文章目录
- [类人脑的另一种计算 ------大语言模型large-lauguage-model](#类人脑的另一种计算 ——大语言模型large-lauguage-model)
类人脑的另一种计算 ------大语言模型large-lauguage-model
我们的大致计划是分享一下我对大模型的理解,知己知彼,百战不殆,了解大模型才能更好的使用大模型
此次分享大模型将会由外向内的去挖掘大模型,把它像一个洋葱一样一层层剥开,并且是带着问题的去寻找答案,最后理解大模型
第一章节:主要看表层现象解析原理
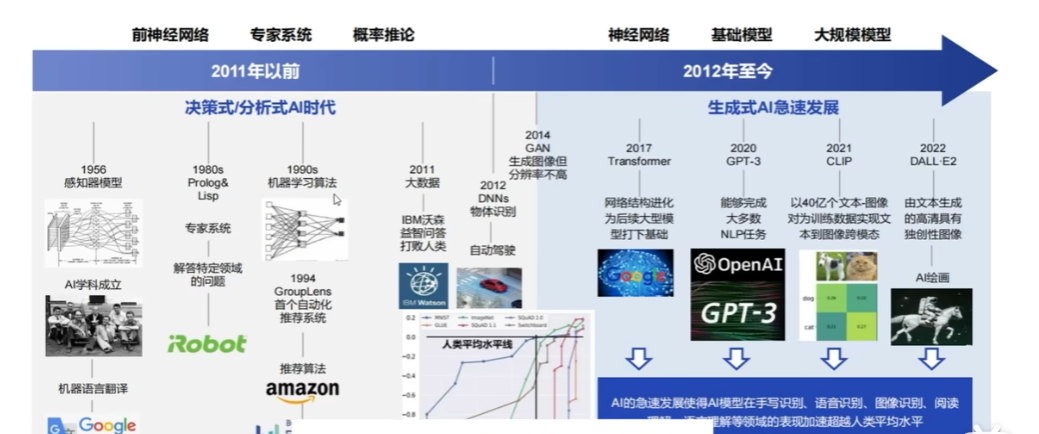
一、历史背景:大语言模型的发展历程
20 世纪 50 年代 - 21 世纪初
- 图灵测试确立智能评判标准;LR 等统计模型让语言建模可量化;MLP 奠定 "多层网络 + 激活函数" 基础架构;RNN 首次实现序列数据 "记忆" 建模。
- 思想升华:从 "人工写规则" 到 "用数据学统计规律",明确语言建模需靠数据而非纯人工。
2010-2016
- FM/FFM 解决稀疏数据特征交互难题;LSTM 攻克 RNN 梯度消失问题,提升长文本处理能力;GPU 普及让深度网络大规模训练成为可能。
- 思想升华:从 "孤立处理单个语言单元" 到 "捕捉时序依赖和特征关联",意识到语言的核心是上下文逻辑。
2017-2019
- 2017 年 Transformer 提出,用自注意力机制替代 RNN,实现并行计算 + 长距离语义捕捉;2018 年 GPT 确立 "预训练 + 微调" 范式,结束 "一个任务一个模型" 的低效时代。
- 思想升华:从 "专用模型" 到 "通用预训练",发现模型可通过海量数据学习通用语言逻辑,再适配具体场景。
2020 - 至今
- GPT-3(1750 亿参数)验证 "规模即能力";ChatGPT 用 RLHF 技术实现人机对齐;算力 / 开源生态成熟推动模型落地;多模态、智能体拓展应用边界。
- 思想升华:从 "追求性能" 到 "适配人类需求",大模型从 "语言工具" 升级为 "协同人类完成复杂任务的智能基础设施"。
二、梦开始的地方
2022年11月30号Open AI发布第一款ai产品叫chat GPT,两个月不到达到用户日活量2亿,打破了tiktok的九个月记录,这是大多数人第一次接触ai大模型
自此大模型便开启了一个新的赛道,无数天才涌入
三、初相识:什么才叫做模型?
先说答案:根据已知的数据(维基百科、书籍、论文等),把这些数据分类并计算出规律,从而给未知的数据做出预测,这种规律被称之为模型。
比如说这个模型把百科全书给吃透了,现在我说中华人民 ,这个模型就猜出来我大概是要说中华人民共和国 了,当我说中华人民共和国时他就有可能会说
中华人民共和国成立于1949年...

