Abstract
传统的通道级剪枝方法 通过减少网络通道数来实现模型压缩,但在面对包含深度可分离卷积层 以及某些高效模块(如广泛使用的倒残差块 )的高效 CNN 模型时,往往难以取得理想的剪枝效果。已有的深度剪枝方法 通过减少网络层数来压缩模型,但由于部分高效模型中存在归一化层 ,这些方法并不适用于此类结构。此外,若在子网微调阶段直接移除激活函数,会破坏原有模型权重的分布,从而阻碍剪枝后模型达到较高的性能。
为了解决上述问题,本文提出了一种面向高效模型的全新深度剪枝方法 。该方法设计了一种新的块级剪枝策略 ,并为子网提出了渐进式训练方法 。此外,我们还将该剪枝方法扩展到视觉 Transformer 模型 中。实验结果表明,在多种剪枝配置下,所提出的方法始终优于现有的深度剪枝方法。基于该方法对 ConvNeXtV1 进行剪枝,我们获得了三种剪枝后的 ConvNeXtV1 模型,其在相近推理性能条件下超越了大多数现有的高效模型(SOTA)。同时,该方法在视觉 Transformer 模型上也取得了当前最优(state-of-the-art)的剪枝性能。
Introduction
深度神经网络(DNN)在多种任务上取得了显著进展,并在工业应用中取得了令人瞩目的成功。在这些应用场景中,模型优化 是一项普遍且关键的需求,其目标是在尽量减少精度损失的前提下提升模型的推理速度。围绕这一目标,研究者提出了多种技术手段,主要包括模型剪枝、模型量化以及高效模型设计。其中,高效模型设计既包括**神经架构搜索(NAS)**方法(Cai et al. 2020;Yu and Huang 2019;Yu et al. 2020;Wang et al. 2021a),也包括人工设计的网络结构。
在工业应用中,模型剪枝 已成为最常用的模型优化策略之一。作为一种核心加速手段,模型剪枝通过有选择地移除冗余权重,在保持模型精度的同时提升推理效率。该过程通常包含三个阶段:首先训练一个基线模型;随后剪除不重要的权重或通道;最后对剪枝后的模型进行微调以恢复性能。根据剪枝方式的不同,模型剪枝可分为非结构化剪枝 和结构化剪枝 两类。由于硬件限制,结构化剪枝更适合于工业部署场景。与非结构化剪枝在卷积核通道内以稀疏方式将不重要权重置零不同,结构化剪枝主要包括通道级剪枝 和块级剪枝 。通道级剪枝通过移除整个通道滤波器实现压缩,而块级剪枝则作用于更大的结构单元,通常以完整的网络块为剪枝对象。由于块级剪枝往往会减少网络的层数,因此也被称为深度剪枝(depth pruning)。
随着 CNN 模型结构的不断演进,越来越多的高效模型 被提出。例如,MobileNetV2(Sandler et al. 2018)大量采用深度可分离卷积层 并堆叠倒残差块,在显著减少参数量和 FLOPs 的同时保持了较高的性能。ConvNeXtV1(Liu et al. 2022)则利用大卷积核设计并结合堆叠式倒残差结构,实现了出色的计算效率。然而,传统的通道级剪枝方法在处理深度可分离卷积层时面临诸多挑战,主要原因在于其计算模式稀疏且参数量较少。此外,当前主流计算平台(如 GPU)更加偏好高度并行的计算方式,而通道级剪枝会使高效模型变得更加"瘦"和稀疏,导致硬件利用率降低,从而难以获得理想的实际加速效果。
