分布式定时任务与SELECT FOR UPDATE:从致命陷阱到优雅解决方案(实战案例+架构演进)
摘要
在微服务架构中,分布式定时任务已成为业务处理的核心组件。然而,许多开发者从单体应用迁移到分布式环境时,仍然沿用传统"线程池+SELECT FOR UPDATE"方案,导致订单重复关闭、数据库连接池耗尽等严重故障。
本文通过电商、支付等真实生产案例,深入剖析分布式定时任务的五大陷阱,提供五种可直接落地的解决方案,并配套完整监控告警体系,帮助企业平滑完成分布式架构演进。
一、引言:分布式定时任务的现实挑战
1.1 真实故障案例:电商平台数十万资损事故
在主导某电商平台微服务迁移过程中,我们曾因沿用单体时代的"线程池+SELECT FOR UPDATE"方案,导致线上出现订单重复关闭 和数据库连接池耗尽两大严重故障。故障期间,用户已支付订单被错误关闭,退款重复发起,直接造成数十万元资损。
1.2 分布式定时任务的本质变化
从单体架构到微服务架构,定时任务的执行环境发生了根本性变化:
| 维度 | 单体环境 | 分布式环境 |
|---|---|---|
| 执行节点 | 单节点,唯一执行者 | 多节点,可能存在多个执行者 |
| 时钟同步 | 本地时钟一致 | NTP同步存在毫秒级误差 |
| 任务协调 | 无需协调 | 需要分布式协调机制 |
| 故障影响 | 节点宕机=任务停止 | 需支持故障转移 |
| 数据一致性 | 简单的事务控制 | 需要分布式锁/乐观锁机制 |
二、分布式环境下线程池定时任务的"五大陷阱"
2.1 时间同步难题:毫秒误差引发的数据错乱
案例背景:某政务数据同步系统,3个节点部署定时任务,因节点时钟未严格同步(NTP同步存在100ms误差),导致数据同步任务出现时间错乱。
节点3(慢100ms) 节点2(正常) 节点1(快100ms) 标准时间 节点3(慢100ms) 节点2(正常) 节点1(快100ms) 标准时间 三节点任务执行时间差达200ms 数据同步出现重复和缺失 00:05:00.000 00:04:59.900 触发任务 00:05:00.000 触发任务 00:05:00.100 触发任务
核心问题:
- 服务器系统时间存在天然差异
- NTP同步仅能控制在毫秒级,无法满足精准调度需求
- 跨时区部署时时间差问题进一步放大
2.2 任务重复执行:电商订单的重复关闭噩梦
故障案例:某电商平台"订单超时关闭"定时任务,部署3个节点后出现同一笔订单被多个节点同时关闭。
java
// 危险代码:多节点同时执行的定时任务
@Scheduled(cron = "0 */5 * * * ?")
public void closeTimeoutOrders() {
// 所有节点都会执行相同的逻辑
List<Order> timeoutOrders = orderDao.findTimeoutOrders();
timeoutOrders.forEach(order -> {
orderService.closeOrder(order.getId());
refundService.initiateRefund(order.getId());
});
}订单超时关闭任务
订单ID:1001
状态:待支付
Node1执行关闭
Node2执行关闭
Node3执行关闭
订单重复关闭3次
重复退款3次
资损:订单金额×3
业务影响分析:
- 订单类:重复关闭、重复支付回调
- 消息类:短信/推送重复发送,引发用户投诉
- 计算类:数据重复统计,导致报表失真
2.3 负载不均与雪崩效应:支付系统的连接池耗尽
案例背景:某支付系统的"交易流水对账"任务,3个节点同时全量拉取10万+条流水,数据库CPU瞬间100%。
数据库压力分析
流水表:10万条记录
Node1:全量拉取10万条
Node2:全量拉取10万条
Node3:全量拉取10万条
CPU:100%
连接池耗尽
正常支付交易无法入库
系统雪崩持续15分钟
监控指标异常:
- 数据库连接池使用率:0% → 100%(3秒内)
- 数据库CPU使用率:30% → 100%
- 应用响应时间:50ms → 5000ms+
2.4 单点故障:政务系统的数据上报中断
故障案例:某政务系统的"数据定时上报"任务仅部署在单个节点,节点宕机导致数据上报中断8小时。
故障情况
正常情况
数据上报定时任务
Node1:唯一执行节点
数据上报成功
业务正常
服务器硬件故障
节点宕机
任务中断8小时
数据无法同步
被通报批评
教训总结:
- 分布式环境下必须有故障转移机制
- 关键业务任务需要多节点部署
- 需要监控任务执行状态
2.5 弹性伸缩困境:初创公司的积分清零问题
问题场景:某初创公司用户积分清零任务,扩容后新增节点不参与任务分担,缩容时任务直接丢失。
java
// 问题代码:弹性伸缩不友好的定时任务
@Scheduled(cron = "0 0 0 * * ?")
