目录
- 引言:为什么HTTP需要不断演进?
- 一、HTTP/1.0:基础但低效的开端
- [1.1 主要特性](#1.1 主要特性)
- [1.2 核心问题](#1.2 核心问题)
- [1.2.1 连接无法复用:昂贵的三次握手](#1.2.1 连接无法复用:昂贵的三次握手)
- [1.2.2 队头阻塞:线性请求队列](#1.2.2 队头阻塞:线性请求队列)
- [1.3 典型工作流程](#1.3 典型工作流程)
- 二、HTTP/1.1:持久连接与优化
- [2.1 重大改进](#2.1 重大改进)
- [2.1.1 持久连接 (Keep-Alive)](#2.1.1 持久连接 (Keep-Alive))
- [2.1.2 管道化 (Pipelining)](#2.1.2 管道化 (Pipelining))
- [2.1.3 分块传输编码 (Chunked Transfer Encoding)](#2.1.3 分块传输编码 (Chunked Transfer Encoding))
- [2.1.4 缓存控制 (Cache-Control)](#2.1.4 缓存控制 (Cache-Control))
- [2.1.5 主机头 (Host Header)](#2.1.5 主机头 (Host Header))
- [2.2 核心机制](#2.2 核心机制)
- [2.2.1 持久连接:Keep-Alive机制](#2.2.1 持久连接:Keep-Alive机制)
- [2.2.2 管道化:有限的并行](#2.2.2 管道化:有限的并行)
- [2.2.3 分块传输:流式传输支持](#2.2.3 分块传输:流式传输支持)
- [2.3 常见混淆问题澄清](#2.3 常见混淆问题澄清)
- [2.3.1 TCP长连接 vs HTTP长连接:它们是什么关系?](#2.3.1 TCP长连接 vs HTTP长连接:它们是什么关系?)
- [2.3.2 为什么HTTP/1.1必须按顺序返回响应?](#2.3.2 为什么HTTP/1.1必须按顺序返回响应?)
- [2.4 仍未解决的问题](#2.4 仍未解决的问题)
- [2.4.1 TCP队头阻塞依然存在](#2.4.1 TCP队头阻塞依然存在)
- [2.4.2 头部冗余严重](#2.4.2 头部冗余严重)
- [2.4.3 并发连接数限制](#2.4.3 并发连接数限制)
- [2.1 重大改进](#2.1 重大改进)
- 三、HTTP/2:性能的革命性提升
- [3.1 设计哲学转变](#3.1 设计哲学转变)
- [3.2 四大核心特性](#3.2 四大核心特性)
- [3.2.1 二进制分帧层:从文本到二进制](#3.2.1 二进制分帧层:从文本到二进制)
- [3.2.2 多路复用:真正的并行传输](#3.2.2 多路复用:真正的并行传输)
- [3.2.3 头部压缩:HPACK算法](#3.2.3 头部压缩:HPACK算法)
- [3.2.4 服务器推送:主动发送资源](#3.2.4 服务器推送:主动发送资源)
- [3.3 HTTP/2性能对比](#3.3 HTTP/2性能对比)
- [3.4 深入理解:多路复用如何消除Stalled时间](#3.4 深入理解:多路复用如何消除Stalled时间)
- [3.5 新引入的问题](#3.5 新引入的问题)
引言:为什么HTTP需要不断演进?

性能需求的爆炸式增长
想象一下,如果你现在打开一个网页需要等10秒才能看到内容,你一定会觉得无法忍受。但这就是早期互联网的常态。
时间线对比:
- 1989年(HTTP诞生):传输几KB的纯文本文档,几秒钟加载完成已经很不错了
- 2024年(现在):需要实时传输4K视频、大型游戏、AR/VR内容,用户期望毫秒级响应
性能需求的变化:
- 从"秒级响应可以接受" → "毫秒级延迟才能容忍"
- 从"加载一个简单页面" → "加载包含数百个资源的复杂应用"
核心矛盾
应用需求增长 vs 底层协议限制
就像城市交通一样:
- 城市越来越大,车辆越来越多(应用需求增长)
- 但道路还是那么宽,红绿灯还是那么慢(协议限制)
- 必须升级道路系统(协议演进)
这就是为什么HTTP从1.0 → 1.1 → 2.0 → 3.0不断演进的根本原因。
一、HTTP/1.0:基础但低效的开端
1.1 主要特性
简单文本协议:采用 ASCII 编码,像人类对话一样直观(例如:GET /index.html HTTP/1.0)。这种设计方便调试,但对于机器解析来说,必须逐字符处理,性能损耗较高。
无状态设计:服务器不会保存客户端的任何上下文信息。虽然这简化了服务器逻辑,但随着应用复杂化,开发者不得不引入 Cookie 来维持登录态或购物车等信息。
基础方法:
- GET:获取资源
- POST:提交数据
- HEAD:只获取响应头(用于检查资源更新或存在性)
状态码体系:
- 200 OK:请求成功
- 404 Not Found:资源不存在
- 500 Internal Server Error:服务器内部错误
1.2 核心问题
HTTP/1.0虽然简单易用,但存在两个致命的性能问题,导致它无法满足现代Web应用的需求。
1.2.1 连接无法复用:昂贵的三次握手
问题描述:每个HTTP请求都需要建立一个新的TCP连接,完成完整的三次握手后才能发送数据。
为什么这很糟糕?
想象你要给朋友打电话:
- HTTP/1.0:每次打电话都要重新拨号、等待接通、确认身份(三次握手)
- 打完一次电话就挂断
- 要打下一个电话,又要重新拨号...
这太浪费时间了!
每个请求都需要建立新的TCP连接,完成完整的三次握手:

Server Client Server Client 请求1:HTML文件 请求2:CSS文件(需新建连接) 请求3:JS文件(再新建连接) SYN SYN-ACK ACK + HTTP请求 HTTP响应 FIN SYN SYN-ACK ACK + HTTP请求 HTTP响应 SYN SYN-ACK ACK + HTTP请求 HTTP响应
性能代价:
- 每个连接:1-3个RTT(往返时间)的握手开销
- 典型网页:6-15个资源 = 18-45个RTT浪费
1.2.2 队头阻塞:线性请求队列
问题描述:请求必须按顺序发送和接收,前一个请求阻塞后续所有请求。
为什么叫"队头阻塞"?
就像在超市排队结账:
- 你排在第5位
- 但第1位的人动作很慢,在找零钱、装袋子...
