企业是国民经济的微观基石,而头部企业的发展轨迹往往折射出整个经济体的结构性变迁。自《财富》中文网发布中国500强榜单以来,这份以营业收入为基准的排名不仅记录了中国企业规模的快速扩张,也成为观察产业兴衰、竞争格局与增长模式演变的重要窗口。然而,在中国经济由高速增长迈向高质量发展的关键阶段,仅关注"谁上榜"或"营收多少"已难以捕捉深层趋势------规模背后是否伴随效率提升?增长是否可持续?新旧动能如何更替?这些问题亟需超越单一指标的系统性审视。
为此,本文基于2020至2025年《财富》中国500强完整榜单数据,通过自动化采集与结构化清洗,构建了一个涵盖五大维度的分析框架:整体营收规模与上榜门槛、头部企业集中度(CRn与HHI)、榜单排名流动性、行业结构变迁以及盈利能力演化。这一多维视角不仅揭示了"量"的变化,更深入"质"的层面------从能源金融主导到高端制造崛起,从高集中垄断到多元竞争格局,从低效内卷扩张到盈利压力倒逼转型,数据清晰勾勒出一幅动态、分化且充满张力的中国大企业生态图景。
本分析所用数据均来自《财富》中文网公开发布的中国500强榜单,经标准化处理后确保跨年度可比性。尽管榜单本身以营收为唯一入榜标准,存在一定局限性(,但其连续性、权威性与行业覆盖广度,仍使其成为观察中国大型企业群体演变的宝贵样本。本文无意对个别企业成败进行评判,而是试图从宏观数据流变中提炼结构性信号------当"做大"不再自动等同于"做强",当"上榜"不再意味着"安全",中国头部企业正站在效率、创新与可持续性的新十字路口。这份基于五年数据的回溯与梳理,希望能为政策制定者、企业管理者与市场观察者提供一份冷静、扎实的参考。
2025年《财富》中国500强查询网址:2025年《财富》中国500强 - 财富中文网

首先,我们找到500强公司数据的存储位置,然后看3个关键部分标头、 负载、 预览;
**标头:**通常包括URL的连接,也就是目标资源的位置;
**负载:**对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里我们可以看到这个网页是静态 HTML,直接就没有负载;
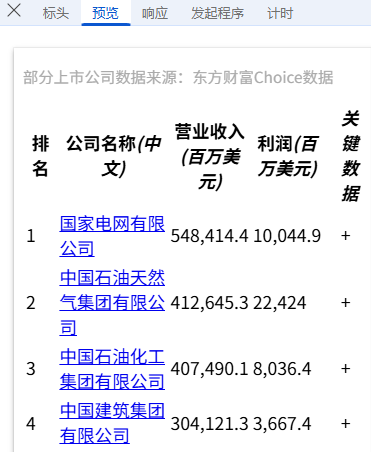
**预览:**指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,我们可以看到数据在HTML里;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应中国500强营收数据存储位置;
- 解析出完整的公司排名表格(排名、上年排名、公司名称、营业收入、利润)等字段;
- 结果保存为 CSV 文件;
**第一步:**利用requests库发送HTTP请求获取所有地级行政区编码表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import csv
import os
# 所有年份的 URL 列表
year_urls = {
2025: "https://www.fortunechina.com/fortune500/c/2025-07/22/content_467056.htm",
2024: "https://www.fortunechina.com/fortune500/c/2024-07/25/content_455919.htm",
2023: "https://www.fortunechina.com/fortune500/c/2023-07/25/content_435913.htm",
2022: "https://www.fortunechina.com/fortune500/c/2022-07/12/content_413677.htm",
2021: "https://www.fortunechina.com/fortune500/c/2021-07/20/content_392708.htm",
2020: "https://www.fortunechina.com/fortune500/c/2020-07/27/content_369925.htm",
2019: "https://www.fortunechina.com/fortune500/c/2019-07/10/content_337536.htm",
2018: "https://www.fortunechina.com/fortune500/c/2018-07/10/content_309961.htm"
}
# 设置请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
"Referer": "https://www.fortunechina.com/"
}
# 存储所有年份数据
all_combined_data = []
for year, url in year_urls.items():
print(f"\n{'='*50}")
print(f"正在处理 {year} 年榜单...")