public void clearUserPoints() {
// 所有节点都执行全量任务
// 新增节点:不会分担任务,资源浪费
// 缩容节点:任务丢失,部分用户积分未清零
userDao.clearExpiredPoints();
}弹性伸缩问题:
- 扩容无效:新增节点不会自动分担任务
- 缩容丢任务:被缩容节点上的任务直接丢失
- 资源浪费:多节点重复执行相同任务
三、SELECT FOR UPDATE:分布式环境下的致命陷阱
3.1 数据库锁竞争风暴:支付系统的连接池耗尽
故障重现:3个节点同时执行SELECT FOR UPDATE,大量连接阻塞在锁等待上。
sql
-- 问题SQL:无限制的行锁
BEGIN;
SELECT * FROM refund_orders
WHERE status = 'PENDING'
ORDER BY create_time ASC
FOR UPDATE; -- 获取所有待处理退款订单并加锁
-- 事务持续5-10秒,锁持有时间过长
COMMIT;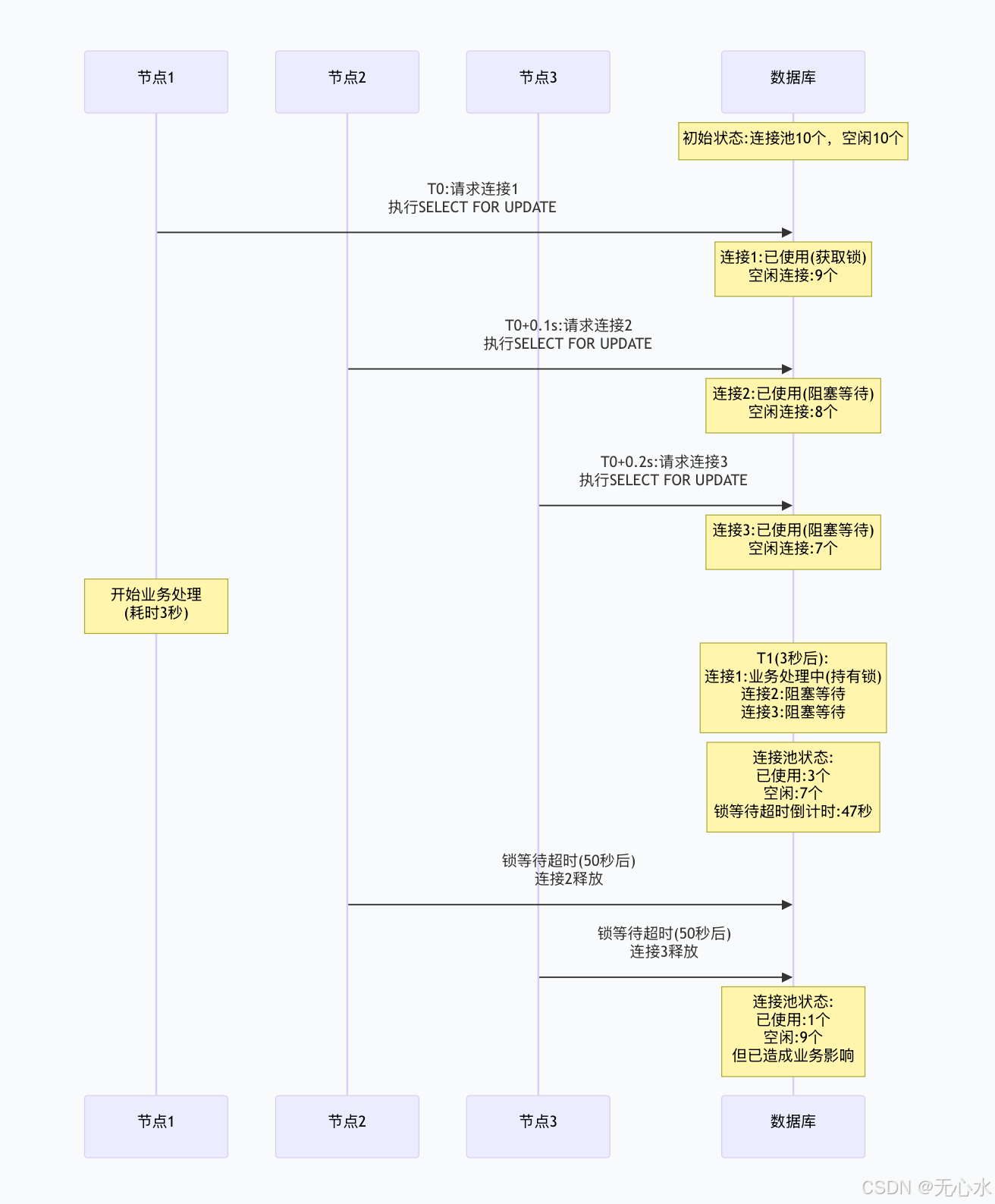
监控告警指标:
- 数据库连接池使用率 > 90%
- 锁等待时间 > 100ms
- 死锁次数 > 0
- 事务执行时间 > 5s
3.2 死锁完美风暴:订单与余额的交叉锁定
死锁场景:订单处理与用户余额更新形成交叉锁依赖。
sql
-- 死锁发生过程
-- T1: Node1 锁定订单表,等待用户表
BEGIN;
SELECT * FROM orders WHERE id = 1001 FOR UPDATE; -- 锁定订单1001
-- T2: Node2 锁定用户表,等待订单表
BEGIN;