- 即使第2、3、4位的人已经准备好了,也必须等第1位完成
- 这就是"队头阻塞"(Head-of-Line Blocking)
在HTTP/1.0中:
- 请求1(大JS文件,需要3秒)→ 必须等待
- 请求2(小CSS文件,只需0.1秒)→ 被阻塞,必须等请求1完成
- 请求3(小图片,只需0.1秒)→ 也被阻塞

现实影响:一个大JS文件会阻塞所有CSS、图片加载,导致页面渲染延迟。
1.3 典型工作流程
一个简单网页(HTML+CSS+JS+3张图片)的加载过程:
时间线:
0ms: 建立连接1 → 请求HTML → 接收HTML (200ms)
200ms: 解析HTML发现CSS
210ms: 建立连接2 → 请求CSS → 接收CSS (150ms)
360ms: 解析HTML发现JS
370ms: 建立连接3 → 请求JS → 接收JS (300ms)
670ms: 解析JS时发现图片1
680ms: 建立连接4 → 请求图片1 → 接收 (100ms)
780ms: 建立连接5 → 请求图片2 → 接收 (100ms)
880ms: 建立连接6 → 请求图片3 → 接收 (100ms)
总耗时:980ms(其中握手开销占60%)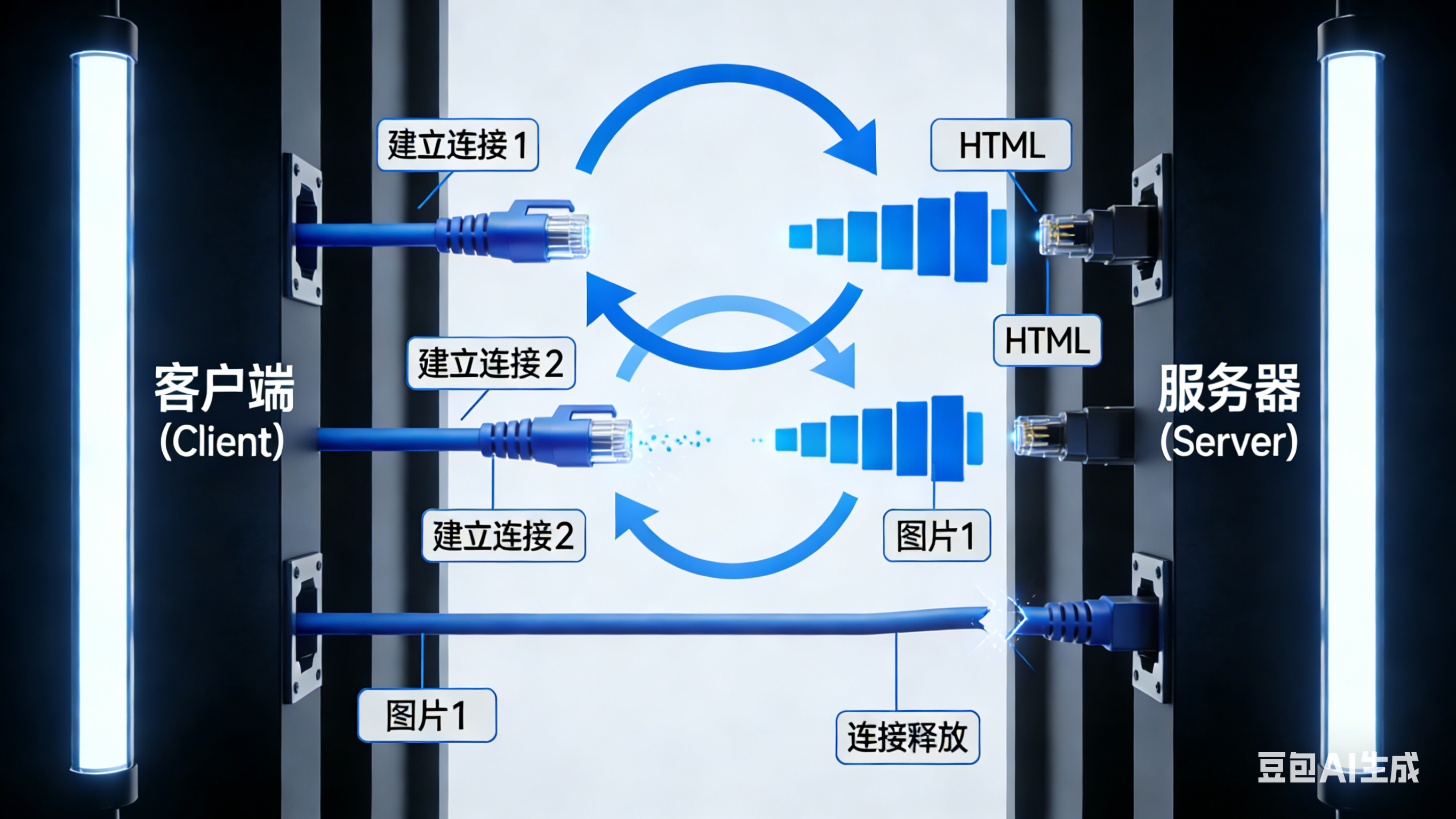
二、HTTP/1.1:持久连接与优化
2.1 重大改进
2.1.1 持久连接 (Keep-Alive)
这是 HTTP/1.1 最核心的性能提升。默认启用 Connection: keep-alive,使得客户端与服务器之间的 TCP 连接在完成一次请求后不会立即关闭。后续的图片、CSS、JS 等资源可以复用同一条通道,消除了频繁建立连接带来的三次握手开销(RTT 损耗)。
2.1.2 管道化 (Pipelining)
在持久连接的基础上,允许客户端在不等待前一个请求响应的情况下,连续发送多个请求。虽然响应仍需按顺序返回(存在响应侧的队头阻塞),但它减少了请求在链路上的往返等待时间。
2.1.3 分块传输编码 (Chunked Transfer Encoding)
引入了 Transfer-Encoding: chunked 机制,允许服务器将数据切分成若干个有编号的数据块进行传输。服务器不需要提前计算响应体的总长度(Content-Length),可以边生成内容边发送,极大提升了动态页面的首字节到达速度。
2.1.4 缓存控制 (Cache-Control)
引入了更精细、更强大的缓存策略,如 Cache-Control 字段(包含 max-age、no-cache 等指令),以及 ETag 和 If-None-Match 的强校验机制。比 HTTP/1.0 的 Expires(基于绝对时间)更准确,有效减少了重复资源的下载。
2.1.5 主机头 (Host Header)
请求头中强制包含 Host 字段。解决了多个域名共享同一个 IP 地址的问题,使得一台物理服务器可以托管多个虚拟主机(网站),这是现代互联网基础设施的基石。
性能表现对比
HTTP/1.0模式(每次请求都要重新建立连接):
握手 -> 请求 HTML -> 响应 -> **断开连接**
握手 -> 请求 CSS -> 响应 -> **断开连接**
握手 -> 请求 JS -> 响应 -> **断开连接**HTTP/1.1模式(复用同一个连接):
握手 -> 请求 HTML -> 响应 -> 请求 CSS -> 响应 -> 请求 JS -> 响应 ...(**最后才断开**)性能提升:
- 减少了N次握手开销(从N次到1次)
- 减少了连接建立和关闭的系统资源消耗
- 典型网页可节省12-30个RTT(往返时间)
2.2 核心机制
2.2.1 持久连接:Keep-Alive机制
单个TCP连接可传输多个HTTP请求/响应对:

优化效果:减少握手次数从N次到1次,典型网页可节省12-30个RTT。
2.2.2 管道化:有限的并行
理论上可连续发送多个请求,但实践中有限制:

工作原理:
- 客户端可以在不等待前一个请求响应的情况下,连续发送多个请求
- 例如:同时发送
GET /a.html、GET /b.jpg、GET /c.css三个请求
现实限制:
- 响应必须按请求顺序返回(这是HTTP/1.1协议规范的要求)
- 一个慢响应阻塞所有后续响应
- 大部分浏览器默认禁用管道化
为什么必须按顺序?(详见2.3节详细解释)
- HTTP/1.1基于文本行,没有请求ID标记
- 服务器无法告诉客户端"这个响应对应哪个请求"
