在软件开发之中,高效、精准地理解代码是至关重要的环节,尤其当面对一个包含几十万行代码、上千个文件 的庞大项目时,这一挑战尤为严峻。一个典型且棘手的场景是:从一个庞杂的代码库中,快速识别并提取出 300 多个对外暴露的 API 及其详细定义。传统的代码分析方法面对这个场景往往力不从心。
本文根据字节跳动服务框架团队研发工程师尹旭然在 CloudWeGo 四周年技术沙龙上的演讲内容整理,详细介绍如何通过结合 ABCoder (AI-Based Coder) 与 Deep Code Research,使模型能够像人类专家一样深度解析代码,从而有效破解大规模代码库的理解难题。

图为字节跳动服务框架团队研发工程师尹旭然
一、传统代码分析方法的困境
当前,主流的大模型或 Agent 在执行代码理解任务时,其"原料"(即代码上下文信息)的获取方式主要依赖以下两种方法:
-
语义化搜索:通过将项目代码转化为向量化知识库,并利用语义相似性进行搜索。这种方法的精确度有限,虽然结果相关,但并非团队真正想找的目标。
-
关键字匹配:直接在代码文本中进行关键字搜索。此方法虽然直接,但严重依赖代码的字面表达,极易因缺乏上下文而遗漏关键信息或被无关内容干扰。
这些方法提供的"原料"往往精度不足,夹杂大量冗余信息。当模型处理这些低质量数据时,其有限的上下文窗口和注意力机制会被迅速占用,进而导致分析精度显著下降。
二、解决方案:模拟人类专家的代码解读模式
面对传统方法的局限,团队回归本源,深入思考一名经验丰富的开发者是如何解决这类问题的。通常,他会从应用程序的入口函数(main 函数)着手,定位到注册路由的关键节点(如 Router 或 Register 相关逻辑),然后沿着调用链层层深入,逐一追踪,最终精确地找到所有 API 的定义及其实现。
这个过程并非基于模糊的搜索,而是一种结构化的、循序渐进的深度探索。这一思路为团队提供了核心启发:让模型模拟人类专家的思维模式去走读和理解代码。基于此,团队提出了结合 ABCoder 和 Deep Code Research 的解决方案。
2.1 精准的"原料":ABCoder
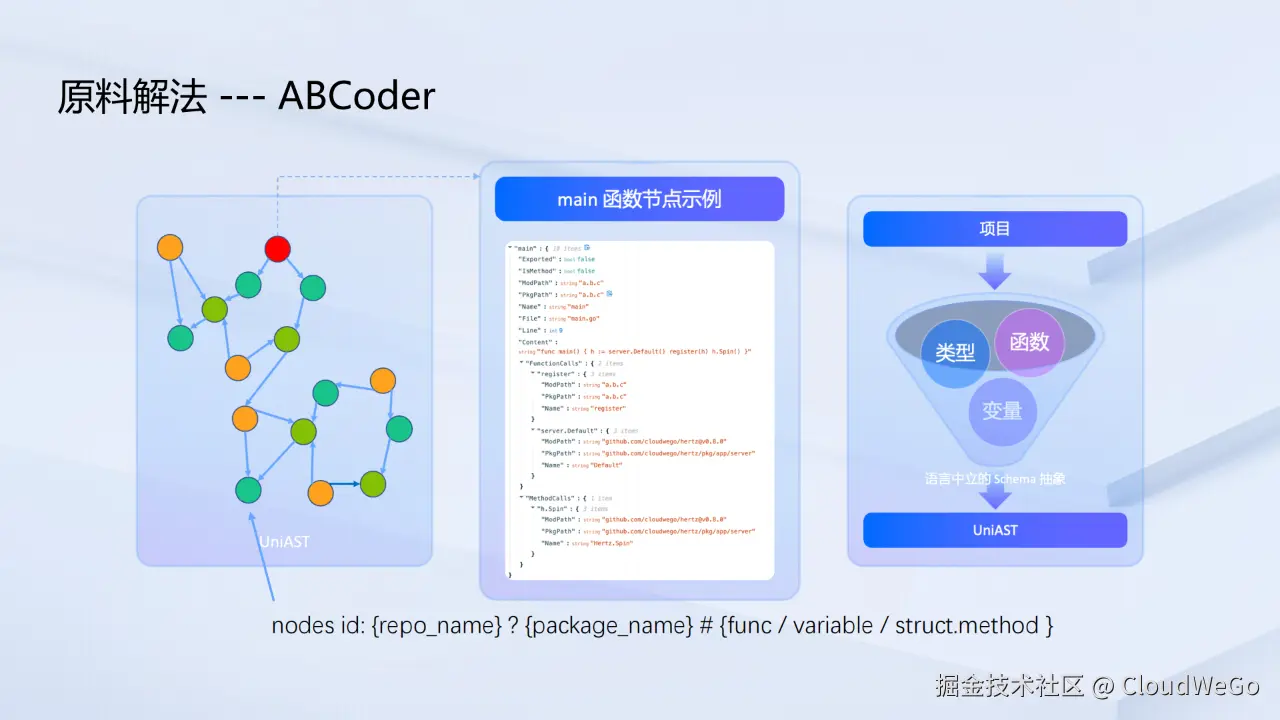
为从根本上解决"原料"的纯度问题,团队引入了 ABCoder 。它的核心理念是将整个项目代码抽象为一个语言无关的抽象语法树(UniAST),并具备以下特点:
