一、引言
近年来,AIGC(Artificial Intelligence Generated Content)技术取得了突破性进展。无论是文本生成、图像创作还是语音合成,AI 模型已经能够产出接近人类水平的内容。然而,在实际产业落地过程中,"能用"并不等于"好用"。许多团队在将训练好的模型投入生产环境时,常常面临推理延迟高、资源消耗大、服务不稳定等问题。
这些问题的本质在于:大多数优化工作停留在实验室阶段,缺乏面向真实业务场景的系统性调优。一个典型的反模式是------数据科学家专注于提升模型精度,而运维工程师则试图通过堆砌硬件来解决性能问题。这种割裂式的优化方式不仅成本高昂,而且难以持续。
因此,我们需要建立一套全链路调优体系,覆盖从模型准备、部署实施、API 设计到线上反馈的完整闭环。本文将以一个典型的图像生成 API 为例,深入剖析各环节的关键优化技术,并提供可复用的最佳实践。
二、阶段一:模型部署前的预调优
1. 数据层面的优化
高质量的数据是高效模型的基础。即便是在推理阶段,数据质量依然影响着模型表现:
- 输入规范化:对用户上传的图片进行自动裁剪、缩放和色彩空间转换,确保输入分布与训练集一致。
- 异常检测:使用轻量级分类器过滤明显不符合要求的请求(如非图像文件),避免无效计算。
- 缓存热点数据:对于频繁出现的相似提示词(prompt),可预先生成特征向量并缓存,减少重复编码开销。
某电商平台在其商品描述生成系统中引入了输入预处理模块后,平均响应时间下降了 23%,GPU 利用率提升了 18%。
2. 模型架构优化
直接部署原始训练模型往往效率低下。应在部署前进行针对性压缩:
| 技术 | 原理 | 适用场景 |
|---|---|---|
| 剪枝(Pruning) | 移除冗余神经元或连接 | 高度稀疏化模型 |
| 量化(Quantization) | FP32 → INT8 转换 | 边缘设备部署 |
| 知识蒸馏(Distillation) | 大模型指导小模型训练 | 实时性要求高的服务 |
以 Stable Diffusion 为例,经过 TensorRT 优化后的量化版本可在消费级显卡上实现 512x512 图像秒级生成,较原版提速近 3 倍。
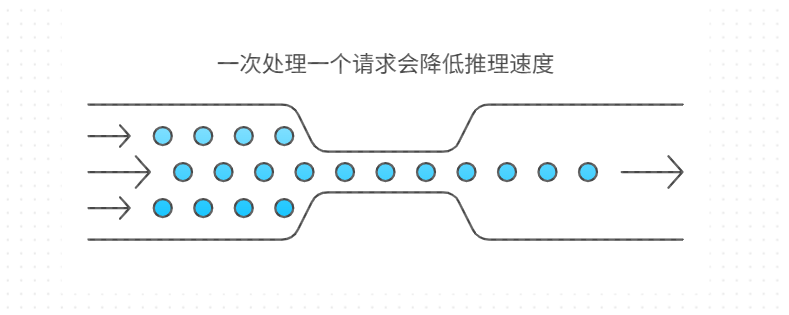
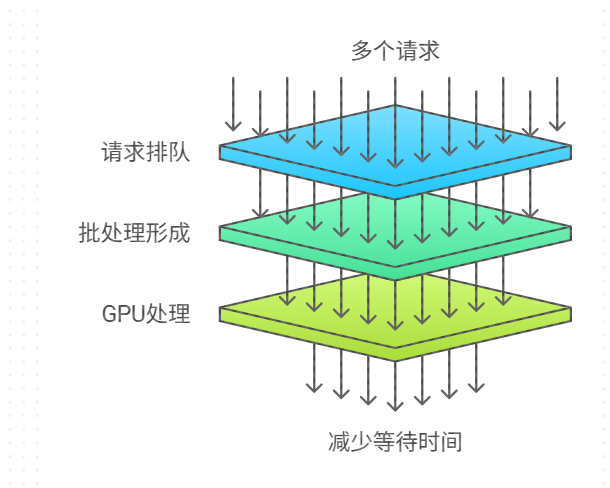
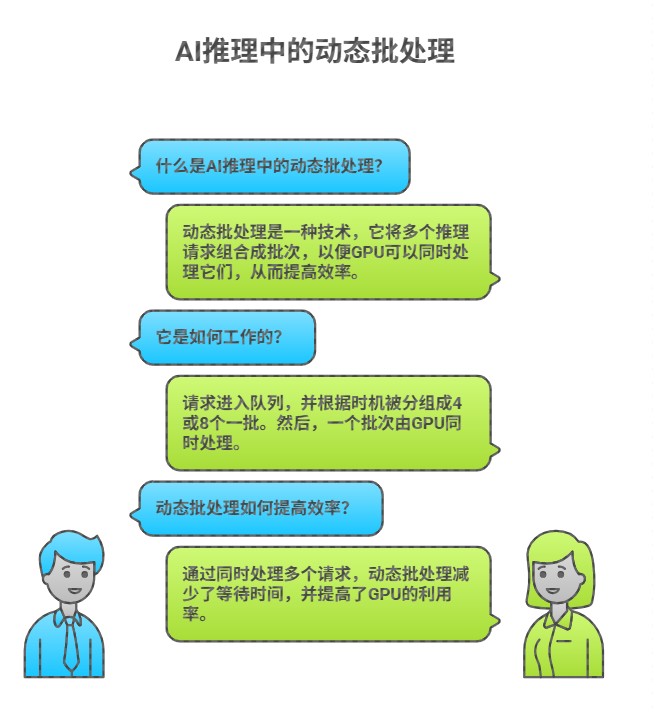
此外,动态批处理(Dynamic Batching)机制也至关重要。它允许服务器累积多个独立请求合并为一个批次处理,显著提高 GPU 利用率。NVIDIA Triton 推理服务器内置支持该功能,配置如下:
dynamic_batching {
max_queue_delay_microseconds: 10000
preferred_batch_size: [4, 8]
}3. 环境准备与封装
建议采用容器化方式封装模型服务,保证环境一致性:
FROM nvcr.io/nvidia/tritonserver:23.12-py3
COPY ./models /models
RUN pip install torch torchvision --index-url https://pypi.tuna.tsinghua.edu.cn/simple
EXPOSE 8000 8001 8002
ENTRYPOINT ["/opt/tritonserver/bin/tritonserver", "--model-repository=/models"]同时,推荐使用 ONNX Runtime 作为跨平台运行时,支持 CPU/GPU 自动切换与多种加速后端(OpenVINO、TensorRT 等)。
三、阶段二:部署中的工程化调优
1. 服务框架选型对比
目前主流的推理服务框架包括:
Triton Inference Server
- 优势:多框架支持(PyTorch/TensorFlow/ONNX)、动态批处理、模型并行
- 缺点:学习曲线较陡,需编写配置文件
- 典型应用场景:大规模生产环境
TorchServe
- 优势:专为 PyTorch 设计,集成良好,支持自定义处理脚本
- 缺点:仅限 PyTorch 模型
- 典型应用场景:纯 PyTorch 技术栈团队
TensorFlow Serving
- 优势:成熟稳定,与 TF 生态无缝对接
- 缺点:灵活性较差,更新缓慢
- 典型应用场景:传统机器学习平台
综合来看,Triton 因其通用性和高性能成为首选。
2. 资源调度与弹性伸缩
在 Kubernetes 环境下,应结合 HPA(Horizontal Pod Autoscaler)与 VPA(Vertical Pod Autoscaler)实现智能扩缩容:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: aigc-inference-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: inference-service
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Pods
pods:
metric:
name: request_per_second
target:
type: AverageValue
averageValue: "100"此外,显存管理尤为关键。可通过以下手段提升利用率:
- 启用 CUDA Unified Memory 实现主机与设备内存共享
- 使用内存池技术(如 RAPIDS cuML)避免频繁分配释放
- 设置合理的
max_workspace_size参数防止 OOM
3. 通信层优化
gRPC 是现代微服务间通信的事实标准。针对 AIGC 场景,建议启用以下特性:
- 流式传输:对于长文本生成或视频生成任务,采用 server-side streaming 模式逐步返回结果。
- 压缩算法:启用 Gzip 压缩减少网络带宽占用,尤其适用于大尺寸图像传输。
- 连接复用:客户端维持长连接,避免 TLS 握手开销。
更进一步,可利用共享内存(Shared Memory)绕过网络协议栈,实现进程间零拷贝数据交换。Triton 支持 system shared memory 与 CUDA shared memory 两种模式,适用于不同部署架构。
四、阶段三:API 层面的应用级调优
1. 接口设计模式选择
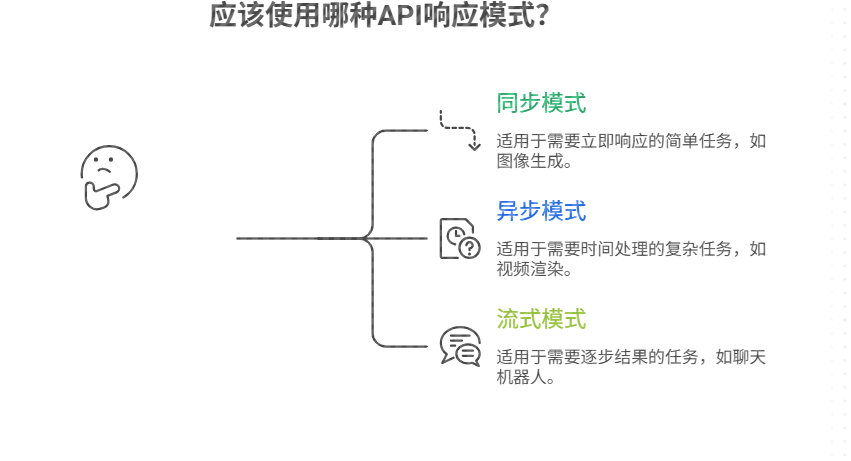
根据业务需求合理选择响应模式:
| 类型 | 特点 | 适用场景 |
|---|---|---|
| 同步阻塞 | 客户端等待直至完成 | 简单查询类接口 |
| 异步轮询 | 返回任务ID,客户端定期检查状态 | 中等耗时任务(<30s) |
| WebSocket 流式 | 实时推送中间结果 | 文本/图像逐步生成 |
| 回调通知 | 完成后主动推送结果 | 长周期任务 |
例如,Midjourney 采用 WebSocket 流式返回图像生成过程中的每一帧,极大提升了用户体验。
2. 缓存与限流机制
缓存策略
- 内容缓存:对相同 prompt + seed 的请求结果进行持久化存储(Redis + MinIO)
- 特征缓存:缓存 CLIP 文本编码结果,节省重复计算
- 分层缓存:本地 LRU 缓存 + 分布式 Redis 构成多级缓存体系
某新闻机构在其标题生成 API 中引入缓存后,QPS 承载能力提升 4.6 倍。
限流与熔断
使用 Sentinel 或 Istio 实现精细化流量控制:
- 单用户 QPS 限制
- 突发流量削峰填谷
- 故障实例自动隔离