- 只能通过顺序一一对应来识别
2.2.3 分块传输:流式传输支持
服务器可在不知道内容总大小的情况下开始传输:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
5\r\n
Hello\r\n
6\r\n
World\r\n
0\r\n
\r\n
2.3 常见混淆问题澄清
在学习HTTP/1.1时,很多初学者会对一些概念产生混淆。本节将澄清最常见的两个问题。
2.3.1 TCP长连接 vs HTTP长连接:它们是什么关系?
核心答案:HTTP/1.1的长连接是应用层的行为,它依赖于传输层TCP长连接所提供的持久通道来实现。
简单比喻
想象两座房子(客户端和服务器)之间:
- TCP连接 :就像修好的一条持久电话线(传输层)
- HTTP/1.1长连接 :规定打完一次电话(完成一次HTTP请求/响应)后,先不挂断电话线,稍等片刻可能还有话要说(下一个HTTP请求)
两者对比表格
| 特性 | TCP长连接 | HTTP/1.1 长连接 |
|---|---|---|
| 所属层级 | 传输层(第4层) | 应用层(第7层) |
| 核心目的 | 提供可靠的、有序的字节流传输通道,避免频繁建立连接的开销(三次握手、慢启动) | 在单个TCP连接上串行或并行地传输多个HTTP请求和响应,减少延迟和服务器资源消耗 |
| 管理方式 | 由操作系统内核通过套接字管理。通过保活机制探测连接是否存活 | 由Web服务器(如Nginx)和客户端(如浏览器)通过HTTP头(Connection, Keep-Alive)和超时设置管理 |
| 生命周期 | 可以远长于任何一个HTTP会话。只要不关闭,可以一直存在,理论上可以传输任何应用层协议的数据 | 通常是多个HTTP事务的持续时间。服务器或客户端可以主动关闭,或因为超时、达到最大请求数而关闭 |
| 关键问题 | "管道"是否通畅、有无丢包、需不需要重传 | 如何在管道上组织多个请求和响应,避免"队头阻塞" |
工作流程示例
- 浏览器(客户端)向
www.example.com发起请求 - 传输层 :客户端操作系统与服务器80端口建立一个 TCP长连接(三次握手)
- 应用层 :通过这个TCP连接,浏览器发送第一个HTTP请求(
GET /page1.html) - 服务器返回
page1.html的响应,并在HTTP头中暗示或明示Connection: keep-alive - 关键点 :此时,TCP连接没有断开
- 浏览器解析HTML,发现需要加载10个图片资源
- 在 同一个TCP长连接 上,浏览器串行地发送10个新的HTTP请求
- 服务器通过同一个TCP连接,串行地返回10个HTTP响应
- 所有资源加载完毕后,连接可能因为空闲超时而被任何一方关闭(触发TCP四次挥手)
重要辨析
-
没有TCP长连接,就没有HTTP长连接:如果TCP连接在每次HTTP请求后都关闭,那么HTTP/1.1的长连接机制就无法实现
-
但有TCP长连接,不一定就有HTTP长连接:
- 即使TCP连接保持打开,应用层协议也可以选择关闭它
- 例如,HTTP/1.0 默认
Connection: close,或者服务器明确发送Connection: close头,都会在本次HTTP事务结束后关闭底层的TCP连接 - 其他应用层协议(如FTP、SMTP)也可以复用TCP长连接,但与HTTP的"长连接"语义无关
-
HTTP/1.1的长连接瓶颈------队头阻塞 :由于HTTP/1.1规定响应必须按请求的顺序返回,如果第一个请求的响应很慢(比如一个大文件),它会阻塞后面所有已经发送的请求的响应。这是应用层协议设计导致的问题,与底层TCP的可靠性无关。TCP层只负责可靠地传输字节流,它不知道里面哪个字节属于哪个HTTP响应。
与HTTP/2、HTTP/3的演进
-
HTTP/2 :依然重度依赖TCP长连接 ,但在该连接上引入了"流"的概念,实现了多路复用,解决了HTTP层的队头阻塞 ,允许多个请求和响应并行交错传输。但TCP本身的队头阻塞(一个TCP包丢失会阻塞所有流)依然存在
-
HTTP/3 :为了彻底解决TCP队头阻塞,抛弃了TCP,基于UDP实现了新的传输协议QUIC。在HTTP/3的语境下,"长连接"是指在QUIC连接上保持多个HTTP事务。此时,应用层的长连接不再依赖于TCP长连接,而是依赖于QUIC连接
总结
HTTP/1.1的长连接是一种应用层策略,它利用并管理着底层已经建立的TCP长连接这个持久通道,以更高效地完成一系列HTTP通信。 理解这种分层协作的关系,对于诊断网络性能问题(是TCP传输慢还是HTTP队头阻塞?)和理解现代Web协议演进至关重要。
2.3.2 为什么HTTP/1.1必须按顺序返回响应?
这是很多人的疑问:为什么服务器不能先处理完哪个请求,就先返回哪个响应?为什么必须严格按顺序?
核心答案:这是HTTP/1.1协议的设计规范所规定的,并不是TCP层的强制要求。根本原因在于HTTP/1.1缺乏"请求ID"或"流ID"的概念,无法标记"这个响应对应哪个请求"。
1. 规定在哪里?
在 HTTP/1.1的RFC规范 中,虽然没有直接说"必须严格按顺序",但通过其请求-响应的简单交换模型隐含了这一要求。
- HTTP/1.1基于文本行 :请求和响应都是纯文本格式,以
\r\n分隔 - 没有明确的请求ID:协议没有提供任何机制来标记"这个响应属于哪个请求"
- 管道化(Pipelining)的明确要求 :HTTP/1.1确实定义了"管道化"的概念,允许客户端在不等待响应的情况下连续发送多个请求 。但规范要求服务器必须按照接收到的请求顺序返回响应
RFC 7230 Section 6.3.2(关于管道化)明确写道:
"A server MUST send its responses to those requests in the same order that the requests were received."
("服务器必须按照接收请求的相同顺序发送对这些请求的响应。")
2. 为什么这样设计?------技术根源
根本原因在于HTTP/1.1的协议设计缺乏"帧"和"流ID"的概念。
用一个比喻来解释:
想象两个人用对讲机通话:
-
HTTP/1.0:我说"Over,请回复",然后等你回复。你说完"Over"后,我再说下一句。(请求-响应-断开)
-
HTTP/1.1(非管道化):我说完第一句,不等你说"Over"就保持频道开放,但还是要等你回复第一句后,我才说第二句。(串行长连接)
-
HTTP/1.1(管道化):我连续说"第一件事是A,第二件事是B,第三件事是C",然后等你回复。你必须按顺序回答"关于A...关于B...关于C..."。如果B的事情比较复杂,你需要时间处理,但你也必须先说完A的答案,才能说B的答案。
关键问题:如果服务器先处理完B,它也不能先发送B的响应!因为客户端无法区分"这个响应是对应请求A还是请求B"。
3. 谁在强制这个顺序?
实际上,是客户端和服务器双方的实现共同遵守这个规范:
在客户端(如浏览器):
- 发送请求1 → 等待响应1 → 收到响应1 → 发送请求2
- 或者(管道化模式下):发送请求1、2、3 → 按顺序解析响应1、2、3
在服务器端:
- 按顺序接收请求1、2、3
- 按顺序生成响应1、2、3
- 即使请求2的处理先完成,也必须等响应1发送完毕,才能发送响应2
4. 管道化为什么失败了?
虽然规范允许管道化(同时发多个请求),但实际上浏览器默认禁用了它,原因包括:
- 中间设备问题:一些老旧的代理服务器不能正确处理管道化请求
- 队头阻塞无解:如果第一个响应很慢,后面的响应还是被卡住
- 错误处理复杂:如果请求序列中有一个出错,整个管道都可能需要重置
因此,现实中HTTP/1.1几乎都退化为串行长连接:发一个请求,等一个响应,再发下一个。
5. 与TCP的关系澄清
TCP层并不强制应用层消息的顺序对应关系!
- TCP只保证字节流的顺序和可靠传输 :你发送的字节
A1,A2,B1,B2,C1,C2,接收方一定会按这个顺序收到 - 但TCP不知道
A1,A2属于HTTP请求1,B1,B2属于请求2。这是应用层协议需要自己解决的消息边界问题 - HTTP/1.1用最简单的方式解决消息边界:按顺序一一对应
6. HTTP/2如何打破这个规定?
HTTP/2通过三个关键创新打破了顺序限制:
-
二进制分帧层:把HTTP消息分解为独立的"帧"
-
流ID:每个帧都带有流ID,标明它属于哪个请求/响应对
-
多路复用:不同流的帧可以交错发送
HTTP/2的数据流可能长这样(数字是流ID):
[帧头:流1][数据:流1][帧头:流2][数据:流2][帧头:流1][数据:流1][帧头:流3][数据:流3]...
服务器可以这样响应:
先发送:流2的响应(因为它先准备好)
再发送:流1的响应
最后发送:流3的响应客户端通过流ID能正确重组各个响应,完全不需要顺序对应。
总结
是HTTP/1.1协议规范本身,由于其基于文本行、缺乏消息标识的设计,规定了请求和响应的顺序必须对应。
这并非网络层的物理限制,而是一个应用层协议设计的选择。这个选择在当时(1999年)是简单实用的,但随着Web应用越来越复杂,它成为了严重的性能瓶颈。HTTP/2通过引入流ID和二进制帧,从根本上重新设计了消息交互模型,才解决了这个问题。
简单记忆:HTTP/1.1就像两个人打电话,你说"第一个问题...第二个问题...第三个问题...",我必须按顺序回答,因为电话线里没有"标签"来区分哪个答案对应哪个问题。HTTP/2给每个问题贴了标签(流ID),我就可以按任何顺序回答了。
2.4 仍未解决的问题
虽然HTTP/1.1相比HTTP/1.0有了显著改进,但仍然存在三个关键问题,这些问题最终推动了HTTP/2的诞生。
2.4.1 TCP队头阻塞依然存在
问题描述:虽然HTTP/1.1解决了应用层的队头阻塞(通过多个连接),但TCP协议本身的队头阻塞问题依然存在。
工作原理:
- TCP保证数据包的顺序和可靠性
- 如果网络传输中丢失了一个数据包,TCP必须等待这个包重传成功
- 在等待期间,整个连接暂停,所有请求都被阻塞
影响:
- 数据包丢失 → 整个连接暂停等待重传
- 影响该连接上的所有并行请求
- 在网络质量差的移动环境下,这个问题尤其严重

2.4.2 头部冗余严重
问题描述:每个HTTP请求都必须携带完整的头部信息,即使这些信息在同一个连接上的多个请求中是完全重复的。
示例:
请求1的头部(500字节):
GET /image1.jpg HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)...
