人工智能(AI)、机器学习、神经网络......这些词汇充斥着我们的生活,但它们究竟是如何运作的?
为什么以前的 AI 被称为"人工智障",而现在的 AI 却能通过图灵测试?本文将剥去高大上的术语外衣,带你深入理解 AI 的"黑盒"里究竟藏着什么秘密。
一、 起源与本质:什么是"智能"?
人工智能的起点可以追溯到 1956 年的达特茅斯会议,科学家们首次提出了"人工智能"这一概念。
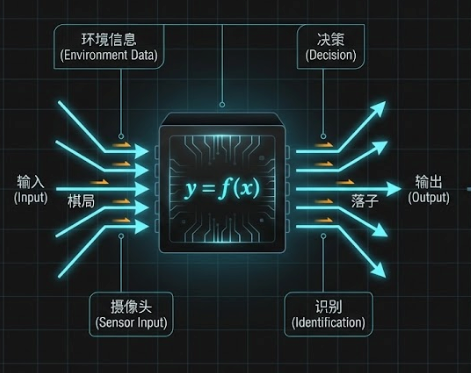
智能的本质是什么? 在计算机科学的视角下,智能就是一个函数(Function),或者说一个"超级黑盒"。它的作用是找到从"输入信息"到"针对性输出"之间的对应关系。
- 输入 () :环境信息(如棋局、用户提问、摄像头画面)。
- 输出 () :决策或反应(如落子位置、回答文本、识别结果)。
- 目标:这个黑盒不能乱来,它必须表现出类似生物的逻辑处理能力。图灵测试就是一种验证这个黑盒是否"像人"的标准。
二、 两条路线:符号主义 vs 连接主义
为了构建这个智能黑盒,人类探索了两条主要路径:
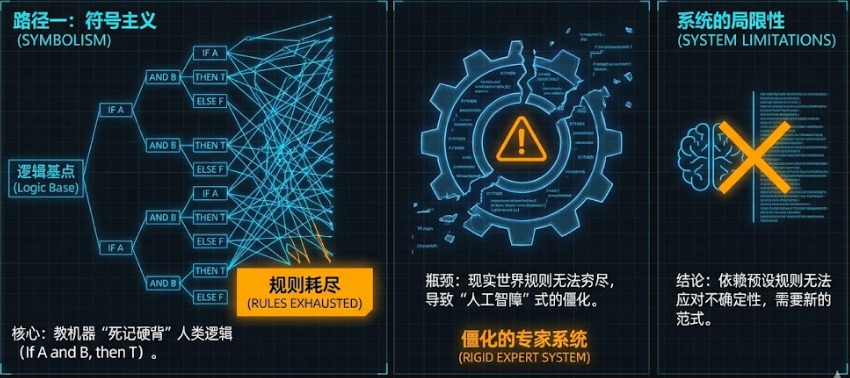
1. 符号主义 (Symbolism):教机器"死记硬背"
- 原理:试图用人类已知的逻辑规则(如"如果 A 且 B,则 T")来模拟智能。
- 代表:专家系统(将人类医生的诊断经验写成成千上万条代码规则)。
- 缺陷:现实世界太复杂,规则无法穷尽。这种方法做出来的 AI 往往很僵化,也就是早期常被嘲笑的"人工智障"。
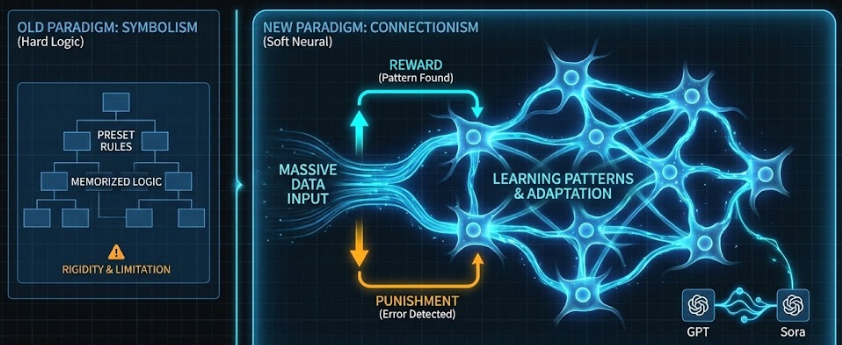
2. 连接主义 (Connectionism):教机器"像人脑一样思考"
- 原理:不预设规则,而是搭建一个具有学习能力的架构,模仿生物大脑的神经元连接。让机器通过"奖励"和"惩罚",从海量数据中自动寻找规律。
- 现状 :这就是 神经网络的基础,也是今天 GPT 和 Sora 成功的基石。
三、 神经网络的进化(上):感知机
这是最基础的 AI 模型。它的核心逻辑其实非常符合直觉,就像我们在脑海中给事物"打分"。
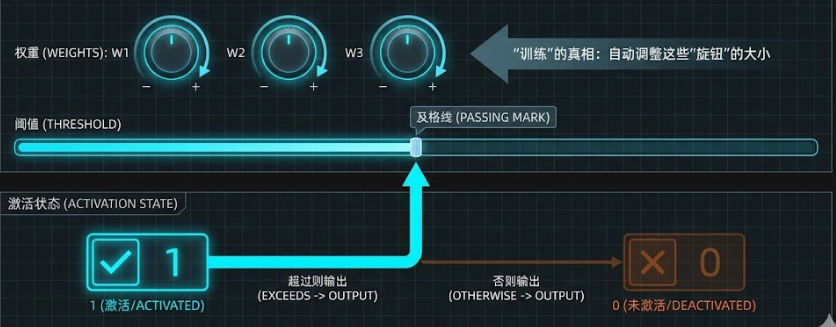
1. 感知机是如何工作的?(以"识别苹果"为例)
- 特征 (输入):假设我们要判断一个水果是不是苹果,我们看三个特征:颜色、味道、大小 。
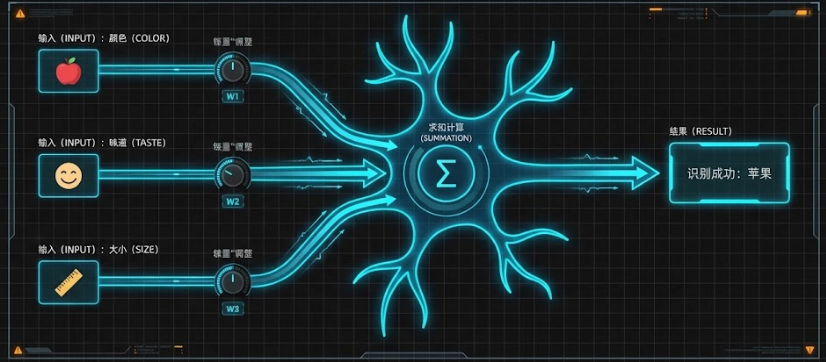
- 旋钮 (权重/Weights) :感知机给每个特征分配一个"系数"(即权重 )。
- 对于"颜色是红色"、"味道甜"这些符合苹果特征的,给 正系数(正向促进)。
