在MySQL数据库运维过程中,开发或运维人员误执行`DELETE`无过滤条件、`UPDATE`缺少`WHERE`子句等操作,导致批量数据错误或丢失的场景时有发生。传统的备份恢复方式往往耗时久、影响范围广,而MySQL Flashback(闪回)技术基于binlog解析,能快速生成反向操作SQL,精准恢复误操作数据,且无需停机,极大降低业务影响。本文将先梳理主流MySQL闪回工具,再结合真实案例,详解最优工具的恢复实操流程。数据恢复🐧 1786283847
一、主流MySQL数据恢复工具对比
MySQL批量数据误操作恢复的核心是解析binlog日志(需提前开启并配置为ROW格式),生成反向执行语句。目前主流的闪回工具主要有3款,各有优劣,具体对比如下:
|------------|----------|---------------|------------------------|----------|------------|----------------------|--------------------------|
| 工具名称 | 开发语言 | 支持MySQL版本 | 核心特性 | 离线解析 | 最后更新时间 | 优势 | 劣势 |
| binlog2sql | Python | 5.7 | 生成回滚SQL/原始SQL,支持库表过滤 | 否 | 2018.10 | 安装简单、SQL可直接审核执行 | 不支持8.0版本、无离线解析能力、长期未更新 |
| MyFlash | C | 5.7 | 生成回滚binlog文件,支持GTID过滤 | 是 | 2020.11 | 解析速度快、支持多条件过滤 | 不支持8.0版本、仅支持单个binlog文件解析 |
| my2sql | Go | 5.7 / 8.0 | 生成回滚/原始SQL、DML统计、长事务分析 | 是 | 2022.11 | 支持高版本、离线解析、功能全面、性能优异 | 需手动配置依赖,对新手有一定门槛 |
综合对比来看,my2sql 是当前最优选择------支持MySQL 8.0(主流线上版本)、离线解析避免影响主库、功能覆盖恢复与事务分析,且性能优于binlog2sql,兼容性强于MyFlash,因此下文将以my2sql为核心,结合真实案例讲解数据恢复流程。
二、恢复前提与环境说明
2.1 必备前提(核心!)
闪回工具依赖binlog实现数据恢复,需提前满足以下配置条件,否则无法正常使用:
- MySQL已开启binlog日志:`log_bin = ON`
- binlog格式为ROW模式:`binlog_format = ROW`(仅ROW模式能记录行级完整变更,支持精准恢复)
- binlog行镜像为完整模式:`binlog_row_image = FULL`(记录字段完整新旧值,避免恢复数据缺失)
- 误操作后表结构未变更(无增删列、修改字段类型等DDL操作)
- 误操作对应的binlog文件未被清理(需提前配置合理的binlog保留策略)
2.2 测试环境信息
本次案例基于以下环境模拟误操作与恢复,贴近线上真实场景:
- MySQL版本:8.0.32
- 数据库名:test_db
- 数据表:user(核心业务表,存储用户信息)
- 表结构:`id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(50), age INT, status TINYINT(1) DEFAULT 1`
- 当前数据量:1000条(id 1~1000,status均为1,代表正常用户)
三、binlog原理深度解析
闪回工具(如my2sql)的核心是解析MySQL的binlog日志,生成反向操作SQL。要理解闪回恢复的本质,需先掌握binlog的内部格式、事件(event)结构及核心event的作用------binlog本质是MySQL记录数据变更的"日志文件",以二进制格式存储,通过事件序列完整记录数据库的所有DML(增删改)、DDL(建表/删表)操作,是数据恢复、主从复制的核心依赖。
3.1 binlog概述与核心作用
binlog(Binary Log,二进制日志)是MySQL的核心日志之一,默认关闭,需手动配置开启。其核心作用包括:
- 数据恢复:通过解析binlog,还原指定时间/操作范围的数据变更,应对误操作场景;
- 主从复制:主库将binlog同步给从库,从库解析binlog并重放操作,实现主从数据一致;
