语义分割从入门到精通教程
语义分割是计算机视觉的核心任务之一 ,目标是对图像中每个像素 进行分类,实现"像素级"的场景理解。为每个像素分配一个预定义的语义类别标签(例如"人"、"车"、"天空"),从而实现对图像的精细化理解 。其核心目标是理解图像中的场景和物体,但不区分同一类别中的不同个体实例。它广泛应用于自动驾驶、医学影像、遥感监测、工业质检等领域。本教程从理论基础→实践操作→进阶优化→前沿方向层层递进,帮助初学者快速掌握语义分割技术。
一、 入门篇:理解语义分割核心概念
1.1 语义分割的定义与定位
-
定义 :语义分割是将图像划分为若干互不重叠的区域,并为每个区域赋予对应的语义类别(如人、车、道路、树木)的过程,最终输出与输入图像尺寸相同的分割掩码(Mask) 。
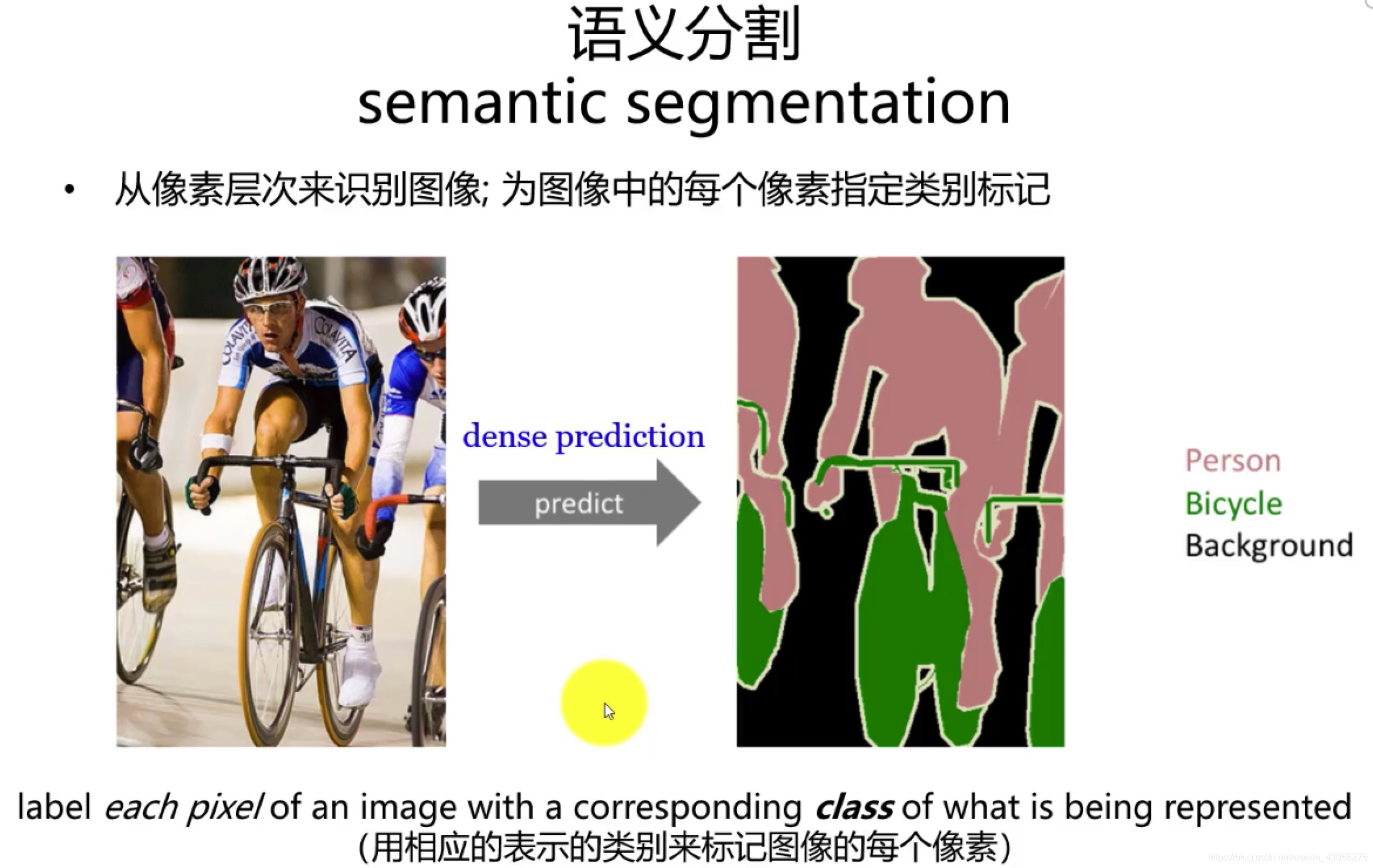
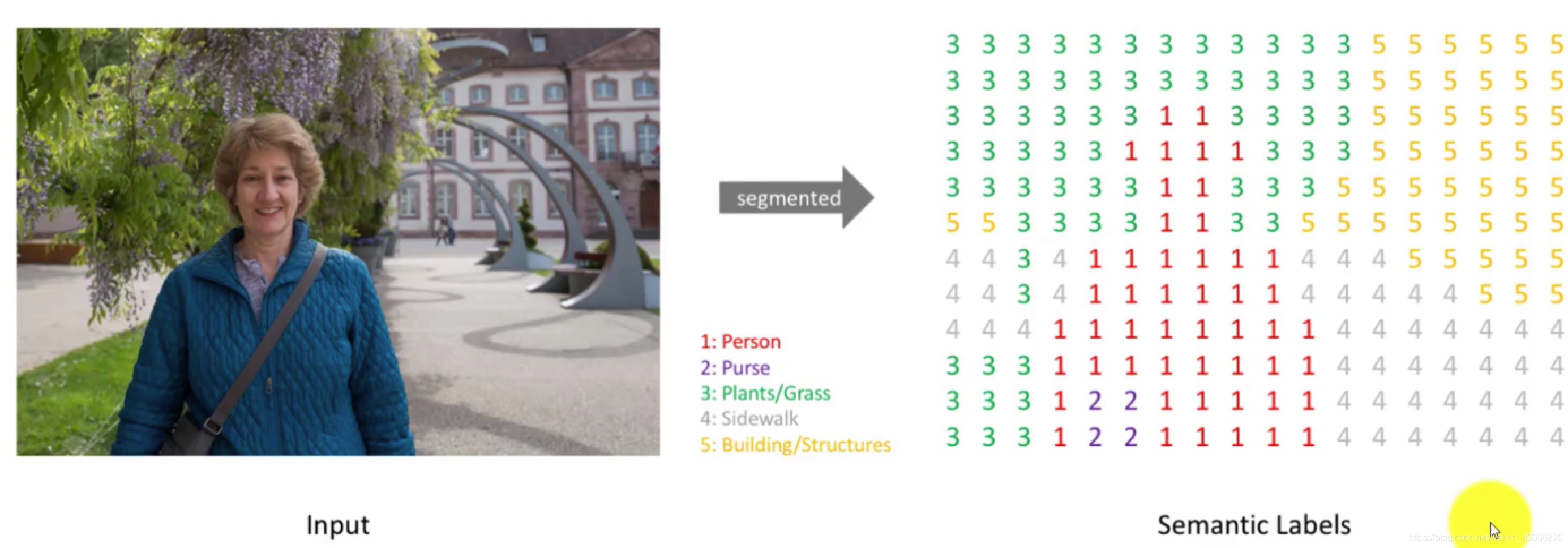

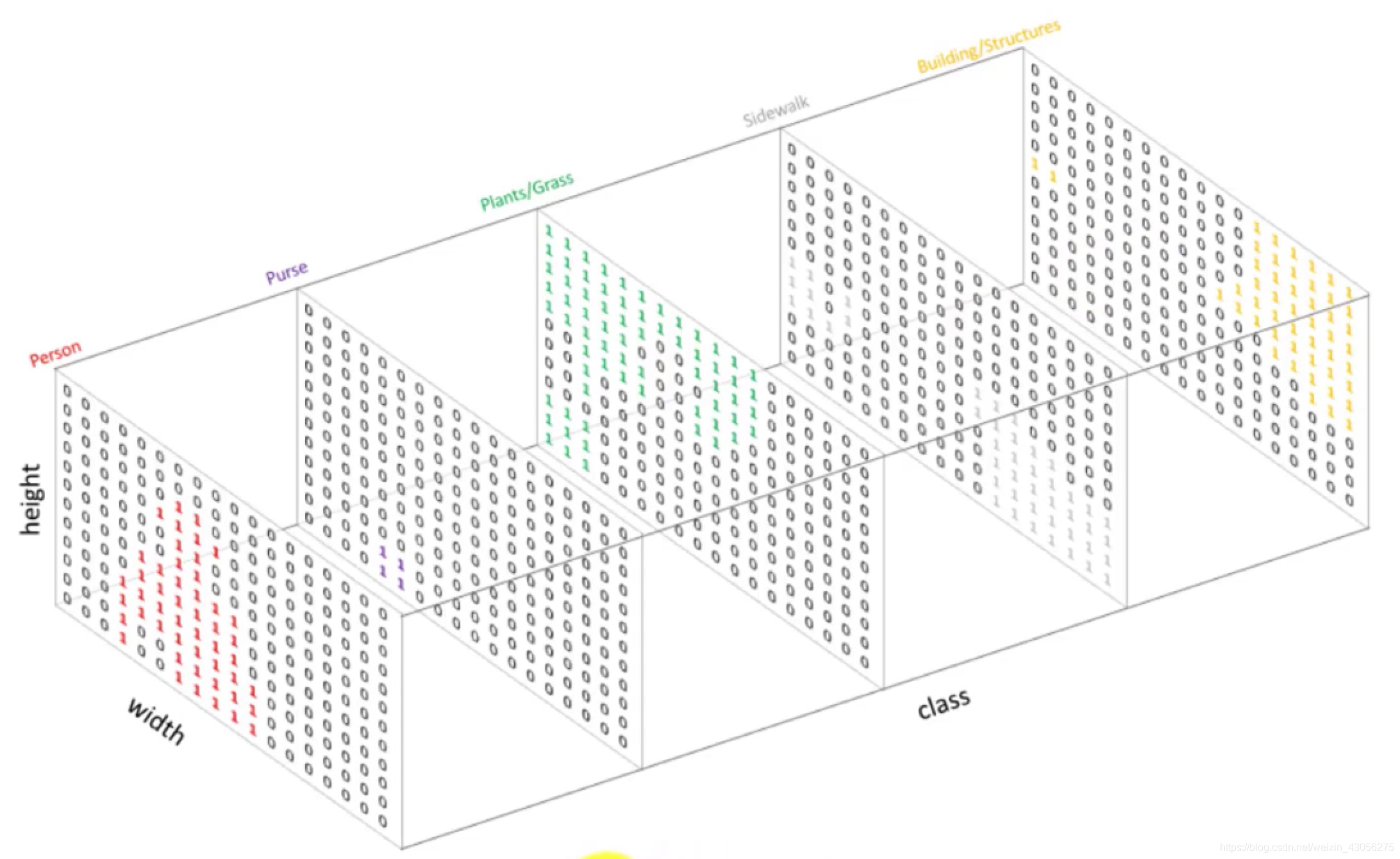
-
与相关任务的区别
任务 核心目标 输出特点 典型场景 图像分类 判断整张图的类别 单一类别标签 猫狗分类 目标检测 定位+识别目标 边界框+类别 人脸检测 语义分割 像素级分类 逐像素类别掩码 自动驾驶道路分割 实例分割 区分同一类别的不同个体 掩码+实例ID 人群中每个人的分割 全景分割 语义分割+实例分割 语义掩码+实例ID 复杂场景完整解析
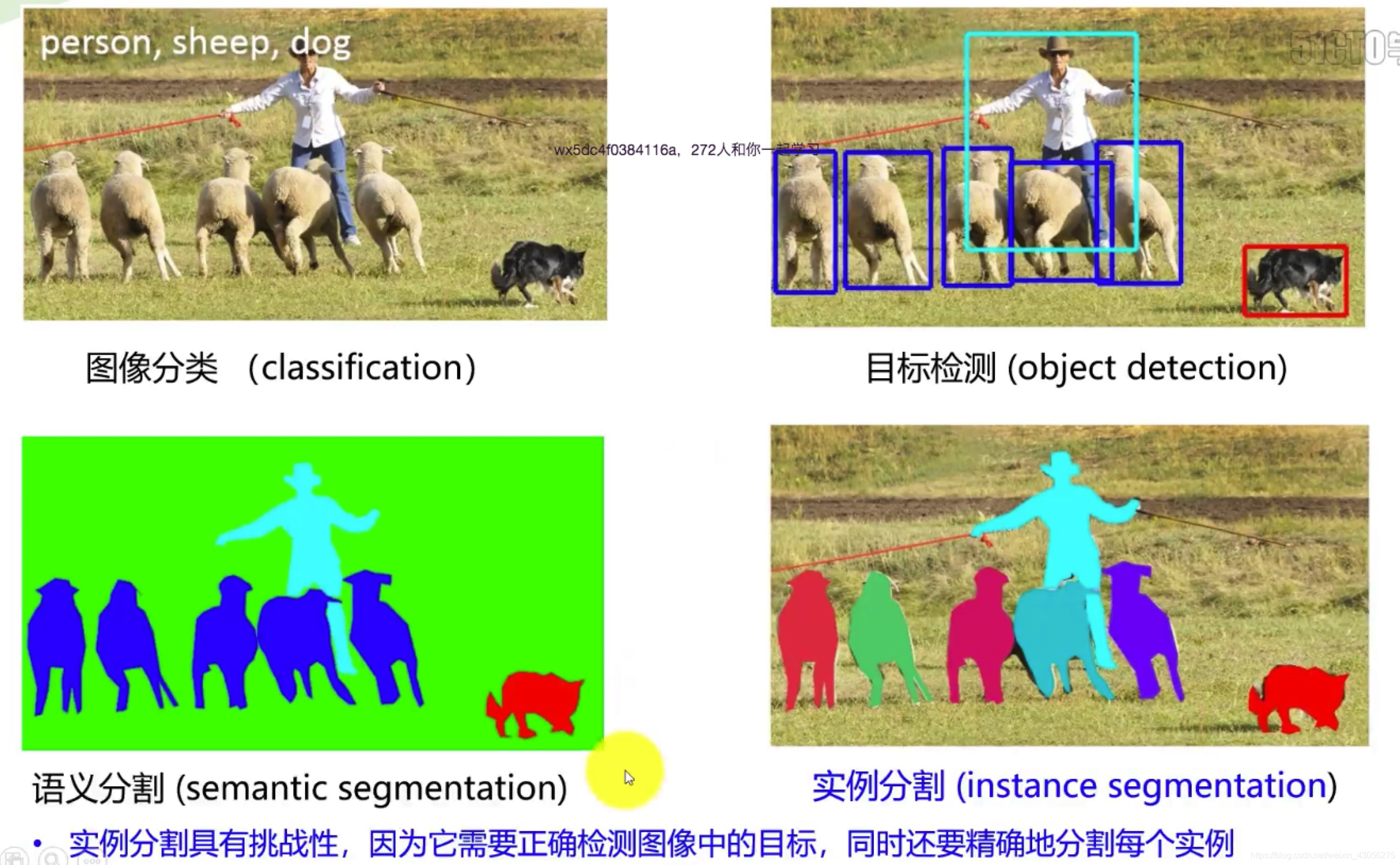

1.2 必备前置知识
语义分割是深度学习+计算机视觉的交叉应用,初学者需掌握以下基础:
- 深度学习基础
- 卷积神经网络(CNN):卷积、池化、上采样的原理;
- 常见模块:BatchNorm、ReLU、Dropout的作用;
- 损失函数:交叉熵损失、Dice损失的适用场景。
- 编程工具
- Python:熟练掌握基本语法、NumPy、Pandas;
- 深度学习框架:PyTorch/TensorFlow(推荐PyTorch,灵活性更高);
- 视觉工具库:OpenCV(图像读写与预处理)、Albumentations(数据增强)、Matplotlib(可视化)。
- 计算机视觉基础
- 图像的表示:像素、通道(RGB/灰度)、分辨率;
- 基本操作:裁剪、翻转、归一化、色域变换。
二、 基础篇:经典语义分割算法原理
语义分割的发展分为传统方法 和深度学习方法两个阶段,深度学习方法是当前主流,需重点掌握。
2.1 传统语义分割方法(了解即可)
传统方法依赖人工设计特征,精度低且泛化性差,仅适用于简单场景:
- 阈值分割:基于像素灰度值的差异划分区域(如二值化分割前景/背景);
- 边缘检测:通过Canny、Sobel算子提取边缘,再连接边缘形成区域;
- 区域生长:从种子像素出发,合并相似特征的相邻像素。
2.2 深度学习语义分割核心算法
深度学习通过端到端训练自动学习特征,大幅提升分割精度,以下是里程碑式算法:
-
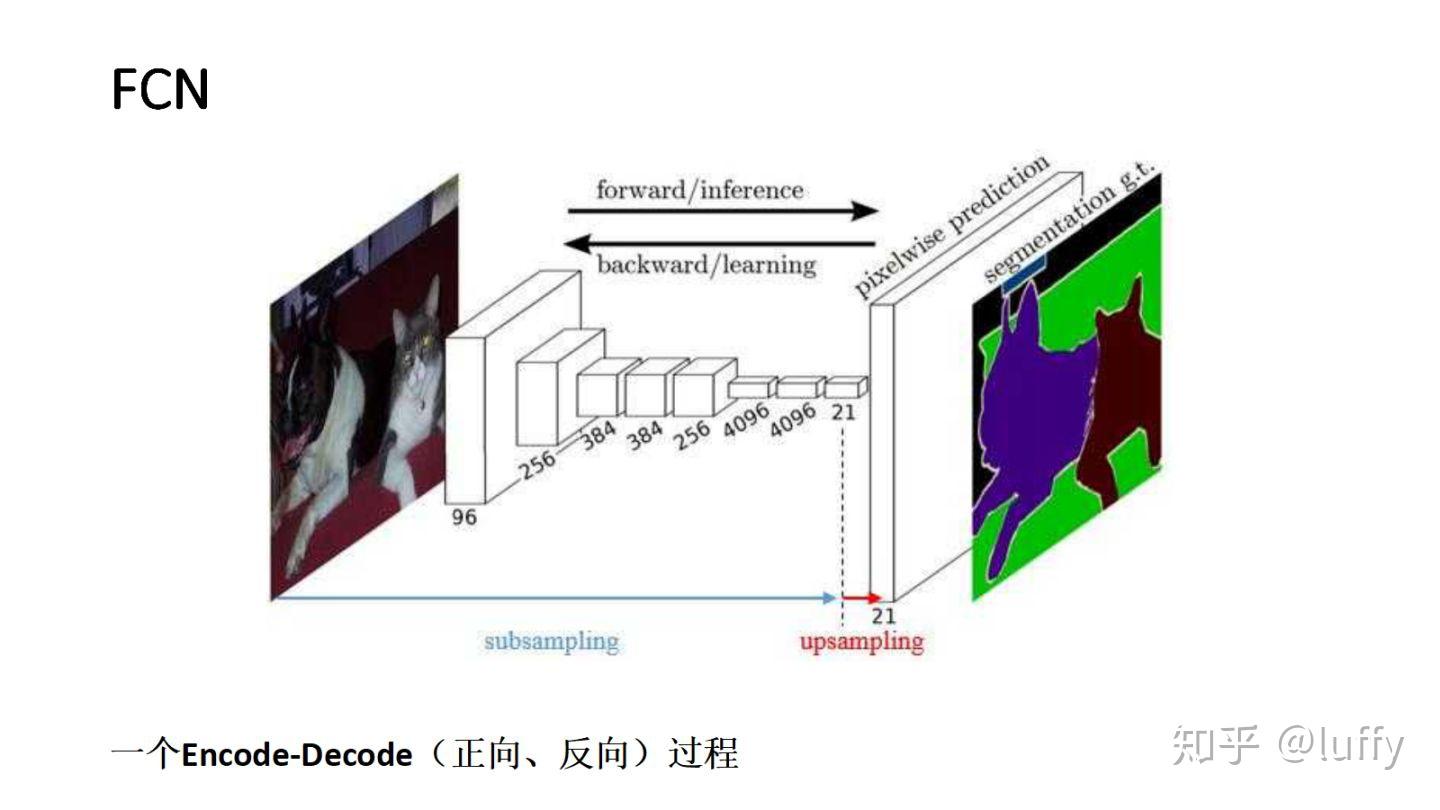
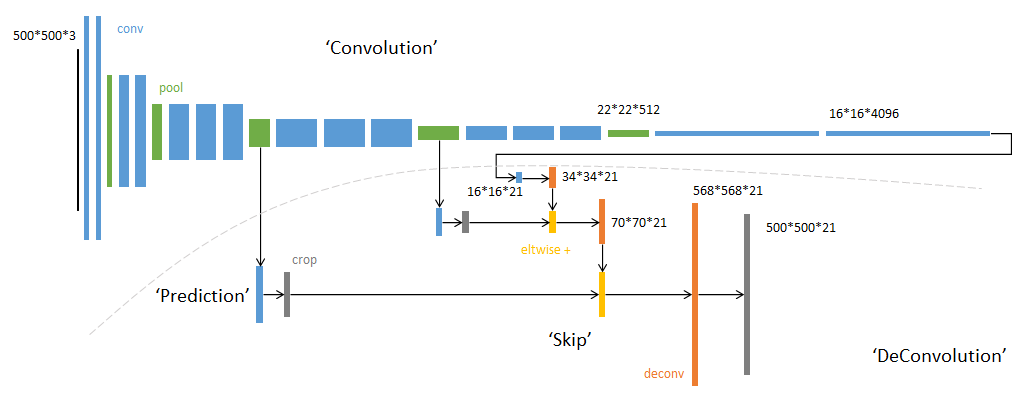
FCN(Fully Convolutional Networks)------ 开山之作
- 核心创新 :用卷积层替代CNN的全连接层,实现任意尺寸图像输入,输出与输入同尺寸的分割图;
- 关键结构 :
- 编码器(Encoder):采用VGG等分类网络提取特征,特征图尺寸逐步缩小、通道数增加;
- 解码器(Decoder):通过反卷积/上采样将低分辨率特征图恢复到原图尺寸;
- 跳跃连接(Skip Connection):融合编码器不同层级的特征,弥补下采样丢失的细节。
- 不足 :分割边缘不够精细,对小目标分割效果差。
-
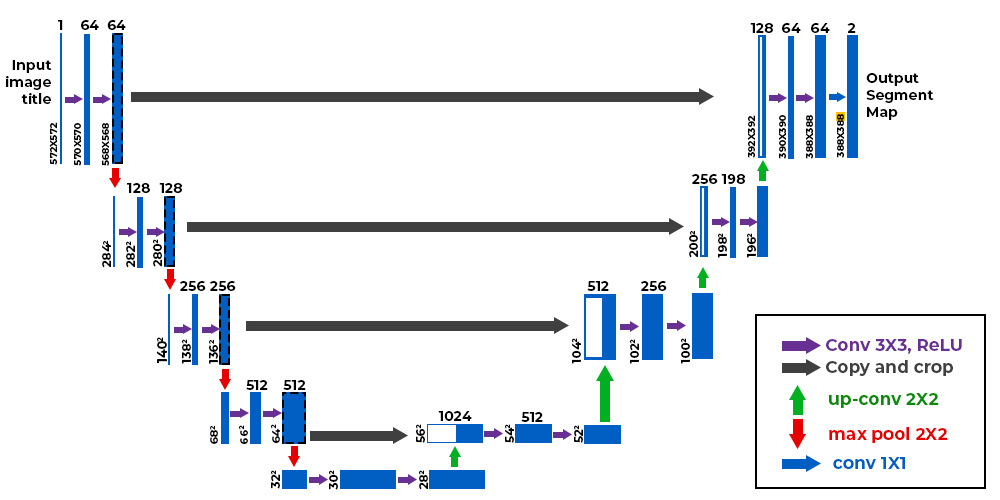
U-Net ------ 医学影像分割标杆
- 适用场景:医学影像(如CT、MRI)分割,标注数据少的场景;
- 核心结构 :
- 对称的"U"型结构:左侧编码器(下采样)+ 右侧解码器(上采样);
- 高强度跳跃连接:将编码器的高分辨率特征图直接拼接(Concatenate)到解码器对应层,保留细节信息;
- 优势 :结构简洁、参数量小、小数据集上效果优异,是初学者入门首选模型。
-
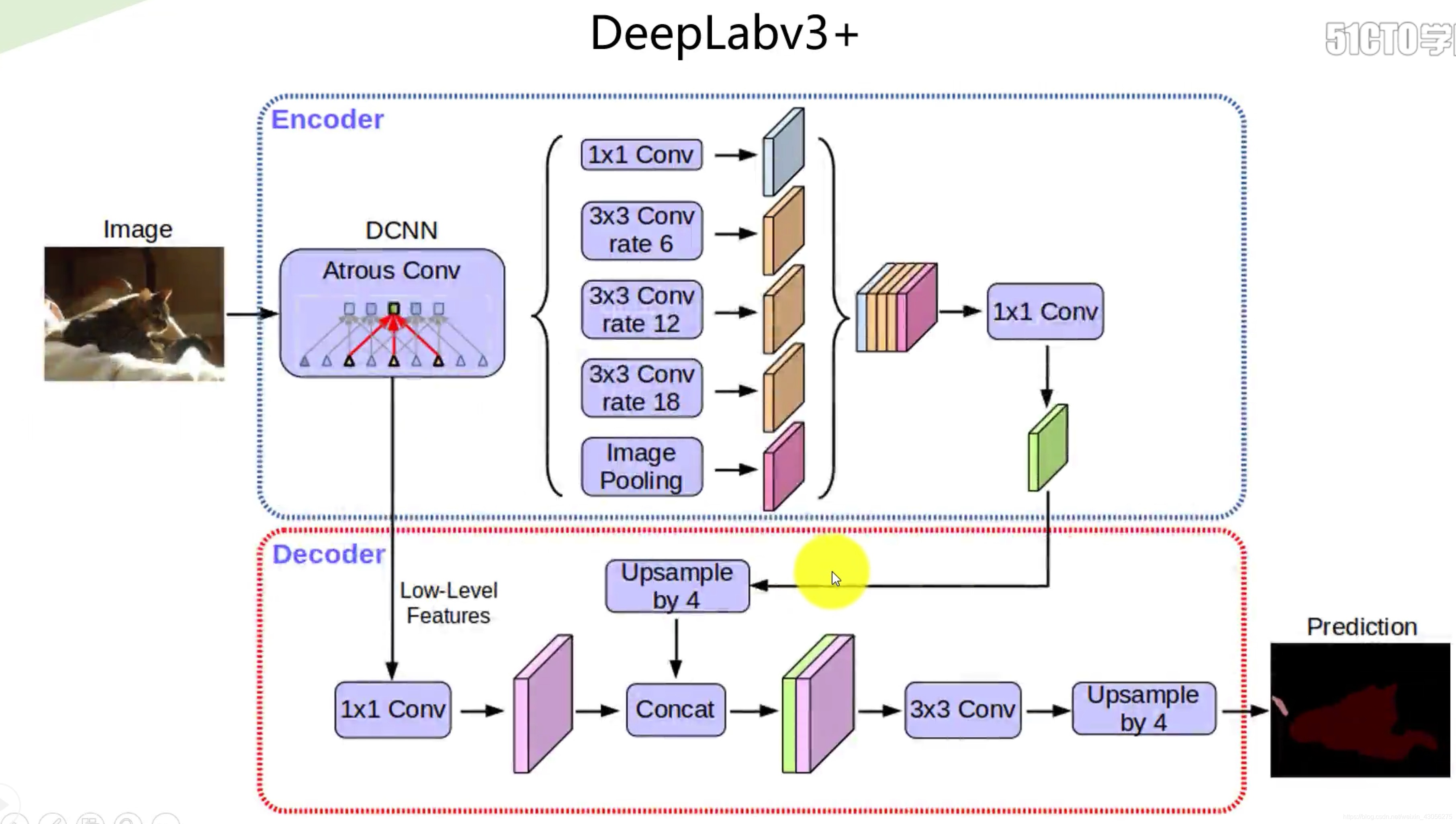
DeepLab系列 ------ 工业级强性能模型
- 核心创新 :引入空洞卷积(Atrous Convolution) 和空间金字塔池化(ASPP) ;
- 空洞卷积:在不增加参数量的前提下,扩大卷积核的感受野,捕捉多尺度上下文信息;
- ASPP模块:用不同膨胀率的空洞卷积并行处理特征,融合多尺度特征,提升对不同大小目标的分割能力;
- 主流版本 :DeepLabv3+(结合编码器-解码器结构,是目前工业界常用的基线模型)。
- 核心创新 :引入空洞卷积(Atrous Convolution) 和空间金字塔池化(ASPP) ;
-
SegFormer ------ Transformer时代的分割模型
- 核心创新:基于Vision Transformer(ViT)设计,摆脱CNN依赖;
- 优势 :Transformer的自注意力机制能捕捉长距离依赖,分割精度更高;模型轻量化,适合实时场景。
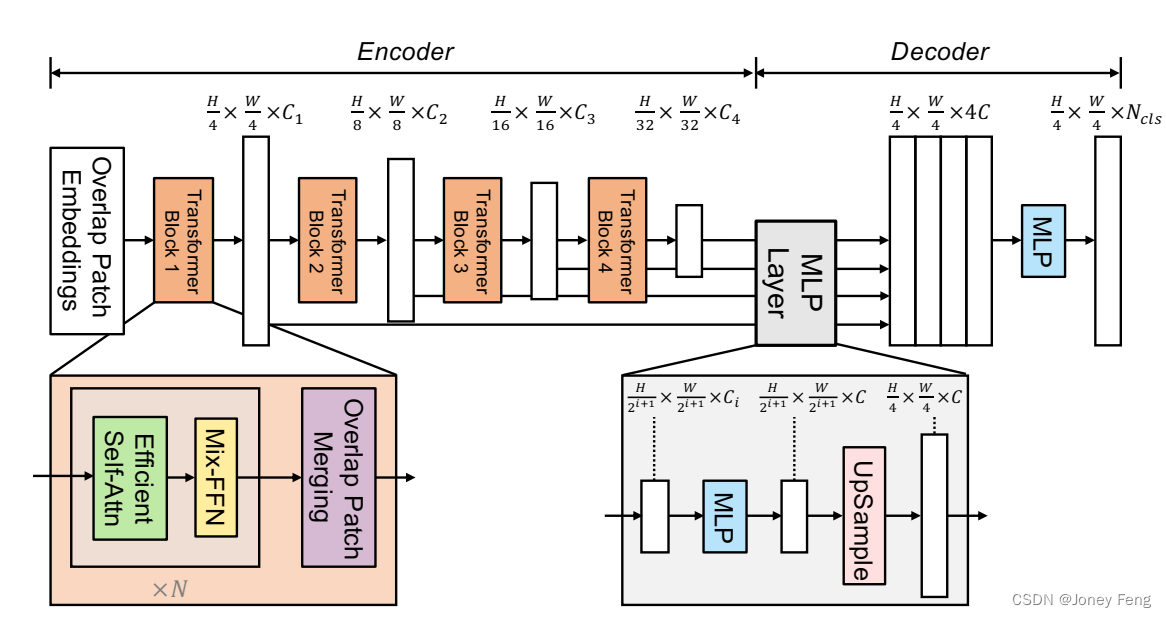
三、 实践篇:从零实现U-Net语义分割
实践是掌握语义分割的关键,本节以PyTorch框架 为例,实现基于U-Net的医学影像分割(数据集:Carvana Image Masking Challenge,可替换为其他数据集)。
3.1 环境搭建
安装必备库:
bash
# 深度学习框架
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 视觉工具
pip install opencv-python albumentations matplotlib
# 数据处理
pip install pandas numpy tqdm3.2 数据集准备与预处理
-
数据集结构
建议按如下结构组织数据,便于读取:dataset/ ├── train/ │ ├── images/ # 训练图像 │ └── masks/ # 训练掩码(与图像一一对应) └── val/ ├── images/ # 验证图像 └── masks/ # 验证掩码 -
数据增强
语义分割对数据增强要求高,需保证图像和掩码的增强操作同步。使用Albumentations库实现:pythonimport albumentations as A from albumentations.pytorch import ToTensorV2 # 训练集增强 train_transform = A.Compose([ A.Resize(height=256, width=256), A.HorizontalFlip(p=0.5), A.RandomRotate90(p=0.5), A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)), ToTensorV2(), ]) # 验证集增强(仅归一化和Resize) val_transform = A.Compose([ A.Resize(height=256, width=256), A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)), ToTensorV2(), ]) -
