数值是无数前辈总结出的最佳值。
2.criterion = nn.CrossEntropyLoss()这段代码就是负责计算出交叉熵CrossEntropy ,什么是交叉熵呢,就是预测结果与真实答案之间的距离,也可以叫损失Loss 。如果Loss太大,就会在 backward() 的时候大幅修改参数。所以我们的训练目标就是得到尽可能接近0的Loss,至于为什么不能为0,是因为这时模型会过拟合,从而让训练失去意义。
ini
model.train()
epochs = 6然后我们开启训练模式,打开Dropout。定义循环次数,其实3次就已经可以让准确率达到90%以上了。
scss
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):这边我们定义了2个循环,一个外层for epoch in range(epochs):让模型把所有的题做6遍。一个内层for batch_idx, (data, target) in enumerate(train_loader):让每一遍做题时一次只做64道(batch),且每做完64道就总结一次。
然后我们正式进入学习的流程,注意我们是在内层循环里学习的。
data, target = data.to(device), target.to(device)OK,我们用这行代码把数据成功的搬进了GPU/CPU里。
那我们开始学习
- 第一步,
optimizer.zero_grad()把梯度清零,把上次算的梯度忘掉。梯度可以理解为,为了让Loss=0 ,模型现在应该往哪个方向走一步,让权重朝着正确的方向修改,于是我们走一步看一圈。清零是因为我们使用的PyTorch会默认把指令累加,如果不清零,上一步的梯度会和这一步的混在一起,导致神经网络'走错方向',因此我们必须清零上次的梯度。
梯度Like this

-
第二步,
output = model(data),可以理解为前向传播,把图片数据喂给神经网络后,经过层层计算,输出预测结果0-9。 -
第三步,
loss = criterion(output, target)计算损失,给出一个具体的Loss,看看错的情况。 -
第四步,
loss.backward()反向传播,程序会从Loss开始往回推,看看每一个神经元的参数(权重)对这个错误的'贡献',这一步算出了梯度,告诉每个神经元应该朝哪个方向更改参数。 -
第五步,
optimizer.step()更新参数,根据第四步算出的梯度 ,配合学习率去更新参数
走完这五步,我们的模型就聪明了一点
python
if batch_idx % 100 == 0:
print(f'Epoch {epoch + 1}/{epochs} | Batch {batch_idx} | Loss: {loss.item():.4f}')这一块是负责定期汇报学习进度,每学习完100个Batch就汇报一次。
scss
print("训练完成,正在保存模型...")
torch.save(model.state_dict(), model_path)训练完成后保存模型
javascript
model.eval()
return model, device然后model.eval()这行代码强制关闭 Dropout,返回模型和使用的设备(GPU/CPU)。
至此,我们村里终于出了个大学生:)
然后就是设计一个岗位给大学生了,是时候就业了
五.GUI交互界面
1.功能介绍
我们最主要的一部分已经完成了,我这边直接给出一个实例,包含了写数字,识别,可信度,处理后图片,概论预测的可视化,热力图(数据的数值强度)。
python
import tkinter as tk
from PIL import Image, ImageDraw, ImageTk
import matplotlib.pyplot as plt
import numpy as np
import torch
# ---导入训练模块---
from neural_net import train_model
# ---GUI---
class DigitRecognizerApp:
def __init__(self, root, model, device):
self.root = root
self.model = model
self.device = device
self.root.title("Handwritten Digit Recognition")
# 布局配置
self.main_frame = tk.Frame(root, padx=20, pady=20)
self.main_frame.pack()
# 1. 画板区域 (Canvas)
self.canvas_width = 280
self.canvas_height = 280
self.canvas_bg = "black"
self.brush_color = "white"
self.brush_size = 18
self.canvas = tk.Canvas(self.main_frame, width=self.canvas_width, height=self.canvas_height, bg=self.canvas_bg,
cursor="cross")
self.canvas.grid(row=0, column=0, rowspan=4, padx=10, pady=10)
# 绑定鼠标事件
self.canvas.bind("<B1-Motion>", self.draw)
# 内存绘图对象 (PIL)
self.image = Image.new("L", (self.canvas_width, self.canvas_height), self.canvas_bg)
self.draw_obj = ImageDraw.Draw(self.image)
# 2. 控制区域
self.btn_frame = tk.Frame(self.main_frame)
self.btn_frame.grid(row=0, column=1, sticky="n")
self.predict_btn = tk.Button(self.btn_frame, text="Predict", command=self.predict, font=("Arial", 12),
bg="#4CAF50", fg="white")
self.predict_btn.pack(pady=10, fill="x")
self.clear_btn = tk.Button(self.btn_frame, text="Clear", command=self.clear_canvas, font=("Arial", 12))
self.clear_btn.pack(pady=10, fill="x")