print(f"URL: {url}")
try:
response = requests.get(url, headers=headers, timeout=15)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 尝试查找标准表格(id="table1")
table = soup.find('table', id='table1')
if not table:
raise ValueError("未找到榜单表格(id='table1')")
# 提取数据行
rows_data = []
for tr in table.find('tbody').find_all('tr'):
cells = tr.find_all('td')
if len(cells) < 6:
continue
rank = cells[0].get_text(strip=True)
last_rank = cells[1].get_text(strip=True)
company = cells[2].get_text(strip=True)
revenue = cells[3].get_text(strip=True)
profit = cells[4].get_text(strip=True)
rows_data.append([rank, last_rank, company, revenue, profit])
all_combined_data.append([year, rank, last_rank, company, revenue, profit])
if not rows_data:
print(f" {year} 年未提取到有效数据")
continue
# 打印前3行预览
print(f"\n成功解析 {len(rows_data)} 家公司!前3行如下:")
print(f"{'排名':<4} {'上年':<4} {'公司名称':<30} {'营收(百万美元)':<15} {'利润(百万美元)':<15}")
print("-" * 80)
for row in rows_data[:3]:
print(f"{row[0]:<4} {row[1]:<4} {row[2]:<30} {row[3]:<15} {row[4]:<15}")
# 保存单年 CSV
output_file = f"财富中国500强_{year}.csv"
with open(output_file, 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
writer.writerow(['排名', '上年排名', '公司名称', '营业收入(百万美元)', '利润(百万美元)'])
writer.writerows(rows_data)
print(f"\n已保存:{os.path.abspath(output_file)}")
except Exception as e:
print(f" {year} 年处理失败: {e}")
# 可选:保存合并总表
if all_combined_data:
combined_file = "财富中国500强_2018_2025_合并.csv"
with open(combined_file, 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