为解决上述问题,DepthShrinker(Fu et al. 2022)和 Layer-Folding(Dror et al. 2021)等方法被提出,通过重参数化技术 (Ding et al. 2021a,b)减少 MobileNetV2 的网络深度。然而,这些方法仍然存在一定局限性:(1)在对子网进行微调时,若直接移除激活函数,可能会破坏基线模型权重的分布,从而限制剪枝后模型性能的提升;(2)这些方法在使用上存在结构限制,无法对包含 LayerNorm (Ba et al. 2016)或 GroupNorm(Wu and He 2018)等非 BatchNorm 归一化层的模型进行剪枝,因为重参数化技术无法将这些归一化层合并到相邻的卷积层或全连接层中;(3)由于视觉 Transformer 模型中普遍存在 LayerNorm 层,上述方法也无法直接应用于 Transformer 模型的优化。
针对这些问题,本文提出了一种渐进式训练策略 和一种新的块级剪枝方法,构成了一种能够同时适用于 CNN 和视觉 Transformer 模型的深度剪枝框架。所提出的渐进式训练策略可以在高效继承基线模型权重的同时,将模型结构平滑地过渡到子网结构,从而获得更高的剪枝后精度。与此同时,本文提出的块级剪枝方法能够有效处理归一化层带来的限制,理论上可以兼容所有激活函数与归一化层。因此,我们的方法能够对视觉 Transformer 模型进行剪枝,这是现有深度剪枝方法难以实现的。我们在 ResNet34、MobileNetV2 和 ConvNeXtV1 上进行了广泛实验,验证了所提出方法的优越剪枝能力。如图 1 所示,在相近推理性能条件下,基于本文方法剪枝得到的 ConvNeXtV1 模型超过了大多数现有的 SOTA 高效模型。进一步地,我们将该方法扩展到视觉 Transformer 模型,并在与其他 Transformer 剪枝方法的比较中取得了领先的性能。
本文的主要贡献总结如下:
(1)提出了一种统一且高效的深度剪枝方法 ,可同时用于 CNN 和视觉 Transformer 模型的优化;
(2)提出了一种用于子网优化的渐进式训练策略 ,并结合基于重参数化技术的新型块级剪枝策略 ;
(3)在多种 CNN 与视觉 Transformer 模型上进行了系统而全面的实验,验证了所提出深度剪枝方法的卓越性能。
Related Work
网络剪枝。剪枝算法大致分为非结构化与结构化两类。非结构化剪枝(Han, Mao, and Dally 2015; Elsen et al. 2020; Pool and Yu 2021)依据准则将权重中的冗余元素置零,但通常需要专用软硬件加速器,通用性较弱。结构化剪枝则移除完整参数结构,如整行/整列权重或卷积层中的整组滤波器。
在 VGG 与 ResNet 流行时期,Pruning Filters(Li et al. 2016)用 L1 范数选择不重要通道并剪除;Network FPGM(He et al. 2019)用卷积滤波器的几何中值寻找冗余滤波器。后续,多种高效网络(MobileNet 及其变体:Howard et al. 2017, 2019; Tan et al. 2019; Radosavovic et al. 2020)引入深度可分离卷积(Chollet 2017)以加速并提升精度,实现跨硬件的实时部署。MatePruning(Liu et al. 2019)提出 PruningNet,为剪枝模型自动生成权重以避免重训。然而,深度可分离卷积虽计算和参数少,但内存占用更高,对 GPU、DSP 等算力密集型硬件构成挑战(Tan and Le 2021);通道剪枝并不能直观高效地缓解这一问题。
