这是当前企业落地大模型最主流、最实用的技术栈------让模型基于你的私有知识(文档、数据库、代码库等)回答问题,而不是胡编乱造("幻觉")。
核心目标
让大模型"知道"你公司的数据,并能准确引用、解释、总结。
典型场景:
- 智能客服:回答产品手册中的问题
- 企业知识库:问"去年 Q3 营收是多少?"
- 技术支持:根据内部 Wiki 解决报错
- 合同审查:比对条款与历史案例
一、核心知识体系
| 模块 | 关键技术点 |
|---|---|
| 1. 文档预处理 | - PDF/Word/Excel 解析 - 分段策略(按句、按语义、按标题) - 清洗噪声(页眉页脚、广告) |
| 2. 向量嵌入(Embedding) | - 选择 Embedding 模型(text-embedding-3, BGE, m3e) - 中文优化 - 批量编码 |
| 3. 向量数据库 | - Milvus / Pinecone / Weaviate / Qdrant - 索引类型(HNSW, IVF) - 相似度度量(Cosine, L2) |
| 4. 检索策略 | - 简单向量检索 - 多路召回(关键词 + 向量) - 查询改写(Query Expansion) - 重排序(Rerank) |
| 5. Prompt 工程 | - 将检索结果注入 Prompt - 引用溯源("根据文档第3页...") - 拒绝回答(当检索不到时) |
| 6. 评估与优化 | - Hit Rate / Recall@k - 幻觉检测 - A/B 测试 |
💡 RAG ≠ "把文档切一切 + 存向量 + 查一查"
真正的难点在:如何让检索结果"刚好"包含回答所需信息?
二、学习路径(分阶段实战)
阶段 1:搭建最简 RAG(1-2 天)
目标:跑通 end-to-end 流程
向量化 ->向量数据库->Top K 相关片段->拼接到 Prompt->大模型生成答案
🛠️技术栈(推荐):
- Embedding 模型:
text-embedding-3-small(OpenAI)或BAAI/bge-small-zh-v1.5(开源中文) - 向量库:ChromaDB(轻量,适合本地开发)
- LLM:OpenAI / 通义千问 / DeepSeek
- 框架:LangChain 或 LlamaIndex
教程推荐:
- 官方:LangChain RAG 快速入门
- 中文实战:《手把手教你搭建 RAG 系统》
✍️ 动手项目:
用公司产品手册 PDF 做一个问答机器人:
python
1# 伪代码
2docs = load_pdf("product_manual.pdf")
3splits = RecursiveCharacterTextSplitter(...).split(docs)
4vectorstore = Chroma.from_documents(splits, embedding_model)
5retriever = vectorstore.as_retriever()
6
7qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever)
8answer = qa_chain.invoke("如何重置密码?")阶段 2:优化检索质量
关键问题:
- 切得太碎 → 丢失上下文
- 切得太长 → 噪声太多
- 用户问"怎么收费",但文档写的是"资费标准"
🔧 优化手段:
| 技术 | 作用 | 工具 |
|---|---|---|
| 语义分段 | 按句子边界 + 语义连贯性切分 | semantic-chunkers, LangChain MarkdownHeaderTextSplitter |
| 查询改写 | 把"怎么收费" → "资费标准 定价" | 使用 LLM 生成同义查询 |
| 多路召回 | 向量 + 关键词(BM25)融合 | LlamaIndex Hybrid Search |
| 重排序(Rerank) | 对 Top 50 结果精排 | BGE-Reranker, Cohere Rerank |
动手实验:
对比三种分段策略对回答准确率的影响:
- 固定 500 字符
- 按段落(
\n\n) - 语义分段(使用
nltk句子分割 + 滑动窗口)
🌳 阶段 3:生产级 RAG 架构(1-2 周)
企业级需求:
- 支持 100+ 万文档
- 响应时间 < 2 秒
- 支持更新/删除文档
- 可追溯答案来源
推荐架构:
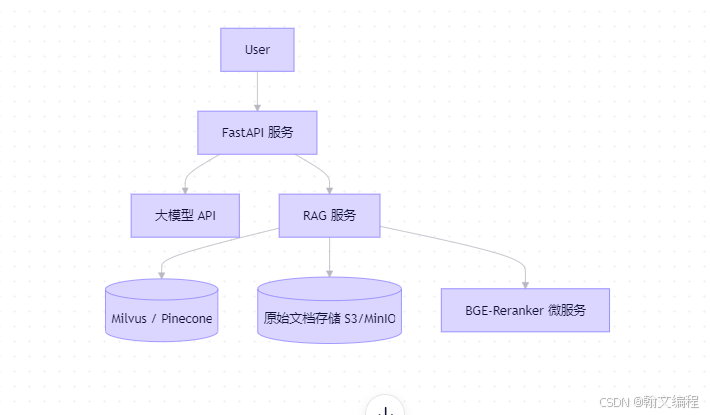
关键组件:
- 向量数据库 :用 Milvus (开源)或 Pinecone(托管)
- 缓存:Redis 缓存高频问题
- 监控:记录 query、retrieved chunks、answer
- 评估 pipeline:定期用测试集评估 Recall@5
动手项目:
用 LlamaIndex + Milvus 搭建可扩展 RAG:
- 支持增量更新文档
- 返回答案时附带"参考来源"(文件名 + 片段)
- 加入 reranker 提升排序质量
阶段 4:高级技巧(持续提升)
| 技术 | 说明 |
|---|---|
| HyDE(Hypothetical Document Embeddings) | 让 LLM 先生成"假设答案",再用它去检索 |
| 子查询(Sub-queries) | 把复杂问题拆成多个简单问题分别检索 |
| 图 RAG(Graph RAG) | 构建知识图谱,支持关系推理(微软提出) |
| 微调 Embedding 模型 | 在你的领域数据上微调,提升相关性 |
推荐论文:
- 《RAG vs Fine-tuning》
- 《Graph RAG: Unlocking LLMs' Potential for Enterprise Knowledge》
三、如何验证"真正掌握"?
完成以下任意一项,说明你已达到 工业级 RAG 开发能力:
能独立实现:
- 一个支持 PDF/Word 的 RAG 系统
- 检索 Recall@5 > 80%(在自建测试集上)
- 答案附带可点击的原文引用
- 支持文档更新后自动同步向量库
能解释清楚:
- 为什么 BM25 + 向量检索比纯向量更好?
- Reranker 为什么能提升效果?
- 如何防止"检索到错误文档但模型强行编答案"?
四、避坑指南
| 坑 | 正确做法 |
|---|---|
| 直接用默认分段 | 根据文档类型定制分段策略 |
| 只看 top-1 结果 | 至少取 top-3~5,让模型综合判断 |
| 忽略评估 | 建立测试集,定期量化效果 |
| 用免费向量库跑生产 | 百万级文档必须用 Milvus/Pinecone |