-
节点化:代码中的变量、函数、方法等基本单元被抽象成独立的"节点"。
-
唯一标识 :每个节点都拥有一个唯一的 ID(
node id),允许系统通过该 ID 进行精准定位。 -
精确上下文:通过定位一个节点,团队可以获取其完整的、无冗余的上下文信息,包括:
-
源代码:该函数或方法的精确代码范围。
-
调用关系:该函数调用了哪些依赖,以及它被哪些其他函数所调用。
-
通过这种方式,原本分散的代码文件被重构为一张结构化、相互连接的"代码图"。分析时,团队可以从任意一个起始节点(如 main 函数对应的节点)出发,沿着调用关系进行深度探索,直至发掘出所有相关信息。这为代码的深度理解提供了前所未有的高质量"原料"。
2.2 优化的流程:Deep Code Research

仅有精准的"原料"尚不足以解决问题,因为无限制的深度探索同样会导致上下文溢出。因此,团队设计了 Deep Code Research 流程对分析过程进行优化。
-
引入 Knowledge 机制,提升信息密度 :团队在传统大模型的 Actions 架构之上,增设了一个 Knowledge 模块。在探索过程中,系统会动态评估信息的相关性,仅将对当前任务至关重要的信息存入
Knowledge模块。这意味着每一步分析都基于一份小而精的知识集,从而极大地提升了信息密度与分析效率。 -
任务分解,化繁为简:团队将宏观、复杂的任务分解为一系列更小、更具体的子任务。例如,将"找出所有暴露的 API 及其接口详情"这一复杂请求,拆解为两个步骤:
-
任务一:找出项目中所有 API 的声明或注册列表。
-
任务二 :基于第一步的产出,为每一个 API 单独创建子任务,以获取其详细的实现逻辑。
-
通过这种"化整为零"的策略,模型的处理压力得到有效缓解,其注意力也更为集中,最终显著提升了分析的准确性与深度。
三、案例对比:查找工厂类的实现
为了直观地展示该方案的有效性,团队以"查找工厂类(Factory Pattern)实现"这一具体场景进行对比。
-
传统方法 (Grep/Search) :严重依赖关键词匹配。在执行过程中,它会反复调用
search工具,尝试使用不同的关键词进行搜索。如果项目代码的语义化表达不佳,这种方式极有可能陷入无效的递归搜索循环,难以获得准确结果。 -
ABCoder + Deep Code Research
-
精准定位 :通过
