通用的拆分思路:
-
首先,按照机器学习的主要工作流程(数据处理、训练、评估等)将代码分离到不同的 `.py` 文件中。这是最基本也是最有价值的一步。
-
然后,创建一个 `utils.py` 来存放通用的辅助函数。
-
考虑将所有配置参数集中到一个 `config.py` 文件中。
-
为你的数据和模型产出物创建专门的顶层目录,如 `data/` 和 `models/`,将它们与你的源代码(通常放在 `src/` 目录)分开。
当遵循这些通用的拆分思路和原则时,项目结构自然会变得清晰。
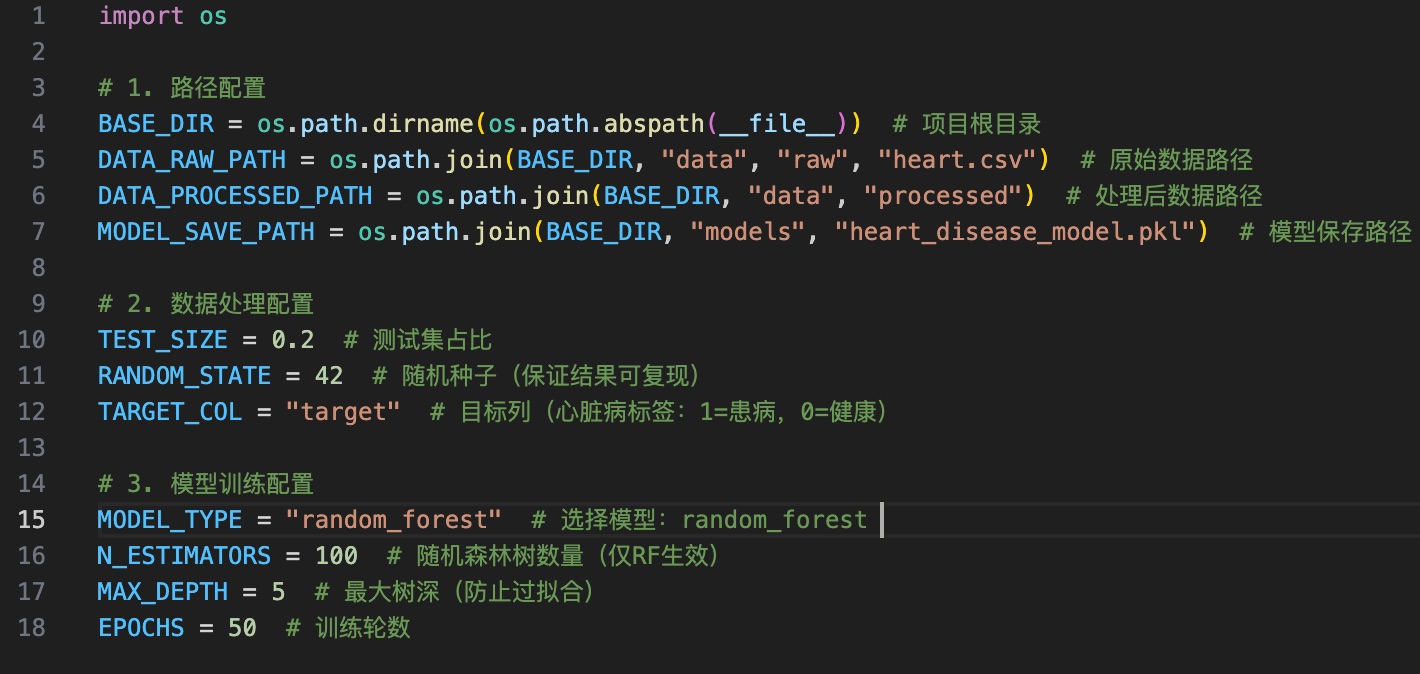
一、config.py(集中配置文件)
用于管理所有参数,后续调整只需修改此文件,无需改动核心代码。
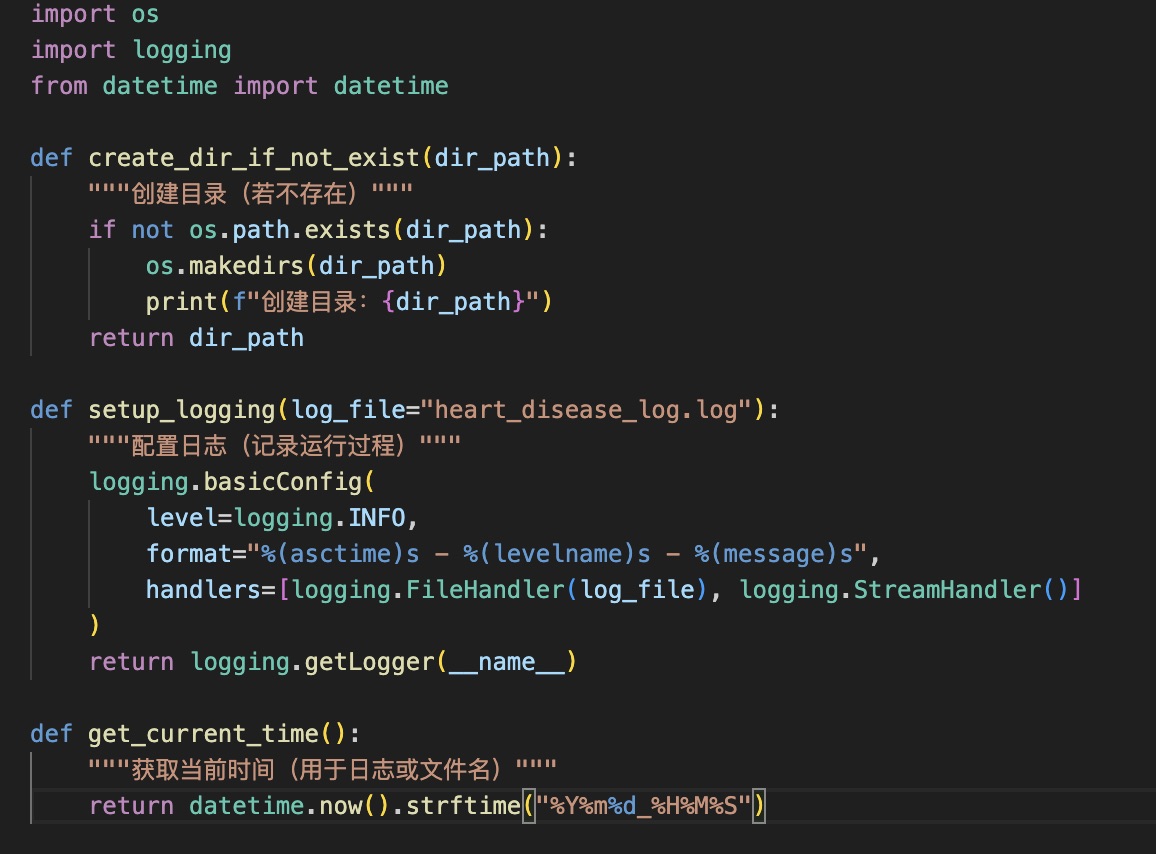
