
别再狂塞 token 了。长文档/长对话真贵的原因,是输入方式太臃肿。本文用 3 分钟带你看完 OCR-free / 像素化语言 / token 压缩,并给出一套最小评测清单。
为什么要看"字当图看"的替代路线
长文档与长对话的成本越来越高,根因不是"模型不够强",而是输入方式太昂贵:文本注意力几乎按 N² 增长。与其无止境地塞 token,不如换一条思路------让输入更密、更稳、更统一 :把页面当图看(OCR-free)、把语言也回到像素(像素化语言),或直接在视觉/文本两侧做token 压缩 。这三条路线不是"谁替代谁",而是互补 :复杂混排靠 OCR-free 保结构,跨语种靠像素化语言更鲁棒,长上下文直接用压缩减重,三者还能打组合拳。
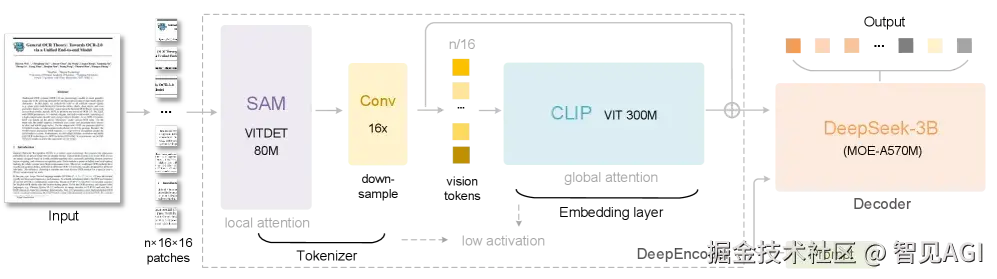
DeepSeek OCR
如果你这两天被 DeepSeek-OCR 刷屏,核心记忆大概有两句:第一,把长文本渲成图片 ;第二,用更少的视觉 token 表示海量信息 ,于是长上下文的算力账突然"省钱"了。很多读者会问:这条思路是不是独一家?其实不止。本文用一篇就够的方式,梳理三条"类同路线":一条是和 DeepSeek-OCR最像的 OCR-free / 端到端文档理解 (整页当图像直接读懂);一条是更"哲学"的 像素化语言建模 (把文字也变像素再学);最后一条是工程味很浓的 token 压缩/合并 (少给点 token 也能懂)。看完你大概就能做两件事:给自己的生产链路选型 ,以及搭一套最小可复现实验,用真实 PDF、表格、公式和多轮对话,测出"谁更省、谁更稳"。