Accept: image/webp,image/apng,*/*
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: session=abc123; theme=dark; cart=item1,item2
请求2的头部(又是500字节,几乎完全相同):
GET /image2.jpg HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)... ← 重复!
Accept: image/webp,image/apng,*/* ← 重复!
Accept-Encoding: gzip, deflate, br ← 重复!
Accept-Language: zh-CN,zh;q=0.9 ← 重复!
Cookie: session=abc123; theme=dark; cart=item1,item2 ← 重复!影响:
- 一个典型网页可能有50-100个资源请求
- 每个请求的头部平均500字节
- 总头部开销:25-50KB(在移动网络下这是巨大的浪费)
- 特别是Cookie字段,可能包含大量会话信息,每个请求都要重复发送
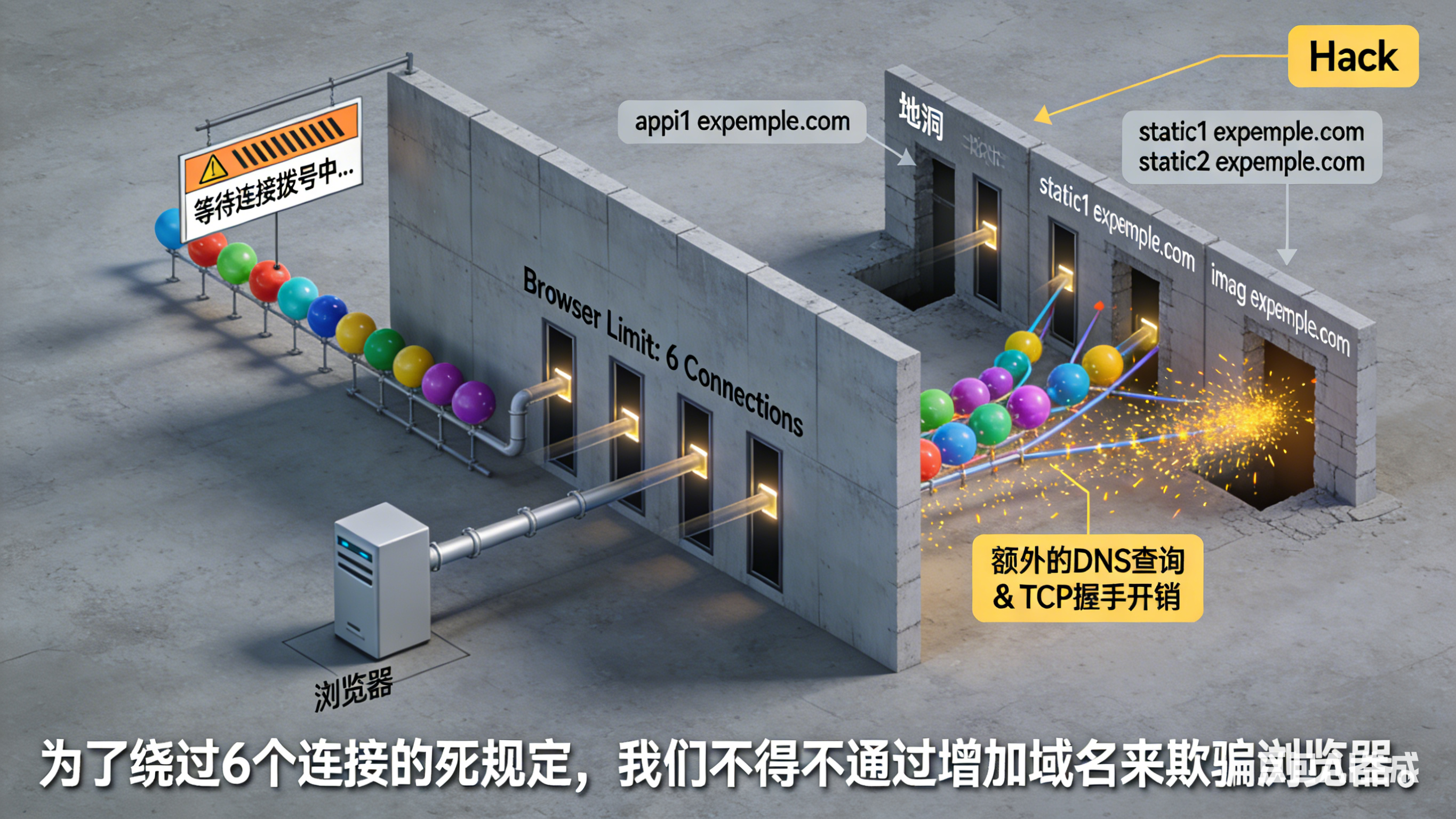
2.4.3 并发连接数限制
问题描述:浏览器为了性能优化,会为同一域名建立多个TCP连接来并行下载资源,但连接数有上限。
浏览器限制:
- 同一域名最多6-8个并发TCP连接
- 这是浏览器厂商的经验值,平衡了性能和服务器负载
导致的问题:
- 现代网页通常需要加载50-200个资源
- 但只能同时使用6-8个连接
- 大量请求必须排队等待空闲连接
- 这就是浏览器开发者工具中"Stalled"时间的主要来源
Hack方案:域名分片(Domain Sharding)
为了绕过连接数限制,开发者想出了一个"歪招":
- 将资源分散到多个子域名:
static1.example.com、static2.example.com、static3.example.com - 每个子域名可以有6-8个连接
- 3个子域名 = 18-24个并发连接
问题:
- 增加了DNS查询次数
- 增加了连接建立开销
- 破坏了HTTP/2的优化(HTTP/2只需要1个连接)
- 这是一个"治标不治本"的方案
总结:这三个问题相互关联,共同限制了HTTP/1.1的性能,推动了HTTP/2的诞生。
三、HTTP/2:性能的革命性提升
3.1 设计哲学转变
HTTP/2相比HTTP/1.1,在底层设计上发生了三个根本性的转变:
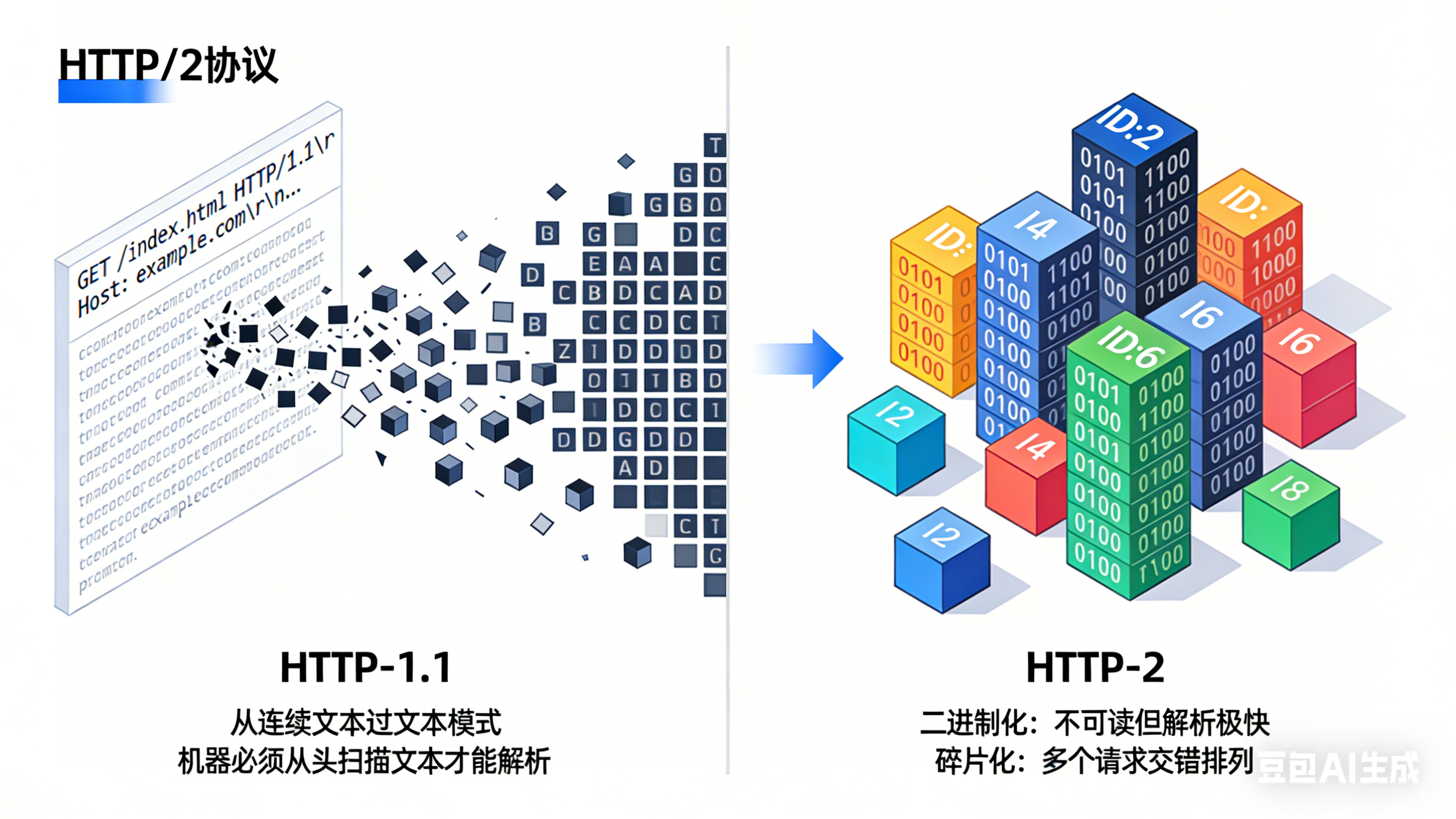
1. 从文本到二进制:
- HTTP/1.x:像人类对话一样,使用ASCII文本(例如:
GET /index.html HTTP/1.1)- 优点:人类可读,方便调试
- 缺点:机器解析慢,必须逐字符处理
- HTTP/2:使用二进制格式
- 优点:机器解析速度快10倍以上
- 缺点:人类无法直接阅读(但这不是问题,因为我们有工具)
2. 从连接为中心到流为中心:
- HTTP/1.1:以"连接"为单位,一个连接一次处理一个请求
- HTTP/2:以"流"为单位,一个连接内可以同时处理成百上千个流(请求/响应对)
3. 从被动响应到主动推送:
- HTTP/1.x:服务器只能被动等待客户端请求
- HTTP/2:服务器可以主动推送客户端可能需要的资源(如CSS、JS文件)
3.2 四大核心特性
3.2.1 二进制分帧层:从文本到二进制
从文本到二进制
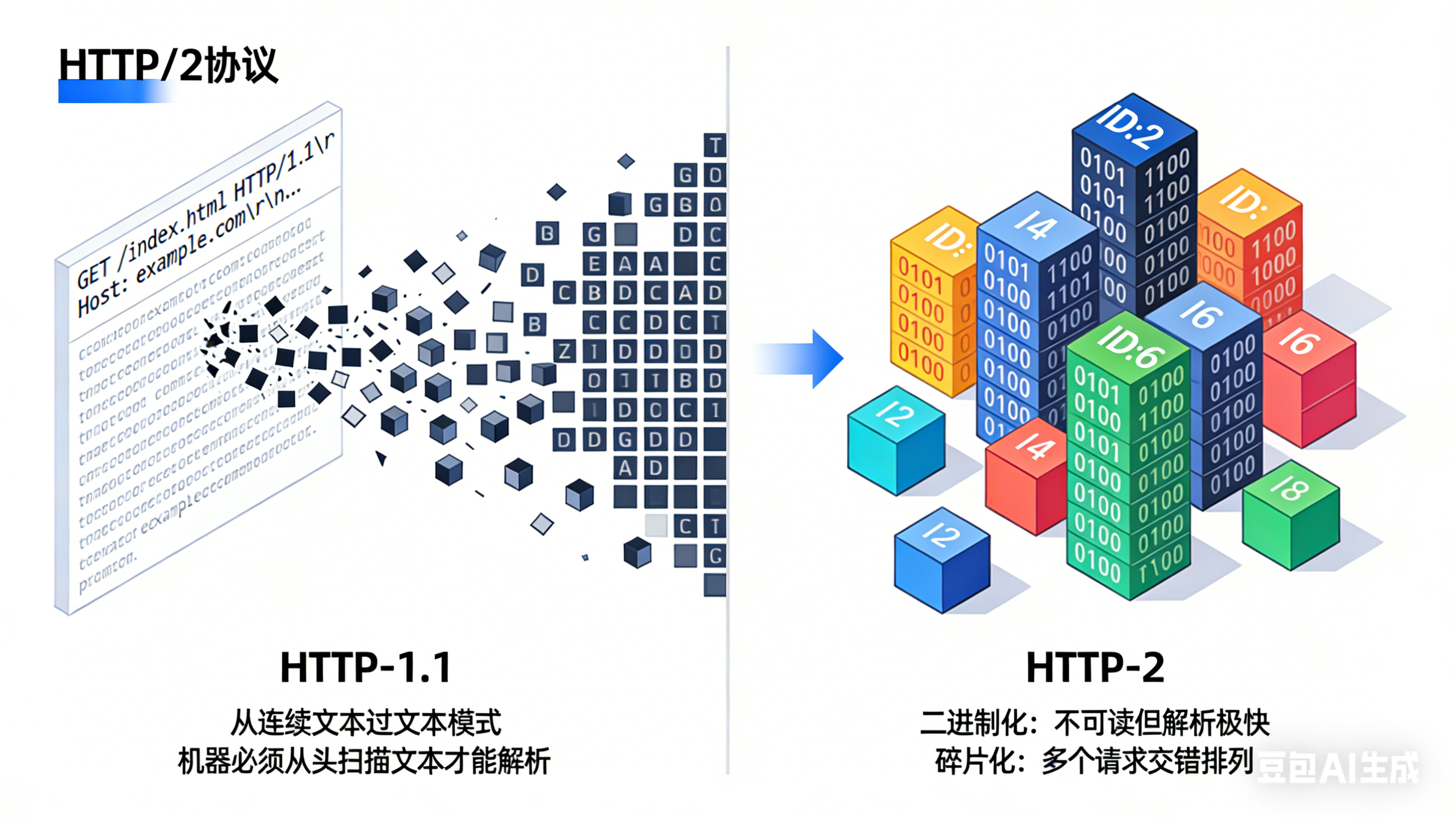
帧结构:
+-----------------------------------------------+
| 长度 (24位) | 类型 (8位) | 标志 (8位) | R (1位) |
+-----------------------------------------------+
| 流标识符 (31位) |
+-----------------------------------------------+
| 帧载荷 |
+-----------------------------------------------+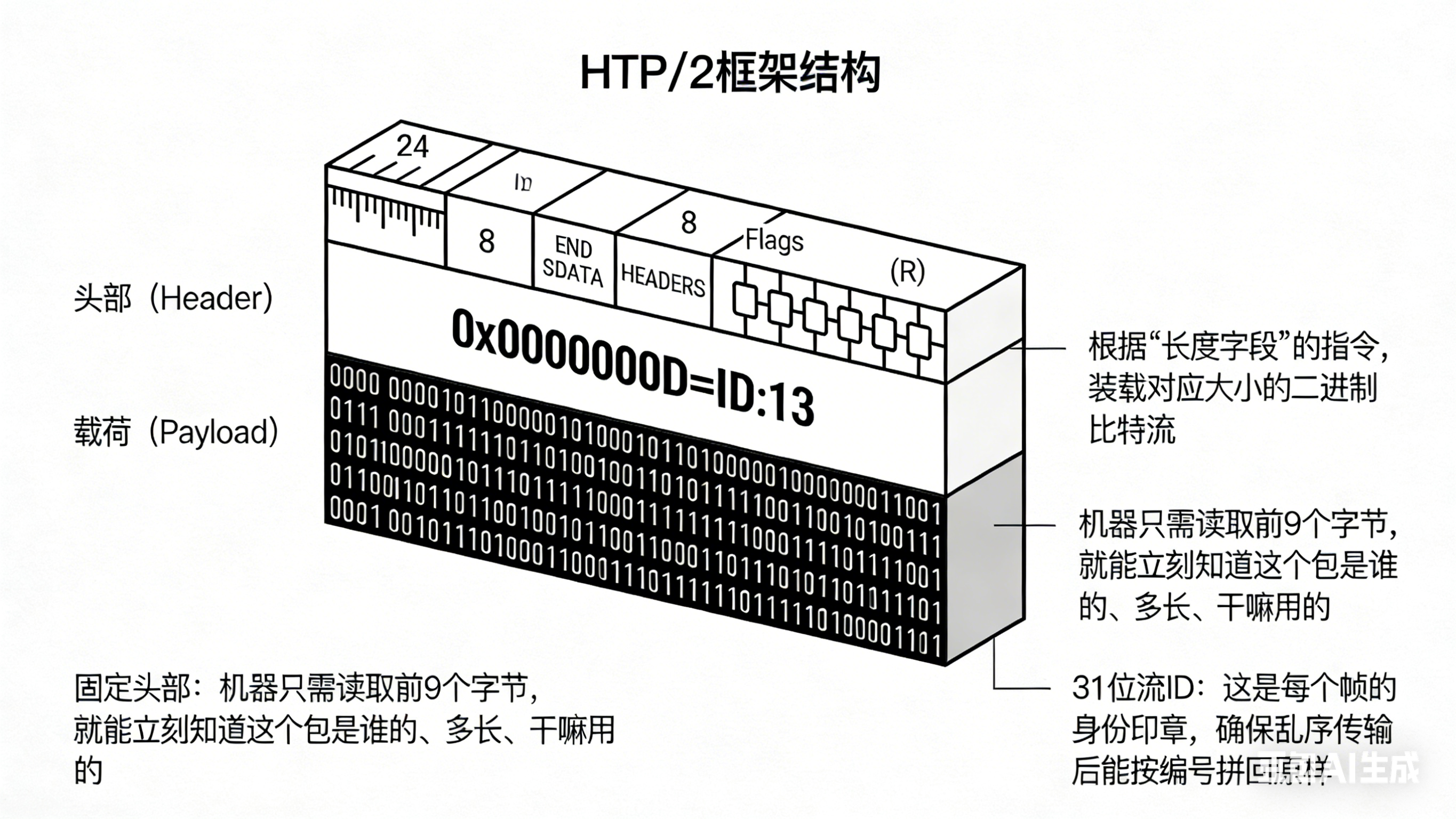