二、src/utils.py(通用辅助函数)
存放全项目复用的工具代码,如路径创建、日志打印。
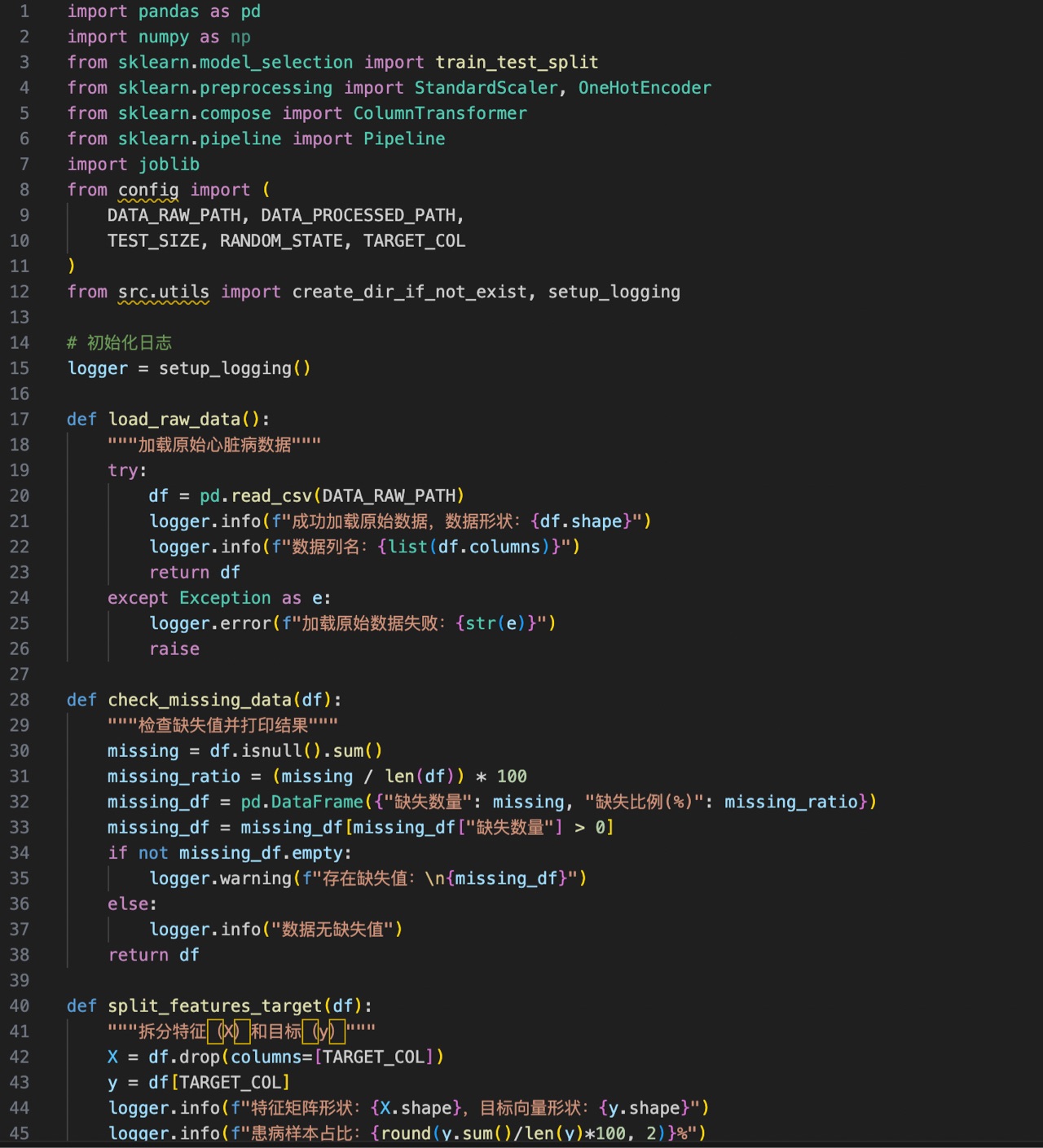
三、src/data/data_processing.py(数据处理)
负责数据加载、清洗、特征工程,输出可直接用于训练的数据。