- 对于"尺寸巨大(像西瓜)"、"味道酸"这些不符合的,给 负系数(负向抑制)。
- 打分与激活:感知机将所有特征乘以对应的系数,然后加在一起得到一个总分。
- 阈值 (Threshold) :设定一个及格线。如果总分超过这个线,感知机就"激活"(输出 1,认为是苹果);否则保持沉默(输出 0)。
所谓的**"训练"**,就是让机器自动调整这些"旋钮"的大小,直到它能准确地给苹果打高分,给橘子打低分。
2. 致命瓶颈:异或问题 (XOR) 与 第一次 AI 寒冬
1969 年,AI 先驱马文·明斯基(Marvin Minsky)指出了感知机的一个致命缺陷,直接导致了 AI 领域的第一次资金冻结(寒冬)。
- "一根筋"的直线 :感知机的数学本质是线性分类器。在二维平面上,它区分两类事物的方法是画一条直线。在这条线一边的判为 A,另一边的判为 B。
- 异或 (XOR) 困境: "异或"逻辑很简单:两个输入不同则为真,相同则为假。想象一下四个点在坐标系里:
- (0,0) 和 (1,1) 是"假"(同一类,位于对角线)。
- (0,1) 和 (1,0) 是"真"(另一类,位于另一条对角线)。
- 不可能的任务 :你能在纸上只画一条直线 ,就把 (0,0) 和 (1,1) 划在一边,同时把 (0,1) 和 (1,0) 划在另一边吗?答案是不可能。这就像你想用一刀切的方式,把对角线上的两个棋子切开一样,一条直线做不到。

因为连这么简单的逻辑都处理不了,当时的人们判定神经网络是"没用的玩物",导致了长达数十年的停滞。
四、 神经网络的进化(下):深度学习
为了解决这个"异或"难题,科学家们发现必须引入多层结构 。我们可以用一个**"专职助理"**的例子来理解它的妙处。
1. 从"光杆司令"到"分工合作"
场景:你想去打球,但有怪癖(异或逻辑) 假设你的决策规则如下:
- 如果朋友 A 和 B 都不来 :没意思, 不去。
- 如果朋友 A 和 B 都来 :太吵了, 不去。
- 只有当 其中一个人来 (且另一个人不来)时:你才 去。
单层感知机的失败 : 单个神经元就像一个只有"一根筋"的管家,他无法理解"必须只有一个人来"这种弯弯绕的逻辑,因为这需要把(都来)和(都不来)这两种极端情况同时排除掉。
多层感知机的成功 : 为了解决这个问题,你聘请了两个助理(这就是隐藏层 )和一个总管(输出层)。大家分工合作:
- 助理 1(专注情况 A) :盯着是不是 "A 来了但 B 没来"。
- 助理 2(专注情况 B) :盯着是不是 "B 来了但 A 没来"。
- 总管(输出层) :只要看到助理 1 或 助理 2 其中有一个举手,他就告诉你:"去!"
