本文介绍了生产级可观测平台的端到端设计,处理大规模实时日志、指标以及结构化/非结构化事件,满足现代大型系统对可靠日志和指标的需求。原文:Design a Distributed Logging and Metrics Platform
可观测性在现代大型系统中(无论是电商、社交平台还是物联网云)至关重要,开发者、SRE 和数据团队依赖可靠的日志、指标和事件流来理解应用行为、解决事故并做出数据驱动的决策。本文将介绍生产级可观测平台的端到端设计,处理大规模实时日志、指标以及结构化/非结构化事件。
🎯 系统需求
✅ 功能性需求
为满足工程师、分析师和系统团队的实际需求,平台必须:
- 近实时的接受来自多个源(如服务、SDK、代理、物联网设备)的日志、指标和事件。
- 支持结构化、半结构化和非结构化文本数据的输入。
- 允许解析、转换并丰富日志和事件,并包含元数据(如 user_id、环境、版本)。
- 提供全文搜索日志,并带有时间戳、服务或错误级别等筛选条件。
- 支持跨时间范围和聚合窗口查询指标。
- 支持类似SQL的查询,并通过 Presto、Trino 或 Spark SQL 等引擎通过事件数据集连接。
- 处理基于标签(如 org_id、区域、event_type)到不同处理路径或汇聚点的消息路由。
- 提供阈值警报和异常检测(例如通过 Grafana 或 Prometheus)。
- 公开 API 和仪表盘,供日志和指标使用。
- 允许历史日志和事件存档于冷存储中,以支持合规或审计。
🔒 非功能性需求
在性能和可靠性方面,系统必须:
- 每秒接收数百万事件,端到端延迟 < 100ms。
- 实现跨数据中心和区域的容错,确保无单点故障。
- 每个层级(输入、流处理、存储和查询)支持横向扩展。
- 利用 TLS 和 KMS 加密静态和实时敏感数据。
- 启用细粒度访问控制(RBAC),并通过审计日志跟踪访问。
- 提供自修复、自动扩展和平台本身的可观测性。
- 将存储分为热存储(快速访问)和冷存储(成本效益高)两个层级。
- 支持模版升级、数据验证和模版注册表集成。
- 实现云中立或兼容混合云,适用于全球工作负载。
📈 容量估算
输入量
- 峰值输入速率:200万次事件/秒
- 日处理量:~1500亿事件/天
日志大小
- 平均日志/事件大小:1.2 KB
- 每日总输入量:~180 TB/天
存储需求
- 热存储(7天保留):~1.2 PB
- 冷存储(90天):~16 PB(假设 Parquet 压缩为2:1)
⚙️ Kafka 容量与对齐
Kafka 作为将输入与下游处理分离的骨干。
为什么是卡夫卡?
Kafka 因其高吞吐量、耐用性、内置复制和生态系统集成而被选中,支持至少一次传输、水平分区和细粒度重放功能。
配置详情:
- 主题分区:约 15,000
- 为了安全处理每秒 2M 事件(≈2,400 MB/秒),保持分区负载 < 10MB/s
- 因此,2400 / 10 = 240 分区的最小分区 → 可扩展到 15,000 分区,以支持多租户、重试和并行处理
- 代理数量:约 150
- 每个分区处理约 100 个活动分区,日志段使用 NVMe SSD
- 复制因子:3(跨机架的 HA)
- 保留时间:热日志保留 3 天,之后进行下游 ETL 或冷归档
- 背压:Kafka 提供有界队列和通过消费者延迟监控的流量控制
🔄 流处理(Apache Flink)
Apache Flink 用于实时、高通量的流处理,如修饰、转换、窗口聚合、异常检测和路由。
为什么是Flink?
- 原生事件时支持(带水印)处理乱序数据
- 低延迟流式传输,高吞吐量,并实现细粒度检查点
- 使用 RocksDB 状态后端实现容错且保证一次的准确性
- 支持丰富的CEP(复杂事件处理)、异步I/O和广播状态
配置:
- 操作符:基于 CPU/内存使用率,可并行 20--50 个
- 事件时间支持:用于乱序窗口的水印
- 检查点设置:RocksDB 状态后端 + S3 检查点(约 100 TB 总状态)
- 恢复 SLA:任务管理器 < 2分钟,否则作业失败
- 使用场景:多租户路由、异常检测、装饰连接
🔍 弹性搜索集群
由 Elasticsearch 驱动日志全文搜索和结构化字段查询。
为什么选择Elasticsearch?
