文章目录
- 快读
-
- 记忆的基本概念
- [Agent 集成记忆的通用模式](#Agent 集成记忆的通用模式)
- 短期记忆的上下文工程
- 长期记忆的技术架构
- [与 RAG、产品和趋势](#与 RAG、产品和趋势)
- 工程实战指南
-
- [一、为什么Agent 一定要有"记忆"](#一、为什么Agent 一定要有“记忆”)
- [二、记忆系统的工程抽象:短期 vs 长期](#二、记忆系统的工程抽象:短期 vs 长期)
-
- [2.1 在不同框架里的概念映射](#2.1 在不同框架里的概念映射)
- [2.2 通用集成模式:四步循环](#2.2 通用集成模式:四步循环)
- [三、短期记忆实战:用 AutoContextMemory 做上下文工程](#三、短期记忆实战:用 AutoContextMemory 做上下文工程)
-
- [3.1 三大策略:缩减 / 卸载 / 隔离](#3.1 三大策略:缩减 / 卸载 / 隔离)
- [3.2 用 AutoContextMemory 落地上下文工程](#3.2 用 AutoContextMemory 落地上下文工程)
- [四、长期记忆实战:Mem0 架构与 AgentScope 集成](#四、长期记忆实战:Mem0 架构与 AgentScope 集成)
-
- [4.1 Mem0 背后的 Record & Retrieve 流程](#4.1 Mem0 背后的 Record & Retrieve 流程)
- [4.2 AgentScope 中对 Mem0 的集成方式](#4.2 AgentScope 中对 Mem0 的集成方式)
- [4.3 Mem0 与 RAG 的工程差异](#4.3 Mem0 与 RAG 的工程差异)
- [五、端到端实践:用 AgentScope + AutoContextMemory + Mem0 搭一个可用的智能助手](#五、端到端实践:用 AgentScope + AutoContextMemory + Mem0 搭一个可用的智能助手)
-
- [5.1 步骤 1:选框架与模型](#5.1 步骤 1:选框架与模型)
- [5.2 步骤 2:接好短期记忆(上下文工程)](#5.2 步骤 2:接好短期记忆(上下文工程))
- [5.3 步骤 3:接好长期记忆(Mem0)](#5.3 步骤 3:接好长期记忆(Mem0))
- [5.4 步骤 4:构建带双层记忆的 Agent](#5.4 步骤 4:构建带双层记忆的 Agent)
- [5.5 步骤 5:设计"写什么"和"读什么"的策略](#5.5 步骤 5:设计“写什么”和“读什么”的策略)
- 六、工程落地关注点与优化建议
-
- [6.1 准确性:别让"错误记忆"害了你](#6.1 准确性:别让“错误记忆”害了你)
- [6.2 安全与隐私:长期记忆=长期风险](#6.2 安全与隐私:长期记忆=长期风险)
- [6.3 多模态与未来演进](#6.3 多模态与未来演进)
- 七、给工程实践者的几条建议
- 实操
-
- [一、路由 Agent 的系统 Prompt 设计](#一、路由 Agent 的系统 Prompt 设计)
-
- [1.1 路由 Agent 的职责](#1.1 路由 Agent 的职责)
- [1.2 路由 Agent 系统 Prompt 示例](#1.2 路由 Agent 系统 Prompt 示例)
- [三、Mem0 记忆 schema 设计示意](#三、Mem0 记忆 schema 设计示意)
- [四、AgentScope 多 Agent + Mem0 示意代码](#四、AgentScope 多 Agent + Mem0 示意代码)
-
- [4.1 初始化模型与短期记忆](#4.1 初始化模型与短期记忆)
- [4.2 初始化 Mem0LongTermMemory(长期记忆)](#4.2 初始化 Mem0LongTermMemory(长期记忆))
- [4.3 定义路由 Agent](#4.3 定义路由 Agent)
- [4.4 定义业务 Agent(以订单 Agent 为例)](#4.4 定义业务 Agent(以订单 Agent 为例))