当后端模型服务健康检查失败时,API 网关应自动切换至降级策略(如返回缓存结果或静态模板)。
3. 监控与可观测性建设
构建三位一体的监控体系:
-
指标(Metrics)
- 请求量(RPS)
- 延迟分布(P50/P95/P99)
- 错误率(HTTP 5xx)
- GPU 利用率、显存占用
-
日志(Logs)
- 结构化日志输出(JSON 格式)
- 请求链路追踪(Trace ID)
- 敏感信息脱敏处理
-
告警(Alerts)
- P99 延迟超过阈值
- 连续 5 分钟错误率 > 1%
- 显存使用率持续高于 90%
Prometheus 负责采集指标,Grafana 提供可视化面板,Alertmanager 实现多通道通知(钉钉/企业微信/短信)。
五、阶段四:持续迭代的反馈闭环
1. 线上行为分析
收集真实用户行为数据用于后续优化:
- 请求模式分析:聚类常见 prompt 类型,针对性优化特定领域表现
- 失败案例归因:统计超时、崩溃等异常请求特征,改进鲁棒性
- 用户满意度评分:嵌入反馈按钮获取人工评价数据
某社交 APP 发现"动漫风格"相关请求占比达 37%,遂专门训练了一个轻量级 LoRA 适配器,使该类生成速度提升 40%。
2. AB测试与灰度发布
建立科学的效果验证机制:
新版本模型
灰度发布
10% 流量
核心指标对比
成功率↑ 5%
延迟↓ 15%
全量上线
评估维度应涵盖:
- 功能性指标(BLEU、FID、CLIP Score)
- 性能指标(延迟、吞吐量)
- 商业指标(转化率、停留时长)
3. 自动化再训练 pipeline
构建 MLOps 流水线实现闭环更新:
# 数据回流
kubectl create job data-export-job --from=cronjob/data-collector
# 模型训练
dvc exp run --queue && dvc exp run --run-all
# 模型验证
pytest tests/model_stability_test.py
# 自动部署
argocd app sync aigc-production配合 GitOps 模式,所有变更均可追溯,保障系统稳定性。
六、典型案例分析
案例一:Stable Diffusion WebUI 企业级改造
某设计公司需将其内部使用的 SD WebUI 改造为企业级服务。原始单机部署无法满足 200+ 用户并发需求。
优化措施:
- 将前端与后端分离,后端改用 Triton 部署
- 启用动态批处理,最大批次设为 8
- 添加 Redis 缓存热门作品
- 配置 K8s HPA 实现自动扩缩容
成果:
- 平均响应时间从 12.4s 降至 3.1s
- 支持峰值 QPS 从 8 提升至 85
- GPU 利用率从 41% 提升至 79%
案例二:金融文档摘要 API 性能攻坚
某银行需要对每日万份财经新闻生成摘要,原有服务经常超时。
问题诊断:
- 单次推理耗时 8.2s(P99)
- 内存泄漏导致每小时重启一次
- 无缓存机制,重复请求反复计算
解决方案:
- 使用 DistilBERT 替代原始 BERT 模型
- 实现基于 SimHash 的语义去重缓存
- 引入异步队列处理高峰流量
- 部署 Prometheus 监控内存增长趋势
成效:
- 推理时间缩短至 2.3s
- 日均节省计算成本约 ¥1,200
- SLA 达标率从 82% 提升至 99.6%
七、结语
AIGC 的真正价值不在于炫技般的 Demo,而在于能否稳定、高效地服务于亿万用户。全链路调优正是打通从实验室到生产线"最后一公里"的关键路径。
未来,随着 MCP(Model Control Plane)概念的普及,我们将看到更多自动化调优工具涌现。但无论技术如何演进,以终为始、系统思维、数据驱动这三大原则始终不变。
唯有如此,才能让 AI 不再是"人工智障",而是真正可用、好用、爱用的生产力工具。