自定义Dataset类
继承torch.utils.data.Dataset,实现图像和掩码的读取:pythonimport os import cv2 import torch from torch.utils.data import Dataset class SegmentationDataset(Dataset): def __init__(self, img_dir, mask_dir, transform=None): self.img_dir = img_dir self.mask_dir = mask_dir self.transform = transform self.images = sorted(os.listdir(img_dir)) def __len__(self): return len(self.images) def __getitem__(self, idx): img_path = os.path.join(self.img_dir, self.images[idx]) mask_path = os.path.join(self.mask_dir, self.images[idx].replace(".jpg", "_mask.gif")) image = cv2.imread(img_path) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE) mask = (mask > 0).astype(np.uint8) # 二值化掩码 if self.transform: augmented = self.transform(image=image, mask=mask) image = augmented["image"] mask = augmented["mask"].unsqueeze(0) # 增加通道维度 return image, mask
3.3 U-Net模型实现
python
import torch
import torch.nn as nn
class DoubleConv(nn.Module):
# 编码器基本单元:2次卷积 + BN + ReLU
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
# 下采样:MaxPool + DoubleConv
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
# 上采样:反卷积 + 拼接 + DoubleConv
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# 对齐尺寸(防止下采样后尺寸不匹配)
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = nn.functional.pad(x1, [diffX//2, diffX - diffX//2, diffY//2, diffY - diffY//2])
x = torch.cat([x2, x1], dim=1) # 跳跃连接:拼接编码器特征
return self.conv(x)
class OutConv(nn.Module):
# 输出层:1x1卷积映射到类别数
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512)
self.up2 = Up(512, 256)
self.up3 = Up(256, 128)
self.up4 = Up(128, 64)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits3.4 训练与验证
-
训练参数设置
pythondevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = UNet(n_channels=3, n_classes=1).to(device) # 二分类任务,n_classes=1 criterion = nn.BCEWithLogitsLoss() # 二分类损失函数 optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=2) # 学习率调度 -
训练循环
pythonfrom torch.utils.data import DataLoader from tqdm import tqdm # 加载数据集 train_dataset = SegmentationDataset("dataset/train/images", "dataset/train/masks", train_transform) val_dataset = SegmentationDataset("dataset/val/images", "dataset/val/masks", val_transform) train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, num_workers=2) val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False, num_workers=2) # 训练函数 def train_epoch(model, loader, optimizer, criterion, device): model.train() total_loss = 0.0 for images, masks in tqdm(loader): images, masks = images.to(device), masks.to(device).float() optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, masks) loss.backward() optimizer.step() total_loss += loss.item() * images.size(0) return total_loss / len(loader.dataset) # 验证函数 def val_epoch(model, loader, criterion, device): model.eval() total_loss = 0.0 with torch.no_grad(): for images, masks in loader: images, masks = images.to(device), masks.to(device).float() outputs = model(images) loss = criterion(outputs, masks) total_loss += loss.item() * images.size(0) return total_loss / len(loader.dataset) # 开始训练 num_epochs = 50 best_val_loss = float('inf') for epoch in range(num_epochs): train_loss = train_epoch(model, train_loader, optimizer, criterion, device) val_loss = val_epoch(model, val_loader, criterion, device) scheduler.step(val_loss) # 根据验证损失调整学习率 print(f"Epoch {epoch+1}/{num_epochs} | Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f}") # 保存最优模型 if val_loss < best_val_loss: best_val_loss = val_loss torch.save(model.state_dict(), "best_unet.pth")
3.5 推理与可视化
加载训练好的模型,对新图像进行分割并可视化结果:
python
import matplotlib.pyplot as plt
import numpy as np
def predict_image(model, image_path, transform, device):
model.eval()
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
augmented = transform(image=image)
image = augmented["image"].unsqueeze(0).to(device) # 增加batch维度
with torch.no_grad():
output = model(image)
pred_mask = torch.sigmoid(output).cpu().numpy().squeeze()
pred_mask = (pred_mask > 0.5).astype(np.uint8) # 阈值化得到二值掩码
return image.cpu().squeeze().permute(1,2,0).numpy(), pred_mask
# 加载模型
model = UNet(n_channels=3, n_classes=1).to(device)
model.load_state_dict(torch.load("best_unet.pth"))
# 预测并可视化
img_path = "test.jpg"
img, mask = predict_image(model, img_path, val_transform, device)
plt.subplot(1,2,1)
plt.imshow(img)
plt.title("Input Image")
plt.subplot(1,2,2)
plt.imshow(mask, cmap="gray")
plt.title("Predicted Mask")
plt.show()四、 进阶篇:模型优化与性能提升
入门后,需掌握以下优化技巧,让模型在精度和速度上达到工业级水平。
4.1 损失函数优化
语义分割常面临类别不平衡(如小目标占比低)问题,需替换损失函数:
- Dice Loss :适合医学影像等二分类场景,解决类别不平衡;
D i c e L o s s = 1 − 2 ∣ Y t r u e ∩ Y p r e d ∣ ∣ Y t r u e ∣ + ∣ Y p r e d ∣ Dice Loss = 1 - \frac{2|Y_{true} \cap Y_{pred}|}{|Y_{true}| + |Y_{pred}|} DiceLoss=1−∣Ytrue∣+∣Ypred∣2∣Ytrue∩Ypred∣ - Focal Loss:降低易分类样本的权重,聚焦难分类样本;
- 混合损失 :如
Dice Loss + BCE Loss,兼顾精度和稳定性。
4.2 模型轻量化与实时性
工业场景(如自动驾驶)要求模型实时推理,需进行轻量化:
- 替换骨干网络:用MobileNet、ShuffleNet、EfficientNet-Lite替代VGG,减少参数量;
- 模型剪枝/量化:剪枝移除冗余参数,量化将32位浮点数转为8位整数,提升推理速度;
- 知识蒸馏:用大模型(教师模型)指导小模型(学生模型)训练,保证精度的同时降低计算量。
4.3 高级训练技巧
- 迁移学习:使用在ImageNet上预训练的骨干网络初始化编码器,大幅减少训练数据量,提升收敛速度;
- 混合精度训练 :使用
torch.cuda.amp混合FP16和FP32精度,减少显存占用,加速训练; - 多尺度训练/测试:训练时用不同尺度的图像输入,测试时融合多尺度输出的掩码,提升精度。
五、 精通篇:前沿方向与论文复现
5.1 语义分割前沿研究方向
- Transformer-based分割:SegFormer、Mask2Former、Segmenter等模型,利用自注意力机制捕捉全局信息;
- 弱监督/半监督语义分割:减少对标注数据的依赖,利用图像标签、边界框等弱标注信息训练;
- 视频语义分割:结合时序信息,实现动态场景的像素级分类,应用于自动驾驶、视频监控;
- 跨域语义分割:解决不同数据集间的分布差异(如晴天/雨天图像分割),提升模型泛化性。
5.2 论文复现技巧
精通语义分割的核心是论文复现,步骤如下:
- 选论文:从经典论文(FCN、U-Net、DeepLabv3+)入手,再过渡到顶会论文(CVPR、ICCV、ECCV);
- 读论文 :重点关注创新点、模型结构、实验设置,画出模型结构图;
- 复现步骤 :
- 复现模型结构(严格对齐论文参数);
- 复现实验设置(数据集、优化器、学习率、训练策略);
- 对比实验结果,分析差异原因(如数据增强、初始化方式)。
5.3 常用评估指标
论文和项目中需用以下指标评估模型性能:
- IoU(交并比) :计算预测掩码与真实掩码的交集和并集的比值,是核心指标;
I o U = T P T P + F P + F N IoU = \frac{TP}{TP + FP + FN} IoU=TP+FP+FNTP - mIoU(平均交并比):所有类别的IoU平均值;
- Pixel Accuracy:正确分类的像素占总像素的比例。
六、 学习资源推荐
- 课程:B站《李沐深度学习笔记》、Coursera《Convolutional Neural Networks》;
- 开源代码 :
- Segmentation Models PyTorch(集成多种分割模型);
- MMSegmentation(OpenMMLab开源的分割工具箱,适合快速开发);
- 论文网站:Papers With Code(按任务分类整理论文和代码)、arXiv(最新论文预印本)。