帧类型:
- HEADERS:头部帧
- DATA:数据帧
- PRIORITY:优先级帧
- RST_STREAM:流终止帧
- PUSH_PROMISE:服务器推送帧

3.2.2 多路复用:真正的并行传输
什么是多路复用?
简单理解:就像一条高速公路,HTTP/1.1时代需要开6条车道(6个连接)才能并行运输,而HTTP/2只需要1条超宽车道,但所有车辆(请求)都贴了标签(流ID),可以混合行驶,到达目的地后按标签分拣。
工作原理:
-
单个TCP连接承载多个双向流
- 一个TCP连接不再只服务一个请求,而是可以同时服务成百上千个请求/响应对(流)
- 每个流是独立的,有自己的流ID
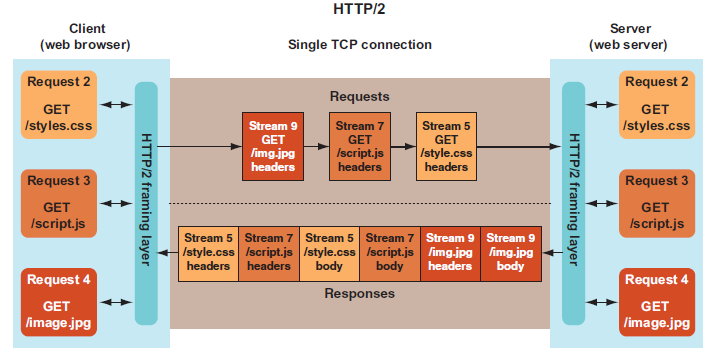
-
每个流有唯一标识符(流ID)
- 这是HTTP/2解决"顺序问题"的关键
- 客户端发送请求时分配流ID(如:流1、流2、流3)
- 服务器返回响应时,帧头中携带对应的流ID
- 客户端根据流ID重组响应,完全不需要顺序对应

-
帧可交错发送,接收方按流ID重组
- 不同流的帧可以混合在一起传输
- 例如:
[流1的帧][流3的帧][流1的帧][流2的帧]... - 接收方根据帧头中的流ID,将属于同一流的帧重组为完整的响应

实际效果:
- 请求几乎立即发出(零Stalled时间)
- 响应可以乱序返回(哪个先准备好就先返回哪个)
- 一个慢请求不会阻塞其他请求
- 一个TCP连接就能处理所有资源请求
3.2.3 头部压缩:HPACK算法
压缩原理:
- 静态表:61个常用头部字段
- "大家公认的常识"。不用说,报个号就行
- 动态表:连接期间维护的自定义字段
- "刚刚说过的话"。记住它,下次别再重复。
- 霍夫曼编码:进一步压缩
- "必须说的生僻词"。缩写它,越短越好。
压缩效果对比:
HTTP/1.1头部(约500字节):
GET /api/data HTTP/1.1
Host: api.example.com
User-Agent: Mozilla/5.0...
Accept: application/json
Authorization: Bearer eyJhbGciOiJ...