与本文最相关的是按层/按块的深度剪枝,它能直接移除层或块以降低网络深度,从而有效降低内存使用。Shallowing deep networks(Chen and Zhao 2018)与 LayerPrune(Elkerdawy et al. 2020)提出评估卷积层重要性的策略;ESNB(Zhou, Yen, and Yi 2021)与 ResConv(Xu et al. 2020)分别通过进化搜索与可微参数确定要剪的层。Layer-Folding(Dror et al. 2021)与 DepthShrinker(Fu et al. 2022)移除块内非线性激活,并借助结构重参数化把多层合并为一层。上述方法仅在少量模型上验证,且硬删 ReLU 可能影响子网精度。
Transformer 家族在多种视觉任务上表现优异(Carion et al. 2020; Strudel et al. 2021; Brown et al. 2020),但高推理开销与较大内存占用限制了广泛应用(Pope et al. 2023)。为缓解内存问题,按层剪枝是有效方案。通过动态跳过部分层已成 Transformer 压缩主流(Zhang and He 2020; Dong, Cordonnier, and Loukas 2021; Michel, Levy, and Neubig 2019)。DynamicViT(Rao et al. 2021)动态筛选需传递到下一层的 token 数量;VTP(Zhu, Tang, and Han 2021)通过鼓励按维度稀疏性来剪除冗余维度。
结构重参数化。若块内没有非线性激活,结构重参数化可将多个卷积层整合为单个卷积层(Bhardwaj et al. 2022),在推理时有效降低内存需求并加速处理。RepVGG(Ding et al. 2021b)区分训练与测试结构,使平坦网络在测试时可超越 ResNet。DBB(Ding et al. 2021a)将多分支结构合并为单一卷积,显著快于常规多分支卷积。
神经架构搜索(NAS)。权重共享 NAS 因其训练一个超网、部署多个子网的灵活性与便利性,已成为主流。Once-for-All(Cai et al. 2020)采用渐进式训练的超网;BigNAS(Yu et al. 2020)使用一系列简单实用的训练方法提升超网训练效率。超网训练完成后,可结合遗传搜索等传统搜索算法,为不同部署场景找到一组帕累托最优网络。
本文方法与上述工作的关系。我们提出统一的深度剪枝方法,兼容高效 CNN 与视觉 Transformer。方法包含渐进式训练策略、全新的块级剪枝方法与重参数化技术。不同于 DepthShrinker 与 Layer-Folding 在微调时直接删除激活层,我们的方法以渐进方式在被剪块中移除激活层,更好地利用并迁移原始权重。此外,我们能解决其在块内遇到的 LayerNorm 或 GroupNorm 的问题;它们无法对这类层完成剪枝。尽管我们与 VanillaNet(Chen et al. 2023)在训练流程上存在相似性,但 VanillaNet 的目标是从零设计完全无非线性的模型;而我们的目标是提出一个通用的剪枝框架,适用于 CNN 与视觉 Transformer。
Method