writer.writerow(['年份', '排名', '上年排名', '公司名称', '营业收入(百万美元)', '利润(百万美元)'])
writer.writerows(all_combined_data)
print(f"\n合并总表已生成:{os.path.abspath(combined_file)}")
print("\n所有年份处理完成!")获取数据标签如下:rank(排名)、last_rank(上年排名)、company(公司名称)、revenue(营业收入)、profit(利润),其他一些非关键标签,这里省略;
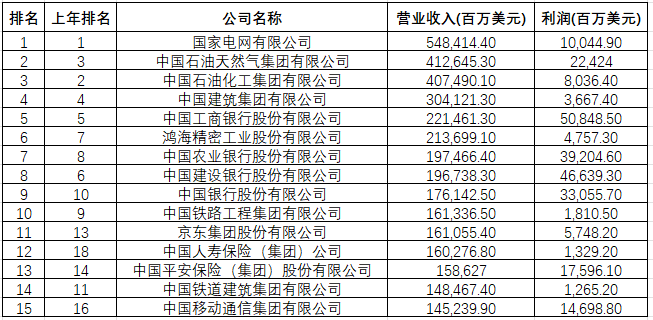
这里是把2020年---2025年以来的数据都拿到了,包含每年的中国500强数据,和一张汇总表;
接下来,我们进行看图说话:
视角1:我们先来看一下中国500强企业整体营收规模和上榜门槛值变化(2020--2025)
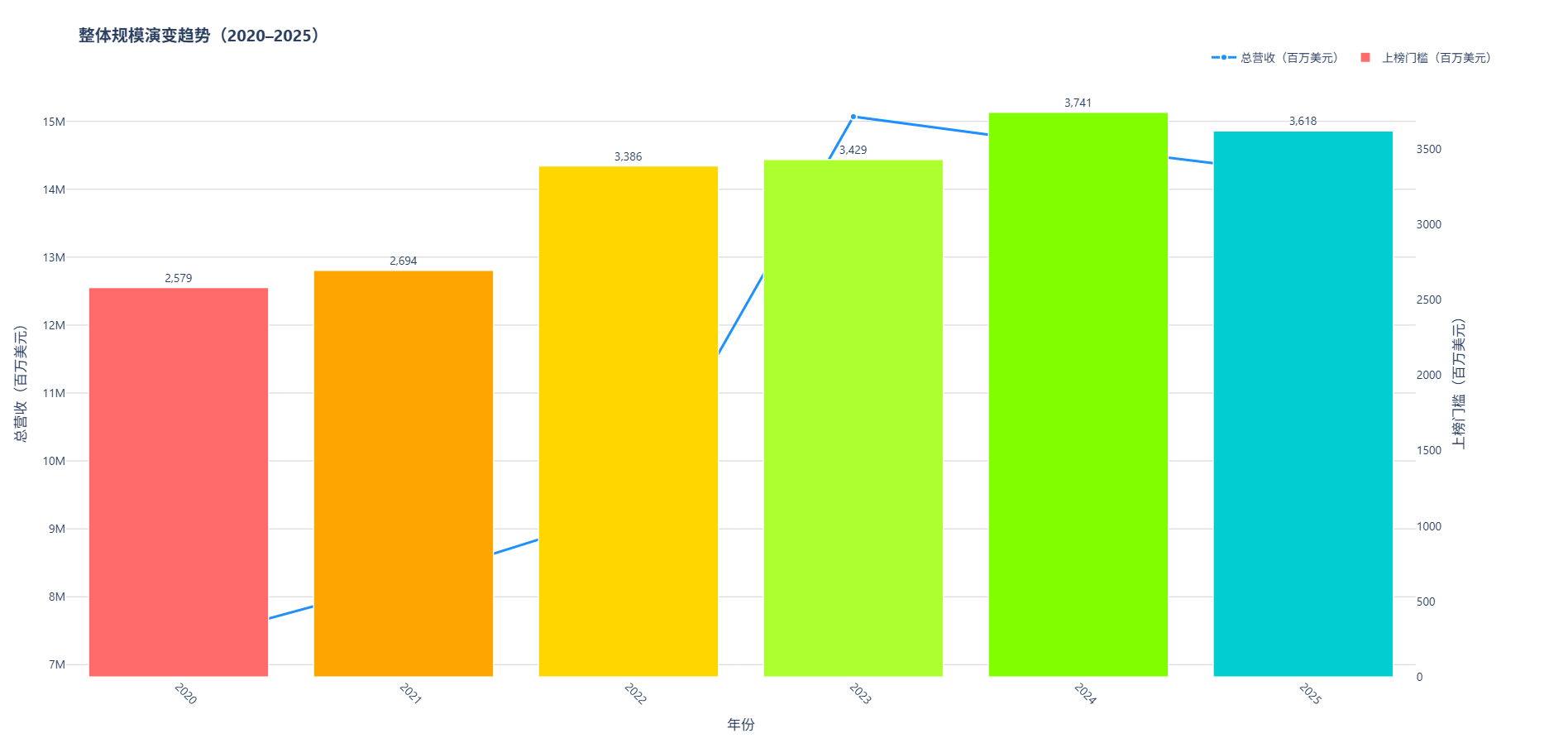 从2020年至2025年,中国500强企业的整体营收呈现稳步增长态势 ,总营收由2020年的约 7.32万亿美元 上升至2025年的 14.2万亿美元 ,期间虽在2021年略有放缓,但自2022年起加速扩张,尤其在2023年实现显著跃升,达到峰值 15.万亿美元 ,反映出企业经营韧性增强与经济复苏的积极信号。与此同时,上榜门槛值也持续攀升,从2020年的 257.9 亿美元 提升至2025年的 361.8 亿美元,增幅超过40%,表明行业集中度不断提高,头部企业对资源的吸纳能力进一步加强。值得注意的是,尽管2024年总营收略有回落,但门槛值仍保持高位,说明市场"强者恒强"格局趋于稳固。整体来看,中国500强企业在规模扩张的同时,正经历从"量增"向"质优"的结构性升级,未来发展趋势值得持续关注。