路线一:OCR-free / 端到端读文档(最像 DeepSeek-OCR 的"把整页当图看")
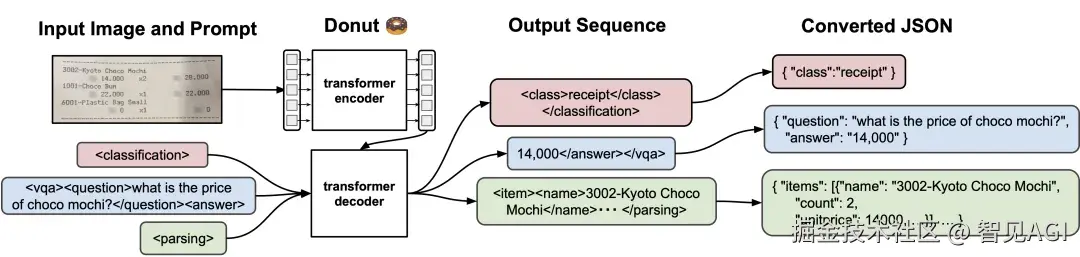
The pipeline of Donut
Donut 开了头:整页图像输入、直接生成结构化结果,不依赖传统 OCR 引擎,排版/层级天然保留,适合表单、票据、报表。
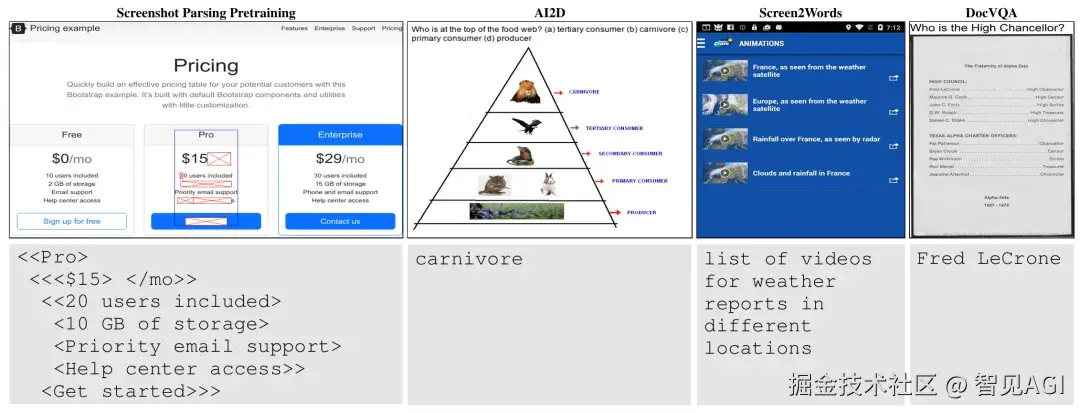
Examples of visually-situated language understanding tasks, including diagram QA (AI2D), app captioning (Screen2Words), and document QA (DocVQA).
Google 的 Pix2Struct 把网页、UI、图表都当"视觉化语言",先学"截图→简化结构"的共性,再去做问答与描述;
UReader
UReader 往通用多模态方向走,一套模型兼容文档/网页/场景文字。
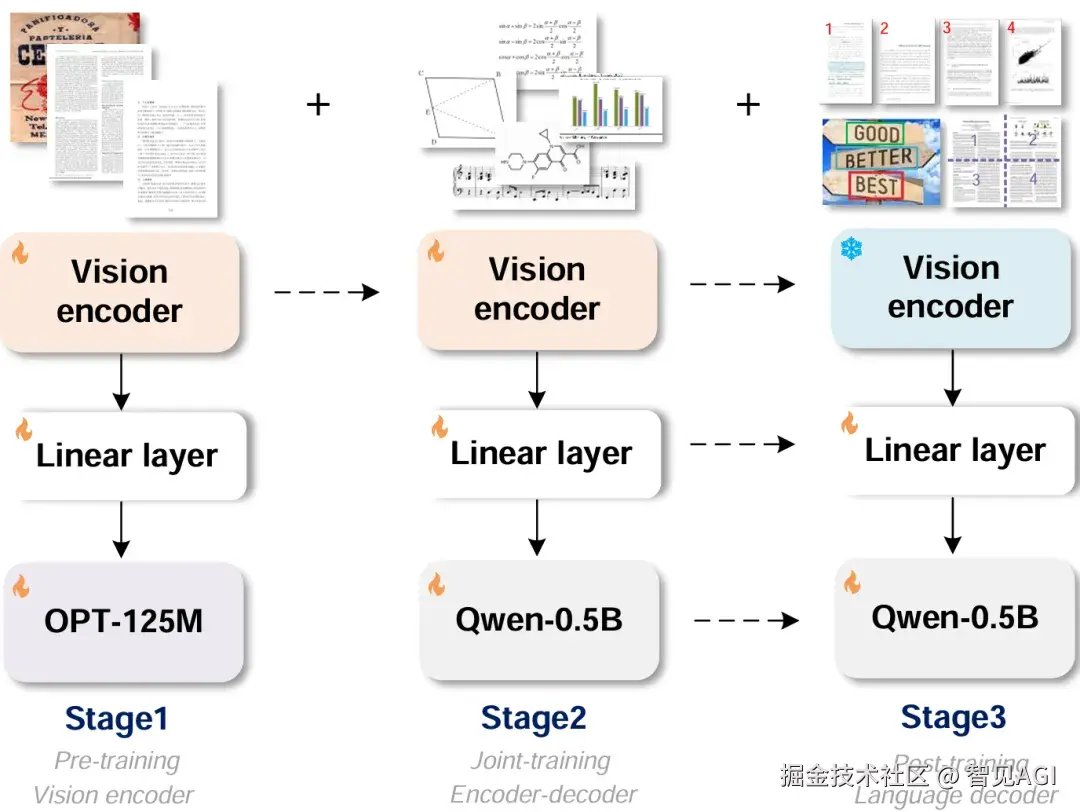
GOT-OCR