而大语言模型最初就是一个智能聊天助手,功能就是能像人类一样对话,ai大模型正是吃了很多语言数据然后计算出规律。
自然语言是文明延续和发展的关键桥梁,从生命源起开始计算,大脑经历了数以万年的精妙计算,它是人类用来探索世界、交流思想的基石
人脑平均860亿神经元,每个神经元与数千个神经元相互连接想成约100万亿个突触,神经元与突触构成复杂网络,才共同造就了我们卓越的认知和表达能力
机器学习正是模仿这种智慧的尝试,研究计算机给定算法,判断如何从给定的数据中计算出规律,从而给未知的数据做出预测,
而这种规律被称为模型
四、谈心扉:模型怎么找到这种规律的?这个规律一劳永逸吗?
模型怎么找出这种规律的,我们需要在之后循序渐进的去了解,待第二章节了解
先回答是否一劳永逸
当然不,模型中规律是 "概率性" 的,不是 "确定性" 的,只有概率性的能被称作为生成式AI。ai每次判断下一个词都是概率性事件,所以也说ai有时候也会"犯糊涂"
数据在变,规律也会 "过时":新数据产生的速度非常快,每年出现的名词也很多,比如(yyds、包的。。。)
模型的规律会 "遗忘",需要持续优化 :模型的规律存在于参数矩阵 里(比如 GPT-3 有 1750 亿个参数),但如果只训练一次,遇到新数据时,旧参数会被 "覆盖"(这叫灾难性遗忘)。
五、寻根源:什么是生成式AI?AI分哪几种?
在大语言模型出现以前市面上只有决策式、分析式
AI分决策式/分析式 以及 生成式
决策式主要是根据以往的信息进行分析,主要是智能推荐、风控辅助决策等等。
比如房价(根据过去一两年房价数据判断影响房价的因素输出一个模型用来分析预测未来的房价,咱们的风控团队也是用以往的贷款数据判断用户是否会还款的各种因素(信用、工作、家庭、imss、cep等)来分析一个人是否借钱会还)
生成式ai是学习归纳已有数据以后,进行一个创造,一般是基于历史的数据,进行一个模仿和学习 ,通过缝合式创作可以生成一个全新的一个内容。也可做出一定的判断和决策,这样生成式ai更符合人类理想中的智能化形态。
"缝合式"是形象比喻,指生成式AI学习海量数据中的统计规律与内容模式后,将不同数据里的元素、句式、风格等进行复杂重组拼接,而非真正理解内容后创作。而缝合式创造生成的"新东西",就是经这种重组形成的文本、图像等内容,比如AI写秋天的散文,是拼接"秋风""落叶"等高频关联的优美句式;AI画古风人物,是融 合训练数据中古风的服饰、线条等元素形成新画面。
六、探真心:到底什么是生成式ai?
人类的智能不仅包括 "分析判断"(如根据经验判断一件事的结果),更包括 "创造表达"(如根据判断写一份报告、设计一个方案)
例子:
- 分析型风控 AI:输出 "用户 B 风险等级高";
- 生成式风控 AI:输出 "用户 B 风险等级高,原因如下:1. 近 6 个月 IMSS 缴费中断 2 次,显示收入稳定性不足;2. 过往 CEP 记录存在 3 次逾期,信用历史较差;3. 家庭负债比超过 50%,还款能力承压。建议:拒绝授信或要求提供额外担保。"
详情看以下三个问题便深入理解
为什么gpt生成内容时是一个词一个词的往外蹦的?
好像真的有个人在屏幕那边在打字回答你一样
其实是通过WebSocket或SEE的流式消息,保持keep-alive,用户的输入发送给服务器,服务器会动态的响应,前端进行拼接逐步将内容更新并传回给客户端
 ai大模型是一个一个词出现然后进行拼接的,大模型就是根据上下文进行推理
ai大模型是一个一个词出现然后进行拼接的,大模型就是根据上下文进行推理

但实际AI大模型不是真的用汉字来推理的,具体要把汉字转换为token,比如你问ai,今天天气怎么样?
web会把"今天天气怎么样?"以及用户提问的部分prompt提示词,web端将他们拼接在一起发送到服务端,此时ai会把这些提示词以及"今天天气怎么样?"一起转换成AI能听到的'机器话'("<|system|>你是一个友好的天气助手,用简洁语言回答问题<|user|>天气怎么样?<|assistant|>"),也就是token,之后根据token来进行推理之后的话。
那就必须要设计成一次只推理一个或者两个字吗?
就不能ai一次性想出来一句话给返回给前端,这样还能省点带宽。
原因如下
- 自回归机制
大多数大模型(比如GPT系列、文心一言)都是"自回归语言模型"。
生成一个词后,把这个词加回输入,再生成下一个词,循环往复,直到结束。
模型怎么判断下一个词该用"晴朗"而不是"晴天"?