从2020年至2025年,中国500强企业的整体营收呈现稳步增长态势 ,总营收由2020年的约 7.32万亿美元 上升至2025年的 14.2万亿美元 ,期间虽在2021年略有放缓,但自2022年起加速扩张,尤其在2023年实现显著跃升,达到峰值 15.万亿美元 ,反映出企业经营韧性增强与经济复苏的积极信号。与此同时,上榜门槛值也持续攀升,从2020年的 257.9 亿美元 提升至2025年的 361.8 亿美元,增幅超过40%,表明行业集中度不断提高,头部企业对资源的吸纳能力进一步加强。值得注意的是,尽管2024年总营收略有回落,但门槛值仍保持高位,说明市场"强者恒强"格局趋于稳固。整体来看,中国500强企业在规模扩张的同时,正经历从"量增"向"质优"的结构性升级,未来发展趋势值得持续关注。
视角2:中国500强企业头部企业集中度 Top 10 / Top 50 营收占比(2020--2025)
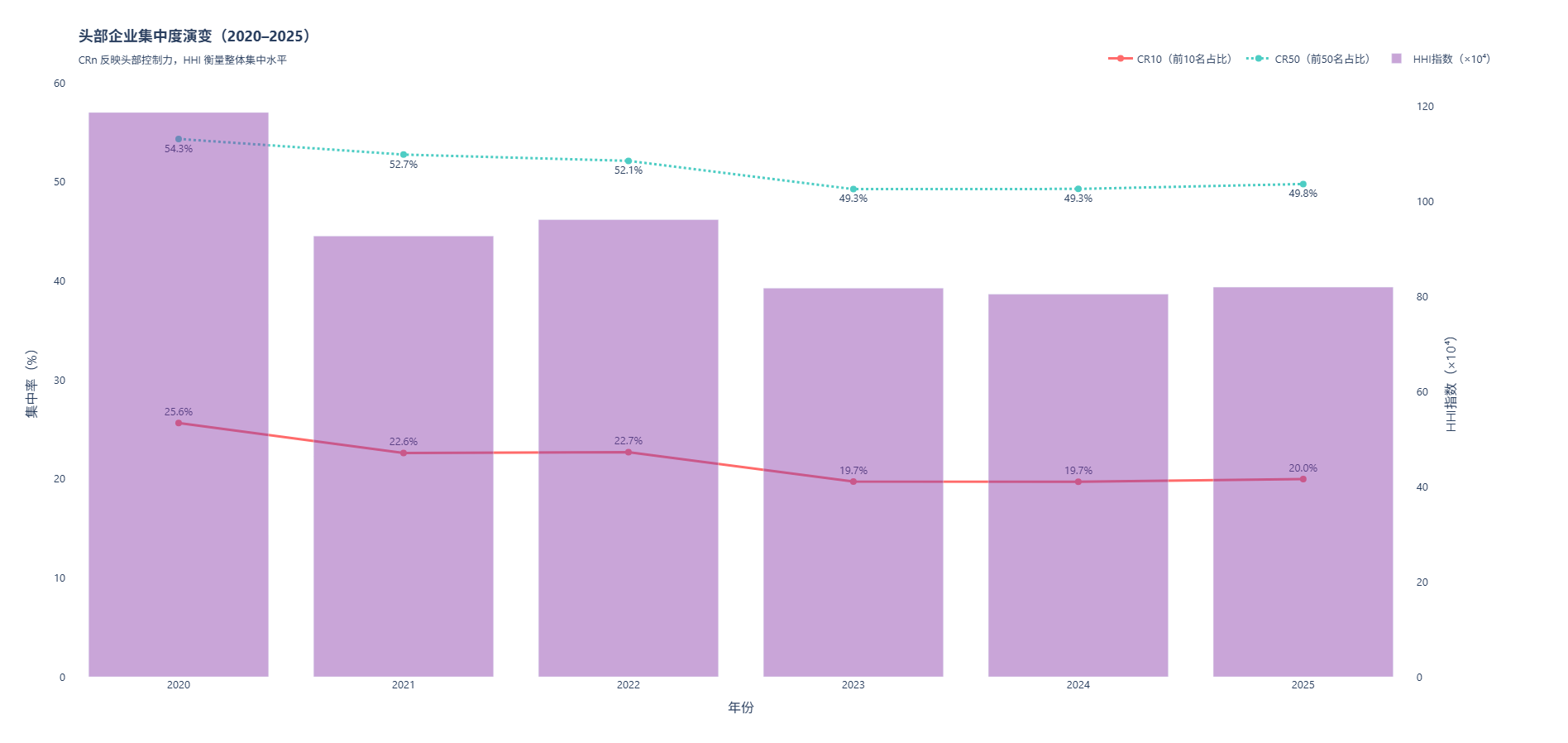
2020至2025年间,中国500强企业的市场集中度呈现显著下降趋势,反映出中国经济结构正经历深刻的"去中心化"转型。数据显示,前10名企业营收占比(CR10)从2020年的25.6%持续回落至2025年的20.0% ,前50名企业占比(CR50)也由54.3%降至49.8% ,与此同时,衡量整体集中水平的赫芬达尔指数(HHI)从约115,000大幅下降至82,000,降幅近三成。