前言
上篇文章我们讲述了 BeanFactoryPostProcessor 的作用,这篇文章我们来学习单例 Bean 的创建过程,这个过程中涉及了 BeanPostProcessor 、Aware、 InitializingBean 等重要的接口,是生命周期的核心点,也是我们后续自定义扩展需要熟悉的核心接口。
本篇文章使用的 SpringBoot 版本是 3.4.1 ,对应 Spring 版本 6.2.1。
SpringBoot & Spring 架构图示概览
这里我以 SpringBoot 源码入口为起点,画了一个相关的流程图,包含了 SpringBoot、Spring 事务、Spring AOP、Spring 事件、BeanFactoryPostProcessor、BeanPostProcessor 等所有 Spring 知识,以及相关模块之间的交互联系,后续也会持续更新此图(因为我自己还没有学完),我试了下作者侧这边更新后,分享的协作链接也会实时变更,希望对大家有帮助
SpringBoot & Spring 架构图 持续更新 对于即将需要面试的同学应该会比较有帮助!
Bean 的创建过程&生命周期图示
Bean 的生命周期从上往下,如图
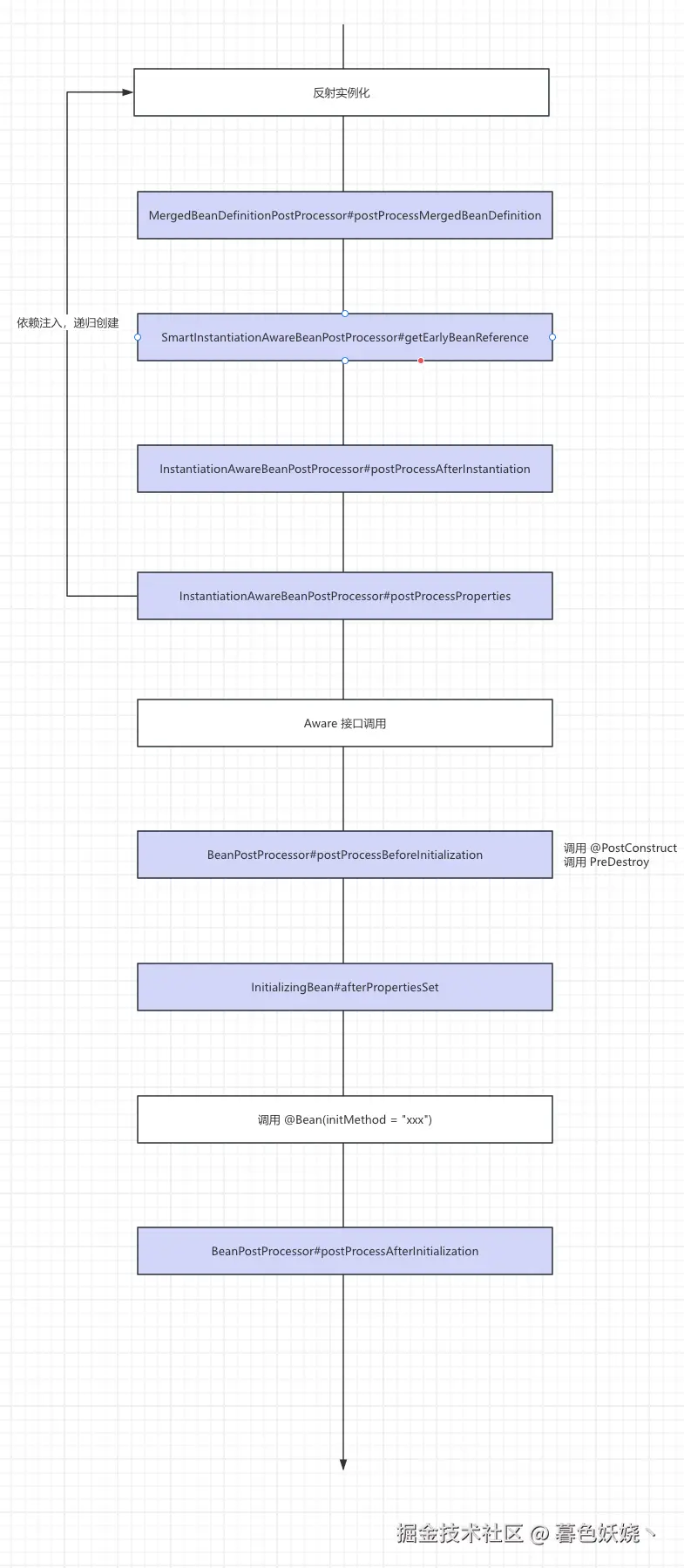
其实很多人可能看着网上的教程,各种说 Bean 的生命周期,什么回调函数,什么后置处理,第一次接触可能会看着有点懵逼,自己都不知道自己在干什么,也不知道这样做的意义。
其实很简单, 就是一个 Bean 从创建到完成的过程中会调用一批固定的方法,这批固定的方法存在于不同的接口中,这是为了代码直观,和分层设计,而我们熟悉了这个过程中各种接口的作用和调用顺序,就可以在日常使用 Spring 框架时,根据业务需求做出各种各样的自定义扩展。
下面我们一一说明这些接口的作用。
BeanPostProcessor 顶层接口
顶层后置处理器接口,查询接口的注释,这也是一个回调方法。提供两个方法让子类扩展,作用时机是在 Bean 创建过程中被调用
java
/**
* Bean 初始化前调用
*/
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
/**
* Bean 初始化后调用
*/
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}上一段生命周期图中标颜色的步骤,全都是它或者它的扩展接口。
BeanPostProcessor 和 BeanFactoryPostProcessor
这两个处理器名字很相似,但是作用大不相同,下图列出了它们的区别
| 接口 | BeanFactoryPostProcessor | BeanPostProcessor |
|---|---|---|
| 作用阶段 | Bean 定义加载阶段,Bean 实例化前 | Bean 实例化后,初始化前后 |
| 处理目标 | BeanDefinition(Bean 的元数据) | Bean 实例对象 |
| 接口方法 | postProcessBeanFactory() ...子接口 |
postProcessBeforeInitialization() postProcessAfterInitialization() ...子接口 |
| 主要功能 | 修改、添加、删除 BeanDefinition | 修改、包装、代理 Bean 实例 |
| 执行时机 | Spring 容器启动早期 | 每个 Bean 的生命周期中,初始化前后 |