# 3. 结果显示区域
self.result_label = tk.Label(self.main_frame, text="Prediction: None", font=("Arial", 16, "bold"), fg="blue")
self.result_label.grid(row=1, column=1)
# 4. 略缩图显示
tk.Label(self.main_frame, text="Neural Network Input:", font=("Arial", 10)).grid(row=2, column=1, sticky="s")
self.thumb_label = tk.Label(self.main_frame, bg="gray")
self.thumb_label.grid(row=3, column=1)
# 5. 初始化 Matplotlib 可视化界面
plt.ion()
self.fig, self.ax = plt.subplots(1, 2, figsize=(8, 4))
self.fig.canvas.manager.set_window_title("Neural Network Visualization") # 英文窗口标题
self.init_plot()
def draw(self, event):
x1, y1 = (event.x - self.brush_size), (event.y - self.brush_size)
x2, y2 = (event.x + self.brush_size), (event.y + self.brush_size)
self.canvas.create_oval(x1, y1, x2, y2, fill=self.brush_color, outline=self.brush_color)
self.draw_obj.ellipse([x1, y1, x2, y2], fill=self.brush_color, outline=self.brush_color)
def clear_canvas(self):
self.canvas.delete("all")
self.image = Image.new("L", (self.canvas_width, self.canvas_height), self.canvas_bg)
self.draw_obj = ImageDraw.Draw(self.image)
self.result_label.config(text="Prediction: None")
self.thumb_label.config(image='')
self.init_plot()
def preprocess_image(self):
img_resized = self.image.resize((28, 28), Image.Resampling.LANCZOS)
img_array = np.array(img_resized)
# 归一化处理
img_tensor = torch.tensor(img_array, dtype=torch.float32) / 255.0
img_tensor = (img_tensor - 0.1307) / 0.3081
img_tensor = img_tensor.unsqueeze(0).unsqueeze(0)
return img_tensor, img_resized
def predict(self):
input_tensor, pil_thumb = self.preprocess_image()
# 显示略缩图
display_thumb = pil_thumb.resize((112, 112), Image.Resampling.NEAREST)
self.photo_thumb = ImageTk.PhotoImage(display_thumb)
self.thumb_label.config(image=self.photo_thumb)
# 调用模型推理
with torch.no_grad():
output = self.model(input_tensor.to(self.device))
probs = torch.exp(output)
prediction = torch.argmax(probs, dim=1).item()
confidence = probs[0][prediction].item()
self.result_label.config(text=f"Prediction: {prediction}\nConfidence: {confidence:.1%}")
self.update_plot(input_tensor, probs)
def init_plot(self):
self.ax[0].clear()
self.ax[0].set_title("Input Heatmap") # 英文
self.ax[0].axis('off')
self.ax[1].clear()
self.ax[1].set_title("Probability Distribution") # 英文
self.ax[1].set_ylim(0, 1)
self.ax[1].set_xticks(range(10))
self.fig.canvas.draw()
self.fig.canvas.flush_events()
def update_plot(self, input_tensor, probs):
img_data = input_tensor.squeeze().cpu().numpy()
self.ax[0].imshow(img_data, cmap='viridis')
probs_data = probs.squeeze().cpu().numpy()
self.ax[1].clear()
self.ax[1].set_title("Probability Distribution") # 英文
self.ax[1].set_xticks(range(10))
self.ax[1].set_ylim(0, 1.1)
bars = self.ax[1].bar(range(10), probs_data, color='skyblue')
bars[np.argmax(probs_data)].set_color('orange')
self.fig.canvas.draw()
self.fig.canvas.flush_events()
if __name__ == "__main__":
# 1. 调用 neural_net.py 中的函数加载/训练模型
print("Initializing AI Model...")
