介绍
这篇文章主要讲解了openresty的监控界面,包括监控界面的安装,展示,以及使用。这里推荐的openresty的监控主要有两个,一个是qps,状态码,upstream连接数等nginx指标的监控大屏,还有一个是lua的异常日志的监控展示。前者让我们可以掌握nginx整体的健康状态,后者则从业务角度告诉我们,当前什么在出错。
成果展示
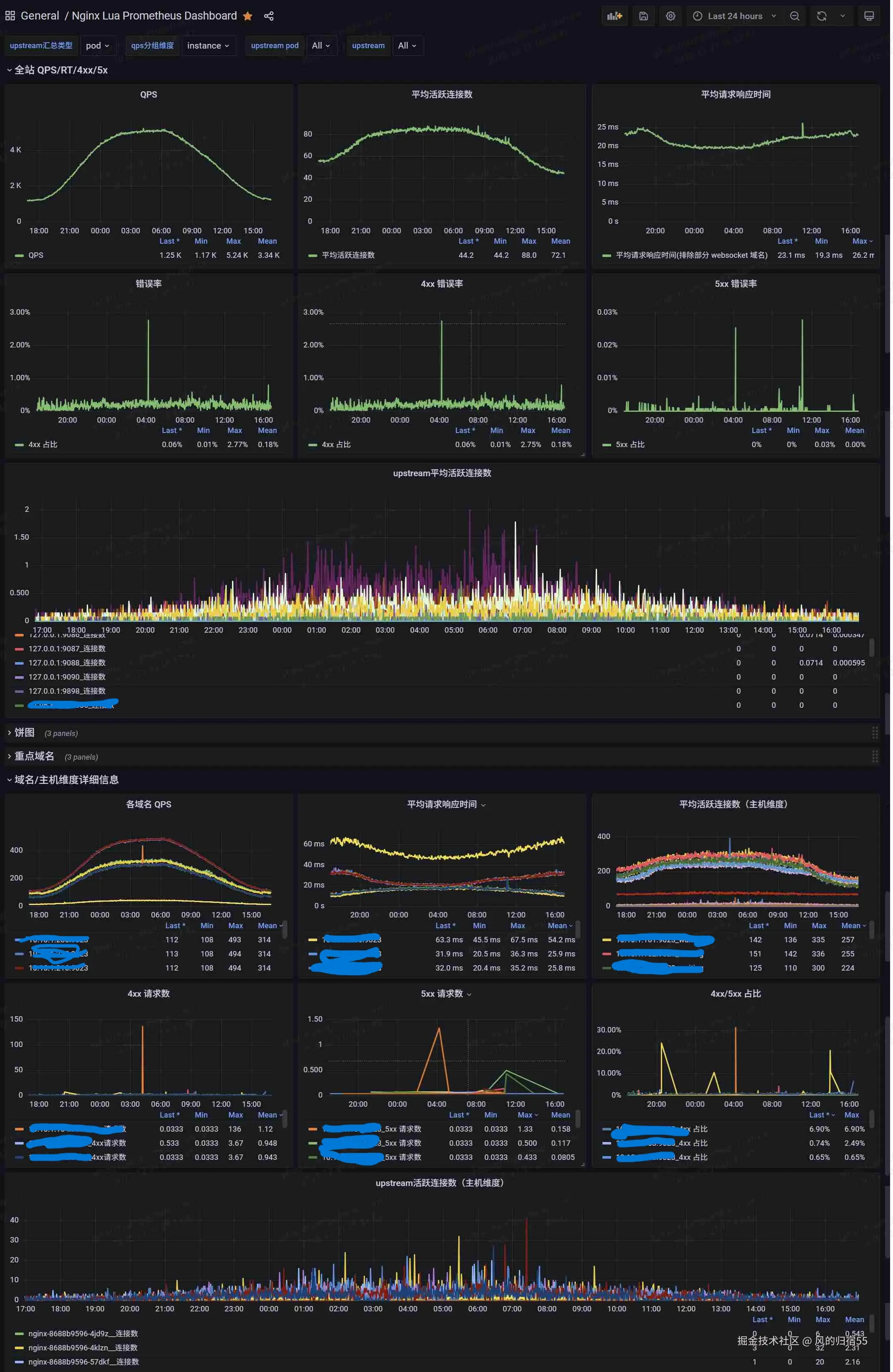
这里贴一下grafana最终展示出来的监控效果
监控大屏
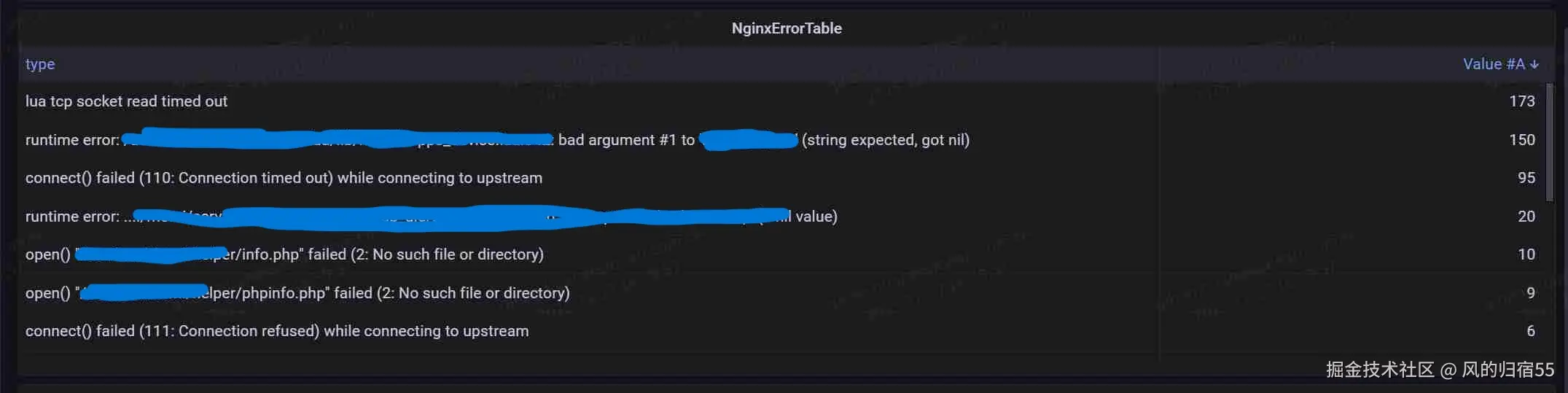
异常监控
监控大屏
这个监控大屏主要是通过openresty的prometheus库来收集数据的,有兴趣的可以看下这个官方文档 github.com/knyar/nginx... 。这个库里面提供了一些功能的函数,可以通过这些函数导出自己感兴趣的指标并展示,本文就额外导出了nginx中的upstream的连接数这一指标,用于协助排查问题。当然,这个库已经默认导出了qps,连接数,延迟等重要信息。
安装
首先从这个git项目获取库文件进行安装: github.com/knyar/nginx... ,需要注意的是,这个库文件生效的前提是需要nginx已经安装了ngx_lua模块,不过对于openresty来说,这是自带的,不需要额外安装。然后可以通过以下步骤进行安装:
- 将git项目中的prometheus.lua,prometheus_keys.lua,prometheus_resty_counter.lua 这几个库文件放置到lua的lua_package_path 指向的文件路径
- 在nginx项目启动时初始化prometheus库,即在nginx.conf配置文件中增加以下内容:
csharp
lua_shared_dict prometheus_metrics 10M;
lua_package_path "/path/to/nginx-lua-prometheus/?.lua;;";
init_worker_by_lua_block {
prometheus = require("prometheus").init("prometheus_metrics")
metric_requests = prometheus:counter(
"nginx_http_requests_total", "Number of HTTP requests", {"host", "status"})
metric_latency = prometheus:histogram(
"nginx_http_request_duration_seconds", "HTTP request latency", {"host"})
metric_connections = prometheus:gauge(
"nginx_http_connections", "Number of HTTP connections", {"state"})
}
log_by_lua_block {
metric_requests:inc(1, {ngx.var.server_name, ngx.var.status})