快读
记忆的基本概念
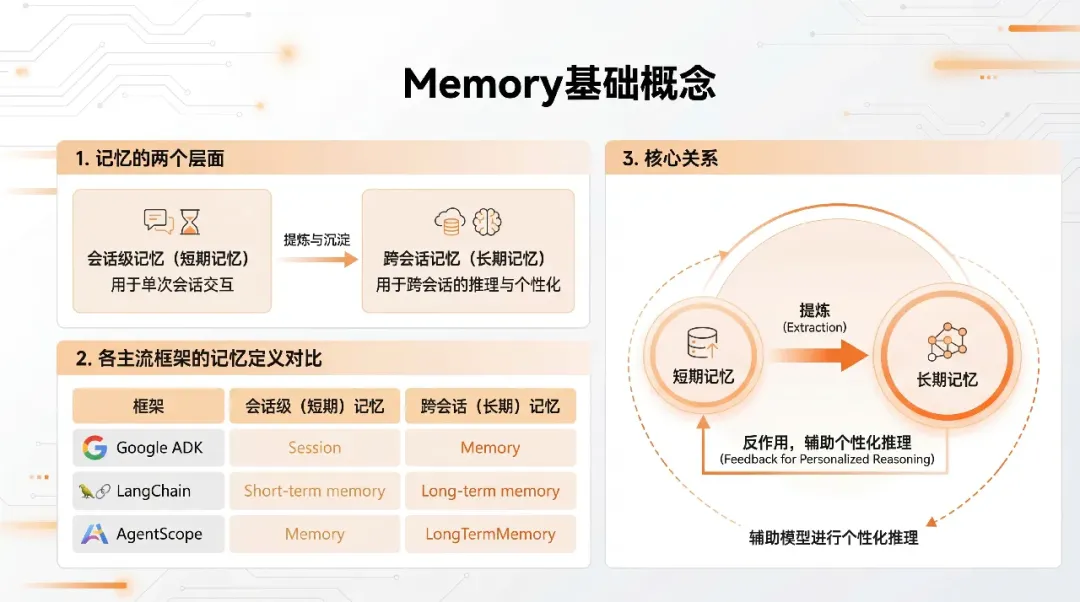
- 大模型记忆分成会话级(短期)和跨会话级(长期):前者保证一段对话内的上下文连贯,后者在多次会话间保留用户偏好、事实和经验。
- 不同框架命名不同,但都遵循"短期(Session 内)+长期(跨 Session)"的划分,比如 Google ADK 的 Session/Memory、LangChain 的 short-term/long-term memory、AgentScope 的 memory/long_term_memory。
Agent 集成记忆的通用模式
- 通用流程是:推理前从长期记忆按当前 query 检索 → 将检索结果注入当前会话上下文 → 推理结束后从会话消息中抽取可沉淀的信息写回长期记忆 → 长期记忆内部用 LLM+向量化做提取和检索。
- 短期记忆保存整个会话中的所有消息(用户、模型、工具调用等),直接作为 LLM 的上下文,受 max token 限制,需要压缩、摘要、卸载等策略管理。
短期记忆的上下文工程
- 核心三种策略:上下文缩减(保留前 N 字/摘要)、上下文卸载(原文存外部,只在上下文中留引用)、上下文隔离(多 Agent,把上下文拆给子 Agent)。
- 不同框架的实现示例:Google ADK 用 events_compaction_config 配压缩;LangChain 用 SummarizationMiddleware 做摘要;AgentScope 用 AutoContextMemory 提供 6 级渐进压缩和四层存储,支持更细粒度控制和追溯。
长期记忆的技术架构
- 长期记忆围绕 Record & Retrieve 两个流程,核心组件包括:LLM、Embedding 模型、向量库、图数据库、Reranker 和用于审计的 SQLite 日志。
- Record 流程是 LLM 提取事实 → 向量化 → 存向量库(可能同步到图库)→ 写日志;Retrieve 流程是 query 向量化 → 向量检索 → 图库补充 → 重排 → 返回结果注入上下文。
与 RAG、产品和趋势
- 个性化长期记忆在技术架构上与 RAG 相似(向量存储、相似性检索、注入上下文),但更强调用户画像、记忆管理和跨会话个性化,而不是文档问答。
- 行业趋势包括:记忆即服务(MaaS)、更精细的分层记忆管理、多模态记忆、以及模型参数化记忆等;当前主流路线仍是外部记忆增强,mem0 等开源项目在长期记忆产品中较领先。
工程实战指南
一、为什么Agent 一定要有"记忆"
在真实业务里,LLM 的"无记忆"会非常致命:它只看得到当前上下文窗口内的内容,看不到更久远的历史,也无法跨会话记住用户是谁、喜欢什么、做过什么。
当对话变长、任务变复杂、用户希望个性化体验时,没有记忆系统的 Agent 会暴露出三类典型问题。
- 会话内:一旦 token 超过窗口,就"失忆",前文的讨论、工具输出、分析过程都丢了。
- 会话间:下次再来,完全认不出用户,不知道用户偏好、历史决策和约定。
- 成本侧:长对话全量塞进上下文,费用爆炸,延迟变长,还容易引出无关内容。
因此,一个工程上可用的记忆系统,至少要覆盖两类能力:
- 短期记忆:在单次会话中做"上下文工程",在有限 token 内尽量保留重要历史。
- 长期记忆:跨会话沉淀用户信息、任务状态、领域经验,并在需要时按需加载。
下面的内容会完全站在工程实战视角,基于 AgentScope 做短期记忆管理(AutoContextMemory),用 Mem0 做长期记忆,并给出端到端代码示例。
二、记忆系统的工程抽象:短期 vs 长期
从工程视角,记忆可以用一个很简单的划分:是否跨 Session。
- 短期记忆(Session 级):只在一次连续会话内有效,直接参与当前模型推理。
- 长期记忆(跨 Session):在多次会话之间共享,如用户画像、偏好、历史任务、常驻知识等。
2.1 在不同框架里的概念映射
虽然名字不同,但主流框架本质上都是这两层结构。
| 框架 | 短期记忆概念 | 长期记忆概念 | 说明 |