| 执行次数 | 整个容器启动过程执行一次 | 每个 Bean 实例化后都会执行两次(前后各一次,不包括扩展接口) |
| 访问权限 | 可访问所有 BeanDefinition,可修改容器配置 | 只能访问当前处理的 Bean 实例,不能修改容器配置 |
| 常见实现 | ConfigurationClassPostProcessor(处理配置类) | AutowiredAnnotationBeanPostProcessor(处理@Autowired 注入) |
MergedBeanDefinitionPostProcessor
和 BeanFactoryPostProcessor 的扩展接口 BeanDefinitionRegistryPostProcessor 类似,MergedBeanDefinitionPostProcessor 是 BeanPostProcessor 的子接口,在 BeanPostProcessor 的两个方法执行前,在 Bean 定义合并后,会执行 MergedBeanDefinitionPostProcessor.postProcessMergedBeanDefinition()
Spring会根据BeanDefinition创建Bean,但是最终BeanDefinition必须被转成RootBeanDefinition,Bean合并的过程就是把不同类型的BeanDefinition转成RootBeanDefinition,以及合并一些父类属性和方法等,得到一个最终的BeanDefinition。
典型的实现是 AutowiredAnnotationBeanPostProcessor, 在重写的 postProcessMergedBeanDefinition() 方法中缓存了当前 Bean 所需要注入的其他 Bean 的相关信息。例如
java
@Service
@Slf4j
public class EventListenerTestService1 {
@Autowired
private ApplicationEventPublisher publisher;
@Autowired
private CashRepayApplyMapper cashRepayApplyMapper;
@Autowired
private EventListenerTestService2 listenerTestService2;
}那么在创建 EventListenerTestService1 的 Bean 对象的过程中,就会调用 postProcessMergedBeanDefinition() 方法,缓存这三个标注了 @Autowired 的类相关信息,后面进行依赖注入的时候会直接从缓存取类信息,然后进行创建这三个成员变量的 Bean 实例
InstantiationAwareBeanPostProcessor
它也是 BeanPostProcessor 的子接口,扩展了一个 postProcessProperties(),经典的实现也是 AutowiredAnnotationBeanPostProcessor 在这里获取 postProcessMergedBeanDefinition() 方法中缓存的注入信息,进行实际依赖注入,这一步完成之后,当前 EventListenerTestService1 的三个成员变量都创建了对应的 Bean 对象
java
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
//注入 @Autowired 成员
metadata.inject(bean, beanName, pvs);
}
//......