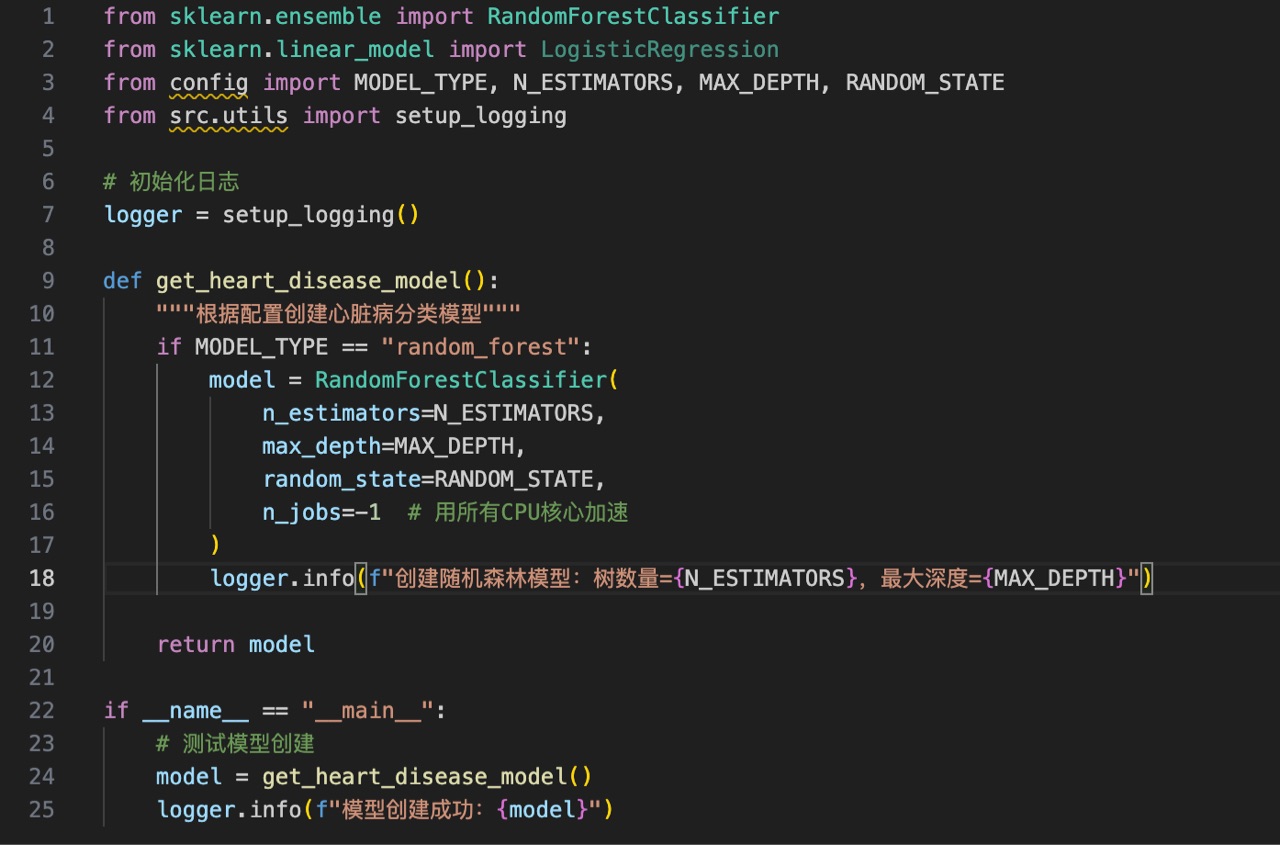
四、src/model/model_definition.py(模型定义)
创建可切换的分类模型,适配二分类任务。