|---|---|---|---|
| Google ADK | Session(会话事件) | Memory(跨对话知识库) | Session 内交互 + 独立 Memory 组件 |
| LangChain | short-term memory | long-term memory(外挂) | 长期记忆是高阶扩展能力 |
| AgentScope | memory(Memory 接口) | long_term_memory 接口 | 短期和长期都有明确组件边界 |
在本文方案中:
- 短期记忆:选择 AgentScope 的 AutoContextMemory,自动做上下文压缩与卸载。
- 长期记忆:通过 Mem0LongTermMemory 集成 Mem0,托管 Record / Retrieve 的所有复杂逻辑。
2.2 通用集成模式:四步循环
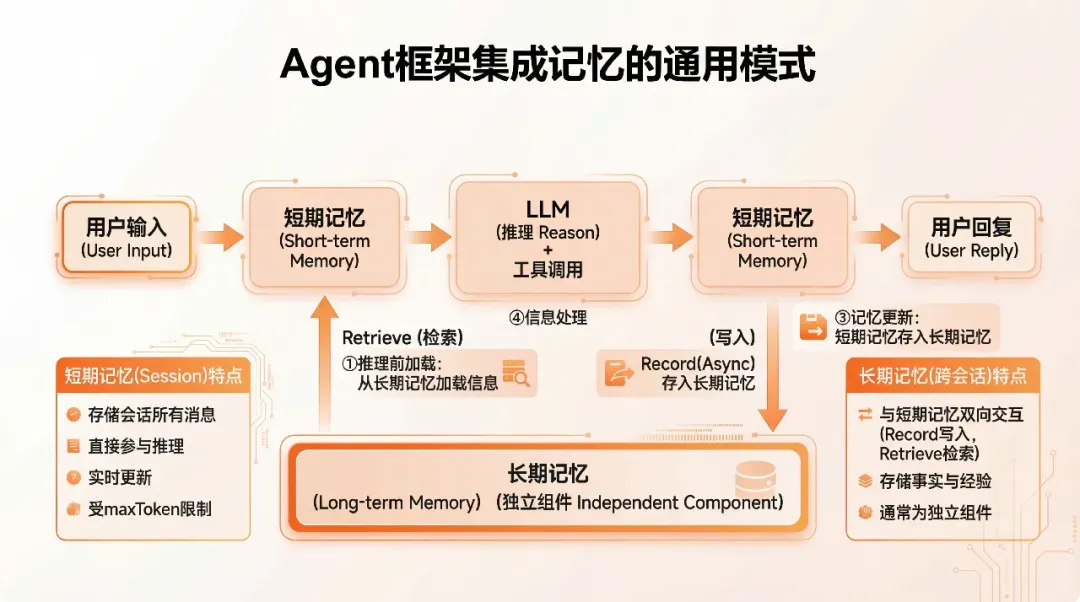
无论用什么框架,Agent + Memory 的通用循环基本都是这四步:
- 推理前:根据当前 user query,从长期记忆检索相关信息。
- 上下文注入:将检索结果作为额外上下文注入短期记忆。
- 推理执行:LLM 基于"当前对话 + 长期记忆"做推理。
- 记忆更新:从本轮对话中抽取值得长期保存的信息写回长期记忆。
AgentScope + Mem0 默认已经帮你实现了大部分 glue 逻辑,你只需要配置好 Memory 组件即可。
三、短期记忆实战:用 AutoContextMemory 做上下文工程
短期记忆的问题不是"有没有",而是"怎么控制不爆窗又不丢关键信息" 。
典型痛点是:工具调用结果很长、历史对话很多、但是大部分内容只在当时有用、之后只需要结论。
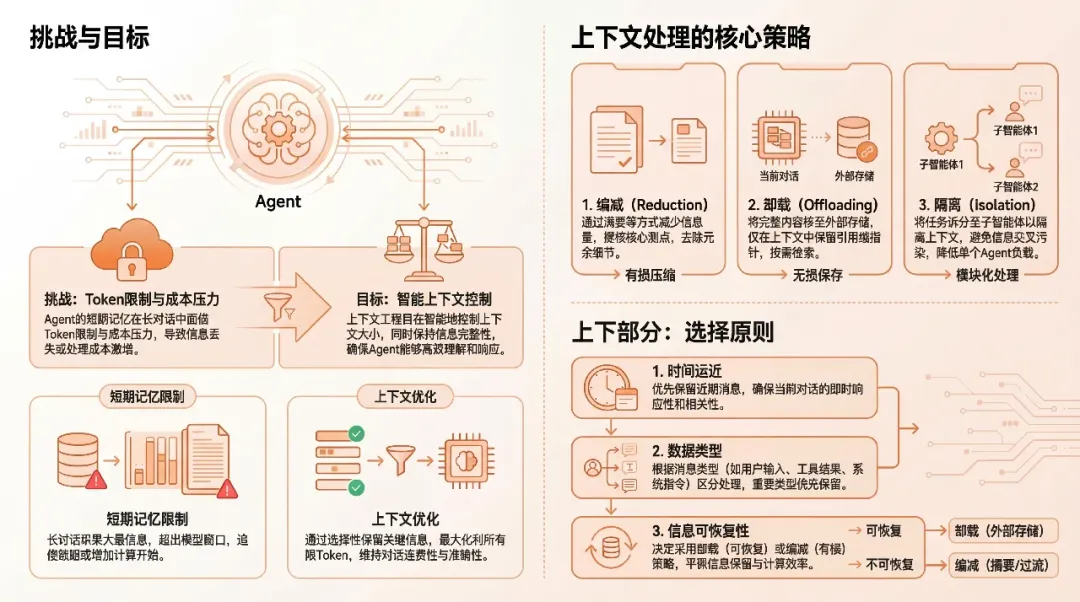
3.1 三大策略:缩减 / 卸载 / 隔离
文章中把狭义的上下文工程归纳为三大策略,非常贴合工程落地。
- 上下文缩减(Reduction):
- 对长文本保留前 N 字符作为预览;
- 或直接生成摘要,只留关键结论。
- 上下文卸载(Offloading):
- 原始大内容写到外部存储(文件 / DB),上下文中只保留引用 ID;
- 当确实需要时再按 ID 加载原文。
- 上下文隔离(Isolation):
- 使用多 Agent,将复杂子任务的上下文隔离到子 Agent 中;
- 主 Agent 只要看子 Agent 的结果,而不是所有中间过程。
这些策略的选择原则是:时间远近、数据类型、是否需要可恢复原文等。
3.2 用 AutoContextMemory 落地上下文工程
AgentScope 的 AutoContextMemory 提供了一套工程实用的实现:
- 实现 Memory 接口,可以直接挂在 Agent 上。
- 支持 6 种渐进式压缩策略 ,例如:
- 优先压缩历史工具调用结果;
- 卸载大型消息到外部存储;
- 合并多轮闲聊为摘要等。
- 提供四层存储:工作内存、原始内存、卸载上下文和压缩事件,方便追溯和调试。
一个典型的 Java 配置示例是这样的:
java
// 创建 AutoContextMemory,配置阈值与 token 限制
AutoContextMemory memory = new AutoContextMemory(
AutoContextConfig.builder()
.msgThreshold(100) // 历史消息超过 100 条开始触发压缩
.maxToken(128 * 1024) // 最大上下文 token 上限
.tokenRatio(0.75) // 超过 75% 上限时启动压缩流程
.build(),
model
);
// 创建带短期记忆的 Agent
ReActAgent agent = ReActAgent.builder()
.name("Assistant")
.model(model)
.memory(memory)
.build();工程实践建议:
- 初期可以设置较宽松的 maxToken + 较低的 msgThreshold,让 Agent 尽量多保留历史,先观察 token 消耗情况再收紧。
- 若工具调用结果较长,优先打开"卸载大消息 + 留摘要 + 存引用"策略,而不是简单截断。
四、长期记忆实战:Mem0 架构与 AgentScope 集成
短期记忆解决的是"一次对话里别失忆",长期记忆要解决的则是"下次再见时还能认出你"。
这就需要一套能跨会话持续存、能精准检索的记忆基础设施,Mem0 就是目前最成熟的开源选择之一。
4.1 Mem0 背后的 Record & Retrieve 流程
从架构图来看,长期记忆主要围绕两个过程:Record 和 Retrieve。
核心组件:
- LLM:从短期会话中抽取"可记忆事实"(用户偏好、行为、总结等)。
- Embedding 模型:把文本变成向量,用于相似度检索。
- VectorStore:存储记忆向量 + 元数据(时间、来源、类型等)。
- GraphStore(可选):存实体与关系,用于复杂推理。
- Reranker:对初步检索结果进行重排,增强相关性。
- SQLite:记录所有记忆读写操作,方便审计和回溯。
Record 流程:
短期会话消息 -> LLM 提取事实 -> 向量化 -> 写入 VectorStore/GraphStore -> 记录操作日志
Retrieve 流程:
当前 query -> 向量化 -> 在向量库检索 top-k -> 图数据库补充关系 -> Rerank -> 返回上下文
对开发者而言,Mem0 已经把这些复杂能力封装成统一 API,AgentScope 做的事情是:在合适的时机调用 Mem0 的 Record / Retrieve,并把结果接到 Agent 的上下文里。
4.2 AgentScope 中对 Mem0 的集成方式
AgentScope 提供了 Mem0LongTermMemory 实现,可以直接挂在 ReActAgent 上作为 longTermMemory。
java
// 1. 初始化 Mem0 长期记忆组件
Mem0LongTermMemory mem0Memory = new Mem0LongTermMemory(
Mem0Config.builder()
.apiKey("your-mem0-api-key") // 从 Mem0 控制台获取
// .baseUrl("https://api.mem0.ai") // 如需自托管或特定环境可配置
.build()
);
// 2. 创建带短期 + 长期记忆的 Agent
ReActAgent agent = ReActAgent.builder()
.name("Assistant")
.model(model)
.memory(memory) // 短期记忆:AutoContextMemory
.longTermMemory(mem0Memory) // 长期记忆:Mem0
.build();这样搭起来之后:
- Agent 在对话过程中的"可长期记忆信息"会通过 Mem0LongTermMemory 写入 Mem0。
- 每次新 query 到来时,Mem0 会基于用户身份和 query 自动检索相关记忆,并注入到短期记忆中。
4.3 Mem0 与 RAG 的工程差异
Mem0 的底层技术栈非常像一个"个体级 RAG 系统":向量化、检索、重排、注入上下文。
但与文档问答型 RAG 相比,它有几个工程上的关键不同点:
- 写入来源不同:
- RAG:主要从已有文档/知识库导入。
- Mem0:主要从用户交互中增量抽取(会话驱动)。
- 粒度不同:
- RAG:文档段落、章节等。
- Mem0:用户偏好、行为事实、历史决策、任务状态。
- 维度不同:
- RAG:多用户共享一个知识库。
- Mem0:更强调 user 维度隔离,一人一套长期记忆。
这也意味着,在设计长记忆 schema 时,要先想清楚:按用户、按任务、按业务域,分别沉淀哪些信息。
五、端到端实践:用 AgentScope + AutoContextMemory + Mem0 搭一个可用的智能助手
5.1 步骤 1:选框架与模型