这一系列变化表明,过去由能源、金融等少数巨头主导的"金字塔型"格局正在松动,资源分配趋于更加均衡和多元。尤其在2023年,集中度出现断崖式下降,凸显反垄断政策深化、传统行业调整与新兴力量崛起的叠加效应。尽管2024--2025年头部企业影响力略有回升,但整体仍处于历史低位,说明以新能源、高端制造、数字经济为代表的新质生产力正加速重塑大企业生态。这一趋势不仅体现了市场竞争活力的增强,也标志着中国经济正从依赖少数巨头拉动,转向由多层次、多领域企业共同驱动的高质量发展新阶段。
视角3:中国500强企业榜单排名流动性分析(2020--2025)
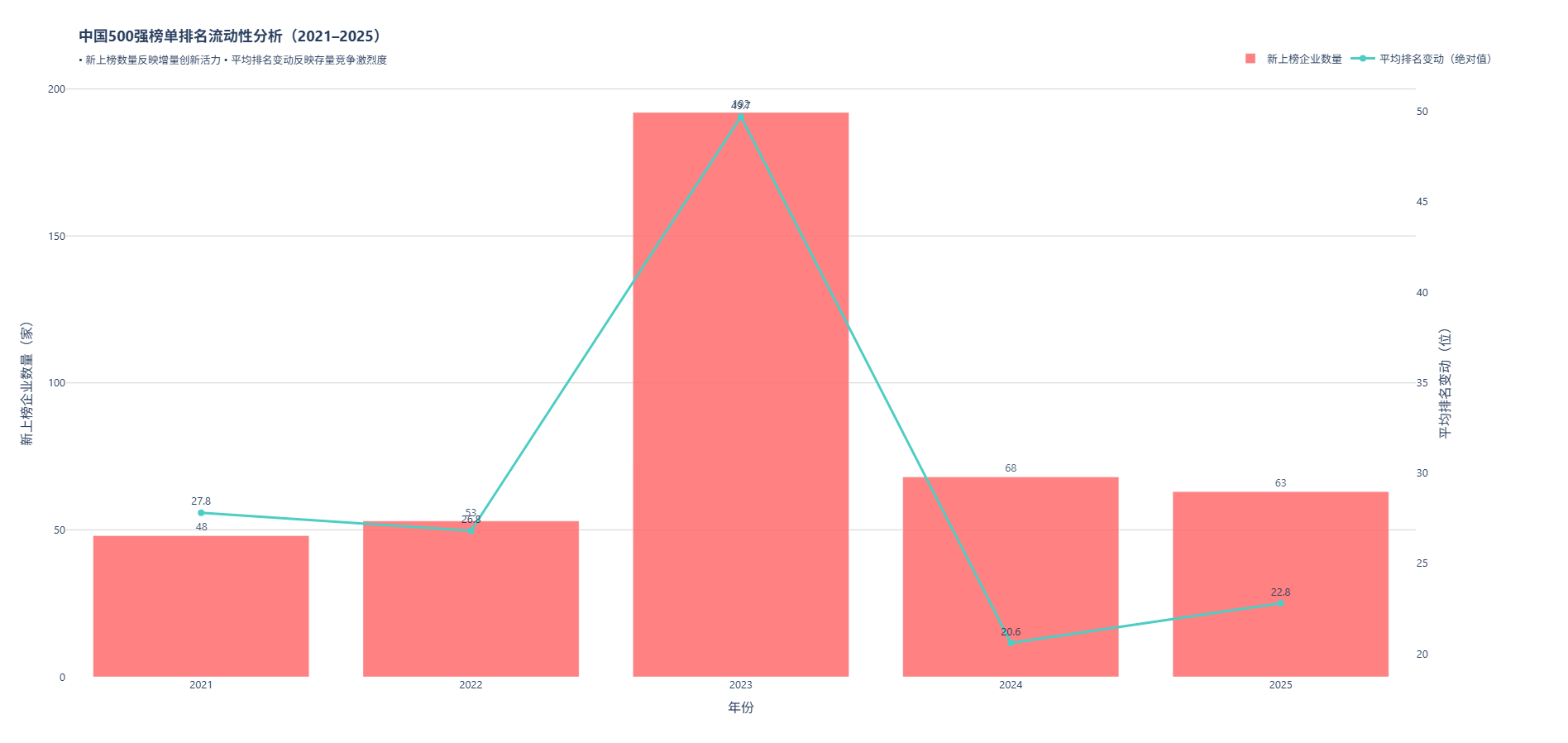
2020至2025年间,中国500强榜单展现出剧烈而结构性的动态更替 ,凸显经济转型期"新旧动能"切换的深度与速度。五年间累计 424家次企业新上榜 ,年均85家,其中2023年出现异常高峰------单年新增192家企业,远超其他年份,主要源于金融监管改革推动地方银行集中入榜(如上海农商行跃升159位),以及政策对专精特新、绿色低碳企业的强力支持。
与此同时,存量企业竞争白热化。平均每年排名变动达26--50位 ,2023年波动最为剧烈(49.7位),反映外部环境剧变下企业命运的快速分化。"黑马"企业多来自战略新兴领域 :牧原股份(2021,+248)、东方盛虹(2022,+173)、理想汽车(2024,+140)和赛力斯(2025,+235)的集体崛起,印证了新能源车、高端材料、现代农业等赛道的爆发式增长。反观退步企业,则高度集中于受政策调整冲击的传统行业:申能股份(能源转型阵痛)、欧菲光(供应链重构)、华融资产(金融风险出清)、陆金所(金融科技监管)及金科地产(房地产深度调整)的大幅下滑,揭示了旧增长模式的不可持续性。
