延迟和成本是当今基于 LLM 的聊天机器人面临的重大挑战。这个问题在恢复增强生成(RAG)代理中更加明显,在返回用户答案之前,我们必须对 LLM 进行多次调用。通常,LLM RAG 应用的延迟时间可能超过5秒!当许多用户提出"类似"问题时,语义缓存是一种简单的方法,可以大大减少聊天机器人的等待时间,使其小于0.1秒。
1. 缓存的简要回顾
在 Web 应用程序的上下文中,缓存是一种快速、低延迟的数据库,它临时存储通常访问的数据。当应用程序需要一些信息时,它会首先检查缓存是否有这些信息,如果有,则直接使用缓存中的数据。如果缓存没有请求的数据,它将从底层事务数据库(OLTP)获取数据。这种类型的缓存称为读缓存。
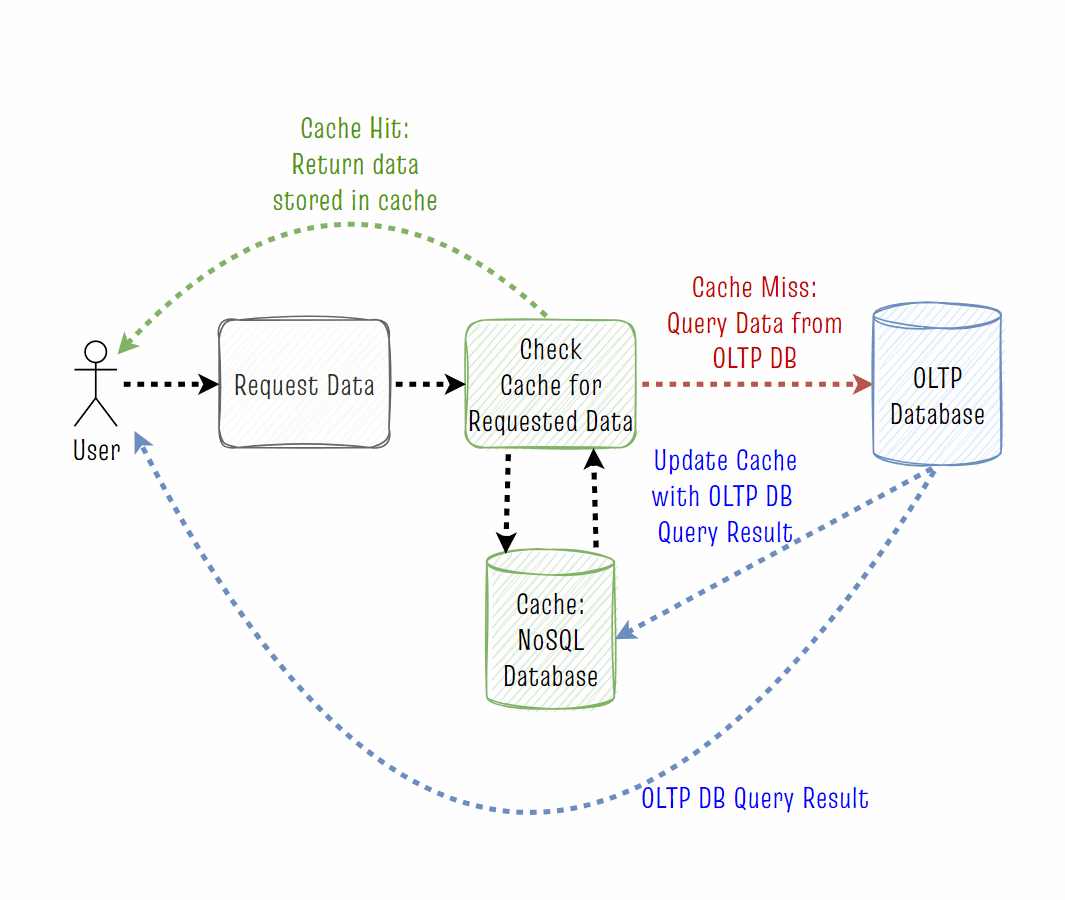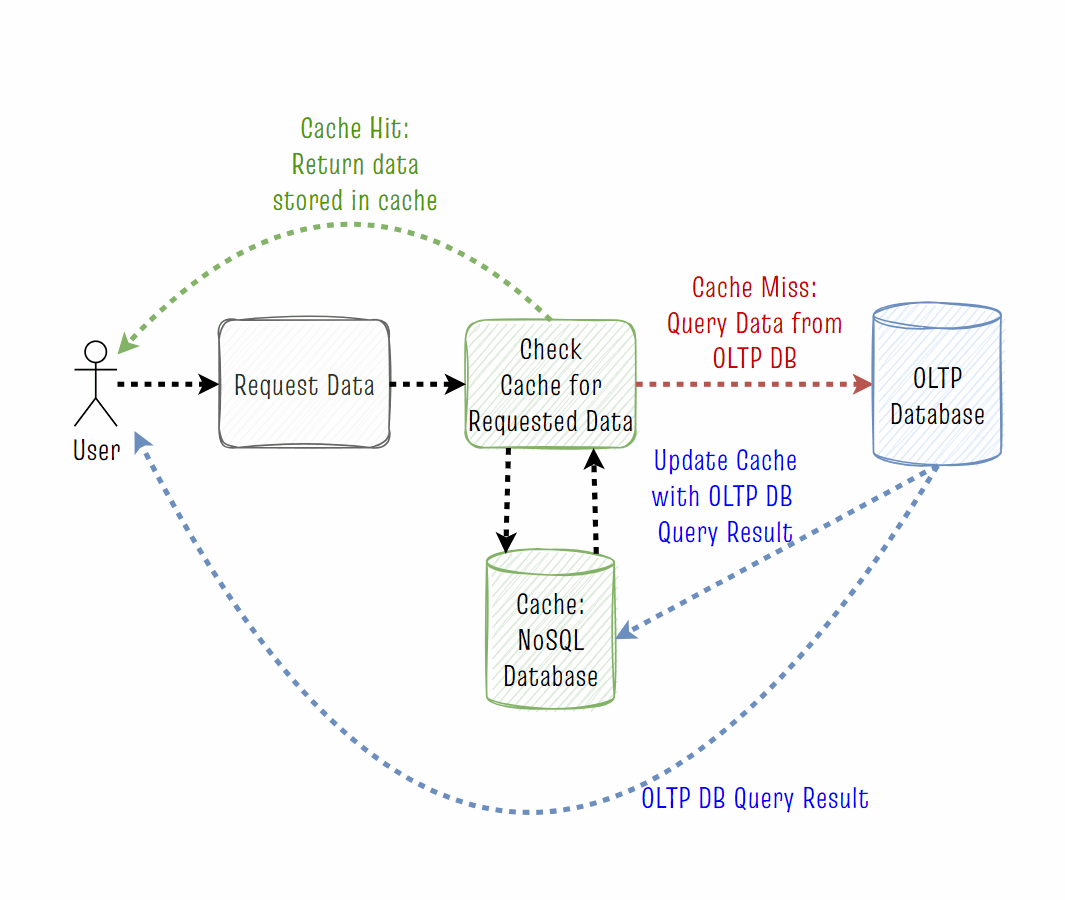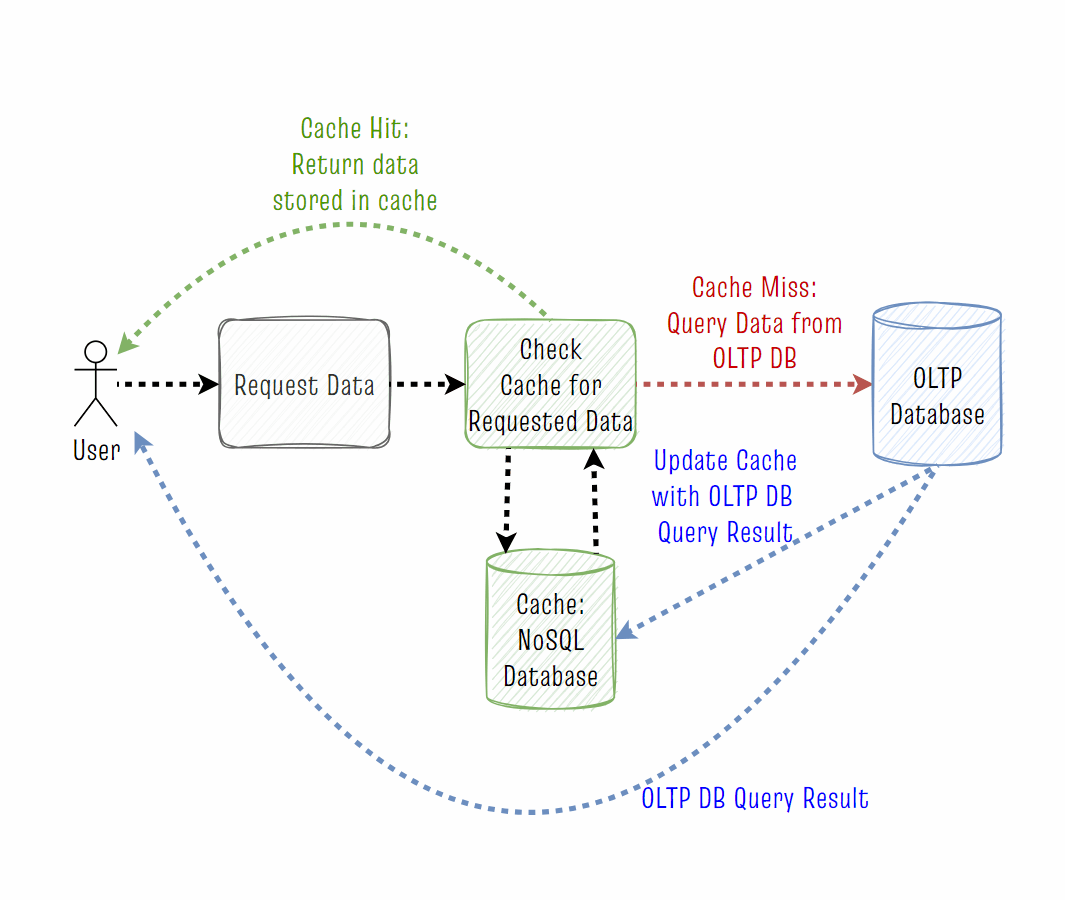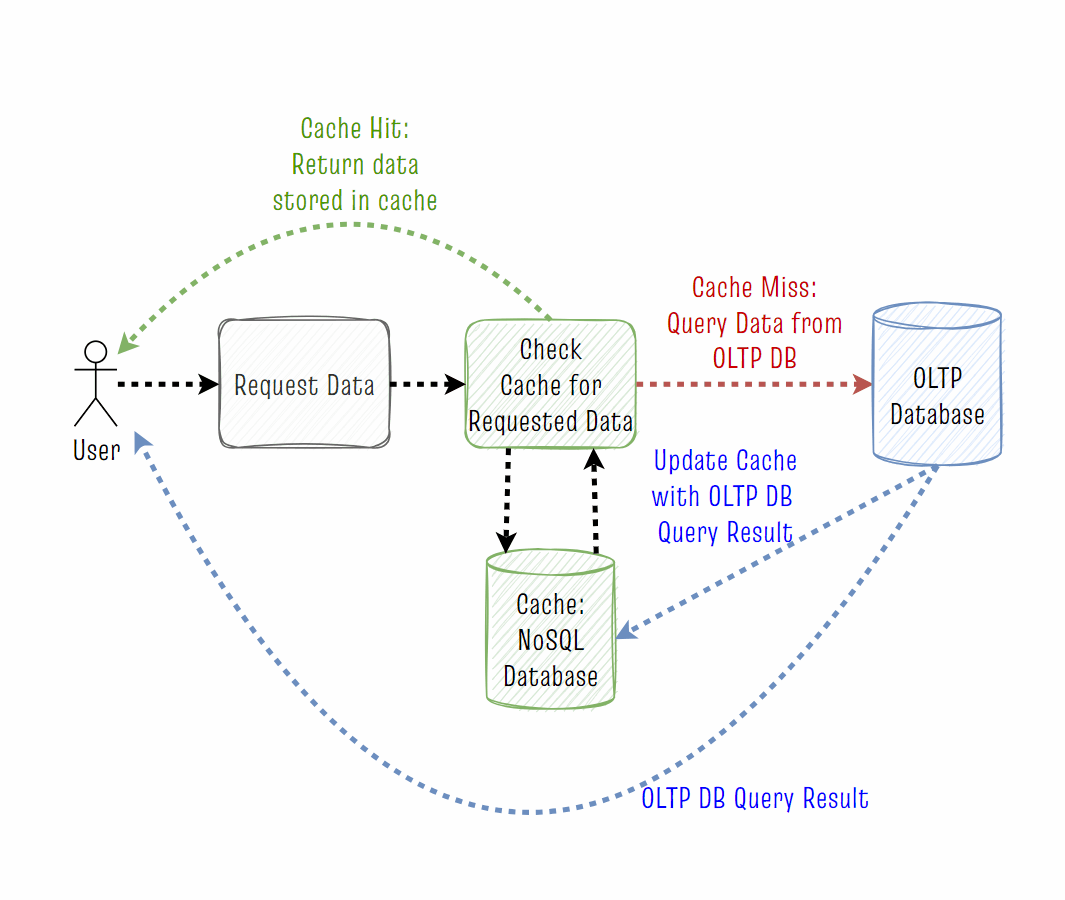