- 选择 AgentScope 作为 Agent 框架(Java 生态 + 企业级场景友好)。
- 选择一个主模型(如企业自建模型或主流闭源 API),并为 AutoContextMemory 配备一个相同或轻量模型用于 token 估算等。
伪代码示例:
LLMModel model = ... // 初始化你的主 LLM 模型 5.2 步骤 2:接好短期记忆(上下文工程)
根据业务预期对话长度配置 AutoContextMemory:
java
AutoContextMemory memory = new AutoContextMemory(
AutoContextConfig.builder()
.msgThreshold(80) // 单会话超过 80 条消息后开始压缩
.maxToken(64 * 1024) // 单次调用最大 64k tokens
.tokenRatio(0.8) // 超过 80% 上限时触发压缩
.build(),
model
);工程建议:
- 如果你的业务中工具输出特别长(如代码生成、日志检索),建议在 AutoContextConfig 里打开"优先卸载工具输出"的策略,而不是让它留在工作内存里长期占位。
- 对咨询类场景,可以更激进地做"多轮归纳摘要",每隔 N 轮将闲聊合并成一段"对话总结"。
5.3 步骤 3:接好长期记忆(Mem0)
准备好 Mem0 服务(云端或自托管),拿到 apiKey/baseUrl 等。
java
Mem0LongTermMemory mem0Memory = new Mem0LongTermMemory(
Mem0Config.builder()
.apiKey("your-mem0-api-key")
// .baseUrl("http://your-mem0-host:port") // 可选
.build()
);5.4 步骤 4:构建带双层记忆的 Agent
java
ReActAgent agent = ReActAgent.builder()
.name("PersonalAssistant")
.model(model)
.memory(memory) // 短期记忆:AutoContext
.longTermMemory(mem0Memory) // 长期记忆:Mem0
.build();此时,你拿到的是一个具备:
- 会话内自动上下文控制;
- 会话间自动长期记忆的 Agent 架子。
5.5 步骤 5:设计"写什么"和"读什么"的策略
有了 Mem0,并不代表所有内容都该写进去,否则长期记忆会非常噪声。工程上可以这样设计规则:
写入策略(Record):
- 写入内容类型:
- 用户显式偏好("我喜欢简洁回答""以后都用中文回复")。
- 用户的长期任务/目标("接下来两周帮我准备面试")。
- 具有持续价值的事实(个人背景、常驻配置、约定好的工作流)。
- 写入时机:
- 每轮结束后由一个"记忆提取 Prompt"让 LLM 决定:当前轮是否有可长期保存的信息,有则调用 Mem0。
- 或者只在特定工具调用 / 特定意图触发时写入。
读取策略(Retrieve):
- 每次新 Session 启动时,根据 userId 和当前 query 做一次 Mem0 检索,将 top-k 结果注入到短期记忆开头部分。
- 对特定意图(如"继续上次的计划")可以再次主动调用 Mem0,按"任务维度"检索历史状态。
在 AgentScope 中,这些策略通常通过:
- 自定义工具 / 中间层逻辑;
- 或者在 ReActAgent 的规划逻辑中,显式增加"记忆管理工具调用"步骤来实现。
六、工程落地关注点与优化建议
真正落地时,除了"能用",还要关注准确性、成本、安全与多模态扩展等问题。
6.1 准确性:别让"错误记忆"害了你
- 记忆建模:需要一个合理的用户画像 schema,区分"偏好""事实""任务状态"等不同类型。
- 记忆管理:要支持更新与遗忘,例如用户改口、撤回、账号注销等场景。
- 检索准确性:适配合适的 embedding 模型和重排策略,对误召回要有容错策略(例如让模型看到"这可能不完全相关")。