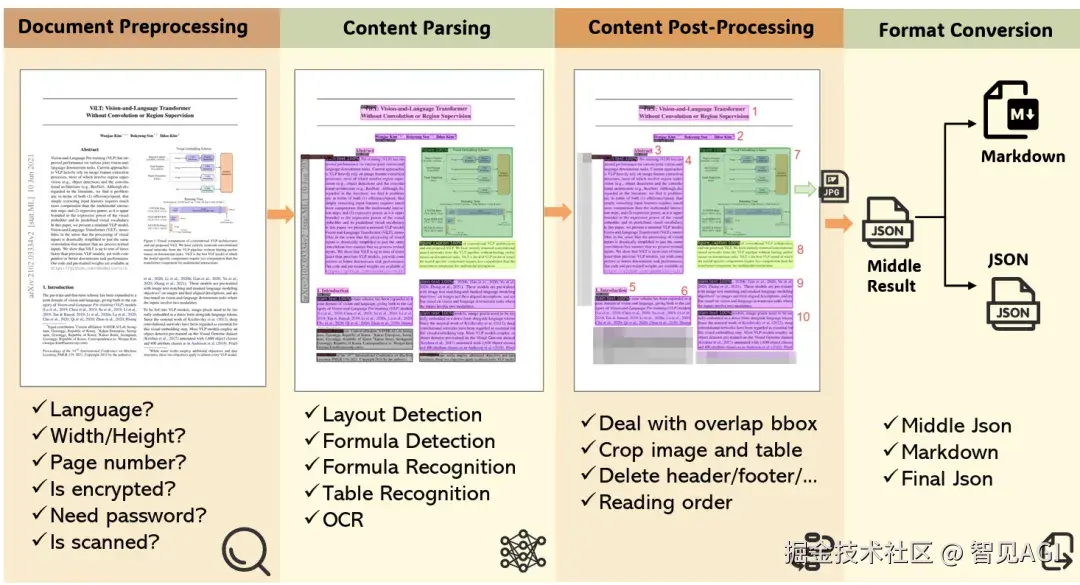
MinerU framework processing workflow
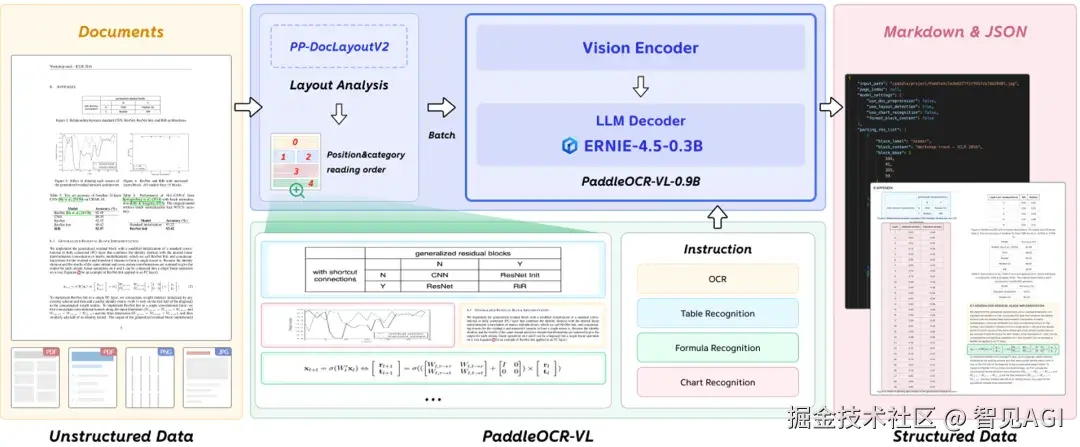
PaddleOCR-VL
而 Haoran Wei 牵头的 GOT-OCR 2.0、以及开源系统 MinerU(最新到 2.5)和百度的 PaddleOCR-VL,则把复杂版式、表格/公式重建、跨语种等拉满,用在真实业务的可用性更强。这些工作的共同点 是:整页进、结构出 ,最大化保留二维版式与图表语义,少走"先 OCR 再拼"的中间损耗;与 DeepSeek-OCR 的差别 是:它们多把"图→文/结构"的链路做到极致,而 DeepSeek-OCR 额外把"文本先视觉化→以视觉 token 进上下文 "这件事做成了长上下文压缩 与记忆管理的新范式。(GitHub)
工程实战里,GOT-OCR、MinerU、PaddleOCR-VL把表格/公式重建与多语 做得更踏实,适合"读懂+重建+再编辑"的生产链路。什么时候用?当你的 PDF/网页图文混排复杂、表格/图表多时,OCR-free 的结构保持会比"先 OCR 再拼"稳定得多。
路线二:像素化语言建模("语言也该回到像素")
如果你认同"语言只是更低维的视觉投影",那这条线会很对胃口。PIXEL 的直觉很简单:把文字渲成图片再学,用像素掩码重建来获得语言表征,这样跨文字体系更鲁棒,也绕开分词器的词表束缚;