get nodes detail工具直接获取main函数的精确上下文,包括其依赖的函数列表。 -
深入追查 :模型根据入口信息,识别出需要进一步检查
register函数,并沿着调用链持续深入。在追查过程中,模型能够精确识别出项目所使用的 Web 框架(如 Hertz **)**,并定位到具体的 Handler 实现。 -
得出结论:Deep Code Research 迅速完成分析,并输出其提炼的完整知识,最终精确定位了工厂模式的具体实现。
-
四、落地成果与未来展望
4.1 知识库的多维度增强
团队将 ABCoder 与 Deep Code Research 的能力应用于构建多维度增强知识库。 如果说从代码中提取的基础信息,如变量、函数、接口及其调用关系等是制作面包的"面粉",那么通过 Deep Code Research 的深度加工,团队便能得到蕴含更高价值的"面包"------即高阶领域知识。
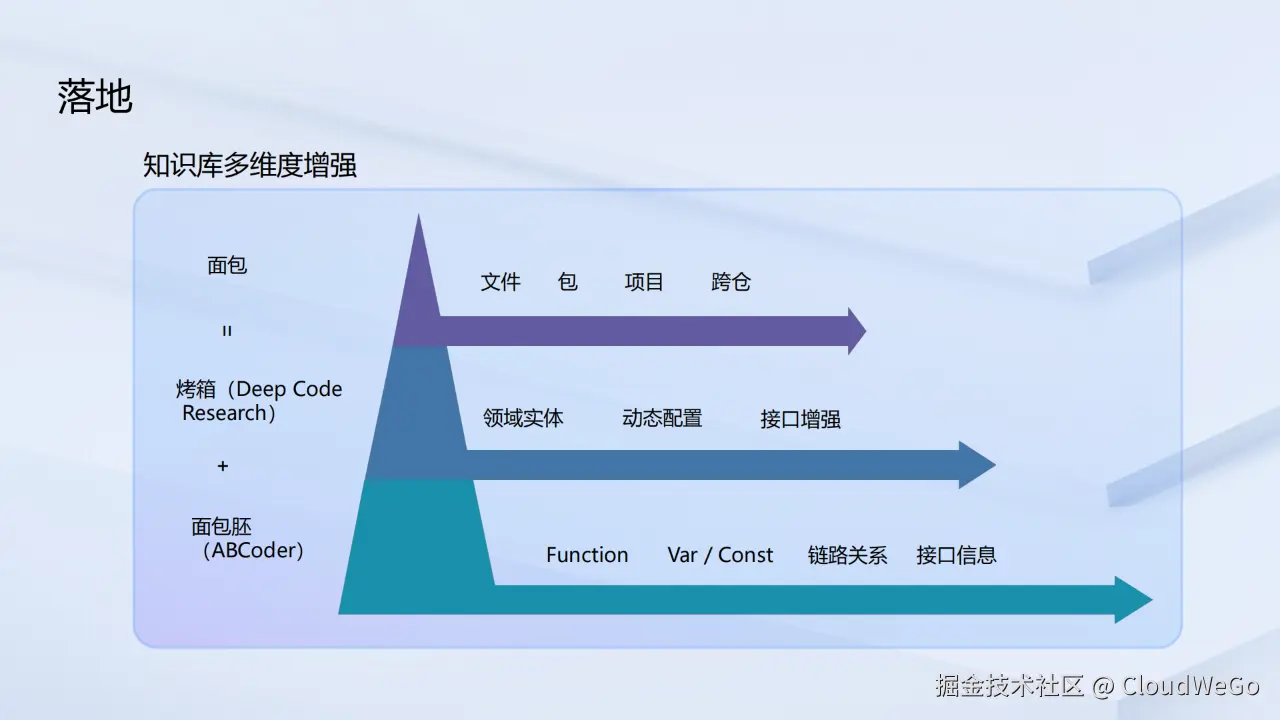
其过程如下:
-
基础信息构建:提取项目中的基础信息,构建出"代码知识图谱"。
-
高阶知识提炼:通过 Deep Code Research 对这些基础信息进行深度分析与加工,提炼出更高维度的领域知识,如领域实体、动态配置、接口间的深层依赖等。
-
关键信息整合:团队得到项目粒度的关键信息摘要,甚至能够构建出跨代码仓库的全局依赖视图。
例如,传统方法难以追踪一个服务中的字段变更对其他服务产生的具体影响。而通过 Deep Code Research,团队可以清晰地刻画数据流,从而精确评估变更的影响范围。同样,对于那些在长期迭代中注释缺失的字段,团队也能通过分析其在代码中的实际使用逻辑,反向推导出其确切含义与默认值。 此外,该技术已在火焰图分析 、系统稳定性分析 、自动化 Code Review 等多个领域展开了落地探索。
4.2 从 AI Coding 到 AI Development

团队的最终愿景,是推动 AI 在软件工程中的角色从 AI Coding 迈向 AI Development,让 AI 不再只是辅助编写代码的工具,而是能够深度参与并贯穿软件开发的全生命周期。借助结构化的代码表征(ABCoder)与深度的逻辑提炼(Deep Code Research),团队相信可以持续为业务赋能,在大幅提升研发效率的同时实现真正的降本增效。