- 概率预测与采样:决定内容"保守"还是"发散"
-
温度(Temperature) :控制随机性。温度越低,模型越倾向于选概率高的词,内容越保守、稳定;温度越高,模型越可能选概率低的词,内容越发散、有创意。比如温度0.1 时,模型可能一直输出"人工智能的未来在于与人类协同";温度1.5时,它可能输出"人工智能的未来在于与星辰对话"。
-
Top-k:只从概率最高的k个词中选。比如k=5,模型就只从概率前5的词里选,避免选到奇怪的词。
-
Top-p:累积概率达到p的词中选。比如p=0.9,模型会把词按概率从高到低排,选到累积概率达到90%的词为止,既保证多样性,又避免离谱。
- 流式返回:前端"拼接"出的逐字效果
这里还有个小知识点:我们在前端看到的"逐字蹦出",不全是模型的功劳,还有工程化的优化。模型生成第一个词后,服务端会通过WebSocket或SSE(服务器推送事件)技术,把这个词立刻推给前端;同时模型继续生成第二个词,生成后再推给前端,前端把这些词拼接起来,就形成了"逐字显示"的效果。
为什么要这么做?因为生成一段长文本可能需要几秒,如果等模型生成完所有内容再推给前端,用户会觉得"卡了";而流式返回能让用户立刻看到反馈,体验更好。
为什么AI大模型会出现幻觉呢?
有时候问它问题它就一本正经的回答毫不相干的答案,相信大家都有经历
这个具体问题就可以理解为当AI使用token进行推理的过程中下一个词是概率性选择,而这个概率性怎么选还是要看之后的ai如何理解token也就是怎么理解人类语言。
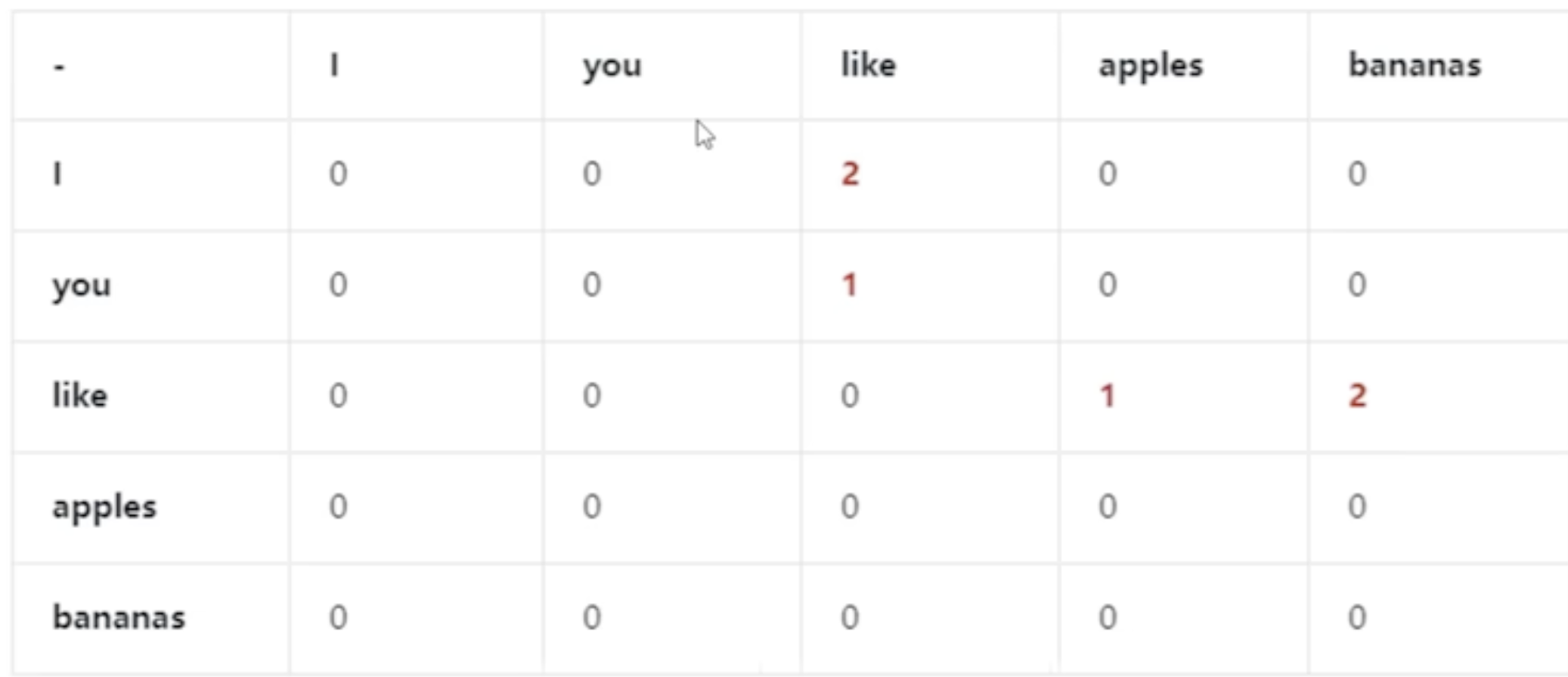
大模型是根据每对token在训练模型中出现多少次,然后可以计算每一个token跟随另一个token的概率,
比如数据组
i like apples
i like bananas
you like bananas
数据库存储
但是说白了,AI 大模型产生幻觉,核心就一个事儿:它不是 "真懂",只是靠概率选下一个词(token),就像你玩接龙,只看哪个词接上去顺嘴,不管对不对,再加上几个坑,错就错到底了:
-
选词只看 "顺不顺",不看 "对不对"
AI 每说一个字,都是从一堆候选里挑概率最高的 ------ 比如 "北京" 后面接 "首都" 概率最高,它就选,但如果训练时混进了 "南京是中国首都" 的错信息,它也可能觉得 "南京" 接 "首都" 顺嘴,直接瞎说。
-
一步错,步步错
只要第一个错词选出去,后面所有词都得基于这个错的来接,就像接龙接错了,后面越接越偏,最后编出一整套离谱但通顺的话。
-
脑子 "记不住" 或 "没学过"
要么是训练时没见过相关知识(比如问 2025 年新政策,它只学到 2024 年),要么是问题太长,前面的关键信息忘了,只能瞎编凑数。
-
为了 "讨好你" 瞎编