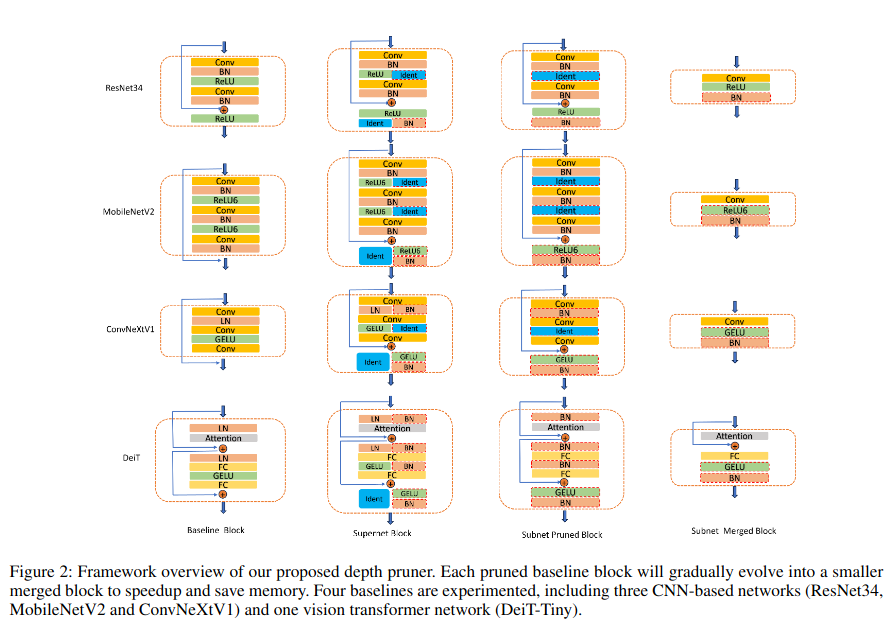

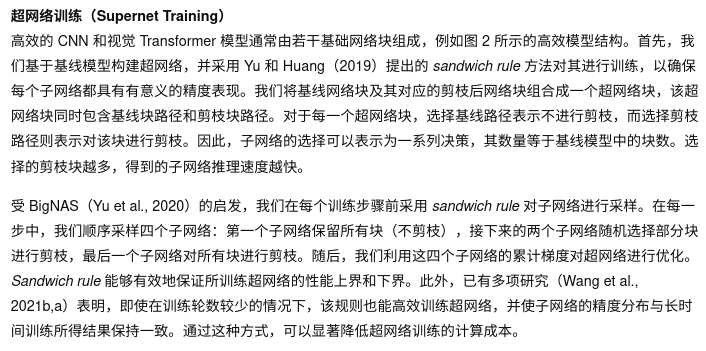






Experiments
在本节中,我们系统地验证了所提出深度剪枝方法的有效性。首先,我们介绍实验设置,并详细说明如何将该深度剪枝方法应用于 CNN 模型和视觉 Transformer。随后,我们将实验结果与当前最先进(state-of-the-art, SOTA)的剪枝方法进行对比,以突出我们方法的优势。最后,通过消融实验分析子网搜索策略和渐进式训练策略在整体方法中的作用。
Datasets
所有实验均在 ImageNet-1K 数据集(Russakovsky et al. 2015)上进行。ImageNet-1K 是图像分类领域广泛使用的基准数据集,包含 1000 个类别 ,共计 1,281,167 张训练图像、50,000 张验证图像和 100,000 张测试图像。
在训练过程中,我们采用常规的数据增强方法对输入图像进行预处理;在所有实验中,输入图像统一缩放至 224 × 224,并在验证集(validation set)上报告模型性能。
Experiments Setting on Different Models
我们将所提出的深度剪枝方法应用于多种 CNN 和视觉 Transformer 模型,以验证其通用性和有效性,具体包括:ResNet34 (He et al. 2016)、MobileNetV2、 ConvNeXtV1 (Liu et al. 2022)、Vision Transformer(DeiT) (Touvron et al. 2021)所有模型均使用 4 张 GPU 进行训练,总 batch size 为 256 。在训练流程中(除 MobileNetV2 外),我们首先使用 10 个 epoch 训练超网,并在此基础上搜索最优子网。随后,采用提出的渐进式训练策略对子网进行训练,并最终通过子网合并获得更高效的浅层模型。
ResNet34:在 ResNet34 的剪枝实验中,我们分别剪除 6 个 和 10 个 网络块,并完整执行超网训练、子网搜索、子网训练和子网合并流程,最终得到两个剪枝后的浅层子网。在子网训练阶段,公式(3)中的超参数 K 设置为 3 ,总训练 epoch 数为 150 。在第 100 个 epoch 时,我们将剪枝块中第一个卷积层的卷积核尺寸从 3 × 3 调整为 1 × 1 ,以进一步减少计算量。我们将该方法与 MetaPruning (Liu et al. 2019)以及基于通道剪枝的 NAS 方法 Universally Slimmable Networks(US)(Yu and Huang 2019)进行对比,以验证所提出方法的剪枝性能。
MobileNetV2:在 MobileNetV2 的剪枝实验中,我们采用 DepthShrinker 中使用的三种剪枝配置。由于这些配置已经明确,我们跳过超网训练和子网搜索阶段 ,直接得到三种相同的子网结构。随后,我们对这三个子网直接进行完整训练,并将最终性能与对应的 DepthShrinker 子网进行比较。此外,我们还采用 NAS 方法搜索了三种具有相近加速比的子网,以进一步验证所提出方法的性能优势。在子网训练阶段,超参数 K 设置为 3 ,总训练 epoch 数为 450。