- 审计追溯:记录所有数据变更操作,可追溯某条数据的修改历史、操作人及时间。
binlog以"文件序列"形式存储,每个binlog文件大小默认1G(可通过`max_binlog_size`配置),文件名为`mysql-bin.xxxxxx`(xxxxxx为递增数字),同时存在`mysql-bin.index`索引文件,记录所有binlog文件的路径与顺序。
3.2 binlog内部格式(三种模式对比)
binlog有三种存储格式,由`binlog_format`参数控制,不同格式的日志记录粒度、适用场景差异极大,其中仅ROW模式支持闪回工具的精准恢复,这也是前文"恢复前提"中强制要求`binlog_format=ROW`的原因。三种格式对比如下:
|-----------------|--------------------------------------------------------|-----------------------------------------------------------|--------------------|------------------------------------------|
| 格式类型 | 记录方式 | 核心特点 | 日志体积 | 对闪回的支持 |
| STATEMENT(语句模式) | 记录执行的SQL语句本身(如`UPDATE user SET status=0`) | 不记录行级变更,依赖SQL语句上下文;可能存在"主从不一致"(如使用`NOW()`、`RAND()`函数) | 最小 | 不支持:无法获取行级新旧值,无法生成精准反向SQL |
| ROW(行模式) | 记录每一行数据的"变更细节"(如某行数据从`status=1`变成`status=0`的完整新旧值) | 记录粒度最细,主从复制无歧义;不依赖SQL语句上下文,仅关注行数据变更 | 最大(批量操作时会记录每一行的变更) | 完全支持:可提取行级新旧值,是闪回恢复的唯一可靠格式 |
| MIXED(混合模式) | 自动切换模式:简单SQL用STATEMENT,复杂SQL(含函数、子查询)用ROW | 兼顾日志体积与一致性,但模式切换不可控 | 中等 | 部分支持:仅ROW模式记录的操作可闪回,STATEMENT模式记录的操作无法闪回 |
补充说明:ROW模式下,`binlog_row_image`参数控制行数据的记录范围------`FULL`(默认)记录行的完整新旧值,`MINIMAL`仅记录变更字段和主键,`NOBLOB`不记录BLOB/TEXT字段。闪回恢复需配置为`FULL`,否则会因缺少字段值导致回滚SQL不完整。
3.3 binlog事件(Event)结构与核心类型
binlog文件并非存储原始SQL,而是由一系列"事件(Event)"组成的二进制流。每个Event对应一次数据变更或日志管理操作,包含"事件头"和"事件体"两部分:
- 事件头(Event Header):固定长度,包含事件类型、事件长度、创建时间、服务器ID、binlog位置(pos)等元信息,用于定位和解析事件;
- 事件体(Event Body):可变长度,存储具体的操作内容(如行数据的新旧值、SQL语句、表结构信息等),不同类型的Event结构不同。
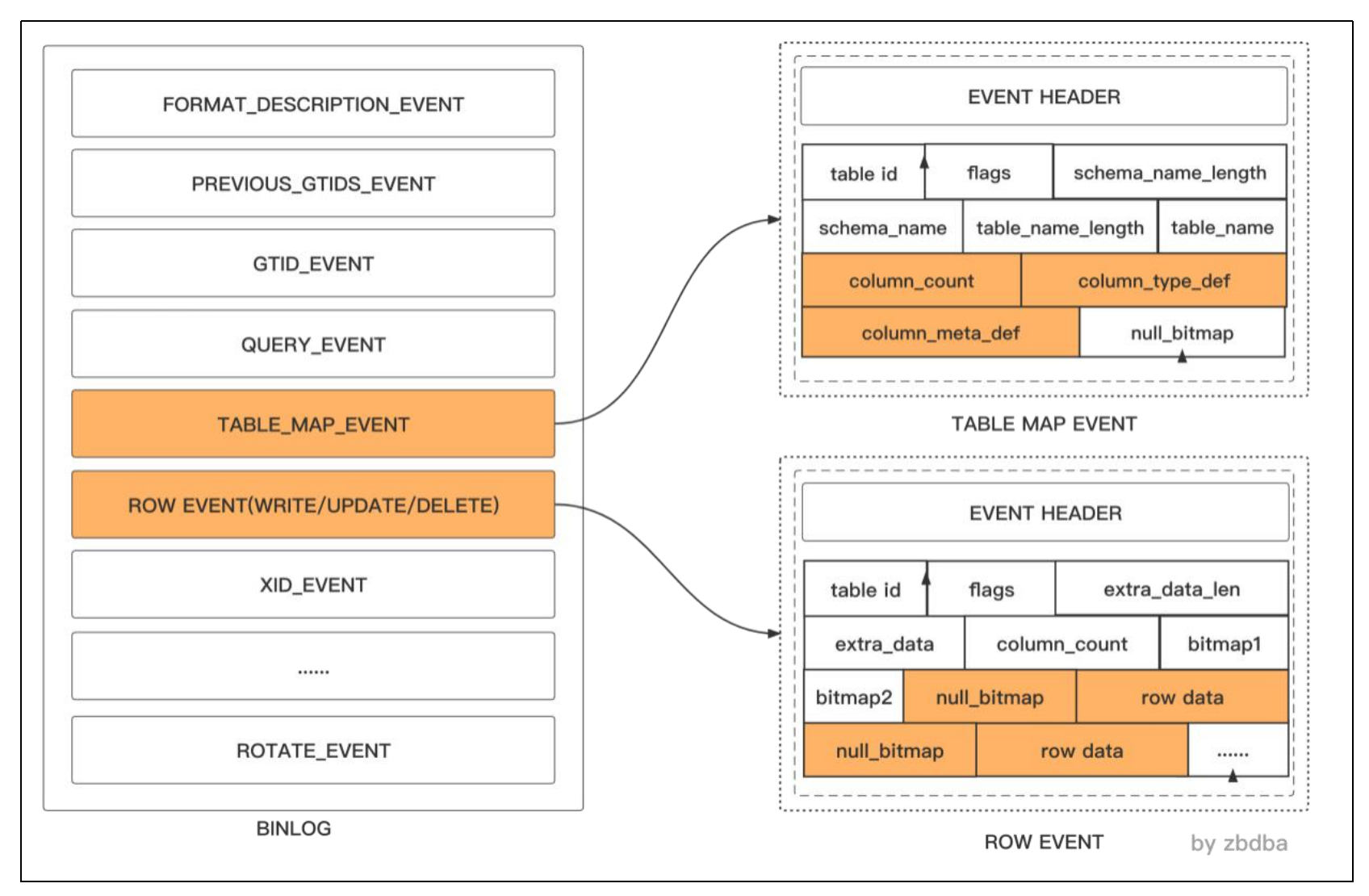
闪回恢复核心关注的Event类型(ROW模式下)如下,其余管理类Event(如日志切换、格式描述)不影响数据恢复:
3.3.1 基础描述类Event
- Format_desc_event:每个binlog文件的第一个Event,描述当前binlog的版本、格式、服务器信息(如MySQL版本、binlog版本),是解析后续Event的"字典"------闪回工具需先解析该Event,才能识别后续Event的结构。
- Table_map_event:数据表映射Event,记录"数据库名-表名-表ID"的映射关系,以及表的字段结构(字段名、字段类型、主键信息)。ROW模式下,所有行级变更Event(如Update_rows_event)都必须紧跟该Event,闪回工具通过它确定变更对应的表及字段信息。
3.3.2 行级变更类Event(闪回核心)
这类Event仅在ROW模式下存在,记录具体的行数据变更,是生成回滚SQL的核心依据:
