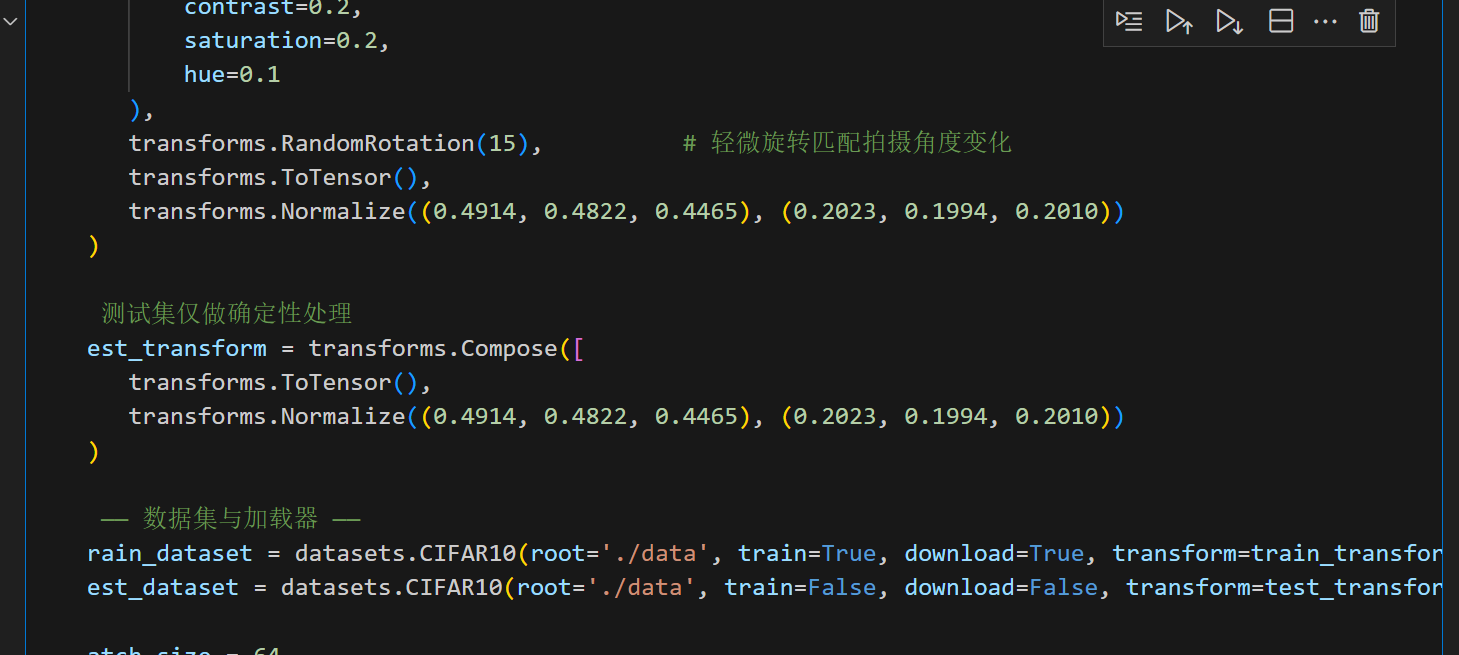
1. 数据准备与增强
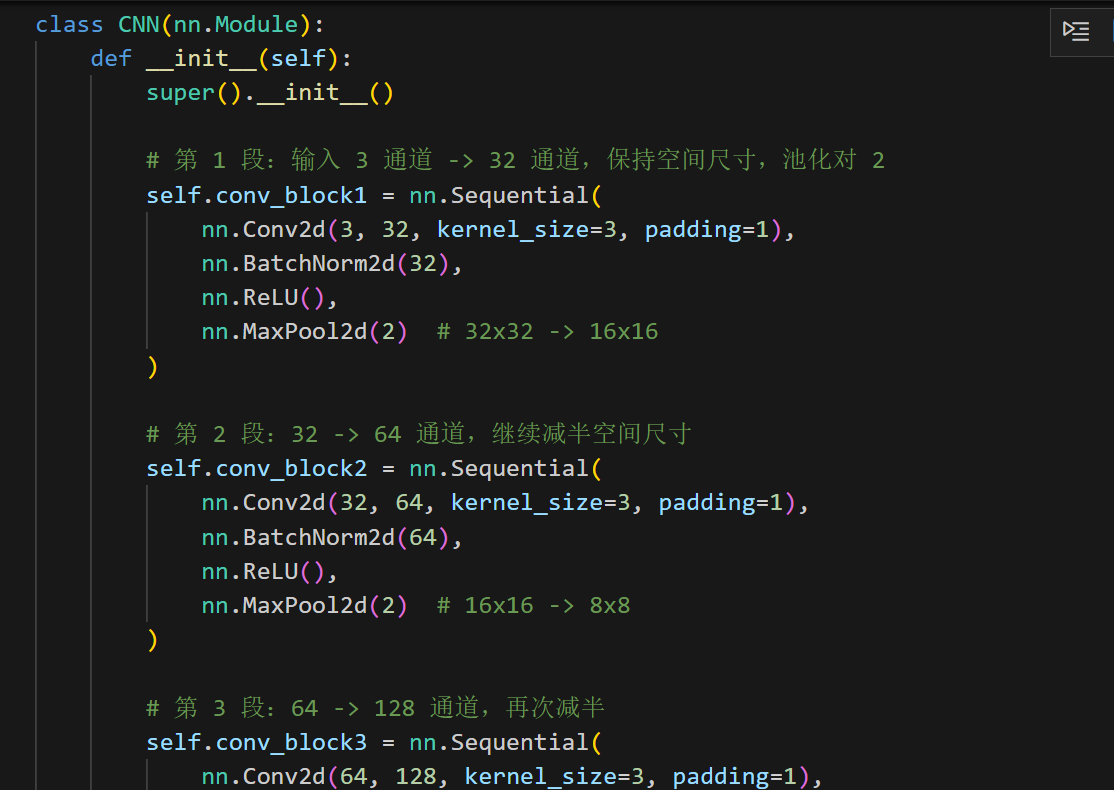
2. 模型设计路线
卷积块 :Conv2d → BatchNorm → ReLU → MaxPool 提取多尺度特征并逐步减小空间维度
分类头:将卷积输出展平成向量,接 1~2 层全连接 + Dropout,输出 10 维 logits。
正则化:BatchNorm 稳定分布、Dropout 降低 co-adaptation。
Batch Normalization 的作用
- 以 batch 为单位对每个通道做标准化,缓解"内部协变量偏移";
- 学习
gamma与beta进行再缩放,允许网络恢复到任意分布; - 由于分布稳定,可使用更大学习率,加速收敛并起到轻微正则化效果
特征图尺寸推导
假设输入尺寸为 (32\times32):
第 1 个卷积块:保持尺寸,池化后得到 32×16×16;
第 2 个卷积块:池化后得到 64×8×8;
第 3 个卷积块:池化后得到 128×4×4,展平即 2048 维向量。