总结
语义分割的学习路径遵循 "理论理解→代码实践→优化调参→前沿研究" 的逻辑。初学者需先掌握U-Net等基础模型的实现,再通过优化技巧提升性能,最终通过论文复现走向精通。
基于U-Net的遥感影像分割完整项目代码 已整理完毕,涵盖数据集处理、模型训练、性能评估、结果可视化、单张影像推理全流程,适配常见的遥感影像分割场景(如土地覆盖分类),代码可直接复制运行。
一、项目说明
1.1 应用场景
遥感影像分割主要用于土地覆盖分类(耕地、建筑、道路、水体等)、城市规划、灾害监测等,本项目以多类别遥感影像分割为例(5类:背景、建筑、道路、耕地、水体)。
1.2 数据集说明
推荐使用公开遥感分割数据集:
- GID数据集(高分遥感影像土地覆盖分类):https://x-ytong.github.io/project/gid.html
- ISPRS Potsdam数据集(航拍遥感分割):https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx
示例数据集结构(需按此格式整理你的数据):
remote_sensing_seg/
├── data/
│ ├── train/
│ │ ├── images/ # 训练影像(.tif/.png/.jpg,分辨率建议512×512)
│ │ └── masks/ # 训练掩码(与影像同名,单通道,像素值为类别ID:0-4)
│ ├── val/
│ │ ├── images/ # 验证影像
│ │ └── masks/ # 验证掩码
│ └── test/ # 测试影像(可选)
├── best_model.pth # 训练后保存的最优模型
└── main.py # 项目主代码二、完整项目代码
将以下代码保存为main.py,放在上述项目根目录下:
python
import os
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import albumentations as A
from albumentations.pytorch import ToTensorV2
import matplotlib.pyplot as plt
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
# ===================== 1. 配置参数 =====================
class Config:
# 路径配置
TRAIN_IMG_DIR = "data/train/images"
TRAIN_MASK_DIR = "data/train/masks"
VAL_IMG_DIR = "data/val/images"
VAL_MASK_DIR = "data/val/masks"
TEST_IMG_PATH = "data/test/test_image.tif" # 测试影像路径
SAVE_MODEL_PATH = "best_model.pth"
# 模型参数
IN_CHANNELS = 3 # 遥感影像通常为RGB 3通道
NUM_CLASSES = 5 # 分割类别数(背景+4类地物)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 训练参数
BATCH_SIZE = 4
LEARNING_RATE = 1e-4
NUM_EPOCHS = 50
EARLY_STOP_PATIENCE = 5 # 早停策略:验证损失连续5轮不下降则停止
# ===================== 2. 数据集定义 =====================
class RemoteSensingDataset(Dataset):
"""遥感影像分割数据集类"""
def __init__(self, img_dir, mask_dir, transform=None):
self.img_dir = img_dir
self.mask_dir = mask_dir
self.transform = transform
self.img_names = [f for f in os.listdir(img_dir) if f.endswith(('.tif', '.png', '.jpg'))]
def __len__(self):
return len(self.img_names)
def __getitem__(self, idx):
# 读取影像和掩码
img_name = self.img_names[idx]
img_path = os.path.join(self.img_dir, img_name)
mask_path = os.path.join(self.mask_dir, img_name.replace('.tif', '.png')) # 掩码建议用png(无损)
# 读取影像(RGB)
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 读取掩码(单通道,像素值为类别ID)
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
# 数据增强/预处理
if self.transform:
augmented = self.transform(image=image, mask=mask)
image = augmented["image"]
mask = augmented["mask"]
return image, mask
# ===================== 3. 数据增强/预处理 =====================
def get_transforms():
"""获取训练/验证集的变换"""
# 训练集增强(提升泛化性)
train_transform = A.Compose([
A.Resize(height=512, width=512),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2(),
])
# 验证集仅做归一化和Resize
val_transform = A.Compose([
A.Resize(height=512, width=512),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2(),
])
return train_transform, val_transform
# ===================== 4. U-Net模型定义 =====================
class DoubleConv(nn.Module):
"""双卷积模块:Conv + BN + ReLU ×2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""下采样模块:MaxPool + DoubleConv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""上采样模块:转置卷积 + 拼接 + DoubleConv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# 对齐尺寸(解决下采样/上采样后的尺寸偏差)