典型的 Web 应用可能会使用像 Redis 这样的 NoSQL 数据库作为缓存。相比之下,它将使用传统的 SQL 数据库(如 PgSQL)作为实际的事务数据库,这是最终的数据源。使用缓存有两个主要原因:
-
速度: 添加一个缓存来临时存储通常访问的数据可以极大地加快应用程序的速度,因为从这些 NoSQL 数据库中提取数据要比从 SQL 数据库中查询数据快得多。
-
负载: 从缓存中检索通常访问的数据极大地减少了对事务数据库的请求数量,并允许它以更少的资源很好地工作。
在 LLM 应用中,许多用户可能有非常"相似"的问题,但措辞略有不同。例如,问题"如何使阅读成为一种习惯?"以及"怎样才能使阅读成为一种常规习惯?"是相似的,但稍有不同。然而,我们可以用一个答案来回答这两个问题。在这里,我们不能使用标准的 Redis 缓存,因为两个问题的key不同。那么,我们如何使用缓存来解决这个问题呢?这就是语义缓存的价值所在。
关于大模型应用入门,可以参考李瀚等老师的《探秘大模型应用开发》一书。
2. 语义缓存
语义缓存通过应用语义文本最近邻搜索的原则扩展了缓存范式。在语义缓存中,我们使用一个向量数据库作为一个低延迟缓存来存储所有用户问题的嵌入以及过去对每个问题产生的相应答案。
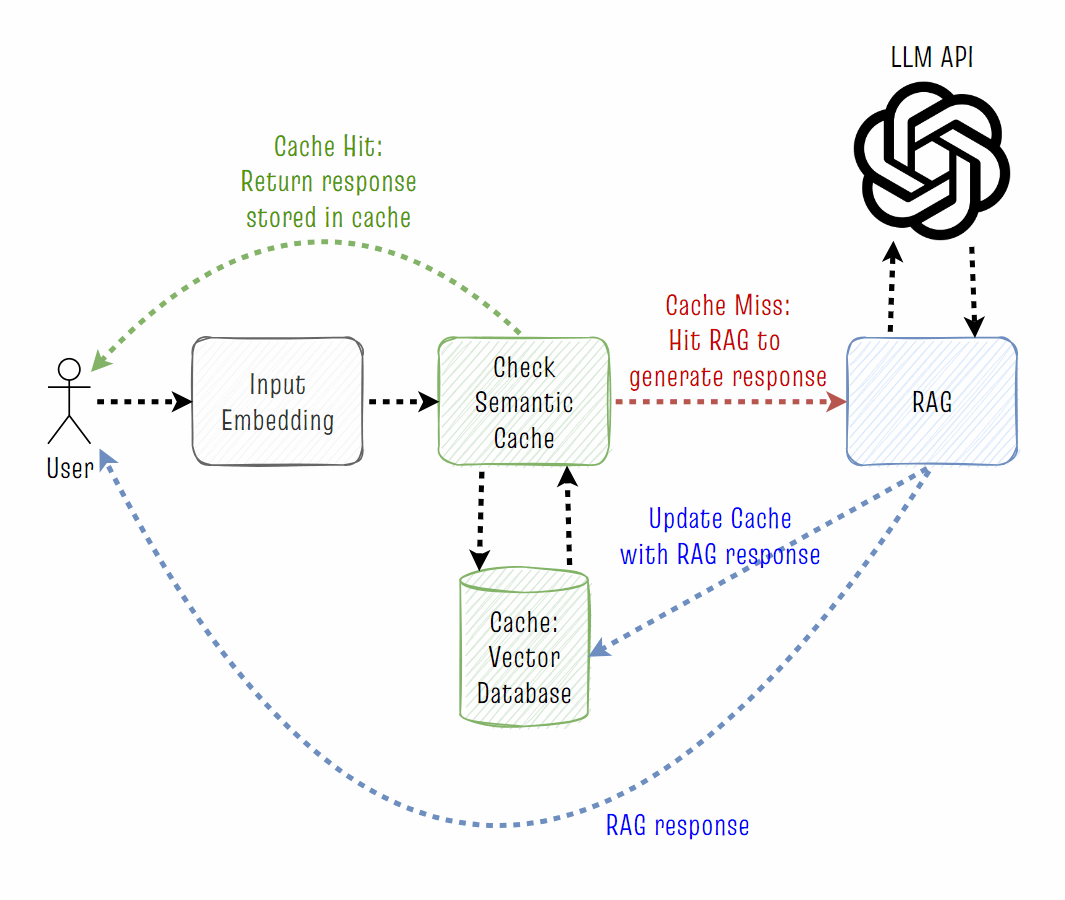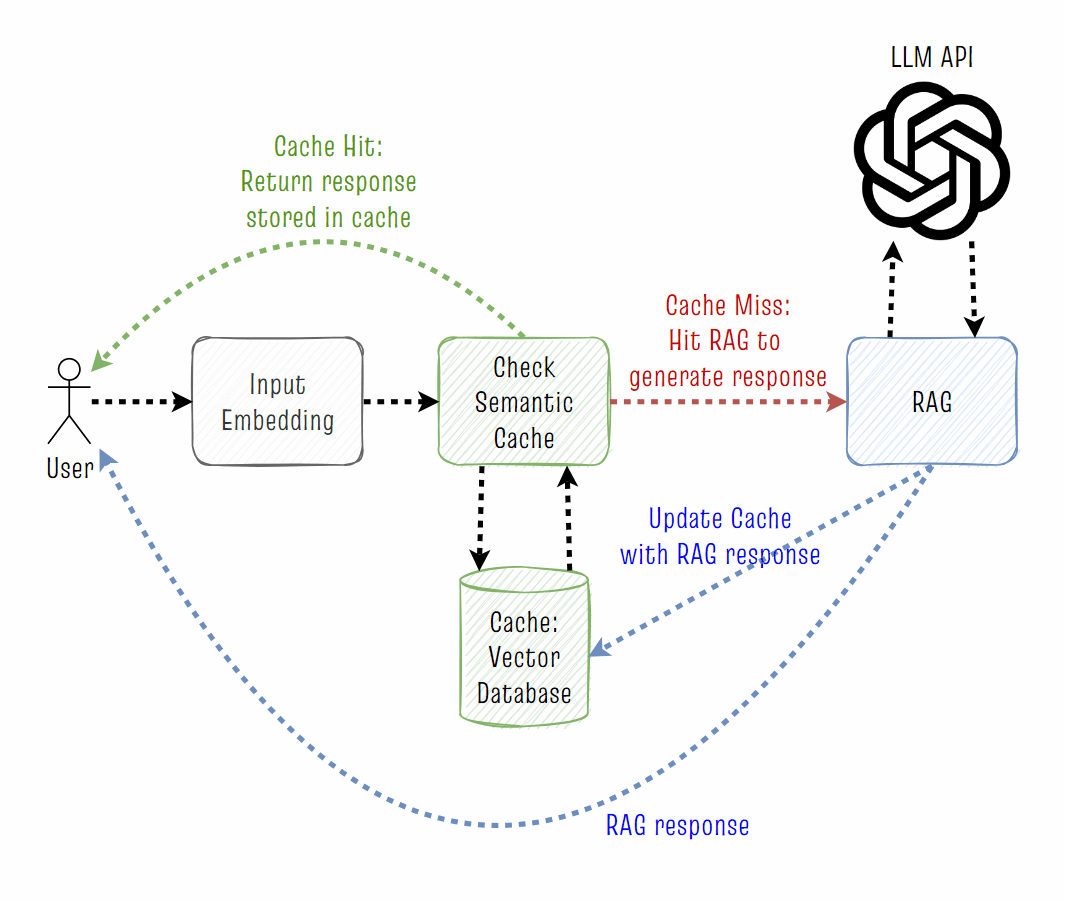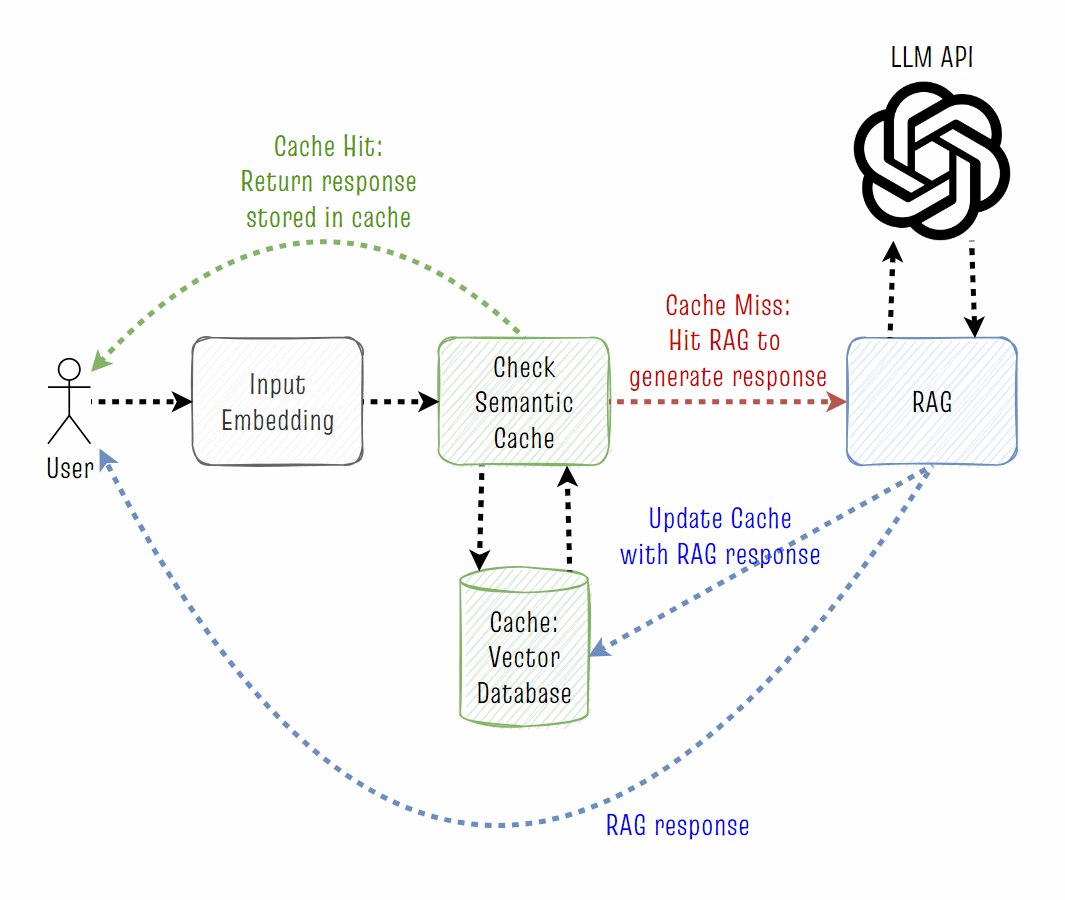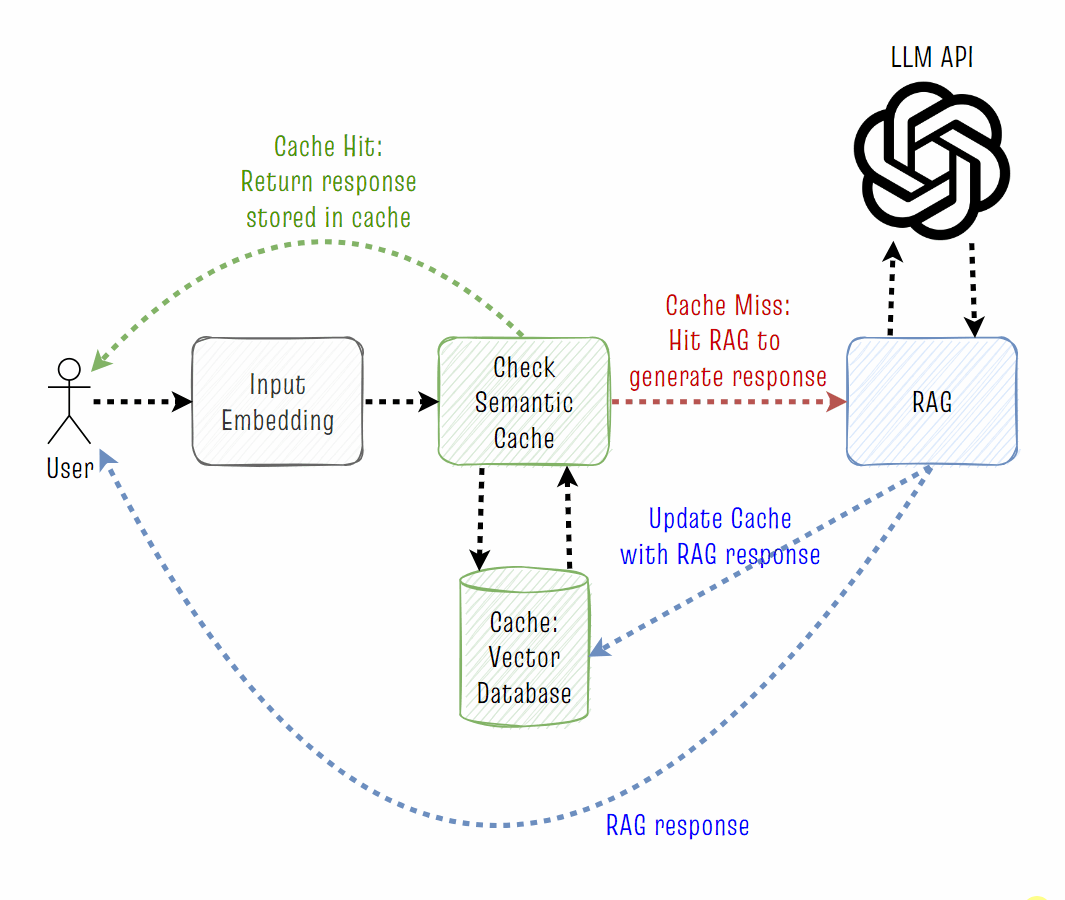
每个新的用户问题被转换成一个嵌入向量,并与缓存进行比较,以找到过去的任何"语义相似"的问题。如果向量数据库缓存找到一个具有足够接近含义的问题,它将从缓存中返回答案给用户,而不是运行 RAG 的流水线。向量数据库通常非常快,可以在100毫秒内完成整个操作。
从过去的"相似"问题中返回答案有三个好处,不需要对每个用户问题都使用 LLM:
-
速度: 从向量数据库返回结果的时间可以达到从 LLM 获得响应所需时间的 5% 以内!