- 成熟且经过生产验证的全文搜索引擎
- 嵌套 JSON 文档的实时索引与查询
- 与 Kibana 集成用于可视化仪表盘
配置:
- 原始日志导入:约 100+ TB/天(未压缩)
- 索引:文本 + JSON 字段映射
- 集群布局:300 个热节点,100 个热节点
- 保留:
- 热数据(7 天):快速 SSD 支持型
- 温数据 (30 天): 较慢的 EBS
- 冷数据(快照到 S3 或 GCS)
- 分片:按租户或服务分片,带有每日轮转指数
🏞️ 对象存储(S3 / GCS)上的数据湖
批处理分析、长期保留和临时探索均通过数据湖处理。
为什么选择对象存储+湖屋引擎?
- 便宜、耐用、无限扩展
- 兼容所有主要引擎(Spark、Trino、Presto、Hive)
- 通过解耦计算和存储以节省成本
配置:
- 每日输入量:约 30 TB/天(Snappy Parquet)
- 分区方式:按
org_id,event_type,dt分区 - 查询引擎:Presto、Trino、Athena、BigQuery
- 生命周期政策:
- 90天有效
- 冷数据/归档层
- 一年后删除(合规受控)
📉 时间序列数据库(指标)
兼容Prometheus(如 Mimir、Cortex、VictoriaMetrics)支持低延迟的指标输入和提醒。
为什么选择时间序列数据库?
- 内置支持聚合、压缩和降采样
- 设计用于高基数和维度标记
- 与 Grafana 和 PromQL 紧密集成
配置:
- 采样率:800 万采样率/秒
- 基数:500万唯一时间序列(通过维标签)
- 保留:30天原始素材 → 降采样层级(1m、5m、1h)
- 存储估算:压缩后每月 100 TB
- 使用场景:SLO、Grafana 仪表盘、异常检测
🧠 设计权衡
Kafka vs. Kinesis / Pulsar
- 选择卡夫卡是因为成熟度、更强的社区和更优越的回放控制。
- Pulsar 原生支持分层存储,但 Kafka + S3 汇聚连接器实现了类似的效果。
Elasticsearch vs. OpenSearch vs. Loki
- 选择 Elasticsearch 是因为更高的成熟度和生态系统支持(例如Kibana)。
- Loki 仅在日志工作负载中更具成本效益,但缺乏全文搜索功能。
- OpenSearch 是一个开源可选项,但在某些版本中缺乏商业支持和稳定性。
Flink vs. Spark Streaming vs. Kafka Streams
- Flink 提供原生事件处理、更好的有状态计算扩展性和高吞吐量。
- Spark 是批处理优化的,Kafka Streams 对于多阶段流水线来说过于简单。
数据湖与传统数据库的区别
- 数据湖更具规模效益,支持读前模式(schema-on-read),能够处理庞大且多样化的格式。
- Iceberg/Hudi/Delta 等湖屋(Lakehouse)能为原生数据湖带来更好的索引和稳定性。
时间序列数据库与 InfluxDB / OLAP
- Prometheus 兼容的后端更适合 Kubernetes 原生工作负载。
- 像 Druid/ClickHouse 这样的OLAP引擎可以补充长期聚合。
mTLS, RBAC & KMS
- mTLS:确保内部微服务之间的相互认证。
- RBAC:基于角色的 API 和 UI 访问策略。
- KMS 集成:S3、Elasticsearch 和数据库的加密密钥管理。
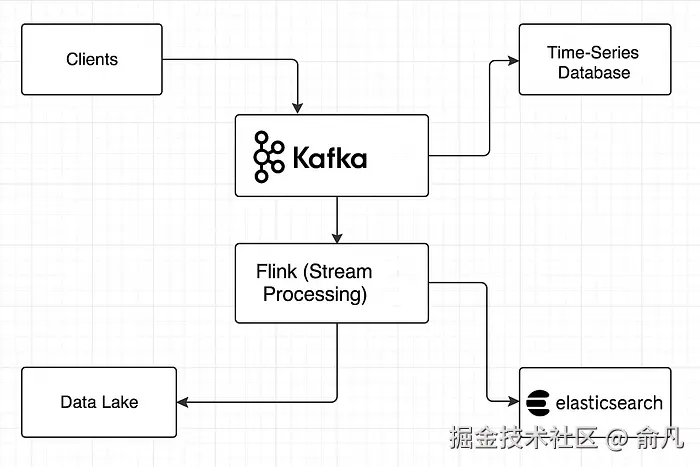
🔁 数据流解释
1. 客户端/应用层:
- 服务、SDK和代理会向输入端点发送日志/指标/事件。
2. Kafka 层:
- 消息落在分区的 Kafka 主题上(基于 org_id、env 等标签)。
- Kafka 缓冲流量,支持重试,并启用扇出功能。
3. Flink 处理:
- 读取 Kafka 数据,丰富事件、筛选,并路由到 Elasticsearch、S3 或指标数据库。
- 数据转换(例如扁平化、JSON 模式修复、异常检测)。
4. Elasticsearch:
- 获取富日志,索引结构化/非结构化字段。
- 通过 Kibana 暴露 API 和仪表盘。
5. 数据湖:
- Flink/Spark 批处理作业会将原始/聚合日志推送到 Parquet 的 S3。
- 可以通过 Trino/Presto/Athena 进行分区修剪查询。
6. 时间序列数据库:
- 兼容 Prometheus 的系统指标抓取或接收数据 exporter 的推送。
- 支持实时仪表盘和提醒。
7. 冷存储/归档:
- 保留窗口结束后,数据会归档到冷存储(Glacier)或深度归档(Deep Archive)层级。
8. 访问层:
- API、仪表盘和 SQL 引擎向用户和系统提供数据。
🧪 深度问答
问题 1. 如何将 Kafka 扩展到超过 15,000 个分区?