这些中间输出就是"特征图",可借助 Grad-CAM 等方法做可视化解释。
class CNN(nn.Module):
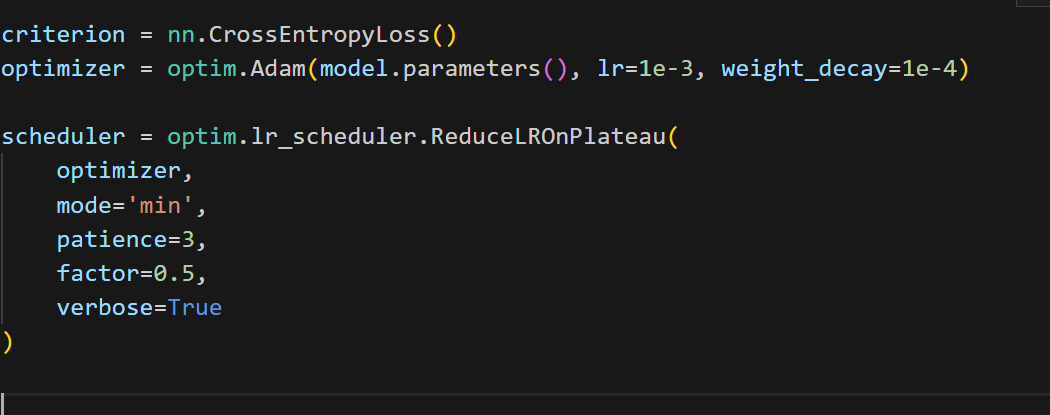
3. 损失函数、优化器与学习率调度
- 损失函数 :
CrossEntropyLoss直接接收 logits 和标签。 - 优化器:Adam 适合快速验证,配合适度权重衰减稳定训练。
- 调度器 :
ReduceLROnPlateau在验证指标停滞时自动降低学习率,比固定周期衰减更智能。
4. 训练与可视化流程
训练函数需要做几件事:
- 记录每个 batch 的损失,以观察局部波动情况;
- 每个 epoch 统计训练/测试损失与准确率,供调度器和图表使用;
- 训练结束后绘制迭代级别与 epoch 级别的曲线,帮助定位过拟合或欠拟合。
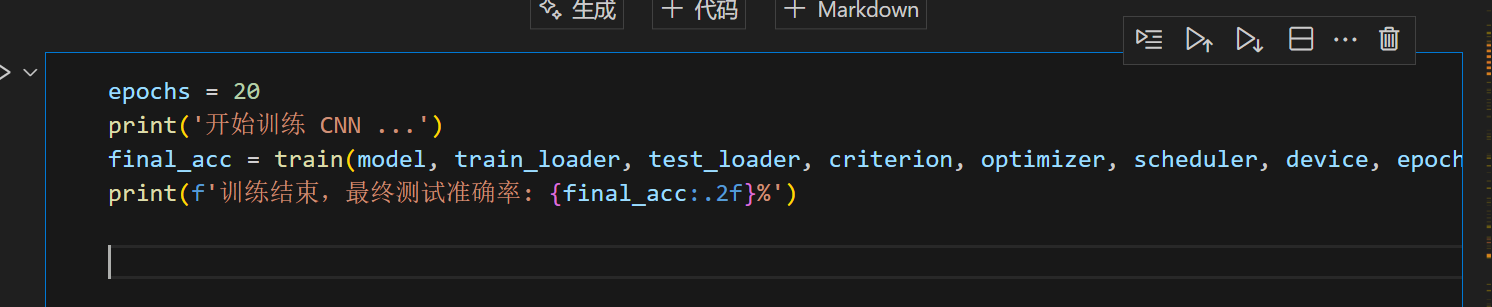
5. 启动训练
- 增加卷积层深度或使用更大的特征维度;
- 加入
CosineAnnealingLR、Mixup等更强的数据/调度策略; - 使用
AutoAugment、CutMix等进阶增强方式