Cookie: session=abc123
HTTP/2编码后(约50字节):
[静态表索引] + [霍夫曼编码值]
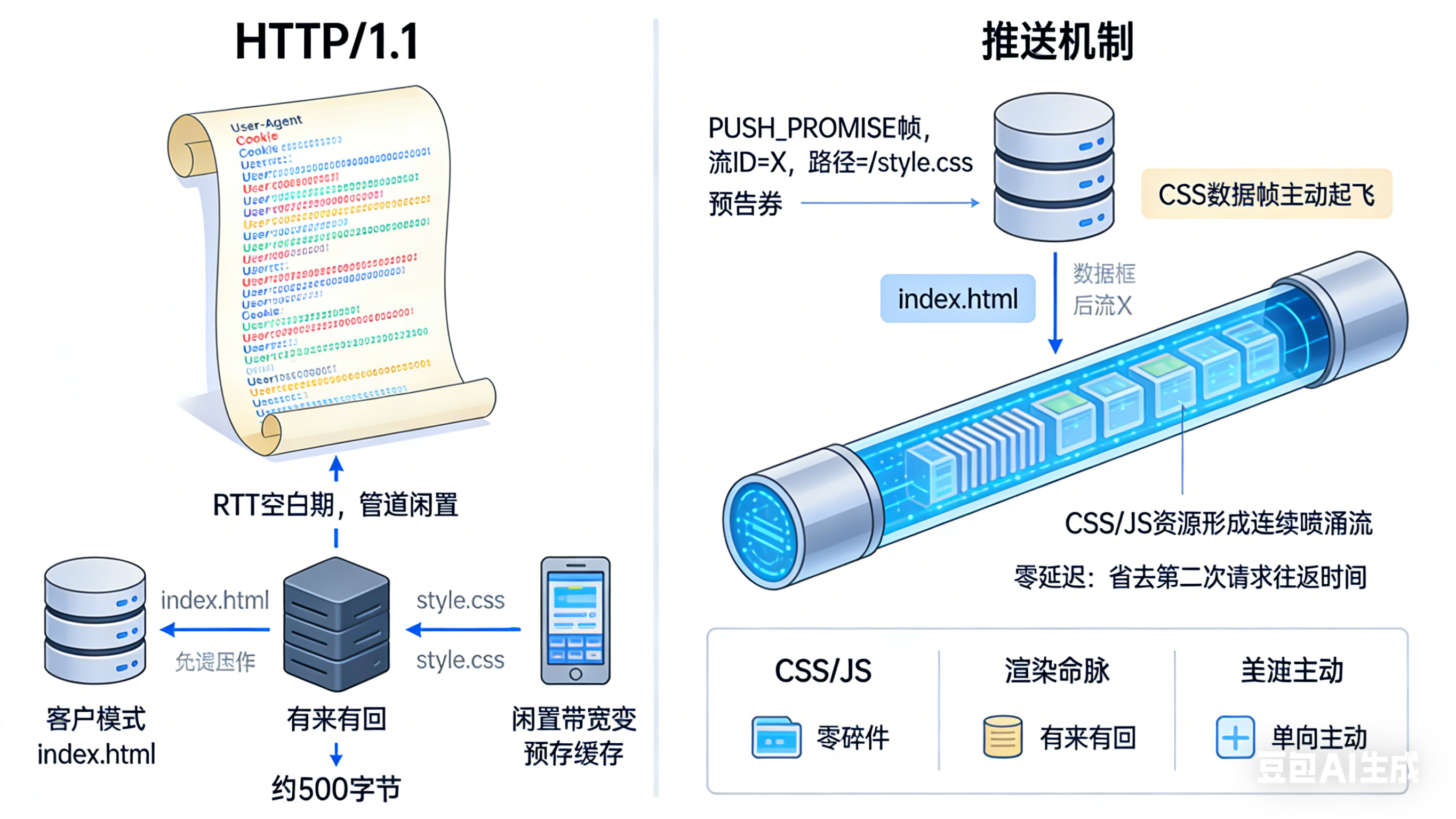
3.2.4 服务器推送:主动发送资源
推送机制:
http2
客户端请求: GET /index.html
服务器响应:
HEADERS: 200 OK
PUSH_PROMISE: 流ID=X, 路径=/style.css
DATA: index.html内容
然后自动发送:
HEADERS(流X): 200 OK
DATA(流X): style.css内容优化场景:
- CSS文件:页面渲染必需
- 关键JS:应用启动依赖
- 小图标:减少后续请求
3.3 HTTP/1.1 vs HTTP/2 性能对比
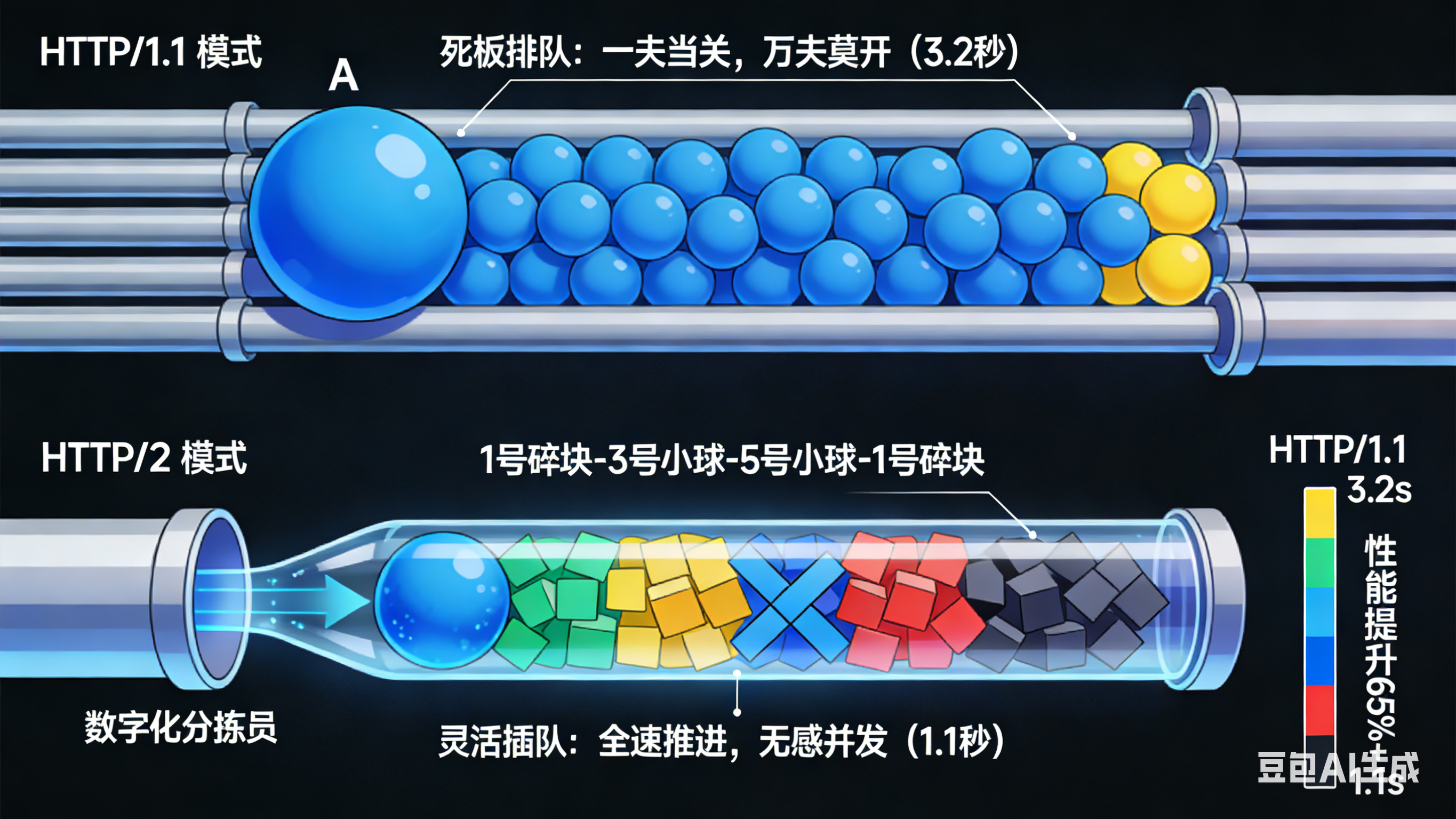
HTTP/1.1(死板排队):
- 必须等 1 号流的所有球走完,3 号流的球才能进场
- 如果 1 号球很大(大图片),3 号就得在管口等到天荒地老
HTTP/2(灵活插队):
- 管口有个分拣员,他先塞一个 1 号球,紧接着塞一个 3 号球,再塞一个 5 号球
- 结果:管子里全是乱序的球:1-3-5-1-3-5...
- 物理上还是一个个走,但不同流的任务都在同时向前推进
HTTP/2 提倡"单连接"主义
HTTP/1.1 时代:
- 浏览器会开 6-8 个 TCP 连接来提高速度
HTTP/2 时代:
- 只开 1 个 TCP 连接才是它的杀手锏
为什么"只走一根管子"反而比"走多根管子"更快?
1. 为什么不再需要多个连接?
- HTTP/1.1:开多个连接是因为"一根管子一次只能传一个完整文件",为了并发,只好通过多开管子来强行实现
- HTTP/2 :
- 有了二进制分帧和流 ID,一根管子内部已经实现了"插队并行"
- 这根管子的带宽利用率被压榨到了极限,已经能同时处理几十个请求了
- 再多开连接反而成了浪费
2. 为什么"单连接"反而能走得更多、更快?