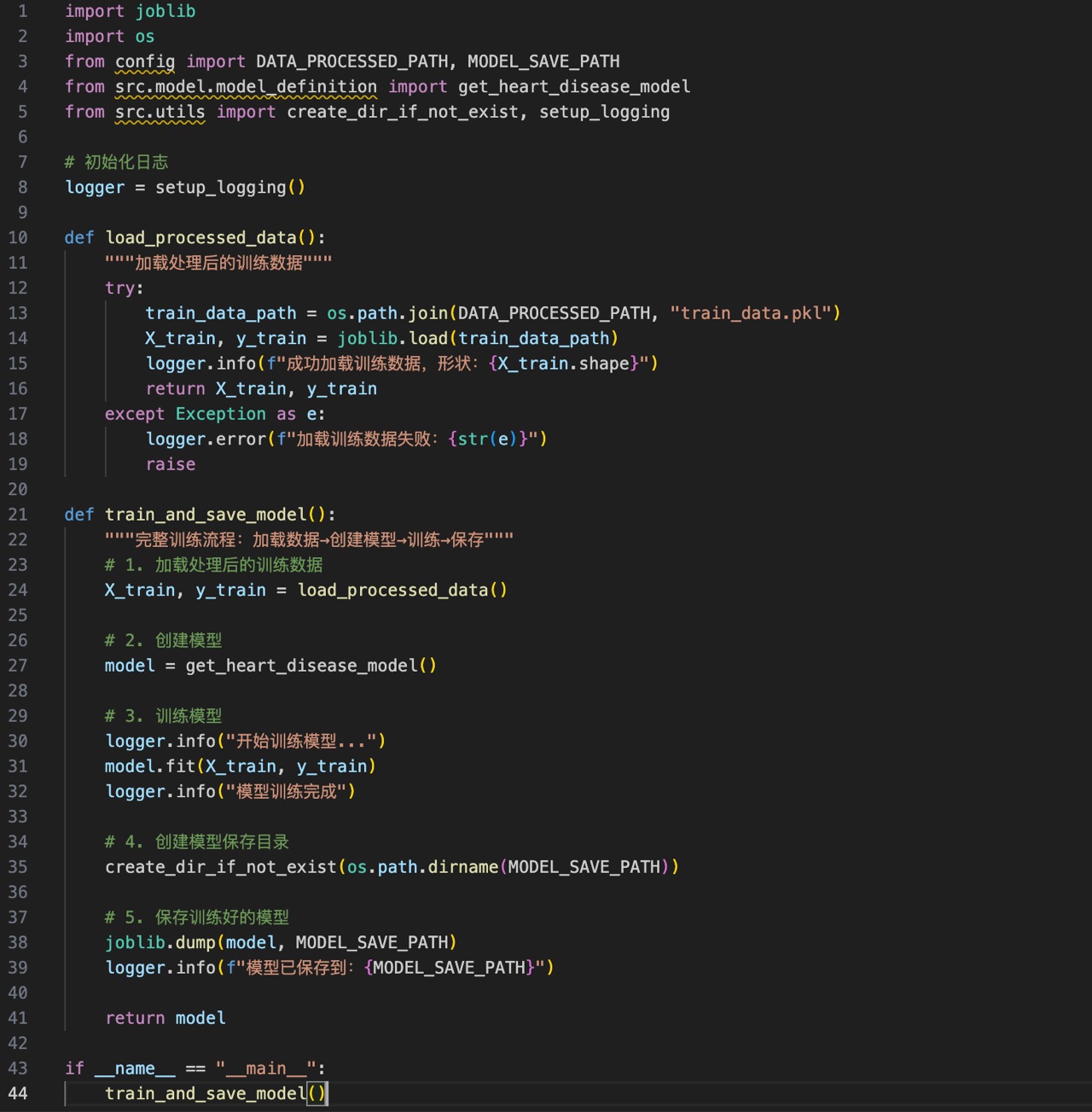
五、src/train/trainer.py(模型训练)
加载处理后的数据和模型,执行训练并保存模型文件。
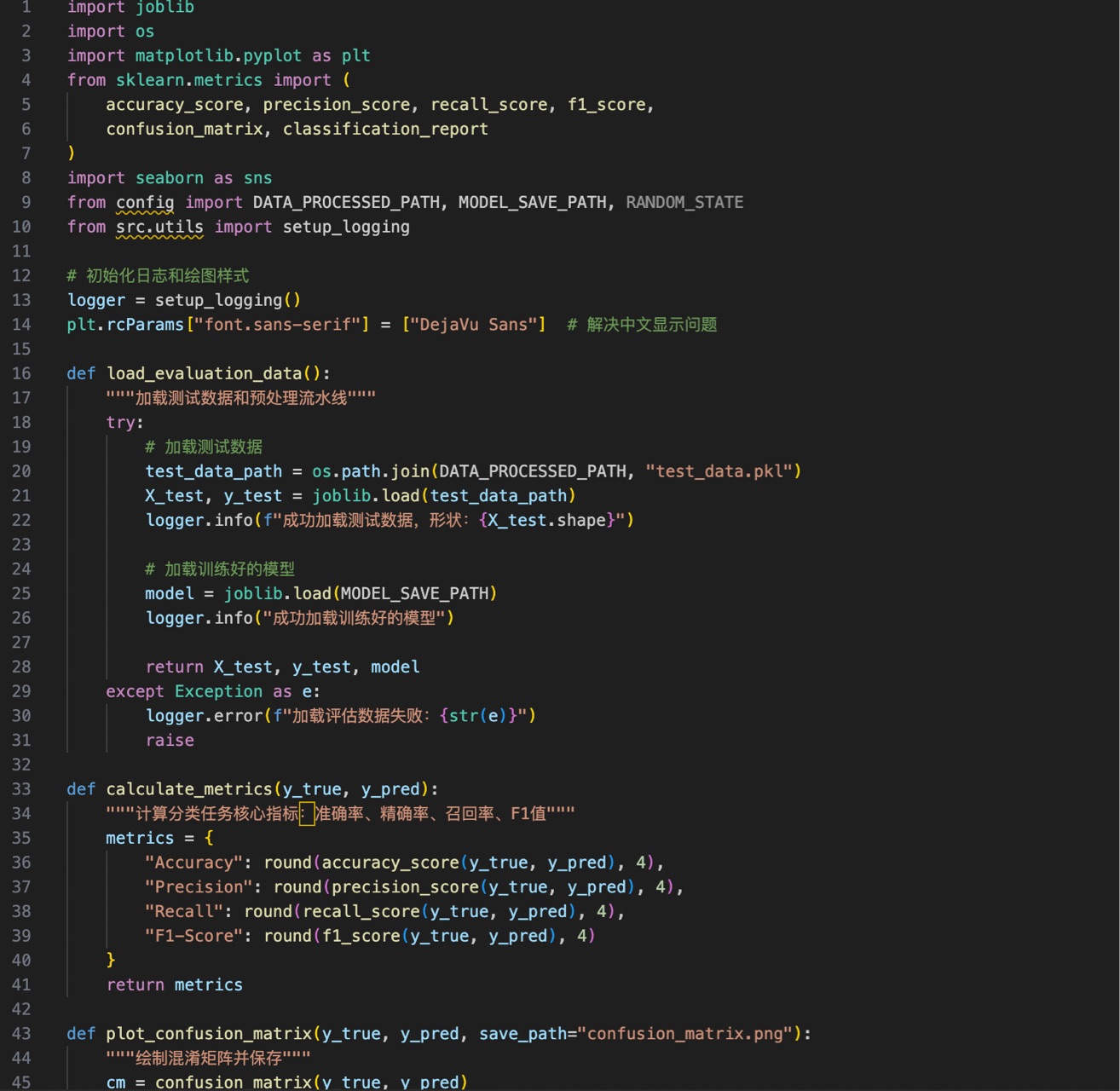