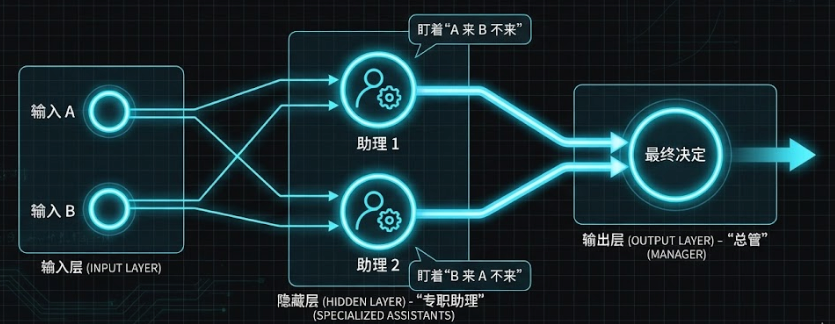
深度学习的诞生: 这就是多层神经网络的魔力:通过增加一层"助理"(隐藏层),网络不再需要试图用一条直线切分所有数据。它让每个神经元只负责识别一种特定的情况,最后再由输出层把这些特定情况组合起来。
这里有一个重要的数学结论:数学上证明,只要神经网络的层数够深、神经元够多,它就能模拟世界上任何复杂的函数关系(万能逼近定理)。
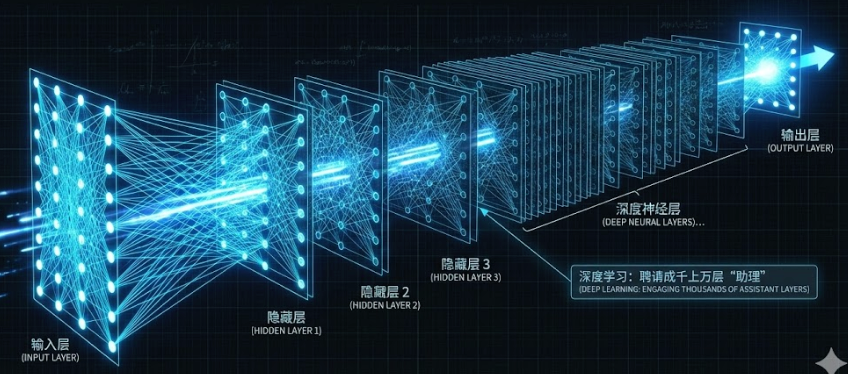
2. 现代架构的演进
既然多一层助理就能解决逻辑问题,那如果我们聘请成千上万层助理呢?这就是深度学习 (Deep Learning) :
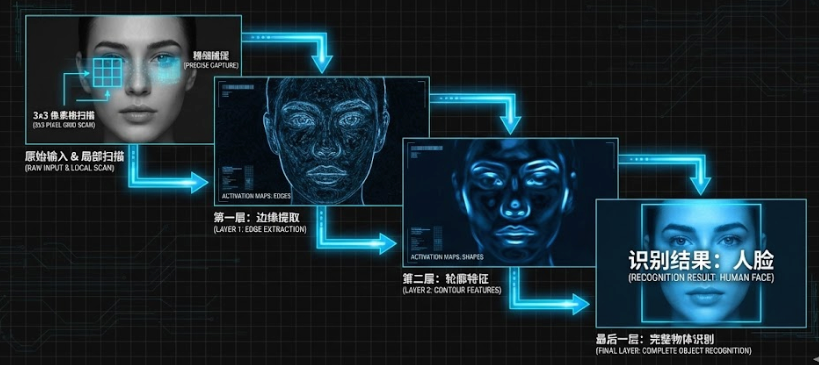
- CNN (卷积神经网络):像人眼一样"层层剥茧" 普通的神经网络(MLP)是"死板"的,它让每个神经元都盯着整张图的所有像素,这既浪费又低效。CNN 的灵感来自生物视觉皮层:
- 只看局部 (Local Scanning) :CNN 的神经元每次只扫描图像的一小块区域(比如 3x3 的像素格)。
- 层层提取 (Layered Extraction) :就像盖楼一样,每一层只负责把上一层的信息组合得更复杂一点。
- 基层:认出边缘、横线、竖线。
- 中层:把线条拼成"眼睛的轮廓"、"鼻子的三角"。
- 高层 :把形状拼成完整的"人脸"概念。 这种 **"局部扫描 + 层层组合"**的机制,让 CNN 成为了人脸识别、自动驾驶等领域的绝对王者。
- Transformer:聪明的"划重点"大师 如果说 CNN 擅长处理图像,那 Transformer 就是处理序列数据(如语言)的绝对王者,也是 ChatGPT 的基石。 它引入了 "注意力机制 (Attention)":不同于老式 AI 只能看前一个词,Transformer 能一眼看到整段话,并计算词与词之间的关联度。