- Write_rows_event:对应INSERT操作,记录新增行的完整字段值(仅包含"新值",无旧值)。闪回时,工具将其反向生成为DELETE语句(删除新增的行)。
- Update_rows_event:对应UPDATE操作,记录被更新行的"旧值"(变更前数据)和"新值"(变更后数据),均包含完整字段值(主键+所有普通字段)。闪回时,工具通过"交换新旧值"生成反向UPDATE语句(如将新值`status=0`改回旧值`status=1`)。
- Delete_rows_event:对应DELETE操作,记录被删除行的完整字段值(仅包含"旧值",无新值)。闪回时,工具将其反向生成为INSERT语句(重新插入被删除的行)。
3.3.3 事务控制类Event
- Begin_event_v2:标记事务开始,记录事务ID。闪回工具通过该Event识别事务边界,确保回滚SQL的事务一致性(避免拆分事务导致的数据异常)。
- Xid_event:标记事务提交,记录事务ID和提交时间。闪回时,工具可通过该Event过滤已提交的事务(仅回滚误操作的已提交事务,不处理未提交事务)。
3.4 闪回工具与binlog Event的关联逻辑
my2sql等闪回工具的核心工作流程,本质是"解析binlog Event → 提取变更信息 → 生成反向Event对应的SQL",具体逻辑如下:
- 读取binlog文件,先解析Format_desc_event,获取binlog格式和版本信息;
- 遍历后续Event,遇到Table_map_event时,缓存"表ID-表结构"映射关系;
- 遇到行级变更Event(Update/Delete/Write_rows_event)时,结合对应的Table_map_event,解析出"库名、表名、行数据新旧值、主键";
- 根据`--flashback`参数,生成反向SQL:Update→反向Update、Delete→Insert、Write→Delete;
- 通过Begin_event_v2和Xid_event,确保反向SQL按事务分组,保持原事务的原子性。
理解该逻辑后,就能明白"为什么闪回必须依赖ROW模式"------只有Update_rows_event等行级Event能提供完整的新旧值,这是反向SQL生成的唯一依据。
四、真实案例:批量更新误操作恢复
3.1 误操作场景
开发人员意图更新`user`表中`id=100`的用户状态为0(禁用),但误遗漏`WHERE`条件,执行以下SQL:
-- 误操作:未加WHERE条件,导致1000条用户数据status全部改为0
UPDATE test_db.user SET status = 0;操作后发现所有用户状态被错误修改,业务端反馈用户无法正常登录,需立即恢复数据。
3.2 恢复步骤(基于my2sql)
全程需遵循「定位误操作→生成回滚SQL→审核SQL→执行恢复→验证数据」流程,避免二次误操作。
步骤1:安装my2sql工具
my2sql基于Go开发,需先安装Go环境(1.16+),再通过源码编译或直接下载二进制包:
# 1. 下载源码(GitHub仓库)
git clone https://github.com/liuhr/my2sql.git
cd my2sql
# 2. 编译生成可执行文件(支持Linux/Mac)
go build -o my2sql
# 3. 验证安装(查看版本)
./my2sql -v
# 输出类似:my2sql version 2.3.0步骤2:确认binlog日志信息
先登录MySQL,查询当前binlog文件列表与最新日志文件,定位误操作所在的binlog:
-- 查看当前binlog文件列表
SHOW BINARY LOGS;
-- 输出示例:
-- +------------------+-----------+-----------+
-- | Log_name | File_size | Encrypted |
-- +------------------+-----------+-----------+
-- | mysql-bin.000018 | 10737420 | No |
-- | mysql-bin.000019 | 2000000 | No | # 误操作时写入的binlog文件
-- | mysql-bin.000020 | 1560 | No |