SELECT * FROM users WHERE id = 2001 FOR UPDATE; -- 锁定用户2001
-- T3: Node1 尝试锁定用户表(等待Node2释放)
SELECT * FROM users WHERE id = 2001 FOR UPDATE; -- 等待用户锁
-- T4: Node2 尝试锁定订单表(等待Node1释放)
SELECT * FROM orders WHERE id = 1001 FOR UPDATE; -- 等待订单锁
-- ⚡ DEADLOCK DETECTED ⚡死锁检测流程图
事务1:锁定订单1001
事务2:锁定用户2001
事务1请求用户2001锁
事务2请求订单1001锁
检测到循环等待
数据库死锁检测机制触发
选择代价小的事务回滚
事务2回滚释放锁
事务1继续执行
死锁解除
3.3 长事务连锁反应:订单核销的阻塞效应
问题分析:SELECT FOR UPDATE在长事务中持有锁时间过长,阻塞其他业务操作。
java
@Transactional
public void processOrderVerification(Long orderId) {
// 1. 锁定订单记录(行锁生效)
Order order = orderDao.lockOrderForUpdate(orderId);
// 2. 调用外部核销服务(平均3秒)
thirdPartyService.verify(order);
// 3. 更新本地状态(1秒)
orderDao.updateStatus(orderId, "VERIFIED");
// 4. 发送通知(1秒)
notificationService.sendVerificationSuccess(order);
// 总耗时5-10秒,锁持有时间过长!