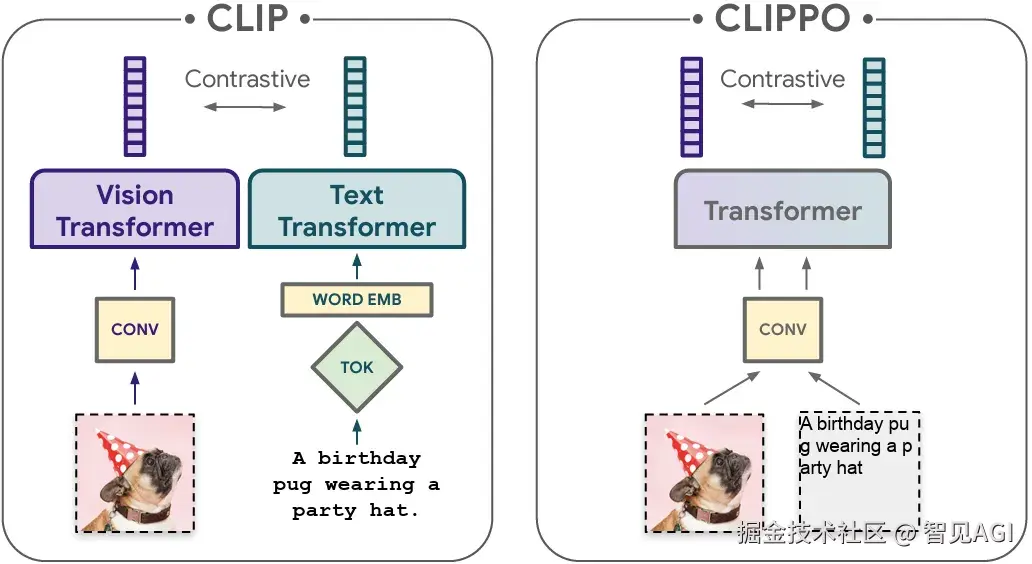
CLIPPO 走得更远,图片与"渲成图的文字"统一用同一个视觉编码器 ,做纯像素的跨模态对齐。什么时候用?当你需要多语/异体字/对抗字符 稳定性时,这条路往往更"抗噪",也让"语言/视觉"的输入侧更一致。思想上它们与 DeepSeek-OCR 高度类同:用像素/视觉表征统一语言与图像,让输入侧更一致、也更抗"分词越狱/编码割裂"。(arXiv)
路线三:token 压缩/合并(介质不同,但目标一致:更少 token,近似效果)

ToMe
在视觉侧,ToMe(Token Merging)通过合并相似视觉 token ,训练免改即可把 ViT/扩散的吞吐拉到 2×,精度只掉零点几个点;专为多模态 LLM 设计的 TokenPacker 则是"粗到细的视觉投影器",常见能把视觉 token 压到 75--89% 还保持细节与推理力;
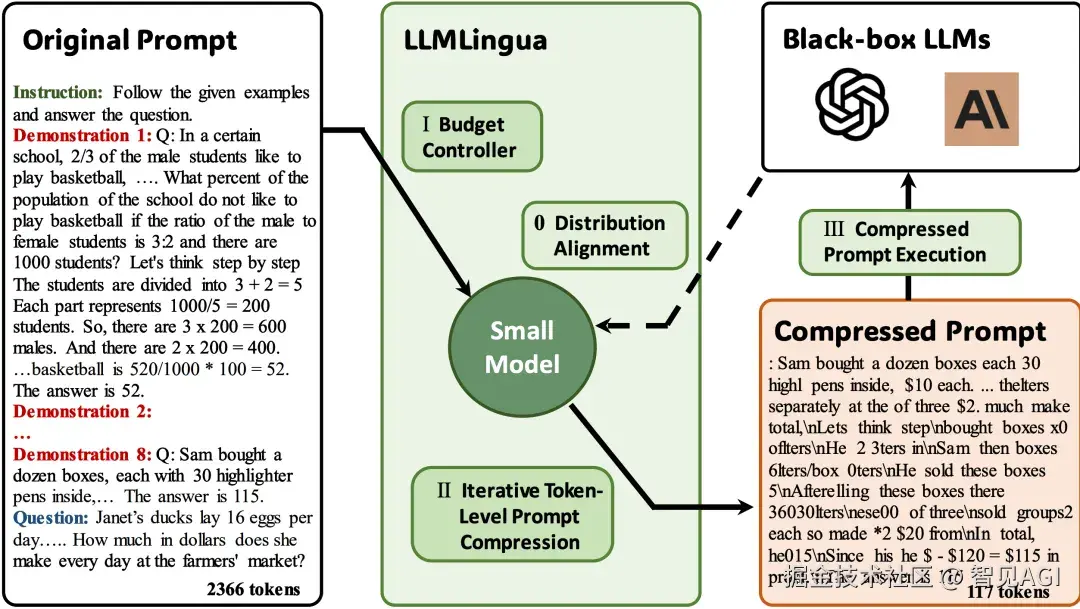
Framework of the proposed approach LLMLingua.
在文本侧,LLMLingua / LongLLMLingua 用提示压缩 把 10×--20× 的 token 砍掉还维持性能,且长上下文里更能抗位置偏置。这条线和 DeepSeek-OCR 的关系很清楚:大家都在减少解码器要吃的 token ,只不过一个从"视觉端"做(合并/投影),一个从"文本端"做(剪裁/蒸馏),而 DeepSeek-OCR 则把"文本先视觉化再压缩"纳入统一记忆管理。(arXiv)
结论:最现实的是"文-视双轨+自适应路由"
复杂混排 → 走 OCR-free;跨语种/抗扰动 → 走像素化语言;一般长上下文 → 走 token 压缩;高价值任务 可在视觉侧配合压缩,既保结构、又控成本。工程上,把三条路线做成一个路由器:检测到"表格/图表/定位"线索就走视觉路由,需要代码/严谨推理就回文本主路,必要时局部回读原文或高分图片,"既便宜又不糊"。
参考
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
UReader: Universal OCR-free Visually-situated Language Understanding with Multimodal Large Language Model
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
MinerU: An Open-Source Solution for Precise Document Content Extraction
DeepSeek-OCR: Contexts Optical Compression