- 比如在处理"天气太热了,我要开__"时,它会将极大的 注意力分配给"热",从而忽略不重要的助词,精准推断出"空调"。这让 AI 真正学会了"划重点"。
五、 机器是如何"学习"的?
神经网络拥有数以亿计的参数(旋钮),如何调节它们以达到最佳效果?这三个概念构成了神经网络"自我进化"的核心循环。如果把训练 AI 比作教一个学生考试,这三步就是**"改卷子 - 找原因 - 改错题"**的过程。
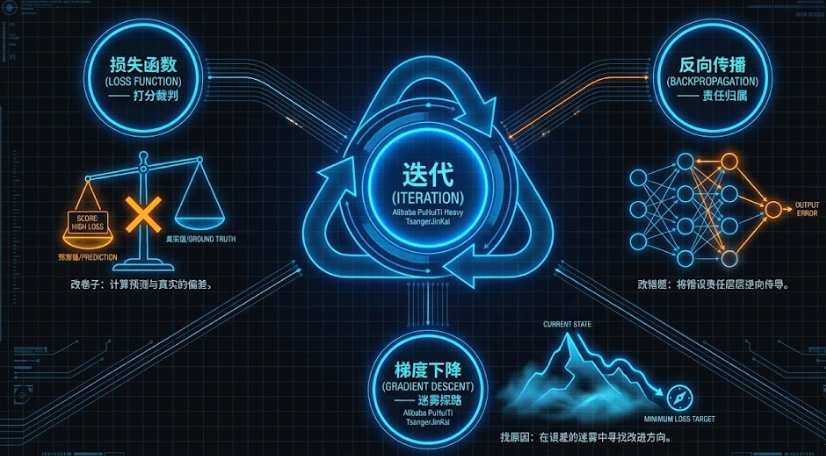
1. 损失函数 (Loss Function) ------ 打分裁判
- 衡量偏差的标尺:AI 做完题(预测)后,损失函数负责拿着"标准答案"来改卷子。
- 不仅仅是打分 :它不是只给"对"或"错",而是计算 "错得有多离谱"。比如预测房价,真实是 100 万,AI 猜 10 万,误差(Loss)就非常大;猜 90 万,误差就小。
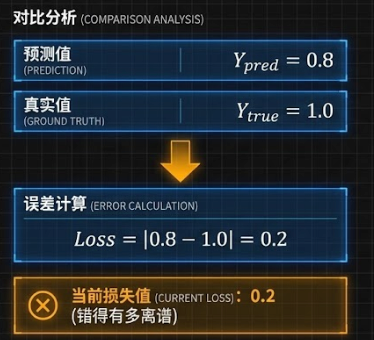
- 目标 :整个训练过程的唯一目标,就是想尽办法让这个损失函数的值变为 0(或者尽可能小)。 但要注意,我们的最终目标是让 AI 学会通用的规律,而不是死记硬背训练题的标准答案(这叫"过拟合")。
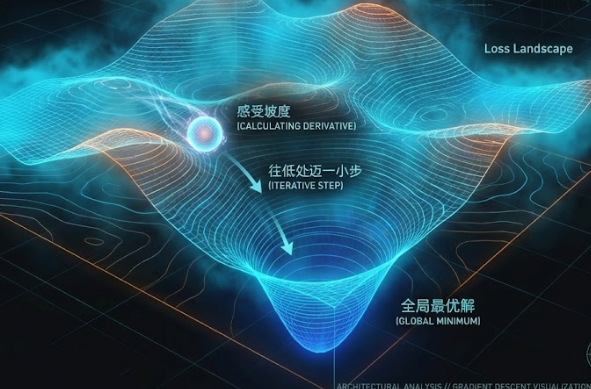
2. 梯度下降 (Gradient Descent) ------ 迷雾探路
- 困境:AI 有几亿个参数(旋钮),就像站在一个地形极度复杂的山上,周围全是大雾,根本看不见哪里是山脚(最优解)。
- 策略(求导):虽然看不见远方,但你可以感觉到脚下的坡度。你伸脚探一探,发现往某个方向走是"下坡"(误差变小),往反方向是"上坡"。