涉及两个核心的通信常识:
A. 避开了"慢启动"(Slow Start)
- TCP 协议特性:刚开始建立连接时,它不信任网络质量,发包速度很慢,然后逐渐提速
- HTTP/1.1:开 6 个连接,每个连接都要经历一次从慢到快的"起步期",效率极低
- HTTP/2:只开 1 个连接。只要起步完成了,这根管子就一直处于高速全速状态,后续所有的请求(流)一进来就是"起飞速度"
B. 节省了"握手"时间
- 建立一个 TCP 连接需要三次握手,如果是加密的(HTTPS),还要进行 TLS 握手,非常耗时
- HTTP/2 只需要握手一次,从此天长地久
- 原本用来握手的时间,现在都用来传数据了
3. 难道没有例外吗?
确实有特殊场景:
A. 不同的域名
B. 网络极差
- 在丢包极其严重的网络下,单连接因为"TCP 队头阻塞",表现可能不如多连接
实测数据(100个资源页面):
- HTTP/1.1(6个连接):3.2秒
- HTTP/2(多路复用):1.1秒
- 性能提升:65%+
3.4 深入理解:多路复用如何消除Stalled时间
在浏览器开发者工具的Network面板中,我们经常看到请求状态栏中有"Stalled"(停滞)时间。HTTP/2的多路复用是如何从根本上减少甚至消除这个Stalled时间的?
什么是Stalled时间?
**Stalled(停滞)**是指请求在发送到服务器之前,在浏览器中等待的时间。在HTTP/1.1中,这是性能的主要瓶颈之一。
HTTP/1.1的Stalled问题根源
虽然浏览器会为同一个域名打开多个TCP连接(通常是6-8个)来并行下载资源,但这只是权宜之计:
- 连接数有上限:浏览器限制同一域名最多6-8个并发连接
- 管理开销大:每个连接都需要独立的三次握手、TLS握手、TCP慢启动
- 请求需要排队:当需要加载的资源超过连接数时,请求必须等待空闲连接
- 队头阻塞加剧排队:在同一个TCP连接上,请求和响应必须严格按顺序处理,慢响应阻塞后续请求
结果 :连接数有限,当需要加载的资源很多时,请求仍然需要排队等待空闲连接。这正是浏览器开发者工具中 "Stalled"(停滞) 时间的根本原因------它在等待一个可用的连接。
HTTP/2的革命性改进
HTTP/2 在一个TCP连接 上引入了 "流" 的概念,核心变化:
- 真正的并行 :一个连接上可同时有几十、几百个请求,响应数据帧交错到达,移除了HTTP层的队头阻塞
- 无需多个TCP连接:一个域名只需一个TCP连接,减少了连接建立、TLS握手和TCP慢启动的开销
- 零Stalled等待:请求几乎立即发出(只要不超过最大并发流限制,通常100+)
工作原理对比:
连接1: [请求A] → [等待响应A] → [响应A] → [请求B] → [等待响应B] → [响应B]
连接2: [请求C] → [等待响应C] → [响应C] → [请求D] → [等待响应D] → [响应D]
连接3: [请求E] → [等待响应E] → [响应E] → [请求F] → [等待响应F] → [响应F]
...
连接6: [请求X] → [等待响应X] → [响应X]
请求Y: [Stalled - 等待空闲连接] → [分配到连接1] → [请求Y] → ...HTTP/2的解决方案:
单个连接: [流1请求][流2请求][流3请求][流4请求]...[流100请求]
↓
[流2响应][流1响应][流4响应][流3响应]...(按准备就绪顺序返回)
请求几乎零Stalled,因为所有请求都能立即发出关键误区澄清:TCP队头阻塞 vs HTTP队头阻塞
这是理解HTTP/2局限性的关键。
HTTP队头阻塞(已解决)
- HTTP/1.1的队头阻塞是应用层协议设计导致的(响应必须按顺序)
- HTTP/2解决了上述应用层队头阻塞:通过流ID,响应可以乱序返回
TCP队头阻塞(仍未解决)
- HTTP/2仍然受到TCP协议本身的队头阻塞影响!
TCP队头阻塞是什么?
TCP是一个保证顺序、可靠的字节流协议。如果网络传输中丢失了一个TCP数据包,整个连接必须停下来等待这个包重传成功。因为接收方必须按顺序重组字节流才能交给应用层(HTTP/2)。
-
在HTTP/1.1中:一个TCP包丢失,只会影响当前连接上的一个请求(因为一个连接上本来就在串行处理一个请求)
-
在HTTP/2中 :一个TCP包丢失,会阻塞这个TCP连接上所有正在传输的"流"!因为这些流的数据都交织在同一个字节流里,丢失的包后面的数据即使收到了也无法处理(顺序不对)。这是一个物理层的瓶颈
直观理解:
HTTP/2的多个流数据交织在TCP字节流中:
TCP字节流: [流1数据][流2数据][流3数据][流1数据][流2数据][流3数据]...
如果中间某个TCP包丢失:
→ TCP必须等待重传
→ 所有流的数据传输都暂停
→ 即使流2和流3的数据已经准备好了,也无法发送这就是为什么HTTP/3要基于UDP的QUIC协议,将流的多路复用功能下移到传输层,使得即使发生丢包,也只会影响丢失包所属的那一个流。
完整对比表格
| 特性 | HTTP/1.1 + 多个连接 | HTTP/2 + 单个连接 |
|---|---|---|
| 连接管理 | 需要为同一域名维护多个(6-8个)TCP连接 | 一个TCP连接承载所有通信 |
| 并发模型 | 依靠多个TCP连接实现连接级别的并行。请求在连接间分配 | 在一个连接内 ,通过"流"实现请求/响应级别的并行与交错 |
| 队头阻塞 | 存在严重的HTTP层队头阻塞(同一个连接上请求顺序处理) | 解决了HTTP层队头阻塞 ,但仍受TCP层队头阻塞影响(一个丢包阻塞所有流) |
| 头部开销 | 每个请求都携带大量重复的头部(Cookie、User-Agent等) | 使用HPACK头部压缩,极大减少了头部大小 |
| 服务器推送 | 不支持。服务器只能被动响应 | 支持。服务器可以主动推送客户端可能需要的资源 |
| "Stalled"时间 | 主要来源:等待可用的TCP连接。连接数有限,排队严重 | 几乎消除。因为所有请求都能立刻发出(只要不超过服务器设置的最大并发流限制,通常很高,如100+) |
实际效果
HTTP/1.1场景(加载100个资源):
时间线:
0ms: 建立连接1-6(6个连接)
50ms: 连接1-6分别发送请求1-6
200ms: 收到响应1-6
250ms: 连接1-6分别发送请求7-12
[请求13-100: Stalled - 等待空闲连接]
400ms: 收到响应7-12
450ms: 连接1-6分别发送请求13-18
[请求19-100: 继续Stalled]
...
3200ms: 所有资源加载完成HTTP/2场景(加载100个资源):
时间线:
0ms: 建立1个TCP连接
50ms: 立即发送请求1-100(所有请求)
200ms: 开始收到响应(按服务器处理速度,乱序返回)
400ms: 继续收到响应
...
1100ms: 所有资源加载完成总结
HTTP/2通过多路复用,从根本上减少了请求排队和Stalled时间。 因为它移除了HTTP/1.1时代因连接数限制和串行处理导致的排队问题。
但完美的协议并不存在,HTTP/2的TCP队头阻塞问题,最终推动了 HTTP/3 的诞生。HTTP/3基于UDP的QUIC协议,将流的多路复用功能下移到了传输层(QUIC的流),使得即使发生丢包,也只会影响丢失包所属的那一个流,彻底解决了队头阻塞问题。
简单记忆:
- HTTP/1.1:6辆小货车,每辆车一次只能拉一个包裹,包裹多了要排队等车
- HTTP/2:1辆超级高铁,所有包裹切碎后贴上标签(流ID)一起装车,几乎不用排队
- HTTP/3:1辆更智能的高铁,即使某个包裹的箱子破了,也不影响其他包裹
3.5 新引入的问题
-
TCP队头阻塞仍未解决
- HTTP/2在应用层解决了队头阻塞
- 但TCP层队头阻塞依然存在
- 一个丢包影响所有流
-
握手延迟依然显著
- TCP握手:1RTT
- TLS握手:1-2RTT
- 总计:2-3RTT后才能发送数据
-
队头阻塞迁移到TCP层
包1丢失
无丢包
HTTP/2多流
TCP字节流
网络丢包
等待重传
所有流阻塞
正常传输