值得注意的是,2024--2025年新上榜数量回落至60余家,但跃迁质量显著提升------以赛力斯为代表的企业凭借与华为合作的智能电动汽车实现"现象级"增长,表明创新正从"广撒网"转向"深突破"。整体来看,中国500强已进入"高流动、高分化、高迭代"的新阶段,榜单不再是静态荣誉,而是中国经济新陈代谢活力的实时晴雨表。
视角4:中国500强企业榜单排名流动性分析(2020--2025)
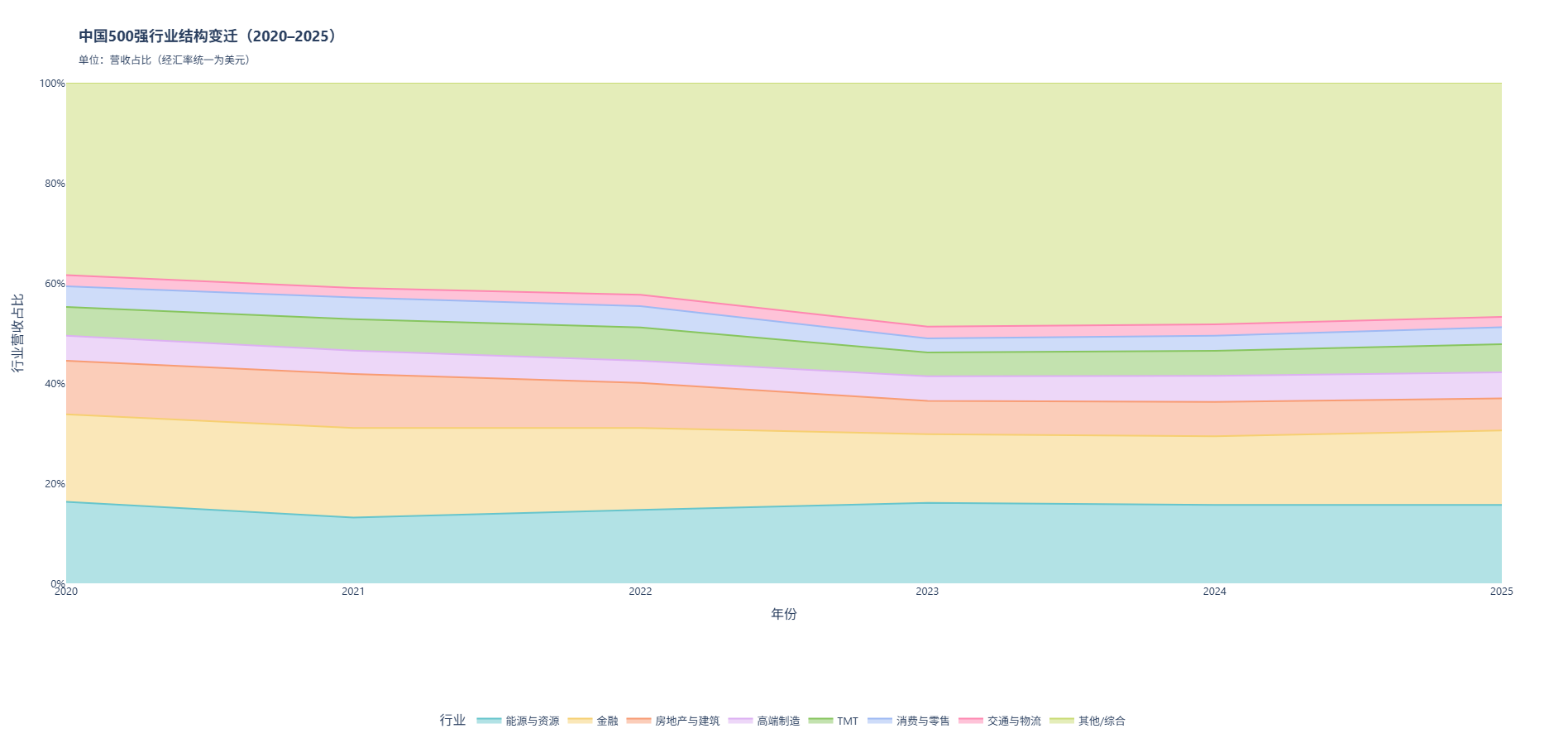
2020至2025年间,中国500强企业的行业格局呈现出"传统支柱持续收缩、新兴力量稳步崛起 "的深刻演变。从营收占比看,能源与资源 和金融 两大传统支柱合计占比由2020年的约45%降至2025年的38%,显示其对经济的主导地位正在被削弱;与此同时,房地产与建筑板块自2021年起持续下行,2025年占比已不足10%,标志着地产黄金时代的终结。
与此形成鲜明对比的是,以高端制造 和TMT 为代表的新兴产业实现逆势扩张。高端制造营收占比从2020年的约6%稳步提升至2025年的12%,成为增长最快板块之一,背后是新能源汽车、光伏储能、半导体等领域的爆发式发展;TMT板块也保持稳定增长,反映数字经济的持续渗透力。此外,消费与零售 和交通与物流维持相对平稳,而"其他/综合"类企业占比长期居高不下,反映出大型多元化集团在榜单中的重要地位。
