用 LangChain 实现有记忆的多轮对话:给 AI 配一个"数字笔记本"
大模型像一位健忘的天才------聪明但记不住事。而 LangChain,就是它的专属笔记本和秘书。
在构建聊天机器人时,我们常遇到一个尴尬场景:
你刚告诉 AI "我叫田晨枫",下一秒问"我叫什么",它却一脸茫然。
这不是它笨,而是大模型天生"无状态" ------每次对话都像第一次见面。
要让它记住你,我们需要一套机制:记录、携带、更新你的对话历史。
LangChain 正是为此而生。下面,我们通过代码 + 比喻,一步步搭建这个"记忆系统"。
一、问题演示:没有笔记本的"健忘天才"
js
const model = new ChatDeepSeek({
model:'deepseek-chat',
temperature:0,
});
const res = await model.invoke('我叫田晨枫,喜欢吃鸡腿饭')
console.log(res.content);
console.log('---------------');
const res2 = await model.invoke('我叫什么名字')
console.log(res2.content);
🧠 大模型:没有笔记本的演讲者
想象一位演讲者站在台上:
- 第一次上台说:"我是田晨枫。"
- 下台后,没人给他发讲稿。
- 第二次上台,他只能凭空回忆:"刚才我说啥了?"
大模型就是这样------每次调用都是全新开始,除非你主动把"讲稿"(历史)塞给它。
二、手动维护历史:你自己当秘书
jsx
let chatHistory = [];
chatHistory.push(new HumanMessage('我叫田晨枫...'));
const aiReply = await model.invoke(chatHistory);
chatHistory.push(aiReply);
// 下次再调用时带上整个 chatHistory📝 你亲自当秘书
- 你拿个小本本(
chatHistory数组) - 每次用户说话,你记下来
- 每次 AI 回答,你也记下来
- 下次提问前,把整本笔记递给 AI
✅ 能工作,但:
- 多用户?你得准备多个本子,并贴上标签(user_a, user_b...)
- 聊100轮?本子越来越厚,AI 看得眼花(Token 爆炸)
太累了!我们需要一个自动化的秘书。
三、LangChain 登场:给 AI 配一个智能秘书
LangChain 的 RunnableWithMessageHistory 就是这位秘书。我们来配置它:
步骤 1:设计"对话模板"------规定怎么读笔记
js
import { ChatDeepSeek } from '@langchain/deepseek';
import{ChatPromptTemplate} from '@langchain/core/prompts';
// 带上历史记录的可运行对象
import { RunnableWithMessageHistory } from '@langchain/core/runnables';
// 内存中的对话历史记录
import { InMemoryChatMessageHistory } from '@langchain/core/chat_history';
import'dotenv/config';
const prompt = ChatPromptTemplate.fromMessages([
['system', '你是一个有记忆的助手'],
['placeholder', '{history}'], // ← 秘书在这里插入笔记内容
['human', '{input}']
]);📖 会议议程模板
就像一场会议的固定流程:
- 主持人开场(system)
- 回顾上次会议纪要({history})
- 讨论新议题({input})
{history} 就是预留的"纪要插入位"。
步骤 2:组装基础工作流
js
const runnable =prompt
.pipe((input) =>{ //debug 节点
console.log(">>> 最终传给模型的信息(Prompt 内存)");
console.log(input);
return input;
})
.pipe(model);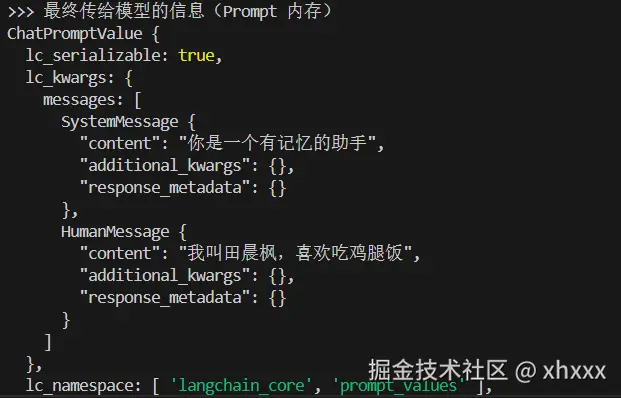 这里我们手动添加了一个用于debug的节点,实际上它只是用来查看我们最终传给大模型的是什么。
这里我们手动添加了一个用于debug的节点,实际上它只是用来查看我们最终传给大模型的是什么。
它等价于下面这段代码
js
const runnable = prompt.pipe(model);⚙️ 核心工作台
这是 AI 的"办公桌":
- 左边放议程模板(prompt)
- 右边连着大脑(model)
但还没配秘书,所以不会自动填纪要。
步骤 3:准备"笔记本"------历史存储
js
const messageHistory = new InMemoryChatMessageHistory();📓 一个空白笔记本
这是秘书用来记对话的本子。
目前是"通用本子"------所有用户共用(后面我们会升级为每人一本)。
步骤 4:雇佣"智能秘书"------RunnableWithMessageHistory
js
const chain = new RunnableWithMessageHistory({
runnable, // ← 把办公桌交给秘书
getMessageHistory: async () => messageHistory, // ← 告诉秘书去哪拿笔记本
inputMessagesKey: 'input', // ← 用户当前说的话叫 "input"
historyMessagesKey: 'history' // ← 笔记内容注入到模板的 "history" 位置
});👨💼 正式聘用秘书
你对秘书说:
- "这是你的工作台(runnable)"
- "笔记本在这儿(messageHistory)"
- "用户当前问题叫
input,上次的笔记叫history,按模板填好就行"
这里就是对runable进行了重新包装:
- getMessageHistory告诉它应该调用哪个历史对话(每段对话会有对话id,我们这里使用了同一个历史对话)
- inputMessagesKey用来记录当前用户说的话
- historyMessagesKey 将历史对话插入到对应位置 对于我们设定的模板你就理解了:
js
const prompt = ChatPromptTemplate.fromMessages([
['system', '你是一个有记忆的助手'],
['placeholder', '{history}'], // ← 插入的历史对话
['human', '{input}']//<- 用户输入
]);而当我们反复提问时就会变成这样
js
[
SystemMessage("你是一个有记忆的助手"),
//对应的历史对话插入
HumanMessage("我叫田晨枫,喜欢吃鸡腿饭"),
AIMessage("好的,田晨枫!..."),
//用户的提问
HumanMessage("我叫什么名字")
]从此,你只需说"问 AI 一个问题" ,秘书会自动:
- 打开笔记本,读取历史
- 按模板整理成完整议程
- 交给 AI 处理
- 把新对话记回笔记本
步骤 5:使用------你只需提问题!
