Day 49通道注意力机制 @浙大疏锦行
概念
- 目的:让神经网络自动学习每个特征通道的重要性,从而增强有用的特征通道,抑制无用的特征通道。
- 实现步骤 :
- Squeeze (压缩) :
- 使用全局平均池化 (
nn.AdaptiveAvgPool2d(1))。 - 将形状为 ( B , C , H , W ) (B, C, H, W) (B,C,H,W) 的特征图压缩为 ( B , C , 1 , 1 ) (B, C, 1, 1) (B,C,1,1),使每个通道获得全局感受野。
- 使用全局平均池化 (
- Excitation (激励) :
- 使用两个全连接层(FC)组成的"瓶颈"结构。
- 第一个 FC 将通道数降低(
reduction_ratio=16),减少计算量并引入非线性。 - 第二个 FC 将通道数恢复。
- 最后通过
Sigmoid激活函数,输出每个通道的权重(范围 0~1)。
- Scale (重标定) :
- 将生成的通道权重与原始特征图相乘 (
x * y),完成特征重标定。
- 将生成的通道权重与原始特征图相乘 (
- Squeeze (压缩) :
代码
模型对比
python
# 基础CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.pool3 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(128 * 4 * 4, 512)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.bn1(self.conv1(x))))
x = self.pool2(self.relu2(self.bn2(self.conv2(x))))
x = self.pool3(self.relu3(self.bn3(self.conv3(x))))
x = x.view(-1, 128 * 4 * 4)
x = self.fc2(self.dropout(self.relu3(self.fc1(x))))
return x
# 通道注意力模块 (SE Block)
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
# 带通道注意力的CNN模型
class CNN_SE(nn.Module):
def __init__(self):
super(CNN_SE, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU()
self.ca1 = ChannelAttention(32)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU()
self.ca2 = ChannelAttention(64)
self.pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.ca3 = ChannelAttention(128)