ConvNeXtV1:在 ConvNeXtV1 的剪枝实验中,我们设置了 三种剪枝配置 ,使剪枝后的子网在 ImageNet-1K 上的 Top-1 准确率均约为 81% 。随后,我们将这些剪枝后的子网与多种现有的 SOTA 高效模型 进行比较,这些模型既包括 CNN 架构,也包括视觉 Transformer 架构,以验证我们方法在剪枝性能上的优势。在子网训练阶段,超参数 K 设置为 4.5 ,总训练 epoch 数为 450 。为了获得更高的推理加速效果,我们将剪枝块中 depthwise 卷积的卷积核尺寸从 7 × 7 调整为 3 × 3。
DeiT:在 DeiT 的剪枝实验中,我们进行了一项 剪除 6 层 Transformer Block 的实验,并将结果与当前最先进的视觉 Transformer 剪枝方法进行对比。在子网训练阶段,超参数 K 设置为 6 ,总训练 epoch 数为 450。
Comparisons with SOTA Models
我们在 单张 AMD MI100 GPU 上,在可比的推理速度 条件下,将所提出的 深度剪枝器(depth pruner) 与当前最先进(SOTA)的剪枝方法进行了比较。按照 Graham et al. (2021) 的设置,我们在 batch size = 128 的条件下,测量压缩网络的平均推理加速比 。在本文中,我们重点比较在相近推理加速比 下,不同模型的分类精度表现。
ResNet34
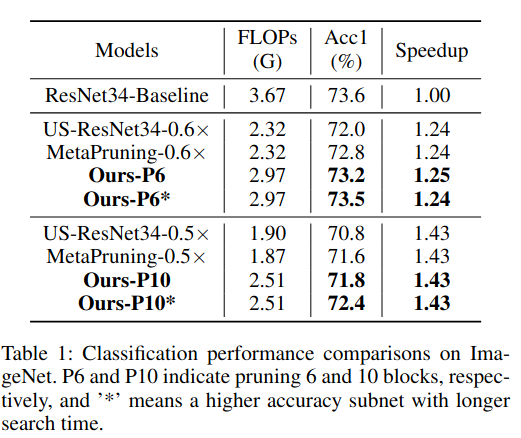
表 1 对比了我们的方法与 MetaPruning 以及 NAS-US 方法在 ResNet34 上的性能。通过应用所提出的深度剪枝器,我们分别剪除 6 个和 10 个残差块 ,得到两个子网络,其推理加速比分别为 1.25× 和 1.43× 。在 1.43× 加速比 这一可比条件下,我们的方法相比 MetaPruning 提高了 0.8% 的准确率,相比 NAS-US 方法提升了 1.6%,尽管 NAS-US 使用了更长的搜索时间。
MobileNetV2
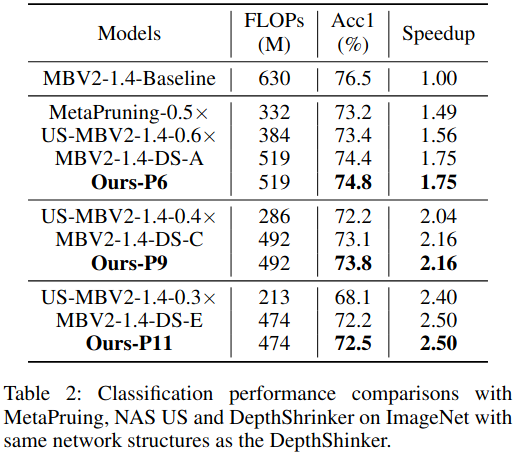
表 2 展示了在 MobileNetV2-1.4 上的实验结果。我们采用了与 DepthShrinker 相同的子网络结构,但子网络的训练过程不同 :DepthShrinker 采用的是常规训练策略,而我们使用的是渐进式训练策略(progressive training strategy) 。在 2.16× 推理加速比 下,我们的方法相比 MBV2-1.4-DS-C 获得了 0.7% 更高的准确率 ,并且在其他加速比设置下,相比 DepthShrinker 也取得了一定的性能提升。此外,我们还与 MetaPruning 方法进行了比较。与 ResNet34 的实验类似,我们复现了 MetaPruning-0.35× ,其推理速度与 MBV2-1.4-DS-C 相当;在此条件下,我们的深度剪枝方法在获得更高加速比 的同时,实现了 2.1% 的准确率提升。
ConvNeXtV1
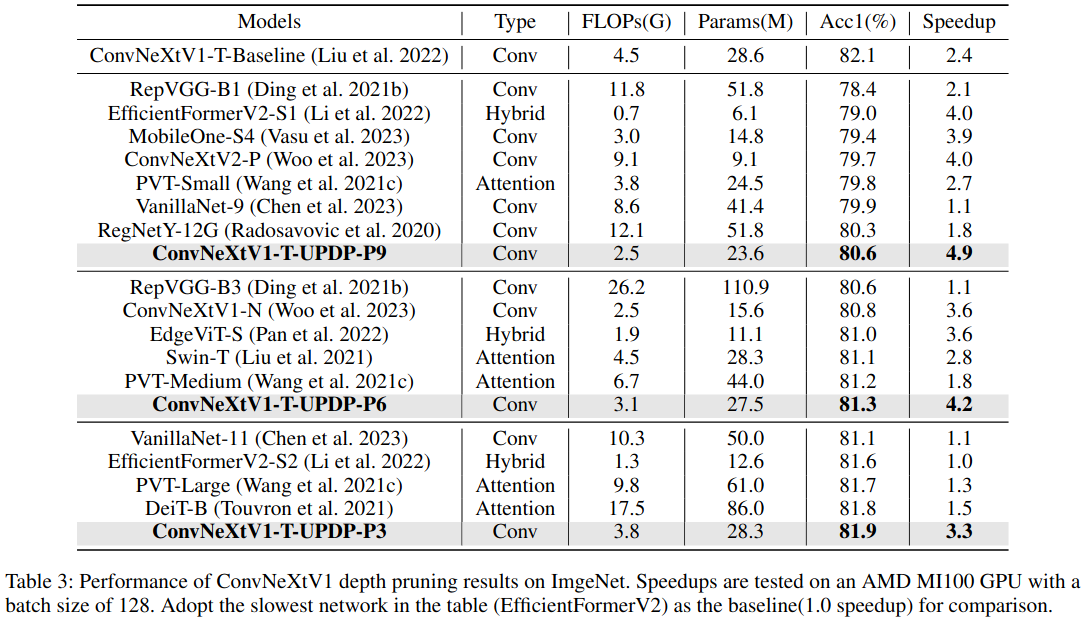