return pvs;
}在 metadata.inject(bean, beanName, pvs) 这一步会先从 ApplicationContext 中寻找已存在的符合的 Bean,如果找不到会走创建 Bean 的流程,这是一个递归,如果需要创建的 Bean 内部也有依赖,会继续递归创建。参考
AbstractAutowireCapableBeanFactory#populateBean↓AutowiredAnnotationBeanPostProcessor#postProcessProperties↓DefaultListableBeanFactory#doResolveDependency↓AbstractBeanFactory#getBean开始递归
SmartInstantiationAwareBeanPostProcessor
它是 InstantiationAwareBeanPostProcessor 的扩展接口,查看这个类的注释,告诉我们这个类是一个特殊的扩展,通常来说只用于框架内部,如果我们业务需要扩展应该直接实现 BeanPostProcessor 。它新增了几个扩展方法,其中有一个很重要的
java
public interface SmartInstantiationAwareBeanPostProcessor extends InstantiationAwareBeanPostProcessor {
/**
* 获取早期引用(三级缓存、代理的实现)
*/
default Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {
return bean;
}AbstractAutoProxyCreator 是它的经典实现,getEarlyBeanReference() 就是为了解决循环依赖过程中,被依赖的 Bean 需要代理。最常见的情况是我们的 Bean 有事务,Spring 事务是需要通过代理来实现的。
java
//org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator#getEarlyBeanReference
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyBeanReferences.put(cacheKey, bean);
return wrapIfNecessary(bean, beanName, cacheKey);
}Aware
Aware 是一个重要通知接口,翻译中文为 意识到,查看注释说它是一个顶层标记接口,表示 Bean 可以通过回调方式被 Spring 容器通知某个对象。实际的方法签名由各个子接口决定,但通常应只定义一个单个入参的 void 方法。例如
java
public interface ApplicationContextAware extends Aware {
void setApplicationContext(ApplicationContext applicationContext) throws BeansException;
}它的作用是给我们的 Bean 设置一些框架内部对象,防止我们扩展的接口需要这些对象,例如
- 当前上下文
ApplicationContext - 当前
BeanFactory - 当前
Bean的名字 - 当前环境对象
Environment - 当前事件发布器
ApplicationEventPublisher - 等等
参考典型的实现 ApplicationContextAware、EnvironmentAware,让我们的 Bean 实现 EnvironmentAware ,就可以在我们 Bean 这个类中获取到 Environment 对象使用
BeanPostProcessor#postProcessBeforeInitialization
Bean 初始化过程前执行,Aware 调用之后执行 。一个典型的实现是 ApplicationContextAwareProcessor,由于上一步调用invokeAwareMethods,只判断了三种类型
java
private void invokeAwareMethods(String beanName, Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware beanNameAware) {
beanNameAware.setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware beanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
beanClassLoaderAware.setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware beanFactoryAware) {
beanFactoryAware.setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}所以对于扩展的 EnvironmentAware、ApplicationContextAware、ApplicationEventPublisherAware 等这些内置扩展的通知接口需要额外特殊处理,因此 Spring 框架把这个工作放到了ApplicationContextAwareProcessor#postProcessBeforeInitialization() 中