metric_latency:observe(tonumber(ngx.var.request_time), {ngx.var.server_name})
}- 增加一个路由,将nginx的监控数据导出,支持prometheus抓取,可以在nginx.conf中增加以下配置:
csharp
server {
listen 9145;
allow 192.168.0.0/16;
deny all;
location /metrics {
content_by_lua_block {
metric_connections:set(ngx.var.connections_reading, {"reading"})
metric_connections:set(ngx.var.connections_waiting, {"waiting"})
metric_connections:set(ngx.var.connections_writing, {"writing"})
prometheus:collect()
}
}
}- 上面几个事官方的安装步骤,我这里加了一个导出upstream信息的路由,可以写在/metrics 这个路由下面
lua
location = /upstreams_metrics {
default_type text/plain;
content_by_lua_block {
local concat = table.concat
local upstream = require "ngx.upstream"
local get_servers = upstream.get_servers
local get_upstreams = upstream.get_upstreams
local get_primary_peers = upstream.get_primary_peers
local us = get_upstreams()
for _, u in ipairs(us) do
local srvs, err = get_primary_peers(u)
if not srvs then
ngx.say("#failed to get servers in upstream ", u)
else
for _, server in ipairs(srvs) do
local message = string.format('nginx_upstream_conn_total{upstream="%s",server="%s"} %s',tostring(u),tostring(server.name),tostring(server.conns or 0))
ngx.say(message)
end
end
end
}
}- 这里nginx就可以把监控数据导出了,接下来需要配置prometheus抓取这部分数据,这里分为两种情况,如果是部署的prometheus实例的话,可以直接抓取对应nginx实例的端口
yaml
- job_name: 'nginx-moniter'
static_configs:
- targets: ['10.10.1.123:9145']
labels:
exporter: 'nginx'- 如果是使用k8s部署的nginx,并且prometheus是使用operator部署的,那可以通过如下方式导出
yaml
k8s的nginx service配置:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
name: nginx
group: default
spec:
type: ClusterIP
ports:
- name: metrics
port: 9145
targetPort: 9145
protocol: TCP
selector:
name: nginx
group: default
k8s的nginx的deployment记得在配置中加下端口:
containers:
ports:
- containerPort: 9023
最后是prometheus的serviceMonitor的配置:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nginx
namespace: monitoring
labels:
app.kubernetes.io/component: monitor
spec:
endpoints:
- port: metrics
path: /metrics
interval: 30s
- port: metrics
path: /upstreams_metrics
interval: 30s
namespaceSelector:
matchNames:
- default
selector:
matchExpressions:
- key: name
operator: In
values:
- nginx- 这样prometheus就抓取到nginx的监控数据了,接下来的就是在grafana中配置大屏进行展示,这个可以在grafana dashboard网页上找喜欢的界面,比如10223这个id,我这边是使用原始的界面然后改造了下,可以通过此链接下载json文件,需要的可以在grafana的导入按钮中输入json格式的数据来导入界面。
使用介绍
安装完之后,就可以看到上面成果介绍中的nginx监控大屏的效果了,他可以同时监控多个nginx实例,上半部分的全站监控数据,展示了所有nginx实例汇总过后的qps,连接数,错误数,延迟等信息,下半部分是按照主机维度或者pod维度汇总的对应数据。下面简单的介绍下:
qps: 可以用于查看每秒的请求数,确认是否有突增请求
平均活跃连接数: 用于查看客户端的连接数,如果突增,可能是内部处理慢了,需要查看是否有瓶颈
平均请求响应时间: 用于查看响应时间,如果太高,说明客户体验会收到严重影响,需要进行排查
5xx错误率 : 500状态码的占比,这个值升高的话,说明服务器内部出现了问题,无法处理请求,可以针对这个值增加监控预警,及时发现问题并处理。
upstream平均活跃连接数: 展示了以upstream来进行汇总的活跃连接数量,如果某个曲线比较高,说明对应的后端服务器处理慢,导致连接池溢出了,需要进行处理。需要注意的是,这里的前提是使用nginx的upstream来代理后端,并且启用keepalive 这个配置的连接池功能,这也是推荐的做法,能通过复用后端代理连接提高性能。