6.2 安全与隐私:长期记忆=长期风险
- 数据加密与访问控制:后端必须做好租户级隔离和权限校验。
- 防数据中毒:对外部来源的内容(如用户上传文件)写入记忆前需要毒性检测和过滤。
- 用户控制权:提供"查看/导出/删除我的记忆"接口和 UI,是产品层必备能力。
6.3 多模态与未来演进
当前大多数记忆系统仍然以文本为主,但趋势非常明确:
- 多模态记忆:图像、语音、文本统一编码到同一向量空间,对工程侧意味着统一 embedding + 高性能索引方案。
- Memory-as-a-Service:记忆系统独立成云服务,像数据库一样被多个 Agent 应用复用。Mem0 本质上就是这条路线的代表之一。
- 参数化记忆:未来会出现更多"Memory Adapter"类技术,把一部分高频记忆写进模型参数,结合外部 Mem0 形成"内外混合记忆"。
七、给工程实践者的几条建议
- 先把短期记忆做好,再上长期记忆:先用 AutoContextMemory 解决"会话内暴窗"的问题,再引入 Mem0。
- 长期记忆从"小而精"开始:先只记"用户偏好 + 关键任务状态",避免一开始就把所有内容都写进去变成噪声堆。
- 把记忆系统当成基础设施:像设计数据库那样设计 schema、权限和运维,而不是只当一个"附属功能"
实操
一、路由 Agent 的系统 Prompt 设计
1.1 路由 Agent 的职责
- 根据用户输入识别意图。
- 选择合适的业务 Agent(如:订单 Agent、客服 Agent、营销 Agent 等)。
- 在必要时,将用户长期偏好/历史上下文作为提示信息附带给业务 Agent。
1.2 路由 Agent 系统 Prompt 示例
text
# 角色
你是一个多智能体系统中的「意图路由 Agent」。
你的任务是:
1. 理解用户当前输入的真实意图。
2. 在多个业务 Agent 中选择最合适的一个或多个进行处理。
3. 为后续的业务 Agent 提供简明的任务说明和必要的用户上下文。
# 可用业务 Agent 列表(示例)
- order_agent:处理订单查询、创建、修改、取消等电商订单相关请求。
- service_agent:处理售后、投诉、退款、物流异常等服务类问题。
- marketing_agent:处理优惠券、营销活动咨询、个性化推荐等问题。
- faq_agent:处理通用问题、基础说明、帮助文档查询等。
# 记忆相关说明
系统为每个用户维护短期记忆和长期记忆:
- 短期记忆:当前会话中的历史对话,由底层 AutoContextMemory 自动管理,你无需关心 token 细节。
- 长期记忆:基于 Mem0 存储的用户偏好、历史行为、长期任务状态等,会在路由前自动检索出若干条关键信息。
你会收到一个字段 `user_long_term_memory`,其中包含与本次请求最相关的若干条用户记忆(若没有则为空)。
你需要:
1. 在路由决策时参考这些记忆(如用户偏好的沟通方式、历史问题背景等)。
2. 在返回给业务 Agent 的任务描述中,合理引用这些记忆(例如"用户之前反馈过类似物流问题")。
# 输入
你会收到以下结构化输入(由上游系统封装):
- user_query:用户本轮自然语言输入。
- user_long_term_memory:列表,每一条是面向 LLM 的自然语言描述,如:
- "用户偏好使用中文简洁回答"
- "用户在 2024-12-20 购买过 iPhone 15 Pro,订单号 XXX"
- "用户对上一次售后处理不满意,期望更快答复"
# 输出要求
1. 以 JSON 格式输出你的路由决策,**不要输出多余自然语言**。
2. JSON 字段定义:
- target_agents:数组,元素为需要调用的业务 Agent 名称(如 ["order_agent"])。
- route_reason:字符串,简要说明路由原因(面向开发者调试,可引用 user_long_term_memory)。
- task_instruction:字符串,发给目标业务 Agent 的任务描述,要求:
- 用简洁中文撰写。
- 说明用户想要解决的问题。