Aware 接口分开处理的原因
如果仔细思考你可能会疑惑,既然 Bean 创建过程中会调用 invokeAwareMethods(),那为什么不把EnvironmentAware、ApplicationContextAware、ApplicationEventPublisherAware 这些通知接口也放到这个方法里设置对应的值,而是要再弄一个 ApplicationContextAwareProcessor 来实现呢?是否多此一举?查看 ApplicationContextAwareProcessor#postProcessBeforeInitialization() 源码
java
@Override
@Nullable
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof Aware) {
invokeAwareInterfaces(bean);
}
return bean;
}
private void invokeAwareInterfaces(Object bean) {
if (bean instanceof EnvironmentAware environmentAware) {
environmentAware.setEnvironment(this.applicationContext.getEnvironment());
}
if (bean instanceof EmbeddedValueResolverAware embeddedValueResolverAware) {
embeddedValueResolverAware.setEmbeddedValueResolver(this.embeddedValueResolver);
}
if (bean instanceof ResourceLoaderAware resourceLoaderAware) {
resourceLoaderAware.setResourceLoader(this.applicationContext);
}
if (bean instanceof ApplicationEventPublisherAware applicationEventPublisherAware) {
applicationEventPublisherAware.setApplicationEventPublisher(this.applicationContext);
}
if (bean instanceof MessageSourceAware messageSourceAware) {
messageSourceAware.setMessageSource(this.applicationContext);
}
if (bean instanceof ApplicationStartupAware applicationStartupAware) {
applicationStartupAware.setApplicationStartup(this.applicationContext.getApplicationStartup());
}
if (bean instanceof ApplicationContextAware applicationContextAware) {
applicationContextAware.setApplicationContext(this.applicationContext);
}
}可以看到这是因为 EnvironmentAware 等接口需要设置的成员变量都是 ApplicationContext 内部的对象,而 DefaultListableBeanFactory 从设计上来说是不该持有 ApplicationContext 的引用的,也就是说 DefaultListableBeanFactory 拿不到这些对象,是 ApplicationContext 容器持有 DefaultListableBeanFactory 的引用。而 DefaultListableBeanFactory 没有这些对象,所以无法在 invokeAwareMethods() 设置
InitializingBean
这是一个 Bean 的初始化接口,在 BeanPostProcessor#postProcessBeforeInitialization 之后调用,从方法名可以看出,此时属性已经全部设置完毕。我们可以实现 InitializingBean 在 afterPropertiesSet() 中做一些自定义逻辑
java
public interface InitializingBean {
void afterPropertiesSet() throws Exception;
}注意,这里指的属性是被
Spring容器管理的属性,不包括我们自定义的属性,例如使用@Autowired、@Value标注的属性,或者实现Aware接口之后setApplicationContext等方法中的属性。这些被
Spring容器管理的属性赋值完毕后会调用这个afterPropertiesSet()方法
调用 @Bean(initMethod = "xxx")