-
成本: LLM 的 API 比嵌入 API 昂贵得多。例如,gpt-3.5-turbo-0125 API 生成令牌的成本为1.5美元/100万个令牌,而text-embedding-3-small 的嵌入 API 生成令牌的成本为0.02美元/100万个令牌。因此,成本降低99% !如果使用开源的嵌入模型 ,成本甚至更低。
-
限制: 托管的 LLM 服务限制了任何单个应用程序使用的速率。与LLM的 API 相比,嵌入 API 具有较宽松的令牌限制。例如,对于一个二级帐户,OpenAI gpt-3.5-turbo 每分钟有一个80K 令牌限制,而text-embedding-3-small 的限制是每分钟1M 令牌!放大了12.5倍!
因此,我们可以通过从过去的"类似"问题返回答案来减少延迟和成本,而不是对每个用户问题都去调用 LLM。
如果对自动驾驶中大模型的应用感兴趣,可以参考张慧敏 老师的《智能座舱:架构原理》一书------
3. 语义缓存的实现
实现一个简单的语义缓存非常简单。Langchain 为使用语义缓存提供了很多抽象,然而,Langchain 的抽象对于较复杂的应用程序可能限制太多,并且,在为特定需求实现语义缓存时,我们还可能需要更多的灵活性。一个可参考的替代方案是 LiteLLM,我们可以用任何自定义缓存函数覆盖它的默认缓存。
3.1 环境设置
设置 Python 环境并在本地启动 Qdrant 矢量数据库,当然使用其他向量数据库也是可以的。
go
# Create and activate a conda environment
conda create -n semantic_cache python=3.11
conda activate semantic_cache
# Install the necessary libraries
pip install -U fastapi uvicorn loguru pandas numpy tqdm
pip install -U litellm sentence-transformers
pip install -U qdrant-client redisvl==0.0.7
# Run Qdrant Vector Database locally
docker run --rm -p 6333:6333 -p 6334:6334 -v $(pwd)/qdrant_storage:/qdrant/storage:z qdrant/qdrant3.2 基于LiteLLM 的语义缓存实现
在 LiteLLM 中实现自定义语义缓存涉及到六个步骤:
-
嵌入模型: 使用嵌入模型将用户的问题文本转换成一个嵌入向量,对文本的上下文和意义进行编码。这里使用一个Sentence Transformer Bi-Encoder 模型来生成嵌入,它在语义文本相似性任务上比 OpenAI 的text-embedding-3-models 给出了更好的结果。
-
矢量数据库: 利用矢量数据库对嵌入矢量进行物理存储和语义相似性检索。Qrdant 向量数据库可以运行在一个 Docker 容器中,可以在本地或云中运行。
-
add_cache(): 这个函数必须实现自定义逻辑,将 API 调用添加到矢量数据库中。Qdrant 矢量数据库中的每个文档都包含新的用户问题嵌入和 LLM 生成的相应答案。
-
get_cache(): 这个函数也必须实现我们的自定义逻辑,以便应用程序如何在向量数据库中搜索"类似"问题。将一个用户问题转换为文本嵌入,并使用它在 向量数据库中搜索最相似的文档,如果最相似的文档的相似度得分超过0.95的阈值,将返回这个答案(稍后将详细介绍)。如果没有文档满足最小相似性阈值条件,则返回"无"。
-
将这些自定义函数添加到 LiteLLM Cache ()。
-
可以将整个服务公开为 FastAPI 端点,以便用户可以轻松地将这个服务并与之交互。
go
import os
import time
import litellm
from fastapi import FastAPI, Response
from litellm.caching import Cache
from loguru import logger
from qdrant_client import QdrantClient, models
from sentence_transformers import SentenceTransformer
litellm.openai_key = os.getenv("OPENAI_API_KEY")
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# Step 1: 引入潜入模型
encoder = SentenceTransformer("sentence-transformers/stsb-mpnet-base-v2")
# Step 2: 建立用于语义缓存的向量数据库
collection_name = "semantic_cache"
qdrant_client = QdrantClient("localhost", port=6333)
try:
qdrant_client.get_collection(collection_name=collection_name)
except:
qdrant_client.recreate_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(
size=encoder.get_sentence_embedding_dimension(),
distance=models.Distance.COSINE,
),
)
# Helper
def generate_embedding(**kwargs) -> list:
"""Take the last message as the prompt and generate an embedding
Args:
kwargs: All the arguments passed to the litellm call
Returns:
list: Embedding vector of the prompt
"""
# Take the last message as the prompt
prompt = kwargs.get("messages", [])[-1].get("content", "")