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = nn.functional.pad(x1, [diffX//2, diffX - diffX//2, diffY//2, diffY - diffY//2])
# 拼接编码器特征(跳跃连接)
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
"""输出层:1×1卷积映射到类别数"""
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512)
self.up2 = Up(512, 256)
self.up3 = Up(256, 128)
self.up4 = Up(128, 64)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
# ===================== 5. 评估指标(mIoU) =====================
def calculate_mIoU(pred_mask, true_mask, num_classes):
"""计算平均交并比(mIoU)"""
iou_list = []
pred_mask = pred_mask.cpu().numpy()
true_mask = true_mask.cpu().numpy()
for cls in range(num_classes):
# 计算当前类别的TP、FP、FN
tp = np.sum((pred_mask == cls) & (true_mask == cls))
fp = np.sum((pred_mask == cls) & (true_mask != cls))
fn = np.sum((pred_mask != cls) & (true_mask == cls))
# 避免除零错误
iou = tp / (tp + fp + fn + 1e-6)
iou_list.append(iou)
return np.mean(iou_list)
# ===================== 6. 训练/验证函数 =====================
def train_one_epoch(model, loader, optimizer, criterion, device):
"""训练一个epoch"""
model.train()
total_loss = 0.0
total_miou = 0.0
for images, masks in tqdm(loader, desc="Training"):
images = images.to(device)
masks = masks.to(device).long() # 掩码为类别ID,需转为long
# 前向传播
outputs = model(images)
loss = criterion(outputs, masks)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 计算指标
total_loss += loss.item() * images.size(0)
pred_masks = torch.argmax(outputs, dim=1)
miou = calculate_mIoU(pred_masks, masks, Config.NUM_CLASSES)
total_miou += miou * images.size(0)
# 计算平均损失和mIoU
avg_loss = total_loss / len(loader.dataset)
avg_miou = total_miou / len(loader.dataset)
return avg_loss, avg_miou
def val_one_epoch(model, loader, criterion, device):
"""验证一个epoch"""
model.eval()
total_loss = 0.0
total_miou = 0.0
with torch.no_grad():
for images, masks in tqdm(loader, desc="Validating"):
images = images.to(device)
masks = masks.to(device).long()
outputs = model(images)
loss = criterion(outputs, masks)
total_loss += loss.item() * images.size(0)
pred_masks = torch.argmax(outputs, dim=1)
miou = calculate_mIoU(pred_masks, masks, Config.NUM_CLASSES)
total_miou += miou * images.size(0)
avg_loss = total_loss / len(loader.dataset)
avg_miou = total_miou / len(loader.dataset)
return avg_loss, avg_miou
# ===================== 7. 结果可视化 =====================
def visualize_results(image, true_mask, pred_mask, class_names):
"""可视化输入影像、真实掩码、预测掩码"""
# 反归一化影像
image = image.cpu().squeeze().permute(1,2,0).numpy()
image = image * np.array([0.229, 0.224, 0.225]) + np.array([0.485, 0.456, 0.406])
image = np.clip(image, 0, 1)
# 转换掩码为彩色(方便可视化)
cmap = plt.cm.get_cmap('tab10', Config.NUM_CLASSES)
true_mask = true_mask.cpu().squeeze().numpy()
pred_mask = pred_mask.cpu().squeeze().numpy()
# 绘图
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
axes[0].imshow(image)
axes[0].set_title("Input Image")
axes[0].axis('off')
im1 = axes[1].imshow(true_mask, cmap=cmap, vmin=0, vmax=Config.NUM_CLASSES-1)
axes[1].set_title("True Mask")
axes[1].axis('off')