afterPropertiesSet() 调用之后,会紧接着调用自定义的 init 方法。
SmartInitializingSingleton
这个接口的作用是当所有单例 Bean 被创建完成之后,调用其方法
java
public interface SmartInitializingSingleton {
void afterSingletonsInstantiated();
}一个典型的实现就是 EventListenerMethodProcessor,当所有单例 Bean 创建完成之后,EventListenerMethodProcessor.afterSingletonsInstantiated() 会遍历所有创建完成的 Bean,查找被 @EventListener、@TransactionalEventListener 注解的,根据不同的 EventListenerFactory 创建不同的 ApplicationListener 实现,添加到当前 ApplicationContext 中。这就是 Spring 事件的基本原理。
java
public void testPublish1(){
publisher.publishEvent(new TestEvent(this,1L));
}
@EventListener
public void listenerTestPublish1(TestEvent event){
log.info("listenerTestPublish1 TestEvent:{}",event);
}当执行 publisher.publishEvent() 时,就会去 ApplicationContext 内部提前存储的监听器列表中寻找符合的监听器,然后执行。可能会存在多个,这相当于广播本地消息。可同步执行,也可以异步执行,甚至还能条件执行,绑定事务执行,后面会详细剖析 Spring 事件的原理
SmartInitializingSingleton 是在所有单例 Bean 创建完成之后执行,是一个特殊的生命周期接口
让人费解的三级缓存
其实标题想表达的并不是三级缓存很复杂,倒是我不明白这东西为什么能一度成为高频面试题,下面这段是这三个缓存集合
java
// 一级缓存(Bean 容器):存放完全初始化好的单例 Bean(成品)
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存:存放早期的 Bean(已实例化未初始化的半成品),解决循环依赖
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
// 三级缓存:存放单例工厂,用于创建早期引用(可能生成代理对象)
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);其实就是一个很简单的创建过程,假设现在我们循环依赖的两个 Bean 都需要被代理
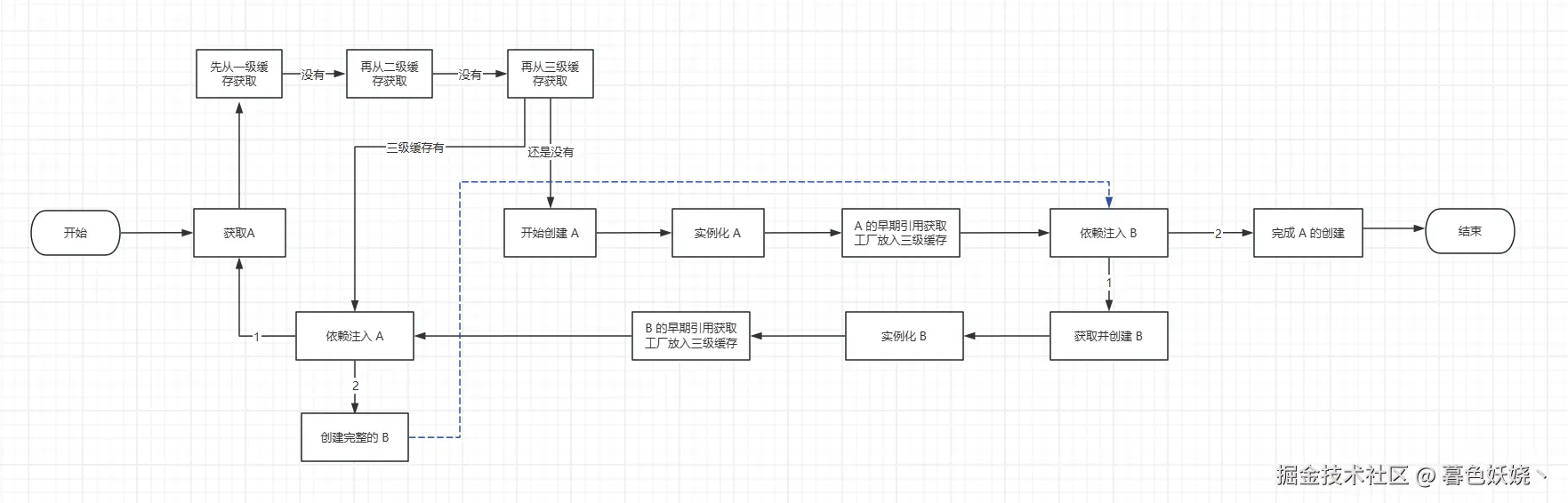
A 与 B 循环依赖的场景,先实例化 A,然后创建 A 的完整 Bean,结果发现 A 依赖 B,然后立即去创建 B 的完整 Bean,发现需要 A,但是 A 的实例已经有了,只是 A 还不是完整的 Bean,但是这完全不影响,只要 A 的实例有了,B 就可以持有 A 的引用,至于它什么时候变成完整的 Bean,B 是不关心的,因为 B 已经持有 A 的引用,A 变成完整 Bean 的过程只是 A 对象的内存内容发生变化,内存地址不会变。
markdown
AService 创建开始
→ 实例化原始对象
→ 早期引用工厂放入三级缓存
→ 需要注入 BService
→ 创建 BService
→ 实例化 BService 原始对象
→ 早期引用工厂放入三级缓存
→ 需要注入 AService
→ 从三级缓存获取 AService
→ 创建 AService 早期代理(第一次代理生成)
→ 注入到 BService
→ BService 初始化完成
→ 创建 BService 最终代理(第二次代理生成)
→ BService 完成
→ BService 代理注入到 AService
→ AService 初始化完成
→ 使用早期代理作为最终代理
→ AService 完成本质上就是一个 A → B → A 的问题,我不明白为什么能成为高频面试题,这似乎没有什么高难度技术含量,从三级缓存获取 Bean 源码如下
java
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从一级缓存获取
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
//一级缓存没有,再从二级缓存获取
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
if (!this.singletonLock.tryLock()) {
// Avoid early singleton inference outside of original creation thread.
return null;
}
try {
// 加锁再次判断一级缓存
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//再判断二级缓存