# Embed
litellm_embedding = encoder.encode(prompt).tolist()
return litellm_embedding
# Step 3: 增加缓存
def add_cache(result: litellm.ModelResponse, **kwargs) -> None:
"""Add the result to the cache
Args:
result (litellm.ModelResponse): Response from the litellm call
kwargs: All the arguments passed to the litellm call
and some additional keys:
`litellm_call_id`, `litellm_logging_obj` and `preset_cache_key`
"""
# Embed
litellm_embedding = generate_embedding(**kwargs)
# Upload to vector DB
qdrant_client.upsert(
collection_name=collection_name,
points=[
models.PointStruct(
id=kwargs.get("litellm_call_id"),
vector=litellm_embedding,
payload=result.dict(),
)
],
)
# Step 4: 获取缓存
def get_cache(**kwargs) -> dict:
"""Read the cache
Args:
kwargs: All the arguments passed to the litellm call
and some additional keys:
`litellm_call_id`, `litellm_logging_obj` and `preset_cache_key`
Returns:
dict: The result that was saved in the cache.
Should be compatible with litellm.ModelResponse schema
"""
similarity_threshold = 0.95
# Embed
litellm_embedding = generate_embedding(**kwargs)
# Cache Search
hits = qdrant_client.search(
collection_name=collection_name,
query_vector=litellm_embedding,
limit=5
)
# Similarity threshold
similar_docs = [
{**hit.payload, "score": hit.score}
for hit in hits
if hit.score > similarity_threshold
]
if similar_docs:
logger.info("Cache hit!")
else:
logger.info("Cache miss!")
# Return result
return similar_docs[0] if similar_docs else None
# Step 5: 语义缓存
cache = Cache()
cache.add_cache = add_cache
cache.get_cache = get_cache
litellm.cache = cache
# Step 6: 基于Fast API 建立服务
app = FastAPI()
@app.get("/")
def health_check():
return {"Status": "Alive"}
@app.post("/chat")
def chat(question: str, response: Response) -> dict:
# LiteLLM call - Handles the cache internally
start = time.time()
result = litellm.completion(
model="gpt-3.5-turbo-0125",
messages=[{"role": "user", "content": question}],
max_tokens=100,
)
end = time.time()
# Add latency to the response header
response.headers["X-Response-Time"] = str(end - start)
return {"response": result.choices[0].message.content}部分实验表明,对于类似但不完全重复的问题,使用语义缓存可以减少98% 的延迟。
4. 约束与增强
对于每个考虑实现语义缓存的开发人员来说,有两个主要的考虑因素:
-
精度(缓存精度) : 使用嵌入向量的语义文本最近邻搜索可能产生不精确的结果。例如,问题是: " 知乎上最有趣的答案是什么?"以及" 知乎上最有趣的问题是什么?"具有 > 0.9的高相似性。
-
召回(缓存命中率)是缓存提供的用户查询的百分比。缓存服务的用户查询越多,LLM 成本就越低。
准召是直接的权衡,仅仅通过增加相似性阈值来提高精度会使召回恶化,反之亦然。
语义缓存与问题数据集密切相关,可以尝试引入监督式方法,在数据集中标记出可能的重复问题对。在不同的相似性阈值下识别"假阳性",并手动标记句子对,以识别更多原始数据集没有明确标记的重复问题。
使用带有"增强"标签的stsb-mpnet-base-v2 sentence transformer bi-encoder 模型,可以以较低的命中率达到较高的缓存精度。因此,对于特定的应用程序,一般可以从主观标记增强的数据集加速 LLM 推理,同时保持很高的精度。
5. 一句话小结
语义缓存,是缓存技术在大模型应用领域的扩展和延伸,作为性能提升的利器,再次验证了"缓存为王"。
ps. 对性能优化感兴趣的朋友可以阅读老码农参与合著的《分布式系统性能优化:方法与实践》一书。
【参考资料与关联阅读】