- 迈步(迭代) :既然找到了下坡的方向,就沿着这个方向走一小步(更新参数)。每走一步,就重新探一次路。只要坚持 "每次都往低处走一点点",最终就能摸索着走到山谷底部(误差最小的地方)。
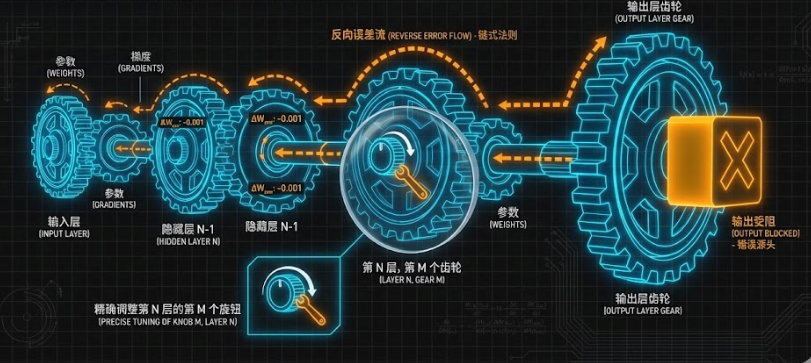
3. 反向传播 (Backpropagation) ------ 责任归属
- 难题:如果是一个深层网络(比如 GPT),输出层算出了误差,但这个误差是由前面 100 层里成千上万个参数共同导致的。到底是谁的锅?每个参数该背多少锅?
- 解决(齿轮传动):利用数学上的链式法则(就像齿轮咬合传动),从输出层的误差开始,一层层向回计算。
- 精确归责:它能算出,为了消除这个误差,第 50 层的第 3 个神经元的参数需要调大一点点,而第 2 层的第 9 个参数需要调小很多。它为梯度下降提供了"导航图"。
总结一下它们的配合流程:
- 前向传播:AI 猜一个结果。
- 损失函数:算出猜得有多错(Loss)。
- 反向传播:算出每个参数对这个错误负多少责任(梯度)。
- 梯度下降:根据责任大小,把所有参数都往"正确"的方向微调一点点。
这就是机器"学习"的本质:在数万次这样的循环中,一点点修正误差,直到变成专家。
结语:通往魔法的阶梯
到这里,我们已经拆解了 AI 最底层的原理:它不是魔法,而是数学诗篇。
- 它通过 神经网络模拟大脑连接;
- 通过 深度学习(CNN/Transformer)理解复杂的图像和语言逻辑;
- 通过 反向传播 和 梯度下降进行自我纠正和进化。
至此,我们终于揭开了这个'黑盒'的盖子。里面并没有神秘的魔法,只有梯度下降的执着和反向传播的纠错。但这正是 AI 最迷人之处:**它用数学公式,在数万亿次迭代中,涌现出了最接近人类的智慧火花。**理解了这些,你就不仅仅是 AI 的使用者,而是这场技术变革清醒的见证者。
本文由mdnice多平台发布