im2 = axes[2].imshow(pred_mask, cmap=cmap, vmin=0, vmax=Config.NUM_CLASSES-1)
axes[2].set_title("Predicted Mask")
axes[2].axis('off')
# 添加颜色条
cbar = fig.colorbar(im1, ax=axes, shrink=0.5, ticks=range(Config.NUM_CLASSES))
cbar.ax.set_yticklabels(class_names)
plt.tight_layout()
plt.savefig("results.png", dpi=300, bbox_inches='tight')
plt.show()
# ===================== 8. 单张影像推理 =====================
def predict_single_image(model, img_path, transform, device):
"""对单张遥感影像进行分割推理"""
model.eval()
# 读取并预处理影像
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
augmented = transform(image=image)
image_tensor = augmented["image"].unsqueeze(0).to(device)
# 推理
with torch.no_grad():
outputs = model(image_tensor)
pred_mask = torch.argmax(outputs, dim=1)
return image_tensor, pred_mask
# ===================== 9. 主训练流程 =====================
def main():
# 1. 加载数据集
train_transform, val_transform = get_transforms()
train_dataset = RemoteSensingDataset(Config.TRAIN_IMG_DIR, Config.TRAIN_MASK_DIR, train_transform)
val_dataset = RemoteSensingDataset(Config.VAL_IMG_DIR, Config.VAL_MASK_DIR, val_transform)
train_loader = DataLoader(train_dataset, batch_size=Config.BATCH_SIZE, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=Config.BATCH_SIZE, shuffle=False, num_workers=2)
# 2. 初始化模型、损失函数、优化器
model = UNet(n_channels=Config.IN_CHANNELS, n_classes=Config.NUM_CLASSES).to(Config.DEVICE)
criterion = nn.CrossEntropyLoss() # 多分类损失
optimizer = optim.Adam(model.parameters(), lr=Config.LEARNING_RATE)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=3) # 按mIoU调整学习率
# 3. 训练过程
best_miou = 0.0
early_stop_counter = 0
class_names = ["Background", "Building", "Road", "Farmland", "Water"] # 类别名称(根据你的数据集修改)
for epoch in range(Config.NUM_EPOCHS):
print(f"\nEpoch {epoch+1}/{Config.NUM_EPOCHS}")
print("-" * 50)
# 训练
train_loss, train_miou = train_one_epoch(model, train_loader, optimizer, criterion, Config.DEVICE)
# 验证
val_loss, val_miou = val_one_epoch(model, val_loader, criterion, Config.DEVICE)
# 学习率调整
scheduler.step(val_miou)
# 打印日志
print(f"Train Loss: {train_loss:.4f} | Train mIoU: {train_miou:.4f}")
print(f"Val Loss: {val_loss:.4f} | Val mIoU: {val_miou:.4f}")
# 保存最优模型
if val_miou > best_miou:
best_miou = val_miou
torch.save(model.state_dict(), Config.SAVE_MODEL_PATH)
print(f"Best model saved! Current best mIoU: {best_miou:.4f}")
early_stop_counter = 0
else:
early_stop_counter += 1
print(f"Early stop counter: {early_stop_counter}/{Config.EARLY_STOP_PATIENCE}")
# 早停
if early_stop_counter >= Config.EARLY_STOP_PATIENCE:
print("Early stopping!")
break
# 4. 加载最优模型并可视化结果
print("\nVisualizing results...")
model.load_state_dict(torch.load(Config.SAVE_MODEL_PATH))
# 取验证集第一张影像可视化
val_images, val_masks = next(iter(val_loader))
val_images = val_images.to(Config.DEVICE)
val_masks = val_masks.to(Config.DEVICE)
with torch.no_grad():
val_outputs = model(val_images)
val_pred_masks = torch.argmax(val_outputs, dim=1)
visualize_results(val_images[0], val_masks[0], val_pred_masks[0], class_names)
# 5. 单张影像推理示例
if os.path.exists(Config.TEST_IMG_PATH):
print("\nPredicting single test image...")