- 补充与本次任务相关的长期记忆信息(如果有)。
# 输出示例
{
"target_agents": ["service_agent"],
"route_reason": "用户反馈包裹多次丢件,且长期记忆显示其对物流问题较为敏感",
"task_instruction": "用户反馈本次包裹疑似丢件,请你查询物流进度并给出处理方案。用户过去多次遇到类似问题,对响应速度比较敏感,请在回答中体现重视并说明后续跟进方式。"
}
## 二、业务 Agent 的 Prompt 设计(结合短期 + 长期记忆)
假设有一个 `order_agent`,需要使用 AutoContextMemory 做短期记忆管理,Mem0 提供的长期记忆会通过上层逻辑注入到短期上下文中(例如以"系统消息 + 历史信息"的方式)。
### 2.1 订单 Agent 系统 Prompt 示例
```text
# 角色
你是电商平台中的「订单服务 Agent」,专门处理与订单相关的业务:
- 订单创建、修改、取消
- 订单状态、物流进度查询
- 订单售后相关的前置处理(需要时会转交给 service_agent)
# 上下文来源说明
- 短期记忆:当前会话的历史消息,由系统通过 AutoContextMemory 自动管理并注入。
- 长期记忆:系统可能会通过一段系统消息提供与用户历史订单、偏好相关的信息(由 Mem0 提供)。
你需要:
1. 在回答用户问题时,优先结合当前会话最新信息。
2. 合理使用长期记忆中与本次问题相关的信息,但不要引用与当前问题无关的历史细节。
3. 对用户保持简洁、专业、礼貌的中文回复。
# 回答风格
- 结构清晰,可使用有序/无序列表。
- 优先给出直接结论,然后根据需要提供补充说明。
- 避免暴露内部系统字段名、ID 结构等实现细节。
# 若需要调用工具
如果系统为你提供了工具(例如:查询订单详情、查询物流信息等),请遵循工具使用规范:
- 先明确你需要什么信息。
- 再决定是否调用工具。
- 最终向用户给出自然语言解释,而不是工具返回的原始 JSON。三、Mem0 记忆 schema 设计示意
在多 Agent + 意图路由场景中,Mem0 的记忆可以从三个维度建模:
- 用户维度(user_profile / preferences)
- 任务/会话维度(task / session)
- 业务维度(domain:order / service / marketing 等)
一个简单的 schema 思路(伪结构,真实实现由 Mem0 内部管理):
json
{
"id": "memory_id",
"user_id": "user_123",
"domain": "order", // order/service/marketing/global
"type": "preference", // preference/fact/task_state/summary
"content": "用户偏好使用中文简洁回答",
"created_at": "2025-12-27T10:00:00Z",
"metadata": {
"source": "chat",
"session_id": "session_abc",
"importance": 0.8
}
}在工程代码里,一般做法是:
- 写入时:根据规则抽取"可记忆内容",拼成自然语言
content+ 元数据metadata,交给 Mem0。 - 读取时:根据
user_id和当前query检索出若干条自然语言记忆,直接拼到路由 Agent 的user_long_term_memory输入列表中。
四、AgentScope 多 Agent + Mem0 示意代码
下面给出一个简化 Java 伪代码,体现结构和关键点,方便你在项目中改造。
4.1 初始化模型与短期记忆
java
// 初始化主模型
LLMModel model = ...; // 例如 OpenAI/Azure/自建模型
// 初始化 AutoContextMemory(短期记忆)
AutoContextMemory shortTermMemory = new AutoContextMemory(