self.pool3 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(128 * 4 * 4, 512)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = self.pool1(self.ca1(self.relu1(self.bn1(self.conv1(x)))))
x = self.pool2(self.ca2(self.relu2(self.bn2(self.conv2(x)))))
x = self.pool3(self.ca3(self.relu3(self.bn3(self.conv3(x)))))
x = x.view(-1, 128 * 4 * 4)
x = self.fc2(self.dropout(self.relu3(self.fc1(x))))
return x代码中定义了两个模型进行对比:
- 基础 CNN (
CNN) :- 包含 3 个卷积块(Conv -> BN -> ReLU -> MaxPool)。
- 最后接全连接层进行分类。
- 带注意力的 CNN (
CNN_SE) :- 结构与基础 CNN 类似。
- 关键区别 :在每个卷积块的 ReLU 激活之后、池化之前,插入了
ChannelAttention模块。
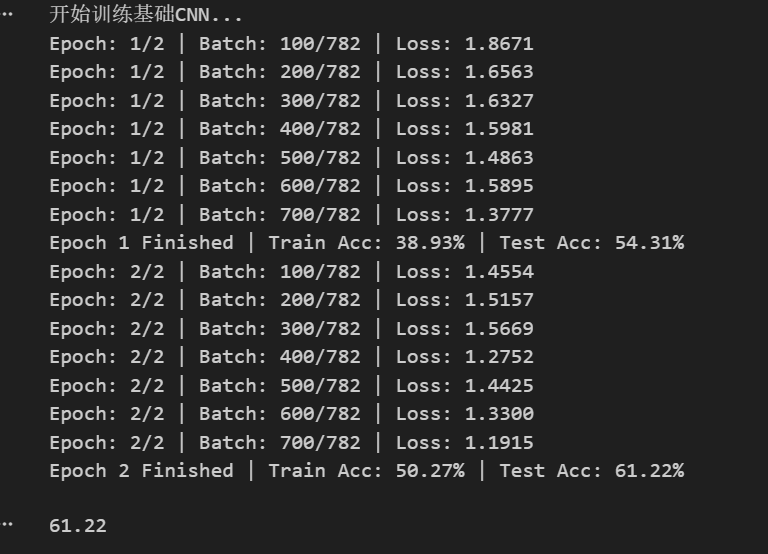
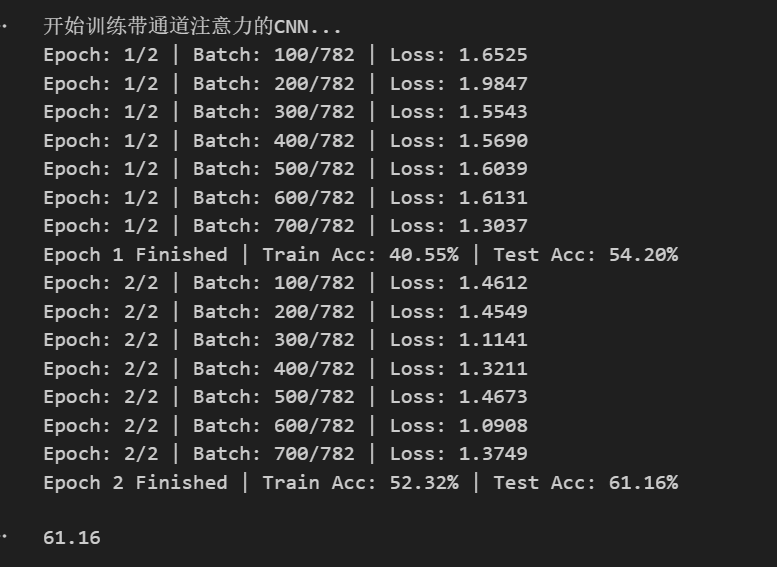
训练
- 定义了
train_and_log函数,统一管理训练循环。 - 记录了每个 Epoch 和 Batch 的 Loss 及 Accuracy,并保存到 CSV 文件中以便后续分析。
- 使用了
Adam优化器和ReduceLROnPlateau学习率调度策略。
可视化
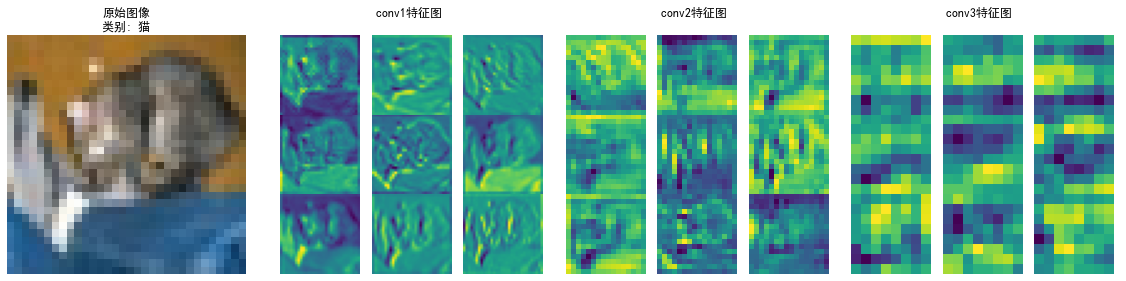
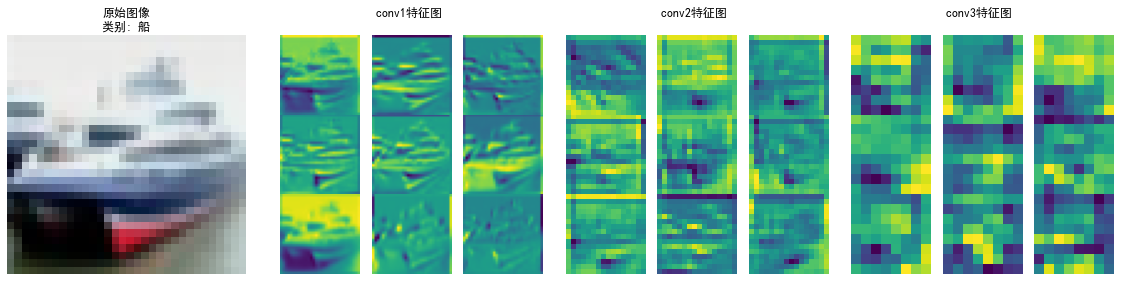
- 特征图可视化 (
visualize_feature_maps) :- 展示模型中间层(如 conv1, conv2, conv3)输出的特征图。
- 帮助理解网络在不同深度提取了什么样的视觉特征(边缘、纹理、部件等)。
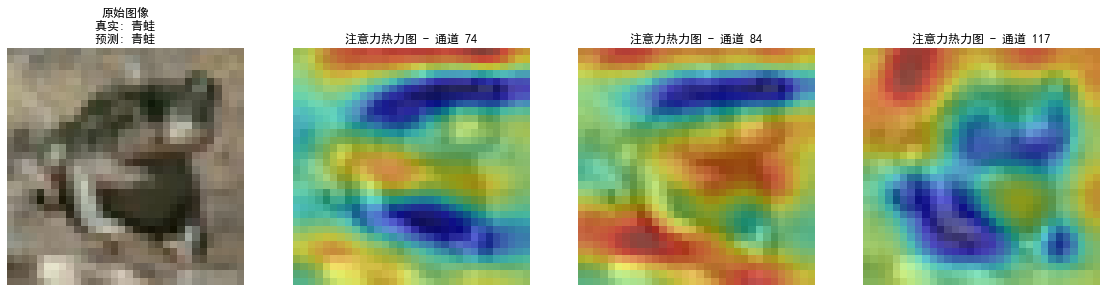
- 注意力热力图 (
visualize_attention_map) :- 提取卷积层输出,计算通道均值作为权重。
- 将高响应的通道特征图叠加在原图上。
- 作用:直观展示模型在进行分类决策时,主要"关注"图像的哪些区域(例如是否聚焦在物体主体上)。
总结
通过在卷积神经网络中引入通道注意力机制(SE Block),模型能够以极小的计算代价(少量的参数增加),显式地建模通道间的依赖关系,从而提升特征表示能力。这种机制是即插即用的,可以方便地集成到现有的 CNN 架构中。
Block),模型能够以极小的计算代价(少量的参数增加),显式地建模通道间的依赖关系,从而提升特征表示能力。这种机制是即插即用的,可以方便地集成到现有的 CNN 架构中。