}影响范围:
- 其他操作该订单的任务全部阻塞
- 数据库连接池被长时间占用
- 系统吞吐量急剧下降
四、综合解决方案:从"蛮力"到"智慧"
4.1 方案一:分布式调度框架(XXL-Job/Elastic-Job)
适用场景:订单定时处理、数据同步、批量计算等中大型分布式场景。
架构优势:
- 统一调度中心,避免多节点重复执行
- 支持任务分片,实现负载均衡
- 故障自动转移,无单点故障
- 完善的监控告警体系
任务分片
执行层
调度层
XXL-Job Admin
调度中心集群
任务配置管理
调度触发
故障转移
监控告警
执行器节点1
执行器节点2
执行器节点3
任务数据分片1
任务数据分片2
任务数据分片3
数据处理完成
结果上报
实战代码:
java
// XXL-Job分布式定时任务实现
@XxlJob("orderTimeoutCloseJob")
public ReturnT<String> orderTimeoutCloseJob(String param) {
// 获取分片参数
ShardingUtil.ShardingVO sharding = ShardingUtil.getShardingVo();
int total = sharding.getTotal(); // 总分片数
int index = sharding.getIndex(); // 当前分片索引
// 按分片查询数据,避免重复处理
List<Order> orders = orderDao.findTimeoutOrdersByShard(total, index);
// 批量处理
orders.forEach(order -> {
try {
orderService.closeTimeoutOrder(order.getId());
} catch (Exception e) {
XxlJobLogger.log("订单{}关闭失败: {}", order.getId(), e.getMessage());
}
});
return ReturnT.SUCCESS;
}4.2 方案二:Redis分布式锁优化
适用场景:库存定时扣减、定时对账、数据清理等轻量级任务。
执行流程:
是
否
定时任务触发
尝试获取Redis锁
获取成功?
执行业务逻辑
释放Redis锁
任务完成
放弃执行
记录日志:其他节点正在处理
执行异常
确保锁释放
异常处理
实战代码:
java
@Component
public class InventoryDeductScheduler {
private final RedissonClient redissonClient;
private final String LOCK_KEY = "lock:inventory:deduct";
@Scheduled(fixedDelay = 10000)
public void deductInventory() {
RLock lock = redissonClient.getLock(LOCK_KEY);
try {
// 尝试获取锁,等待3秒,锁超时30秒
if (lock.tryLock(3, 30, TimeUnit.SECONDS)) {
try {
// 获取锁成功,执行库存扣减
executeInventoryDeduct();
} finally {
lock.unlock();
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}4.3 方案三:乐观锁+重试机制
适用场景:低并发数据更新场景,如用户积分更新、配置同步。
执行流程:
是
否
是
否
开始处理
查询数据+版本号
执行业务逻辑
更新数据+版本号条件
更新成功?
处理成功
乐观锁冲突
重试次数<3?
等待100ms后重试
记录失败入人工队列
实战代码:
java
@Service
public class OptimisticLockService {
@Retryable(value = OptimisticLockingFailureException.class, maxAttempts = 3)
public void updateWithOptimisticLock(Long id) {
// 1. 查询数据(带版本号)
UserPoints points = userPointsDao.findById(id);
// 2. 执行业务计算
points.setPoints(points.getPoints() - calculateExpiredPoints(points));
points.setVersion(points.getVersion() + 1);
// 3. 带版本号更新
int rows = userPointsDao.updateWithVersion(
points.getId(),
points.getPoints(),
points.getVersion() - 1,
points.getVersion()
);
if (rows == 0) {
throw new OptimisticLockingFailureException("乐观锁冲突");
}
}
}4.4 方案四:消息队列解耦架构
适用场景:高并发异步处理,如消息推送、日志处理。
架构图:
业务处理
消费者层
消息队列层
生产者层
定时任务生产者
拉取待处理任务
推送至消息队列
标记任务状态
RabbitMQ/Kafka
消息持久化
负载均衡
幂等性保证
消费者节点1
消费者节点2
消费者节点3
处理任务1
处理任务2
处理任务3
4.5 方案五:SELECT FOR UPDATE SKIP LOCKED
适用场景:PostgreSQL/MySQL 8.0+,不想引入中间件的小型系统。
执行原理:
sql
-- 跳过已锁定的行,避免等待
SELECT * FROM orders
WHERE status = 'PENDING'
ORDER BY create_time
LIMIT 10
FOR UPDATE SKIP LOCKED; -- 关键:跳过已锁定行五、架构设计最佳实践
5.1 分层任务调度架构
接入层: 负载均衡
调度层: XXL-Job