-- 查看当前正在写入的binlog文件
SHOW MASTER STATUS;
-- 输出示例:
-- +------------------+----------+--------------+------------------+-------------------+
-- | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
-- +------------------+----------+--------------+------------------+-------------------+
-- | mysql-bin.000020 | 1560 | | | 88a888d8-xxxx-xxxx |
-- +------------------+----------+--------------+------------------+-------------------+通过业务日志或操作记录,确认误操作时间为「15:30:00~15:30:30」,结合binlog文件时间戳,确定误操作位于`mysql-bin.000019`文件中。
步骤3:解析binlog,定位误操作范围
使用my2sql解析目标binlog文件,过滤出`test_db.user`表的`UPDATE`操作,精准定位误操作的起始/结束位置(pos点)或GTID:
./my2sql -h 127.0.0.1 -P 3306 -u root -p'YourPassword' \
--start-file=mysql-bin.000019 \
--start-datetime='2025-12-27 15:30:00' \
--stop-datetime='2025-12-27 15:30:30' \
-d test_db -t user \
--sql-type=update \
--print-header > /tmp/raw_update.sql参数说明:
- -h/-P/-u/-p:数据库连接信息
- --start-file/--stop-file:指定解析的binlog文件
- --start-datetime/--stop-datetime:过滤误操作时间范围
- -d/-t:指定数据库与表,精准过滤
- --sql-type=update:仅解析UPDATE操作(排除无关操作)
- --print-header:输出SQL包含pos点、时间等头部信息,便于定位
查看解析结果`/tmp/raw_update.sql`,找到误操作SQL对应的pos范围:
-- 头部信息示例:# startTime=2025-12-27 15:30:10, endTime=2025-12-27 15:30:10, pos=1000-25000
UPDATE test_db.user SET status=0 WHERE id=1 AND name='zhangsan' AND age=20 AND status=1;
UPDATE test_db.user SET status=0 WHERE id=2 AND name='lisi' AND age=22 AND status=1;
-- ... 共1000条UPDATE语句(对应批量误操作)确定误操作的pos范围为「1000~25000」,后续仅针对该范围生成回滚SQL。
步骤4:生成回滚SQL
使用my2sql的`--flashback`参数,针对误操作pos范围生成反向UPDATE语句(将status从0改回1),并输出到文件:
./my2sql -h 127.0.0.1 -P 3306 -u root -p'YourPassword' \
--start-file=mysql-bin.000019 \
--start-position=1000 \
--stop-position=25000 \
-d test_db -t user \
--sql-type=update \
--flashback > /tmp/rollback.sql核心参数`--flashback`:生成反向操作SQL,原理为「交换UPDATE语句的SET与WHERE值」------将误操作的`SET status=0`改为`SET status=1`,WHERE条件保留原数据的完整值(确保仅恢复误操作数据)。
步骤5:审核回滚SQL(关键!)