js
await chain.invoke({ input: '我叫田晨枫...' });
await chain.invoke({ input: '我叫什么名字?' }); // ✅ 正确回答!
💬老板只管下指令**
你作为老板,只需说:"帮我问 AI 我叫什么?"
秘书默默完成所有幕后工作,你甚至不用知道笔记本的存在。
四、升级:给每位用户配专属笔记本(多会话支持)
之前的笔记本是公用的。现在,我们让秘书管理多个带标签的笔记本:
js
const sessionStore = new Map(); // ← 一个文件柜,每个抽屉贴了标签
const getMessageHistory = async (sessionId) => {
if (!sessionStore.has(sessionId)) {
// 如果没这个用户的笔记本,就新建一本
sessionStore.set(sessionId, new InMemoryChatMessageHistory());
}
return sessionStore.get(sessionId); // ← 返回对应笔记本
};
// 调用时指定用户 ID
await chain.invoke(
{ input: '我叫张三' },
{ configurable: { sessionId: 'user_zhang' } } // ← "请用张三的笔记本!"
);🗂️ 带标签的文件柜
- 文件柜(
sessionStore)里有很多抽屉- 每个抽屉贴着用户 ID 标签(
sessionId)- 秘书根据你提供的标签,取出对应的笔记本
- 张三和李四的对话完全隔离,互不干扰
五、防止笔记本太厚:自动清理旧记录
聊得越多,笔记本越厚。长期下去:
- AI 阅读困难(上下文太长)
- 成本飙升(Token 按字数计费)
解决方案:让秘书定期清理旧页
js
const MAX_MESSAGES = 6; // 只保留最近 3 轮对话(6 条消息)
const getMessageHistory = async (sessionId) => {
let history = sessionStore.get(sessionId) || new InMemoryChatMessageHistory();
const messages = await history.getMessages();
if (messages.length > MAX_MESSAGES) {
// 清空笔记本,只抄写最后几页
await history.clear();
for (const msg of messages.slice(-MAX_MESSAGES)) {
await history.addMessage(msg);
}
}
sessionStore.set(sessionId, history);
return history;
};✂️ 秘书的"精简笔记"习惯
秘书有个规矩:
- 笔记本超过 6 页,就撕掉前面的
- 只保留最近 3 轮对话(足够理解上下文)
- 既节省空间,又不影响工作
六、总结:LangChain 的记忆系统全景图
| 组件 | 比喻 | 作用 |
|---|---|---|
ChatPromptTemplate |
会议议程模板 | 规定如何组织上下文 |
{history} 占位符 |
"上次会议纪要"位置 | 历史消息插入点 |
InMemoryChatMessageHistory |
笔记本 | 存储对话记录 |
getMessageHistory |
文件柜管理员 | 根据用户 ID 分发笔记本 |
RunnableWithMessageHistory |
智能秘书 | 自动读写笔记、组装请求 |
sessionId |
用户标签 | 区分不同用户的笔记本 |
大模型本身没有记忆,就像一位才华横溢却健忘的演讲者------每次登台都像初次见面。
而 LangChain 并没有改变模型的本质,而是在它身边搭建了一套完整的记忆支持系统:
- 用模板定义记忆格式(Prompt)
- 用存储承载记忆内容(MessageHistory)
- 用会话机制隔离记忆边界(sessionId)
- 用自动包装实现记忆流转(RunnableWithMessageHistory)
更重要的是,这套系统是可插拔、可扩展、可控制的 :
你可以轻松替换内存存储为 Redis,可以加入自动摘要压缩长对话,也可以设定最大轮数防止 Token 膨胀。
真正的"AI 记忆",从来不是模型自己记住什么,而是我们为它构建了一个恰到好处的记忆环境。
LangChain 提供的,正是这样一套让记忆变得简单、可靠又高效的工程化方案。