队列层: RabbitMQ
执行层: Worker集群
存储层: 数据库/缓存
监控层: Prometheus
告警层: AlertManager
通知渠道: 钉钉/邮件
5.2 数据库优化配置
yaml
# 连接池优化配置
spring:
datasource:
hikari:
maximum-pool-size: 20 # CPU核心数×2+1
minimum-idle: 5 # 最小空闲连接
idle-timeout: 300000 # 5分钟
max-lifetime: 1800000 # 30分钟
connection-timeout: 3000 # 3秒连接超时
# 事务配置
@Configuration
@EnableTransactionManagement
public class TransactionConfig {
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
DataSourceTransactionManager manager = new DataSourceTransactionManager(dataSource);
manager.setDefaultTimeout(30); # 全局事务超时30秒
return manager;
}
}5.3 熔断降级机制
java
@CircuitBreaker(name = "orderService", fallbackMethod = "fallback")
@TimeLimiter(name = "orderService")
@Retry(name = "orderService")
public CompletableFuture<Order> processOrder(Long orderId) {
return CompletableFuture.supplyAsync(() -> {
// 业务处理逻辑
return orderService.process(orderId);
});
}
// 降级方法
public CompletableFuture<Order> fallback(Long orderId, Throwable t) {
log.warn("订单处理降级, orderId: {}", orderId, t);
// 入延迟队列,后续重试
delayQueue.offer(orderId);
return CompletableFuture.completedFuture(null);
}六、监控与告警体系
6.1 核心监控指标
| 监控维度 | 指标名称 | 告警阈值 | 监控工具 |
|---|---|---|---|
| 任务调度 | 任务执行成功率 | <99% | Prometheus |
| 任务调度 | 任务执行耗时 | >10秒 | Grafana |
| 数据库 | 锁等待时间 | >100ms | MySQL监控 |
| 数据库 | 死锁次数 | >0 | 慢查询日志 |
| 系统资源 | CPU使用率 | >80% | Node Exporter |
| 系统资源 | 内存使用率 | >85% | Node Exporter |
6.2 Prometheus监控配置
yaml
# prometheus.yml
scrape_configs:
- job_name: 'scheduled-tasks'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['node1:8080', 'node2:8080']
labels:
application: 'order-service'
- job_name: 'mysql-exporter'
static_configs:
- targets: ['mysql-exporter:9104']
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']6.3 Grafana监控面板
json
{
"panels": [
{
"title": "任务执行成功率",
"targets": [
{
"expr": "rate(scheduled_task_success_total[5m]) / rate(scheduled_task_total[5m]) * 100",
"legendFormat": "{{job}}"
}
],
"thresholds": [
{
"value": 99,
"color": "red"
}
]
}
]
}七、总结与展望
7.1 技术选型建议
根据业务场景选择合适的解决方案:
| 场景特征 | 推荐方案 | 优势 |
|---|---|---|
| 中大型分布式系统 | 分布式调度框架 | 功能完善,支持分片、监控 |
| 轻量级定时任务 | Redis分布式锁 | 简单易用,无单点故障 |
| 低并发数据更新 | 乐观锁+重试 | 无锁竞争,性能高 |
| 高并发异步处理 | 消息队列解耦 | 解耦彻底,支持弹性伸缩 |
| 数据库原生方案 | SKIP LOCKED | 无需中间件,数据库原生支持 |
7.2 实施路线图
- 评估阶段:分析现有定时任务问题,收集监控数据
- 试点阶段:选择非核心业务进行方案验证
- 推广阶段:逐步迁移核心业务定时任务
- 优化阶段:根据监控数据持续优化配置
- 自动化阶段:建立自动扩缩容、自愈机制
7.3 未来发展趋势
- Serverless定时任务:基于云函数的定时任务执行
- AI智能调度:根据历史数据预测任务执行时间
- 混沌工程:定期进行故障演练,验证系统韧性
- 多云部署:跨云厂商的定时任务高可用部署
结语
分布式环境下的定时任务管理是微服务架构中的关键技术挑战。通过理解传统方案的陷阱,采用合适的分布式解决方案,结合完善的监控告警体系,企业可以构建稳定、高效、可扩展的定时任务处理系统。本文提供的五种解决方案已在多个生产环境验证,读者可根据自身业务场景选择实施,平滑完成从单体到分布式的架构演进。
关键词:分布式定时任务、SELECT FOR UPDATE、微服务架构、数据库锁竞争、任务调度、Redis分布式锁、消息队列、监控告警、架构优化