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
//从三级缓存获取
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
// 三级缓存获取到就放入二级缓存
if (this.singletonFactories.remove(beanName) != null) {
this.earlySingletonObjects.put(beanName, singletonObject);
}
else {
singletonObject = this.singletonObjects.get(beanName);
}
}
}
}
}
finally {
this.singletonLock.unlock();
}
}
}
return singletonObject;
}真的需要第三级缓存吗
我们思考这个场景,是否一定需要三级缓存,如果换成二级缓存是否可以?其实如果所有的 Bean 都不需要代理的话,完全可以。第三级的缓存就是为了解决依赖的 Bean 需要被代理存在的,如果允许循环依赖,在创建 Bean 的过程中
java
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}会向第三级缓存中存放一个工厂方法,用来获取 Bean 的引用。我们可以看到 singletonFactories 第三级缓存的 value 是一个 ObjectFactory<?> 。
所谓第三级缓存就是在内存里找个地方先存着这个工厂回调方法,等创建当前 A 所依赖的 B 时,发现 B 需要 A,那么就从这里来获取 A 的真实引用,因为 A 实例的引用已经存在了,如果不需要代理那么我们直接获取这个 A 的实例引用即可,但是我们为了防止 A 是一个有事务的 Bean,防止它需要被代理,所以从这个工厂获取真实引用。
java
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}AbstractAutoProxyCreator#getEarlyBeanReference() 会返回被代理后(如果需要)的对象引用
回头再看三级缓存
其实抛开 singletonObjects 先不谈,因为它是 Bean 容器,只有两个缓存的 ConcurrentHashMap,singletonFactories 是存放早期引用的获取工厂,因为我们不确定是否会发生循环依赖,以备不时之需。而 earlySingletonObjects 就是存放调用早期引用工厂后获取的引用,如果需要被代理,存储的就是代理对象,如果不需要被代理,存储的就是原始对象。
因为工厂执行后返回的是最终真实代理对象,我们需要有个地方存储它,所以二级缓存 earlySingletonObjects 是必要的
说白了就是我需要找个地方临时存放一下这两个操作得到的结果,至于你存在哪无所谓,所谓的三级缓存不过是这些面试官自己凭空定义出来的概念罢了。
自定义扩展修改一个 Bean 的方式
现在我们来思考假如我们需要自定义扩展,修改一个 Spring Bean 有哪些方式
修改 BeanDefiniton
因为 Bean 的创建是根据 BeanDefinition 决定的,所以我们可以自定义 BeanFactoryPostProcessor ,根据 beanDefinitionNames 获取指定的 BeanDefinition 对其属性进行修改
java
@Bean
public BeanFactoryPostProcessor myBeanFactoryPostProcessor(){
return new BeanFactoryPostProcessor() {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
BeanDefinition testBean = beanFactory.getBeanDefinition("testBean");
testBean.setAttribute("name", "test");//修改指定属性
}
};
}自定义 BeanPostProcessor
因为所有 Bean 创建都会执行 BeanPostProcessor,所以我们可以自定义一个 BeanPostProcessor
java
@Bean
public BeanPostProcessor myBeanPostProcessor(){
return new BeanPostProcessor() {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if(beanName.equals("testBean")){
//先强转 bean
//然后设置属性
}
return BeanPostProcessor.super.postProcessAfterInitialization(bean, beanName);
}
};
}判断当执行到我们目标 Bean 的时候对其修改
定义 Customizers
很多 SpringBoot 自动配置的 Bean 为了方便都给开发者预留了客户定制化器,例如事务管理器的自动配置
java
@Configuration(proxyBeanMethods = false)