img_tensor, pred_mask = predict_single_image(model, Config.TEST_IMG_PATH, val_transform, Config.DEVICE)
visualize_results(img_tensor[0], torch.zeros_like(pred_mask[0]), pred_mask[0], class_names)
if __name__ == "__main__":
main()三、代码运行指南
3.1 前置准备
- 安装依赖(补充遥感影像处理库):
bash
pip install opencv-python albumentations torch torchvision matplotlib tqdm numpy pillow gdal # gdal用于读取.tif格式遥感影像- 数据集准备 :
- 按上述
remote_sensing_seg/data目录结构整理你的遥感影像和掩码; - 掩码要求:单通道图像,像素值为类别ID(如0=背景、1=建筑、2=道路、3=耕地、4=水体);
- 若没有标注数据,可先下载GID/ISPRS公开数据集,或用随机生成的示例数据测试代码运行流程。
- 按上述
3.2 关键参数修改
根据你的数据集调整Config类中的参数:
NUM_CLASSES:修改为你的分割类别数;BATCH_SIZE:根据显卡显存调整(1080Ti建议4-8,3090建议8-16);class_names:修改为你的类别名称(如"背景", "林地", "草地", "水体");TRAIN_IMG_DIR/VAL_IMG_DIR:确保路径指向你的数据集。
3.3 运行代码
bash
python main.py四、注意事项
- 遥感影像格式 :若你的影像为
.tif格式且包含地理信息,cv2.imread可能无法读取,需改用gdal库读取:
python
from osgeo import gdal
def read_tif_image(img_path):
ds = gdal.Open(img_path)
arr = ds.ReadAsArray()
arr = np.transpose(arr, (1,2,0)) # (C,H,W) → (H,W,C)
return arr- 类别不平衡处理 :若某类地物占比极低,可将损失函数替换为
DiceLoss或FocalLoss; - 模型优化 :若训练速度慢,可改用
UNet++/Attention U-Net,或用MobileNetV2作为编码器轻量化模型。
总结
关键点回顾
- 本项目核心模块:数据集类(适配遥感影像)+ U-Net模型 + mIoU评估 + 可视化,覆盖遥感分割全流程;
- 运行核心:需按指定目录结构整理数据集,调整
Config类参数适配你的数据; - 优化方向:针对遥感影像特点,可增加多光谱特征融合 、随机裁剪 (适配大尺寸遥感影像)、迁移学习(用ImageNet预训练权重初始化编码器)提升性能。
语义分割的训练样本核心是**「输入图像-像素级标注掩码(Mask)」的一一对应数据对**,目标是让模型学习"每个像素属于哪个类别"的映射关系。其结构和格式有明确的规范,具体如下:
一、 训练样本的基本构成
一套完整的语义分割训练样本包含两个核心文件,二者尺寸必须完全一致,像素位置一一对应:
-
原始输入图像
- 类型:通常是 RGB 三通道彩色图像,也可以是单通道灰度图(如工业探伤图、医学影像)。
- 内容:包含待分割的目标场景,比如自动驾驶的街景、医学的 CT 切片、工业领域的管道表面图像、燃气调压器部件图等。
- 格式:常见格式为 JPG、PNG、TIFF 等,需保证清晰度足以区分不同类别边界。
-
像素级标注掩码图(Label Mask)
这是语义分割样本的核心,是对原始图像的逐像素类别标注,有两种常见表现形式:
- 单通道灰度掩码(模型训练用)
掩码图为单通道图像,每个像素的灰度值对应一个类别 ID,类别 ID 通常从 0 开始连续编号。- 例:背景类别 ID = 0,管道本体 ID = 1,腐蚀缺陷 ID = 2,裂纹缺陷 ID = 3。
- 特点:数值无物理意义,仅代表类别索引,是模型训练时的直接监督信号。
- 伪彩色掩码(人工标注/可视化用)
为方便人工检查标注质量,会将单通道灰度掩码映射为彩色图像,不同类别对应不同颜色(如背景灰色、腐蚀红色、裂纹蓝色)。- 特点:仅用于人眼识别,训练前需转换回单通道灰度格式。
- 单通道灰度掩码(模型训练用)
二、 标注的核心规则
-
类别定义明确
需提前制定类别字典 ,明确每个类别 ID 对应的实际对象,且类别需相互独立、无重叠。
例:石油管道缺陷分割的类别字典
类别 ID 类别名称 0 背景 1 管道金属本体 2 腐蚀区域 3 裂纹区域 -
像素级一一对应
掩码图的每个像素必须与原始图像的同一位置像素属于同一类别,不允许错位、漏标或过标。
- 例:原始图像中坐标 (x=100, y=200) 的像素是腐蚀区域,掩码图同一坐标的像素值必须为 2。
-
边界标注精准
目标与背景的边缘需标注清晰,尤其是小目标(如细微裂纹)或模糊边界(如轻度腐蚀),否则会降低模型分割精度。
三、 不同领域的样本实例(含石油燃气工业场景)
| 应用领域 | 原始输入图像示例 | 掩码标注示例 |
|---|---|---|
| 石油管道缺陷检测 | 管道外壁的实拍图(含腐蚀、划痕、油污) | 灰度掩码:0=背景、1=管道本体、2=腐蚀区、3=划痕区 |
| 燃气调压器质检 | 调压器阀芯的高清图像(含磨损、变形) | 灰度掩码:0=背景、1=阀芯本体、2=磨损区、3=变形区 |
| 自动驾驶 | 车载摄像头拍摄的街景图 | 灰度掩码:0=背景、1=道路、2=车辆、3=行人 |
| 医学影像 | 肺部 CT 切片 | 灰度掩码:0=背景、1=正常肺组织、2=肿瘤区域 |
四、 特殊类型的训练样本
除了标准的强标注样本,实际训练中还会用到以下特殊样本:
- 弱标注样本
当像素级标注成本过高时,会用边界框、点标注等弱监督信号代替掩码,再通过算法生成伪掩码用于训练(如石油管道巡检的海量图像快速标注)。 - 数据增强后的样本
为提升模型泛化能力,会对原始样本进行翻转、裁剪、缩放、亮度调整等增强操作,同时对掩码图执行完全相同的变换,生成新的训练样本。
五、 样本存储与组织规范
训练样本通常按固定目录结构存放,方便模型读取,例:
dataset/
├── train/
│ ├── images/ # 训练集原始图像
│ │ ├── img_001.jpg
│ │ └── img_002.jpg
│ └── masks/ # 训练集掩码图
│ ├── img_001.png
│ └── img_002.png
└── val/ # 验证集(结构同训练集)语义分割的核心目标是像素级的类别划分 ,其关键问题围绕精度提升、数据效率、模型泛化、工程落地四大维度展开,这些问题在石油燃气等工业场景的落地中尤为突出。具体可分为以下6类核心问题:
1. 类别不平衡问题
这是语义分割最普遍且影响极大的问题。
- 表现 :图像中不同类别的像素占比差距悬殊,比如石油管道巡检图像中,管道本体、背景 等大类像素占比超90%,而腐蚀、裂纹等缺陷小目标像素占比不足1%。
- 影响:模型会偏向学习占比高的类别,导致小目标缺陷漏检、误检率大幅上升。
- 典型场景:燃气调压器磨损区域分割、油藏岩芯图像孔隙分割。
2. 边缘分割精度问题
语义分割的核心痛点之一是目标边缘的精准划分。
- 表现:目标与背景的边界像素(如管道腐蚀区和正常本体的交界、调压器阀芯磨损边缘)特征模糊,模型容易将边缘像素误判为背景或其他类别。
- 根源:卷积神经网络(CNN)的下采样操作会丢失边缘细节,而上采样的插值操作无法完全恢复精准边界;Transformer类模型虽能捕捉全局信息,但对细粒度边缘的建模能力仍不足。
- 工业影响:边缘误判会直接导致缺陷面积计算偏差,影响后续的风险等级评估。
3. 多尺度目标建模问题
同一幅图像中往往存在不同尺度的目标,模型难以同时兼顾大目标的完整性和小目标的检出率。
- 表现:比如在油气站场的俯瞰图像分割中,既有"储油罐"这类大尺度目标,也有"阀门、仪表"这类小尺度目标;模型若聚焦大目标,会丢失小目标细节;若聚焦小目标,会导致大目标分割不完整。
- 解决难点:多尺度特征融合需要平衡计算量和精度,过度融合会导致模型参数量暴增,不利于工业端部署。
4. 像素级标注成本高、效率低问题