六、src/evaluate/evaluator.py(模型评估)
加载测试数据和训练好的模型,计算分类指标并打印结果。
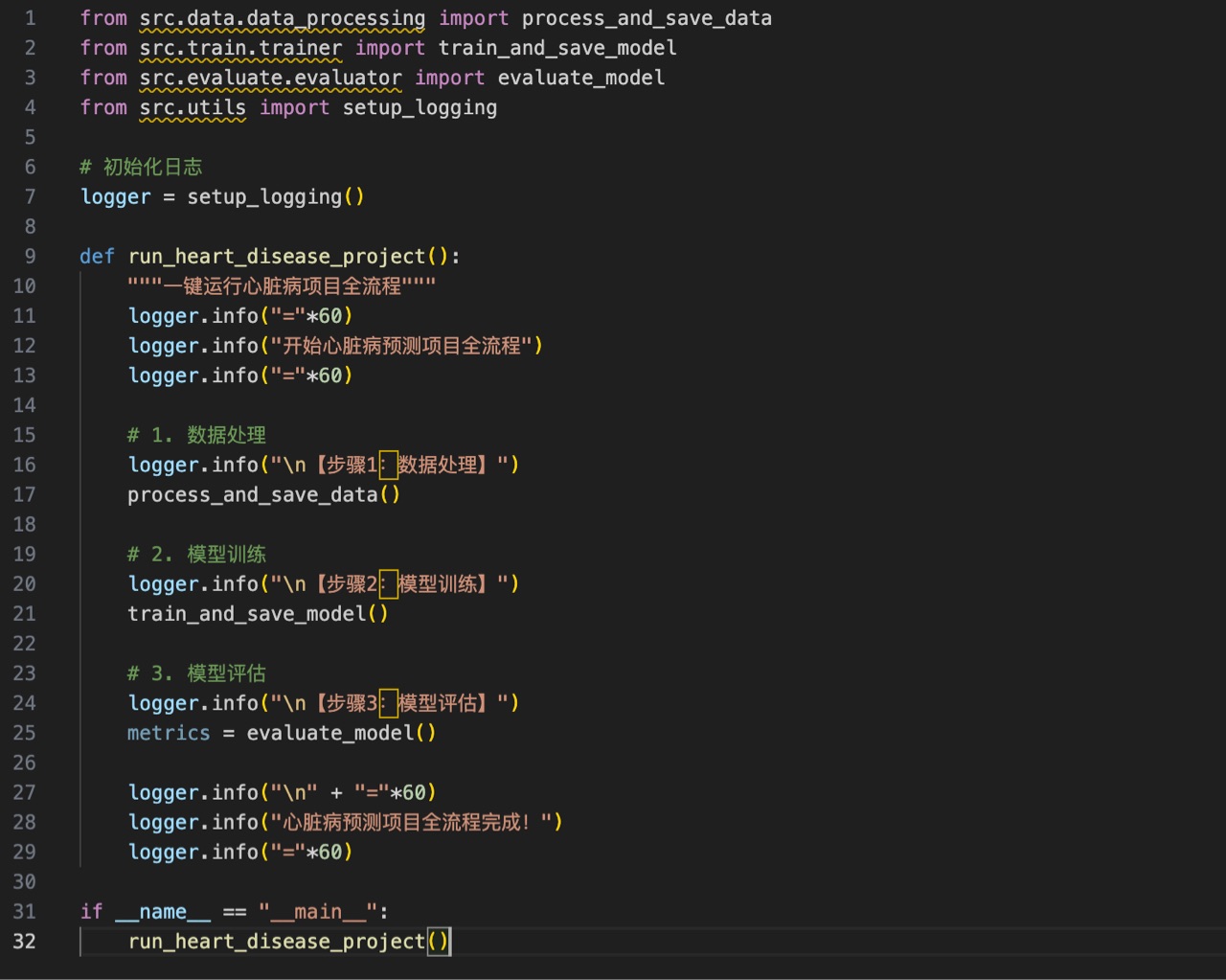
七、main.py(项目入口)
一键运行全流程:数据处理→模型训练→模型评估。