AutoContextConfig.builder()
.msgThreshold(100) // 消息超过 100 条开始压缩
.maxToken(128 * 1024) // 单次上下文 token 上限
.tokenRatio(0.75) // 超过 75% 开始触发压缩
.build(),
model
);4.2 初始化 Mem0LongTermMemory(长期记忆)
java
Mem0LongTermMemory mem0Memory = new Mem0LongTermMemory(
Mem0Config.builder()
.apiKey("your-mem0-api-key")
// .baseUrl("https://api.mem0.ai") // 如有自建可替换
.build()
);4.3 定义路由 Agent
java
ReActAgent routerAgent = ReActAgent.builder()
.name("RouterAgent")
.model(model)
.memory(shortTermMemory) // 路由 Agent 也使用短期记忆
.longTermMemory(mem0Memory) // 可选:让路由 Agent 也使用 Mem0
.systemPrompt(ROUTER_SYSTEM_PROMPT) // 即上面「路由 Agent 系统 Prompt」
.build();业务侧调用时,可以在调用 routerAgent 前,显式从 Mem0 拉一遍用户相关记忆,拼到 user_long_term_memory 字段(也可以由 Mem0LongTermMemory 在内部自动完成):
java
// 伪代码:组装路由输入
Map<String, Object> routerInput = new HashMap<>();
routerInput.put("user_query", userQuery);
routerInput.put("user_long_term_memory", mem0Memory.search(userId, userQuery)); // 返回若干条文本记忆
String routerResultJson = routerAgent.run(JsonUtils.toJson(routerInput));
RouterDecision decision = JsonUtils.fromJson(routerResultJson, RouterDecision.class);4.4 定义业务 Agent(以订单 Agent 为例)
java
ReActAgent orderAgent = ReActAgent.builder()
.name("OrderAgent")
.model(model)
.memory(shortTermMemory) // 也可以为每个 Agent 定制不同 Memory 实例
.longTermMemory(mem0Memory) // 如需在业务 Agent 内直接读写长期记忆
.systemPrompt(ORDER_AGENT_PROMPT) // 即上面「订单 Agent 系统 Prompt」
.build();当路由结果返回后:
java
for (String target : decision.getTargetAgents()) {
String taskInstruction = decision.getTaskInstruction();
if ("order_agent".equals(target)) {
String reply = orderAgent.run(taskInstruction);
// 返回给用户
}
// 其他 agent 类似
}记忆写入策略(Record)通常在中间层做:在每轮对话结束后,根据当前对话 + 工具结果,用一个"记忆提取 Prompt"生成若干条可写入 Mem0 的自然语言,再调用
mem0Memory.save(userId, content, metadata)即可。