语义分割依赖逐像素标注的掩码数据,这是其落地的核心瓶颈。
- 表现:人工标注一张工业图像的掩码图,耗时是目标检测框标注的5-10倍;复杂场景(如岩芯图像的孔隙、裂缝交织)的标注难度更高,且标注质量受人工经验影响大。
- 衍生问题:标注数据不足会导致模型过拟合,尤其在石油燃气的小众场景(如深海管道腐蚀)中,很难获取大规模标注样本。
- 应对思路:弱监督学习(用边界框、点标注代替像素标注)、半监督学习(利用未标注数据)、数据增强(生成伪标注样本)。
5. 模型泛化能力不足问题
模型在训练集上表现优异,但在真实工业场景中精度大幅下降。
- 表现:训练集的图像通常是实验室采集的标准样本(如干净的管道表面),而现场图像存在光照变化(如强光、阴影)、遮挡(如油污、杂物)、设备形变等干扰因素,导致模型"认不出"真实目标。
- 典型案例:实验室标注的调压器阀芯图像,模型分割精度达95%;但现场拍摄的带油污阀芯图像,精度可能降至60%以下。
6. 模型轻量化与实时性矛盾问题
工业场景(如管道巡检机器人、无人机实时监测)对模型推理速度有严格要求,但高精度语义分割模型通常参数量大、计算耗时。
- 矛盾点:主流的高精度模型(如DeepLab系列、HRNet)参数量达千万级,在嵌入式设备上推理速度不足5帧/秒;而轻量化模型(如MobileNet+U-Net)虽速度快,但精度会损失10%-20%。
- 核心需求:需要在精度和速度之间找到最优平衡点,满足工业实时检测的要求。
针对石油燃气领域语义分割的6大关键问题,结合工业场景的实际需求(如管道缺陷检测、调压器质检、油藏岩芯分析等),以下是针对性的落地解决方案:
1. 类别不平衡问题(缺陷小目标 vs 背景/设备本体)
核心痛点 :石油管道腐蚀、调压器磨损等缺陷像素占比极低(通常<1%),模型易偏向背景/设备本体。
针对性方案
- 采样策略优化
- 过采样小目标样本 :对含腐蚀、裂纹的缺陷图像进行复制、旋转、裁剪等增强,提升缺陷样本在训练集中的占比;采用随机裁剪+缺陷区域锚定,确保裁剪后的子图至少包含一个缺陷目标。
- 欠采样大类样本:对背景、管道本体等占比高的样本进行随机抽样,避免大类样本主导梯度更新。
- 损失函数改进
- 用 Focal Loss 替代交叉熵损失:降低易分类样本(背景/本体)的权重,提升难分类样本(小缺陷)的梯度贡献。
- 引入 Dice Loss 或 IoU Loss:直接优化分割结果的重叠度,适合像素占比悬殊的工业场景,尤其适用于油藏岩芯孔隙、裂缝的分割。
- 硬样本挖掘
训练过程中动态筛选难分样本(如模糊的轻度腐蚀、细微裂纹),单独构建难分样本集进行迭代微调,强化模型对小缺陷的识别能力。
2. 边缘分割精度问题(缺陷边界模糊、边缘误判)
核心痛点 :腐蚀区与管道本体的交界、阀芯磨损边缘特征模糊,边缘误判会导致缺陷面积计算偏差,影响风险评估。
针对性方案
- 边缘增强双分支训练
- 构建"分割分支 + 边缘检测分支"的多任务模型:分割分支负责像素分类,边缘分支专门学习缺陷边界的梯度特征(如用Canny边缘检测结果作为监督信号),两个分支共享骨干网络特征,互相促进。
- 示例:在管道腐蚀分割中,边缘分支引导模型聚焦腐蚀区的轮廓,减少边缘像素的误分类。
- 高分辨率特征融合
- 采用 HRNet 作为骨干网络:全程保持高分辨率特征图,避免传统下采样-上采样过程中的边缘细节丢失;相比U-Net,更适合工业小缺陷的边缘精准分割。
- 后处理边界细化
- 分割结果后接 条件随机场(CRF):利用像素间的上下文关系优化边缘,平滑分割结果,修正孤立的误判像素;该方法计算量小,适合工业部署。
3. 多尺度目标建模问题(大目标如储油罐 vs 小目标如阀门/仪表)
核心痛点 :油气站场俯瞰图中,储油罐、管道等大目标与阀门、仪表等小目标共存,模型难以兼顾两者的分割精度。
针对性方案
- 多尺度输入与特征金字塔(FPN)
- 多尺度训练:将图像缩放到不同尺寸(如 512×512、1024×1024)输入模型,让模型适应不同尺度的目标;推理时采用多尺度融合预测,提升小目标的检出率。
- 特征金字塔融合:在骨干网络的不同层级提取特征(浅层特征对应小目标细节,深层特征对应大目标语义),通过FPN将多尺度特征加权融合,兼顾大/小目标的分割需求。
- 场景先验知识约束
- 结合石油燃气场景的目标尺寸先验:比如阀门的像素尺寸通常在 20×20~50×50 之间,在模型中加入尺寸约束层,过滤超出合理范围的预测框/区域,减少小目标的误检。
- 空间注意力机制
- 在特征融合阶段引入 空间注意力模块:让模型自动聚焦小目标区域(如阀门、仪表),抑制背景干扰;例如使用CBAM注意力模块,增强小目标的特征响应。
4. 像素级标注成本高、效率低问题
核心痛点 :工业图像像素级标注耗时是目标检测的5-10倍,且深海管道、极端工况样本稀缺,标注难度大。
针对性方案
- 弱监督/半监督学习
- 弱监督标注 :用边界框标注替代像素级掩码------通过算法(如GrabCut、种子点扩散)将边界框转换为伪掩码,再结合少量人工修正,标注效率提升5-8倍;适合大规模管道巡检图像的快速标注。
- 半监督训练:利用大量未标注的工业图像(如正常管道表面、无缺陷调压器)进行自监督预训练(如对比学习),再用少量标注样本微调,大幅降低标注成本。
- 迁移学习+领域适配
- 用公开数据集(如Cityscapes、VOC)预训练模型骨干网络,再用石油燃气领域的小样本进行微调;预训练模型已学习到通用的边缘、纹理特征,可显著提升小样本场景下的分割精度。
- 针对跨域问题(如实验室干净样本 vs 现场油污样本),采用域自适应(Domain Adaptation) 方法,对齐源域(标注样本)和目标域(未标注现场样本)的特征分布。
- 自动化标注工具链
- 搭建"传统算法初标 + 人工修正"的工具链:例如用阈值分割、边缘检测等传统方法生成初步掩码,人工仅需修正错误区域;推荐使用LabelMe、CVAT等工具,并开发行业专属的标注插件(如管道缺陷类别快捷标注)。
5. 模型泛化能力不足问题(实验室样本 vs 现场复杂场景)
核心痛点 :实验室采集的干净样本与现场图像差异大(光照变化、油污遮挡、设备形变),导致模型现场精度骤降。
针对性方案
- 工业场景专属数据增强
- 模拟现场干扰因素,生成鲁棒性训练样本:
- 光照增强:随机调整亮度、对比度、色温,模拟晴天/阴天/夜间的巡检环境;
- 污染模拟:添加油污、灰尘、水渍等噪声,贴合管道、调压器的现场状态;
- 遮挡增强:随机添加杂物、管道保温层等遮挡物,提升模型对遮挡缺陷的识别能力。
- 模拟现场干扰因素,生成鲁棒性训练样本:
- 鲁棒性训练策略
- 加入对抗训练:在输入图像中添加微小扰动,让模型学习抗干扰的特征,提升对现场噪声的容忍度;
- 混合数据训练:将实验室样本与现场样本按1:3的比例混合训练,强制模型适应现场数据分布。
- 少量现场样本微调
采集10-20张典型现场样本进行标注,用预训练模型进行小批量微调(学习率降低至1e-5),快速适配现场场景,这是工业落地的"性价比最高"方案。
6. 轻量化与实时性矛盾问题(嵌入式设备部署需求)
核心痛点 :高精度模型(如DeepLabv3+、HRNet)参数量大,无法在管道巡检机器人、无人机等嵌入式设备上实时推理。
针对性方案
- 轻量化模型架构设计
- 替换骨干网络:用 MobileNetv3、ShuffleNetv2 等轻量化网络替代ResNet,参数量可降低70%以上;例如构建"MobileNetv3 + U-Net"的轻量分割模型,适合嵌入式设备。
- 模型剪枝与量化:
- 剪枝:裁剪冗余的卷积通道(如用L1正则化筛选重要通道),去除对分割精度贡献小的层;
- 量化:将模型权重从32位浮点型(FP32)转换为16位(FP16)或8位(INT8),推理速度提升2-4倍,精度损失可控制在2%以内。
- 知识蒸馏
- 用高精度模型(如HRNet)作为教师模型 ,轻量模型作为学生模型:让学生模型学习教师模型的输出概率分布和中间层特征,在几乎不损失精度的前提下,实现模型轻量化;适合无人机实时巡检场景。
- 推理加速优化
- 利用 TensorRT、ONNX Runtime 等工具进行模型优化:融合卷积、BN、激活等算子,减少推理时的内存访问次数;在NVIDIA Jetson系列嵌入式设备上,可将推理速度提升至10帧/秒以上,满足实时检测需求。
- 区域聚焦推理
- 先通过目标检测模型定位疑似缺陷区域(如管道的腐蚀疑点),再对该区域进行语义分割,而非对整幅图像分割;可大幅减少计算量,提升推理效率。