trained_model, device = train_model()
# 2. 启动 GUI
print("Starting GUI...")
root = tk.Tk()
app = DigitRecognizerApp(root, trained_model, device)
def on_closing():
plt.close('all')
root.destroy()
root.protocol("WM_DELETE_WINDOW", on_closing)
root.mainloop()六.源码
没有模型的话先运行neural_net.py,然后运行gui_app.py。之后使用的话直接运行gui_app.py即可。
1.neural_net.py
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import os
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return torch.log_softmax(x, dim=1)
def train_model():
"""训练模型或加载已有模型"""
model_path = "mnist_model.pth"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
if os.path.exists(model_path):
print(f"发现已保存的模型 {model_path},正在加载...")
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval()
return model, device
print("未发现模型,开始下载数据集并训练 (准确率目标 > 90%)...")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
model.train()
epochs = 6
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch {epoch + 1}/{epochs} | Batch {batch_idx} | Loss: {loss.item():.4f}')
print("训练完成,正在保存模型...")
torch.save(model.state_dict(), model_path)
model.eval()
return model, device2.gui_app.py
python
import tkinter as tk
from PIL import Image, ImageDraw, ImageTk
import matplotlib.pyplot as plt
import numpy as np
import torch
# ---导入训练模块---
from neural_net import train_model
# ---GUI---
class DigitRecognizerApp:
def __init__(self, root, model, device):
self.root = root
self.model = model
self.device = device
self.root.title("Handwritten Digit Recognition")
# 布局配置
self.main_frame = tk.Frame(root, padx=20, pady=20)
self.main_frame.pack()
# 1. 画板区域 (Canvas)
self.canvas_width = 280
self.canvas_height = 280
self.canvas_bg = "black"
self.brush_color = "white"
self.brush_size = 18
self.canvas = tk.Canvas(self.main_frame, width=self.canvas_width, height=self.canvas_height, bg=self.canvas_bg,
cursor="cross")
self.canvas.grid(row=0, column=0, rowspan=4, padx=10, pady=10)
# 绑定鼠标事件
self.canvas.bind("<B1-Motion>", self.draw)
# 内存绘图对象 (PIL)
self.image = Image.new("L", (self.canvas_width, self.canvas_height), self.canvas_bg)
self.draw_obj = ImageDraw.Draw(self.image)
# 2. 控制区域
self.btn_frame = tk.Frame(self.main_frame)
self.btn_frame.grid(row=0, column=1, sticky="n")
self.predict_btn = tk.Button(self.btn_frame, text="Predict", command=self.predict, font=("Arial", 12),
bg="#4CAF50", fg="white")
self.predict_btn.pack(pady=10, fill="x")
self.clear_btn = tk.Button(self.btn_frame, text="Clear", command=self.clear_canvas, font=("Arial", 12))
self.clear_btn.pack(pady=10, fill="x")
# 3. 结果显示区域
self.result_label = tk.Label(self.main_frame, text="Prediction: None", font=("Arial", 16, "bold"), fg="blue")
self.result_label.grid(row=1, column=1)
# 4. 略缩图显示
tk.Label(self.main_frame, text="Neural Network Input:", font=("Arial", 10)).grid(row=2, column=1, sticky="s")
self.thumb_label = tk.Label(self.main_frame, bg="gray")
self.thumb_label.grid(row=3, column=1)
# 5. 初始化 Matplotlib 可视化界面
plt.ion()
self.fig, self.ax = plt.subplots(1, 2, figsize=(8, 4))
self.fig.canvas.manager.set_window_title("Neural Network Visualization") # 英文窗口标题