整体来看,中国500强正经历一场从"资源+金融驱动"向"技术+制造驱动"的战略转型。尽管传统行业仍占主体,但新兴力量已从边缘走向核心,构成中国经济新质生产力的重要支撑。这一趋势不仅体现了产业升级的必然性,也预示着未来市场竞争将更加依赖技术创新与全球竞争力。
视角5:中国500强盈利能力深度分析(2020--2025)
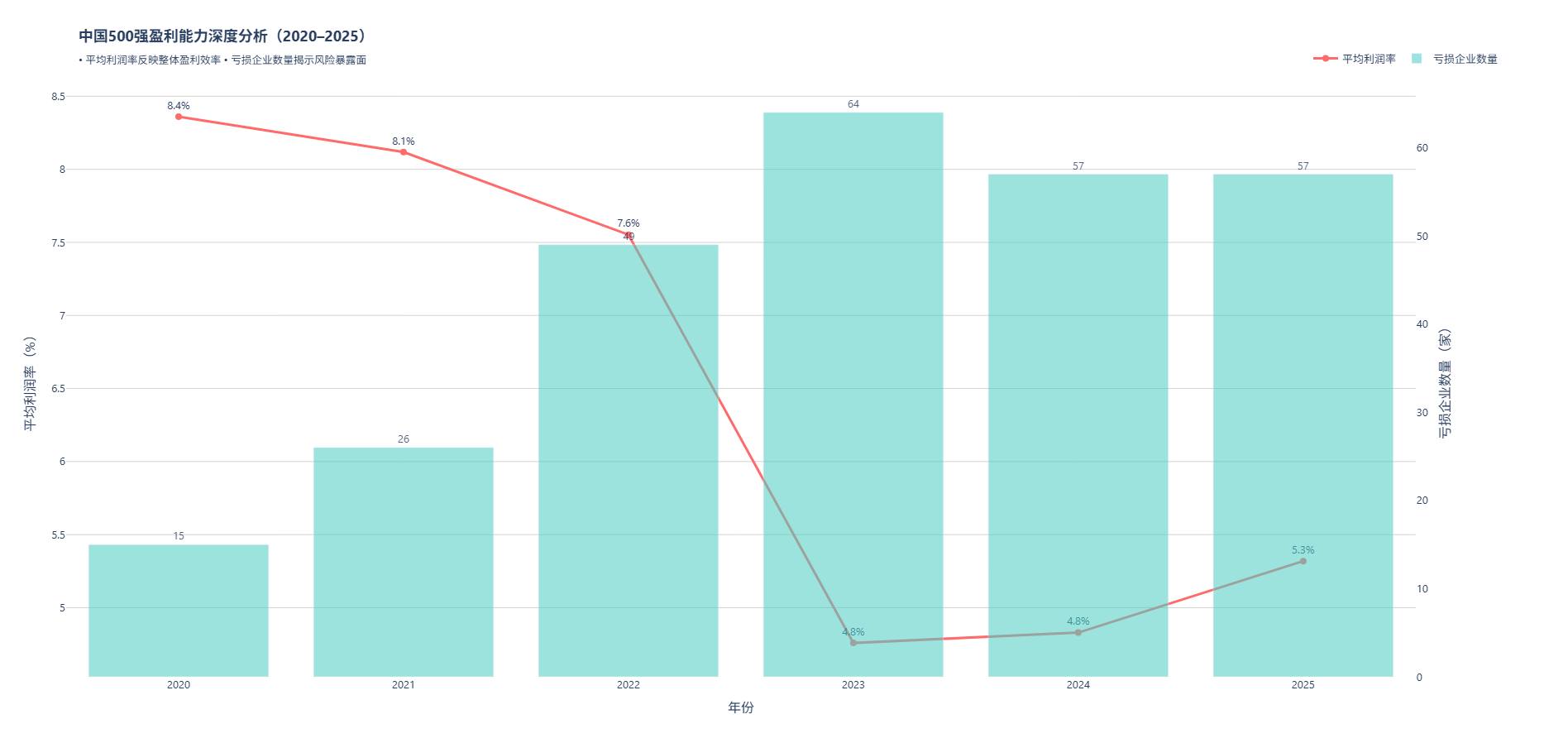
2020至2025年间,中国500强企业的盈利格局呈现出"整体效率下滑、风险暴露加剧 "的显著特征---平均利润率从8.4%降至5.3%,亏损企业数量翻了近四倍。这一趋势不仅反映成本高企与需求疲软的宏观压力,更暴露出长期依赖"规模扩张+价格战"的内卷式增长模式已走到尽头。过去,许多企业通过压低利润、扩大产能、抢占份额来维持榜单地位,结果却陷入"营收增长、利润萎缩"的陷阱,甚至因过度杠杆或同质化竞争而滑入亏损泥潭。
如今,市场正以残酷的方式倒逼企业"反内卷 ":2023年成为分水岭,那些仍沉迷于低效扩张的企业加速出清,而真正具备技术壁垒、品牌溢价或独特商业模式的头部公司(如高端制造、新能源、核心消费品牌)则在微利环境中稳住阵脚,甚至逆势提升盈利质量。这印证了一个关键转变------未来的竞争力不再来自"谁做得更大",而在于"谁做得更不可替代"。
因此,"反内卷"并非简单的降本裁员,而是战略层面的升维:从拼资源转向拼创新,从抢市场转向建护城河,从追求短期排名转向构建可持续盈利模型。中国500强若想穿越周期,必须告别"以量补价"的旧逻辑,在产品力、技术自主性和客户价值上真正实现高质量突围。唯有如此,才能在"总量见顶、利润承压"的新常态中,走出一条不靠内耗也能赢的道路。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。