执行回滚前必须审核SQL,避免包含正常操作或错误语句:
-- 查看回滚SQL示例(仅展示前2条)
UPDATE test_db.user SET status=1 WHERE id=1 AND name='zhangsan' AND age=20 AND status=0;
UPDATE test_db.user SET status=1 WHERE id=2 AND name='lisi' AND age=22 AND status=0;审核要点:确认回滚SQL的SET值为误操作前的正确值(status=1),WHERE条件包含完整的行数据(避免误更新其他数据),且SQL数量与误操作数据量一致(1000条)。
步骤6:执行回滚并验证数据
在业务低峰期执行回滚SQL(若数据量较大,可分批次执行,避免锁表影响业务):
-- 执行回滚SQL
mysql -h 127.0.0.1 -P 3306 -u root -p'YourPassword' < /tmp/rollback.sql执行完成后,登录MySQL验证数据恢复情况:
-- 统计status=1的用户数量(应恢复为1000条)
SELECT COUNT(*) FROM test_db.user WHERE status=1;
-- 输出:1000
-- 查看指定用户数据(确认单条数据恢复正确)
SELECT * FROM test_db.user WHERE id=100;
-- 输出:id=100, name='xxx', age=25, status=1(恢复为误操作前状态)数据全部恢复正常,业务端反馈用户可正常登录,恢复完成。
五、误删除数据恢复补充说明
若误操作是`DELETE`(无过滤条件删除批量数据),恢复流程与上述一致,核心差异为:
- 解析binlog时,`--sql-type=delete`
- 生成回滚SQL时,my2sql会将`DELETE`操作反向生成为`INSERT`语句(包含被删除行的完整字段值)
- 执行回滚前需确认表中无重复主键数据(避免插入冲突)
示例回滚SQL(DELETE误操作):
INSERT INTO test_db.user (id, name, age, status) VALUES (1, 'zhangsan', 20, 1);
INSERT INTO test_db.user (id, name, age, status) VALUES (2, 'lisi', 22, 1);六、关键注意事项与预防措施
5.1 恢复操作注意事项
- 恢复前必须备份当前数据:执行`mysqldump`或`mydumper`备份目标表,避免回滚失败导致二次数据丢失
- 优先在测试环境验证:将binlog文件复制到测试环境,先执行回滚验证,确认无误后再操作生产库
- 避免在业务高峰期执行:回滚大批量数据可能触发表锁,需选择低峰期(如凌晨)操作
- 不支持DDL操作恢复:若误执行`DROP TABLE`、`TRUNCATE`等DDL,闪回工具无法恢复,需依赖备份
5.2 误操作预防措施
最好的恢复是无需恢复,建议从以下维度预防批量误操作:
- 权限管控:限制开发人员对生产库的`DELETE`、`UPDATE`权限,高危操作需DBA审核后执行
- SQL审核:接入SQL审核工具(如美团SQLAdvisor、阿里Druid),拦截无`WHERE`条件的高危SQL
- 开启事务确认:执行高危SQL前开启事务(`BEGIN`),验证结果后再提交(`COMMIT`),避免直接执行
- 完善备份策略:采用「全量备份+增量binlog备份」,确保数据可通过备份恢复兜底
- 监控告警:对大批量DML操作(如影响行数>1000)触发告警,及时发现异常操作
七、总结
MySQL闪回技术基于binlog解析,是批量数据误操作的高效恢复方案,其中my2sql工具因支持高版本、离线解析、功能全面等优势,成为生产环境首选。本文通过真实批量更新案例,详细演示了my2sql的恢复流程,核心在于「精准定位误操作范围→生成反向SQL→审核执行→验证数据」。
需要注意的是,闪回工具仅能解决DML误操作问题,且依赖正确的binlog配置,因此日常运维中需做好binlog配置与权限管控,结合备份策略与SQL审核,形成「预防-兜底-恢复」的完整数据安全 体系。