self.init_plot()
def draw(self, event):
x1, y1 = (event.x - self.brush_size), (event.y - self.brush_size)
x2, y2 = (event.x + self.brush_size), (event.y + self.brush_size)
self.canvas.create_oval(x1, y1, x2, y2, fill=self.brush_color, outline=self.brush_color)
self.draw_obj.ellipse([x1, y1, x2, y2], fill=self.brush_color, outline=self.brush_color)
def clear_canvas(self):
self.canvas.delete("all")
self.image = Image.new("L", (self.canvas_width, self.canvas_height), self.canvas_bg)
self.draw_obj = ImageDraw.Draw(self.image)
self.result_label.config(text="Prediction: None")
self.thumb_label.config(image='')
self.init_plot()
def preprocess_image(self):
img_resized = self.image.resize((28, 28), Image.Resampling.LANCZOS)
img_array = np.array(img_resized)
# 归一化处理
img_tensor = torch.tensor(img_array, dtype=torch.float32) / 255.0
img_tensor = (img_tensor - 0.1307) / 0.3081
img_tensor = img_tensor.unsqueeze(0).unsqueeze(0)
return img_tensor, img_resized
def predict(self):
input_tensor, pil_thumb = self.preprocess_image()
# 显示略缩图
display_thumb = pil_thumb.resize((112, 112), Image.Resampling.NEAREST)
self.photo_thumb = ImageTk.PhotoImage(display_thumb)
self.thumb_label.config(image=self.photo_thumb)
# 调用模型推理
with torch.no_grad():
output = self.model(input_tensor.to(self.device))
probs = torch.exp(output)
prediction = torch.argmax(probs, dim=1).item()
confidence = probs[0][prediction].item()
self.result_label.config(text=f"Prediction: {prediction}\nConfidence: {confidence:.1%}")
self.update_plot(input_tensor, probs)
def init_plot(self):
self.ax[0].clear()
self.ax[0].set_title("Input Heatmap") # 英文
self.ax[0].axis('off')
self.ax[1].clear()
self.ax[1].set_title("Probability Distribution") # 英文
self.ax[1].set_ylim(0, 1)
self.ax[1].set_xticks(range(10))
self.fig.canvas.draw()
self.fig.canvas.flush_events()
def update_plot(self, input_tensor, probs):
img_data = input_tensor.squeeze().cpu().numpy()
self.ax[0].imshow(img_data, cmap='viridis')
probs_data = probs.squeeze().cpu().numpy()
self.ax[1].clear()
self.ax[1].set_title("Probability Distribution") # 英文
self.ax[1].set_xticks(range(10))
self.ax[1].set_ylim(0, 1.1)
bars = self.ax[1].bar(range(10), probs_data, color='skyblue')
bars[np.argmax(probs_data)].set_color('orange')
self.fig.canvas.draw()
self.fig.canvas.flush_events()
if __name__ == "__main__":
# 1. 调用 neural_net.py 中的函数加载/训练模型
print("Initializing AI Model...")
trained_model, device = train_model()
# 2. 启动 GUI
print("Starting GUI...")
root = tk.Tk()
app = DigitRecognizerApp(root, trained_model, device)
def on_closing():
plt.close('all')
root.destroy()
root.protocol("WM_DELETE_WINDOW", on_closing)
root.mainloop()七.结语
恭喜你,我们终于完成了Python神经网络识别手写数字的学习。使用时你可能会发现为什么答案有时不是完全对的,因为我们手写的数字还是与我们使用的训练数据有所出入,所以并不能保证100%识别出,尤其是一些比较复杂的数字,比如3,4,5,8。但是识别率还是挺高的,识别不出来的多写两次也能识别出。我们所学习的只是神经网络的冰山一角和最基础的概念框架,我们仍道阻且长,有更多的等着我们去探索。神经网络本身就在不断学习改错,更何况我们本身就是一个庞大的神经集群在控制。
写这么一篇文章相信大家都有所收获,我也一样!感觉理解又加深了一个层次。
这是我的第一篇文章,可能还存在一些解释上的不全面,如有错误欢迎大家改正!
至此,感谢你的观看!
1部分图片来自《Python神经网络编程》塔里克-拉希德