监控大屏设置了几个选项,这里也介绍下:
upstream汇总类型 : 用于设置下半部分的upstream活跃连接数,可以通过设置为pod来查看每个nginx实例的汇总代理连接数,如果这个值突增,那代表对应的nginx实例的后端代理有问题,可以使用upstream选项来查看是哪个后端服务组有问题 qps分组维度 : 用于设置下半部分的各个指标的分组维度,由pod和instant两种选项,分别按照nginx实例或者主机汇总,在出现突增情况时,可以用于确定是哪个实例有问题。 upstream pod和upstream: 用于指定某个实例或者后端代理来查看对应数据
排查问题方式
推荐可以先看下上半部分的整体数据,确认集群是否正常,然后再查看下半部分,确认出问题的实例。
出问题的维度有两种,一种是部分nginx实例有问题,此时可以通过按照pod分组查看监控找到问题实例,还有一种是某个后端代理服务有问题,此时可以通过upstream分组查看出问题的具体后端服务。
如果是某个后端服务有问题,比如处理请求很慢,就会出现nginx中的对应的后端代理连接数激增,然后因为连接数太多,导致nginx整体出现cpu使用率高,服务报错等情况,通过这个upstream连接数的监控就可以识别出 有问题的后端服务,快速查出问题。
异常监控
异常监控是指在使用lua处理请求时,如果有值得需要注意的情况,可以使用error级别进行打印,同时通过日志收集系统将error级别的日志过滤出来,导出到prometheus中作为监控。 这样,业务的lua异常和系统的异常就都导入到prometheus中了,可以通过查看这部分最新的数据来排查当前系统是否有问题,也可以通过增加监控来及时发现问题。
关于此部分,也可以查看笔者的另一篇文章监控利器:java异常监控,这篇文章具体介绍了导出java异常监控的优势和实现方式。
安装
- 可以在需要关注的地方手动加入打印,使用error级别的日志打印,如 ngx.log(ngx.ERR, "there is an error")
- error级别的日志在打印时会自带error的字符,在日志收集端将nginx日志中带有error字符的日志统一转存到一个文件,这个文件中的日志就都是error日志,包括用户打印的和nginx的系统异常日志。
- 使用mtail解析异常日志文件,将nginx的异常日志导出到prometheus中
- grafana增加界面显示最新的nginx异常,这是json文件的链接,可以通过复制json文件的内容,在grafana的导入界面导入。
使用方式
可以在界面直接查看,根据选择的日期区间,会显示指定时间范围内的nginx异常。这个监控主要有三种用法:
- 在prometheus中增加监控规则,当某一时刻突然出现很多异常时触发报警,用于及时发现问题
- 在排查nginx的问题时,查看此监控,可能会发现一些系统异常,说不定就能直接找到问题原因
- 在排查问题结束后,查看此监控,只有确保这个监控中的最近几分钟已经确实没有新异常了,才能大概率说明nginx的问题被解决了,只要还有不断地新增异常,说明问题并未彻底解决。
结语
以上就是这篇文章的内容,主要介绍了两种openresty的监控方式,希望对大家监控和排查nginx问题有帮助。