@ConditionalOnSingleCandidate(DataSource.class)
static class JdbcTransactionManagerConfiguration {
@Bean
@ConditionalOnMissingBean(TransactionManager.class)
DataSourceTransactionManager transactionManager(Environment environment, DataSource dataSource,
ObjectProvider<TransactionManagerCustomizers> transactionManagerCustomizers) {
DataSourceTransactionManager transactionManager = createTransactionManager(environment, dataSource);
//应用 TransactionManagerCustomizers 包装 Bean 集合
transactionManagerCustomizers.ifAvailable((customizers) -> customizers.customize(transactionManager));
return transactionManager;
}
//创建 jdbc 事务管理器
private DataSourceTransactionManager createTransactionManager(Environment environment, DataSource dataSource) {
return environment.getProperty("spring.dao.exceptiontranslation.enabled", Boolean.class, Boolean.TRUE)
? new JdbcTransactionManager(dataSource) : new DataSourceTransactionManager(dataSource);
}
}
java
@ConditionalOnClass(PlatformTransactionManager.class)
@AutoConfiguration(before = TransactionAutoConfiguration.class)
@EnableConfigurationProperties(TransactionProperties.class)
public class TransactionManagerCustomizationAutoConfiguration {
@Bean
@ConditionalOnMissingBean
TransactionManagerCustomizers platformTransactionManagerCustomizers(
ObjectProvider<TransactionManagerCustomizer<?>> customizers) {
//应用 TransactionManagerCustomizer 集合 Bean
return TransactionManagerCustomizers.of(customizers.orderedStream().toList());
}
@Bean
ExecutionListenersTransactionManagerCustomizer transactionExecutionListeners(
ObjectProvider<TransactionExecutionListener> listeners) {
//应用 TransactionExecutionListener 集合 Bean
return new ExecutionListenersTransactionManagerCustomizer(listeners.orderedStream().toList());
}
}那我们只要定义一个或者多个 TransactionExecutionListener 交给 Spring 管理就会自动配应用到当前数据源的事务管理器上,监听事务的执行阶段
@Bean 替换
SpringBoot 中自动配置类的 @Bean 声明都加了条件注解当不存在这个 Bean 的时候才会生效,我们可以把源码中的声明拷贝过来修改其中一些部分,例如
java
@Bean
//@ConditionalOnMissingBean 去掉这个
public SqlSessionTemplate sqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
//...修改自定义逻辑
ExecutorType executorType = this.properties.getExecutorType();
if (executorType != null) {
return new SqlSessionTemplate(sqlSessionFactory, executorType);
} else {
return new SqlSessionTemplate(sqlSessionFactory);
}
}结语
静态文本的方式始终无法形象的解析详细的代码执行过程,这里只能提供一些关键代码,要深入理解还需要我们自己多读源码,多实践。