- 使用多个按组织/环境分片的 Kafka 集群。
- 对旧消息采用分层存储。
- 使用 Kafka Raft(KRaft)模式以提升控制器的可扩展性。
问题 2. 如果 Flink 作业检查点失败会发生什么?如何恢复?
- Flink 会回到最后一个成功的检查点。
- 恢复方法:修复问题根源(例如磁盘/满载状态、损坏状态),并在启用 HA 的状态下重启作业。
问题 3. 如何确保 Kafka 与下游消费者之间的幂等性?
- 使用 Kafka 消息键进行查重。
- 应用一致的唯一 event_id,并在下游汇聚点(如 ES 或 DB)中跟踪。
问题 4. 为什么在这种设计中选择 Elasticsearch 而不是 OpenSearch?
- 更稳定的生态系统,更好的可观测集成。
- 商业支持(如有需要),但 OpenSearch 更受青睐,因为许可证灵活性更高。
问题 5. 如何划分 Kafka 主题以实现多租户隔离?
- 主题名称如
log.org_<org_id>.env_<env> - 每个租户使用不同的主题,并应用 ACL 来执行访问控制。
问题 6. Kafka → Flink → ES 的背压处理机制是什么?
- 启用 Flink 缓冲区超时调优和异步检查点。
- Kafka 消费者延迟监控 + Flink 操作指标。
- 调整 ES 的批量和重试策略。
问题 7. 如何在 Elasticsearch 和 S3 中实现符合 GDPR 的删除功能?
- 在 ES + 生命周期策略中使用文档级 TTL 或标签。
- 对于 S3:按组织/日期划分,使用 Lambda 根据请求日志进行删除。
问题 8. 如果日志峰值飙升至 5M/秒,最先出现的瓶颈是什么?怎么修复?
- Kafka 磁盘/网络 I/O 使用 SSD 支持的代理 → 增加分区。
- Flink 反压 → 扩展作业管理器/任务管理器。
- ES 批量索引队列饱和 → 扩展 ES 数据节点,调优 JVM 堆和队列设置。
运维与基础设施重点
问题 1. 如何在服务之间启用 mTLS?用什么工具来轮换认证?
- 使用 Istio 或 Consul Connect 实现自动 mTLS。
- 证书管理器(带 Vault 或 ACM)用于签发/轮换 TLS 证书。
问题 2. 日志输入和搜索延迟的 SLO 是多少?
- 导入时间:日志为 p95 < 2s,指标为 < 1s。
- 搜索延迟:最近日志为 p95 < 1s,30 天保留日志为 64s 秒。
问题 3. 如何根据流量量自动调整 Flink 作业?
- 监控 Kafka 延迟 + Flink 操作使用率。
- 使用 Flink 的反应式缩放模式 + Kubernetes HPA。
问题 4. 如何进行基准测试,并选择 NVMe 还是 EBS 作为 ES 集群?
- 为各种查询/写工作负载运行一次拉力基准测试。
- NVMe 提供更好的 IOPS,可用于高 QPS 集群,成本敏感工作负载则回退到 EBS。
高级分析
问题 1. 如何将 Kafka 中的日志与数据库中的元数据(例如用户信息)连接起来?
- 使用 Flink 异步 I/O 操作实时丰富日志。
- 缓存频繁查询或使用侧输入(side-inputs)。
问题 2. 如何近实时的检测系统日志中的异常?
- Flink + 滑动窗口聚合 + z 分数/异常值检测。
- 使用部署在 Flink 上的机器学习模型,或发送丰富的日志给异常检测服务。
问题 3. 如何防止 Prometheus 中的高基数问题?
- 限制动态标签的使用(例如 user_id、IP)。
- 使用录制规则 + 在刮取时下采样。
🚦 总结
该日志与可观测性平台设计具备以下功能:
- 处理 PB 级日志流
- 支持实时指标仪表盘
- 实现跨多层的高效连接和分析查询
- 通过低延迟、高可用性架构来保证SLA
以 Kafka、Flink、Elasticsearch 和 S3 为核心构建模块,该系统已具备生产准备,适合初创企业和企业。添加托管解决方案(如MSK、OpenSearch、Dataflow)以简化操作。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!