表 3 将我们的方法与若干常见的高效模型进行了对比,这是因为目前尚无针对 ConvNeXtV1 的专门压缩方法 。我们在 AMD 平台上测试了表中所有网络的推理加速比,并以其中最慢的模型 EfficientFormerV2-S2 作为速度基准。根据准确率水平,我们将模型划分为多个性能层级(levels),实验结果表明:在不同准确率层级下,我们的深度剪枝方法 均能在相近推理速度 下取得更高的准确率。
DeiT
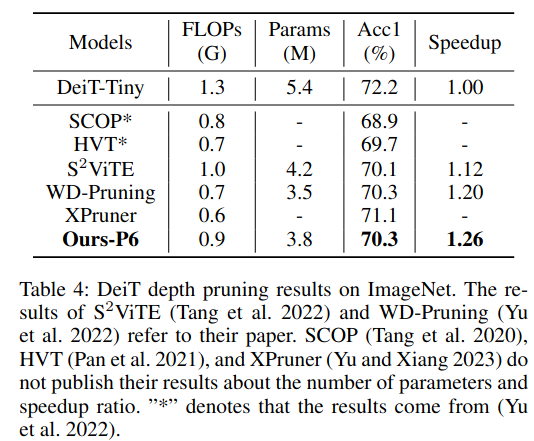
如表 4 所示,我们的方法在准确率和推理加速比 两个方面均优于其他最先进方法。所提出的深度剪枝器在实现 1.26× 推理加速 的同时,仅带来了 1.9% 的 Top-1 准确率下降 。此外,通过替换可合并模块(mergeable modules)并结合重参数化(reparameterization)技术 ,我们的方法能够有效地缩减网络结构 ,并带来真实的推理加速效果。
Ablation Study
在本节中,我们分析 子网搜索(subnet searching) 以及 渐进式训练策略(progressive training strategy) 的有效性。
Effectiveness of Subnet Searching:我们通过比较 基于 ResNet34 的两个剪枝 10 层子网 来验证子网搜索策略的有效性。这两个子网在 子网微调(subnet fine-tuning, FT)之前 具有不同的初始精度。
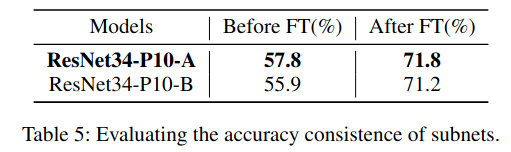
表 5 显示,在微调之前具有更高初始精度的 ResNet34-P10-A 子网,在微调后同样能够获得更高的最终精度 。这一结果表明,通过 超网训练(supernet training)与子网搜索(subnet searching),可以有效地筛选出具有更高潜力的最优子网,从而获得更高的最终性能。
Effectiveness of Progressive Training Strategy:与 直接移除非线性激活函数(hard removal of non-linear activation functions) 的训练方式相比,渐进式训练策略在各个子网络上均显著提升了模型精度。
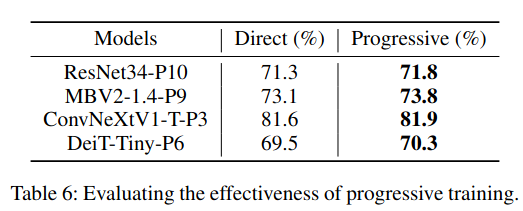
如表 6 所示,对于不同的子网络,渐进式训练相比直接训练方法可带来约 0.3%--0.8% 的精度提升,这验证了该训练策略在缓解性能退化方面的有效性。
Conclusion
本文提出了一种统一的深度剪枝器(depth pruner) ,可同时适用于高效 CNN 模型与视觉 Transformer 模型 ,以在深度维度 上对模型进行剪枝。该深度剪枝框架包含四个阶段:超网训练(supernet training) 、子网搜索(subnet searching) 、子网训练(subnet training)以及子网合并(subnet merging) 。我们提出了一种新的块级剪枝方法 和一种渐进式训练策略 ,以更充分地继承和利用基线模型的权重。在子网合并阶段,我们采用重参数化(reparameterization)技术 ,使子网结构更加浅层且推理速度更快。我们将所提出的方法应用于多种 CNN 模型和 Transformer 模型,实验结果表明,该方法在剪枝性能上达到了当前最优(SOTA)水平,充分验证了其有效性。未来,我们将进一步探索该方法在更多 Transformer 模型及下游任务中的应用。