AI 被训练成 "说话要流畅、合你心意",哪怕内容是错的,只要说得顺、你可能爱听,它就优先选这些词,比如你问 "某偏方能治病不",它可能不说 "没用",反而编一堆 "有效" 的理由。
比如:
你问:世界上最好的编程语言是什么?
拆成token:世界上/最好的/编程语言/是/什么
查概率库:Python/Java/XXX语言(虚构)都有概率
概率库有坑:营销软文里XXX语言和"最好"绑定
选错误token:XXX语言
基于XXX语言继续选词:诞生于2020年→谷歌开发→80%企业在用
输出完整幻觉回答
七、话崛起:为什么AI大模型在2022年才爆发?一场迟到的"完美风暴"
简单说,这不是一个偶然,而是一场因核心算法、算力、数据与资本 四大条件在特定时间点汇聚而成的"完美风暴"。在此之前,不是没人想做,而是真的"做不了",没人给它撑腰。
- "心脏"未就位:直到2017年,Transformer架构才提供了一套高效处理序列数据的机制。
- "身体"太孱弱:在A100/H100这类专业GPU大规模普及之前,算力基础不存在。
- "燃料"成本天文数字:数千万美元的训练成本,让绝大多数企业和研究机构望而却步。
一、硬件与算力:从"做不到"到"有可能"
- GPU性能与成本:大模型训练需要海量并行计算,早期GPU算力不足,且堆叠成千上万张GPU的成本极高,企业和研究机构难以承担。
- 专用芯片与云计算:随着英伟达等公司持续推出高性能GPU(如V100、A100),以及云服务商(如AWS、Google Cloud)提供大规模算力租赁,降低了训练门槛。
- 算力需求指数级增长:2018年GPT-1的参数仅1.5亿,而2022年GPT-3达到1750亿。这种规模的计算在十年前是不可想象的。
二、NLP:为计算机安装"语言大脑"
NLP(自然语言处理)的目标是为计算机赋予理解和运用人类语言的能力。
传统软件与"智能"无关,其行为完全由程序员预设的"if-else"规则驱动,本质是复杂的条件判断。而当今的大模型却展现出真正的语义理解能力,是真正能够解析"用毒毒毒蛇毒蛇会不会被毒毒死"这种复杂歧义句。
这一质变的核心驱动力,是2017年Google在《Attention Is All You Need》论文中提出的Transformer架构。它如同大模型的"心脏",通过"自注意力"机制,解决了传统RNN、LSTM处理长序列数据时的梯度消失和计算效率低下的问题。让计算机能像人一样权衡上下文所有词语的关系,从而真正"读懂"语言,而非机械执行指令。正是它的出现,让NLP从"死板执行"迈向了"灵活理解"的新纪元。
三、数据量的积累与质变
- 互联网数据爆炸:过去十年,互联网文本、图像、视频数据量呈指数增长,为模型训练提供了充足的"燃料"。
- 数据清洗与处理技术:大模型需要高质量、多样化的数据。近年来,数据去噪、标注和多模态融合技术的进步,提升了数据可用性。